文章目录
- 1 TopicDeletionManager: Topic是怎么被删除的?
- 1.1 课前导读
- 1.2 TopicDeletionManager 概览
- 1.3 DeletionClient 接口及其实现
- 1.4 TopicDeletionManager 定义及初始化
- 1.5 TopicDeletionManager 重要方法
- 1.6 总结
- 2 ReplicaStateMachine:揭秘副本状态机实现原理
- 2.1 课前导读
- 2.2 定义与初始化
- 2.3 副本状态及状态管理流程
- 2.4 具体实现类:ZkReplicaStateMachine
- (1)状态转换方法定义
- (2)handleStateChanges 方法
- (3)doHandleStateChanges 方法
- (4)第1路:转换到 NewReplica 状态
- (5)第 2 路:转换到 OnlineReplica 状态
- (6)第 3 路:转换到 OfflineReplica 状态
- 2.5 总结
- 3 PartitionStateMachine:分区状态转换如何实现?
- 3.1 PartitionStateMachine 简介
- 3.2 类定义与字段
- 3.2 分区状态
- 3.3 分区 Leader 选举的场景及方法
- 3.3.1 PartitionLeaderElectionStrategy
- 3.3.2 PartitionLeaderElectionAlgorithms
- 3.4 处理分区状态转换的方法
- 3.4.1 handleStateChanges
- 3.4.2 doHandleStateChanges
- 3.5 总结
1 TopicDeletionManager: Topic是怎么被删除的?
今天,我们正式进入到第四大模块“状态机”的学习。
Kafka 源码中有很多状态机和管理器,比如之前我们学过的 Controller 通道管理器 ControllerChannelManager、处理 Controller 事件的 ControllerEventManager,等等。这些管理器和状态机,大多与各自的“宿主”组件关系密切,可以说是大小不同、功能各异。就比如 Controller 的这两个管理器,必须要与 Controller 组件紧耦合在一起才能实现各自的功能。
不过,Kafka 中还是有一些状态机和管理器具有相对独立的功能框架,不严重依赖使用方,也就是我在这个模块为你精选的 TopicDeletionManager(主题删除管理器)、ReplicaStateMachine(副本状态机)和 PartitionStateMachine(分区状态机)。
- TopicDeletionManager:负责对指定 Kafka 主题执行删除操作,清除待删除主题在集群上的各类“痕迹”。
- ReplicaStateMachine:负责定义 Kafka 副本状态、合法的状态转换,以及管理状态之间的转换。
- PartitionStateMachine:负责定义 Kafka 分区状态、合法的状态转换,以及管理状态之间的转换。
无论是主题、分区,还是副本,它们在 Kafka 中的生命周期通常都有多个状态。而这 3 个状态机,就是来管理这些状态的。而如何实现正确、高效的管理,就是源码要解决的核心问题。今天,我们先来学习 TopicDeletionManager,看一下 Kafka 是如何删除一个主题的。
1.1 课前导读
刚开始学习 Kafka 的时候,我对 Kafka 删除主题的认识非常“浅薄”。之前我以为成功执行了 kafka-topics.sh --delete 命令后,主题就会被删除。我相信,很多人可能都有过这样的错误理解。这种不正确的认知产生的一个结果就是,我们经常发现主题没有被删除干净。于是,网上流传着一套终极“武林秘籍”:手动删除磁盘上的日志文件,以及手动删除 ZooKeeper 下关于主题的各个节点。
我不推荐使用这套“秘籍”,理由有二:
- 它并不完整。事实上,除非你重启 Broker,否则,这套“秘籍”无法清理 Controller 端和各个 Broker 上元数据缓存中的待删除主题的相关条目。
- 它并没有被官方所认证,换句话说就是后果自负。从某种程度上说,它会带来什么不好的结果,是你没法把控的。
所谓“本事大不如不摊上”,我们与其琢磨删除主题失败之后怎么自救,不如踏踏实实地研究下 Kafka 底层是怎么执行这个操作的。搞明白它的原理之后,再有针对性地使用“秘籍”,才能做到有的放矢。你说是不是?
1.2 TopicDeletionManager 概览
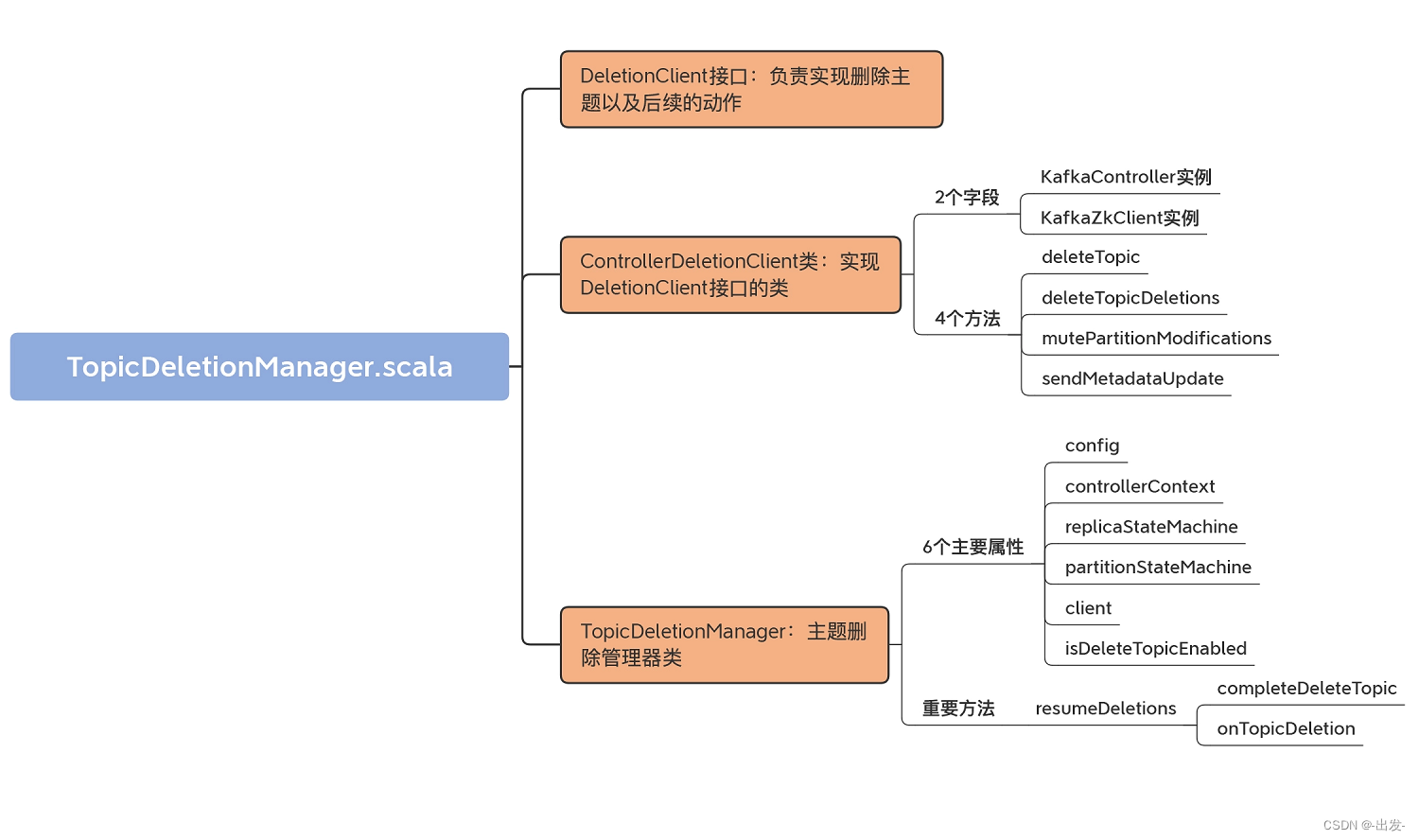
这个管理器位于 kafka.controller 包下,文件名是 TopicDeletionManager.scala。在总共不到 400 行的源码中,它定义了 3 个类结构以及 20 多个方法。总体而言,它还是比较容易学习的。为了让你先有个感性认识,我画了一张 TopicDeletionManager.scala 的代码 UML 图:
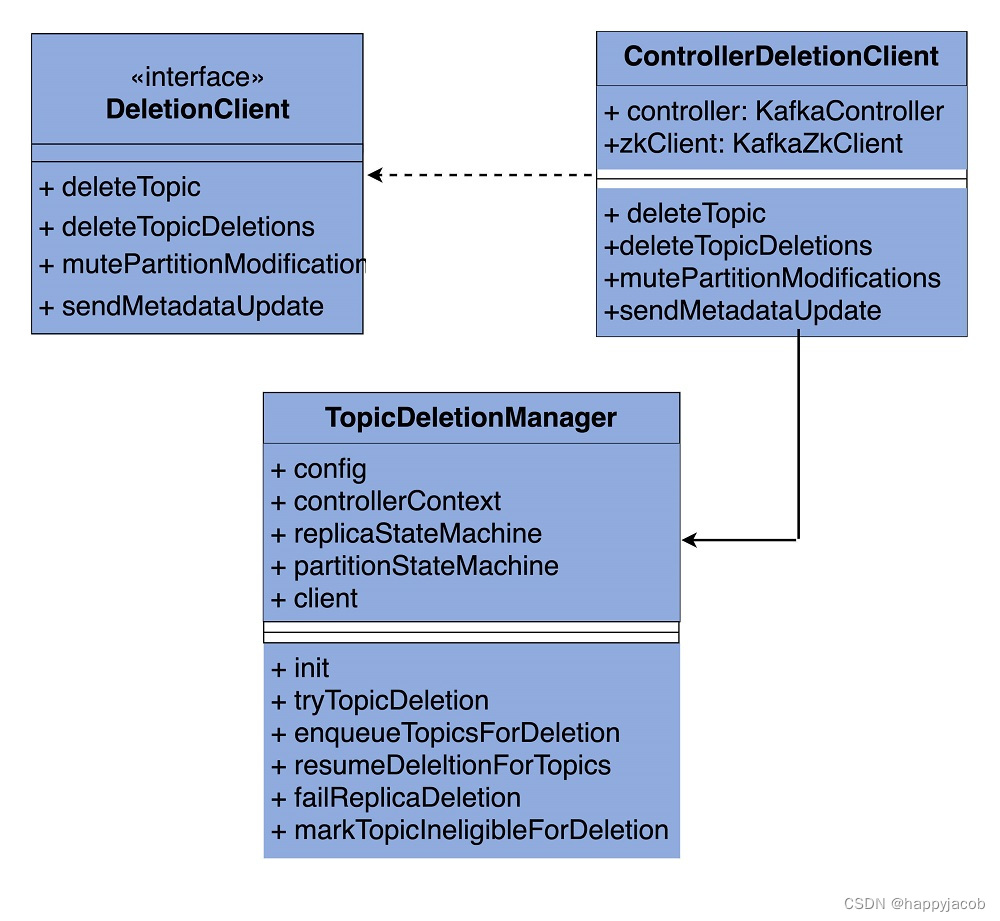
TopicDeletionManager.scala 这个源文件,包括 3 个部分。
- DeletionClient 接口:负责实现删除主题以及后续的动作,比如更新元数据等。这个接口里定义了 4 个方法,分别是 deleteTopic、deleteTopicDeletions、mutePartitionModifications 和 sendMetadataUpdate。我们后面再详细学习它们的代码。
- ControllerDeletionClient 类:实现 DeletionClient 接口的类,分别实现了刚刚说到的那 4 个方法。
- TopicDeletionManager 类:主题删除管理器类,定义了若干个方法维护主题删除前后集群状态的正确性。比如,什么时候才能删除主题、什么时候主题不能被删除、主题删除过程中要规避哪些操作,等等。
1.3 DeletionClient 接口及其实现
接下来,我们逐一讨论下这 3 部分。首先是 DeletionClient 接口及其实现类。就像前面说的,DeletionClient 接口定义的方法用于删除主题,并将删除主题这件事儿同步给其他 Broker。目前,DeletionClient 这个接口只有一个实现类,即 ControllerDeletionClient。我们看下这个实现类的代码:
class ControllerDeletionClient(controller: KafkaController, zkClient: KafkaZkClient) extends DeletionClient {
// 删除给定主题
override def deleteTopic(topic: String, epochZkVersion: Int): Unit = {
// 删除/brokers/topics/<topic>节点
zkClient.deleteTopicZNode(topic, epochZkVersion)
// 删除/config/topics/<topic>节点
zkClient.deleteTopicConfigs(Seq(topic), epochZkVersion)
// 删除/admin/delete_topics/<topic>节点
zkClient.deleteTopicDeletions(Seq(topic), epochZkVersion)
}
// 删除/admin/delete_topics下的给定topic子节点
override def deleteTopicDeletions(topics: Seq[String], epochZkVersion: Int): Unit = {
zkClient.deleteTopicDeletions(topics, epochZkVersion)
}
// 取消/brokers/topics/<topic>节点数据变更的监听
override def mutePartitionModifications(topic: String): Unit = {
controller.unregisterPartitionModificationsHandlers(Seq(topic))
}
// 向集群Broker发送指定分区的元数据更新请求
override def sendMetadataUpdate(partitions: Set[TopicPartition]): Unit = {
controller.sendUpdateMetadataRequest(controller.controllerContext.liveOrShuttingDownBrokerIds.toSeq, partitions)
}
}
这个类的构造函数接收两个字段。同时,由于是 DeletionClient 接口的实现类,因而该类实现了 DeletionClient 接口定义的四个方法。
先来说构造函数的两个字段:KafkaController 实例和 KafkaZkClient 实例。KafkaController 实例,我们已经很熟悉了,就是 Controller 组件对象;而 KafkaZkClient 实例,就是 Kafka 与 ZooKeeper 交互的客户端对象。接下来,我们再结合代码看下 DeletionClient 接口实现类 ControllerDeletionClient 定义的 4 个方法。我来简单介绍下这 4 个方法大致是做什么的。
1.deleteTopic
它用于删除主题在 ZooKeeper 上的所有“痕迹”。具体方法是,分别调用 KafkaZkClient 的 3 个方法去删除 ZooKeeper 下 /brokers/topics/节点、/config/topics/节点和 /admin/delete_topics/节点。
2.deleteTopicDeletions
它用于删除 ZooKeeper 下待删除主题的标记节点。具体方法是,调用 KafkaZkClient 的 deleteTopicDeletions 方法,批量删除一组主题在 /admin/delete_topics 下的子节点。注意,deleteTopicDeletions 这个方法名结尾的 Deletions,表示 /admin/delete_topics 下的子节点。所以,deleteTopic 是删除主题,deleteTopicDeletions 是删除 /admin/delete_topics 下的对应子节点。
到这里,我们还要注意的一点是,这两个方法里都有一个 epochZkVersion 的字段,代表期望的 Controller Epoch 版本号。如果你使用一个旧的 Epoch 版本号执行这些方法,ZooKeeper 会拒绝,因为和它自己保存的版本号不匹配。如果一个 Controller 的 Epoch 值小于 ZooKeeper 中保存的,那么这个 Controller 很可能是已经过期的 Controller。这种 Controller 就被称为 Zombie Controller。epochZkVersion 字段的作用,就是隔离 Zombie Controller 发送的操作。
3.mutePartitionModifications
它的作用是屏蔽主题分区数据变更监听器,具体实现原理其实就是取消 /brokers/topics/节点数据变更的监听。这样当该主题的分区数据发生变更后,由于对应的 ZooKeeper 监听器已经被取消了,因此不会触发 Controller 相应的处理逻辑。
为什么要取消这个监听器呢?其实,主要是为了避免操作之间的相互干扰。设想下,用户 A 发起了主题删除,而同时用户 B 为这个主题新增了分区。此时,这两个操作就会相互冲突,如果允许 Controller 同时处理这两个操作,势必会造成逻辑上的混乱以及状态的不一致。为了应对这种情况,在移除主题副本和分区对象前,代码要先执行这个方法,以确保不再响应用户对该主题的其他操作。
mutePartitionModifications 方法的实现原理很简单,它会调用 unregisterPartitionModificationsHandlers,并接着调用 KafkaZkClient 的 unregisterZNodeChangeHandler 方法,取消 ZooKeeper 上对给定主题的分区节点数据变更的监听。
4.sendMetadataUpdate
它会调用 KafkaController 的 sendUpdateMetadataRequest 方法,给集群所有 Broker 发送更新请求,告诉它们不要再为已删除主题的分区提供服务。该方法会给集群中的所有 Broker 发送更新元数据请求,告知它们要同步给定分区的状态。
1.4 TopicDeletionManager 定义及初始化
有了这些铺垫,我们再来看主题删除管理器的主要入口:TopicDeletionManager 类。这个类的定义代码,如下:
class TopicDeletionManager(config: KafkaConfig, // KafkaConfig类,保存Broker端参数
controllerContext: ControllerContext, // 集群元数据
replicaStateMachine: ReplicaStateMachine, // 副本状态机,用于设置副本状态
partitionStateMachine: PartitionStateMachine, // 分区状态机,用于设置分区状态
client: DeletionClient) extends Logging { // DeletionClient接口,实现主题删除
// 是否允许删除主题
val isDeleteTopicEnabled: Boolean = config.deleteTopicEnable
......
}
该类主要的属性有 6 个,我们分别来看看。
- config:KafkaConfig 实例,可以用作获取 Broker 端参数 delete.topic.enable 的值。该参数用于控制是否允许删除主题,默认值是 true,即 Kafka 默认允许用户删除主题。
- controllerContext:Controller 端保存的元数据信息。删除主题必然要变更集群元数据信息,因此 TopicDeletionManager 需要用到 controllerContext 的方法,去更新它保存的数据。
- replicaStateMachine 和 partitionStateMachine:副本状态机和分区状态机。它们各自负责副本和分区的状态转换,以保持副本对象和分区对象在集群上的一致性状态。这两个状态机是后面两讲的重要知识点。
- client:前面介绍的 DeletionClient 接口。TopicDeletionManager 通过该接口执行 ZooKeeper 上节点的相应更新。
- isDeleteTopicEnabled:表明主题是否允许被删除。它是 Broker 端参数 delete.topic.enable 的值,默认是 true,表示 Kafka 允许删除主题。源码中大量使用这个字段判断主题的可删除性。前面的 config 参数的主要目的就是设置这个字段的值。被设定之后,config 就不再被源码使用了。
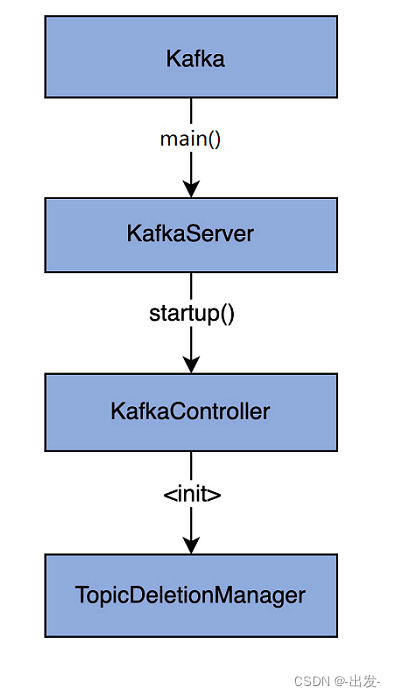
好了,知道这些字段的含义,我们再看看 TopicDeletionManager 类实例是如何被创建的。
实际上,这个实例是在 KafkaController 类初始化时被创建的。在 KafkaController 类的源码中,你可以很容易地找到这行代码:
val topicDeletionManager = new TopicDeletionManager(config, controllerContext, replicaStateMachine,
partitionStateMachine, new ControllerDeletionClient(this, zkClient))
可以看到,代码实例化了一个全新的 ControllerDeletionClient 对象,然后利用这个对象实例和 replicaStateMachine、partitionStateMachine,一起创建 TopicDeletionManager 实例。
为了方便你理解,我再给你画一张流程图:
1.5 TopicDeletionManager 重要方法
除了类定义和初始化,TopicDeletionManager 类还定义了 16 个方法。在这些方法中,最重要的当属 resumeDeletions 方法。它是重启主题删除操作过程的方法。
主题因为某些事件可能一时无法完成删除,比如主题分区正在进行副本重分配等。一旦这些事件完成后,主题重新具备可删除的资格。此时,代码就需要调用 resumeDeletions 重启删除操作。
这个方法之所以很重要,是因为它还串联了 TopicDeletionManager 类的很多方法,如 completeDeleteTopic 和 onTopicDeletion 等。因此,你完全可以从 resumeDeletions 方法开始,逐渐深入到其他方法代码的学习。那我们就先学习 resumeDeletions 的实现代码吧。
private def resumeDeletions(): Unit = {
// 从元数据缓存中获取要删除的主题列表
val topicsQueuedForDeletion = Set.empty[String] ++ controllerContext.topicsToBeDeleted
// 待重试主题列表
val topicsEligibleForRetry = mutable.Set.empty[String]
// 待删除主题列表
val topicsEligibleForDeletion = mutable.Set.empty[String]
if (topicsQueuedForDeletion.nonEmpty)
info(s"Handling deletion for topics ${topicsQueuedForDeletion.mkString(",")}")
// 遍历每个待删除主题
topicsQueuedForDeletion.foreach { topic =>
// if all replicas are marked as deleted successfully, then topic deletion is done
// 如果该主题所有副本已经是ReplicaDeletionSuccessful状态
// 即该主题已经被删除
if (controllerContext.areAllReplicasInState(topic, ReplicaDeletionSuccessful)) {
// clear up all state for this topic from controller cache and zookeeper
// 调用completeDeleteTopic方法完成后续操作即可
completeDeleteTopic(topic)
info(s"Deletion of topic $topic successfully completed")
// 如果主题删除尚未开始并且主题当前无法执行删除的话
} else if (!controllerContext.isAnyReplicaInState(topic, ReplicaDeletionStarted)) {
// if you come here, then no replica is in TopicDeletionStarted and all replicas are not in
// TopicDeletionSuccessful. That means, that either given topic haven't initiated deletion
// or there is at least one failed replica (which means topic deletion should be retried).
if (controllerContext.isAnyReplicaInState(topic, ReplicaDeletionIneligible)) {
// 把该主题加到待重试主题列表中用于后续重试
topicsEligibleForRetry += topic
}
}
// 如果该主题能够被删除
if (isTopicEligibleForDeletion(topic)) {
info(s"Deletion of topic $topic (re)started")
topicsEligibleForDeletion += topic
}
}
// 重试待重试主题列表中的主题删除操作
if (topicsEligibleForRetry.nonEmpty) {
retryDeletionForIneligibleReplicas(topicsEligibleForRetry)
}
// 调用onTopicDeletion方法,对待删除主题列表中的主题执行删除操作
if (topicsEligibleForDeletion.nonEmpty) {
onTopicDeletion(topicsEligibleForDeletion)
}
}
通过代码我们发现,这个方法首先从元数据缓存中获取要删除的主题列表,之后定义了两个空的主题列表,分别保存待重试删除主题和待删除主题。
然后,代码遍历每个要删除的主题,去看它所有副本的状态。如果副本状态都是 ReplicaDeletionSuccessful,就表明该主题已经被成功删除,此时,再调用 completeDeleteTopic 方法,完成后续的操作就可以了。对于那些删除操作尚未开始,并且暂时无法执行删除的主题,源码会把这类主题加到待重试主题列表中,用于后续重试;如果主题是能够被删除的,就将其加入到待删除列表中。
最后,该方法调用 retryDeletionForIneligibleReplicas 方法,来重试待重试主题列表中的主题删除操作。对于待删除主题列表中的主题则调用 onTopicDeletion 删除之。
值得一提的是,retryDeletionForIneligibleReplicas 方法用于重试主题删除。这是通过将对应主题副本的状态,从 ReplicaDeletionIneligible 变更到 OfflineReplica 来完成的。这样,后续再次调用 resumeDeletions 时,会尝试重新删除主题。
看到这里,我们再次发现,Kafka 的方法命名真的是非常规范。得益于这一点,很多时候,我们不用深入到方法内部,就能知道这个方法大致是做什么用的。比如:
- topicsQueuedForDeletion 方法,应该是保存待删除的主题列表;
- controllerContext.isAnyReplicaInState 方法,应该是判断某个主题下是否有副本处于某种状态;
- 而 onTopicDeletion 方法,应该就是执行主题删除操作用的。
这时,你再去阅读这 3 个方法的源码,就会发现它们的作用确实如其名字标识的那样。这也再次证明了 Kafka 源码质量是非常不错的。因此,不管你是不是 Kafka 的使用者,都可以把 Kafka 的源码作为阅读开源框架源码、提升自己竞争力的一个选择。
下面,我再用一张图来解释下 resumeDeletions 方法的执行流程:
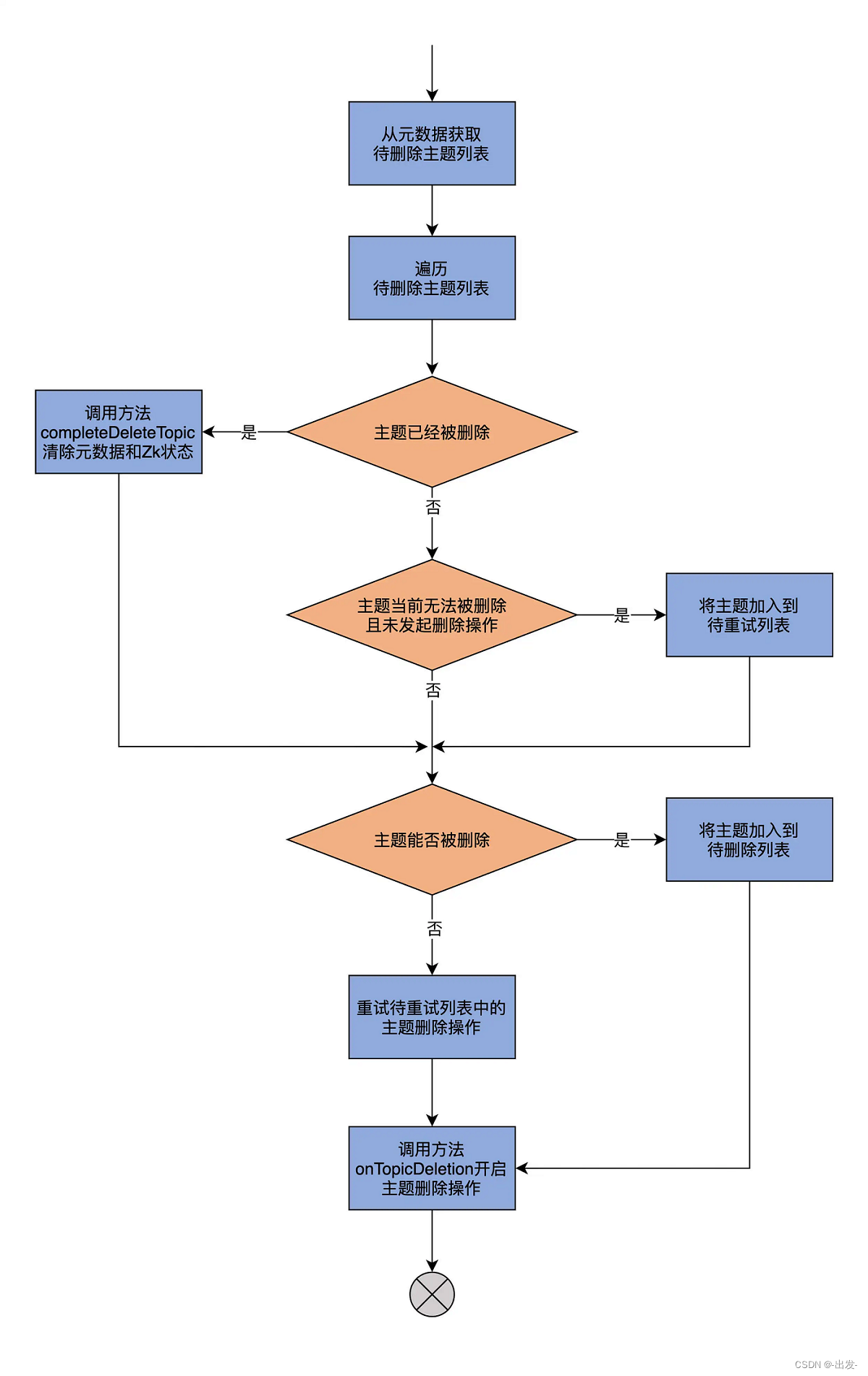
到这里,resumeDeletions 方法的逻辑我就讲完了,它果然是串联起了 TopicDeletionManger 中定义的很多方法。其中,比较关键的两个操作是 completeDeleteTopic 和 onTopicDeletion。接下来,我们就分别看看。
先来看 completeDeleteTopic 方法代码
private def completeDeleteTopic(topic: String): Unit = {
// 第1步:注销分区变更监听器,防止删除过程中因分区数据变更导致监听器被触发,引起状态不一致
client.mutePartitionModifications(topic)
// 第2步:获取该主题下处于ReplicaDeletionSuccessful状态的所有副本对象,即所有已经被成功删除的副本对象
val replicasForDeletedTopic = controllerContext.replicasInState(topic, ReplicaDeletionSuccessful)
// 第3步:利用副本状态机将这些副本对象转换成NonExistentReplica状态。等同于在状态机中删除这些副本
replicaStateMachine.handleStateChanges(replicasForDeletedTopic.toSeq, NonExistentReplica)
// 第4步:移除ZooKeeper上关于该主题的一切“痕迹”
client.deleteTopic(topic, controllerContext.epochZkVersion)
// 第5步:移除元数据缓存中关于该主题的一切“痕迹”
controllerContext.removeTopic(topic)
}
再来看看 onTopicDeletion 方法的代码:
private def onTopicDeletion(topics: Set[String]): Unit = {
// 找出给定待删除主题列表中那些尚未开启删除操作的所有主题
val unseenTopicsForDeletion = topics.diff(controllerContext.topicsWithDeletionStarted)
if (unseenTopicsForDeletion.nonEmpty) {
// 获取到这些主题的所有分区对象
val unseenPartitionsForDeletion = unseenTopicsForDeletion.flatMap(controllerContext.partitionsForTopic)
// 将这些分区的状态依次调整成OfflinePartition和NonExistentPartition等同于将这些分区从分区状态机中删除
partitionStateMachine.handleStateChanges(unseenPartitionsForDeletion.toSeq, OfflinePartition)
partitionStateMachine.handleStateChanges(unseenPartitionsForDeletion.toSeq, NonExistentPartition)
// 把这些主题加到“已开启删除操作”主题列表中
controllerContext.beginTopicDeletion(unseenTopicsForDeletion)
}
// 给集群所有Broker发送元数据更新请求,告诉它们不要再为这些主题处理数据了
client.sendMetadataUpdate(topics.flatMap(controllerContext.partitionsForTopic))
// 分区删除操作会执行底层的物理磁盘文件删除动作
onPartitionDeletion(topics)
}
onTopicDeletion 方法会多次使用分区状态机,来调整待删除主题的分区状态。在后两讲的分区状态机和副本状态机的课里面,我还会和你详细讲解它们,包括它们都定义了哪些状态,这些状态彼此之间的转换规则都是什么,等等。
onTopicDeletion 方法的最后一行调用了 onPartitionDeletion 方法,来执行真正的底层物理磁盘文件删除。实际上,这是通过副本状态机状态转换操作完成的。下节课,我会和你详细聊聊这个事情。
学到这里,我还想提醒你的是,在学习 TopicDeletionManager 方法的时候,非常重要一点的是,你要理解主题删除的脉络。对于其他部分的源码,也是这个道理。一旦你掌握了整体的流程,阅读那些细枝末节的方法代码就没有任何难度了。照着这个方法去读源码,搞懂 Kafka 源码也不是什么难事!
1.6 总结
今天,我们主要学习了 TopicDeletionManager.scala 中关于主题删除的代码。这里有几个要点,需要你记住。
- 在主题删除过程中,Kafka 会调整集群中三个地方的数据:ZooKeeper、元数据缓存和磁盘日志文件。删除主题时,ZooKeeper 上与该主题相关的所有 ZNode 节点必须被清除;Controller 端元数据缓存中的相关项,也必须要被处理,并且要被同步到集群的其他 Broker 上;而磁盘日志文件,更是要清理的首要目标。这三个地方必须要统一处理,就好似我们常说的原子性操作一样。现在回想下开篇提到的那个“秘籍”,你就会发现它缺少了非常重要的一环,那就是:无法清除 Controller 端的元数据缓存项。因此,你要尽力避免使用这个“大招”。
- DeletionClient 接口的作用,主要是操作 ZooKeeper,实现 ZooKeeper 节点的删除等操作。
- TopicDeletionManager,是在 KafkaController 创建过程中被初始化的,主要通过与元数据缓存进行交互的方式,来更新各类数据。
今天我们看到的代码中出现了大量的 replicaStateMachine 和 partitionStateMachine,其实这就是我今天反复提到的副本状态机和分区状态机。接下来两讲,我会逐步带你走进它们的代码世界,让你领略下 Kafka 通过状态机机制管理副本和分区的风采。
2 ReplicaStateMachine:揭秘副本状态机实现原理
前几节课,在讲 Controller、TopicDeletionManager 时,我反复提到副本状态机和分区状态机这两个组件。现在,你应该知道了,它们分别管理着 Kafka 集群中所有副本和分区的状态转换,但是,你知道副本和分区到底都有哪些状态吗?带着这个问题,我们用两节课的时间,重点学习下这两个组件的源码。我们先从副本状态机(ReplicaStateMachine)开始。
2.1 课前导读
坦率地说,ReplicaStateMachine 不如前面的组件有名气,Kafka 官网文档中甚至没有任何关于它的描述,可见,它是一个内部组件,一般用户感觉不到它的存在。因此,很多人都会有这样的错觉:既然它是外部不可见的组件,那就没有必要学习它的实现代码了。其实不然。弄明白副本状态机的原理,对于我们从根本上定位很多数据不一致问题是有帮助的。
下面,我跟你分享一个我的真实经历。曾经,我们部署过一个 3-Broker 的 Kafka 集群,版本是 2.0.0。假设这 3 个 Broker 是 A、B 和 C,我们在这 3 个 Broker 上创建了一个单分区、双副本的主题。当时,我们发现了一个奇怪的现象:如果两个副本分别位于 A 和 B,而 Controller 在 C 上,那么,当关闭 A、B 之后,ZooKeeper 中会显示该主题的 Leader 是 -1,ISR 为空;但是,如果两个副本依然位于 A 和 B 上,而 Controller 在 B 上,当我们依次关闭 A 和 B 后,该主题在 ZooKeeper 中的 Leader 和 ISR 就变成了 B。这显然和刚刚的情况不符。
虽然这并不是特别严重的问题,可毕竟出现了数据的不一致性,所以还是需要谨慎对待。在仔细查看源码之后,我们找到了造成不一致的原因:原来,在第一种情况下,Controller 会调用 ReplicaStateMachine,调整该主题副本的状态,进而变更了 Leader 和 ISR;而在第二种情况下,Controller 执行了 Failover,但是并未在新 Controller 组件初始化时进行状态转换,因而出现了不一致。
你看,要是不阅读这部分源码,我们肯定是无法定位这个问题的原因的。总之,副本状态机代码定义了 Kafka 副本的状态集合,同时控制了这些状态之间的流转规则。对于想要深入了解内部原理的你来说,短小精悍的 ReplicaStateMachine 源码是绝对不能错过的。
2.2 定义与初始化
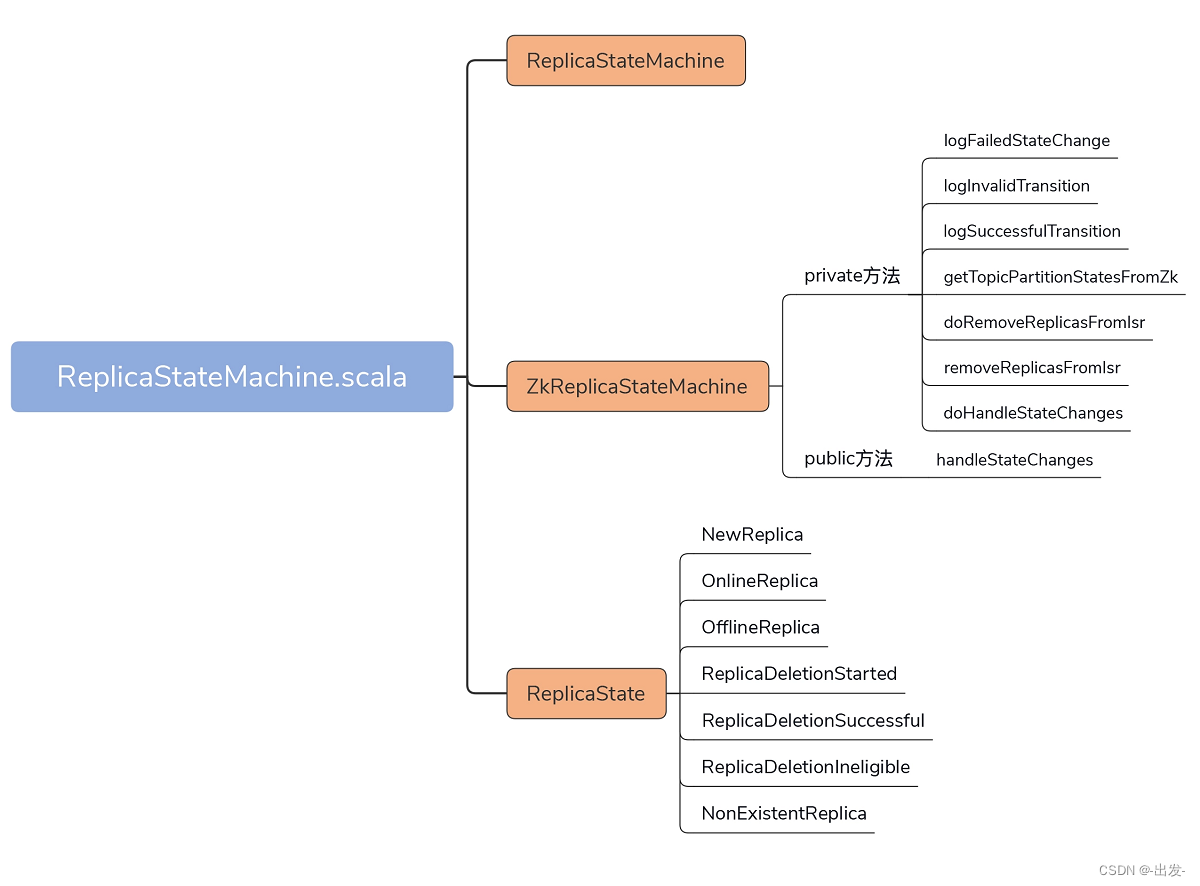
今天,我们要关注的源码文件是 controller 包下的 ReplicaStateMachine.scala 文件。它的代码结构非常简单,如下图所示:
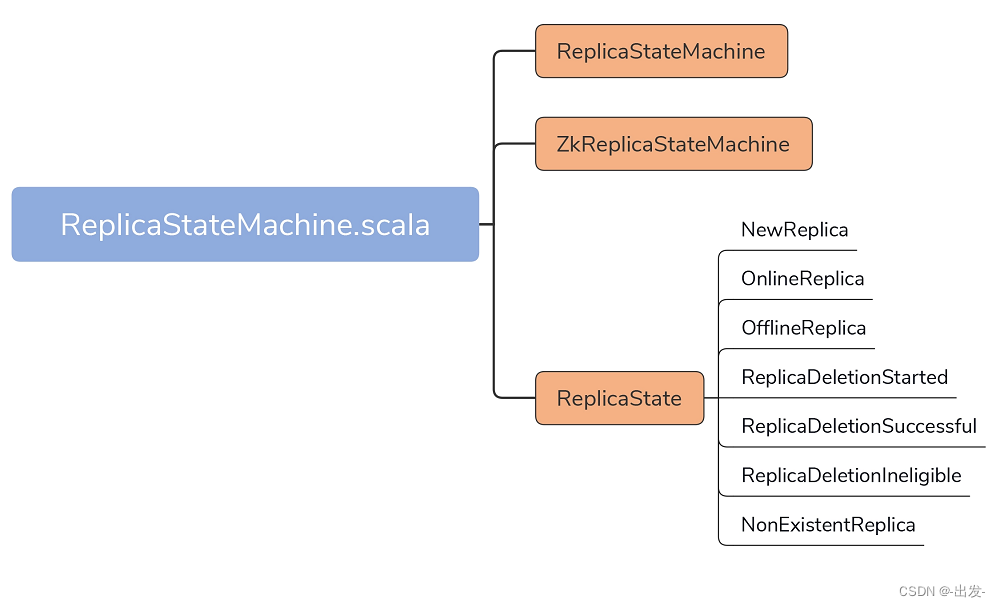
在不到 500 行的源文件中,代码定义了 3 个部分。
- ReplicaStateMachine:副本状态机抽象类,定义了一些常用方法(如 startup、shutdown 等),以及状态机最重要的处理逻辑方法 handleStateChanges。
- ZkReplicaStateMachine:副本状态机具体实现类,重写了 handleStateChanges 方法,实现了副本状态之间的状态转换。目前,ZkReplicaStateMachine 是唯一的 ReplicaStateMachine 子类。
- ReplicaState:副本状态集合,Kafka 目前共定义了 7 种副本状态。
下面,我们看下 ReplicaStateMachine 及其子类 ZKReplicaStateMachine 在代码中是如何定义的,请看这两个代码片段:
// ReplicaStateMachine抽象类定义
abstract class ReplicaStateMachine(controllerContext: ControllerContext) extends Logging {
......
}
// ZkReplicaStateMachine具体实现类定义
class ZkReplicaStateMachine(config: KafkaConfig,
stateChangeLogger: StateChangeLogger,
controllerContext: ControllerContext,
zkClient: KafkaZkClient,
controllerBrokerRequestBatch: ControllerBrokerRequestBatch)
extends ReplicaStateMachine(controllerContext) with Logging {
......
}
ReplicaStateMachine 只需要接收一个 ControllerContext 对象实例。在前几节课,我反复说过,ControllerContext 封装了 Controller 端保存的所有集群元数据信息。
ZKReplicaStateMachine 的属性则多一些。如果要构造一个 ZKReplicaStateMachine 实例,除了 ControllerContext 实例,比较重要的属性还有 KafkaZkClient 对象实例和 ControllerBrokerRequestBatch 实例。前者负责与 ZooKeeper 进行交互;后者用于给集群 Broker 发送控制类请求(也就是Controller模块中讲过的 LeaderAndIsrRequest、StopReplicaRequest 和 UpdateMetadataRequest)。
ControllerBrokerRequestBatch 对象的源码位于 ControllerChannelManager.scala 中,这是一个只有 10 行代码的类,主要的功能是将给定的 Request 发送给指定的 Broker。
在副本状态转换操作的逻辑中,一个很重要的步骤,就是为 Broker 上的副本更新信息,而这是通过 Controller 给 Broker 发送请求实现的,因此,你最好了解下这里的请求发送逻辑。
好了,学习了副本状态机类的定义,下面我们看下副本状态机是在何时进行初始化的。一句话总结就是,KafkaController 对象在构建的时候,就会初始化一个 ZkReplicaStateMachine 实例,如下列代码所示:
val replicaStateMachine: ReplicaStateMachine = new ZkReplicaStateMachine(config, stateChangeLogger, controllerContext, zkClient,
new ControllerBrokerRequestBatch(config, controllerChannelManager, eventManager, controllerContext, stateChangeLogger))
你可能会问:“如果一个 Broker 没有被选举为 Controller,它也会构建 KafkaController 对象实例吗?”没错!所有 Broker 在启动时,都会创建 KafkaController 实例,因而也会创建 ZKReplicaStateMachine 实例。
每个 Broker 都会创建这些实例,并不代表每个 Broker 都会启动副本状态机。事实上,只有在 Controller 所在的 Broker 上,副本状态机才会被启动。具体的启动代码位于 KafkaController 的 onControllerFailover 方法,如下所示:
private def onControllerFailover(): Unit = {
......
replicaStateMachine.startup() // 启动副本状态机
partitionStateMachine.startup() // 启动分区状态机
......
}
当 Broker 被成功推举为 Controller 后,onControllerFailover 方法会被调用,进而启动该 Broker 早已创建好的副本状态机和分区状态机。
2.3 副本状态及状态管理流程
副本状态机一旦被启动,就意味着它要行使它最重要的职责了:管理副本状态的转换。
不过,在学习如何管理状态之前,我们必须要弄明白,当前都有哪些状态,以及它们的含义分别是什么。源码中的 ReplicaState 定义了 7 种副本状态。
- NewReplica:副本被创建之后所处的状态。
- OnlineReplica:副本正常提供服务时所处的状态。
- OfflineReplica:副本服务下线时所处的状态。
- ReplicaDeletionStarted:副本被删除时所处的状态。
- ReplicaDeletionSuccessful:副本被成功删除后所处的状态。
- ReplicaDeletionIneligible:开启副本删除,但副本暂时无法被删除时所处的状态。
- NonExistentReplica:副本从副本状态机被移除前所处的状态。
具体到代码而言,ReplicaState 接口及其实现对象定义了每种状态的序号,以及合法的前置状态。我以 OnlineReplica 代码为例进行说明:
// ReplicaState接口
sealed trait ReplicaState {
def state: Byte
def validPreviousStates: Set[ReplicaState] // 定义合法的前置状态
}
// OnlineReplica状态
case object OnlineReplica extends ReplicaState {
val state: Byte = 2
val validPreviousStates: Set[ReplicaState] = Set(NewReplica, OnlineReplica, OfflineReplica, ReplicaDeletionIneligible)
}
OnlineReplica 的 validPreviousStates 属性是一个集合类型,里面包含 NewReplica、OnlineReplica、OfflineReplica 和 ReplicaDeletionIneligible。这说明,Kafka 只允许副本从刚刚这 4 种状态变更到 OnlineReplica 状态。如果从 ReplicaDeletionStarted 状态跳转到 OnlineReplica 状态,就是非法的状态转换。
这里,我只列出了 OnlineReplica。实际上,其他 6 种副本状态的代码逻辑也是类似的。下图绘制出了完整的状态转换规则:
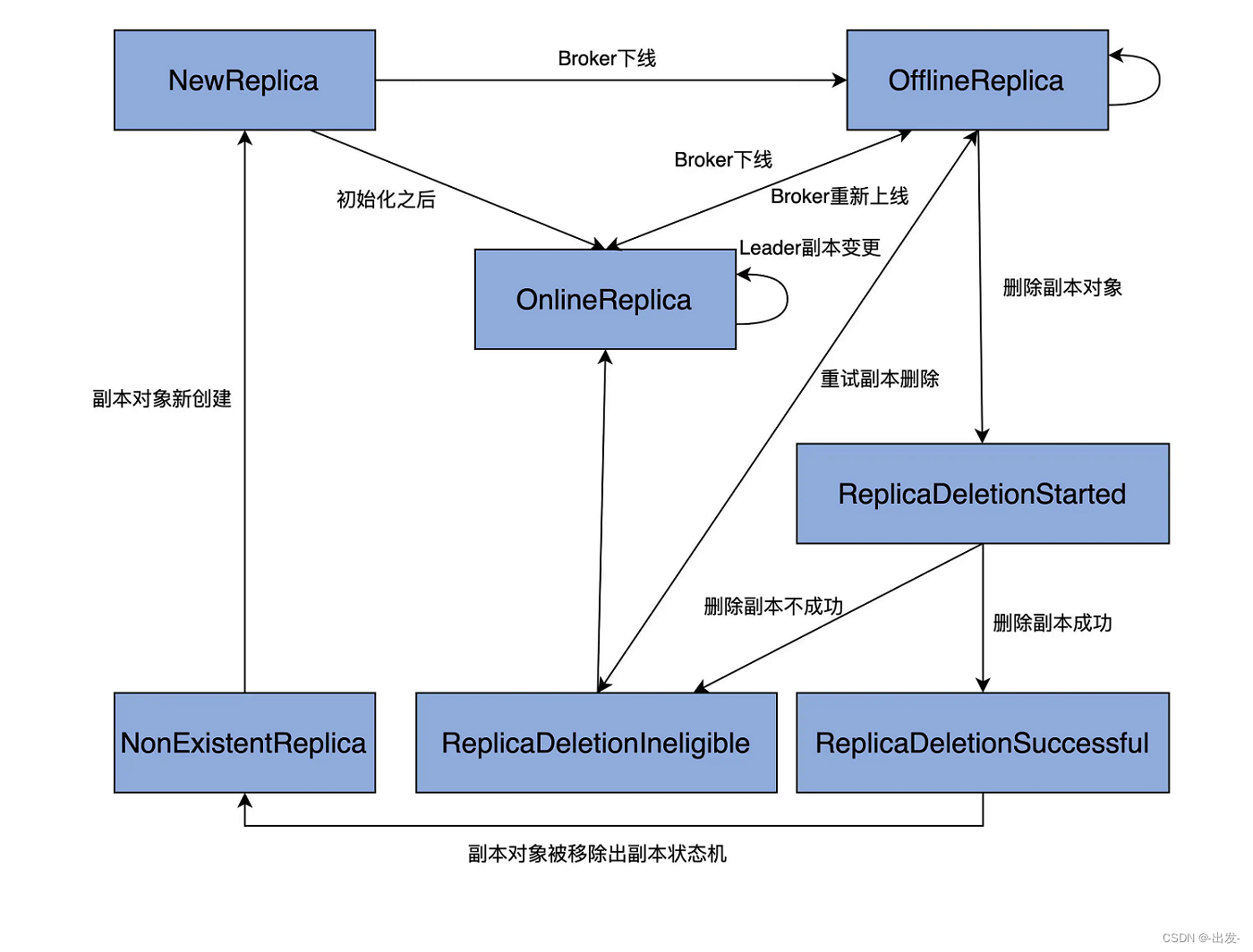
图中的单向箭头表示只允许单向状态转换,双向箭头则表示转换方向可以是双向的。比如,OnlineReplica 和 OfflineReplica 之间有一根双向箭头,这就说明,副本可以在 OnlineReplica 和 OfflineReplica 状态之间随意切换。
结合这张图,我再详细解释下各个状态的含义,以及它们的流转过程。
当副本对象首次被创建出来后,它会被置于 NewReplica 状态。经过一番初始化之后,当副本对象能够对外提供服务之后,状态机会将其调整为 OnlineReplica,并一直以该状态持续工作。
如果副本所在的 Broker 关闭或者是因为其他原因不能正常工作了,副本需要从 OnlineReplica 变更为 OfflineReplica,表明副本已处于离线状态。
一旦开启了如删除主题这样的操作,状态机会将副本状态跳转到 ReplicaDeletionStarted,以表明副本删除已然开启。倘若删除成功,则置为 ReplicaDeletionSuccessful,倘若不满足删除条件(如所在 Broker 处于下线状态),那就设置成 ReplicaDeletionIneligible,以便后面重试。
当副本对象被删除后,其状态会变更为 NonExistentReplica,副本状态机将移除该副本数据。
2.4 具体实现类:ZkReplicaStateMachine
了解了这些状态之后,我们来看下 ZkReplicaStateMachine 类的原理,毕竟,它是副本状态机的具体实现类。该类定义了 1 个 public 方法和 7 个 private 方法。这个 public 方法是副本状态机最重要的逻辑处理代码,它就是 handleStateChanges 方法。而那 7 个方法全部都是用来辅助 public 方法的。
(1)状态转换方法定义
在详细介绍 handleStateChanges 方法前,我稍微花点时间,给你简单介绍下其他 7 个方法都是做什么用的。就像前面说过的,这些方法主要是起辅助的作用。只有清楚了这些方法的用途,你才能更好地理解 handleStateChanges 的实现逻辑。
- logFailedStateChange:仅仅是记录一条错误日志,表明执行了一次无效的状态变更。
- logInvalidTransition:同样也是记录错误之用,记录一次非法的状态转换。
- logSuccessfulTransition:记录一次成功的状态转换操作。
- getTopicPartitionStatesFromZk:从 ZooKeeper 中获取指定分区的状态信息,包括每个分区的 Leader 副本、ISR 集合等数据。
- doRemoveReplicasFromIsr:把给定的副本对象从给定分区 ISR 中移除。
- removeReplicasFromIsr:调用 doRemoveReplicasFromIsr 方法,实现将给定的副本对象从给定分区 ISR 中移除的功能。
- doHandleStateChanges:执行状态变更和转换操作的主力方法。接下来,我们会详细学习它的源码部分。
(2)handleStateChanges 方法
handleStateChange 方法的作用是处理状态的变更,是对外提供状态转换操作的入口方法。其方法签名如下:
def handleStateChanges(replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit
该方法接收两个参数:replicas 是一组副本对象,每个副本对象都封装了它们各自所属的主题、分区以及副本所在的 Broker ID 数据;targetState 是这组副本对象要转换成的目标状态。这个方法的完整代码如下:
override def handleStateChanges(replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit = {
if (replicas.nonEmpty) {
try {
// 清空Controller待发送请求集合
controllerBrokerRequestBatch.newBatch()
// 将所有副本对象按照Broker进行分组,依次执行状态转换操作
replicas.groupBy(_.replica).forKeyValue { (replicaId, replicas) =>
doHandleStateChanges(replicaId, replicas, targetState)
}
// 发送对应的Controller请求给Broker
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
} catch {
// 如果Controller易主,则记录错误日志然后抛出异常
case e: ControllerMovedException =>
error(s"Controller moved to another broker when moving some replicas to $targetState state", e)
throw e
case e: Throwable => error(s"Error while moving some replicas to $targetState state", e)
}
}
}
代码逻辑总体上分为两步:第 1 步是调用 doHandleStateChanges 方法执行真正的副本状态转换;第 2 步是给集群中的相应 Broker 批量发送请求。
在执行第 1 步的时候,它会将 replicas 按照 Broker ID 进行分组。举个例子,如果我们使用 < 主题名,分区号,副本 Broker ID> 表示副本对象,假设 replicas 为集合(<test, 0, 0>, <test, 0, 1>, <test, 1, 0>, <test, 1, 1>),那么,在调用 doHandleStateChanges 方法前,代码会将 replicas 按照 Broker ID 进行分组,即变成:Map(0 -> Set(<test, 0, 0>, <test, 1, 0>),1 -> Set(<test, 0, 1>, <test, 1, 1>))。
待这些都做完之后,代码开始调用 doHandleStateChanges 方法,执行状态转换操作。这个方法看着很长,其实都是不同的代码分支。
(3)doHandleStateChanges 方法
我先用一张图,帮你梳理下它的流程,然后再具体分析下它的代码:
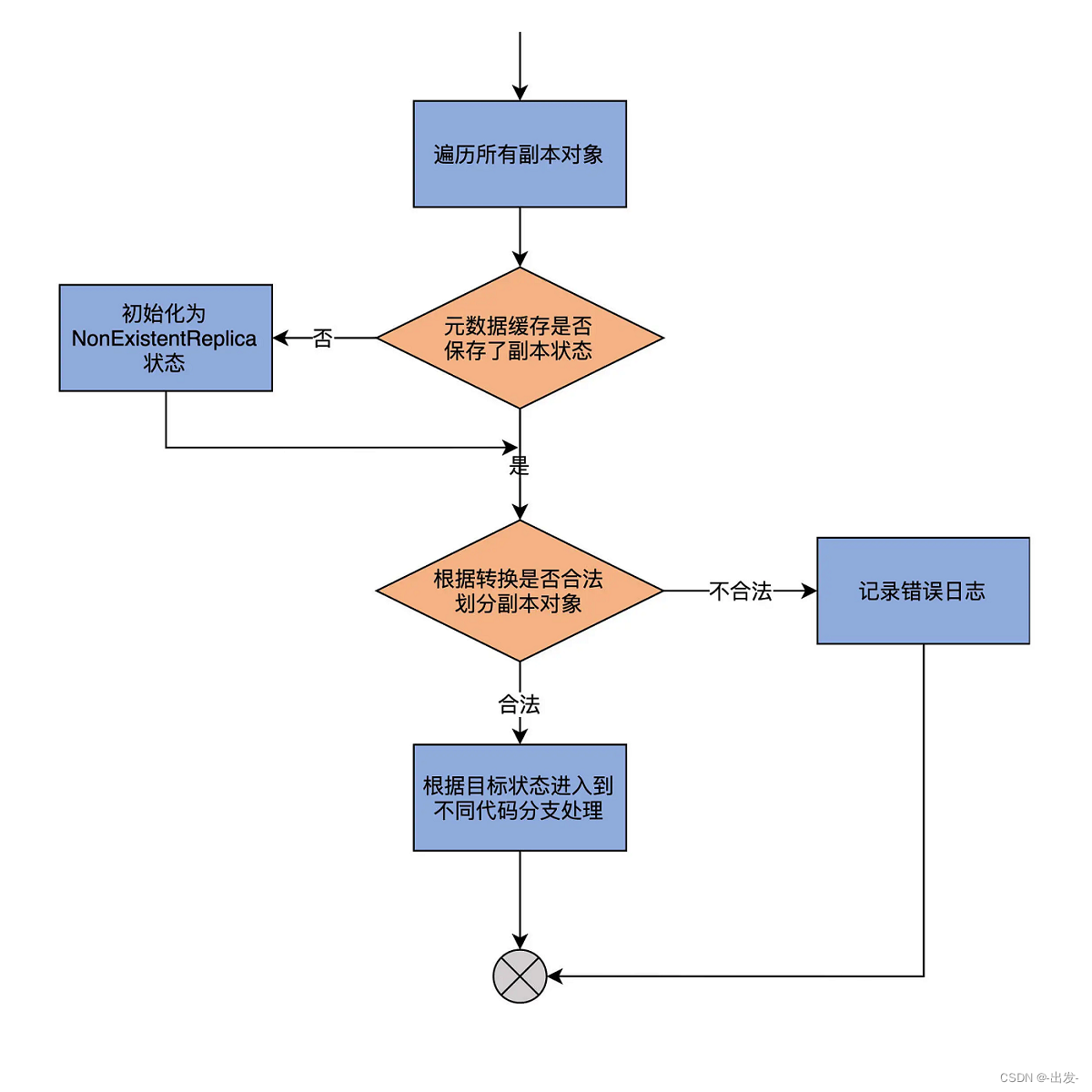
从图中可以发现,代码的第 1 步,会尝试获取给定副本对象在 Controller 端元数据缓存中的当前状态,如果没有保存某个副本对象的状态,代码会将其初始化为 NonExistentReplica 状态。
第 2 步,代码根据不同 ReplicaState 中定义的合法前置状态集合以及传入的目标状态(targetState),将给定的副本对象集合划分成两部分:能够合法转换的副本对象集合,以及执行非法状态转换的副本对象集合。doHandleStateChanges 方法会为后者中的每个副本对象记录一条错误日志。
第 3 步,代码携带能够执行合法转换的副本对象集合,进入到不同的代码分支。由于当前 Kafka 为副本定义了 7 类状态,因此,这里的代码分支总共有 7 路。
我挑选几路最常见的状态转换路径详细说明下,包括副本被创建时被转换到 NewReplica 状态,副本正常工作时被转换到 OnlineReplica 状态,副本停止服务后被转换到 OfflineReplica 状态。其他的转换操作原理大致是相同的。
(4)第1路:转换到 NewReplica 状态
首先,我们先来看第 1 路,即目标状态是 NewReplica 的代码。代码如下:
case NewReplica =>
// 遍历所有能够执行转换的副本对象
validReplicas.foreach { replica =>
// 获取该副本对象的分区对象,即<主题名,分区号>数据
val partition = replica.topicPartition
// 获取副本对象的当前状态
val currentState = controllerContext.replicaState(replica)
// 尝试从元数据缓存中获取该分区当前信息,包括Leader是谁、ISR都有哪些副本等数据
controllerContext.partitionLeadershipInfo(partition) match {
// 如果成功拿到分区数据信息
case Some(leaderIsrAndControllerEpoch) =>
// 如果该副本是Leader副本
if (leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId) {
val exception = new StateChangeFailedException(s"Replica $replicaId for partition $partition cannot be moved to NewReplica state as it is being requested to become leader")
// 记录错误日志。Leader副本不能被设置成NewReplica状态
logFailedStateChange(replica, currentState, OfflineReplica, exception)
// 否则,给该副本所在的Broker发送LeaderAndIsrRequest 向它同步该分区的数据,
// 之后给集群当前所有Broker发送UpdateMetadataRequest通知它们该分区数据发生变更
} else {
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
replica.topicPartition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(replica.topicPartition),
isNew = true)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, partition, currentState, NewReplica)
// 更新元数据缓存中该副本对象的当前状态为NewReplica
controllerContext.putReplicaState(replica, NewReplica)
}
// 如果没有相应数据
case None =>
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, partition, currentState, NewReplica)
// 仅仅更新元数据缓存中该副本对象的当前状态为NewReplica即可
controllerContext.putReplicaState(replica, NewReplica)
}
}
看完了代码,你可以再看下这张流程图:
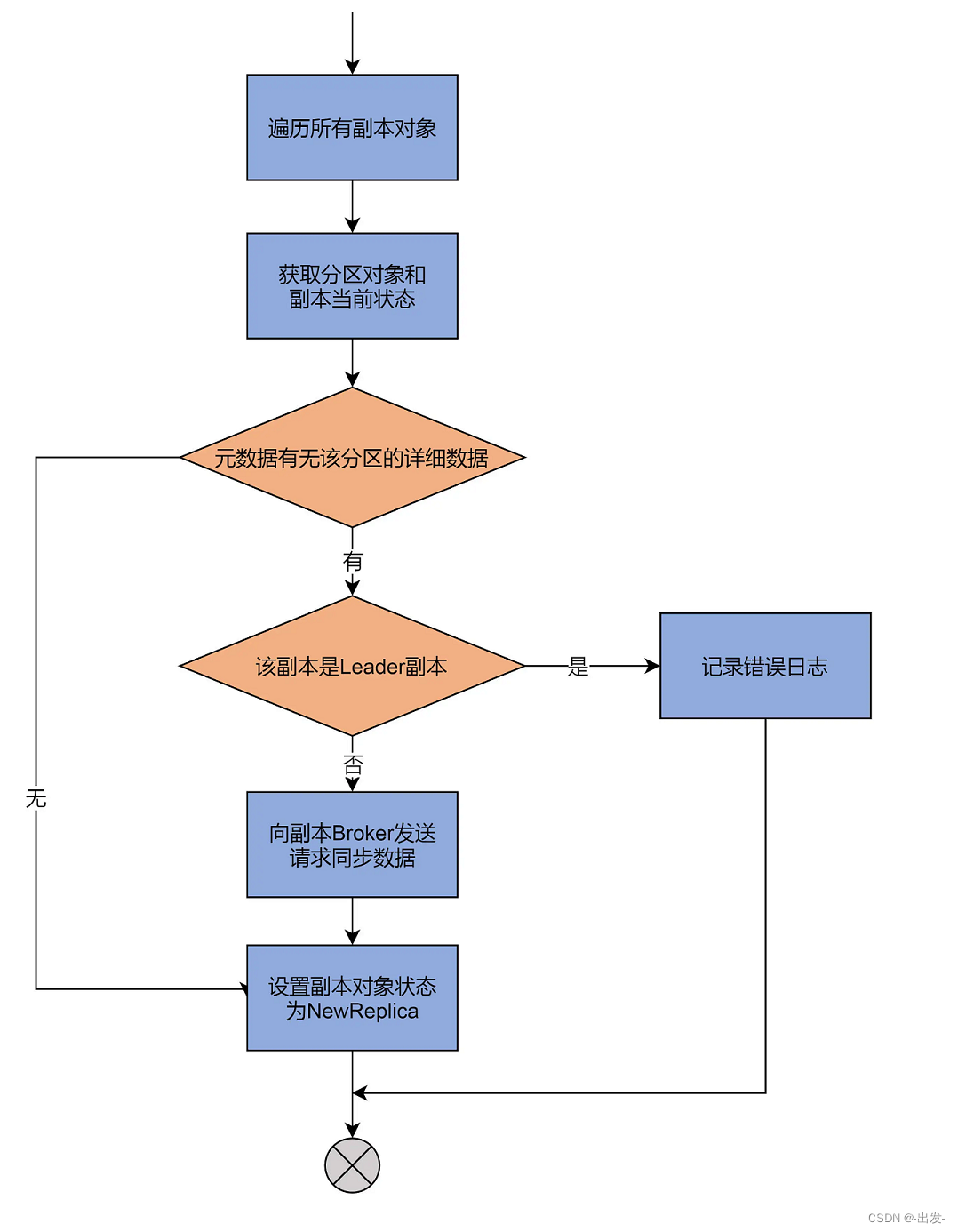
这一路主要做的事情是,尝试从元数据缓存中,获取这些副本对象的分区信息数据,包括分区的 Leader 副本在哪个 Broker 上、ISR 中都有哪些副本,等等。
如果找不到对应的分区数据,就直接把副本状态更新为 NewReplica。否则,代码就需要给该副本所在的 Broker 发送请求,让它知道该分区的信息。同时,代码还要给集群所有运行中的 Broker 发送请求,让它们感知到新副本的加入。
(5)第 2 路:转换到 OnlineReplica 状态
下面我们来看第 2 路,即转换副本对象到 OnlineReplica。刚刚我说过,这是副本对象正常工作时所处的状态。我们来看下要转换到这个状态,源码都做了哪些事情:
case OnlineReplica =>
validReplicas.foreach { replica =>
// 获取副本所在分区
val partition = replica.topicPartition
// 获取副本当前状态
val currentState = controllerContext.replicaState(replica)
currentState match {
// 如果当前状态是NewReplica
case NewReplica =>
// 从元数据缓存中拿到分区副本列表
val assignment = controllerContext.partitionFullReplicaAssignment(partition)
// 如果副本列表不包含当前副本,视为异常情况
if (!assignment.replicas.contains(replicaId)) {
error(s"Adding replica ($replicaId) that is not part of the assignment $assignment")
// 将该副本加入到副本列表中,并更新元数据缓存中该分区的副本列表
val newAssignment = assignment.copy(replicas = assignment.replicas :+ replicaId)
controllerContext.updatePartitionFullReplicaAssignment(partition, newAssignment)
}
// 如果当前状态是其他状态
case _ =>
// 尝试获取该分区当前信息数据
controllerContext.partitionLeadershipInfo(partition) match {
// 如果存在分区信息,向该副本对象所在Broker发送请求,令其同步该分区数据
case Some(leaderIsrAndControllerEpoch) =>
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(Seq(replicaId),
replica.topicPartition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
case None =>
}
}
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, partition, currentState, OnlineReplica)
// 将该副本对象设置成OnlineReplica状态
controllerContext.putReplicaState(replica, OnlineReplica)
}
同样使用一张图来说明:
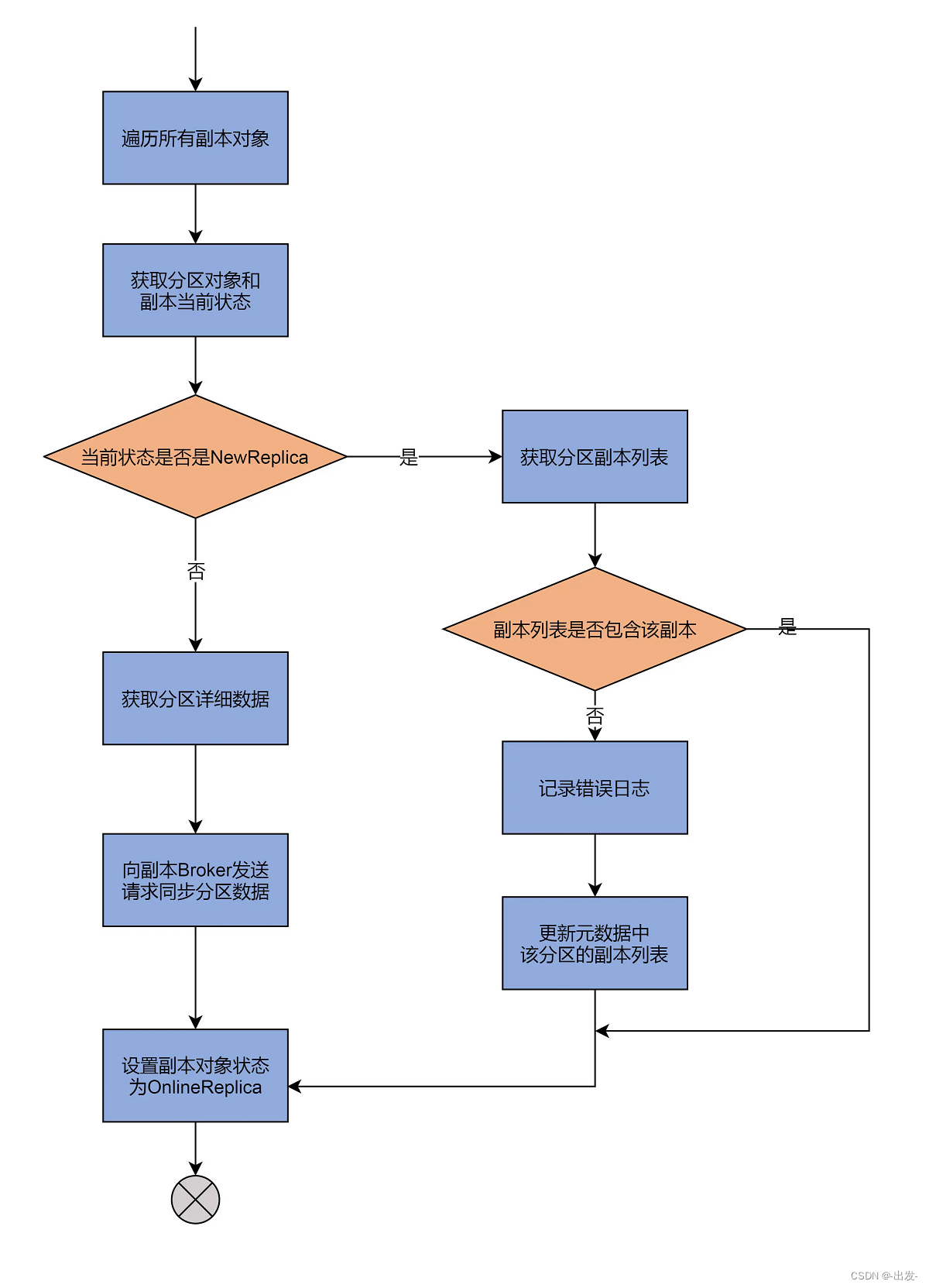
代码依然会对副本对象进行遍历,并依次执行下面的几个步骤。
- 第 1 步,获取元数据中该副本所属的分区对象,以及该副本的当前状态。
- 第 2 步,查看当前状态是否是 NewReplica。如果是,则获取分区的副本列表,并判断该副本是否在当前的副本列表中,假如不在,就记录错误日志,并更新元数据中的副本列表;如果状态不是 NewReplica,就说明,这是一个已存在的副本对象,那么,源码会获取对应分区的详细数据,然后向该副本对象所在的 Broker 发送 LeaderAndIsrRequest 请求,令其同步获知,并保存该分区数据。
- 第 3 步,将该副本对象状态变更为 OnlineReplica。至此,该副本处于正常工作状态。
(6)第 3 路:转换到 OfflineReplica 状态
最后,再来看下第 3 路分支。这路分支要将副本对象的状态转换成 OfflineReplica。我依然以代码注释的方式给出主要的代码逻辑:
case OfflineReplica =>
// 向副本所在Broker发送StopReplicaRequest请求,停止对应副本
validReplicas.foreach { replica =>
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = false)
}
// 将副本对象集合划分成有Leader信息的副本集合和无Leader信息的副本集合
val (replicasWithLeadershipInfo, replicasWithoutLeadershipInfo) = validReplicas.partition { replica =>
controllerContext.partitionLeadershipInfo(replica.topicPartition).isDefined
}
// 对于有Leader信息的副本集合而言从,它们对应的所有分区中移除该副本对象并更新ZooKeeper节点
val updatedLeaderIsrAndControllerEpochs = removeReplicasFromIsr(replicaId, replicasWithLeadershipInfo.map(_.topicPartition))
// 遍历每个更新过的分区信息
updatedLeaderIsrAndControllerEpochs.forKeyValue { (partition, leaderIsrAndControllerEpoch) =>
stateLogger.info(s"Partition $partition state changed to $leaderIsrAndControllerEpoch after removing replica $replicaId from the ISR as part of transition to $OfflineReplica")
// 如果分区对应主题并未被删除
if (!controllerContext.isTopicQueuedUpForDeletion(partition.topic)) {
// 获取该分区除给定副本以外的其他副本所在的Broker
val recipients = controllerContext.partitionReplicaAssignment(partition).filterNot(_ == replicaId)
// 向这些Broker发送请求更新该分区更新过的分区LeaderAndIsr数据
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipients,
partition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
}
val replica = PartitionAndReplica(partition, replicaId)
val currentState = controllerContext.replicaState(replica)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, partition, currentState, OfflineReplica)
// 设置该分区给定副本的状态为OfflineReplica
controllerContext.putReplicaState(replica, OfflineReplica)
}
// 遍历无Leader信息的所有副本对象
replicasWithoutLeadershipInfo.foreach { replica =>
val currentState = controllerContext.replicaState(replica)
if (traceEnabled)
logSuccessfulTransition(stateLogger, replicaId, replica.topicPartition, currentState, OfflineReplica)
// 向集群所有Broker发送请求,更新对应分区的元数据
controllerBrokerRequestBatch.addUpdateMetadataRequestForBrokers(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(replica.topicPartition))
// 设置该分区给定副本的状态为OfflineReplica
controllerContext.putReplicaState(replica, OfflineReplica)
}
我依然用一张图来说明它的执行流程:
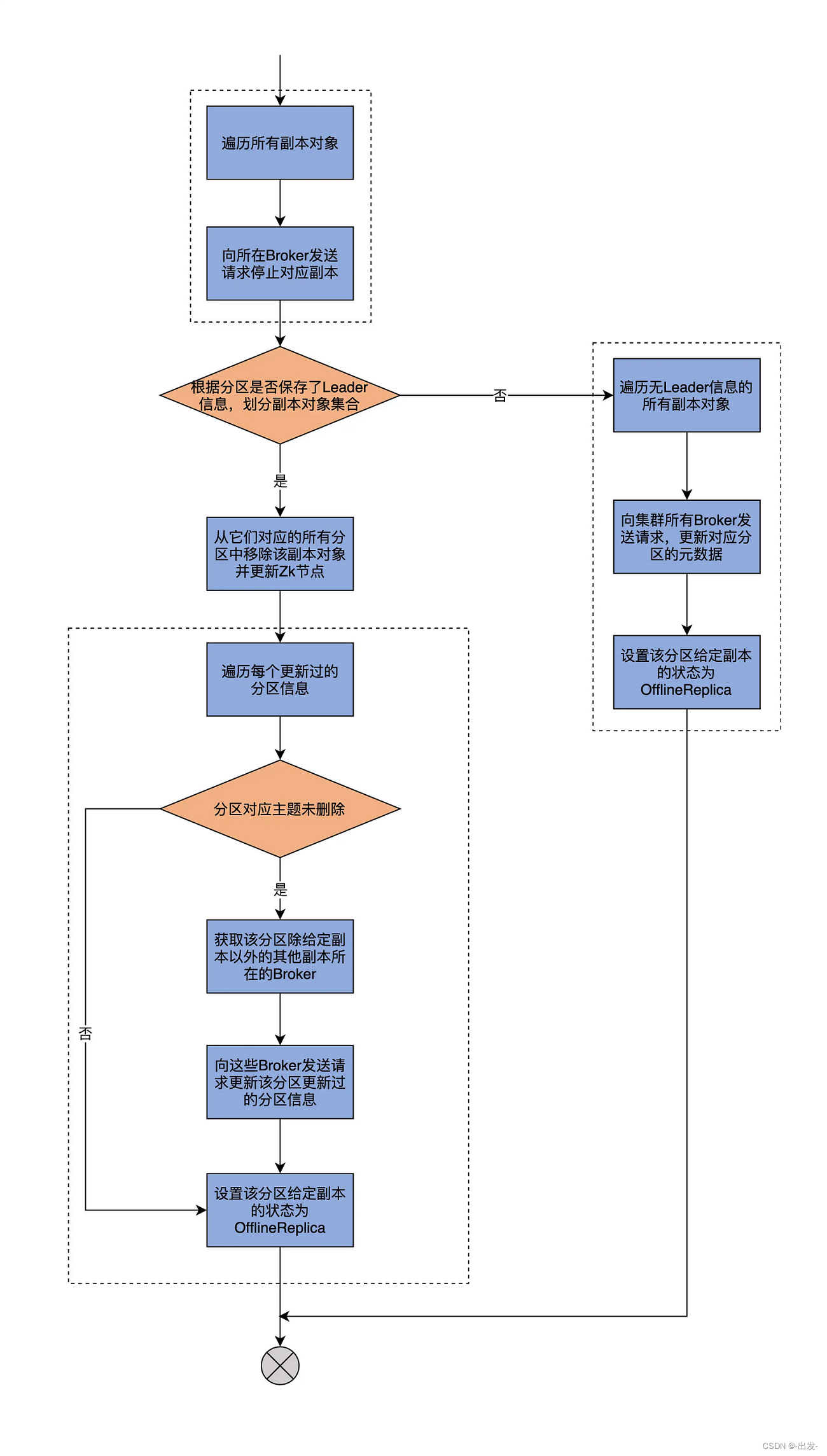
首先,代码会给所有符合状态转换的副本所在的 Broker,发送 StopReplicaRequest 请求,显式地告诉这些 Broker 停掉其上的对应副本。Kafka 的副本管理器组件(ReplicaManager)负责处理这个逻辑。后面我们会用两节课的时间专门讨论 ReplicaManager 的实现,这里你只需要了解,StopReplica 请求被发送出去之后,这些 Broker 上对应的副本就停止工作了。
其次,代码根据分区是否保存了 Leader 信息,将副本集合划分成两个子集:有 Leader 副本集合和无 Leader 副本集合。有无 Leader 信息并不仅仅包含 Leader,还有 ISR 和 controllerEpoch 等数据。不过,你大致可以认为,副本集合是根据有无 Leader 进行划分的。
接下来,源码会遍历有 Leader 的子集合,向这些副本所在的 Broker 发送 LeaderAndIsrRequest 请求,去更新停止副本操作之后的分区信息,再把这些分区状态设置为 OfflineReplica。
从这段描述中,我们可以知道,把副本状态变更为 OfflineReplica 的主要逻辑,其实就是停止对应副本 + 更新远端 Broker 元数据的操作。
2.5 总结
今天,我们重点学习了 Kafka 的副本状态机实现原理,还仔细研读了这部分的源码。我们简单回顾一下这节课的重点。
- 副本状态机:ReplicaStateMachine 是 Kafka Broker 端源码中控制副本状态流转的实现类。每个 Broker 启动时都会创建 ReplicaStateMachine 实例,但只有 Controller 组件所在的 Broker 才会启动它。
- 副本状态:当前,Kafka 定义了 7 类副本状态。同时,它还规定了每类状态合法的前置状态。
- handleStateChanges:用于执行状态转换的核心方法。底层调用 doHandleStateChanges 方法,以 7 路 case 分支的形式穷举每类状态的转换逻辑。
下节课,学习 Kafka 中另一类著名的状态机:分区状态机。掌握了这两个状态机,你就能清楚地知道 Kafka Broker 端管理分区和副本对象的完整流程和手段了。事实上,弄明白了这两个组件之后,Controller 负责主题方面的所有工作内容基本上都不会难倒你了。
3 PartitionStateMachine:分区状态转换如何实现?
今天我们进入到分区状态机(PartitionStateMachine)源码的学习。
PartitionStateMachine 负责管理 Kafka 分区状态的转换,和 ReplicaStateMachine 是一脉相承的。从代码结构、实现功能和设计原理来看,二者都极为相似。
在面试的时候,很多面试官都非常喜欢问 Leader 选举的策略。学完了今天的课程之后,你不但能够说出 4 种 Leader 选举的场景,还能总结出它们的共性。对于面试来说,绝对是个加分项!
3.1 PartitionStateMachine 简介
PartitionStateMachine.scala 文件位于 controller 包下,代码结构不复杂,可以看下这张思维导图:
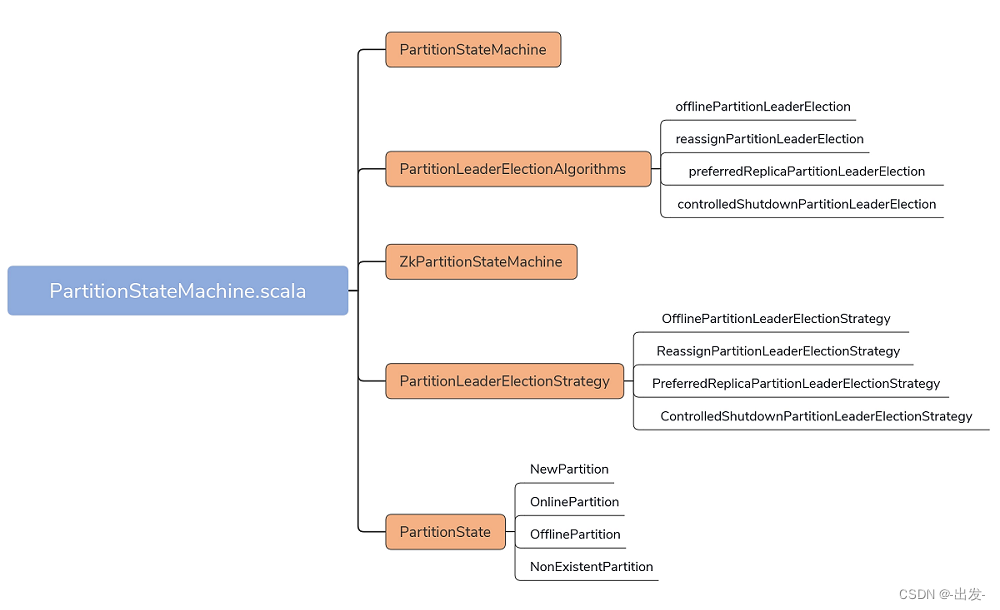
代码总共有 5 大部分。
- PartitionStateMachine:分区状态机抽象类。它定义了诸如 startup、shutdown 这样的公共方法,同时也给出了处理分区状态转换入口方法 handleStateChanges 的签名。
- ZkPartitionStateMachine:PartitionStateMachine 唯一的继承子类。它实现了分区状态机的主体逻辑功能。和 ZkReplicaStateMachine 类似,ZkPartitionStateMachine 重写了父类的 handleStateChanges 方法,并配以私有的 doHandleStateChanges 方法,共同实现分区状态转换的操作。
- PartitionState 接口及其实现对象:定义 4 类分区状态,分别是 NewPartition、OnlinePartition、OfflinePartition 和 NonExistentPartition。除此之外,还定义了它们之间的流转关系。
- PartitionLeaderElectionStrategy 接口及其实现对象:定义 4 类分区 Leader 选举策略。你可以认为它们是发生 Leader 选举的 4 种场景。
- PartitionLeaderElectionAlgorithms:分区 Leader 选举的算法实现。既然定义了 4 类选举策略,就一定有相应的实现代码,PartitionLeaderElectionAlgorithms 就提供了这 4 类选举策略的实现代码。
3.2 类定义与字段
PartitionStateMachine 和 ReplicaStateMachine 非常类似,我们先看下面这两段代码:
// PartitionStateMachine抽象类定义
abstract class PartitionStateMachine(
controllerContext: ControllerContext) extends Logging {
......
}
// ZkPartitionStateMachine继承子类定义
class ZkPartitionStateMachine(config: KafkaConfig,
stateChangeLogger: StateChangeLogger,
controllerContext: ControllerContext,
zkClient: KafkaZkClient,
controllerBrokerRequestBatch: ControllerBrokerRequestBatch) extends PartitionStateMachine(controllerContext) {
// Controller所在Broker的Id
private val controllerId = config.brokerId
......
}
从代码中,可以发现,它们的类定义一模一样,尤其是 ZkPartitionStateMachine 和 ZKReplicaStateMachine,它们接收的字段列表都是相同的。此刻,你应该可以体会到它们要做的处理逻辑,其实也是差不多的。
同理,ZkPartitionStateMachine 实例的创建和启动时机也跟 ZkReplicaStateMachine 的完全相同,即:每个 Broker 进程启动时,会在创建 KafkaController 对象的过程中,生成 ZkPartitionStateMachine 实例,而只有 Controller 组件所在的 Broker,才会启动分区状态机。
下面这段代码展示了 ZkPartitionStateMachine 实例创建和启动的位置:
class KafkaController(......) {
......
// 在KafkaController对象创建过程中,生成ZkPartitionStateMachine实例
val partitionStateMachine: PartitionStateMachine = new ZkPartitionStateMachine(config, stateChangeLogger, controllerContext, zkClient,
new ControllerBrokerRequestBatch(config, controllerChannelManager, eventManager, controllerContext, stateChangeLogger))
private def onControllerFailover(): Unit = {
replicaStateMachine.startup() // 启动副本状态机
partitionStateMachine.startup() // 启动分区状态机
}
}
有句话我要再强调一遍:每个 Broker 启动时,都会创建对应的分区状态机和副本状态机实例,但只有 Controller 所在的 Broker 才会启动它们。如果 Controller 变更到其他 Broker,老 Controller 所在的 Broker 要调用这些状态机的 shutdown 方法关闭它们,新 Controller 所在的 Broker 调用状态机的 startup 方法启动它们。
3.2 分区状态
既然 ZkPartitionStateMachine 是管理分区状态转换的,那么,我们至少要知道分区都有哪些状态,以及 Kafka 规定的转换规则是什么。这就是 PartitionState 接口及其实现对象做的事情。和 ReplicaState 类似,PartitionState 定义了分区的状态空间以及流转规则。
以 OnlinePartition 状态为例,说明下代码是如何实现流转的:
sealed trait PartitionState {
def state: Byte // 状态序号,无实际用途
def validPreviousStates: Set[PartitionState] // 合法前置状态集合
}
case object OnlinePartition extends PartitionState {
val state: Byte = 1
val validPreviousStates: Set[PartitionState] = Set(NewPartition, OnlinePartition, OfflinePartition)
}
如代码所示,每个 PartitionState 都定义了名为 validPreviousStates 的集合,也就是每个状态对应的合法前置状态集。
对于 OnlinePartition 而言,它的合法前置状态集包括 NewPartition、OnlinePartition 和 OfflinePartition。在 Kafka 中,从合法状态集以外的状态向目标状态进行转换,将被视为非法操作。
目前,Kafka 为分区定义了 4 类状态。
- NewPartition:分区被创建后被设置成这个状态,表明它是一个全新的分区对象。处于这个状态的分区,被 Kafka 认为是“未初始化”,因此,不能选举 Leader。
- OnlinePartition:分区正式提供服务时所处的状态。
- OfflinePartition:分区下线后所处的状态。
- NonExistentPartition:分区被删除,并且从分区状态机移除后所处的状态。
下图展示了完整的分区状态转换规则:
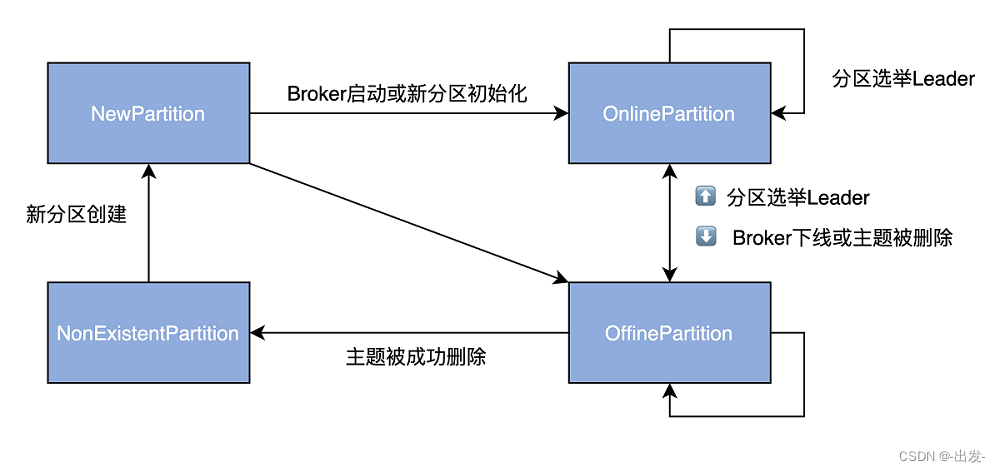
图中的双向箭头连接的两个状态可以彼此进行转换,如 OnlinePartition 和 OfflinePartition。Kafka 允许一个分区从 OnlinePartition 切换到 OfflinePartition,反之亦然。
另外,OnlinePartition 和 OfflinePartition 都有一根箭头指向自己,这表明 OnlinePartition 切换到 OnlinePartition 的操作是允许的。当分区 Leader 选举发生的时候,就可能出现这种情况。接下来,我们就聊聊分区 Leader 选举那些事儿。
3.3 分区 Leader 选举的场景及方法
刚刚我们说了两个状态机的相同点,接下来,我们要学习的分区 Leader 选举,可以说是 PartitionStateMachine 特有的功能了。每个分区都必须选举出 Leader 才能正常提供服务,因此,对于分区而言,Leader 副本是非常重要的角色。既然这样,我们就必须要了解 Leader 选举什么流程,以及在代码中是如何实现的。我们重点学习下选举策略以及具体的实现方法代码。
3.3.1 PartitionLeaderElectionStrategy
先明确下分区 Leader 选举的含义,其实很简单,就是为 Kafka 主题的某个分区推选 Leader 副本。
那么,Kafka 定义了哪几种推选策略,或者说,在什么情况下需要执行 Leader 选举呢?
这就是 PartitionLeaderElectionStrategy 接口要做的事情,请看下面的代码:
// 分区Leader选举策略接口
sealed trait PartitionLeaderElectionStrategy
// 离线分区Leader选举策略
final case class OfflinePartitionLeaderElectionStrategy(allowUnclean: Boolean) extends PartitionLeaderElectionStrategy
// 分区副本重分配Leader选举策略
final case object ReassignPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
// 分区Preferred副本Leader选举策略
final case object PreferredReplicaPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
// Broker Controlled关闭时Leader选举策略
final case object ControlledShutdownPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
当前,分区 Leader 选举有 4 类场景。
- OfflinePartitionLeaderElectionStrategy:因为 Leader 副本下线而引发的分区 Leader 选举。
- ReassignPartitionLeaderElectionStrategy:因为执行分区副本重分配操作而引发的分区 Leader 选举。
- PreferredReplicaPartitionLeaderElectionStrategy:因为执行 Preferred 副本 Leader 选举而引发的分区 Leader 选举。
- ControlledShutdownPartitionLeaderElectionStrategy:因为正常关闭 Broker 而引发的分区 Leader 选举。
3.3.2 PartitionLeaderElectionAlgorithms
针对这 4 类场景,分区状态机的 PartitionLeaderElectionAlgorithms 对象定义了 4 个方法,分别负责为每种场景选举 Leader 副本,这 4 种方法是:
- offlinePartitionLeaderElection;
- reassignPartitionLeaderElection;
- preferredReplicaPartitionLeaderElection;
- controlledShutdownPartitionLeaderElection。
offlinePartitionLeaderElection 方法的逻辑是这 4 个方法中最复杂的,我们就先从它开始学起。
def offlinePartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int], uncleanLeaderElectionEnabled: Boolean, controllerContext: ControllerContext): Option[Int] = {
// 从当前分区副本列表中寻找首个处于存活状态的ISR副本
assignment.find(id => liveReplicas.contains(id) && isr.contains(id)).orElse {
// 如果找不到满足条件的副本,查看是否允许Unclean Leader选举
// 即Broker端参数unclean.leader.election.enable是否等于true
if (uncleanLeaderElectionEnabled) {
// 选择当前副本列表中的第一个存活副本作为Leader
val leaderOpt = assignment.find(liveReplicas.contains)
if (leaderOpt.isDefined)
controllerContext.stats.uncleanLeaderElectionRate.mark()
leaderOpt
} else {
None // 如果不允许Unclean Leader选举,则返回None表示无法选举Leader
}
}
}
流程图帮助理解它的代码逻辑:
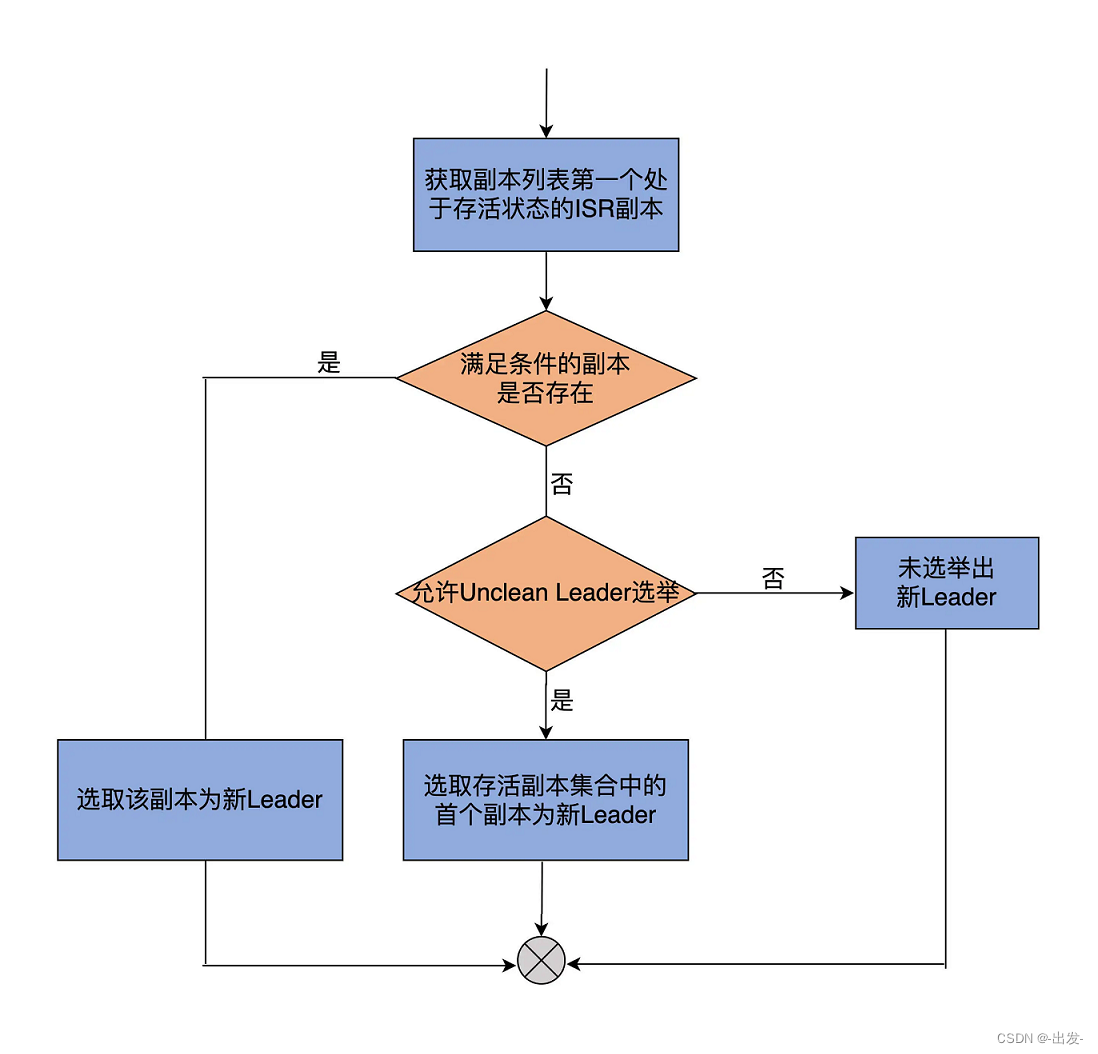
这个方法总共接收 5 个参数。除了你已经很熟悉的 ControllerContext 类,其他 4 个非常值得我们花一些时间去探究下。
- assignments
这是分区的副本列表。该列表有个专属的名称,叫 Assigned Replicas,简称 AR。当我们创建主题之后,使用 kafka-topics 脚本查看主题时,应该可以看到名为 Replicas 的一列数据。这列数据显示的,就是主题下每个分区的 AR。assignments 参数类型是 Seq[Int]。这揭示了一个重要的事实:AR 是有顺序的,而且不一定和 ISR 的顺序相同!
- isr
ISR 在 Kafka 中很有名气,它保存了分区所有与 Leader 副本保持同步的副本列表。注意,Leader 副本自己也在 ISR 中。另外,作为 Seq[Int]类型的变量,isr 自身也是有顺序的。
- liveReplicas
从名字可以推断出,它保存了该分区下所有处于存活状态的副本。怎么判断副本是否存活呢?可以根据 Controller 元数据缓存中的数据来判定。简单来说,所有在运行中的 Broker 上的副本,都被认为是存活的。
- uncleanLeaderElectionEnabled
在默认配置下,只要不是由 AdminClient 发起的 Leader 选举,这个参数的值一般是 false,即 Kafka 不允许执行 Unclean Leader 选举。所谓的 Unclean Leader 选举,是指在 ISR 列表为空的情况下,Kafka 选择一个非 ISR 副本作为新的 Leader。由于存在丢失数据的风险,目前,社区已经通过把 Broker 端参数 unclean.leader.election.enable 的默认值设置为 false 的方式,禁止 Unclean Leader 选举了。
值得一提的是,社区于 2.4.0.0 版本正式支持在 AdminClient 端为给定分区选举 Leader。目前的设计是,如果 Leader 选举是由 AdminClient 端触发的,那就默认开启 Unclean Leader 选举。不过,在学习 offlinePartitionLeaderElection 方法时,你可以认为 uncleanLeaderElectionEnabled=false,这并不会影响你对该方法的理解。
了解了这几个参数的含义,我们就可以研究具体的流程了。
代码首先会顺序搜索 AR 列表,并把第一个同时满足以下两个条件的副本作为新的 Leader 返回:
- 该副本是存活状态,即副本所在的 Broker 依然在运行中;
- 该副本在 ISR 列表中。
倘若无法找到这样的副本,代码会检查是否开启了 Unclean Leader 选举:如果开启了,则降低标准,只要满足上面第一个条件即可;如果未开启,则本次 Leader 选举失败,没有新 Leader 被选出。
其他 3 个方法要简单得多,我们直接看代码:
def reassignPartitionLeaderElection(reassignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
reassignment.find(id => liveReplicas.contains(id) && isr.contains(id))
}
def preferredReplicaPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
assignment.headOption.filter(id => liveReplicas.contains(id) && isr.contains(id))
}
def controlledShutdownPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int], shuttingDownBrokers: Set[Int]): Option[Int] = {
assignment.find(id => liveReplicas.contains(id) && isr.contains(id) && !shuttingDownBrokers.contains(id))
}
可以看到,它们的逻辑几乎是相同的,大概的原理都是从 AR,或给定的副本列表中寻找存活状态的 ISR 副本。
讲到这里,你应该已经知道 Kafka 为分区选举 Leader 的大体思路了。基本上就是,找出 AR 列表(或给定副本列表)中首个处于存活状态,且在 ISR 列表的副本,将其作为新 Leader。
3.4 处理分区状态转换的方法
掌握了刚刚的这些知识之后,现在,我们正式来看 PartitionStateMachine 的工作原理。
3.4.1 handleStateChanges
前面我提到过,handleStateChanges 是入口方法,所以我们先看它的方法签名:
def handleStateChanges(
partitions: Seq[TopicPartition],
targetState: PartitionState,
leaderElectionStrategy: Option[PartitionLeaderElectionStrategy]
): Map[TopicPartition, Either[Throwable, LeaderAndIsr]]
如果用一句话概括 handleStateChanges 的作用,应该这样说:handleStateChanges 把 partitions 的状态设置为 targetState,同时,还可能需要用 leaderElectionStrategy 策略为 partitions 选举新的 Leader,最终将 partitions 的 Leader 信息返回。
其中,partitions 是待执行状态变更的目标分区列表,targetState 是目标状态,leaderElectionStrategy 是一个可选项,如果传入了,就表示要执行 Leader 选举。
下面是 handleStateChanges 方法的完整代码,我以注释的方式给出了主要的功能说明:
override def handleStateChanges(
partitions: Seq[TopicPartition],
targetState: PartitionState,
partitionLeaderElectionStrategyOpt: Option[PartitionLeaderElectionStrategy]
): Map[TopicPartition, Either[Throwable, LeaderAndIsr]] = {
if (partitions.nonEmpty) {
try {
// 清空Controller待发送请求集合,准备本次请求发送
controllerBrokerRequestBatch.newBatch()
// 调用doHandleStateChanges方法执行真正的状态变更逻辑
val result = doHandleStateChanges(
partitions,
targetState,
partitionLeaderElectionStrategyOpt
)
// Controller给相关Broker发送请求通知状态变化
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
// 返回状态变更处理结果
result
} catch {
// 如果Controller易主,则记录错误日志,然后重新抛出异常
// 上层代码会捕获该异常并执行maybeResign方法执行卸任逻辑
case e: ControllerMovedException =>
error(s"Controller moved to another broker when moving some partitions to $targetState state", e)
throw e
// 如果是其他异常,记录错误日志,封装错误返回
case e: Throwable =>
error(s"Error while moving some partitions to $targetState state", e)
partitions.iterator.map(_ -> Left(e)).toMap
}
} else { // 如果partitions为空,什么都不用做
Map.empty
}
}
整个方法就两步:第 1 步是,调用 doHandleStateChanges 方法执行分区状态转换;第 2 步是,Controller 给相关 Broker 发送请求,告知它们这些分区的状态变更。至于哪些 Broker 属于相关 Broker,以及给 Broker 发送哪些请求,实际上是在第 1 步中被确认的。
当然,这个方法的重点,就是第 1 步中调用的 doHandleStateChanges 方法。
3.4.2 doHandleStateChanges
先来看这个方法的实现:
private def doHandleStateChanges(
partitions: Seq[TopicPartition],
targetState: PartitionState,
partitionLeaderElectionStrategyOpt: Option[PartitionLeaderElectionStrategy]
): Map[TopicPartition, Either[Throwable, LeaderAndIsr]] = {
val stateChangeLog = stateChangeLogger.withControllerEpoch(controllerContext.epoch)
val traceEnabled = stateChangeLog.isTraceEnabled
// 初始化新分区的状态为NonExistentPartition
partitions.foreach(partition => controllerContext.putPartitionStateIfNotExists(partition, NonExistentPartition))
// 找出要执行非法状态转换的分区,记录错误日志
val (validPartitions, invalidPartitions) = controllerContext.checkValidPartitionStateChange(partitions, targetState)
invalidPartitions.foreach(partition => logInvalidTransition(partition, targetState))
// 根据targetState进入到不同的case分支
targetState match {
.....
}
}
这个方法首先会做状态初始化的工作,具体来说就是,在方法调用时,不在元数据缓存中的所有分区的状态,会被初始化为 NonExistentPartition。
接着,检查哪些分区执行的状态转换不合法,并为这些分区记录相应的错误日志。
之后,代码携合法状态转换的分区列表进入到 case 分支。由于分区状态只有 4 个,因此,它的 case 分支代码远比 ReplicaStateMachine 中的简单,而且,只有 OnlinePartition 这一路的分支逻辑相对复杂,其他 3 路仅仅是将分区状态设置成目标状态而已,
所以,我们来深入研究下目标状态是 OnlinePartition 的分支:
case OnlinePartition =>
// 获取未初始化分区列表,也就是NewPartition状态下的所有分区
val uninitializedPartitions = validPartitions.filter(partition => partitionState(partition) == NewPartition)
// 获取具备Leader选举资格的分区列表
// 只能为OnlinePartition和OfflinePartition状态的分区选举Leader
val partitionsToElectLeader = validPartitions.filter(partition => partitionState(partition) == OfflinePartition || partitionState(partition) == OnlinePartition)
// 初始化NewPartition状态分区,在ZooKeeper中写入Leader和ISR数据
if (uninitializedPartitions.nonEmpty) {
val successfulInitializations = initializeLeaderAndIsrForPartitions(uninitializedPartitions)
successfulInitializations.foreach { partition =>
stateChangeLog.info(s"Changed partition $partition from ${partitionState(partition)} to $targetState with state " +
s"${controllerContext.partitionLeadershipInfo(partition).get.leaderAndIsr}")
controllerContext.putPartitionState(partition, OnlinePartition)
}
}
// 为具备Leader选举资格的分区推选Leader
if (partitionsToElectLeader.nonEmpty) {
val electionResults = electLeaderForPartitions(
partitionsToElectLeader,
partitionLeaderElectionStrategyOpt.getOrElse(
throw new IllegalArgumentException("Election strategy is a required field when the target state is OnlinePartition")
)
)
electionResults.foreach {
case (partition, Right(leaderAndIsr)) =>
stateChangeLog.info(
s"Changed partition $partition from ${partitionState(partition)} to $targetState with state $leaderAndIsr"
)
// 将成功选举Leader后的分区设置成OnlinePartition状态
controllerContext.putPartitionState(partition, OnlinePartition)
// 如果选举失败,忽略之
case (_, Left(_)) => // Ignore; no need to update partition state on election error
}
// 返回Leader选举结果
electionResults
} else {
Map.empty
}
第 1 步是为 NewPartition 状态的分区做初始化操作,也就是在 ZooKeeper 中,创建并写入分区节点数据。节点的位置是/brokers/topics/<topic>/partitions/<partition>,每个节点都要包含分区的 Leader 和 ISR 等数据。而 Leader 和 ISR 的确定规则是:选择存活副本列表的第一个副本作为 Leader;选择存活副本列表作为 ISR。至于具体的代码,可以看下 initializeLeaderAndIsrForPartitions 方法代码片段的倒数第 5 行:
private def initializeLeaderAndIsrForPartitions(partitions: Seq[TopicPartition]): Seq[TopicPartition] = {
......
// 获取每个分区的副本列表
val replicasPerPartition = partitions.map(partition => partition -> controllerContext.partitionReplicaAssignment(partition))
// 获取每个分区的所有存活副本
val liveReplicasPerPartition = replicasPerPartition.map { case (partition, replicas) =>
val liveReplicasForPartition = replicas.filter(replica => controllerContext.isReplicaOnline(replica, partition))
partition -> liveReplicasForPartition
}
// 按照有无存活副本对分区进行分组
// 分为两组:有存活副本的分区;无任何存活副本的分区
val (partitionsWithoutLiveReplicas, partitionsWithLiveReplicas) = liveReplicasPerPartition.partition { case (_, liveReplicas) => liveReplicas.isEmpty }
......
// 为"有存活副本的分区"确定Leader和ISR
// Leader确认依据:存活副本列表的首个副本被认定为Leader
// ISR确认依据:存活副本列表被认定为ISR
val leaderIsrAndControllerEpochs = partitionsWithLiveReplicas.map { case (partition, liveReplicas) =>
val leaderAndIsr = LeaderAndIsr(liveReplicas.head, liveReplicas.toList)
......
}.toMap
......
}
第 2 步是为具备 Leader 选举资格的分区推选 Leader,代码调用 electLeaderForPartitions 方法实现。这个方法会不断尝试为多个分区选举 Leader,直到所有分区都成功选出 Leader。
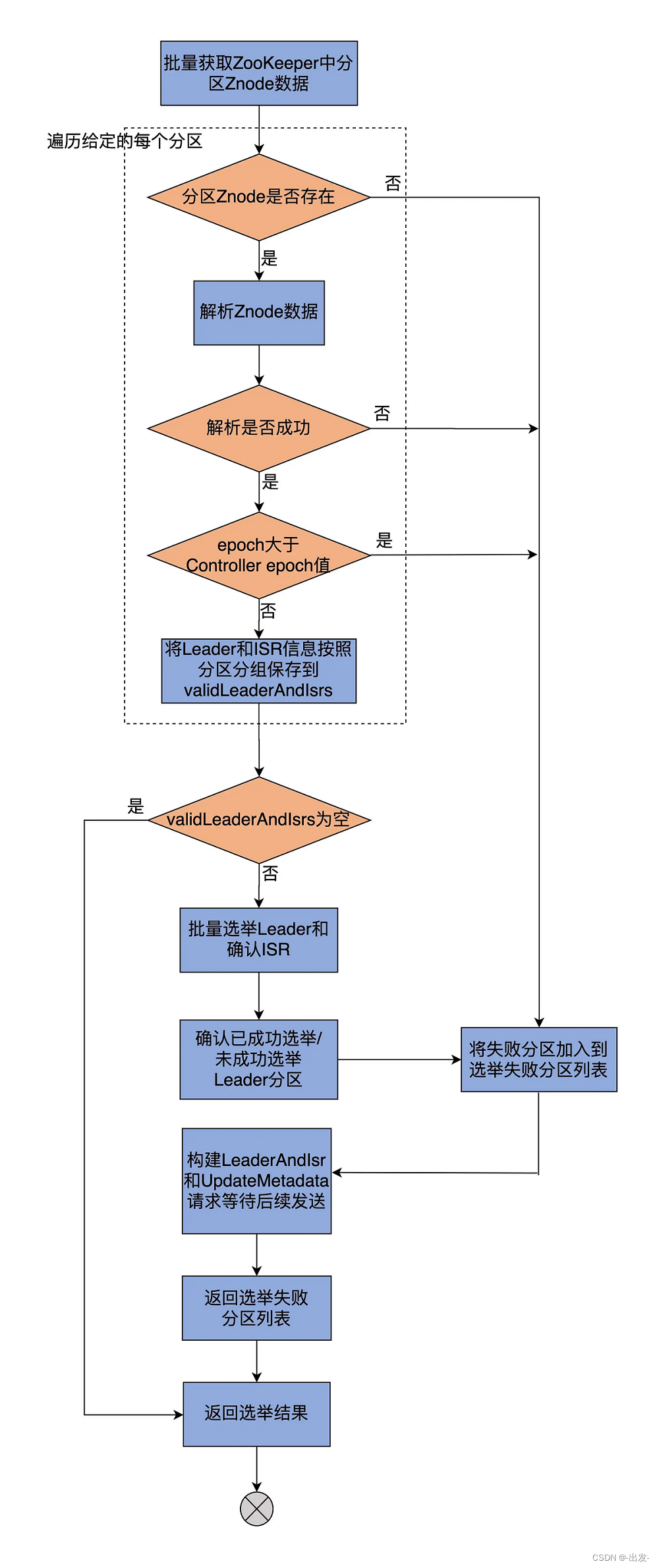
选举 Leader 的核心代码位于 doElectLeaderForPartitions 方法中,该方法主要有 3 步。代码很长,我先画一张图来展示它的主要步骤,然后再分步骤给你解释每一步的代码,以免你直接陷入冗长的源码行里面去。
看着好像图也很长,别着急,我们来一步步拆解下。
就像前面说的,这个方法大体分为 3 步。第 1 步是从 ZooKeeper 中获取给定分区的 Leader、ISR 信息,并将结果封装进名为 validLeaderAndIsrs 的容器中,代码如下:
// doElectLeaderForPartitions方法的第1部分
val getDataResponses = try {
// 批量获取ZooKeeper中给定分区的znode节点数据
zkClient.getTopicPartitionStatesRaw(partitions)
} catch {
case e: Exception =>
return (partitions.iterator.map(_ -> Left(e)).toMap, Seq.empty)
}
// 构建两个容器,分别保存可选举Leader分区列表和选举失败分区列表
val failedElections = mutable.Map.empty[TopicPartition, Either[Exception, LeaderAndIsr]]
val validLeaderAndIsrs = mutable.Buffer.empty[(TopicPartition, LeaderAndIsr)]
// 遍历每个分区的znode节点数据
getDataResponses.foreach { getDataResponse =>
val partition = getDataResponse.ctx.get.asInstanceOf[TopicPartition]
val currState = partitionState(partition)
// 如果成功拿到znode节点数据
if (getDataResponse.resultCode == Code.OK) {
TopicPartitionStateZNode.decode(getDataResponse.data, getDataResponse.stat) match {
// 节点数据中含Leader和ISR信息
case Some(leaderIsrAndControllerEpoch) =>
// 如果节点数据的Controller Epoch值大于当前Controller Epoch值
if (leaderIsrAndControllerEpoch.controllerEpoch > controllerContext.epoch) {
val failMsg = s"Aborted leader election for partition $partition since the LeaderAndIsr path was " +
s"already written by another controller. This probably means that the current controller $controllerId went through " +
s"a soft failure and another controller was elected with epoch ${leaderIsrAndControllerEpoch.controllerEpoch}."
// 将该分区加入到选举失败分区列表
failedElections.put(partition, Left(new StateChangeFailedException(failMsg)))
} else {
// 将该分区加入到可选举Leader分区列表
validLeaderAndIsrs += partition -> leaderIsrAndControllerEpoch.leaderAndIsr
}
// 如果节点数据不含Leader和ISR信息
case None =>
val exception = new StateChangeFailedException(s"LeaderAndIsr information doesn't exist for partition $partition in $currState state")
// 将该分区加入到选举失败分区列表
failedElections.put(partition, Left(exception))
}
// 如果没有拿到znode节点数据,则将该分区加入到选举失败分区列表
} else if (getDataResponse.resultCode == Code.NONODE) {
val exception = new StateChangeFailedException(s"LeaderAndIsr information doesn't exist for partition $partition in $currState state")
failedElections.put(partition, Left(exception))
} else {
failedElections.put(partition, Left(getDataResponse.resultException.get))
}
}
if (validLeaderAndIsrs.isEmpty) {
return (failedElections.toMap, Seq.empty)
}
首先,代码会批量读取 ZooKeeper 中给定分区的所有 Znode 数据。之后,会构建两个容器,分别保存可选举 Leader 分区列表和选举失败分区列表。接着,开始遍历每个分区的 Znode 节点数据,如果成功拿到 Znode 节点数据,节点数据包含 Leader 和 ISR 信息且节点数据的 Controller Epoch 值小于当前 Controller Epoch 值,那么,就将该分区加入到可选举 Leader 分区列表。倘若发现 Zookeeper 中保存的 Controller Epoch 值大于当前 Epoch 值,说明该分区已经被一个更新的 Controller 选举过 Leader 了,此时必须终止本次 Leader 选举,并将该分区放置到选举失败分区列表中。
遍历完这些分区之后,代码要看下 validLeaderAndIsrs 容器中是否包含可选举 Leader 的分区。如果一个满足选举 Leader 的分区都没有,方法直接返回。至此,doElectLeaderForPartitions 方法的第一大步完成。
下面,我们看下该方法的第 2 部分代码:
// doElectLeaderForPartitions方法的第2部分
// 开始选举Leader,并根据有无Leader将分区进行分区
val (partitionsWithoutLeaders, partitionsWithLeaders) = partitionLeaderElectionStrategy match {
case OfflinePartitionLeaderElectionStrategy(allowUnclean) =>
val partitionsWithUncleanLeaderElectionState = collectUncleanLeaderElectionState(
validLeaderAndIsrs,
allowUnclean
)
// 为OffinePartition分区选举Leader
leaderForOffline(controllerContext, partitionsWithUncleanLeaderElectionState).partition(_.leaderAndIsr.isEmpty)
case ReassignPartitionLeaderElectionStrategy =>
// 为副本重分配的分区选举Leader
leaderForReassign(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
case PreferredReplicaPartitionLeaderElectionStrategy =>
// 为分区执行Preferred副本Leader选举
leaderForPreferredReplica(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
case ControlledShutdownPartitionLeaderElectionStrategy =>
// 为因Broker正常关闭而受影响的分区选举Leader
leaderForControlledShutdown(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
}
这一步是根据给定的 PartitionLeaderElectionStrategy,调用 PartitionLeaderElectionAlgorithms 的不同方法执行 Leader 选举,同时,区分出成功选举 Leader 和未选出 Leader 的分区。
前面说过了,这 4 种不同的策略定义了 4 个专属的方法来进行 Leader 选举。其实,如果你打开这些方法的源码,就会发现它们大同小异。基本上,选择 Leader 的规则,就是选择副本集合中首个存活且处于 ISR 中的副本作为 Leader。
现在,我们再来看这个方法的最后一部分代码,这一步主要是更新 ZooKeeper 节点数据,以及 Controller 端元数据缓存信息。
// doElectLeaderForPartitions方法的第3部分
// 将所有选举失败的分区全部加入到Leader选举失败分区列表
partitionsWithoutLeaders.foreach { electionResult =>
val partition = electionResult.topicPartition
val failMsg = s"Failed to elect leader for partition $partition under strategy $partitionLeaderElectionStrategy"
failedElections.put(partition, Left(new StateChangeFailedException(failMsg)))
}
val recipientsPerPartition = partitionsWithLeaders.map(result => result.topicPartition -> result.liveReplicas).toMap
val adjustedLeaderAndIsrs = partitionsWithLeaders.map(result => result.topicPartition -> result.leaderAndIsr.get).toMap
// 使用新选举的Leader和ISR信息更新ZooKeeper上分区的znode节点数据
val UpdateLeaderAndIsrResult(finishedUpdates, updatesToRetry) = zkClient.updateLeaderAndIsr(
adjustedLeaderAndIsrs, controllerContext.epoch, controllerContext.epochZkVersion)
// 对于ZooKeeper znode节点数据更新成功的分区,封装对应的Leader和ISR信息
// 构建LeaderAndIsr请求,并将该请求加入到Controller待发送请求集合
// 等待后续统一发送
finishedUpdates.forKeyValue { (partition, result) =>
result.foreach { leaderAndIsr =>
val replicaAssignment = controllerContext.partitionFullReplicaAssignment(partition)
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
controllerContext.putPartitionLeadershipInfo(partition, leaderIsrAndControllerEpoch)
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipientsPerPartition(partition), partition,
leaderIsrAndControllerEpoch, replicaAssignment, isNew = false)
}
}
if (isDebugEnabled) {
updatesToRetry.foreach { partition =>
debug(s"Controller failed to elect leader for partition $partition. " +
s"Attempted to write state ${adjustedLeaderAndIsrs(partition)}, but failed with bad ZK version. This will be retried.")
}
}
// 返回选举结果,包括成功选举并更新ZooKeeper节点的分区、选举失败分区以及
// ZooKeeper节点更新失败的分区
(finishedUpdates ++ failedElections, updatesToRetry)
首先,将上一步中所有选举失败的分区,全部加入到 Leader 选举失败分区列表。
然后,使用新选举的 Leader 和 ISR 信息,更新 ZooKeeper 上分区的 Znode 节点数据。对于 ZooKeeper Znode 节点数据更新成功的那些分区,源码会封装对应的 Leader 和 ISR 信息,构建 LeaderAndIsr 请求,并将该请求加入到 Controller 待发送请求集合,等待后续统一发送。
最后,方法返回选举结果,包括成功选举并更新 ZooKeeper 节点的分区列表、选举失败分区列表,以及 ZooKeeper 节点更新失败的分区列表。
这会儿,你还记得 handleStateChanges 方法的第 2 步是 Controller 给相关的 Broker 发送请求吗?那么,到底要给哪些 Broker 发送哪些请求呢?其实就是在上面这步完成的,即这行语句:
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(
recipientsPerPartition(partition), partition,
leaderIsrAndControllerEpoch, replicaAssignment, isNew = false)
3.5 总结
今天,我们重点学习了 PartitionStateMachine.scala 文件的源码,主要是研究了 Kafka 分区状态机的构造原理和工作机制。
学到这里,我们再来回答开篇面试官的问题,应该就不是什么难事了。现在我们知道了,Kafka 目前提供 4 种 Leader 选举策略,分别是分区下线后的 Leader 选举、分区执行副本重分配时的 Leader 选举、分区执行 Preferred 副本 Leader 选举,以及 Broker 下线时的分区 Leader 选举。
这 4 类选举策略在选择 Leader 这件事情上有着类似的逻辑,那就是,它们几乎都是选择当前副本有序集合中的、首个处于 ISR 集合中的存活副本作为新的 Leader。当然,个别选举策略可能会有细小的差别,你可以结合我们今天学到的源码,课下再深入地研究一下每一类策略的源码。
我们来回顾下这节课的重点。
- PartitionStateMachine 是 Kafka Controller 端定义的分区状态机,负责定义、维护和管理合法的分区状态转换。
- 每个 Broker 启动时都会实例化一个分区状态机对象,但只有 Controller 所在的 Broker 才会启动它。
- Kafka 分区有 4 类状态,分别是 NewPartition、OnlinePartition、OfflinePartition 和 NonExistentPartition。其中 OnlinPartition 是分区正常工作时的状态。NewPartition 是未初始化状态,处于该状态下的分区尚不具备选举 Leader 的资格。
- Leader 选举有 4 类场景,分别是 Offline、Reassign、Preferrer Leader Election 和 ControlledShutdown。每类场景都对应于一种特定的 Leader 选举策略。
- handleStateChanges 方法是主要的入口方法,下面调用 doHandleStateChanges 私有方法实现实际的 Leader 选举功能。
下个模块,我们将来到 Kafka 延迟操作代码的世界。在那里,你能了解 Kafka 是如何实现一个延迟请求的处理的。另外,一个 O(N) 时间复杂度的时间轮算法也等候在那里,到时候我们一起研究下它!