深度学习模型复杂度分析大杂烩
时间复杂度和空间复杂度是衡量一个算法的两个重要指标,用于表示算法的最差状态所需的时间增长量和所需辅助空间.
在深度学习神经网络模型中我们也通过:
计算量/FLOPS(时间复杂度)即模型的运算次数
访存量/Bytes(空间复杂度)即模型的参数数量
这两个指标来评判深度学习模型的性能

复杂度对模型的影响:
时间复杂度决定了模型的训练/预测时间。如果复杂度过高,会导致模型训练和预测耗费大量时间,既无法快速的验证想法和改善模型,也无法做到快速的预测。
空间复杂度决定了模型的参数数量。由于维度灾难的限制,模型的参数越多,训练模型所需的数据量就越大,而现实生活中的数据集通常不会太大,这会导致模型的训练更容易过拟合。
经典模型复杂度分析
基本模型框架
模型框架的选择影响模型的复杂性。影响因素包括模型类型(如CNN、GAN)、激活函数(如Sigmoid、ReLU)等。不同的模型框架可能需要不同的复杂性度量和方法,这些度量和方法可能彼此之间无法直接比较。
模型大小
深度模型的大小会影响模型的复杂性。用于测量模型大小的一些常见方法包括参数的数量、隐藏层的数量、隐蔽层的宽度、过滤器的数量和过滤器的大小。在相同的模型框架下,模型的复杂度可以通过相同的复杂度度量对不同大小的模型进行量化,以成为可比较的标准。
优化过程
优化过程影响模型的复杂度,包括目标函数的形式、学习算法的选择和超参数的设置。
数据复杂度
网络模型的主要任务是拟合真实世界中的数据分布问题。而真实世界中的数据规模一般比较大,所以我们一般需要比较复杂的模型才能比较好地拟合。训练模型的数据也会影响模型的复杂性。主要影响因素包括数据维度、数据类型和数据类型分布、由Kolmogorov复杂性度量的信息量等。
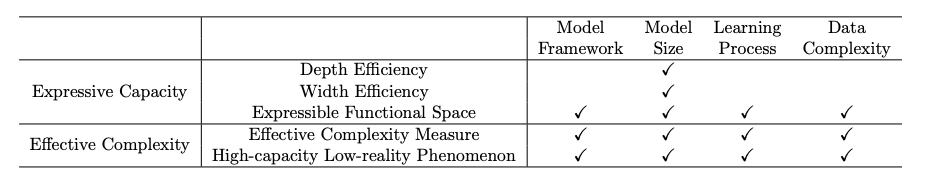
通常来说,复杂度的研究模型选取有如下两种:
一是指定模型(model-specific)的方法关注于特定类型的模型,并基于结构特征探索复杂性。例如,Bianchini等人和Hanin等人研究了FCNNs的模型复杂性,Bengio和Delalleau关注和积网络的模型复杂性。此外,一些研究进一步提出了激活的限制条件约束非线性特性的函数。
还有一种方法是跨模型(cross-model),当它涵盖多种类型的模型时,而不是多个特定类型的模型,因此可以应用于比较两个或多个更多不同类型的模型。例如,Khrulkov等人比较了建筑物连接对一般RNN、CNN和浅层FCNN复杂性的影响在这些网络结构和张量分解中。
「表达能力」与「有效模型复杂度」
模型的表达能力
模型的表达能力意味着这个模型在不同数据上的表达能力,即性能,综述主要分析方法是从下面四个角度分析。
深度效率(depth efficiency)分析深度学习模型如何从架构的深度获得更好地性能(例如,精确度)。
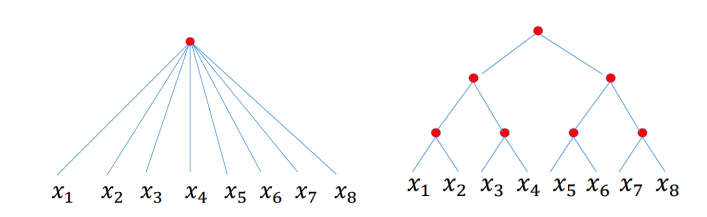
宽度效率(width efficiency)分析深度学习中各层的宽度对模型影响程度。
可表达功能空间(expressible functional space)研究可表达的功能由具有特定框架和指定大小的深模型表示,在不同参数的情况下。
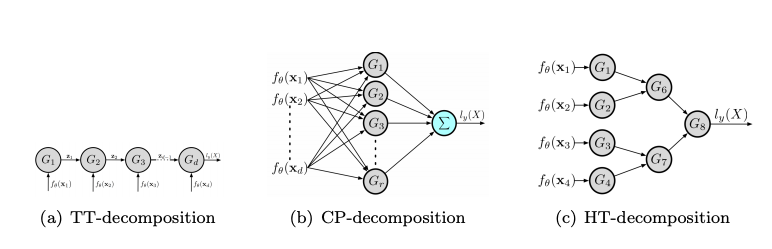
最后,VC维度和Rademacher复杂性是机器学习中表达能力的两个经典度量。
模型的有效复杂度
深度学习模型的有效复杂性也称为实际复杂性、实际表达能力和可用容量。
它反映了复杂性具有特定参数化的深部模型所代表的函数。深度学习模型的有效复杂性主要从以下两个方面进行了探讨。
有效复杂性的一般度量(general measures of effective complexity)设计深度学习模型有效复杂性的量化度量。
对高容量低现实现象的调查发现深度学习模型的有效复杂性可能远低于他们的表达能力。一些研究探讨了深度学习模型的有效复杂性和表达能力之间的差距。
模型复杂度的应用
这篇论文主要介绍了三个应用,理解模型泛化能力、模型优化、模型选择和设计。
理解模型泛化能力
深度学习模型总是过于参数化,也就是说,它们的参数要多得多,模型参数比最优解和训练样本数多。然而,人们经常发现大型的过参数化神经网络具有良好的泛化能力。一些研究甚至发现更大、更复杂的网络通常更具通用性。这一观察结果与函数复杂性的经典概念相矛盾,例如著名的奥卡姆剃须刀原则,更喜欢简单的定理。
什么导致过度参数化深度学习模型的良好泛化能力?
1、在训练误差为零的情况下,一个网络训练在真实的标签上,导致良好的泛化能力,其复杂度比在随机标签上训练的网络要低得多。
2、增加隐藏单元的数量或参数的数量,从而减少了泛化误差,有望降低复杂度。
3、使用两种不同的优化算法,如果都导致零训练误差,具有较好泛化能力的模型具有较低的复杂度。
优化策略
模型优化关注的是神经网络模型如何建立以及为什么建立,为什么可以成功训练。具体来说,优化一个深度学习模型一般是确定模型参数,使损失函数最小化非凸的。损失函数的设计通常基于一个问题和模型的要求,因此一般包括在训练集上评估的性能度量和其他约束条件。
模型复杂度被广泛用于提供一个度量来进行优化可追踪。例如,有效模型复杂性的度量指标神经网络有助于监测优化过程中模型的变化处理并理解优化过程是如何进行的。这样的度量也有助于验证优化算法新改进的有效性。
Nakkiran等人研究了训练过程中的双下降现象利用有效复杂度度量数据集的最大大小,在该数据集上可以得到零训练误差实现。结果表明,双下降现象是可以表示的作为有效复杂性的函数。Raghu等人和Hu等人提出了新的正则化方法,并证明了这些方法对减小复杂度是有效的。
模型选择和设计
给定一个具体的学习任务,研究人员如何为这个任务确定一个可行的模型结构。给出了各种不同体系结构和不同性能的模型复杂性,研究人员如何从中挑选出最好的模型?这就是模型选择和设计问题。
一般来说,模型的选择和设计是基于两者之间的权衡,预测性能和模型复杂性。

一方面,高精度的预测是学习模型的基本目标。模型应该能够捕获隐藏在模型中的底层模式训练数据和实现预测的精度尽可能高。为了表示大量的知识并获得较高的准确度,一个模型具有较高的表达能力,自由度大,体积大,需要更大训练集。在这个程度上,一个具有更多参数和更高的复杂性是有利的。
另一方面,过于复杂的模型可能很难进行训练,可能会导致不必要的资源消耗,例如存储、计算和时间成本。不必要的资源消耗特别是在实际的大规模应用中,应避免使用。为了这个目标,一个更简单的模型比一个更精确的模型更可取。
大模型分析
大模型火出圈已经好久,然而为什么能拿出手的大模型还就是那几个。无论国内还是国外真正的拿的出手的大模型,能打的大模型都不会超过一只手。国内更是如此基本都是基于LLama或者GLM开源的参数在调,百度基本是闭源的算是一个独立自主从零开始训练模型。
理论上讲大模型需要训练的数据是知道的、模型架构也是知道的、最后的效果也是知道,甚至还有论文介绍一些思苦。对于输入输出、架构约束都是知道的这么一个系统,逆向出来应该就是一个半开卷的题目了。但为什么却一直后无来者,这个事情到底难在哪,复杂度在哪,有哪些因素带来了复现复杂度呢?
首先我们可以来分析下复杂度的来源(与工艺流程实际差不多):
1.原料:配比、不同步骤配比
2.流程:需要多少步工艺、每步需要哪些工序组合
3.每阶段如何测评
4.工序之间重复多少次
大模型训练用的就是系统性工程的打法,但是我们大部分人的思考思路还在用单一模块的思路,思维的惯性导致把问题考虑的简单了。国内大部分参与大模型训练的同学还是用单一模块训练的思路在做实验实践,而没有认真的思考考虑如何更上一个层次系统工程的构建这件事情,如何做好实验设计和规划来持续的推进这件事情。个人的建议是这块实验设计应该有宏观的长期的规划和设计,我觉得甚至可以参考系统工程管理做的非常出色的航空航天行业学习(需不需要做的这么重,可以结合实际情况考虑,但是这种系统工程管理设计思路是值得引入的)。
大模型的基础能力
衡量大模型的基础能力最重要的3个要素是:算法、算力、数据。
1.参数尺度:可能有更多的维度来衡量算法的强度,可以简单地用参数尺度来衡量,参数尺度是衡量模型复杂性和能力的量化指标。参数规模越大,模型所能支持的复杂问题就越多,所能考虑的维度就越多,简而言之,它就越强大;
2.数据量:该模型是在数据的基础上运行的。模型背后的数据量值越大,模型的性能可能越好;
3.数据质量:数据质量包括数据本身的价值和业务对数据的清理;数据本身在质量上是分层的。例如,用户消费的数据比用户的一般社交属性信息具有更高的价值。数据的值越高,模型的性能就越好;二是业务对数据的清理,体现在数据标注的精细度上;
4.训练次数:模型训练次数越多,模型的经验越多,性能越好;
5.算力:算力的衡量主要是芯片数量、服务器数量和网络能力。计算能力代表了模型的计算量,计算能力是模型发展速度的重要制约因素之一。

显存优化复杂
显存消耗估计
模型训练时消耗的显存,往往是参数量的几倍还多。不说特别大的,仅以100B模型为例,我们大致估算一下 不做任何显存优化 时,使用AdamOptimizer训练的固定消耗:
| Section | 参数量 | 存储消耗 |
|---|---|---|
| 模型参数本身 | 100B | 400GB |
| Adam辅助变量(两份) | 200B | 800GB |
| 总计 | 300B | 1200GB |
即使没有列出Activations的消耗,上面的部分应该也比较吓人了。这得堆多少GPU卡,多少台机器?
- 16GB显卡:75张GPU卡,约等于单机八卡服务器10台;
- 32GB显卡:38张GPU显卡,约等于单机八卡服务器,5台。
也就是说,即使抠抠索索的使用,也得消耗这么多资源,显存优化不做不行。于是,大量的显存优化工作就必须得上了。
显存优化方法
- 合理的计算调度:如DAPPLE中提到的early backward;
- Gradient Checkpointing:习惯上称之为重算(Re-computation)
- CPU-offload:ZeRO中提到的借用Host memory做辅助变量的offload
- Optimization-state优化:切分辅助变量分片存储
上面的有些优化,在目前流行的一些框架上,是需要手动做的。目前也有一些框架在自动化托管这些工作,但是上面这些优化组合,全自动化方案能否做到性能最优,并不容易。
这是第一个难点。
分布式复杂
即使做了显存优化,单卡也绝对不够,分布式方案是必然选择。但这里问题在于:Dense巨无霸模型很难用Naive Data Parallelism训练(单卡放不下一份完整的replica),迫使必须叠加各种各样的并行模式,所以只能是所谓的Hybrid Parallelism。例如可以是如下这种组合方案:
数据并行 + 算子拆分 + 流水并行
大家对数据并行比较熟悉,所以下面只展开后面两项、
算子拆分
算子拆分并不是什么新鲜想法。我用矩阵乘法举个最简单的例子。例如我们有如下变量和矩阵运算:
- variable矩阵: WWW
- batch input矩阵 XXX :
- 输出: Y=WXY=WXY=WX 。
单个矩阵乘法可以分到两个device上计算。我们在工程上要做的就是:将 WWW 切分到两个device上,将 XXX 复制到两个device上,然后两个device分别做矩阵乘法即可。有的时候,切分会带来额外的通信,比如矩阵乘法切到了reduction维度上,为了保持语义正确,就必须再紧跟一个AllReduce通信。
在Megatron-LM中,对Attention Block就做了这样的算子拆分(拆K,Q,V的head维度),像下面这样。
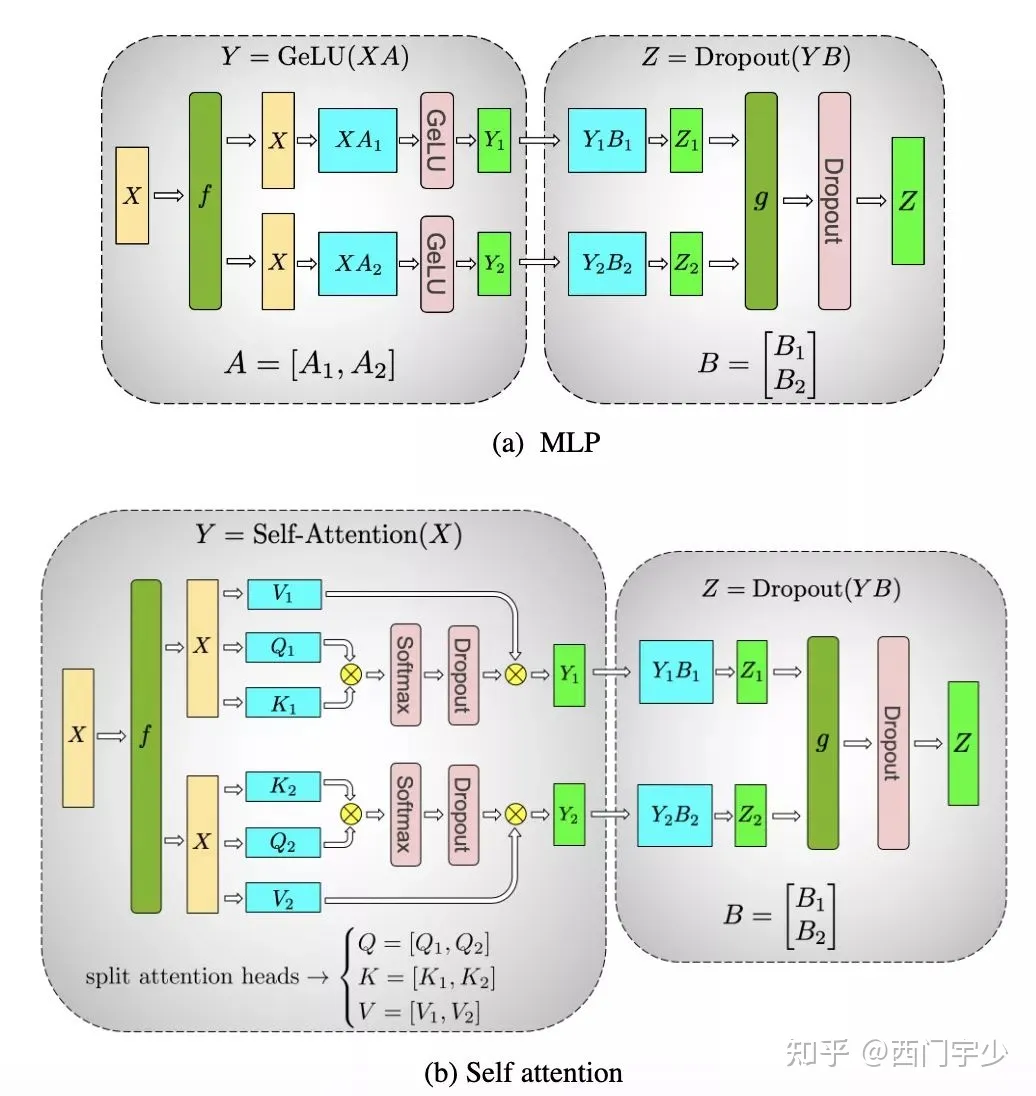
Megatron-LM的算子拆分方案
这里复杂之处在于,你不能无脑地将所有算子全部做拆分,因为拆分可能会引入一些额外通信,降低总体吞吐。所以你得做些分析,决定哪些算子被拆分,这得考虑以下因素:
- Workload的特点:计算量、参数量、Tensor shape等;
- 硬件拓扑:GPU算力,通信带宽等。
写个程序自动化行不行?能不能让程序自动搜索出来最佳的拆分方案?这取决于你在什么层次上做搜索。以TensorFlow为例,如果在GraphDef上的Operator这个粒度上做,搜索空间肯定爆炸。如果在Layer这个粗粒度上搜索,则是有可能的。但自动化方案也有一定的工作量:
- 拆分规则定制:为每种算子都需要定制一个完备的推导方案;
- 推导传播算法:推导影响链以及通信的引入(比如引入Reshard);
- Cost model:快速评估每种方案的性能;
- 高效地搜索算法:在巨大的空间里快速搜索出较好的方案。
现在大部分框架都不支持这种全自动化策略,要么是半自动或纯手工,要么是针对某种模型把它的拆分方案写死。所以只能造轮子解决这个事。
流水并行
不切算子,而是将不同的Layer切分到不同的Device上,就可以形成Pipeline方案。GPipe就是这样一种方案,提出了将一个batch拆分成若干个micro-batch,依次推入到Pipeline系统中,即可消除Bubble time(打时间差:Device 1计算micro-batch 1时,Device 0为空闲状态,正好推入下一个micro-batch)。下面这个图应该能看明白,就不过多解释了。
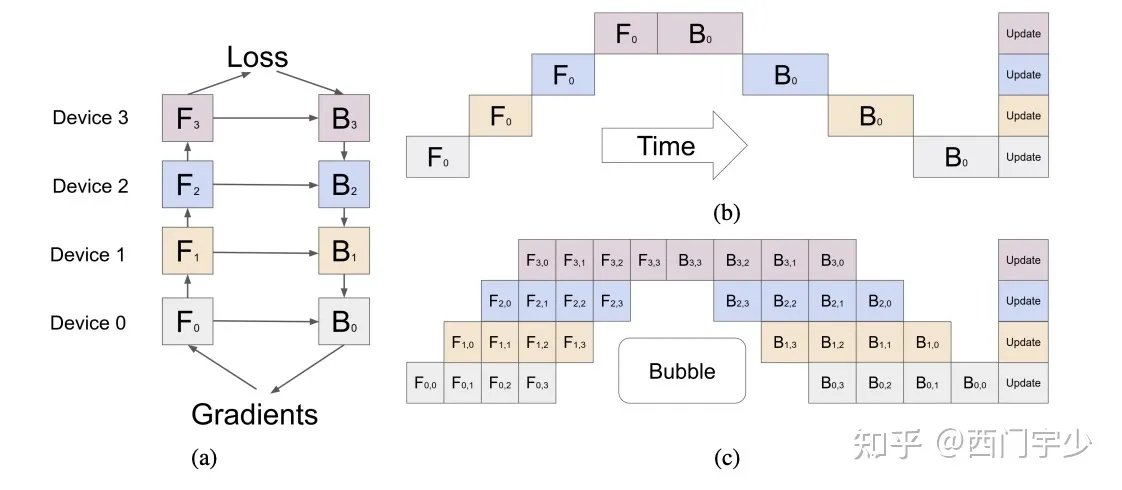
GPipe流水并行方案:F代表forward,B代表Backward。拆分多个micro-batch推入系统,有效地消除了Bubble time
然而,这种方案有显存压力。上图(a)中看到,B0的计算依赖于B1和F0,也就是说F0计算完成后,其Activations不能立即释放,直到B0算完才能丢掉。所以针对F0来说,推N个micro-batch时,我们要保存N份这样的Activations,直到他们的反向计算完成才能释放,显存峰值是很大的。
因此我们又要做显存优化了,我们在DAPPLE中提出了Early Backward方案,通过合理调度计算顺序,及早释放Activations,如下图所示。
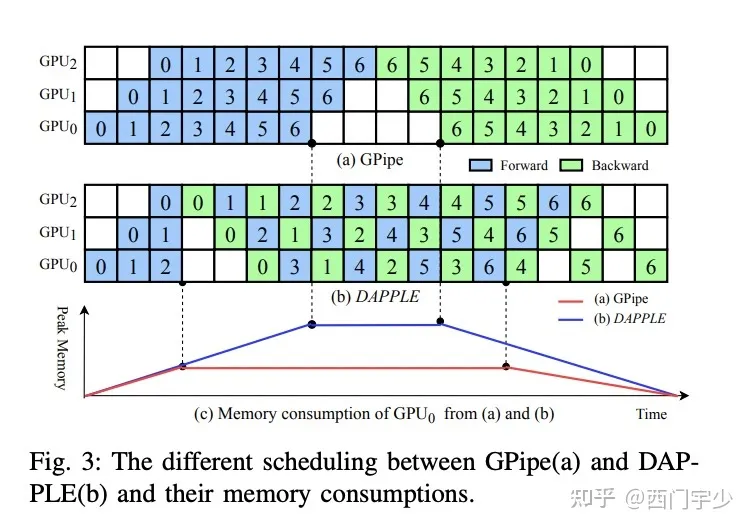
DAPPLE early backward调度方案。同个数字代表同个micro-batch,蓝色和绿色分别代表前向和反向计算。
和算子拆分类似,全自动化方案工作量不小,比如Pipeline怎么切,才能让通信量小,计算还能均匀,这需要一定的算法和工程量。
而且,在TensorFlow这样的框架上实现Early backward方案,除了让用户在编写模型时强行加上control flow严格控制,没有别的办法。大家自己可以试一试,用TF的Graph mode写这样的调度顺序,是有多么的噩梦,最好的解决方案可能还真就是造个轮子。
混合并行
如果把上述数据并行、算子拆分和流水并行混合起来,复杂度就更高了。
所以分布式,是第二个难点。
AI学习任重而道远。一起加油
参考:理解深度学习模型复杂度评估_全连接层计算复杂度_coco_12345的博客-CSDN博客
裴健团队44页新作:理解深度学习模型复杂度,看这一篇就够了!_腾讯新闻 (qq.com)
大模型训练的复杂度在哪_远洋之帆的博客-CSDN博客
(2 封私信) 为什么说大模型训练很难? - 知乎 (zhihu.com)
qq.com)](https://new.qq.com/rain/a/20210319A05DLG00)
大模型训练的复杂度在哪_远洋之帆的博客-CSDN博客
(2 封私信) 为什么说大模型训练很难? - 知乎 (zhihu.com)