浏览器面试题
- 1.常见的浏览器内核有哪些?
- 2.浏览器的主要组成部分有哪些?
- 3.说一说从输入URL到页面呈现发生了什么?
- 4.浏览器重绘域重排的区别?
- 5.CSS加载会阻塞DOM吗?
- 6.JS会阻塞页面吗?
- 7.说一说浏览器的缓存机制?
- 8.Cookie相关与HttpOnly
- 9.说说跨站请求伪造(CSRF)攻击
- 10.浏览器的存储
- 11.HTTP与HTTPS、第三方证书工作原理、以及HTTP各个版本
- react原理fiber调度算法
- React中的diff算法
1.常见的浏览器内核有哪些?
浏览器的内核分成两部分:
渲染引擎和JS引擎(⚠️注意:我们常说的浏览器内核就是指JS引擎)
FireFox 和 Chrome 使用不同的渲染引擎和 JavaScript 引擎:
-
FireFox:
- 渲染引擎: Gecko
- JavaScript 引擎: SpiderMonkey
-
Chrome (以及大多数基于Chromium的浏览器,如新的Microsoft Edge):
- 渲染引擎: Blink (注意:Blink是从WebKit分叉出来的,WebKit是早期Chrome和现在的Safari使用的渲染引擎)
- JavaScript 引擎: V8
2.浏览器的主要组成部分有哪些?
浏览器是一个复杂的应用程序,其主要组件如下:
-
用户界面 (User Interface): 这部分包括地址栏、书签栏、前进/后退按钮、刷新按钮等。简而言之,除了您在浏览页面时看到的内容外,用户界面包括了其他所有部分。
-
浏览器引擎 (Browser Engine): 该模块在用户界面和渲染引擎之间起到中介的作用,传递命令。
-
渲染引擎 (Rendering Engine): 负责显示请求的内容。如果请求的是HTML内容,渲染引擎就负责解析HTML和CSS,并将解析后的内容显示在屏幕上。
-
网络 (Networking): 用于网络调用,例如HTTP请求。它负责发送查询和下载网页、图片、其他资源。
-
JavaScript解释器 (JavaScript Engine): 解析和执行JavaScript来实现网页的动态功能。
-
数据存储 (Data Storage): 这是持久层。浏览器需要在本地存储各种数据,如cookies。HTML5引入了web storage,允许网页本地存储数据。
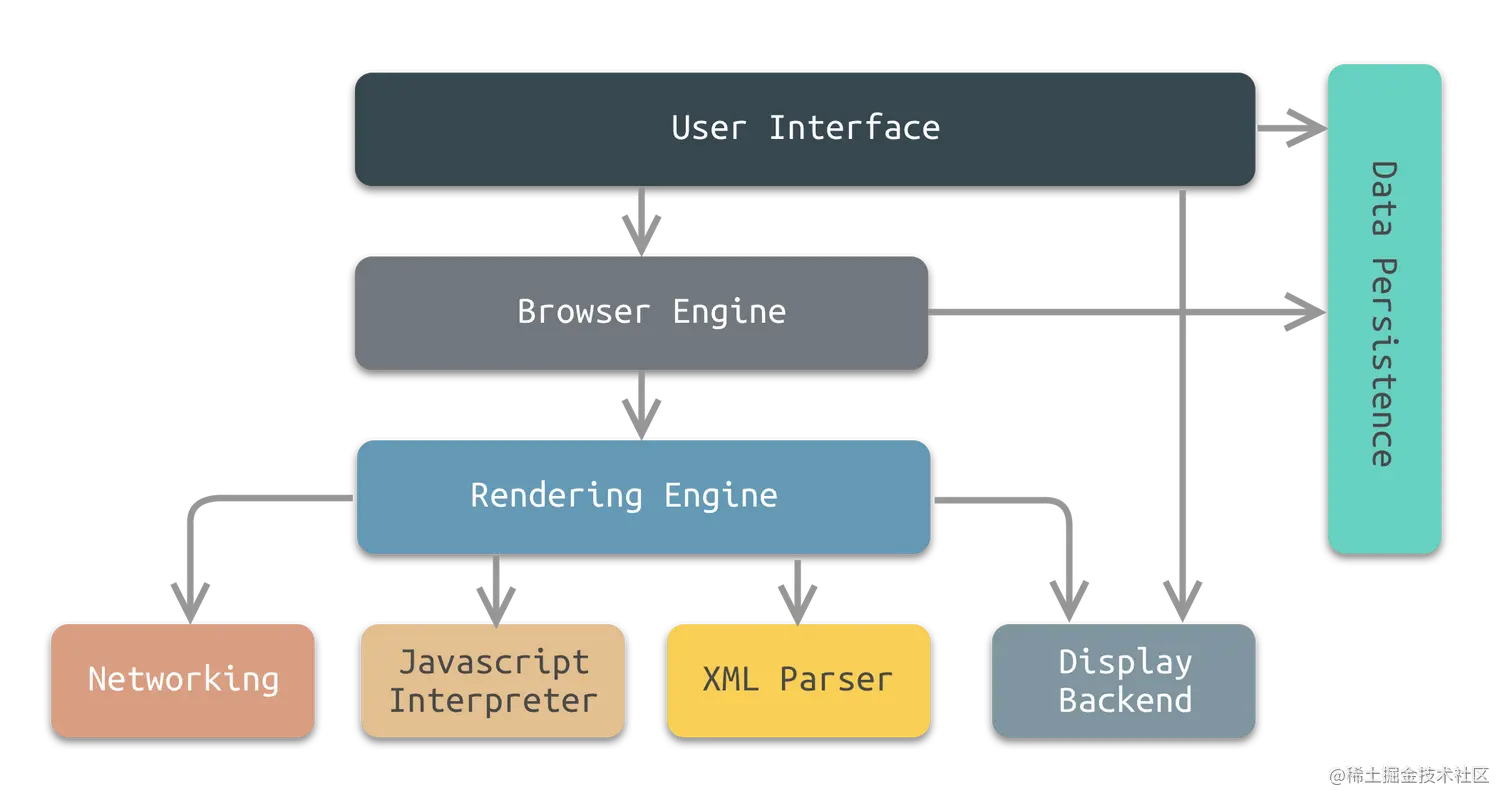
交互流程:
-
当您在地址栏中输入URL并按下Enter时,用户界面指示浏览器引擎加载请求的网页。
-
浏览器引擎告知网络模块获取该URL的内容。
-
一旦网络模块完成下载网页的主要内容(通常是HTML文件),它将数据传递给渲染引擎。
-
渲染引擎开始解析HTML,并在解析过程中遇到其他资源(如CSS文件、JavaScript文件或图片)时请求网络模块加载它们。
-
如果渲染引擎在解析HTML时遇到JavaScript,并且JavaScript没有被延迟或异步加载(deffer\async异步加载js),则渲染引擎暂停HTML解析并将控制权交给JavaScript引擎。一旦JavaScript引擎完成执行,控制权返回渲染引擎。
-
渲染引擎根据HTML和CSS创建渲染树,并在屏幕上显示内容。
-
JavaScript可以用来修改渲染后的页面,它通过DOM(文档对象模型)与页面内容交互。
-
用户与页面交互(例如点击按钮)可能会触发JavaScript代码的执行,这可能会导致页面内容的更改,进而可能会导致重新渲染部分或全部页面。
-
浏览器的数据存储模块在整个过程中也会起到作用,例如,当页面设置或查询cookie时。
⚠️注意:与大多数浏览器不同的是,谷歌(Chrome)浏览器的每个标签页都分别对应一个渲染引擎实例。每个标签页都是一个独立的进程(进程和线程)
3.说一说从输入URL到页面呈现发生了什么?
这个题可以说是面试最常见也是一道可以无限难的题了,一般面试官出这道题就是为了考察你的前端知识深度。
-
URL解析:浏览器首先会解析输入的URL,提取出协议**(如HTTP、HTTPS)**、域名(如www.example.com)和路径等信息。
-
DNS解析:浏览器会向本地DNS解析器发送一个DNS查询请求,以获取输入域名对应的IP地址。如果本地DNS缓存中存在域名的解析结果,则直接返回IP地址;否则,本地DNS解析器会向根DNS服务器、顶级域名服务器和授权域名服务器等级联查询,最终获取到域名的IP地址。
-
建立TCP连接:浏览器使用获取到的IP地址,通过TCP/IP协议与服务器建立网络连接。这个过程通常经历三次握手,确保客户端和服务器之间的可靠连接。
-
发起HTTP请求:一旦建立了TCP连接,浏览器就会发送一个HTTP请求到服务器。请求中包含了请求行(请求方法,如GET或POST,以及请求的资源路径)、请求头(如Accept、User-Agent等)和请求体(对于POST请求)等信息。
-
服务器处理请求:服务器接收到浏览器发送的HTTP请求后,会根据请求的路径和参数等信息,处理请求并生成相应的响应。
-
接收响应:浏览器接收到服务器发送的HTTP响应后,会解析响应头和响应体。响应头包含了状态码(如200表示成功,404表示资源未找到)和其他元信息,响应体包含了服务器返回的实际内容(如HTML、CSS、JavaScript、图片等)。
-
渲染页面:浏览器开始解析响应体中的HTML文档,并构建DOM(文档对象模型)树。同时,它还会解析CSS文件和JavaScript代码,并进行样式计算、布局和渲染。最终,将解析后的内容显示在用户界面上,呈现出完整的页面。
-
关闭TCP连接(四次挥手):一旦页面呈现完成,浏览器会关闭与服务器之间的TCP连接。如果页面中存在其他资源(如图片、脚本、样式表),则会继续发送相应的HTTP请求来获取这些资源,并重复执行步骤5到步骤7,直至所有资源加载完成。
4.浏览器重绘域重排的区别?
- 重排: 布局改变,重排成本高
- 重绘: 样式改变,布局没变
重绘不一定导致重排,但重排一定绘导致重绘
如何触发重绘和重排?
任何改变 用来构建渲染树的信息 都会导致一次重排或重绘:
- 添加、删除、更新DOM节点
- 通过display: none隐藏一个DOM节点-触发重排和重绘
- 通过visibility: hidden隐藏一个DOM节点-只触发重绘,因为没有几何变化
如何避免重绘或重排?
- 集中改变样式:比如使用class的方式来集中改变样式
- 使用document.createDocumentFragment():我们可以通过createDocumentFragment创建一个游离于DOM树之外的节点,然后在此节点上批量操作,最后插入DOM树中,因此只触发一次重排
- 提升为合成层
使用 CSS 的 will-change 属性将元素提升为合成层。有以下优点:交由 GPU 合成,比 CPU 处理要快 - 使用 CSS3 的 transform 和 opacity 属性来进行动画效果,它们可以利用 GPU 加速,减少重排的发生。
5.CSS加载会阻塞DOM吗?
先上结论:
- CSS不会阻塞DOM的解析,但会阻塞DOM的渲染
- CSS会阻塞JS执行,但不会阻塞JS文件的下载
为什么CSS不会阻塞DOM的解析,但会阻塞DOM的渲染?(DOM和CSSOM通常是并行构建的,所以CSS加载不会阻塞DOM的解析,前一个DOM的解析指的是HTML的解析构建DOM树,后一个DOM的渲染指的是DOM与CSSOM结合的渲染树的渲染)
CSS解析之前,由HTML解析出来的DOM已经开始构建?(并行的,但是,如果dom解析到一半,遇到js改变css样式则需要等待css被加载完毕,这也是为什么css会阻塞JS的执行)
-
DOM 构建: 当浏览器开始接收到HTML内容时,它会开始构建DOM(Document Object Model)。DOM是一个树形结构,表示页面的内容结构。DOM的构建是逐步的,也就是说,当浏览器接收到HTML内容的一部分时,它就开始构建DOM的这一部分。
-
CSSOM 构建: 同时,当浏览器遇到外部CSS文件(通过
<link>标签)或内部样式(通过<style>标签)时,它开始构建另一个树结构,称为CSSOM(CSS Object Model)。CSSOM表示样式规则及其如何应用到DOM上。 -
渲染树 构建: 一旦浏览器有了DOM和CSSOM,它会结合这两者来创建渲染树。渲染树只包含在页面上可见的元素以及这些元素的样式。
-
布局: 当渲染树被创建并完成之后,浏览器开始了布局过程,也被称为"reflow"。这是计算每个可见元素的大小和位置的过程。
-
绘制: 经过布局之后,浏览器会开始绘制页面,将每个元素渲染到屏幕上。
但是,一个重要的点要注意:当浏览器在构建DOM时遇到<script>标签,并且该脚本不是async或defer的,浏览器会暂停DOM的构建,直到脚本执行完毕。如果此时的JavaScript试图访问某些尚未解析的CSS属性,那么浏览器可能需要先完成CSSOM的构建。这就是为什么阻塞的(非异步的)JavaScript和大量的CSS可能会导致页面加载延迟的原因之一。
6.JS会阻塞页面吗?
先上结论
JS会阻塞DOM的解析,也会与渲染线程互斥,因此也就会阻塞页面的加载
这也是为什么要把JS文件放在最下面的原因
由于 JavaScript 是可操纵 DOM 的,如果在修改这些元素属性同时渲染界面(即 JavaScript 线程和 UI 线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置 「GUI 渲染线程与 JavaScript 引擎为互斥」的关系。
当浏览器在执行 JavaScript 程序的时候,GUI 渲染线程会被保存在一个队列中,直到 JS 程序执行完成,才会接着执行。
因此如果 JS 执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞的感觉。
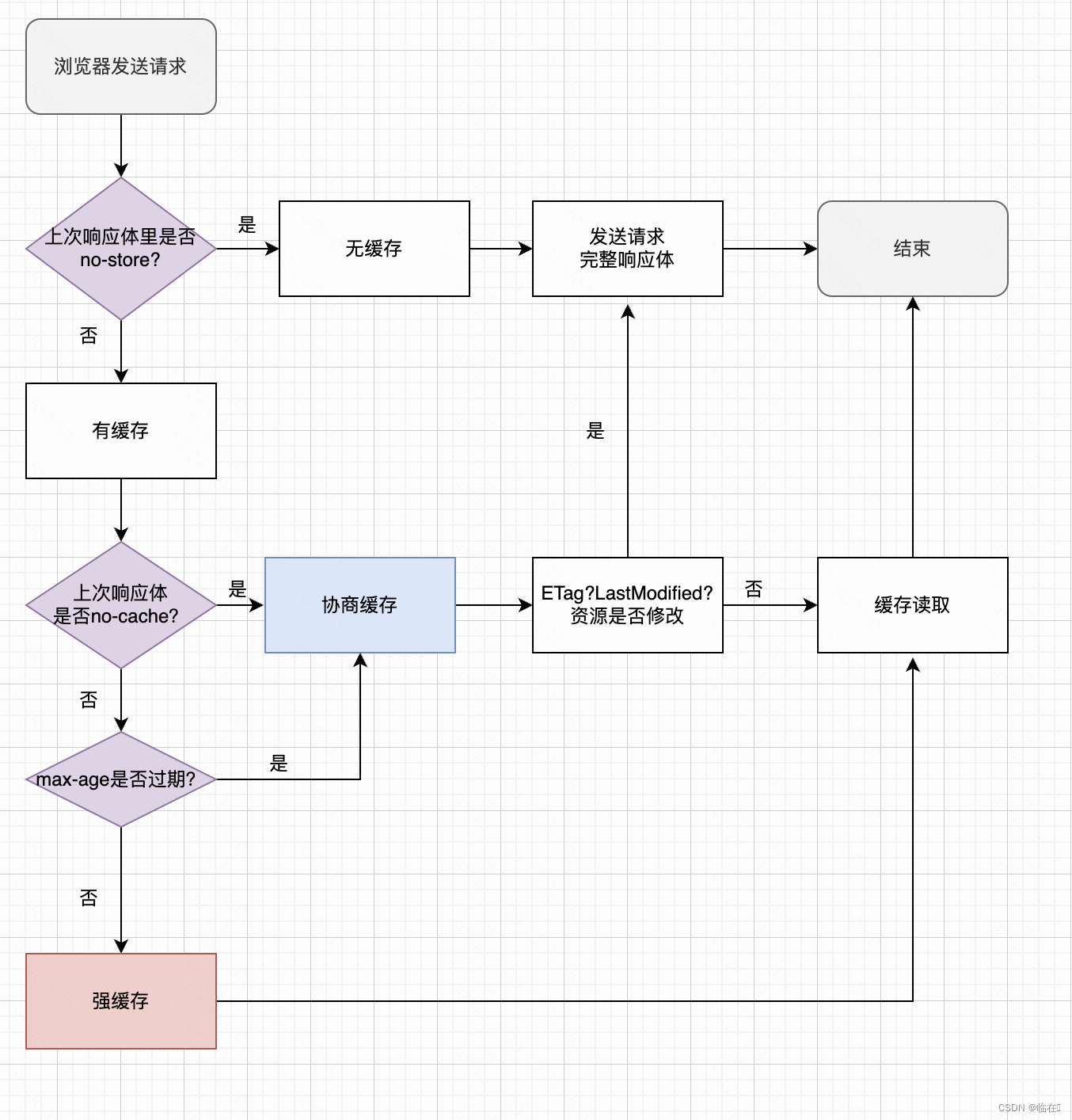
7.说一说浏览器的缓存机制?
认识浏览器缓存:
当浏览器请求一个网站时,会加载各种资源,对于一些不经常变动的资源,浏览器会将他们保存在本地内存中,下次访问时直接加载这些资源,提高访问速度。
浏览器缓存分类:
- 强缓存:不会发请求给服务器,直接从本地缓存读取,返回状态码是200(from cache)。
- 协商缓存:会发请求给服务器,比对资源是否有变化,如果没有变化,返回状态码是304(not modified),然后从本地缓存读取。
什么样的资源使用强缓存,什么样的资源使用协商缓存?
-
使用强缓存的资源:不经常变化的资源(例如 CSS、JavaScript 文件,图片、视频等)
-
使用协商缓存的资源:经常变化的资源(例如来自数据库的内容、新闻、博客帖子等,它们可能经常变化)
如何实现强缓存?
设置Expires与Cache-Control,Expires逐渐被Cache-Control取代。
- Cache-Control:控制缓存字段,后端配置,常见的取值包括:
- public:表示资源可以被任何缓存(包括浏览器和CDN)缓存。
- private:表示资源只能被单个用户的私有缓存缓存,不能被共享缓存(如CDN)缓存。
- no-cache:强制使用协商缓存,即每次请求都要与服务器确认资源是否有更新。
- no-store:不使用缓存,每次重发请求,包括请求响应体。
- max-age=<seconds:用来设置强缓存,表示资源的有效期,即从请求时间开始,缓存会在指定的秒数内有效。
- s-maxage=<seconds:类似于 max-age,但仅适用于共享缓存(如CDN)。
- Expires:这是一个过时的字段,被 Cache-Control 所取代。它指定了一个绝对的过期日期,由于客户端与服务器端的时间不同,可能存在不准确的问题。
如何实现协商缓存?
- Cache-Control中的no-cache
- Last-Modified / If-Modified-Since
- ETag(哈希值) / If-None-Match
后面两种方法通常与Cache-Control指令一起使用。
与缓存相关的配置方法:
请求头(Request Headers):
If-None-Match: 等于上次服务器响应体中的ETag值,询问服务器资源是否被修改。If-Modified-Since: 询问资源是否过期。
响应头(Response Headers):
-
Cache-Control: 指明了资源如何被缓存的指令,例如max-age,no-cache,private,public等。 -
Expires: 设置资源过期的绝对时间。 -
ETag: 服务器为资源生成的一个标识符。 -
Last-Modified: 表示资源最后一次被修改的时间。 -
Vary: 告诉缓存机制哪些请求头部信息应该被考虑进去。
缓存完整流程图:
8.Cookie相关与HttpOnly
- 什么是
HttpOnly?为什么我们需要它?
HttpOnly 是一个用于设置 HTTP Cookie 的属性,它的作用是限制客户端(通常是浏览器)对 Cookie 的访问,只允许通过 HTTP 或 HTTPS 协议进行访问,而禁止通过脚本(如 JavaScript)进行访问。
使用 HttpOnly 属性可以提高 Web 应用程序的安全性:防止跨站脚本攻击(XSS):浏览器将禁止 JavaScript 访问带有该属性的 Cookie
- 除了
HttpOnly,哪些其他标志或属性可以提高Cookie的安全性?
-
Secure属性:只允许通过 HTTPS 连接传输 Cookie。 -
SameSite属性:SameSite属性用于定义 Cookie 发送的规则,以防止跨站点请求伪造(CSRF)攻击。可以将SameSite属性设置为以下值之一:Strict、Lax或None。Strict模式完全禁止跨站点发送 Cookie,Lax模式在导航到目标站点之前仅允许在安全上下文(指顶导)中发送 Cookie,而None模式允许在任何情况下发送 Cookie(需要同时设置Secure属性)。使用适当的SameSite设置可以限制 Cookie 的发送范围,减少 CSRF 攻击的风险。 -
Domain属性:通过设置Domain属性,可以限制 Cookie 的作用域。将Domain属性设置为与当前网站的主域名匹配,可以防止恶意网站访问到另一个网站的 Cookie。这可以提高 Cookie 的隔离性和安全性。 -
Path属性:Path属性用于限制 Cookie 的可见性。将Path属性设置为特定的路径,可以确保 Cookie 只在与该路径匹配的 URL 下发送。这样可以防止其他路径下的恶意脚本访问和窃取 Cookie。 -
定期更新和轮换 Cookie:定期更改敏感 Cookie 的值,增加攻击者窃取 Cookie 的难度。同时,使用有限的有效期限制 Cookie 的生命周期。
-
CSP(内容安全策略):通过 CSP,可以定义网页可以加载的资源源,限制恶意脚本的执行和 Cookie 的访问。
res.cookie('cookieName', 'cookieValue', {
httpOnly: true,
secure: true,
sameSite: 'Strict',
domain: 'example.com',
path: '/'
});
SameSite场景:
那我如果设置SameSite中的Strict,那是不是完全禁止跨站点发送 Cookie。也就是在evil.com里面点 。也不会携带cookie了?
。也不会携带cookie了?
您完全正确。SameSite 属性是一个相对较新的 Cookie 属性,用于增强浏览器中的跨站点请求的安全性。该属性有三个可能的值:Strict、Lax 和 None。
-
当设置为
SameSite=Strict时,该 Cookie 仅在请求来自同一站点时发送。这意味着,即使用户已经在bank.com上登录,如果他们访问了evil.com并从那里尝试通过<img>标签或任何其他方式触发一个跨站点请求,浏览器将不会附带与bank.com相关的任何SameSite=Strict的 Cookie。 -
SameSite=Lax是一个稍微宽松一点的版本,它允许一些安全的跨站点请求(例如GET请求)携带 Cookie,但不允许跨站点的 POST 请求携带 Cookie。这可以避免许多 CSRF 攻击,同时仍然允许某些跨站点的使用场景。 -
SameSite=None意味着 Cookie 可以在任何跨站点请求中发送,但这需要与Secure标志一起使用,这意味着 Cookie 只能通过 HTTPS 发送。
为了增强安全性,许多现代浏览器已经开始更改其对 SameSite 的默认行为,将其默认设置为 Lax。这就是为什么在某些场景中,如果没有明确设置 SameSite 属性,您可能会看到一些关于 Cookie 行为的变化。
综上所述,设置 SameSite=Strict 确实可以大大减少 CSRF 攻击的风险,因为它会完全阻止跨站点发送 Cookie。
如何理解Samesite = Lax?:
- 假设用户已登录
bank.com并获取了一个带有SameSite=Lax属性的cookie。 - 用户访问一个第三方的恶意网站
evil.com。 - 在
evil.com上有一个尝试利用CSRF漏洞发起的XHR请求,目标是bank.com/transferMoney。由于cookie设置为Lax,这个跨站XHR请求不会携带bank.com的cookie,从而防止了潜在的CSRF攻击。 - 但是,如果用户在
evil.com上点击一个指向bank.com的链接,由于这是一个顶层导航请求,bank.com的cookie将会被发送,尽管是从evil.com触发的。
总结:从而确保不破坏用户的正常浏览体验.
SameSite与Secure的不同:
SameSite属性用来控制 Cookie 是否能够在跨站请求中被发送。Secure属性确保 Cookie 只能通过 HTTPS 协议发送。
如何理解Domain属性?:
Domain属性在Cookie中定义了哪些域名可以访问该Cookie。它有助于定义Cookie的范围。
默认情况下,Cookie只能被创建它的页面所访问。但是,如果你设置了Domain属性,这个Cookie就可以被此域下的其他子域所访问。
假设你有一个主域example.com,以及两个子域sub1.example.com和sub2.example.com。
-
如果你在
sub1.example.com上设置了一个Cookie,并未指定Domain属性,那么默认情况下,只有sub1.example.com可以访问该Cookie,sub2.example.com和example.com都无法访问。 -
但如果你在
sub1.example.com设置了一个Cookie,并且指定了Domain属性为.example.com(注意域名前面的点,表示这是一个通配符匹配),那么example.com、sub1.example.com、sub2.example.com都可以访问该Cookie。
需要注意的是,为了安全性,你不能设置一个与当前域完全不相关的Domain属性。也就是说,sub1.example.com不能设置一个Domain为.anotherexample.com的Cookie。
另外,使用Domain属性时应特别小心,因为它可能会导致隐私和安全问题。确保你完全理解了这个属性的工作方式并合理使用。
- 如何在JavaScript中设置和读取Cookies?如果一个Cookie被设置为
HttpOnly,这会发生什么?
如何在JavaScript中设置和读取Cookies?
在JavaScript中,可以使用document.cookie属性来读取和设置cookies。
- 设置cookie:
document.cookie = "username=JohnDoe; expires=Thu, 18 Dec 2023 12:00:00 UTC; path=/";
这里,我们设置了一个名为 “username” 的cookie,其值为 “JohnDoe”,该cookie将在2023年12月18日12:00:00 UTC到期,并且它可在整个网站上使用(由于path=/)。
- 读取cookie:
var allCookies = document.cookie;
这会返回一个字符串,其中包含所有为当前页面设置的cookies。你可能需要解析此字符串以获得特定的cookie值。
如果一个Cookie被设置为HttpOnly,这会发生什么?
当一个cookie被设置为HttpOnly时,它将不能被JavaScript脚本访问。这意味着,尽管该cookie仍然存在于客户端,且仍可以通过HTTP或HTTPS请求发送给服务器,但你无法使用例如document.cookie的方法在浏览器端JavaScript代码中读取或修改它。
这个属性的主要目的是增加安全性,防止潜在的跨站脚本攻击(XSS)。在这样的攻击中,攻击者可能会尝试使用恶意脚本来读取用户的cookies,包括可能包含敏感信息或会话标识符的cookies。通过将cookie设置为HttpOnly,我们可以有效地减少这种风险,因为即使恶意脚本运行在用户的浏览器上,它也无法访问这些标记为HttpOnly的cookies。
-
解释第三方Cookies与第一方Cookies的区别。
-
为什么长时间的session cookies可能不是一个好主意?
-
什么是Cookie的域(Domain)和路径(Path)?它们如何影响Cookie的作用域?
-
在服务端,如何设置
HttpOnlyCookie? -
为什么我们应该避免在Cookies中存储敏感信息,即使它们被设置为
HttpOnly? -
描述Cookie的生命周期。怎样设置一个会话Cookie,以及一个持久性Cookie?
-
在Web应用程序中,Cookies与Session有什么区别和联系?
-
如何确保Cookies在不同的环境和浏览器中一致性地工作?
-
什么是Cookie的大小限制?如果你需要存储的信息超过了这个限制,你会如何处理?
9.说说跨站请求伪造(CSRF)攻击
CSRF 攻击简化流程:
-
目标:攻击者希望攻击某个受害者在网站
bank.com上的账户,该受害者在bank.com有登录状态。 -
建立陷阱:攻击者在一个他控制的网站
evil.com上放置了一个恶意脚本或者构造了一个看起来正常的链接。这个链接或脚本其实是向bank.com发送一个请求。例如:
<img src="https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fbank.com%2Ftransfer%3Fto%3Dattacker%26amount%3D1000&pos_id=img-kXng9Qhn-1694418053406)" width="0" height="0">当受害者访问
evil.com时,上述链接会尝试向bank.com发起一个转账请求。 -
利用用户登录状态:如果受害者在
bank.com处于登录状态,并且其浏览器还有bank.com的 Cookie,这个请求就会带上这个 Cookie,因为浏览器会自动附带相应站点的 Cookie。从bank.com的角度看,这个请求看起来是一个合法的用户请求。 -
完成攻击:如果
bank.com没有进行 CSRF 保护,它会执行这个恶意请求,将受害者的钱转到攻击者的账户。
如何防范 CSRF 攻击:
-
使用 CSRF 令牌:为每个会话和请求生成一个随机的、不可预测的令牌。只有在收到正确的令牌时,服务器才会处理请求。
-
检查 Referer 标头:如果请求的来源不是预期的域(例如从
evil.com来的请求),那么可以拒绝该请求。 -
强制重新认证:对于敏感的操作(如转账),要求用户再次输入密码或进行其他形式的二次认证。
我的问题:
cookie默认情况就是不跨域的,为什么受害者访问 evil.com 时点击了链接能发送bank.com 的 Cookie?
当我们提到 CSRF 攻击,其关键在于它是如何利用浏览器的自动行为进行的。
在 CSRF 攻击中,攻击者不会尝试直接读取 bank.com 的 Cookie,也不会尝试从 evil.com 创建或设置一个新的 Cookie 为 bank.com。而是利用的是浏览器在用户请求特定站点时,自动将与该站点相关联的 Cookie 附加到请求上的特性。
详细解释一下:
- 用户先前登录了
bank.com并获得了一个与其会话关联的 Cookie。 - 用户在另一个标签或窗口中访问了
evil.com。 evil.com包含一个使浏览器发起请求到bank.com的恶意代码,如之前提到的<img src="https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fbank.com%2Ftransfer%3Fto%3Dattacker%26amount%3D1000&pos_id=img-kXng9Qhn-1694418053406)" width="0" height="0">。- 当浏览器尝试加载上述
<img>标签指向的 URL 时,它会自动地,按照设计,将与bank.com相关的 Cookie 附加到这个请求上。这就是浏览器的正常行为。 - 这意味着,即使请求是从
evil.com页面发起的,由于它是针对bank.com的,浏览器仍然会附加与bank.com相关的 Cookie。
这就是 CSRF 攻击的核心:它不是试图窃取或直接利用 Cookie,而是利用浏览器的这种自动行为来执行未经授权的操作。
10.浏览器的存储
浏览器提供了多种客户端存储机制,每种机制都有其特定的用途、特性和限制。以下是对 cookie、localStorage、sessionStorage 和 IndexedDB 的对比:
1. Cookie
- 存储大小: 通常限制为4KB。
- 生命周期: 可以设置过期时间。如果没有设置,它的生命周期将与会话持续相同,即关闭浏览器后会被删除。
- 与服务器交互: 每次HTTP请求都会附带,这可能会浪费带宽。
- 访问性: JavaScript可以访问,但需要考虑安全性(例如:设置
HttpOnly标志以防止通过JS访问)。 - 使用场景: 适合小量数据的存储,经常用于身份验证(如存储JWT或会话ID)。
2. LocalStorage
- 存储大小: 通常限制为5-10MB。
- 生命周期: 没有过期时间,除非明确删除,否则数据会永久存储。
- 与服务器交互: 数据只在客户端存储,不会随每次请求发送给服务器。
- 访问性: 可以通过JavaScript访问。
- 使用场景: 适合大量持久化的数据,如用户偏好设置、主题等。
3. SessionStorage
- 存储大小: 通常限制为5-10MB。
- 生命周期: 数据在页面会话期间可用,关闭页面或浏览器后会被清除。
- 与服务器交互: 数据只在客户端存储,不会随每次请求发送给服务器。
- 访问性: 可以通过JavaScript访问。
- 使用场景: 适合需要在浏览器会话中临时存储的数据。
4. IndexedDB
- 存储大小: 无明确的限制,但可能受到磁盘空间的影响。通常可以存储大量数据。
- 生命周期: 没有过期时间,除非明确删除,否则数据会永久存储。
- 与服务器交互: 数据只在客户端存储,不会随每次请求发送给服务器。
- 访问性: 可以通过JavaScript访问。
- 结构: 它是一个事务性的数据库系统,可以存储键值对,支持索引,事务和游标。
- 使用场景: 适合大量数据的存储,如离线应用数据、大数据集等。
总结
- 大小:
cookie<localStorage/sessionStorage<<IndexedDB - 生命周期:
sessionStorage<cookie(如果设置了过期时间) =localStorage=IndexedDB - 与服务器交互: 只有
cookie会随HTTP请求自动发送。 - 结构: 只有
IndexedDB提供了数据库的功能和结构。 - 用途: 根据存储需求和数据的大小、持续性来选择合适的存储机制。
11.HTTP与HTTPS、第三方证书工作原理、以及HTTP各个版本
HTTP各个版本
HTTP(Hypertext Transfer Protocol)和HTTPS(HTTP Secure)是用于在客户端和服务器之间传输数据的协议,它们在以下几个方面有所区别:
- 安全性:
- HTTP是明文协议,数据在传输过程中不加密,容易被窃取和篡改。而HTTPS通过使用SSL/TLS协议对数据进行加密,确保传输的数据是安全的,可以有效防止中间人攻击和数据泄露。
- HTTPS使用数字证书对数据进行数字签名,确保传输的数据在传输过程中没有被篡改或修改。客户端可以验证证书的合法性,确保与服务器建立的连接是可信的。
- 默认端口:HTTP使用80端口进行通信,而HTTPS使用443端口进行通信。
对于第三方证书如何保证服务器的可信性,这涉及到公开密钥基础设施(PKI)的工作原理。具体步骤如下:
-
服务器生成密钥对:服务器首先生成一个密钥对,包括公钥和私钥。
-
证书请求:服务器将公钥发送给受信任的第三方机构(证书颁发机构,CA),请求颁发证书。
-
验证身份:证书颁发机构验证服务器的身份。
-
颁发证书:一旦服务器的身份验证通过,证书颁发机构会生成证书并将其签名。证书中包含了服务器的公钥以及其他相关信息。
-
客户端验证:当客户端与服务器建立HTTPS连接时,服务器会将证书发送给客户端。客户端会验证证书的合法性,包括检查证书的签名、过期时间、颁发机构等。
-
可信根证书:客户端会使用自己内置的受信任的根证书(Root CA)来验证服务器证书的合法性。如果证书链可以追溯到受信任的根证书,且没有被撤销或过期,客户端会信任服务器的证书。
react原理fiber调度算法
数据驱动视图改变的一种框架,它的核心驱动方法就是用其提供的 setState 方法设置 state 中的数据从而驱动存放在内存中的虚拟 DOM 树的更新
更新方法就是通过 React 的 Diff 算法比较旧虚拟 DOM 树和新虚拟 DOM 树之间的 Change ,然后批处理这些改变。
React中的diff算法
在 React 中,虚拟 DOM 的 diff(差异)算法是用于比较前后两个虚拟 DOM 树的差异,并尽可能高效地更新实际 DOM 的过程。这样可以避免对整个 DOM 树进行重新渲染,而只更新需要变化的部分,提高渲染性能。
React 的 diff 算法主要包括以下几个步骤:
-
树的遍历:React 会逐层遍历前后两个虚拟 DOM 树,并比较对应节点的类型和属性。
-
节点比较:对比相同位置的节点,React 会比较节点类型、节点的属性以及子节点等信息。如果节点类型不同,React 会直接删除旧节点并创建新节点。如果节点类型相同,React 会比较节点的属性差异,并更新需要变更的属性。
-
子节点比较:如果节点的子节点有变化,React 会进行进一步的比较。React 使用一种称为 “key” 的机制来识别列表中的每个子节点,并根据 key 值来进行优化的比较。它会尽量复用相同 key 的节点,减少不必要的 DOM 操作。
-
递归处理:在比较子节点时,React 会递归地调用 diff 算法,继续比较子节点的差异。这样可以处理更深层次的嵌套结构,并找到需要更新的具体节点。
-
批量更新:在进行差异比较时,React 会将变更记录在内存中,而不是立即更新实际 DOM。在比较完成后,React 会批量处理所有变更,进行最小化的 DOM 操作,以提高性能。
通过使用 diff 算法,React 可以高效地比较前后两个虚拟 DOM 树的差异,并只更新需要变化的部分。这样可以减少不必要的 DOM 操作,提高渲染性能,并保持用户界面的一致性。然而,值得注意的是,diff 算法并不是完全无代价的,因此在某些情况下,手动优化和使用 key 来管理列表的性能也是重要的。
在 React 中,“key” 是用来标识列表中每个子节点的特殊属性。它在 diff 算法中发挥作用,用于识别节点的变更和复用。
当 React 进行列表的 diff 比较时,它会遍历旧的虚拟 DOM 树和新的虚拟 DOM 树中的子节点,并尝试匹配它们。匹配的过程是通过比较相同位置的节点的 “key” 属性来进行的。
如果两个节点的 “key” 值相同,React 会认为它们是相同的节点,并尽可能复用该节点以减少 DOM 操作。这意味着 React 不会删除旧节点,而是尽可能地更新旧节点的属性,从而避免了重新创建和插入新节点的开销。
如果两个节点的 “key” 值不同,React 会将其视为不同的节点,直接删除旧节点并创建新节点。这样可以确保节点的正确更新和渲染。
在进行节点比较时,React 进行的是浅比较,比较节点的属性和子节点的引用。它会比较两个节点的类型、属性以及子节点的数量和顺序。如果节点类型或属性不同,React 会直接删除旧节点并创建新节点。如果节点类型和属性相同,React 会继续递归比较子节点。
需要注意的是,“key” 属性应该在列表中具有唯一性,这样才能确保正确的节点复用和更新。如果列表中的 “key” 不唯一,可能会导致不正确的节点复用,出现意料之外的结果。
总结起来,“key” 属性在 React 的 diff 算法中发挥作用,用于识别列表中子节点的变更和复用。它帮助 React 在进行节点比较时,准确地判断哪些节点需要更新、复用或删除,并提高渲染性能。节点的比较是浅比较,比较节点的属性和子节点的引用。
进程和线程
七层模型、五层模型
deffer\async 加载js
Http、Https
深度优先遍历和广度优先遍历
diff算法
安全性相关
react原理fiber调度算法






![B站:AB test [下]](https://img-blog.csdnimg.cn/02ee3d668d0c44ec94f232b11d405470.png)