一、说明
在我之前的文章中,我讨论了推荐系统的基础知识、矩阵分解和神经协同过滤 (NCF),您可以在下面的“我的博客”部分找到它们。接下来,这次我将通过示例和代码来探索因式分解机器。
将因子分解机用于推荐系统的一些优点是
- 它相对很好地处理稀疏和高维数据。
- 您可以在用户和项目周围添加元信息以获得更多上下文。因此,因子分解机不是像NCF和矩阵分解那样仅使用用户-项目交互的纯协同过滤方法。
因子分解机是一种受监督的ML算法,可用于分类和回归。虽然,它以推荐系统而闻名。也
它可以被视为线性回归的扩展,除了捕获线性关系外,
通过使用潜在分解引入高阶特征交互,也可以捕获高阶关系。
二、什么是高阶特征交互?
高阶交互作用是指两个或多个特征对目标变量的综合效应,其中影响不是线性的,不能用单个特征效应的总和来表示。例如
假设我们有用户是否会点击广告的分类数据。功能集具有
用户 ID、用户年龄、广告类型、广告 ID、点击与否(标签)
我们可能会发现,“广告类型”对用户点击广告的可能性的影响取决于“用户年龄”。例如,年轻用户可能更有可能点击图片广告,而年长用户可能更喜欢视频广告。这种互动意味着“广告类型”的影响并非在所有年龄段都一致。为了捕捉这种高阶互动,模型需要考虑“广告类型”和“用户年龄”如何相互作用以影响点击率。
因子分解机可以帮助我们捕获线性回归忽略的高阶交互作用。
FM 模型方程包含不同阶次特征之间的 n 向交互作用。最普遍的配置是二阶模型,它包含数据集中单个特征的权重和每对特征的交互作用项。我将在这篇文章中解释双向交互。
三、它是如何实施的?让我们用一个例子来理解
假设我们有以下用户-项交互数据
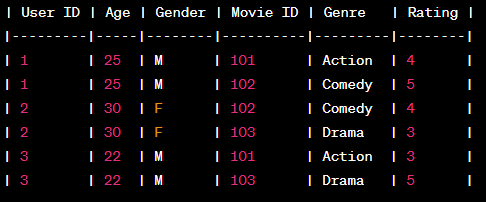
如您所见,除了用户-项目交互之外,它还具有有关用户和项目的一些元信息。
- 独热编码数据集中存在的分类特征。这将包括用户(用户ID)和项目(电影ID)列的One-Hot En编码以及标签(评级)列除外。
四、因式分解机方程
y = w₀ + ∑(wi * xi) + ∑i(∑j(<vi . vj> * xi * xj))
哪里
y = 标签
w₀ = 偏差
wi = 权重
xi = 来自 One-Hot 编码特征集的功能
<六.vj> = 潜在向量之间的点积
注意:如果忽略第 3 项,则第 1 项将形成线性回归方程。
- 前两项类似于线性回归,其中 w₀=bias 和
- wi * xi 捕获每个 One-Hot-Encoding 特征的权重。
- 第 3 项对于捕获高阶交互很重要
∑i(∑j(<vi . vj> * xi * xj)),我们将在One-Hot Encoding 所有特征以及点积之后获得的每一列相乘这些 OHE 列的潜在向量表示之间。
假设我们有 2 个功能,年龄和流派,其中流派有两个可能的值:动作和喜剧,那么 FM 中 One-Hot 编码流派(Genre_Action 和 Genre_Comedy)之后的第 3 个术语将如下所示
<v_age .v_age> * 年龄 * 年龄 +
<v_genre_action .v_genre_action> * genre_action* genre_action+
<v_genre_comedy .v_genre_comedy> * genre_comedy* genre_comedy+
<v_age .v_genre_action> * 年龄 * genre_action +
<v_age .v_genre_action>年龄 * genre_comedy +
<v_genre_action .v_genre_comedy> * genre_comedy* genre_action
在这里,您可以看到,对于每对可能的 OHE 列,我们将有一个项,捕获它们的相互作用以及它们的潜在向量表示。由于“流派”有两个可能的值,因此它被分成两列。 “年龄”是数字,因此此列没有 OHE。因此,对于 3 列,我们得到了 6 种不同的组合
W₀、WI 和 VI 是模型在训练过程中将学习的实体。
最后一个疑问
为什么我们在第三项中不使用权重矩阵代替潜在向量?还是潜在向量类似于某些权重矩阵?
潜在向量与权重矩阵不同。它们的尺寸通常较小。
这样做是因为潜在向量的数量通常远小于在第 3 项中形成的唯一特征组合的数量。这在处理高维数据集时特别有利,因为完整的权重矩阵将变得计算昂贵且占用大量内存。
数学够了,是时候采取行动了
首先,我们需要一个虚拟数据集。我们将使用具有 10 个特征的 sklearn.datasets 创建一个。
注意: 此示例适用于任何类型的分类。对于推荐,整个过程保持不变
#pip install git+https://github.com/coreylynch/pyFM
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from pyfm import pylibfm
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=100000,n_features=10, n_clusters_per_class=1)让我们看看我们的训练数据集
和标签

- 接下来,我们将使用加载的数据集创建一个字典,其中特征名称作为键,相应的值作为值。训练数据集的每一行将由一个这样的字典表示
data = [ {v: k for k, v in dict(zip(i, range(len(i)))).items()} for i in X]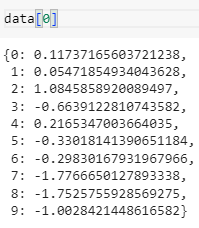
列车测试拆分时间
X_train, X_test, y_train, y_test = train_test_split(data, y, test_size=0.1, random_state=42)- 现在,正如在因子分解机中所讨论的,我们将把所有特征转换为One-Hot向量。这将使用DictVectorizer完成。这将产生一个稀疏矩阵
v = DictVectorizer()
X_train = v.fit_transform(X_train)
X_test = v.transform(X_test)接下来,让我们训练因子分解机并分析测试数据的结果
fm = pylibfm.FM(num_factors=50,num_iter=10, verbose=True, task="classification", initial_learning_rate=0.0001, learning_rate_schedule="optimal")
fm.fit(X_train,y_train)
# Evaluate
from sklearn.metrics import log_loss,accuracy_score
print("Validation log loss: %.4f" % log_loss(y_test,fm.predict(X_test)))
print("Validation accuracy: %.4f" % accuracy_score(y_test,np.where(fm.predict(X_test)<0.5,0,1)))上面显示的实现非常简单。但是,您应该考虑调整几个关键的超参数
num_factors:潜在向量的大小 (v)。尺寸越大,它可以捕获的复杂性就越高,但计算和内存量很大。
任务:分类(隐式反馈)/回归(显式反馈)任务
下面附的屏幕截图描述了培训的进行情况
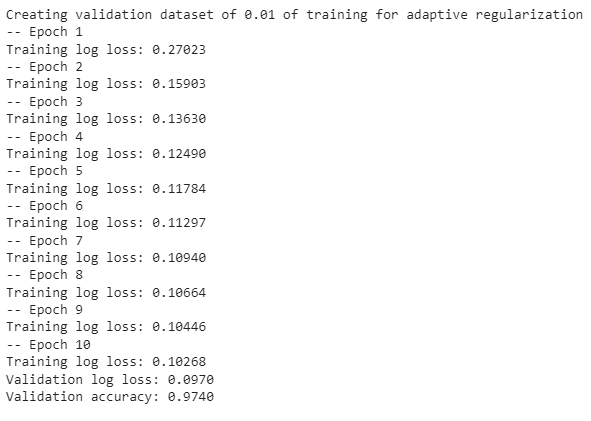
如您所见,我们在logloss=97.0时达到了097%的准确率,这很棒!!
许多其他库也提供了因子分解机的实现,如xlearn,fastFM等,你可以尝试一下。梅胡尔·古普塔









![B站:AB test [下]](https://img-blog.csdnimg.cn/02ee3d668d0c44ec94f232b11d405470.png)