1、环境搭建
conda create -n mmyolo python=3.7 -y #创建环境
conda activate mmyolo #激活环境
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch #安装 PyTorch and torchvision (官方)
#如果网不好,可以这样安装
pip3 install torch==1.8.2+cu102 torchvision==0.9.2+cu102 torchaudio===0.8.2 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install torch==1.11.0+cu115 torchvision==0.12.0+cu115 torchaudio==0.11.0 -f https://download.pytorch.org/whl/torch_stable.html -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
#验证是否安装成功
>>> import torchvision
>>> import torch
>>> import.__version__
File "<stdin>", line 1
import.__version__
^
SyntaxError: invalid syntax
>>> torch.__version__
'1.8.2+cu102'
conda create -n mmyolo python=3.8 pytorch==1.10.1 torchvision==0.11.2 cudatoolkit=11.3 -c pytorch -y
conda activate mmyolo
pip install openmim -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
mim install "mmengine>=0.6.0" -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
mim install "mmcv>=2.0.0rc4,<2.1.0" -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
mim install "mmdet>=3.0.0,<4.0.0" -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
git clone https://github.com/open-mmlab/mmyolo.git
cd mmyolo
# Install albumentations
pip install -r requirements/albu.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# Install MMYOLO
mim install -v -e .
2、环境测试
To verify whether MMYOLO is installed correctly, we provide an inference demo.
Step 1. We need to download config and checkpoint files.
mim download mmyolo --config yolov5_s-v61_syncbn_fast_8xb16-300e_coco --dest .
下载将需要几秒钟或更长时间,具体取决于您的网络环境。完成后,您将在当前文件夹中找到两个文件yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py和。yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
Step 2. Verify the inference demo.
选项(a)。如果您从源安装 MMYOLO,只需运行以下命令。
支持的输入类型:
单幅图像,包括jpg、jpeg、png、ppm、bmp、pgm、tif、tiff、webp。
文件夹,会遍历该文件夹下的所有图像文件并输出相应的结果。
URL,会自动从该URL下载并输出相应的结果。
python demo/image_demo.py demo/demo.jpg \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
# Optional parameters
# --out-dir ./output *The detection results are output to the specified directory. When args have action --show, the script do not save results. Default: ./output
# --device cuda:0 *The computing resources used, including cuda and cpu. Default: cuda:0
# --show *Display the results on the screen. Default: False
# --score-thr 0.3 *Confidence threshold. Default: 0.3
您将在文件夹中看到一个新图像output,其中绘制了边界框。

3、 15 分钟开始 MMYOLO 物体检测
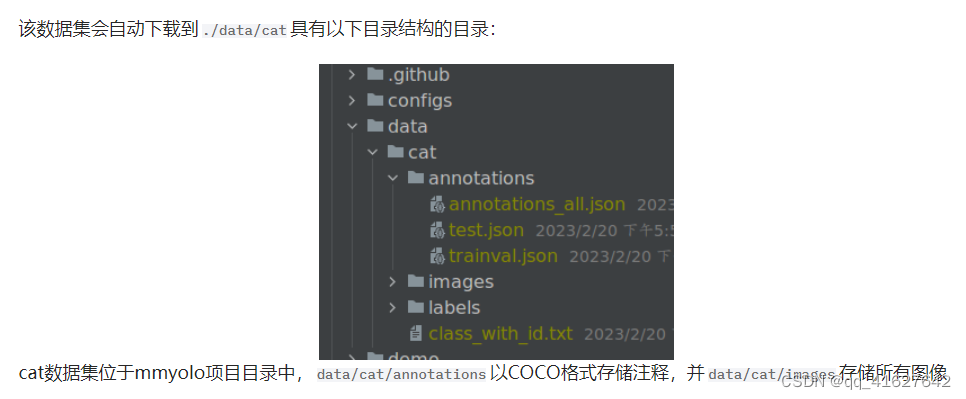
1、数据

python tools/misc/download_dataset.py --dataset-name cat --save-dir ./data/cat --unzip --delete
2、配置
以YOLOv5算法为例,考虑到用户的GPU内存有限,我们需要修改一些默认的训练参数以使其顺利运行。需要修改的关键参数如下:
YOLOv5是Anchor-Based算法,不同的数据集需要自适应计算合适的anchor
默认配置使用 8 个 GPU,每个 GPU 的批量大小为 16 个。现在将其更改为单 GPU,批量大小为 12。
默认训练 epoch 为 300。将其更改为 40 epoch
考虑到数据集较小,我们选择使用固定主干权重
原则上,当batch size改变时,学习率应该相应地线性缩放,但实际测量发现这是没有必要的。
在该文件夹中创建一个yolov5_s-v61_fast_1xb12-40e_cat.py配置文件configs/yolov5(我们已提供此配置供您直接使用)并将以下内容复制到配置文件中。
# Inherit and overwrite part of the config based on this config
_base_ = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
data_root = './data/cat/' # dataset root
class_name = ('cat', ) # dataset category name
num_classes = len(class_name) # dataset category number
# metainfo is a configuration that must be passed to the dataloader, otherwise it is invalid
# palette is a display color for category at visualization
# The palette length must be greater than or equal to the length of the classes
metainfo = dict(classes=class_name, palette=[(20, 220, 60)])
# Adaptive anchor based on tools/analysis_tools/optimize_anchors.py
anchors = [
[(68, 69), (154, 91), (143, 162)], # P3/8
[(242, 160), (189, 287), (391, 207)], # P4/16
[(353, 337), (539, 341), (443, 432)] # P5/32
]
# Max training 40 epoch
max_epochs = 40
# Set batch size to 12
train_batch_size_per_gpu = 12
# dataloader num workers
train_num_workers = 4
# load COCO pre-trained weight
load_from = 'https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth' # noqa
model = dict(
# Fixed the weight of the entire backbone without training
backbone=dict(frozen_stages=4),
bbox_head=dict(
head_module=dict(num_classes=num_classes),
prior_generator=dict(base_sizes=anchors)
))
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
# Dataset annotation file of json path
ann_file='annotations/trainval.json',
# Dataset prefix
data_prefix=dict(img='images/')))
val_dataloader = dict(
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/test.json',
data_prefix=dict(img='images/')))
test_dataloader = val_dataloader
_base_.optim_wrapper.optimizer.batch_size_per_gpu = train_batch_size_per_gpu
val_evaluator = dict(ann_file=data_root + 'annotations/test.json')
test_evaluator = val_evaluator
default_hooks = dict(
# Save weights every 10 epochs and a maximum of two weights can be saved.
# The best model is saved automatically during model evaluation
checkpoint=dict(interval=10, max_keep_ckpts=2, save_best='auto'),
# The warmup_mim_iter parameter is critical.
# The default value is 1000 which is not suitable for cat datasets.
param_scheduler=dict(max_epochs=max_epochs, warmup_mim_iter=10),
# The log printing interval is 5
logger=dict(type='LoggerHook', interval=5))
# The evaluation interval is 10
train_cfg = dict(max_epochs=max_epochs, val_interval=10)
上面的配置继承自yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py. 根据cat数据集的特点更新了、、、、、data_root等配置。metainfotrain_dataloaderval_dataloadernum_classes
3、训练
python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py
运行上述训练命令,work_dirs/yolov5_s-v61_fast_1xb12-40e_cat会自动生成文件夹,检查点文件和训练配置文件将保存在该文件夹中。在低端 1660 GPU 上,整个训练过程大约需要八分钟。
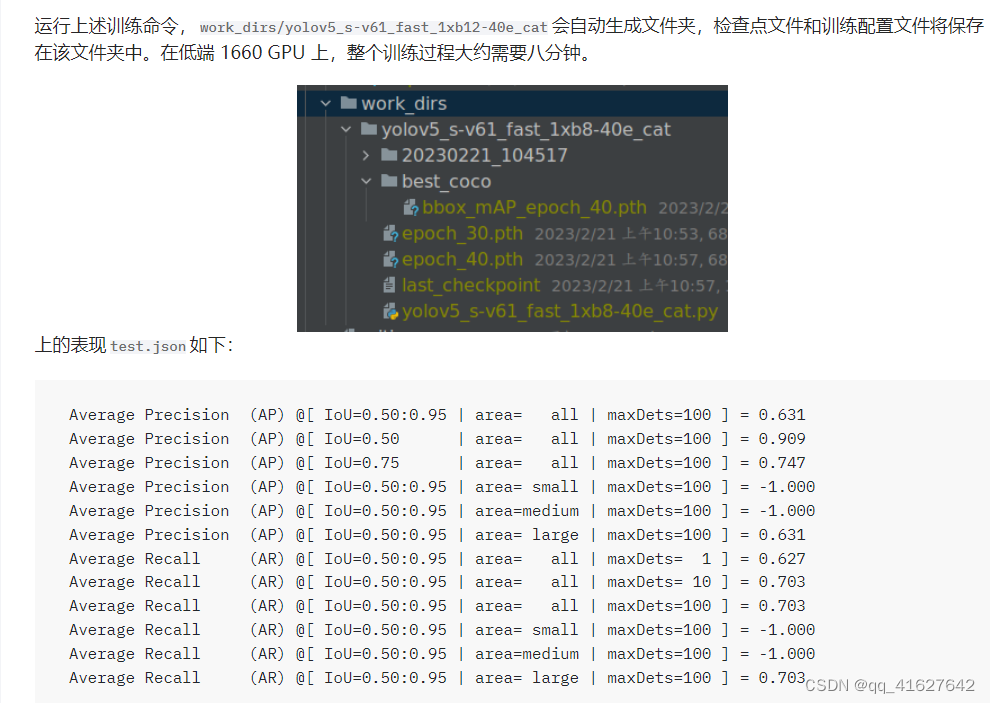
上述属性是通过 COCO API 打印的,其中 -1 表示该比例不存在对象。根据COCO定义的规则,Cat数据集包含所有大型物体,不存在小型或中型物体。
训练中断后恢复
如果您停止训练,您可以添加–resume到训练命令的末尾,程序将自动使用来自 的最新权重文件恢复训练work_dirs。
python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py --resume
保存GPU内存策略
上述配置需要大约 3G RAM,所以如果你没有足够的内存,请考虑开启混合精度训练
python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py --amp
培训可视化
MMYOLO目前支持本地、TensorBoard、WandB等后端可视化。默认使用本地可视化,训练过程中可以切换到WandB等各种指标实时可视化。
Tensorboard
pip install tensorboard
Add the tensorboard config at the end of config file we just created: configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py.
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
重新运行训练命令后,将在可视化文件夹中生成Tensorboard文件work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/{timestamp}/vis_data。我们可以通过运行以下命令,使用 Tensorboard 从 Web 链接查看损失、学习率和 coco/bbox_mAP 可视化:
tensorboard --logdir=work_dirs/yolov5_s-v61_fast_1xb12-40e_cat
4、训练特征图可视化
MMYOLO 提供了特征图的可视化脚本来分析当前的模型训练。请参考特征图可视化
由于直接可视化的偏差test_pipeline,我们需要test_pipeline修改configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
到以下配置:
test_pipeline = [
dict(
type='LoadImageFromFile',
backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # modify the LetterResize to mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
我们选择该data/cat/images/IMG_20221020_112705.jpg图像作为示例来可视化 YOLOv5 主干层和颈部层的输出特征图
1.可视化YOLOv5主干的三个通道
python demo/featmap_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layers backbone \
--channel-reduction squeeze_mean

结果将保存到当前路径的输出文件夹中。上图中绘制的三个输出特征图分别对应小、中、大输出特征图。由于本次训练的backbone实际上并没有参与训练,所以从上图可以看出,大物体猫是在小特征图上进行预测的,这符合物体检测的分层检测的思想。
2.可视化YOLOv5颈部的三个通道
python demo/featmap_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layers neck \
--channel-reduction squeeze_mean
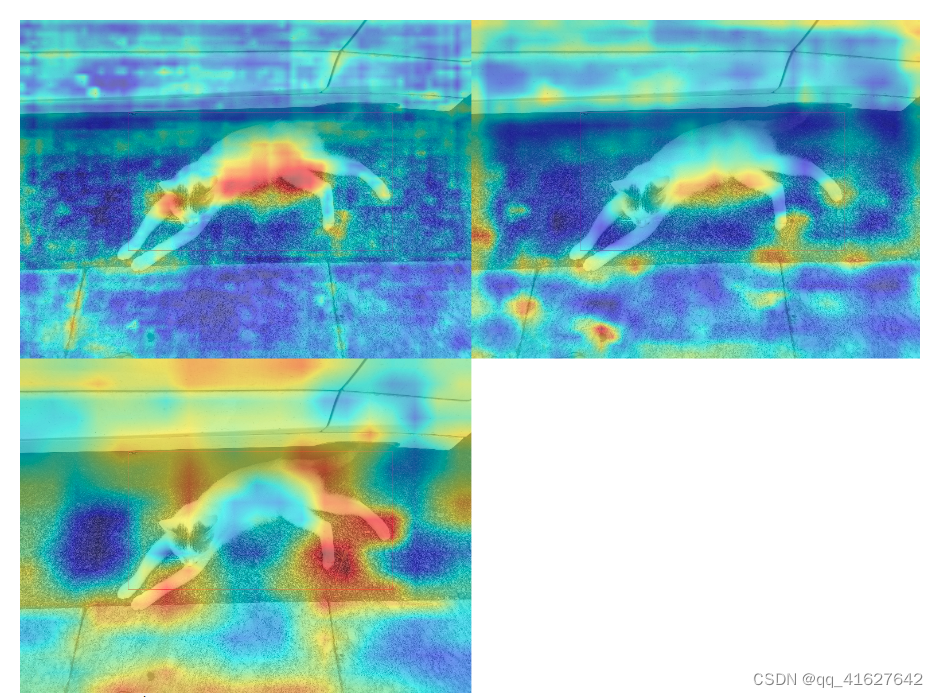
从上图可以看出,由于neck参与训练,而且我们也重置了anchor,导致三个输出特征图被迫模拟相同尺度的物体,导致neck的三个输出特征图相似,这就破坏了neck的三个输出特征图。原始骨干预训练分布。同时也可以看出,40个epoch不足以训练上述数据集,并且特征图表现不佳。
3. 基于梯度的 CAM 可视化
基于上述特征图可视化,我们可以在bbox级别的特征层分析Grad CAM
安装grad-cam包:
pip install "grad-cam"
(a) 查看颈部最小输出特征图的Grad CAM
python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layer neck.out_layers[2]

(b) 查看颈部中等输出特征图的Grad CAM
python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layer neck.out_layers[1]

© 查看颈部最大输出特征图的Grad CAM
python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--target-layer neck.out_layers[0]

5、EasyDeploy部署
这里我们将使用MMYOLO的EasyDeploy来演示模型的转换部署和基本推理。
首先你需要按照EasyDeploy的基本文档控制每个库自己安装的设备。
pip install onnx
pip install onnx-simplifier # Install if you want to use simplify
pip install tensorrt # If you have GPU environment and need to output TensorRT model you need to continue execution
安装完成后,您可以使用以下命令将训练好的模型一键转换并部署到cat数据集上。当前ONNX版本为1.13.0,TensorRT版本为8.5.3.1,因此保留值–opset11。其余参数需要根据使用的配置进行调整。这里我们导出 ONNX 的 CPU 版本,设置–backend为 1。
python projects/easydeploy/tools/export.py \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--work-dir work_dirs/yolov5_s-v61_fast_1xb12-40e_cat \
--img-size 640 640 \
--batch 1 \
--device cpu \
--simplify \
--opset 11 \
--backend 1 \
--pre-topk 1000 \
--keep-topk 100 \
--iou-threshold 0.65 \
--score-threshold 0.25
成功后,您将在 下获得转换后的 ONNX 模型work-dir,该模型end2end.onnx默认命名。
让我们使用end2end.onnxmodel 来执行基本的图像推理:
python projects/easydeploy/tools/image-demo.py \
data/cat/images/IMG_20210728_205312.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/end2end.onnx \
--device cpu
output推理成功后,会在默认MMYOLO根目录的文件夹中生成结果图像。如果想查看结果而不保存,可以–show在上述命令末尾添加。为了方便起见,以下是生成的结果。
我们继续转换TensorRT的引擎文件,因为TensorRT需要针对当前环境和部署版本,所以一定要导出参数,这里我们导出TensorRT8文件,为2 --backend。
python projects/easydeploy/tools/export.py \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
--work-dir work_dirs/yolov5_s-v61_fast_1xb12-40e_cat \
--img-size 640 640 \
--batch 1 \
--device cuda:0 \
--simplify \
--opset 11 \
--backend 2 \
--pre-topk 1000 \
--keep-topk 100 \
--iou-threshold 0.65 \
--score-threshold 0.25
生成的结果end2end.onnx是 TensorRT8 部署的 ONNX 文件,我们将使用它来完成 TensorRT 引擎转换。
python projects/easydeploy/tools/build_engine.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/end2end.onnx \
--img-size 640 640 \
--device cuda:0
执行成功会生成end2end.engine以下文件work-dir:
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat
├── 202302XX_XXXXXX
│ ├── 202302XX_XXXXXX.log
│ └── vis_data
│ ├── 202302XX_XXXXXX.json
│ ├── config.py
│ └── scalars.json
├── best_coco
│ └── bbox_mAP_epoch_40.pth
├── end2end.engine
├── end2end.onnx
├── epoch_30.pth
├── epoch_40.pth
├── last_checkpoint
└── yolov5_s-v61_fast_1xb12-40e_cat.py
让我们继续用于image-demo.py图像推理:
python projects/easydeploy/tools/image-demo.py \
data/cat/images/IMG_20210728_205312.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/end2end.engine \
--device cuda:0
这里我们选择将推理结果保存在下面,output而不是直接显示它们。推理结果如下所示。

3、 15 分钟开始使用 MMYOLO 实例分割
实例分割是计算机视觉中的一项任务,旨在分割图像中的每个对象并为每个对象分配唯一的标识符。
与语义分割不同,实例分割不仅分割出图像中的不同类别,而且还分离出同一类别的不同实例。

1、数据集


您可以通过以下命令直接下载并使用:
python tools/misc/download_dataset.py --dataset-name balloon --save-dir ./data/balloon --unzip --delete
python ./tools/dataset_converters/balloon2coco.py
MMYOLO 项目的数据位于 MMYOLO 项目目录中。和文件以 COCO 格式存储注释,而和目录train.json包含数据集的所有图像。val.jsondata/balloon/traindata/balloon/val
2、配置
以YOLOv5算法为例,考虑到用户的GPU内存有限,我们需要修改一些默认的训练参数以使其顺利运行。需要修改的关键参数如下:
YOLOv5是一种Anchor-Based算法,不同的数据集需要自适应计算合适的anchor。
默认配置使用 8 个 GPU,每个 GPU 的批量大小为 16 个。现在将其更改为单 GPU,批量大小为 12。
原则上,当批量大小改变时,学习率应该相应地线性缩放,但实际测量发现这是没有必要的。
要执行特定操作,请yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py在该configs/yolov5/ins_seg文件夹中创建一个名为的新配置文件。为了方便起见,我们已经提供了这个配置文件。将以下内容复制到配置文件中。
_base_ = './yolov5_ins_s-v61_syncbn_fast_8xb16-300e_coco_instance.py' # noqa
data_root = 'data/balloon/' # dataset root
# Training set annotation file of json path
train_ann_file = 'train.json'
train_data_prefix = 'train/' # Dataset prefix
# Validation set annotation file of json path
val_ann_file = 'val.json'
val_data_prefix = 'val/'
metainfo = {
'classes': ('balloon', ), # dataset category name
'palette': [
(220, 20, 60),
]
}
num_classes = 1
# Set batch size to 4
train_batch_size_per_gpu = 4
# dataloader num workers
train_num_workers = 2
log_interval = 1
#####################
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
data_prefix=dict(img=train_data_prefix),
ann_file=train_ann_file))
val_dataloader = dict(
dataset=dict(
data_root=data_root,
metainfo=metainfo,
data_prefix=dict(img=val_data_prefix),
ann_file=val_ann_file))
test_dataloader = val_dataloader
val_evaluator = dict(ann_file=data_root + val_ann_file)
test_evaluator = val_evaluator
default_hooks = dict(logger=dict(interval=log_interval))
#####################
model = dict(bbox_head=dict(head_module=dict(num_classes=num_classes)))
上述配置根据气球数据集的特点,继承yolov5_ins_s-v61_syncbn_fast_8xb16-300e_coco_instance.py并更新了data_root、metainfo、train_dataloader、val_dataloader、num_classes等配置。
3、Training
python tools/train.py configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py
运行上述训练命令后,work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance会自动生成该文件夹。本次训练的权重文件和训练配置文件将保存在该文件夹中。在 GTX 1660 这样的低端 GPU 上,整个训练过程大约需要 30 分钟。
4、测试
python tools/test.py configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py \
work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance/best_coco_bbox_mAP_epoch_300.pth \
--show-dir show_results
4、训练技巧
训练技巧
###1 提高检测性能
1. 多尺度训练
在目标检测领域,多尺度训练是一个非常常见的技巧。然而,在YOLO中,大多数模型都是使用640x640的单尺度输入进行训练的。有两个原因:
单尺度训练比多尺度训练更快。当训练epoch为300或500时,训练效率是用户主要关心的问题。多尺度训练会更慢。
训练管道中隐含了多尺度增强,相当于多尺度训练的应用,如‘Mosaic’、‘RandomAffine’和‘Resize’,因此不需要引入多尺度训练再次输入模型。
通过在COCO数据集上的实验发现,YOLOv5的DataLoader输出后直接引入多尺度训练,实际性能提升很小。如果你想在 MMYOLO 中开始对 YOLO 系列算法进行多尺度训练,可以参考ms_training_testing,不过,这并不意味着用户自定义数据集微调模式没有明显的收益。
MMYOLO 目前支持流行的 YOLOv5、YOLOv6、YOLOv7、YOLOv8 和 RTMDet 算法,默认配置为单尺度 640x640 训练。MM系列开源库中常用的多尺度训练的实现有两种
中的每个图像输出train_pipeline都是可变比例的,并通过DataPreprocessor中的stack_batch函数将不同比例的输入图像填充到相同的比例。MMDet 中的大多数算法都是使用这种方法实现的。
中的每个图像输出train_pipeline都是固定尺度的,并且DataPreprocessor对图像批次进行上采样和下采样,直接进行多尺度训练。
MMYOLO 支持两种多尺度训练方法。理论上,第一种实现可以生成更丰富的尺度,但由于其对单个图像的独立增强,其训练效率不如第二种。因此,我们建议使用第二种方法。
以configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py配置为例,其默认配置是640x640固定尺度训练,假设你想实现32的倍数、多尺度范围(480、800)的训练,可以参考YOLOX的实践,通过DataPreprocessor中的YOLOXBatchSyncRandomResize实现。
在使用以下内容configs/yolov5命名的路径下创建新配置。configs/yolov5/yolov5_s-v61_fast_1xb12-ms-40e_cat.py
_base_ = 'yolov5_s-v61_fast_1xb12-40e_cat.py'
model = dict(
data_preprocessor=dict(
type='YOLOv5DetDataPreprocessor',
pad_size_divisor=32,
batch_augments=[
dict(
type='YOLOXBatchSyncRandomResize',
# multi-scale range (480, 800)
random_size_range=(480, 800),
# The output scale needs to be divisible by 32
size_divisor=32,
interval=1)
])
)
上述配置将实现多尺度训练。为了方便起见,我们已经在下面提供了此配置configs/yolov5/。YOLO 系列算法的其余部分类似。
2 使用Mask标注优化物体检测性能
当数据集标注完整时,例如边界框标注和实例分割标注同时存在,但任务只需要部分标注,则可以使用完整的数据标注来训练任务,以提高性能。在对象检测中,我们还可以从实例分割注释中学习来提高对象检测的性能。以下是YOLOv8引入的附加实例分割标注优化的检测结果。性能提升如下所示:
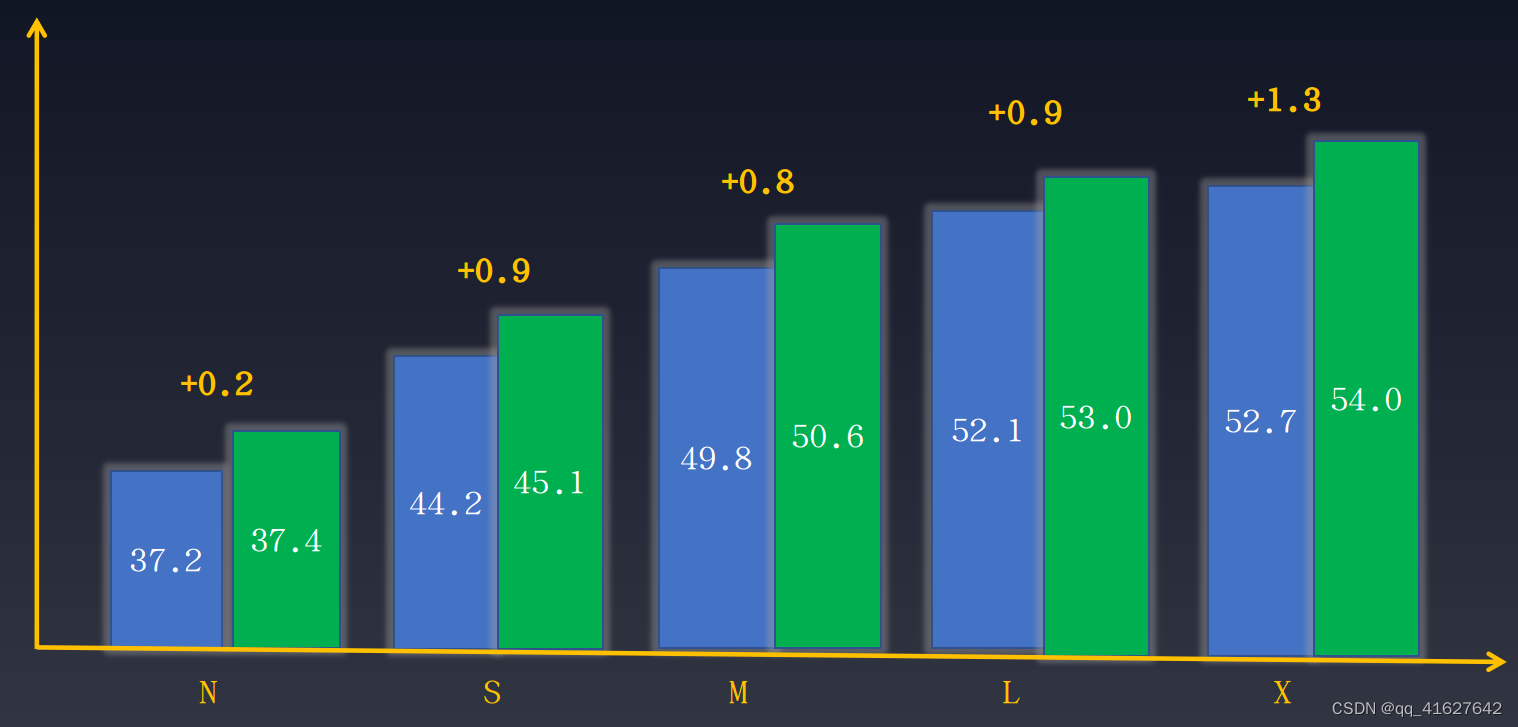
如图所示,不同尺度的模型有不同程度的性能提升。需要注意的是,“Mask Refine”仅在数据增强阶段起作用,不需要对模型的其他训练部分进行任何更改,也不会影响训练速度。详情如下所示:
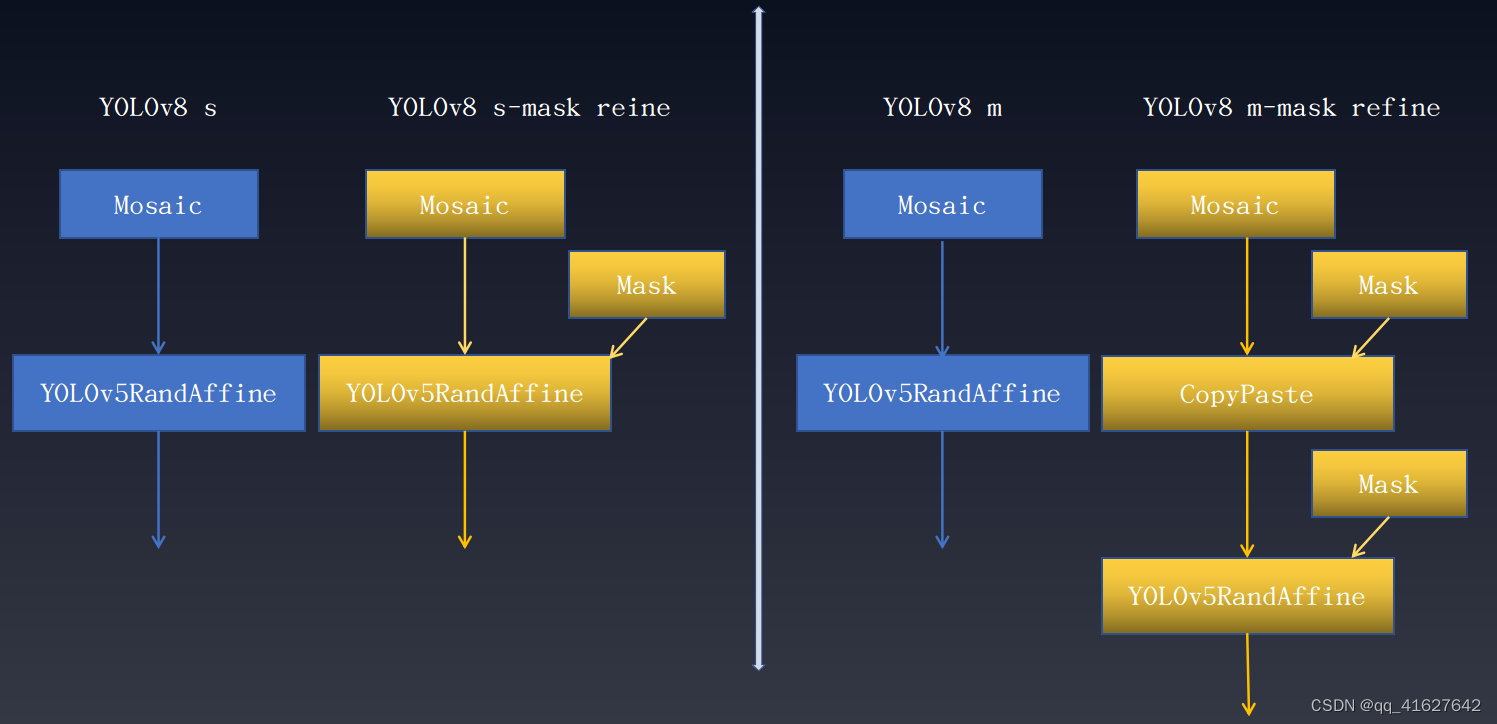
上述Mask代表了一种数据增强转换,其中实例分割注释起着关键作用。该技术在其他YOLO系列中的应用都有不同程度的增加。
3 训练后期关闭强增强以提高检测性能
该策略在YOLOX算法中首次提出,可以极大地提高检测性能。论文指出,Mosaic+MixUp 可以大幅提升目标检测性能,但训练图片与自然图片的真实分布相去甚远,而且 Mosaic 大量的裁剪操作会带来很多不准确的标签框,因此,YOLOX 提出将去掉最后15个epoch的强增强,改用较弱的增强,这样检测器就可以避免不准确标记框的影响,在自然图片的数据分布下完成最终的收敛。
该策略已应用于大多数YOLO算法。以YOLOv8为例,其数据增强管道如下所示:
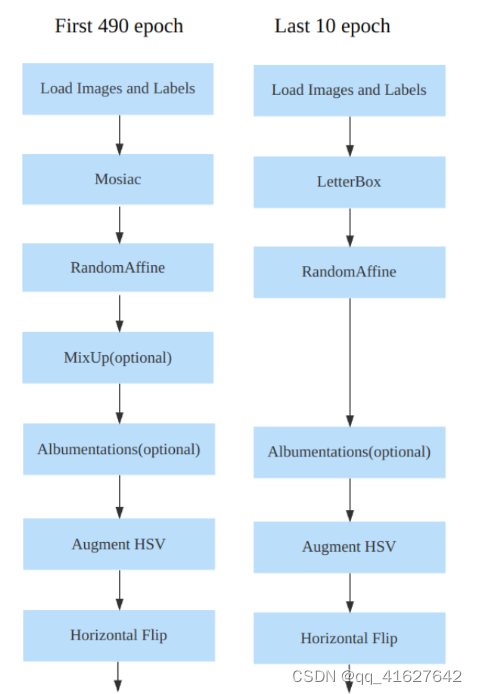
然而,何时关闭强增强是一个超参数。如果过早关闭强增强,可能无法充分发挥马赛克等强增强效果。如果太晚关闭强增强,它就没有增益,因为之前已经过拟合了。在YOLOv8实验中可以观察到这种现象
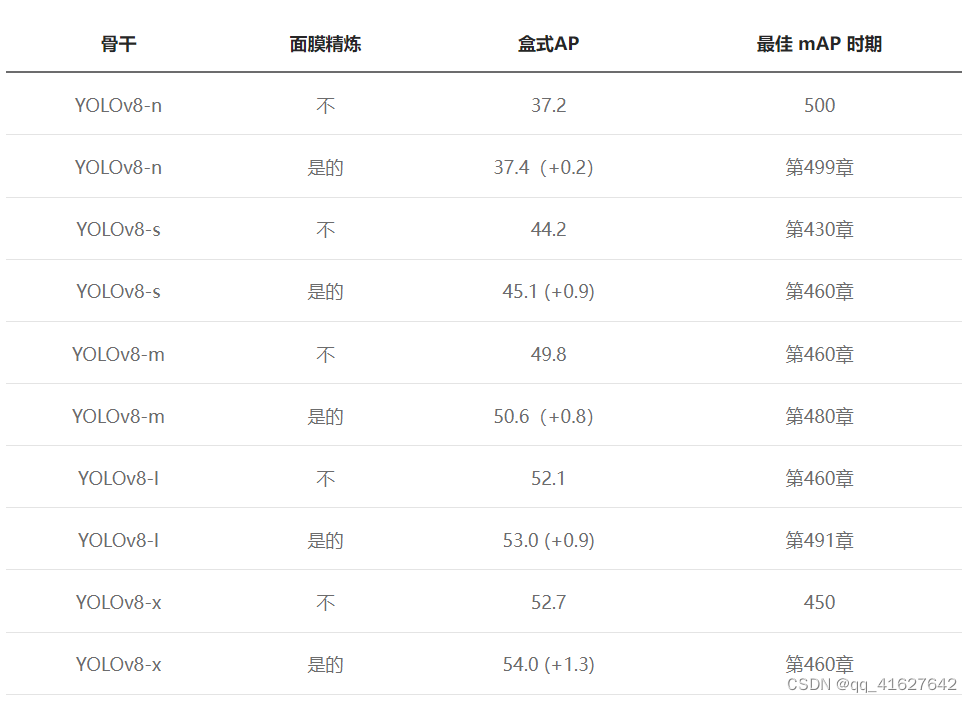
从上表可以看出:
在 COCO 数据集上训练 500 个 epoch 的大型模型很容易出现过度拟合,在这种情况下,禁用 Mosaic 等强增强功能可能无法有效减少过度拟合。
使用Mask注释可以缓解过度拟合并提高性能
4 添加纯背景图片抑制FP
对于目标检测中的非开放世界数据集,训练和测试都是在一组固定的类上进行的,当应用于未经训练的类的图像时,有可能产生误报。常见的缓解策略是添加一定比例的纯背景图片。在大多数YOLO系列中,默认启用通过添加纯背景图像来抑制误报的功能。用户只需将train_dataloader.dataset.filter_cfg.filter_empty_gt设置为False,表示训练时不应该过滤掉纯背景图像。
5 也许 AdamW 能创造奇迹
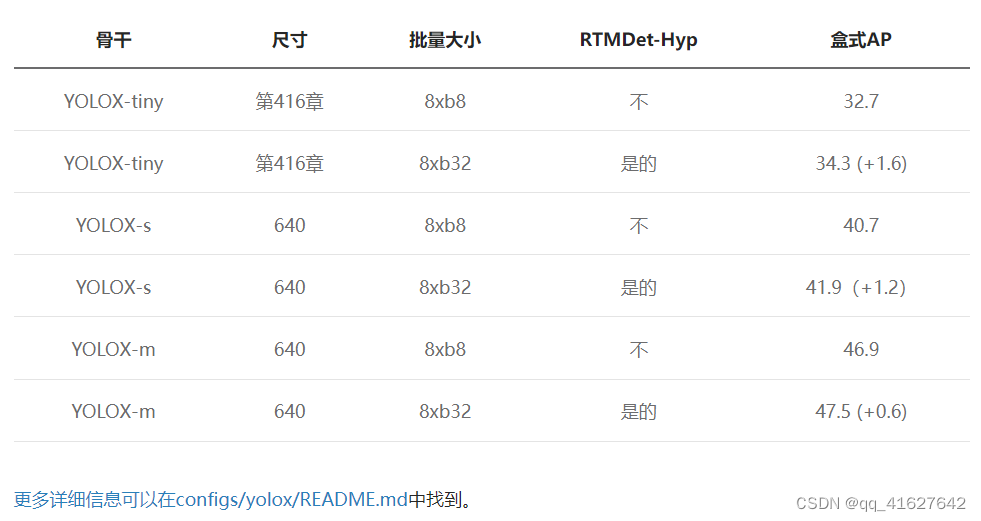
YOLOv5、YOLOv6、YOLOv7、YOLOv8均采用SGD优化器,对参数设置比较严格,而AdamW则相反,对学习率不太敏感。如果用户微调自定义数据集可以尝试选择 AdamW 优化器。我们在YOLOX中做了简单的试验,发现在tiny、s、m尺度模型上用AdamW替换优化器都有一定的改进。
6 考虑忽略场景以避免不确定的注释
以 CrowdHuman 为例,这是一个拥挤的行人检测数据集。这是一个典型的图像:
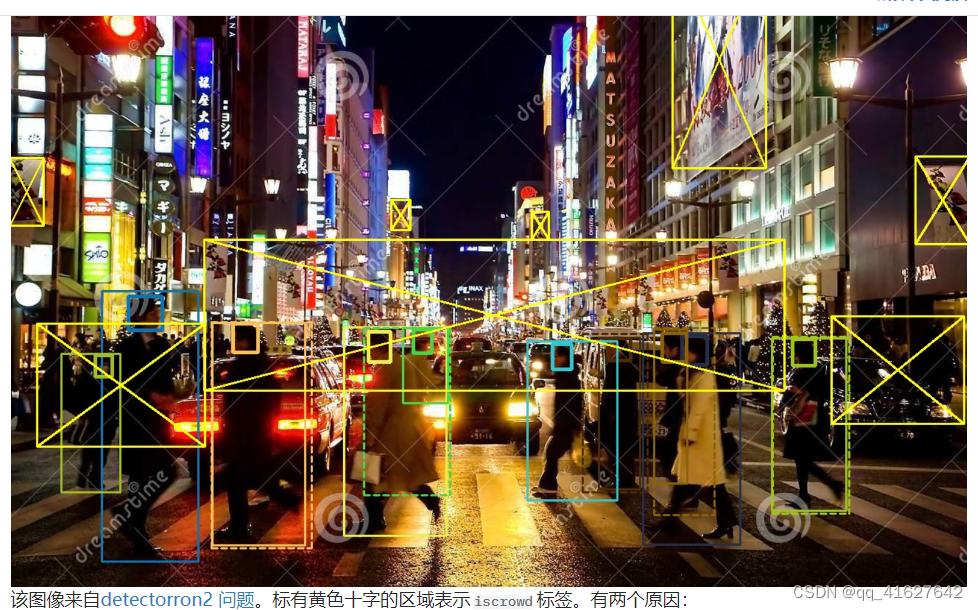
该区域不是真人,例如海报上的人
该区域太拥挤,无法标记
在这种情况下,您不能简单地删除此类注释,因为一旦删除它们,就意味着在训练期间将它们视为背景区域。然而,它们与背景不同。首先,海报上的人与真人非常相似,而且人群密集的地方确实存在难以标注的人。如果只是将它们作为背景进行训练,会导致漏报。最好的方法是将拥挤区域视为忽略区域,该区域中的任何输出都被直接忽略,不计算损失,也不强制执行模型拟合。


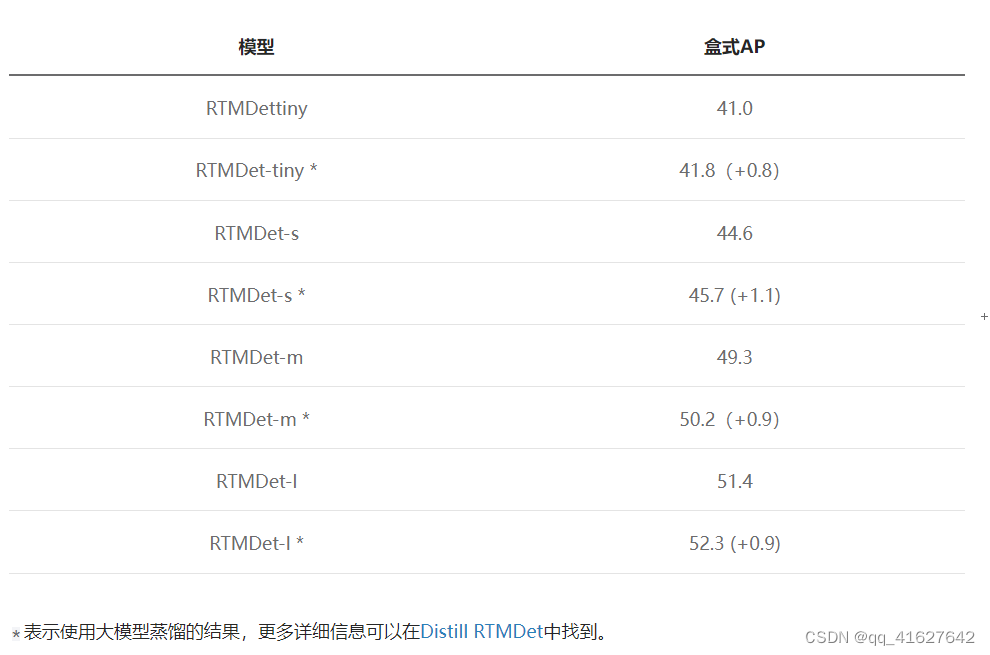
7 使用知识蒸馏
知识蒸馏是一种广泛使用的技术,可以将大模型的性能转移到较小的模型上,从而提高较小模型的检测性能。目前MMYOLO和MMRazor已经支持该功能,并在RTMDet上进行了初步验证。
8 更强的增强参数用于更大的模型
如果您在默认配置的基础上修改了模型或更换了主干网络,建议根据当前模型大小缩放数据增强参数。一般来说,较大的模型需要更强的增强参数,否则它们可能无法充分利用大型模型的优势。相反,如果对小模型应用强增强,则可能会导致欠拟合。以 RTMDet 为例,我们可以观察不同模型大小的数据增强参数。

random_resize_ratio_range表示 的随机缩放范围RandomResize,mosaic_max_cached_images/mixup_max_cached_images表示增强时缓存的图像数量Mosaic/MixUp,可用于调整增强的强度。YOLO系列模型都遵循同一套参数设置原则。
加快训练速度
1 启用 cudnn_benchmark 进行单尺度训练
YOLO系列算法中大部分输入图像尺寸都是固定的,属于单尺度训练。这种情况下,可以开启cudnn_benchmark来加快训练速度。该参数主要是为PyTorch的cuDNN底层库设置的,设置该标志可以让内置的cuDNN自动寻找最适合当前配置的最高效的算法,以优化运行效率。如果在多尺度模式下打开该标志,它将不断搜索最优算法,这可能反而会减慢训练速度。
要在 MMYOLO 中启用cudnn_benchmark,您可以在配置中进行设置。env_cfg = dict(cudnn_benchmark=True)
2 使用 Mosaic 和 MixUp 进行缓存
如果您在数据增强中应用了 Mosaic 和 MixUp,并且在调查训练瓶颈后发现随机图像读取导致了问题,那么建议将常规 Mosaic 和 MixUp 替换为建议的启用缓存的版本在 RTMDet 中。

Mosaic和MixUp涉及混合多张图像,其耗时是普通数据增强的K倍(K是混合图像的数量)。例如YOLOv5中,每次做Mosaic时,都需要从硬盘重新加载4张图像的信息。而Mosaic和MixUp的缓存版本只需要重新加载当前图像,而混合增强涉及的剩余图像则从缓存队列中获取,通过牺牲一定的内存空间大大提高了效率。
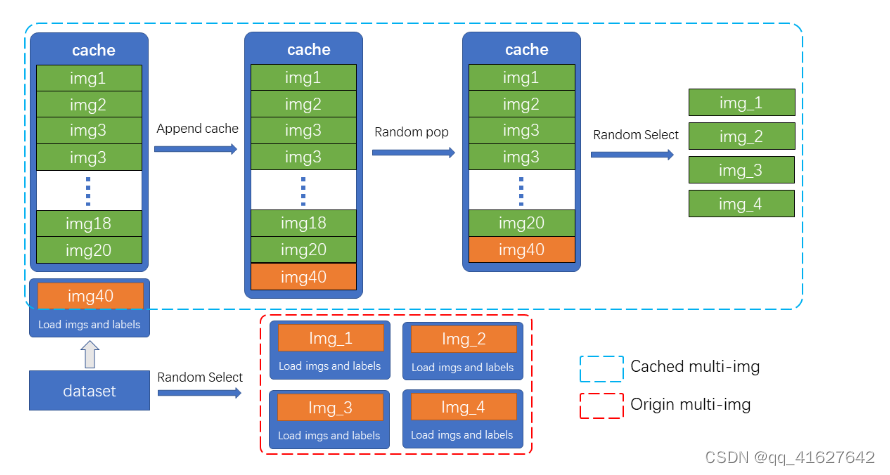
如图所示,缓存队列中存储了N张预加载的图像和标签数据。在每个训练步骤中,只需要在缓存队列中加载和更新一张新图像及其标签数据。(缓存队列中的图片可以重复,如图img3出现两次。)如果缓存队列的长度超过预设长度,则会随机弹出一张图片。当需要进行混合数据增强时,只需从缓存中随机选择所需的图像进行串联或其他处理,而不需要从硬盘加载所有图像,从而节省图像加载时间。
减少超参数的数量
YOLOv5提供了一些减少超参数数量的实用方法,如下所述。
5、测试技巧
1、TTA 提高测试准确性
使用 TTA(测试时间增强)进行数据增强是一种多功能技巧,可以提高目标检测模型的性能,在竞赛场景中特别有用。–ttaMMYOLO已经支持TTA,测试时只需添加即可启用。欲了解更多详情,请参阅TTA
2、推理速度和测试精度之间的平衡
在模型性能测试时,我们一般要求较高的mAP,但在实际应用或推理中,我们希望模型执行得更快,同时保持较低的误报率和漏报率。也就是说,测试时只关注mAP,而忽略后处理和评估速度,而在实际应用中,追求速度和精度之间的平衡。在YOLO系列中,可以通过控制某些参数来实现速度和精度之间的平衡。在此示例中,我们将使用 YOLOv5 详细描述这一点。
1 在推理过程中避免单个检测框的多个类输出
YOLOv5在分类分支的训练过程中使用BCE Loss(use_sigmoid=True)。假设有4个对象类别,则分类分支输出的类别数为4而不是5。而且,由于使用了sigmoid而不是softmax预测,因此可以在a上预测多个满足过滤阈值的检测框。某个位置,这意味着可能存在一个预测bbox对应多个预测标签的情况。如下图所示:
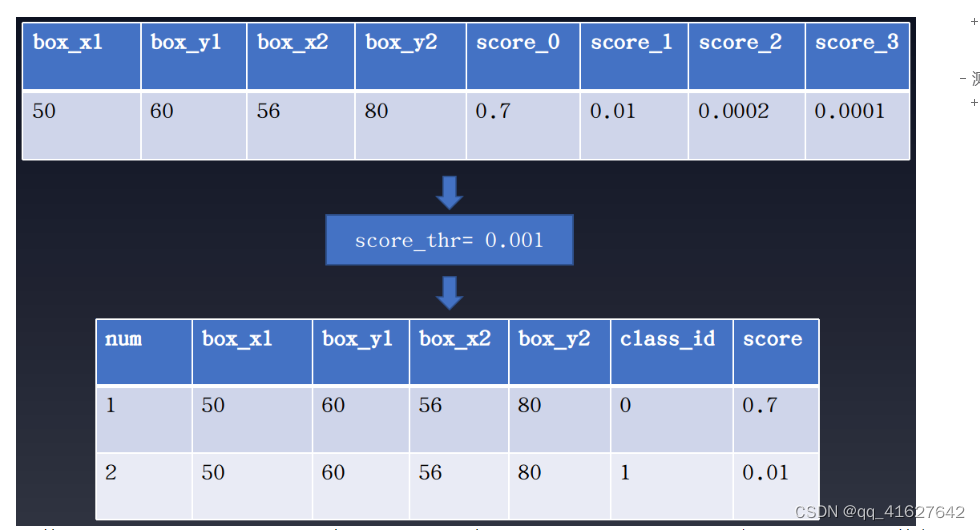
一般计算mAP时,过滤阈值设置为0.001。由于sigmoid的非竞争性预测模式,一个box可能对应多个标签。这种计算方法在计算mAP时可以提高召回率,但实际应用中可能不太方便。
一种常见的方法是提高过滤阈值。不过,如果不想出现很多漏报,建议将该multi_label参数设置为False。它位于配置文件中mode.test_cfg.multi_label,默认值为True,允许一个检测框对应多个标签。
2 简化测试流程
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
scale=img_scale,
allow_scale_up=False,
pad_val=dict(img=114)),
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
它使用两种不同功能的Resize,目的是提高评估时的mAP值。在实际部署中,你可以简化这个管道,如下所示:
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='LetterResize',
scale=_base_.img_scale,
allow_scale_up=True,
use_mini_pad=True),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor', 'pad_param'))
]
在实际应用中,YOLOv5算法使用简化的管道,multi_label设置为False,score_thr增加到0.25,iou_threshold减小到0.45。在YOLOv5配置中,我们提供了一组用于地面检测的配置参数,详细信息请参见yolov5_s-v61_syncbn-detect_8xb16-300e_coco.py。
3 Batch Shape加快测试速度
Batch Shape 是 YOLOv5 中提出的一种测试技术,可以加快推理速度。这个想法是不再要求测试过程中的所有图像都是 640x640,而是以可变比例进行测试,只要当前批次中的形状相同即可。这种方法可以减少额外的图像像素填充并加快推理过程。Batch Shape的具体实现可以参见链接。MMYOLO 中的几乎所有算法在测试期间都默认启用 Batch Shape 策略。如果用户想禁用该功能,可以设置val_dataloader.dataset.batch_shapes_cfg=None。
在实际应用中,由于动态形状不如固定形状快速高效。因此,该策略一般不会在现实场景中使用。
6、模型设计说明
1、YOLO系列模型基础类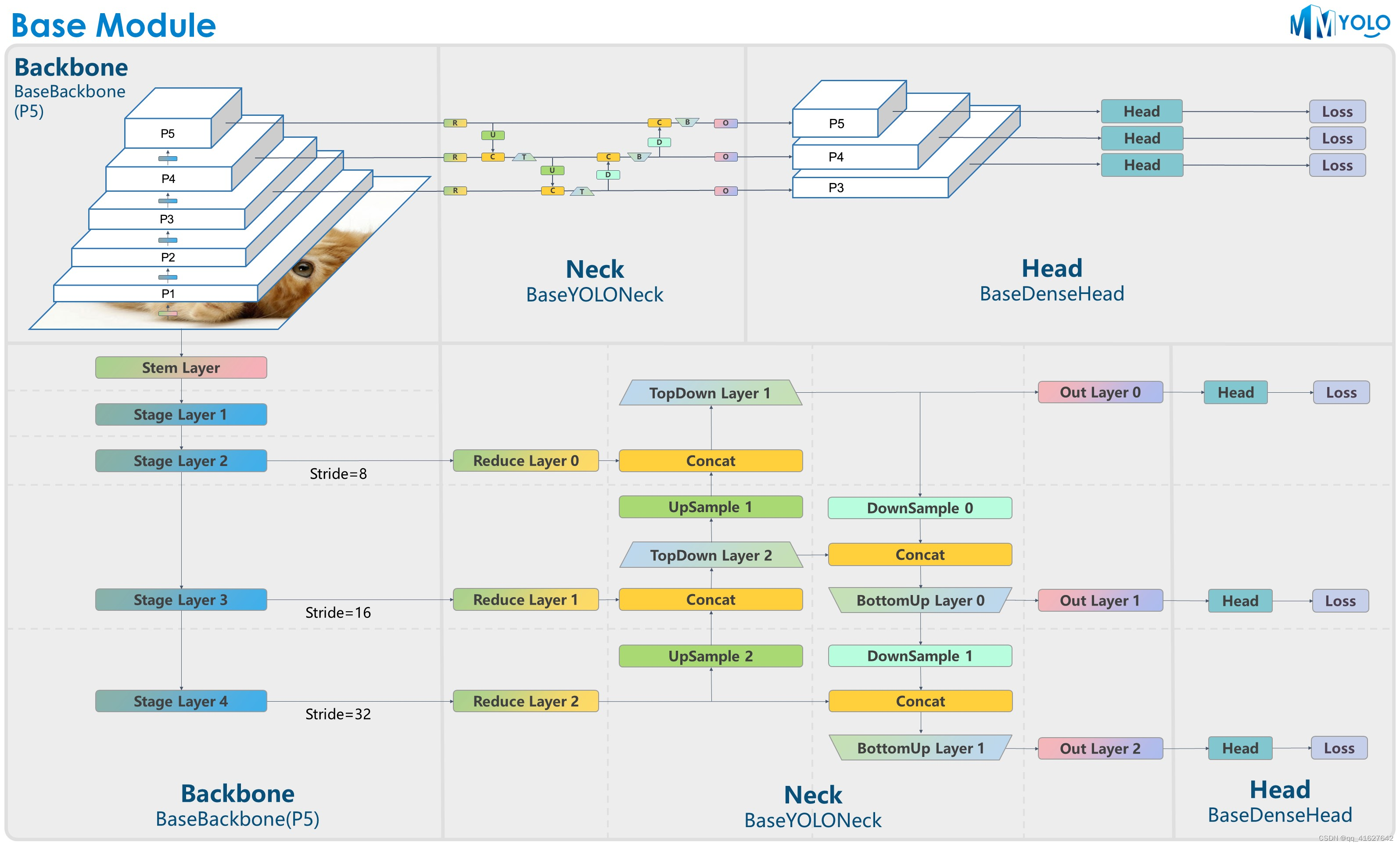
图1:P5模型结构
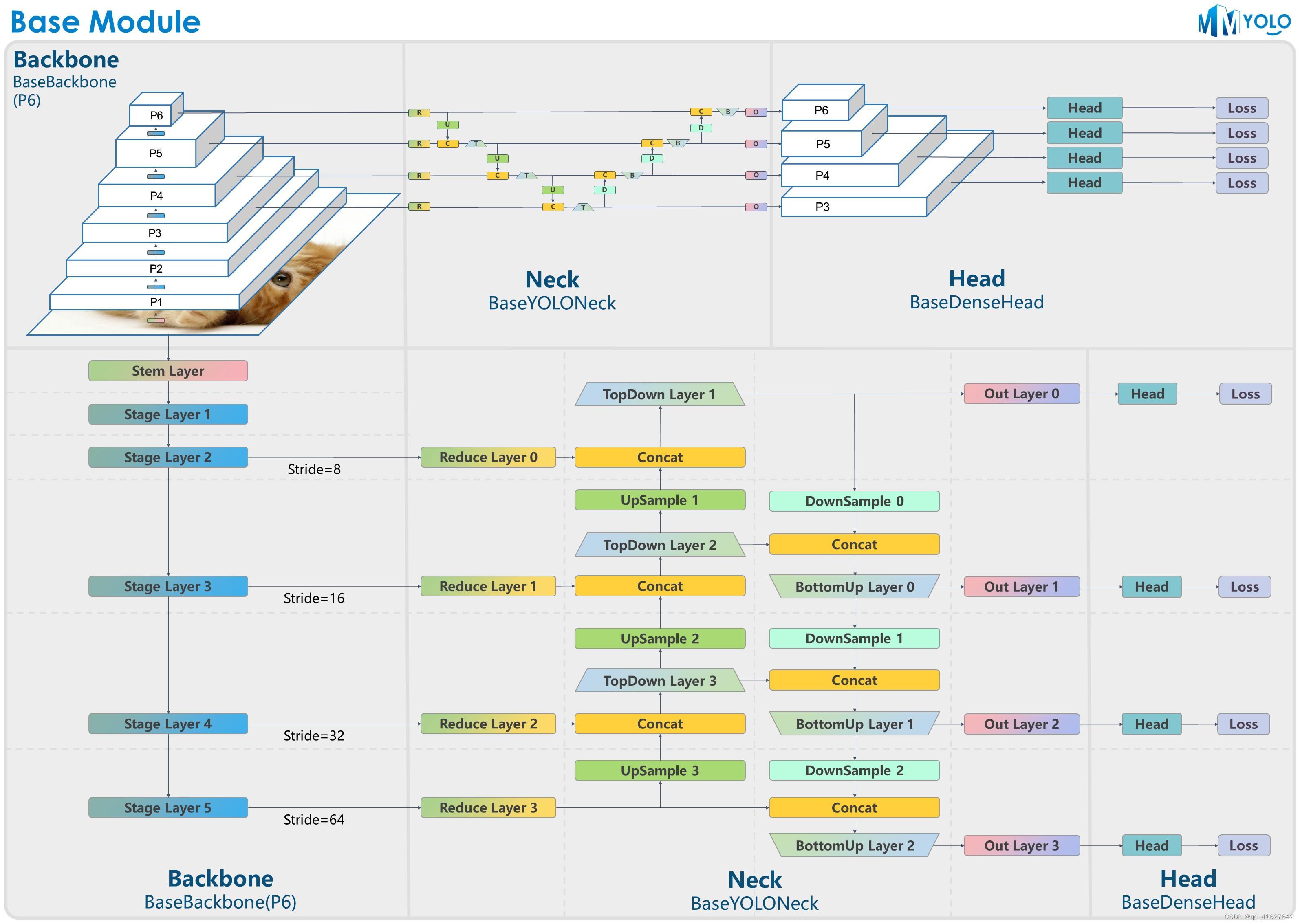
图2:P6模型结构
YOLO系列算法大多采用统一的算法构建结构,典型为Darknet + PAFPN。为了让用户快速了解YOLO系列算法架构,我们特意设计了BaseBackbone+BaseYOLONeck结构,如上图所示。
he benefits of the abstract BaseBackbone include:
子类不需要关心前向过程。只需将模型构建为构建器模式即可。
可以配置实现自定义插件功能。用户可以轻松插入一些类似的注意力模块。
所有子类自动支持冻结某些阶段和 bn 函数。
BaseYOLONeck具有与 相同的优点BaseBackbone。
1、基础骨干网
如图1所示,对于P5,BaseBackbone包括1个stem层和4个stage层,与ResNet的基本结构类似。
如图2所示,对于P6,BaseBackbone包括1个干层和5个阶段层。不同的骨干网络算法继承BaseBackbone. 用户可以通过内部方法实现定制的基础模块来构建整个网络的每一层build_xx。
2、BaseYOLONeck
我们以类似的方式重现YOLO系列Neck组件BaseBackbone,我们主要可以将它们分为Reduce layer, UpSample layer, TopDown layer, DownSample layer, BottomUP layer和output convolution layer。
每一层都可以通过方法的继承和重写来定制其内部构造。
3、BaseDenseHead
MMYOLO使用MMDetection中设计的BaseDenseHead作为Head结构的基类。以YOLOv5为例,其HeadModule的forward函数替代了原来的forward方法。
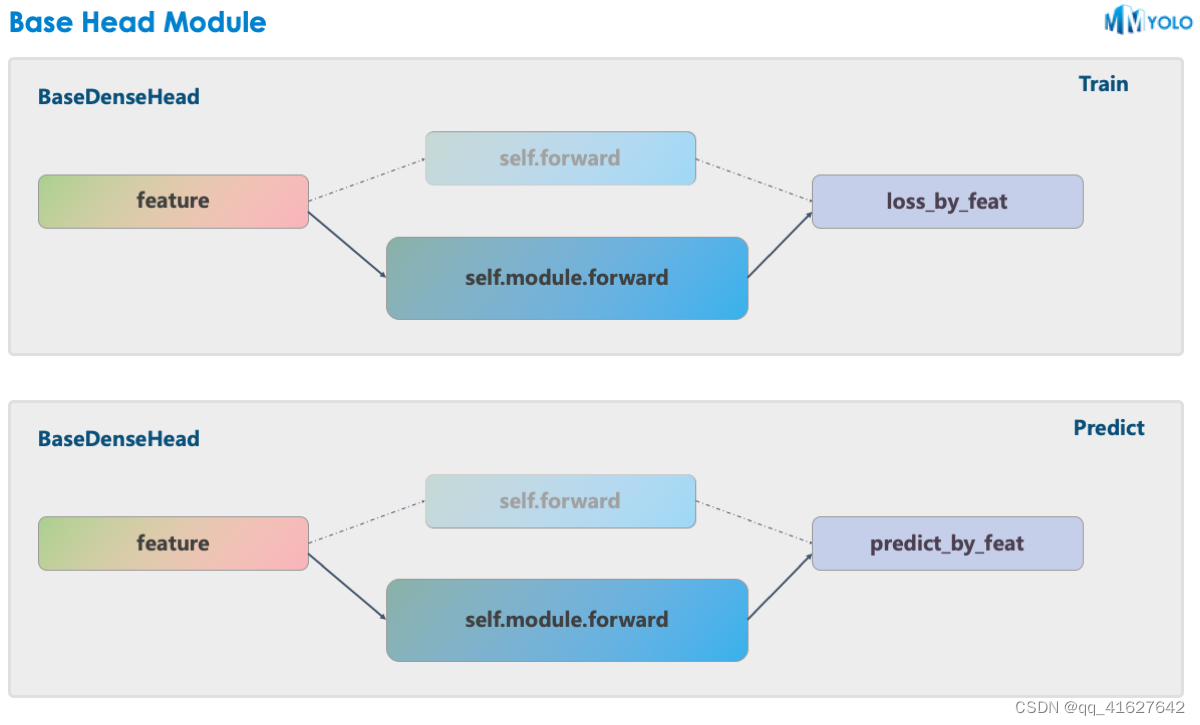
如上图所示,实线是MMYOLO中的实现,而MMDetection中的原始实现如虚线所示。MMYOLO 相对于原来的实现有以下优点:
在 MMDetection 中,bbox_head分为三个大组件:assigner + box coder + sampler 。但由于这三个组件之间的传递是通用的,所以需要封装额外的对象。通过 MMYOLO 的统一,用户无需将它们分开。不刻意强行划分三个组件的好处是:不再需要内部数据的数据封装,简化代码逻辑,降低社区使用和算法复现的难度
MMYOLO 更快。用户在定制实现算法时,可以不依赖原有框架,对部分代码进行深度优化。
In general, with the partly decoupled model + loss_by_feat part in MMYOLO, users can construct any model with any loss_by_feat by modifying the configuration. For example, applying the loss_by_feat of YOLOX to the YOLOv5 model, etc.
总的来说,MMYOLO中采用部分解耦的模型+部分的方式,用户可以通过修改配置来loss_by_feat构建任意模型。loss_by_feat例如将loss_by_featYOLOX的应用到YOLOv5模型等。
以MMDetection中YOLOX配置为例,Head模块配置写法如下:
bbox_head=dict(
type='YOLOXHead',
num_classes=80,
in_channels=128,
feat_channels=128,
stacked_convs=2,
strides=(8, 16, 32),
use_depthwise=False,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='Swish'),
...
loss_obj=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
reduction='sum',
loss_weight=1.0),
loss_l1=dict(type='L1Loss', reduction='sum', loss_weight=1.0)),
train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)),
对于MMYOLO中的head_module,新的配置写法如下:
bbox_head=dict(
type='YOLOXHead',
head_module=dict(
type='YOLOXHeadModule',
num_classes=80,
in_channels=256,
feat_channels=256,
widen_factor=widen_factor,
stacked_convs=2,
featmap_strides=(8, 16, 32),
use_depthwise=False,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True),
),
...
loss_obj=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='sum',
loss_weight=1.0),
loss_bbox_aux=dict(type='mmdet.L1Loss', reduction='sum', loss_weight=1.0)),
train_cfg=dict(
assigner=dict(
type='mmdet.SimOTAAssigner',
center_radius=2.5,
iou_calculator=dict(type='mmdet.BboxOverlaps2D'))),
7、更换骨干网
当使用其他骨干网络时,需要保证骨干网络的输出通道与颈网络的输入通道匹配。
下面给出的配置文件仅确保训练正常进行,其训练性能可能不是最佳的。因为某些主干网络需要特定的学习率、优化器和其他超参数。相关内容稍后会在“训练技巧”部分补充。
使用MMYOLO中实现的骨干网络
假设要作为YOLOv6EfficientRep的骨干网络YOLOv5,示例配置如下
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
model = dict(
backbone=dict(
type='YOLOv6EfficientRep',
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='ReLU', inplace=True))
)
使用在其他 OpenMMLab 存储库中实现的骨干网络
MMYOLO、MMDetection、MMClassification 和 MMSegmentation 中的模型注册表均继承自 OpenMMLab 2.0 系统中 MMEngine 中的根注册表,允许这些存储库直接使用彼此已实现的模块。因此,在MMYOLO中,用户可以使用MMDetection和MMClassification的骨干网络,而无需重新实现。
假设要作为ResNet-50的骨干网络YOLOv5,示例配置如下:
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
deepen_factor = _base_.deepen_factor
widen_factor = 1.0
channels = [512, 1024, 2048]
model = dict(
backbone=dict(
_delete_=True, # Delete the backbone field in _base_
type='mmdet.ResNet', # Using ResNet from mmdet
depth=50,
num_stages=4,
out_indices=(1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='YOLOv5PAFPN',
widen_factor=widen_factor,
in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
out_channels=channels),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
in_channels=channels, # input channels of head need to be changed accordingly
widen_factor=widen_factor))
)
假设要作为SwinTransformer-Tiny的骨干网络YOLOv5,示例配置如下:
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
deepen_factor = _base_.deepen_factor
widen_factor = 1.0
channels = [192, 384, 768]
checkpoint_file = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth' # noqa
model = dict(
backbone=dict(
_delete_=True, # Delete the backbone field in _base_
type='mmdet.SwinTransformer', # Using SwinTransformer from mmdet
embed_dims=96,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
mlp_ratio=4,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.2,
patch_norm=True,
out_indices=(1, 2, 3),
with_cp=False,
convert_weights=True,
init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
neck=dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=channels, # Note: The 3 channels of SwinTransformer-Tiny output are [192, 384, 768], which do not match the original yolov5-s neck and need to be changed.
out_channels=channels),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
in_channels=channels, # input channels of head need to be changed accordingly
widen_factor=widen_factor))
)
使用 MMClassification 中实现的骨干网络
假设要作为ConvNeXt-Tiny的骨干网络YOLOv5,示例配置如下
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
# import mmcls.models to trigger register_module in mmcls
custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth' # noqa
deepen_factor = _base_.deepen_factor
widen_factor = 1.0
channels = [192, 384, 768]
model = dict(
backbone=dict(
_delete_=True, # Delete the backbone field in _base_
type='mmcls.ConvNeXt', # Using ConvNeXt from mmcls
arch='tiny',
out_indices=(1, 2, 3),
drop_path_rate=0.4,
layer_scale_init_value=1.0,
gap_before_final_norm=False,
init_cfg=dict(
type='Pretrained', checkpoint=checkpoint_file,
prefix='backbone.')), # The pre-trained weights of backbone network in MMCls have prefix='backbone.'. The prefix in the keys will be removed so that these weights can be normally loaded.
neck=dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=channels, # Note: The 3 channels of ConvNeXt-Tiny output are [192, 384, 768], which do not match the original yolov5-s neck and need to be changed.
out_channels=channels),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
in_channels=channels, # input channels of head need to be changed accordingly
widen_factor=widen_factor))
)
假设要作为MobileNetV3-small的骨干网络YOLOv5,示例配置如下:
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
# import mmcls.models to trigger register_module in mmcls
custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth' # noqa
deepen_factor = _base_.deepen_factor
widen_factor = 1.0
channels = [24, 48, 96]
model = dict(
backbone=dict(
_delete_=True, # Delete the backbone field in _base_
type='mmcls.MobileNetV3', # Using MobileNetV3 from mmcls
arch='small',
out_indices=(3, 8, 11), # Modify out_indices
init_cfg=dict(
type='Pretrained',
checkpoint=checkpoint_file,
prefix='backbone.')), # The pre-trained weights of backbone network in MMCls have prefix='backbone.'. The prefix in the keys will be removed so that these weights can be normally loaded.
neck=dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=channels, # Note: The 3 channels of MobileNetV3 output are [24, 48, 96], which do not match the original yolov5-s neck and need to be changed.
out_channels=channels),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
in_channels=channels, # input channels of head need to be changed accordingly
widen_factor=widen_factor))
)
timm通过 MMClassification使用骨干网络
MMClassification还为Py Torch Image Models ( )骨干网络提供了包装器,用户可以通过MMClassificationtimm直接使用骨干网络timm。假设要作为EfficientNet-B1的骨干网络YOLOv5,示例配置如下:
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
# and the command, pip install timm, to install timm
# import mmcls.models to trigger register_module in mmcls
custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
deepen_factor = _base_.deepen_factor
widen_factor = 1.0
channels = [40, 112, 320]
model = dict(
backbone=dict(
_delete_=True, # Delete the backbone field in _base_
type='mmcls.TIMMBackbone', # Using timm from mmcls
model_name='efficientnet_b1', # Using efficientnet_b1 in timm
features_only=True,
pretrained=True,
out_indices=(2, 3, 4)),
neck=dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=channels, # Note: The 3 channels of EfficientNet-B1 output are [40, 112, 320], which do not match the original yolov5-s neck and need to be changed.
out_channels=channels),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
in_channels=channels, # input channels of head need to be changed accordingly
widen_factor=widen_factor))
)
使用MMSelfSup中实现的骨干网络
假设你想使用MMSelfSup中ResNet-50自监督训练的网络作为 的骨干网络,示例配置如下:MoCo v3YOLOv5
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
# please run the command, mim install "mmselfsup>=1.0.0rc3", to install mmselfsup
# import mmselfsup.models to trigger register_module in mmselfsup
custom_imports = dict(imports=['mmselfsup.models'], allow_failed_imports=False)
checkpoint_file = 'https://download.openmmlab.com/mmselfsup/1.x/mocov3/mocov3_resnet50_8xb512-amp-coslr-800e_in1k/mocov3_resnet50_8xb512-amp-coslr-800e_in1k_20220927-e043f51a.pth' # noqa
deepen_factor = _base_.deepen_factor
widen_factor = 1.0
channels = [512, 1024, 2048]
model = dict(
backbone=dict(
_delete_=True, # Delete the backbone field in _base_
type='mmselfsup.ResNet',
depth=50,
num_stages=4,
out_indices=(2, 3, 4), # Note: out_indices of ResNet in MMSelfSup are 1 larger than those in MMdet and MMCls
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
neck=dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
out_channels=channels),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
in_channels=channels, # input channels of head need to be changed accordingly
widen_factor=widen_factor))
)
不要使用预训练权重
当我们更换主干网络时,默认加载主干网络的预训练权重来训练模型初始化。如果您想从头开始训练时间模型,而不是使用主干网络的预训练权重,您可以将init_cfg“backbone”设置为“None”。在这种情况下,主干网络将使用默认的初始化方法进行初始化,而不是使用训练好的预训练权重。
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
deepen_factor = _base_.deepen_factor
widen_factor = 1.0
channels = [512, 1024, 2048]
model = dict(
backbone=dict(
_delete_=True, # Delete the backbone field in _base_
type='mmdet.ResNet', # Using ResNet from mmdet
depth=50,
num_stages=4,
out_indices=(1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=None # If init_cfg is set to None, backbone will not be initialized with pre-trained weights
),
neck=dict(
type='YOLOv5PAFPN',
widen_factor=widen_factor,
in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
out_channels=channels),
bbox_head=dict(
type='YOLOv5Head',
head_module=dict(
type='YOLOv5HeadModule',
in_channels=channels, # input channels of head need to be changed accordingly
widen_factor=widen_factor))
)
8、插件
MMYOLO 支持在 Backbone 的不同阶段添加 none_local and dropblock等插件。用户可以通过修改config中backbone的plugins参数来直接管理插件。例如,GeneralizedAttention为YOLOv5. 配置文件如下:
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
model = dict(
backbone=dict(
plugins=[
dict(
cfg=dict(
type='GeneralizedAttention',
spatial_range=-1,
num_heads=8,
attention_type='0011',
kv_stride=2),
stages=(False, False, True, True))
]))
cfg参数表示插件的具体配置。该stages参数表示是否在主干相应阶段之后添加插件。列表的长度stages必须与主干阶段的数量相同。

CBAM
GeneralizedAttention
NonLocal2d
ContextBlock
9、冻结图层
1、Freeze the weight of backbone
在MMYOLO中,我们可以通过设置frozen_stages参数来冻结一些主干网络stages,使这些stage参数不参与模型更新。需要注意的是,frozen_stages = i,这意味着从initial到thi的所有参数都将被冻结。下面是一个例子。其他算法也是同样的逻辑。
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
model = dict(
backbone=dict(
frozen_stages=1 # Indicates that the parameters in the first stage and all stages before it are frozen
))
2、Freeze the weight of neck
另外,还可以通过freeze_all参数来冻结在MMYOLO的整体neck。下面是一个例子YOLOv5。其他算法也是同样的逻辑。
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
model = dict(
neck=dict(
freeze_all=True # If freeze_all=True, all parameters of the neck will be frozen
))
10、设置随机种子
如果你想在训练过程中设置随机种子,可以使用以下命令
python ./tools/train.py \
${CONFIG} \ # path of the config file
--cfg-options randomness.seed=2023 \ # set seed to 2023
[randomness.diff_rank_seed=True] \ # set different seeds according to global rank
[randomness.deterministic=True] # set the deterministic option for CUDNN backend
# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
randomness可设置三个参数,含义如下。
randomness.seed=2023,将随机种子设置为 2023。
randomness.diff_rank_seed=True,根据global rank设置不同的种子。默认为 False。
randomness.deterministic=True,set the deterministic option for cuDNN backend,即设置torch.backends.cudnn.deterministic为 True 和torch.backends.cudnn.benchmarkFalse。默认为 False。有关更多详细信息,请参阅 https://pytorch.org/docs/stable/notes/randomness.html。
11、应用multiple necks
如果要堆叠multiple Necks,可以直接在config中设置Neck参数。MMYOLO 支持以List形式组合multiple Necks。您需要确保前一个 Neck 的输出通道与下一个 Neck 的输入通道匹配。如果需要调整通道数,可以插入模块mmdet.ChannelMapper来对齐多个Neck之间的通道数。具体配置如下:
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
deepen_factor = _base_.deepen_factor
widen_factor = _base_.widen_factor
model = dict(
type='YOLODetector',
neck=[
dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=[256, 512, 1024],
out_channels=[256, 512, 1024], # The out_channels is controlled by widen_factor,so the YOLOv5PAFPN's out_channels equls to out_channels * widen_factor
num_csp_blocks=3,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True)),
dict(
type='mmdet.ChannelMapper',
in_channels=[128, 256, 512],
out_channels=128,
),
dict(
type='mmdet.DyHead',
in_channels=128,
out_channels=256,
num_blocks=2,
# disable zero_init_offset to follow official implementation
zero_init_offset=False)
]
bbox_head=dict(head_module=dict(in_channels=[512,512,512])) # The out_channels is controlled by widen_factor,so the YOLOv5HeadModuled in_channels * widen_factor equals to the last neck's out_channels
)
12、在训练或推理期间指定特定的 GPU
如果您有多个 GPU,例如 8 个 GPU,编号为,则默认使用 GPU 0 进行训练或推理。如果您想指定其他GPU进行训练或推理,可以使用以下命令:0, 1, 2, 3, 4, 5, 6, 7
CUDA_VISIBLE_DEVICES=5 python ./tools/train.py ${CONFIG} #train
CUDA_VISIBLE_DEVICES=5 python ./tools/test.py ${CONFIG} ${CHECKPOINT_FILE} #test
如果设置CUDA_VISIBLE_DEVICES为-1或大于最大GPU数量的数字,例如8,则CPU将用于训练或推理。
如果您想使用其中几个 GPU 并行训练,可以使用以下命令:
CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/dist_train.sh ${CONFIG} ${GPU_NUM}
这里GPU_NUM是4。另外,如果在一台机器上并行训练多个任务,并且每个任务需要多个GPU,则每个任务的PORT需要设置不同,以避免通信冲突,例如以下命令:
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG} 4
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG} 4