相关系数矩阵
相关系数矩阵是用于衡量多个变量之间关系强度和方向的统计工具。它是一个对称矩阵,其中每个元素表示对应变量之间的相关系数。
要计算相关系数矩阵,首先需要计算每对变量之间的相关系数。常用的相关系数包括皮尔逊相关系数和斯皮尔曼相关系数。皮尔逊相关系数适用于连续变量,而斯皮尔曼相关系数适用于排序数据或者非线性关系。
通过计算每对变量之间的相关系数,可以构建一个矩阵,其中每个元素代表对应变量之间的相关程度。这个矩阵就是相关系数矩阵。
相关系数矩阵可以帮助我们了解变量之间的关系,例如是否存在线性关系、正相关还是负相关等。在数据分析、机器学习和统计建模等领域中,相关系数矩阵常常用于特征选择、多重共线性检测和变量关系分析等任务。
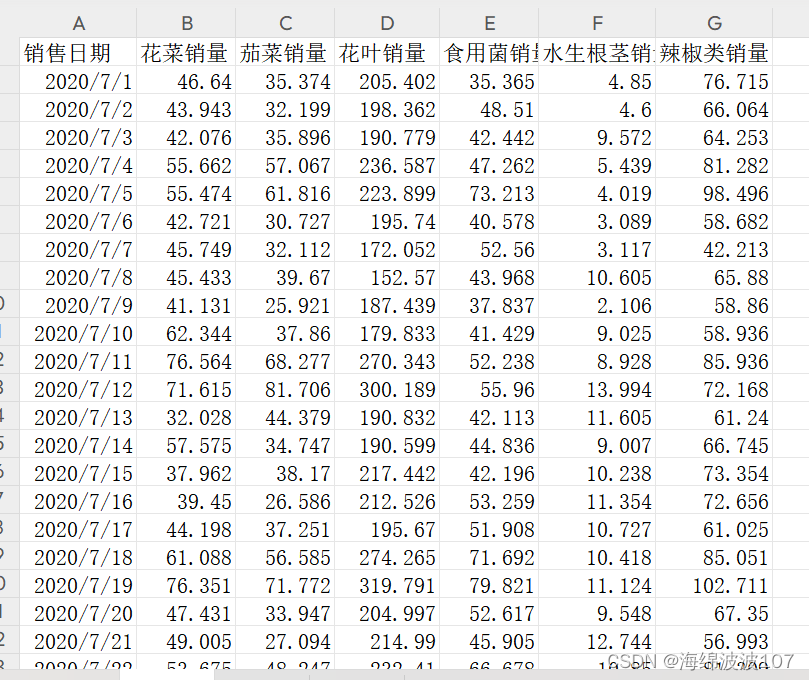
数据
使用的数据为某超市时间序列的不同类型蔬菜的销量,现要分析蔬菜类别之间两两有没有关联。
源代码
#!usr/bin/env python
# encoding:utf-8
'''
from __future__ import print_function
import pandas as pd
doc = open('out.txt', 'w')#将结果输出到文件out.txt中,注意运行文件与输出结果文件必须在同一个存储目录下。
sale = 'D:/Learn_数学建模/08_23年大学生数学建模/过程数据/p1/p1各品类历史销量汇总.xlsx'
data = pd.read_excel(sale)
pre_data=data.iloc[:,1:7]
xg = pre_data.corr() #相关系数矩阵,显示任意两款菜式之间的相关系数
#将结果完整显示
pd.set_option('display.max_columns',1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth',1000)
print(xg)
print(xg, file=doc)
doc.close()
代码注释
1、xg = pre_data.corr() 。这段代码的作用是计算pre_data中各个变量之间的相关系数,并将结果保存在变量xg中。相关系数常用于衡量变量之间的线性相关性,取值范围为-1到1,越接近1表示正相关,越接近-1表示负相关,接近0表示无相关关系。
2、print(xg, file=doc)。使用了print函数将变量xg的值输出到名为doc的文件中。
结果
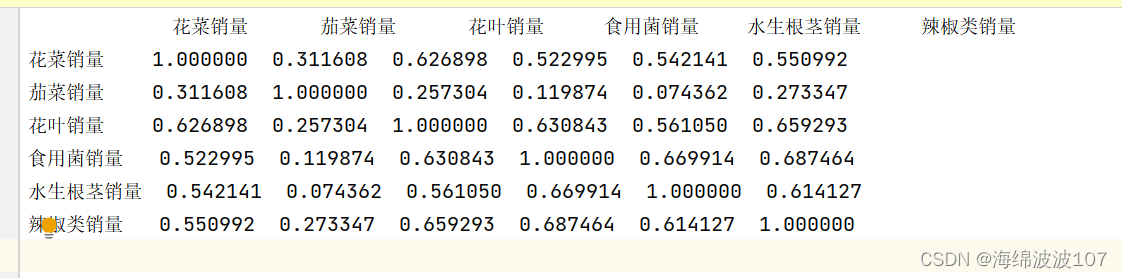
下一步就是将该结果用热力图可视化。见博文