前言
🏠个人主页:泡泡牛奶
🌵系列专栏:[C语言] 数据结构奋斗100天
本期所介绍的是栈和队列,那么什么是栈呢,什么是队列呢?在知道答案之前,请大家思考一下下列问题:
- 你如何理解物理结构和逻辑结构?
- 栈的规则是什么?
- 栈和队列最重要的基本操作有哪些?
- 什么是循环队列?
让我们带着这些问题,开始今天的学习吧( •̀ ω •́ )✧
文章目录
- 前言
- 一、物理结构?逻辑结构?
- 二、栈 (stack)
- 1. 什么是栈?
- 2. 栈类型的定义
- 1) 用链表来实现
- 2) 用数组来实现
- 3. 栈的基本操作
- 1) 栈的初始化
- 2) 栈的销毁
- 3) 判断栈是否为空
- 4) 栈的元素个数
- 5) 取栈顶元素
- 6) 压栈✨
- 7) 出栈✨
- 三、队列 (queue)
- 1. 什么是队列?
- 2. 队列类型的定义
- 1) 用链表来实现
- 2) 用数组来实现
- 3. 队列的基本操作
- 1) 队列的初始化
- 2) 队列的销毁
- 3) 判断队列是否为空
- 4) 队列的元素个数
- 5) 取队首元素
- 6) 取队尾元素
- 7) 入队✨
- 8) 出队✨
- 4. 循环队列
- 四、小结
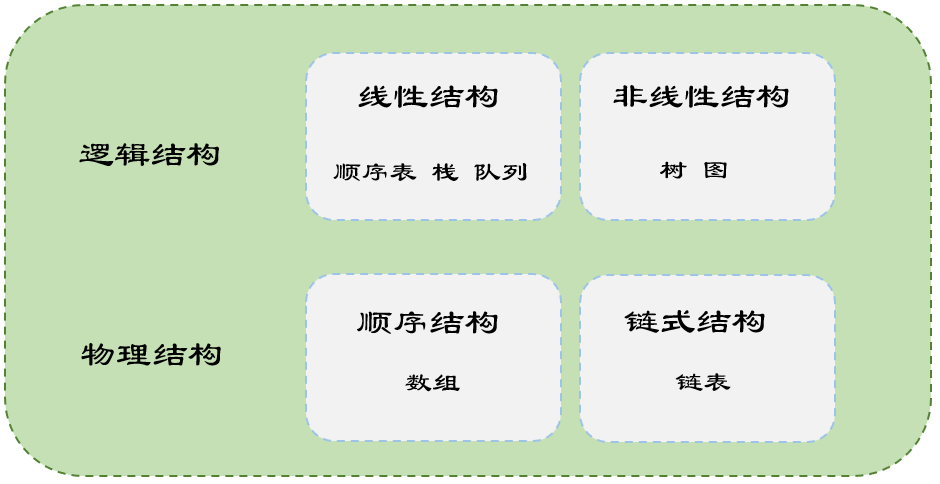
一、物理结构?逻辑结构?
物理结构是指的是数据在计算机内存中的存储方式。数组是在内存中连续存放,链表则是通过指针将各个节点的地址串连起来。前者随机访问速度快,后者插入删除效率高。
**逻辑结构指的是数据 在一定逻辑规则下限制 的组织方式。**逻辑结构往往需要通过物理结构加以规则限制来实现想要的功能。所以你也可以说逻辑结构是为了满足人的需求的一种结构。就例如我接下说的栈和队列。
总的来说,数据结构中的物理结构关注的是数据在计算机内存中的存储方式,而逻辑结构关注的是数据在逻辑上的组织方式。在使用数据结构时,通常需要考虑这两个方面,以便确定最合适的数据结构。
二、栈 (stack)
1. 什么是栈?
要想了解什么是栈,我们可以用一个简单的例子。假设我们有一个羽毛球筒,一端封口,另一端开口。现在要往羽毛球筒里装羽毛球,先放入的靠近底部,后放入的靠近入口。

现在我们将球装入球筒后,想将最里面的球拿出来,那么只能先将最靠近入口的球先拿出来。先放进去的后取出来,后放进去的先取出来。

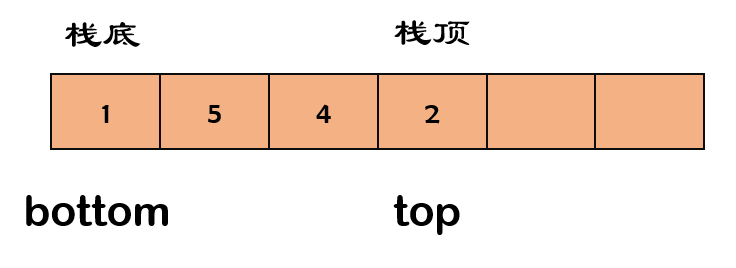
栈(stack)就像这个羽毛球筒,是一种特殊的线性表,满足一种先进后出(First In Last Out,简称FILO)限制规则。最早进入的元素存放在栈底(bottom),最后进入的元素在栈顶(top)。
知道了限制规则,我们可以用数组或者链表这些物理结构来实现。
栈若要用数组实现。只要压入的元素等于数组的容量,就要考虑扩容。
栈若要用链表来实现。压栈的操作可以想象成头插,出栈的操作可以想象成头删,只要注意 没有元素时的处理就好了。
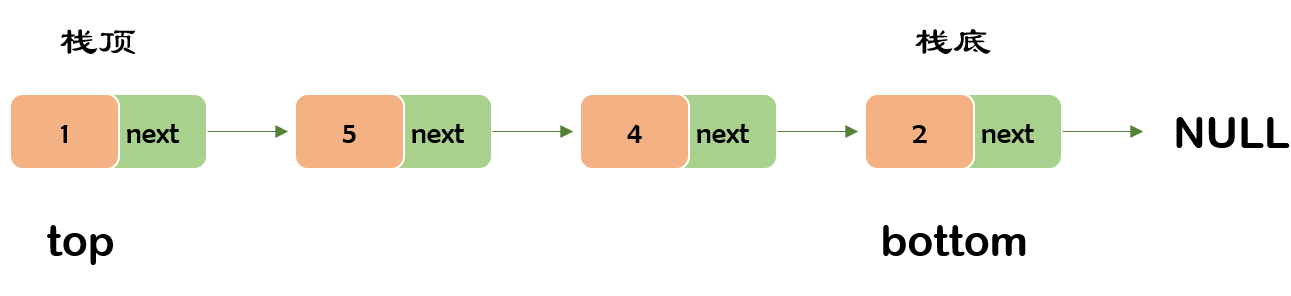
2. 栈类型的定义
1) 用链表来实现
typedef int StackType;//定义元素类型,方便后续修改
typedef struct StackValue
{
StackType value;
struct StackValue* next;//指向下一个节点的地址
}StackValue;
typedef struct Stack
{
size_t size;//方便确定栈的大小
StackValue* top;//方便找到头节点
}Stack;
在接下来的内容中,不会有具体的代码展现,但是会提供用链表实现的思路(还是希望大家在学数据结构时能开阔自己的思维φ(゜▽゜*)♪
这样的写法只是给大家一个参考,如果在你看完本篇博客后有兴趣想用链表来实现栈,那么可以尝试一下( •̀ ω •́ )✧,不要只局限于一种物理结构上。
2) 用数组来实现
选用数组的原因:
- 尾插尾删效率很高,不用重复像内存申请空间再释放空间
- CPU高速缓存命中率更高。CPU在扫描时会按照一定大小(三级缓存)扫描缓存,因为数组是一块连续的空间,扫描时更容易一次性扫描完
typedef int StackType;//定义元素类型,方便后续修改
typedef struct Stack
{
StackType* arr;
size_t top;
size_t capacity;
}Stack;
3. 栈的基本操作
1) 栈的初始化
从写代码接口的角度来看,任何简单的工作最好通过一个接口式函数来实现,因为使用者并不知道你的底层是如何实现的(万一使用的是链表来实现呢(o゚v゚)ノ
- 以数组为例,代码实现如下:
void stack_init(Stack* pst)
{
assert(pst);
pst->arr = NULL;
pst->top = pst->capacity = 0;
}
2) 栈的销毁
为了防止内存的泄露,结束使用需要对栈进行销毁。
void stack_distory(Stack* pst)
{
assert(pst);
free(pst->arr);
pst->arr = NULL;
pst->capacity = pst->top = 0;
}
3) 判断栈是否为空
数组实现判断是否为空,只要看top是否为0。链表实现需要看top指向的地址是否为NULL
bool stack_empty(const Stack* pst)
{
assert(pst);
return pst->top == 0;
}
4) 栈的元素个数
我们设计的栈top表示的数组的下标,所以取元素个数的时候,需要+1
有些封装top直接表示元素个数,所以这就是封装的好处,随意暴露底层,底层的结构容易被破坏,使用者并不需要知道底层是什么(这里提一下,有些栈实现下标是从-1开始的,也许你会在某些地方看到,不要觉得奇怪(*^-^*)
size_t stack_size(const Stack* pst)
{
assert(pst);
return pst->top+1;
}
5) 取栈顶元素
因为我们设计的栈 top 表示的最后一个元素的数组下标,所以可以直接返回 arr[top]
StackType stack_top(const Stack* pst)
{
assert(pst);
return pst->arr[pst->top];
}
6) 压栈✨
栈的插入操作被叫做压栈/进栈/入栈(
push),压入的数据在栈顶。
- 以数组为例子:注意如果数组满了,要考虑开新空间
 代码实现如下:
代码实现如下:
void stack_push(Stack* pst, StackType data)
{
//断言指针有效性
assert(pst);
if (pst->top == pst->capacity)
{
//扩容
size_t newcapacity = pst->capacity==0 ? 4 : 2*pst->capacity;
StackType* tmp = (StackType*)realloc(pst->arr, newcapacity*sizeof(StackType));
//检查扩容后指针的有效性
if (tmp == NULL)
{
perror("push realloc fail");
exit(-1);
}
pst->arr = tmp;
pst->capacity = newcapacity;
}
pst->arr[pst->top] = data;
++pst->top;
}
- 以链表为例:链表头插之后更新top指向的头节点就好了
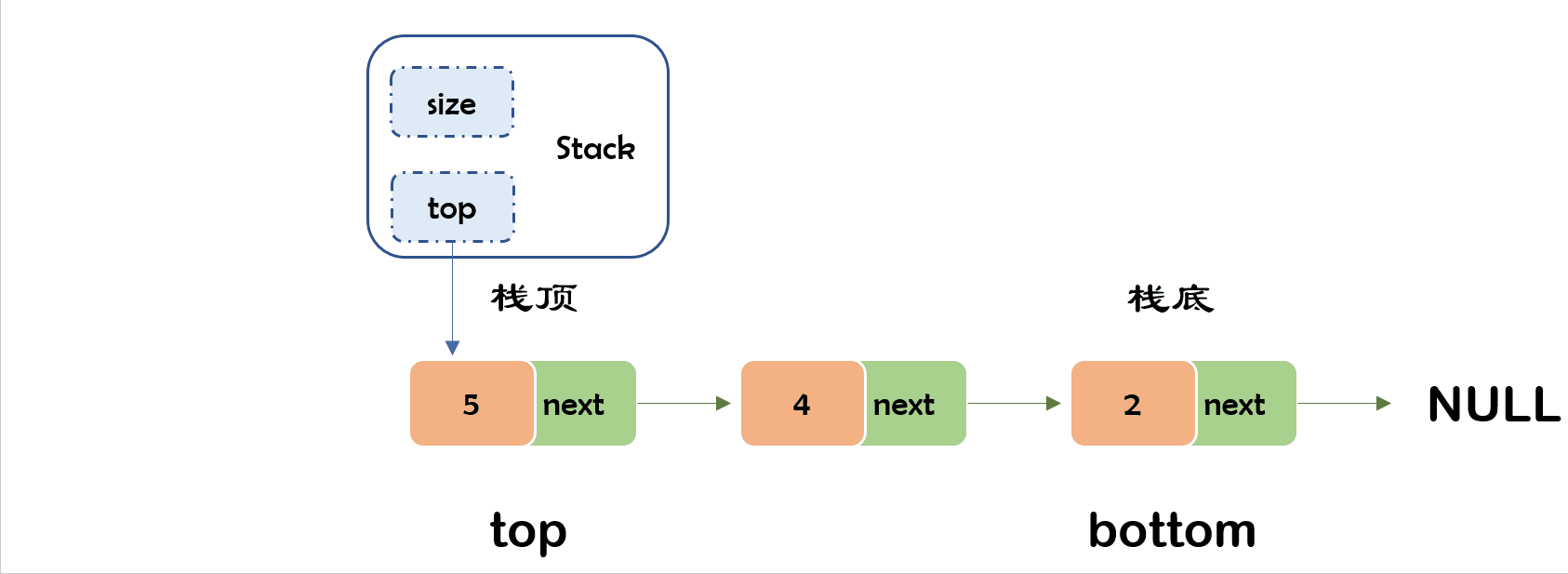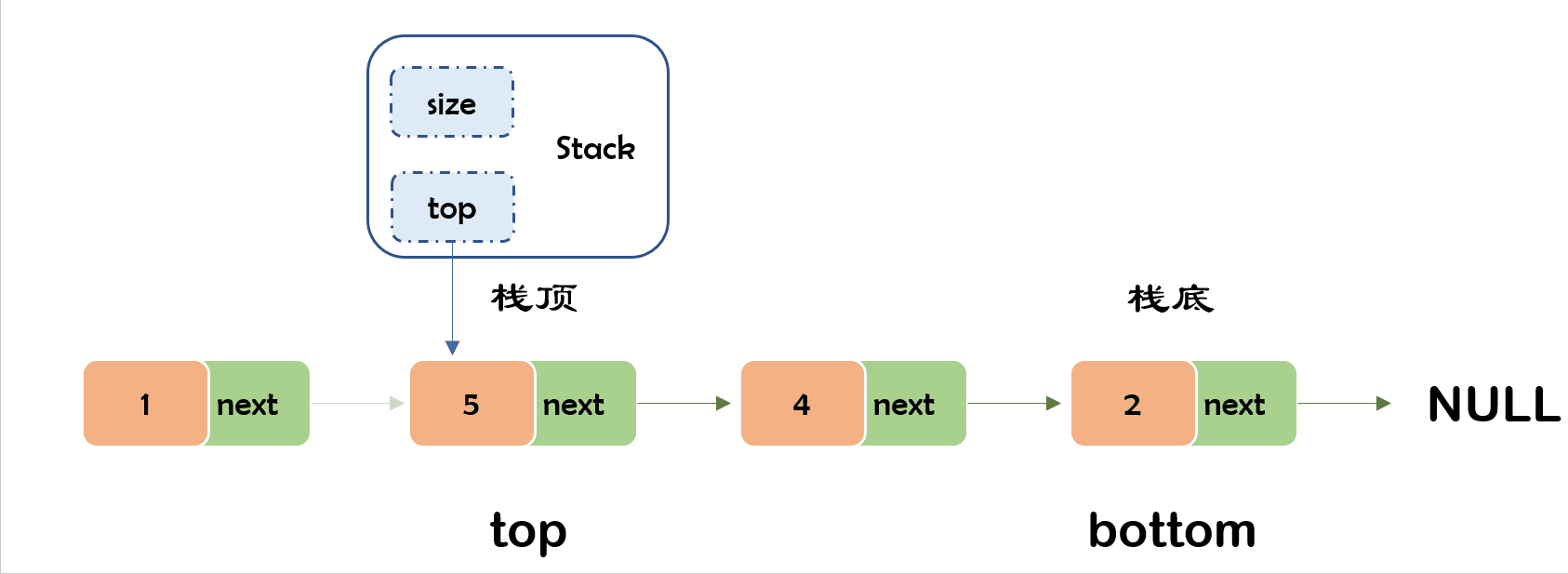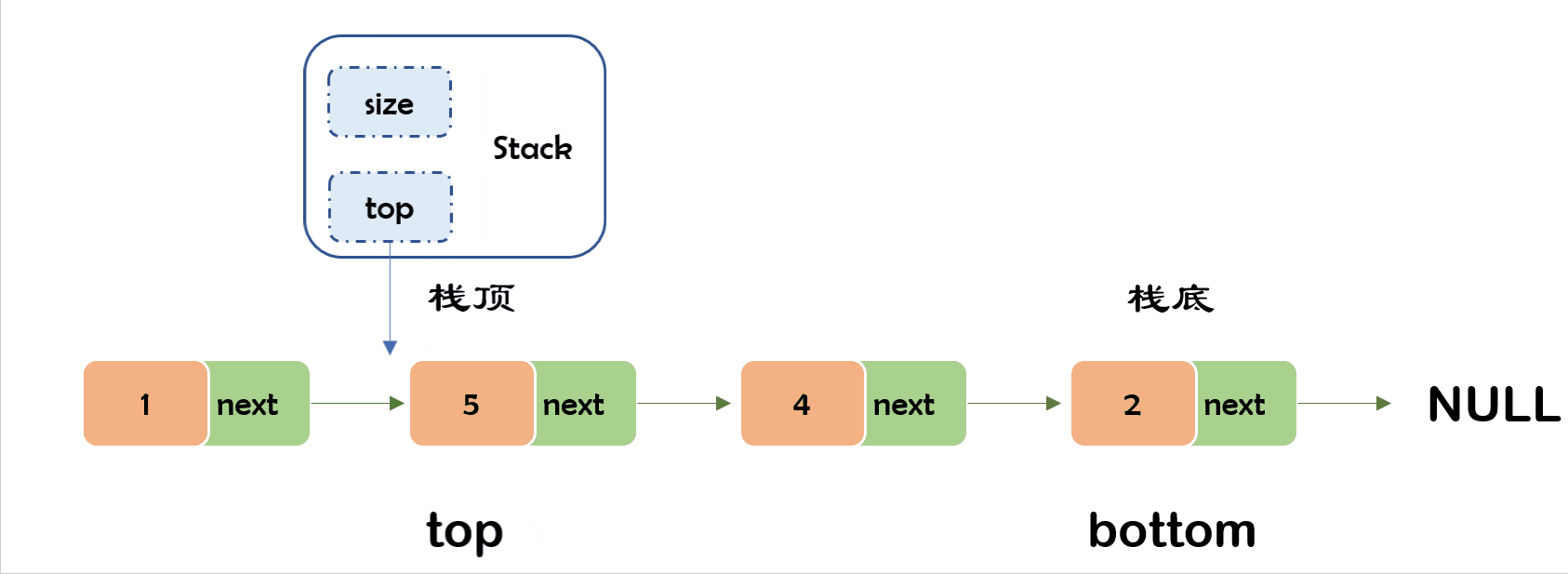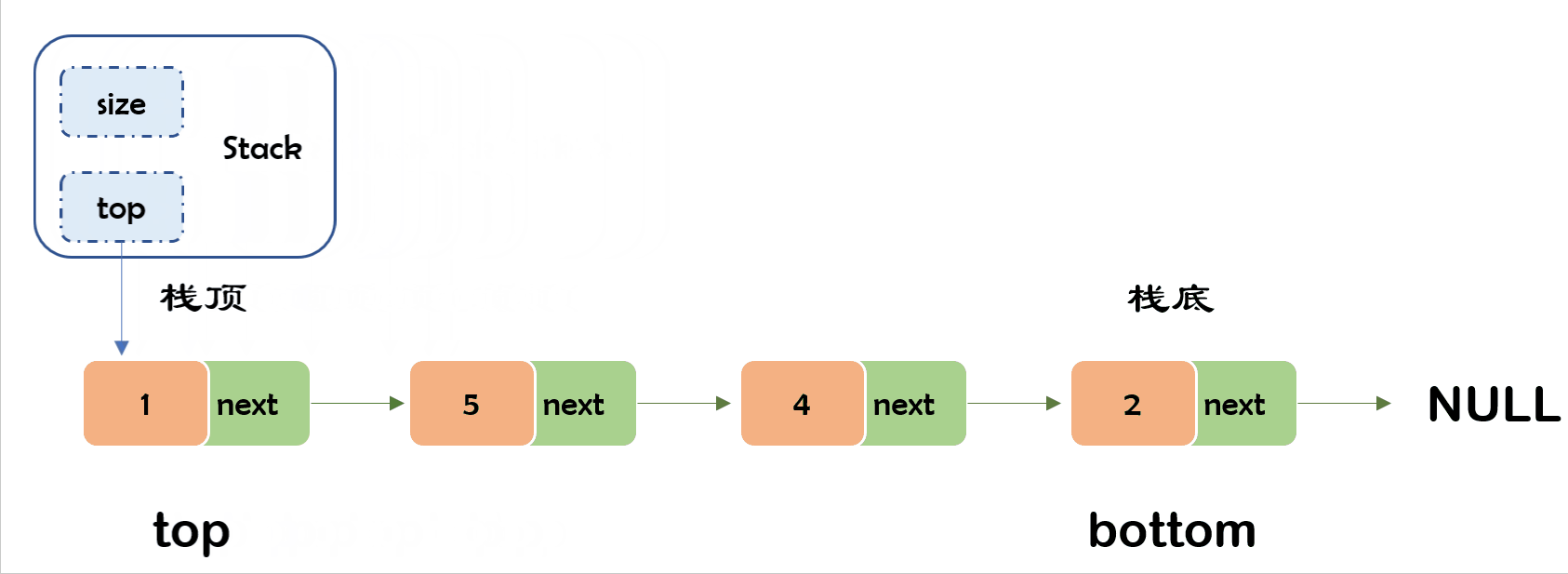
7) 出栈✨
栈元素的删除被叫做出栈(
pop)。出栈就是要将栈顶的元素弹出,只有栈顶元素才允许出栈。
- 以数组为例:数组不考虑缩容的操作,缩容代表你要重新申请空间,并将原来的数据拷贝回去,大大降低了效率。
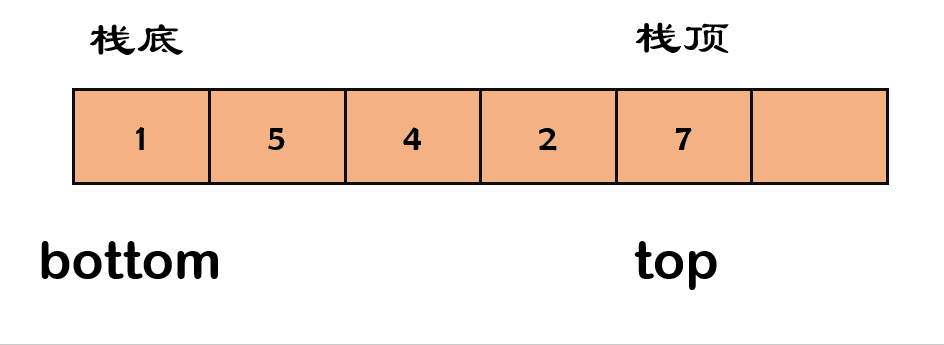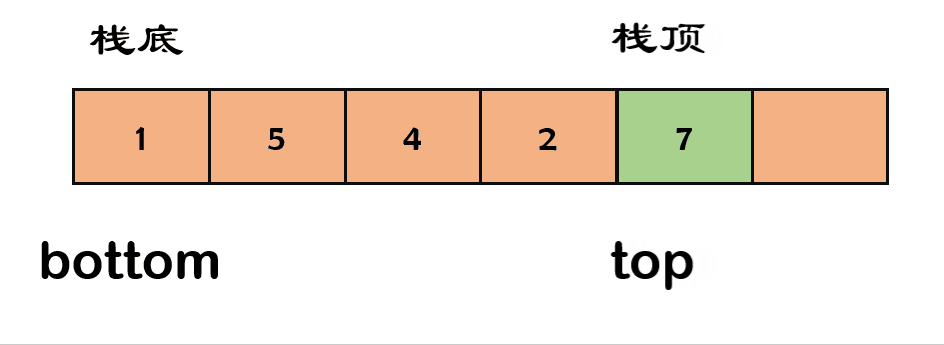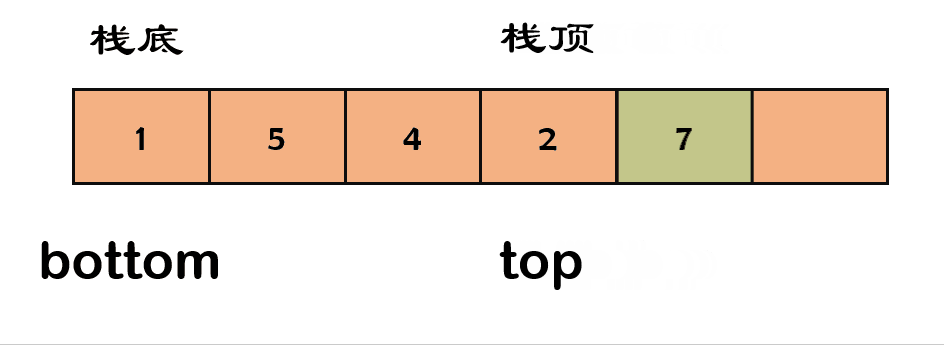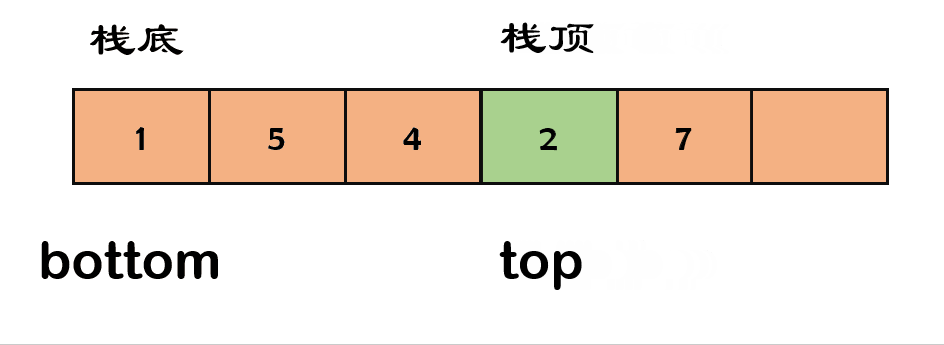
代码实现如下:
void stack_pop(Stack* pst)
{
assert(pst);
//判断栈不为空,这个函数下面会实现 pst->top == 0
assert(!stack_empty(pst));
--pst->top;
}
- 以链表为例:将头节点删掉之后,更新top的节点(要注意当top指向为NULL时,说明已经栈为空的,不能继续删除。

三、队列 (queue)
1. 什么是队列?
要知道什么时队列,我们同样可以用一个生活中的例子。假设有一排人排队打饭,食堂阿姨需要给这一排人打饭,不允许插队,那么新来的同学想打饭,只能排在队伍的后面。
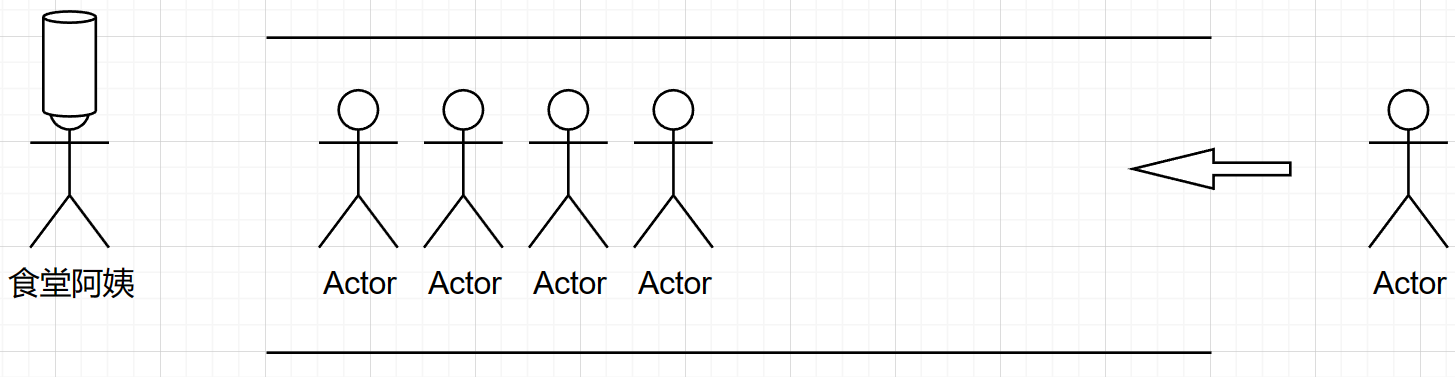
食堂阿姨给最前面的人打完饭之后,最前面的人就可以离开队伍。
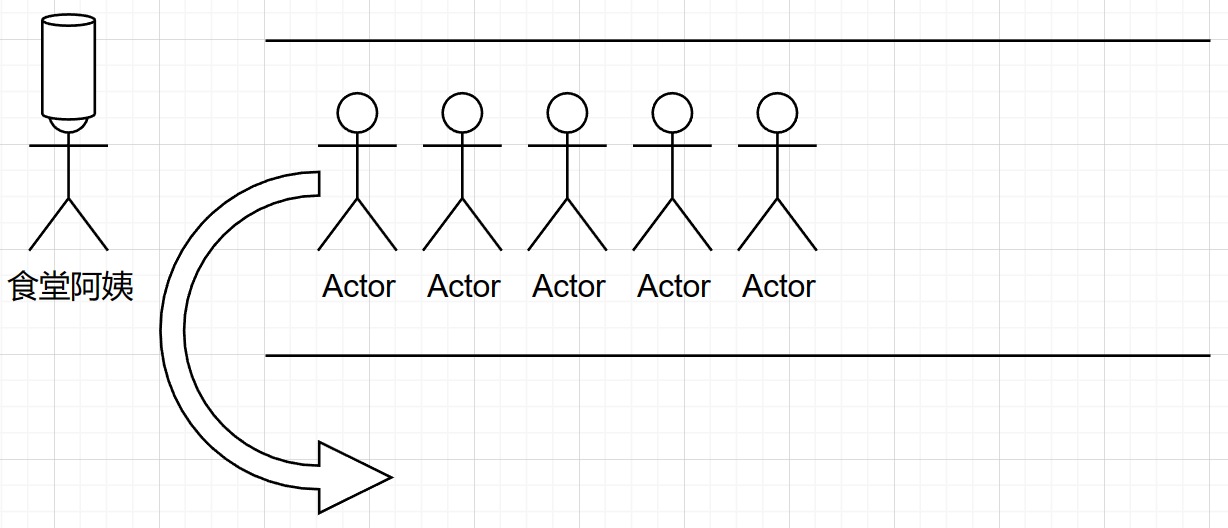
而队列就是这么一个道理,是一种特殊的线性表,队列的元素只能先进先出 ( First In First Out , 简称 FIFO )。队列的出口叫 队头( front ) ,队列的出口叫 队尾 (rear)
与栈类似,队列既可以用数组实现,也可以用链表来实现。但用数组实现时,为了入队操作方便,需要将队尾的位置规定为最后入队元素的下一个位置。
队列的链表实现如下。

2. 队列类型的定义
1) 用链表来实现
选用链表的原因:
- 插入数据操作方便
- 空间按需申请,节省空间,避免不必要的空间浪费
typedef int QueueType;
typedef struct QueueNode
{
QueueType value;
struct QueueNode* next;
}QueueNode;
typedef struct Queue
{
QueueNode* front;
QueueNode* rear;
size_t size;
}Queue;
2) 用数组来实现
想要用数组来实现,当我们有多个元素时,要进行出队操作,可以移动front达到头删的操作,但假设元素有很多,那势必会造成不必要的空间浪费,在实际开发中不推荐使用(但在用C语言刷题的时候经常会用到
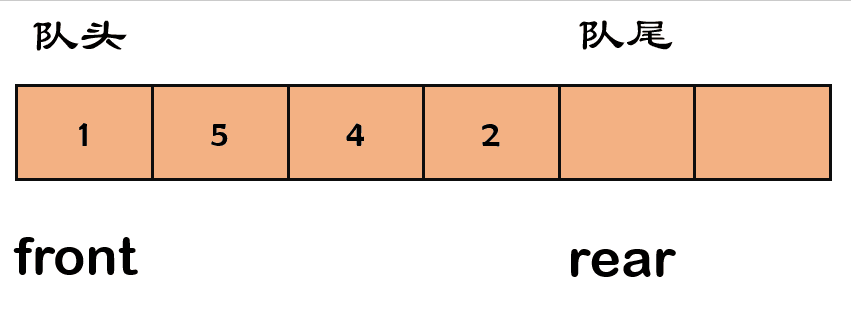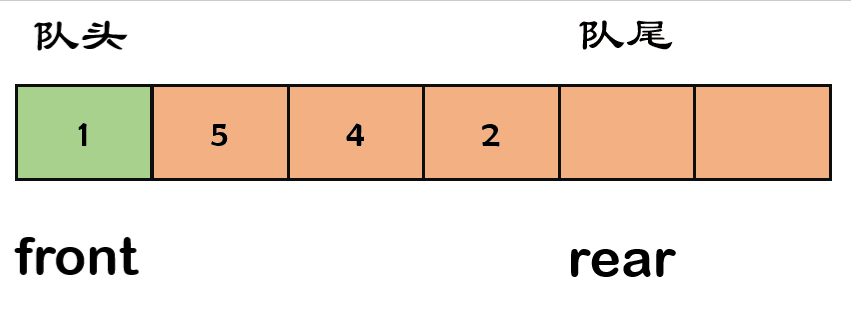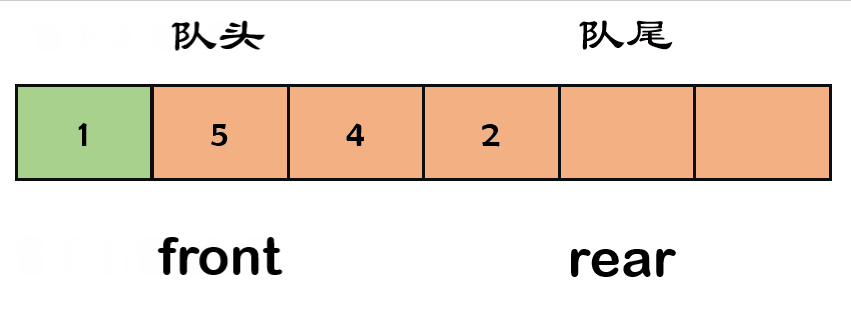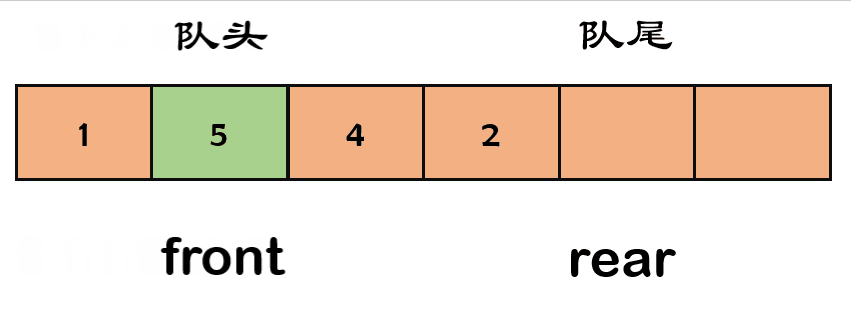
3. 队列的基本操作
1) 队列的初始化
void queue_init(Queue* pque)
{
assert(pque);
pque->front = pque->rear = NULL;
pque->size = 0;
}
2) 队列的销毁
用链表来实现队列,当销毁链表的时候,需要将链表的每一个节点都删除(防止内存泄漏
void queue_destory(Queue* pque)
{
assert(pque);
QueueNode* cur = pque->front;
while (cur != NULL)
{
QueueNode* del = cur;
cur = cur->next;
free(del);
}
pque->front = pque->rear = NULL;
3) 判断队列是否为空
代码如下:
void queue_empty(const Queue* pque)
{
assert(pque);
return ((pque->front == NULL) && (pque->rear == NULL));
}
4) 队列的元素个数
代码如下:
void queue_size(const Queue* pque)
{
assert(pque);
return pque->size;
}
5) 取队首元素
代码如下:
QueueType queue_front(const Queue* pque)
{
assert(pque);
//判断队列不为空
assert(!queue_empty(pque));
return pque->front->value;
}
6) 取队尾元素
代码如下:
QueueType queue_back(const Queue* pque)
{
assert(pque);
//判断队列不为空
assert(!queue_empty(pque));
return pque->rear->value;
}
7) 入队✨
入队就是将新的元素放入队列中,只允许在队尾的位置放入元素,新元素会成为新的队尾。

要注意,当队列为空的时候(front 和 rear 都为 NULL),rear无法指向下一个节点,所以要进行特殊处理。

代码实现如下:
void queue_push(Queue* pque, QueueType value)
{
assert(pque);
//创建新节点
QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));
if (newnode == NULL)
{
perror("push malloc error");
exit(-1);
}
//给新节点赋值
newnode->value = value;
newnode->next = NULL;
//特殊处理,若队列为空
if (queue_empty(pque))
{
//让队头和队尾 等于 新节点
pque->front = pque->rear = newnode;
}
else
{
pque->rear->next = newnode;
pque->rear = newnode;
}
++pque->size;
}
8) 出队✨
出队操作就是把元素移出队列,只允许在队头一侧移出元素,出队的后一个元素会成为新的队头。
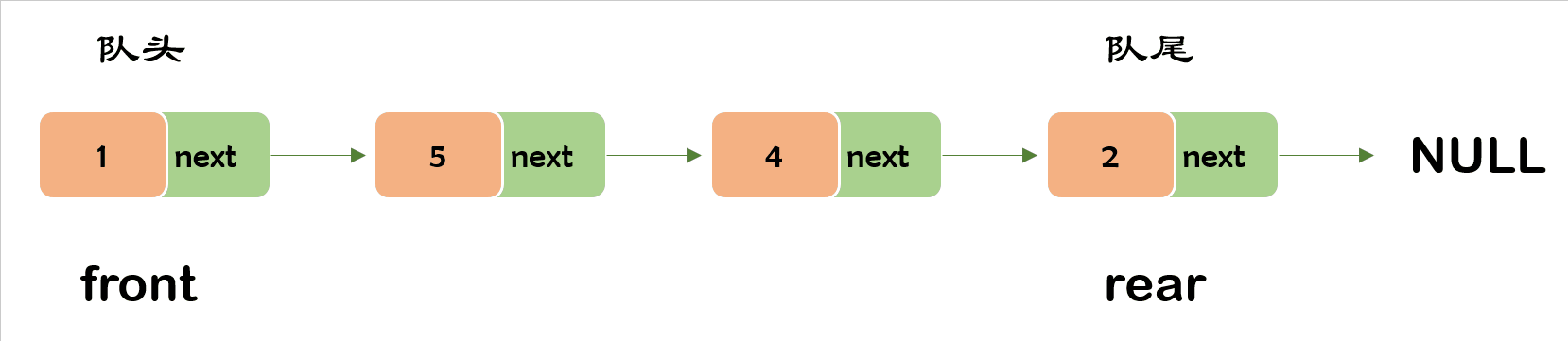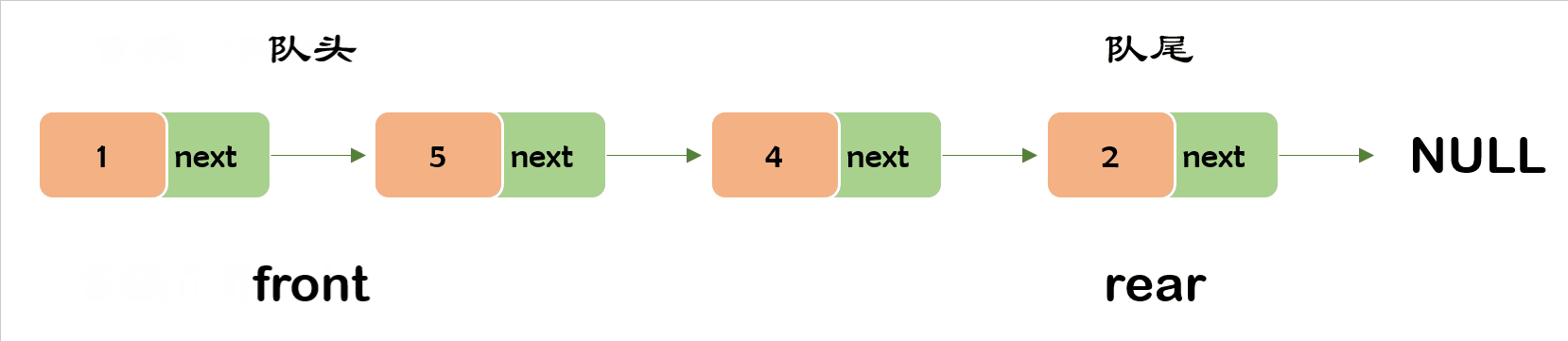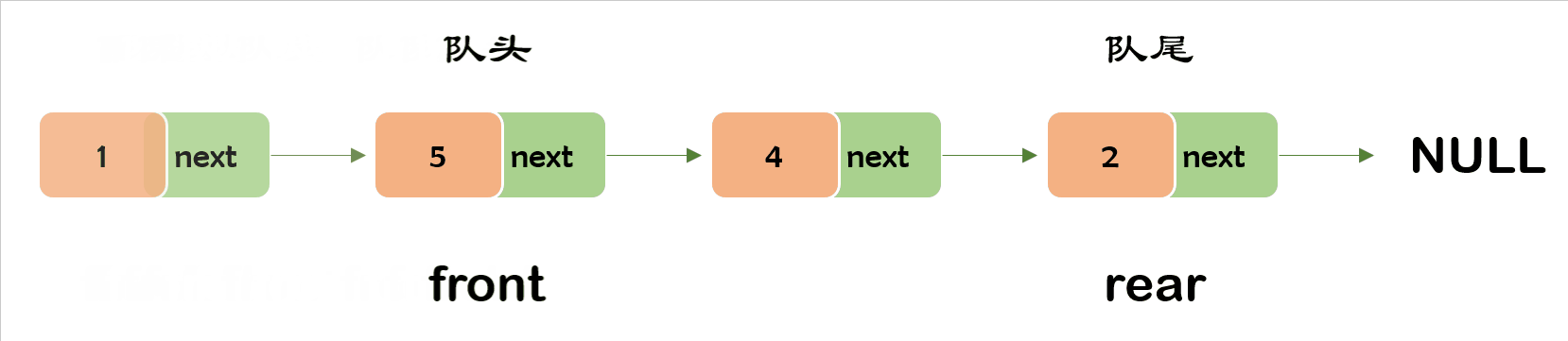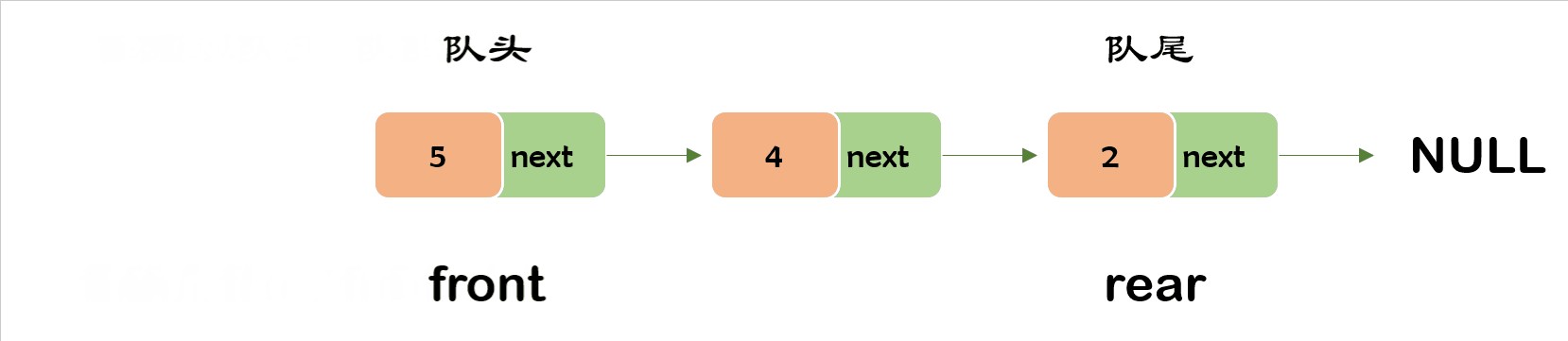
要注意,当队列只有一个元素的时候,队头和队尾是一个位置,需要把两个都置为NULL才行。

代码实现如下:
void queue_pop(Queue* pque)
{
assert(pque);
assert(!queue_empty(pque));
//特殊处理,只有一个元素的时候,删除节点并将头尾置空
if (pque->front->next == NULL)
{
free(pque->front);
pque->front = pque->rear = NULL;
}
else
{
QueueNode* del = pque->front;
pque->front = pque->front->next;
free(del);
del = NULL;
}
--pque->size;
}
4. 循环队列
循环队列指的是头尾相接的一种队列。
若考虑用数组实现想要实现头尾相接的效果,可以考虑取模操作
%,那么这样一来,数组的大小一定是固定的大小,假设循环队列长度为N,那么有效长度就为(front - rear + N) % N其中front和rear都表示数组的下标。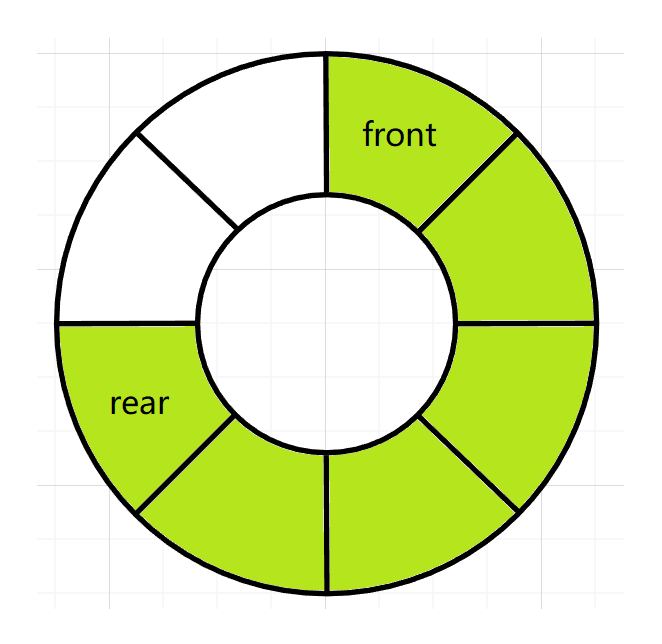
若考虑用链表来实现,可以考虑使用单向循环链表,但相对的效率会有所降低,得到的是无固定大小,有效长度就是链表节点的个数。
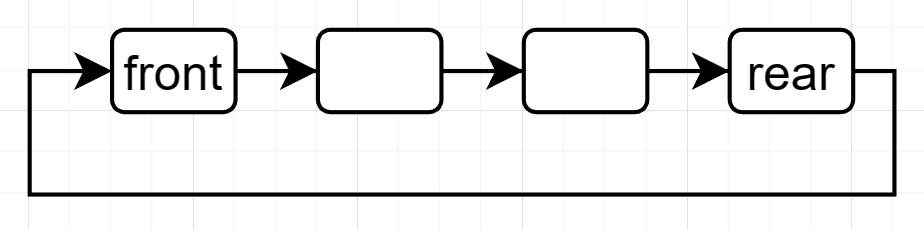
四、小结
- 什么是栈
栈是一种线性逻辑结构,可以用数组实现,也可以用链表实现。栈包括压栈和出栈的操作,遵循先进后出的原则(FILO)
- 什么是队列
队列是一种线性逻辑结构,可以用数组实现,也可以用链表实现。队列包括入队和出队操作,遵循先进先出的原则(FIFO)。队列一种特殊的形式,叫循环队列,循环队列在队列的基础上遵循着头尾相接的原则。
如果这篇博客对你有帮助的话,还不忘给一个大大的三连支持博主,你的关注的是我最大的动力😚😚😚,我们下期再见。