需要源码和依赖请点赞关注收藏后评论区留言私信~~~
一、Dataframe操作
步骤如下
1)利用IntelliJ IDEA新建一个maven工程,界面如下
2)修改pom.XML添加相关依赖包
3)在工程名处点右键,选择Open Module Settings
4)配置Scala Sdk,界面如下
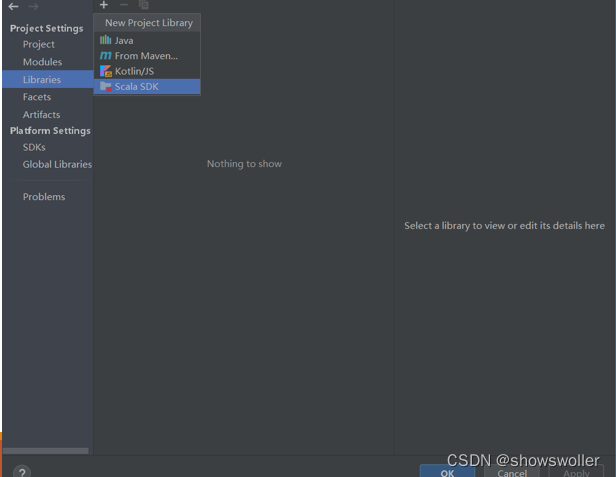
5)新建文件夹scala,界面如下:
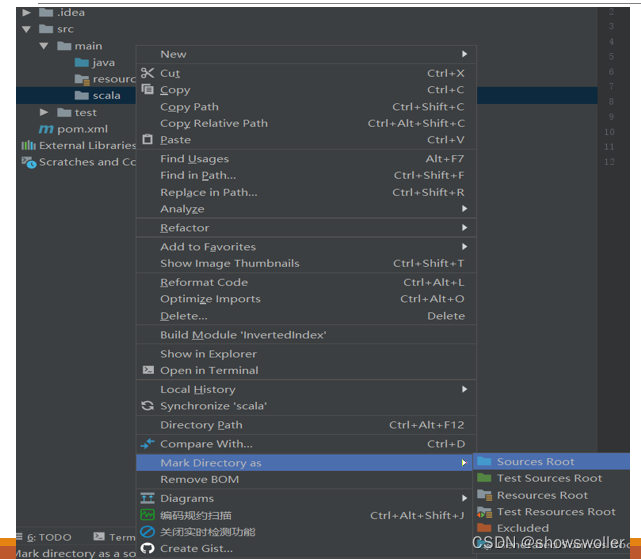
6) 将文件夹scala设置成Source Root,界面如下:
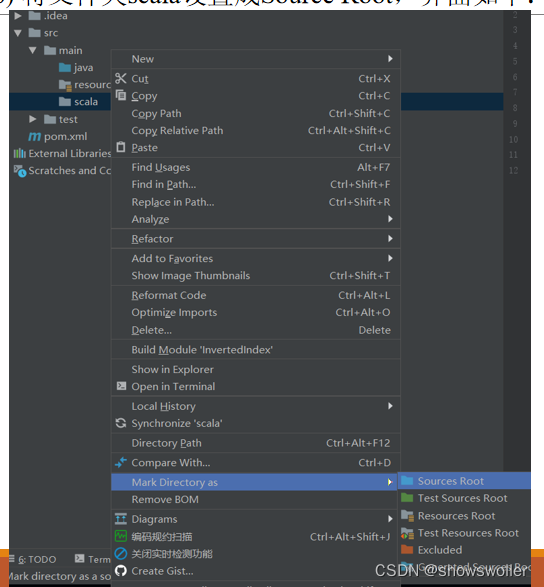
7) 新建scala类,界面如下:
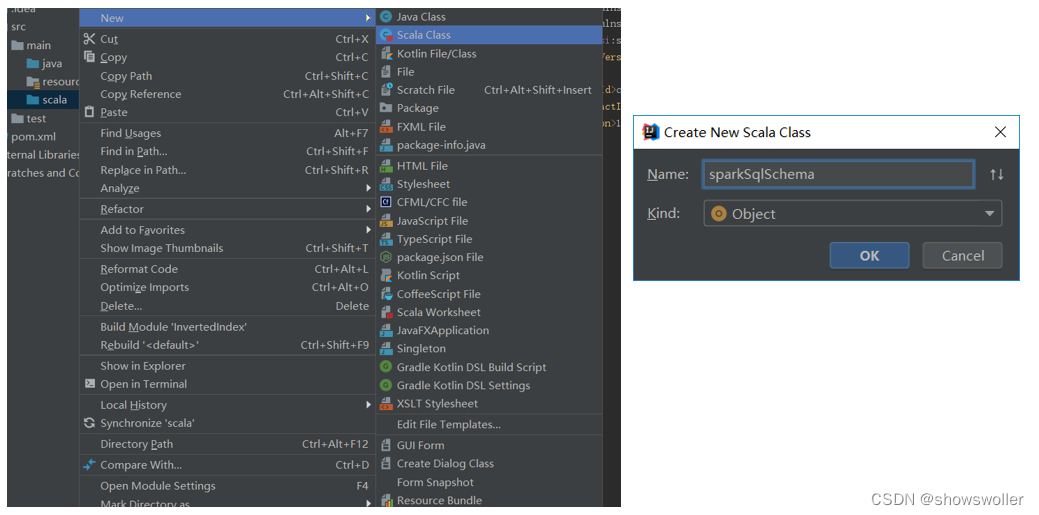
此类主要功能是读取D盘下的people.txt文件,使用编程方式操作DataFrame,相关代码如下
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
case class Person(name:String,age:Long)
object sparkSqlSchema {
def main(args: Array[String]): Unit = {
//创建Spark运行环境
val spark = SparkSession.builder().appName("sparkSqlSchema").master("local").getOrCreate()
val sc = spark.sparkContext;
//读取文件
val data: RDD[Array[String]] = sc.textFile("D:/people.txt"). map (x => x.split(","));
//将RDD与样例类关联
val personRdd: RDD[Person] = data. map (x => Person(x(0),x(1).toLong))
//手动导入隐式转换
import spark.implicits._
val personDF: DataFrame = personRdd.toDF
//显示DataFrame的数据
personDF.show()
//显示DataFrame的schema信息
personDF.printSchema()
//显示DataFrame记录数
println(personDF.count())
//显示DataFrame的所有字段
personDF.columns.foreach(println)
//取出DataFrame的第一行记录
println(personDF.head())
//显示DataFrame中name字段的所有值
personDF.select("name").show()
//过滤出DataFrame中年龄大于20的记录
personDF.filter($"age" > 20).show()
//统计DataFrame中年龄大于20的人数
println(personDF.filter($"age" > 20).count())
//统计DataFrame中按照年龄进行分组,求每个组的人数
personDF.groupBy("age").count().show()
//将DataFrame注册成临时表
personDF.createOrReplaceTempView("t_person")
//传入sql语句,进行操作
spark.sql("select * from t_person").show()
spark.sql("select * from t_person where name='王五'").show()
spark.sql("select * from t_person order by age desc").show()
//DataFrame转换成Dataset
var ds=personDF.as[Person]
ds.show()
//关闭操作
sc.stop()
spark.stop()
}
}
二、Spark SQL读写MySQL数据库
下面的代码使用JDBC连接MySQL数据库,并进行读写操作 主要步骤如下
1:新建数据库
2:新建表
3:添加依赖包
4:新建类
5:查看运行结果
代码如下
import java.util.Properties
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SaveMode,SparkSession}
object sparkSqlMysql {
def main(args: Array[String]): Unit = {
//创建sparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("sparkSqlMysql")
.master("local")
.getOrCreate()
val sc = spark.sparkContext
//读取数据
val data: RDD[Array[String]] = sc.textFile("D:/people.txt").map(x => x.split(","));
//RDD关联Person
val personRdd: RDD[Person] = data.map(x => Person(x(0), x(1).toLong))
//导入隐式转换
import spark.implicits._
//将RDD转换成DataFrame
val personDF: DataFrame = personRdd.toDF()
personDF.show()
//创建Properties对象,配置连接mysql的用户名和密码
val prop =new Properties()
prop.setProperty("user","root")
prop.setProperty("password","123456")
//将personDF写入MySQL
personDF.write.mode(SaveMode.Append).jdbc("jdbc:mysql://127.0.0.1:3306/spark?useUnicode=true&characterEncoding=utf8","person",prop)
//从数据库里读取数据
val mysqlDF: DataFrame = spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/spark", "person", prop)
mysqlDF.show()
spark.stop()
}
}
三、Spark SQL读写Hive
下面的示例程序连接Hive,并读写Hive下的表 主要步骤如下
1:在pom.xml中添加Hive依赖包
2:连接Hive
3:新建表
4:向Hive表写入数据,新scala类sparksqlToHIVE,主要功能是读取D盘下的people.txt文件,使用编程方式操作DataFrame,然后插入到HIVE的表中。
5:查看运行结果
代码如下
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame,SparkSession}
object sparksqlToHIVE {
def main(args: Array[String]): Unit = {
//设置访问用户名,主要用于访问HDFS下的Hive warehouse目录
System.setProperty("HADOOP_USER_NAME", "root")
//创建sparkSession
val spark: SparkSession = SparkSession.builder()
.appName("sparksqlToHIVE")
.config("executor-cores",1)
.master("local")
.enableHiveSupport() //开启支持Hive
.getOrCreate()
val sc = spark.sparkContext
//读取文件
val data: RDD[Array[String]] = sc.textFile("D:/people.txt"). map (x => x.split(","));
//将RDD与样例类关联
val personRdd: RDD[Person] = data. map (x => Person(x(0),x(1).toLong))
//手动导入隐式转换
import spark.implicits._
val personDF: DataFrame = personRdd.toDF
//显示DataFrame的数据
personDF.show()
//将DataFrame注册成临时表t_person
personDF.createOrReplaceTempView("t_person")
//显示临时表t_person的数据
spark.sql("select * from t_person").show()
//使用Hive中bigdata的数据库
spark.sql("use bigdata")
//将临时表t_person的数据插入使用Hive中bigdata数据库下的person表中
spark.sql("insert into person select * from t_person")
//显示用Hive中bigdata数据库下的person表数据
spark.sql("select * from person").show()
spark.stop()
}
}
创作不易 觉得有帮助请点赞关注收藏~~~