Python基础练习案例
- 一、Python基础语法
- 1、练习案例1:求钱包余额
- 2、练习案例2:股价计算小程序
- 3、练习案例3:欢迎登陆小程序
- 二、Python判断语句
- 1、练习案例1:成年人判断
- 2、练习案例2:我要买票吗
- 3、练习案例3:猜猜心里数字
- 4、练习案例4:猜数字
- 三、Python循环语句
- 1、练习案例1:求1-100的和
- 2、练习案例2:猜数字案例
- 3、练习案例3:打印九九乘法表
- 4、练习案例4:数一数有几个a
- 5、练习案例5:有几个偶数
- 6、练习案例6:for循环打印九九乘法表
- 7、练习案例7:发工资
- 四、Python函数
- 1、练习案例1:自动查核酸
- 2、练习案例2:升级版自动查核酸
- 3、练习案例3:黑马ATM
- 五、Python数据容器
- 1、练习案例1:列表常用功能练习
- 2、练习案例2:取出列表内的偶数
- 3、练习案例3:元组的基本操作
- 4、练习案例4:分割字符串
- 5、练习案例5:序列的切片实践
- 6、练习案例6:信息去重
- 7、练习案例7:升职加薪
- 8、练习案例8:第六章PPT作业题
- 六、Python文件操作
- 1、练习案例1:单词计数
- 2、练习案例2:文件备份案例
- 七、Python异常、模块与包
- 1、练习案例1:自定义工具包
- 八、Python数据可视化
- 1、练习案例1:折线图可视化
- 2、练习案例2:地图可视化
- 3、练习案例3:动态柱状图
- 九、面向对象
- 1、练习案例1:学生信息录入
- 2、练习案例2:设计带有私有成员的手机
- 3、练习案例3:数据分析案例
- 十、PySpark
- 1、练习案例1:WordCount案例
- 2、练习案例2:城市销售分析统计案例
- 3、练习案例3:搜索引擎日志分析
一、Python基础语法
1、练习案例1:求钱包余额
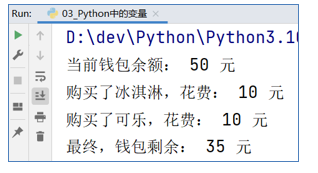
请在程序中定义如下变量:钱包余额(变量名:money),初始余额为50元。请通过程序计算,在购买了:冰淇淋10元,可乐5元后,钱包余额还剩余多少元。请通过print语句按照下图所示,进行输出:
代码如下:
# Day01 变量练习
money = 50
print("当前钱包余额:", money, "元")
# 冰淇淋10元
ice_cream = 10
print("购买冰淇淋,花费:", ice_cream, "元")
# 可乐5元
coke = 5
print("购买了可乐,花费:", coke, "元")
print("最终,钱包剩余:", money - ice_cream - coke, "元")
运行结果:
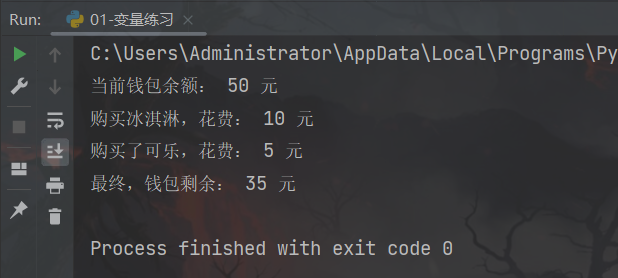
2、练习案例2:股价计算小程序
定义如下变量:name,公司名;stock_price,当前股价;stock_code,股票代码;stock_price_daily_growth_factor,股票每日增长系数,浮点数类型,比如1.2;growth_days,增长天数;计算经过growth_days天的增长后,股价达到了多少钱,使用字符串格式化进行输出,如果是浮点数,要求小数点精度2位数。
示例输出:

红色框框都是变量,要使用格式化的方式拼接进去
提示,可以使用: 当前股价 * 增长系数 ** 增长天数, 用来计算最终股价哦
如,股价19.99 * 系数1.2 ** 7天 = 71.62778419199998,小数点现在精度2位后结果:71.63
代码如下:
name = "传智播客" # 公司名
stock_price = 19.99 # 当前股价
stock_code = "003032" # 股票代码
stock_price_daily_growth_factor = 1.2 # 股票每日增长系数
growth_days = 7 # 增长天数
after_growth_price = stock_price * stock_price_daily_growth_factor ** growth_days
# f"{变量}的方式"
print(f"公司:{name},股票代码:{stock_code},当前股价:{stock_price}")
# % 占位符的方式
print("每日增长系数是:%.2f,经过%d天的增长后,股价达到了:%.2f" % (stock_price_daily_growth_factor, growth_days, after_growth_price))
运行结果:
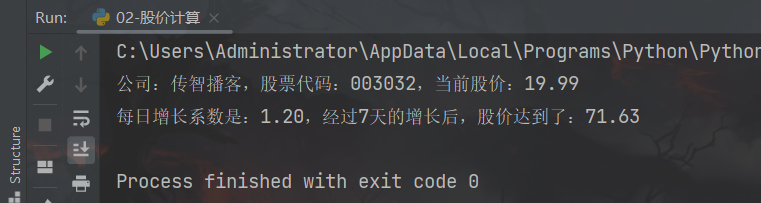
3、练习案例3:欢迎登陆小程序
定义两个变量,用以获取从键盘输入的内容,并给出提示信息:
变量1,变量名:user_name,记录用户名称
变量2,变量名:user_type,记录用户类型
并通过格式化字符串的形式,通过print语句输出欢迎信息,如下:

代码如下:
user_name = input("请输入用户名:")
user_type = input("请输入用户类型:")
print(f"您好:{user_name},您是尊贵的:{user_type}用户,欢迎您的光临!")
运行结果:
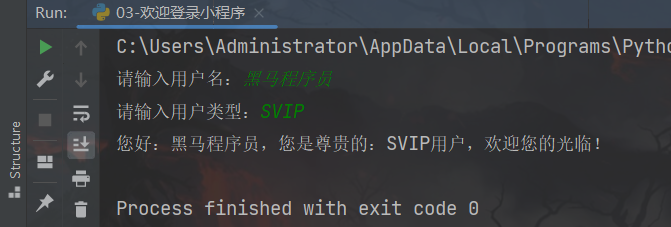
二、Python判断语句
1、练习案例1:成年人判断
结合前面学习的input输入语句,完成如下案例:
1、通过input语句,获取键盘输入,为变量age赋值。(注意转换成数字类型)
2、通过if判断是否是成年人,满足条件则输出提示信息,如下:

提示:您已成年,需要补票的信息输出,来自if判断
代码如下:
print("欢迎来到黑马儿童游乐场,儿童免费,成人收费")
# input获取键盘输入,转换成数字类型
age = int(input("请输入您的年龄:"))
# if判断
if age >= 18:
print("您已成年,游玩需要补票10元")
print("祝您游玩愉快!")
运行结果:
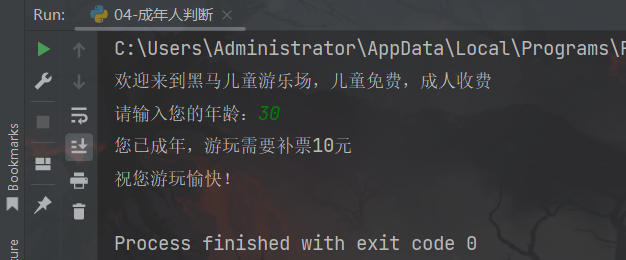
2、练习案例2:我要买票吗
通过input语句获取键盘输入的身高,判断身高是否超过120cm,并通过print给出提示信息。
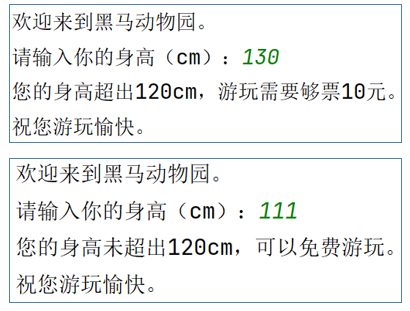
代码如下:
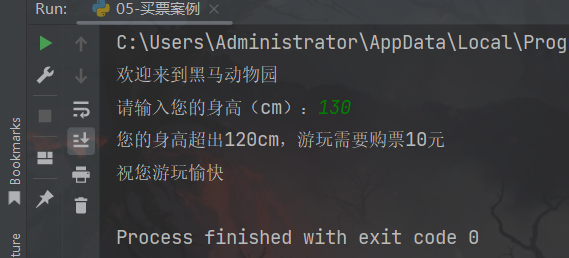
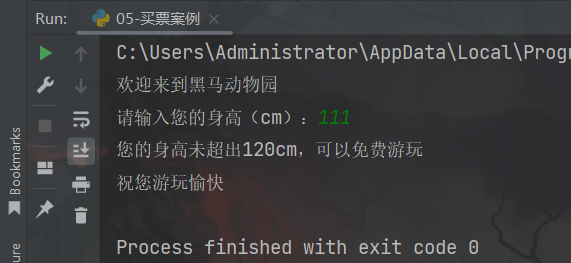
print("欢迎来到黑马动物园")
height = int(input("请输入您的身高(cm):"))
if height > 120:
print("您的身高超出120cm,游玩需要购票10元")
else:
print("您的身高未超出120cm,可以免费游玩")
print("祝您游玩愉快")
运行结果:
3、练习案例3:猜猜心里数字
- 定义一个变量,数字类型,内容随意。
- 基于input语句输入猜想的数字,通过if和多次elif的组合,判断猜想数字是否和心里数字一致。

代码如下:
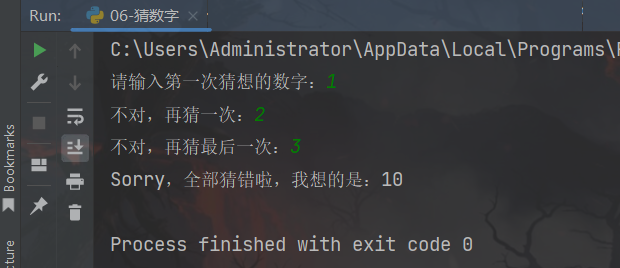
number = 10
if int(input("请输入第一次猜想的数字:")) == number:
print("第一次就猜对了!")
elif int(input("不对,再猜一次:")) == number:
print("猜对了!")
elif int(input("不对,再猜最后一次:")) == number:
print("终于猜对了!")
else:
print("Sorry,全部猜错啦,我想的是:%d" % number)
运行结果:
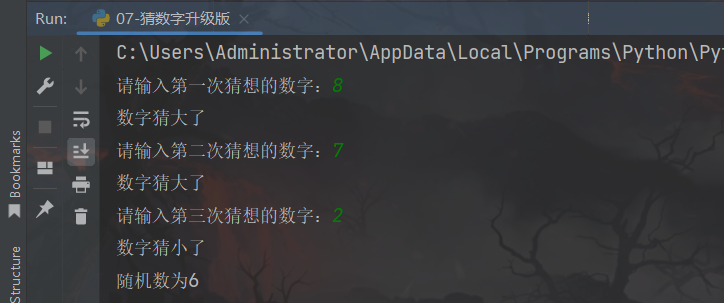
4、练习案例4:猜数字
定义一个数字(1~10,随机产生),通过3次判断来猜出来数字
1、数字随机产生,范围1-10
2、有3次机会猜测数字,通过3层嵌套判断实现
3、每次猜不中,会提示大了或小了
提示,通过如下代码,可以定义一个变量num,变量内存储随机数字。

代码如下:
# 未使用循环语句
import random
num = random.randint(1, 10)
num1 = int(input("请输入第一次猜想的数字:"))
if num1 == num:
print("恭喜你,猜对了!")
else:
if num1 > num:
print("数字猜大了")
else:
print("数字猜小了")
num2 = int(input("请输入第二次猜想的数字:"))
if num2 == num:
print("恭喜你,猜对了!")
else:
if num2 > num:
print("数字猜大了")
else:
print("数字猜小了")
num3 = int(input("请输入第三次猜想的数字:"))
if num3 == num:
print("恭喜你,猜对了!")
else:
if num3 > num:
print("数字猜大了")
else:
print("数字猜小了")
print(f"随机数为{num}")
运行结果:
三、Python循环语句
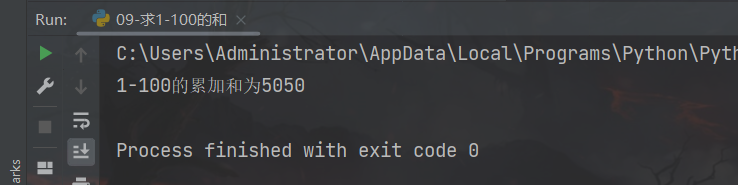
1、练习案例1:求1-100的和
通过while循环,计算从1累加到100的和
1、终止条件不要忘记,设置为确保while循环100次
2、确保累加的数字,从1开始,到100结束
代码如下:
result = 0
i = 1
while i <= 100:
result += i
i = i + 1
print("1-100的累加和为%d" % result)
运行结果:
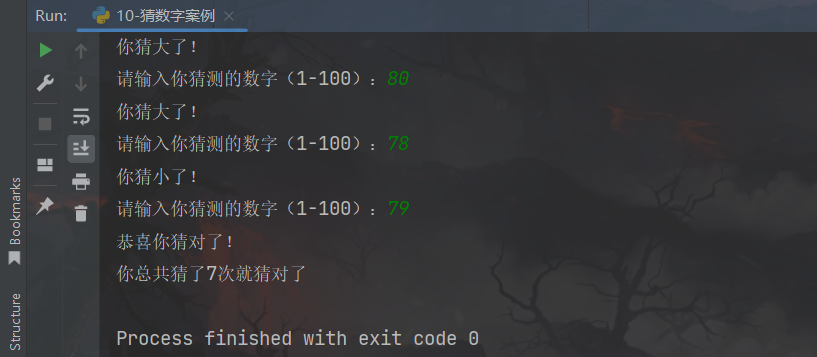
2、练习案例2:猜数字案例
设置一个范围1-100的随机整数变量,通过while循环,配合input语句,判断输入的数字是否等于随机数
1、无限次机会,直到猜中为止
2、每一次猜不中,会提示大了或小了
3、猜完数字后,提示猜了几次
代码如下:
import random
random_number = random.randint(1, 100) # 生成的随机数
guess_time = 0 # 记录猜测了几次
label = True # 是否结束循环的标志,猜对了就结束
while label:
usr_number = int(input("请输入你猜测的数字(1-100):")) # 获取用户猜测的数字
if random_number == usr_number:
print("恭喜你猜对了!")
label = False
elif random_number < usr_number:
print("你猜大了!")
else:
print("你猜小了!")
guess_time += 1
print(f"你总共猜了{guess_time}次就猜对了")
运行结果:
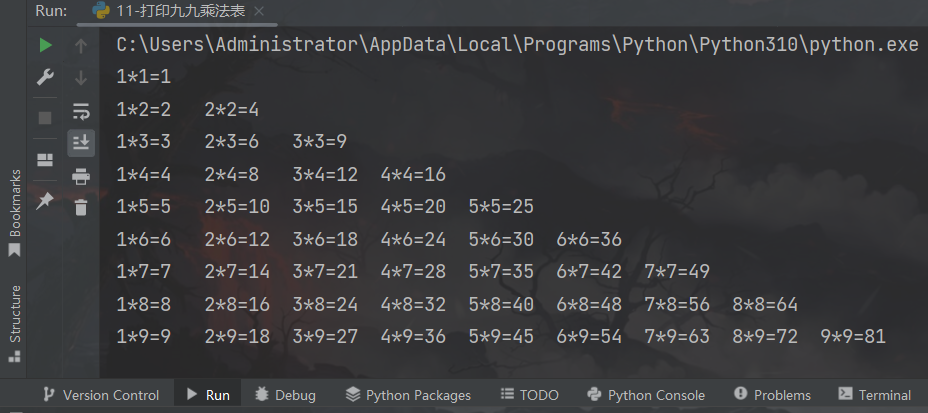
3、练习案例3:打印九九乘法表
通过while循环,输出如下九九乘法表内容

代码如下:
"""
打印九九乘法表
"""
i = 1 # 行数
while i <= 9:
j = 1 # 列数
while j <= i:
print(f"{j}*{i}={i * j}", end="\t")
j += 1
print()
i += 1
运行结果:
4、练习案例4:数一数有几个a
定义字符串变量name,内容为:“itheima is a brand of itcast”
通过for循环,遍历此字符串,统计有多少个英文字母:“a”

提示:
1、计数可以在循环外定义一个整数类型变量用来做累加计数
2、判断是否为字母"a",可以通过if语句结合比较运算符来完成
代码如下:
name = "itheima is a brand of itcast"
number = 0 # 用来统计个数
for x in name:
if x == "a":
number += 1
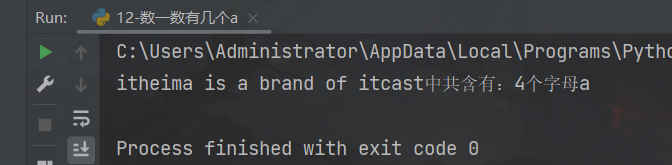
print(f"{name}中共含有:{number}个字母a")
运行结果:
5、练习案例5:有几个偶数
定义一个数字变量num,内容随意,并使用range()语句,获取从1到num的序列,使用for循环遍历它。在遍历的过程中,统计有多少偶数出现。

提示:
1、序列可以使用:range(1, num)得到
2、偶数通过if来判断,判断数字余2是否为0即可
代码如下:
num = int(input("请输入一个数字:"))
count = 0
for x in range(1, num):
if x % 2 == 0:
count += 1
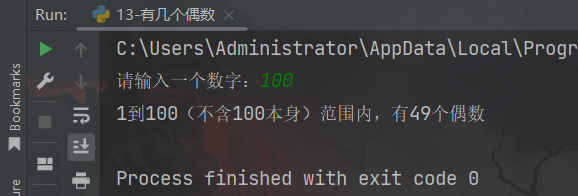
print(f"1到{num}(不含{num}本身)范围内,有{count}个偶数")
运行结果:
6、练习案例6:for循环打印九九乘法表
代码如下:
for i in range(1, 10):
for j in range(1, i + 1):
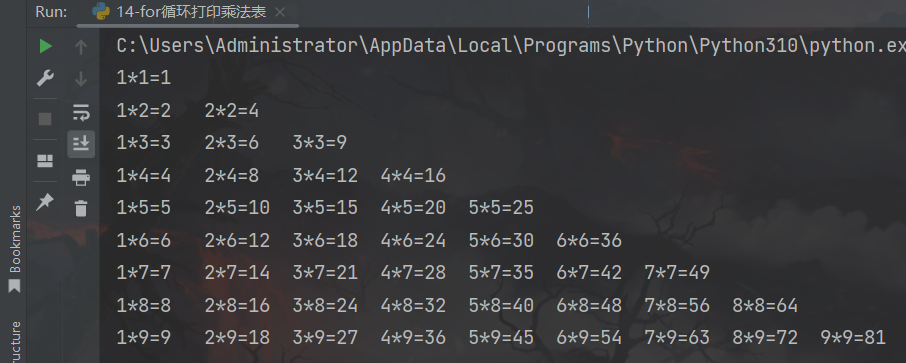
print(f"{j}*{i}={i * j}", end="\t")
print()
运行结果:
7、练习案例7:发工资
代码如下:
import random
balance = 10000 # 公司账户余额
for i in range(1, 21):
performance = random.randint(1, 10) # 随机绩效
if performance < 5:
print(f"员工{i},绩效分为{performance},低于5分,不发工资,下一位")
continue
else:
balance -= 1000
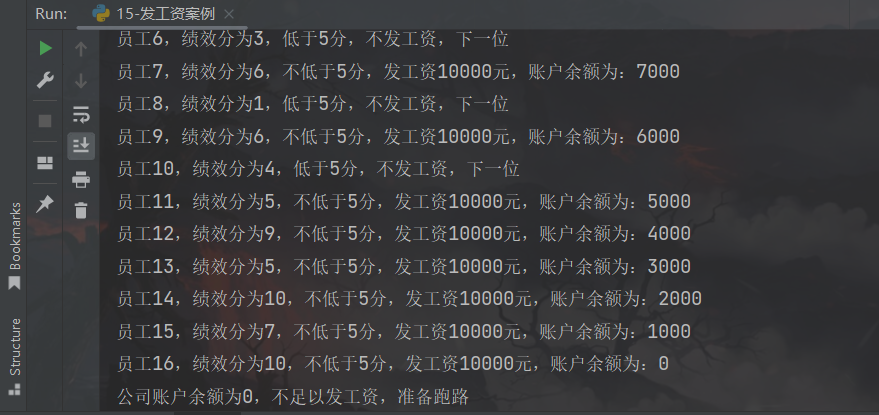
print(f"员工{i},绩效分为{performance},不低于5分,发工资10000元,账户余额为:{balance}")
if balance < 1000:
print(f"公司账户余额为{balance},不足以发工资,准备跑路")
break
运行结果:
四、Python函数
1、练习案例1:自动查核酸
代码如下:
def auto_check():
print("欢迎来到黑马程序员!")
print("请出示您的健康码以及72小时核酸证明")
auto_check()
运行结果:
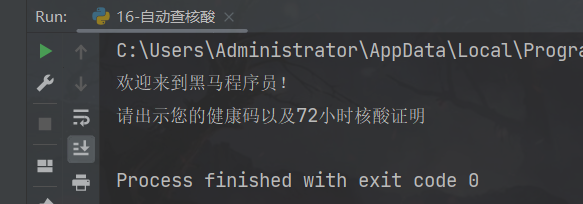
2、练习案例2:升级版自动查核酸
代码如下:
def auto_check(temperature):
print("欢迎来到黑马程序员!")
print("请出示您的健康码以及72小时核酸证明,并配合测量体温!")
if temperature <= 37.5:
print(f"体温测量中,您的体温是:{temperature}度,体温正常请进!")
else:
print(f"体温测量中,您的体温是:{temperature}度,体温异常,需要隔离!")
auto_check(float(input("请输入测试的体温:")))
运行结果:
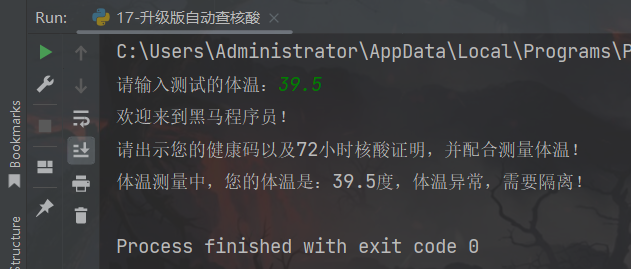
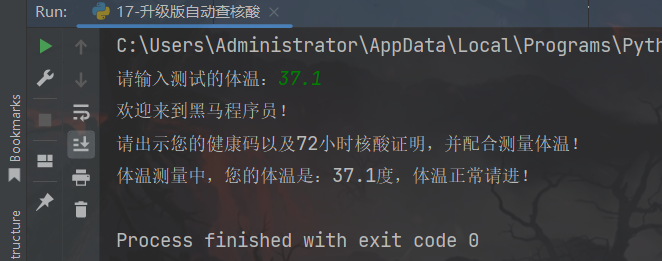
3、练习案例3:黑马ATM
代码如下:
money = 5000000 # 银行卡余额
name = None # 记录客户姓名
def begin():
"""
开始函数,用于检查账户密码等
"""
global name
name = input("欢迎登录本系统,请输入您的姓名:")
count = 0 # 记录密码错误的次数,超过三次,账户锁定
while True:
password = input("请输入你的账户密码:")
if password == "123456":
print("正在进入系统,请稍候......")
main_menu()
break
else:
print("密码错误,请重新输入!")
count += 1
if count == 3:
print("您已经3次输错账户密码,账户已被锁定,请联系工作人员!")
break
def check_balance():
"""
用于查询当前账户的余额
"""
print("-------------余额查询中,请稍候-------------")
print(f"{name},您好,您的余额为:{money}")
def deposit():
"""
用于进行存款操作
"""
global money
print("----------------存款界面----------------")
add_money = int(input("请将整理好的钞票放入入钞口:"))
print("正在验钞,请稍候......")
money = money + add_money
print(f"{name},您好,您存款{add_money}元成功")
print(f"{name},您好,您的余额为{money}")
def withdrawal():
"""
用于进行取款操作
"""
global money
print("----------------取款界面----------------")
sub_money = int(input("请输入你的取款金额:"))
if sub_money > money: # 判断账户余额是否足够
print(f"您当前账户余额为{money},账户余额不足!")
else:
print("请拿走您的钞票......")
money = money - sub_money
print(f"{name},您好,您取款{sub_money}元成功")
print(f"{name},您好,您的余额为{money}")
def main_menu():
"""
主菜单界面
"""
while True: # 确保程序可以一直执行
print("----------------主菜单----------------")
print(f"{name},您好,欢迎来到黑马银行ATM,请选择操作。")
print("查询余额\t[输入1]")
print("存款\t\t[输入2]")
print("取款\t\t[输入3]")
print("退出\t\t[输入4]")
choice = int(input("请输入您的选择:"))
if choice == 1:
check_balance()
elif choice == 2:
deposit()
elif choice == 3:
withdrawal()
else:
print("感谢您的使用,再见,祝您生活愉快!")
break # 用户选择退出或输入错误,程序结束
# 调用开始函数
begin()
运行结果:
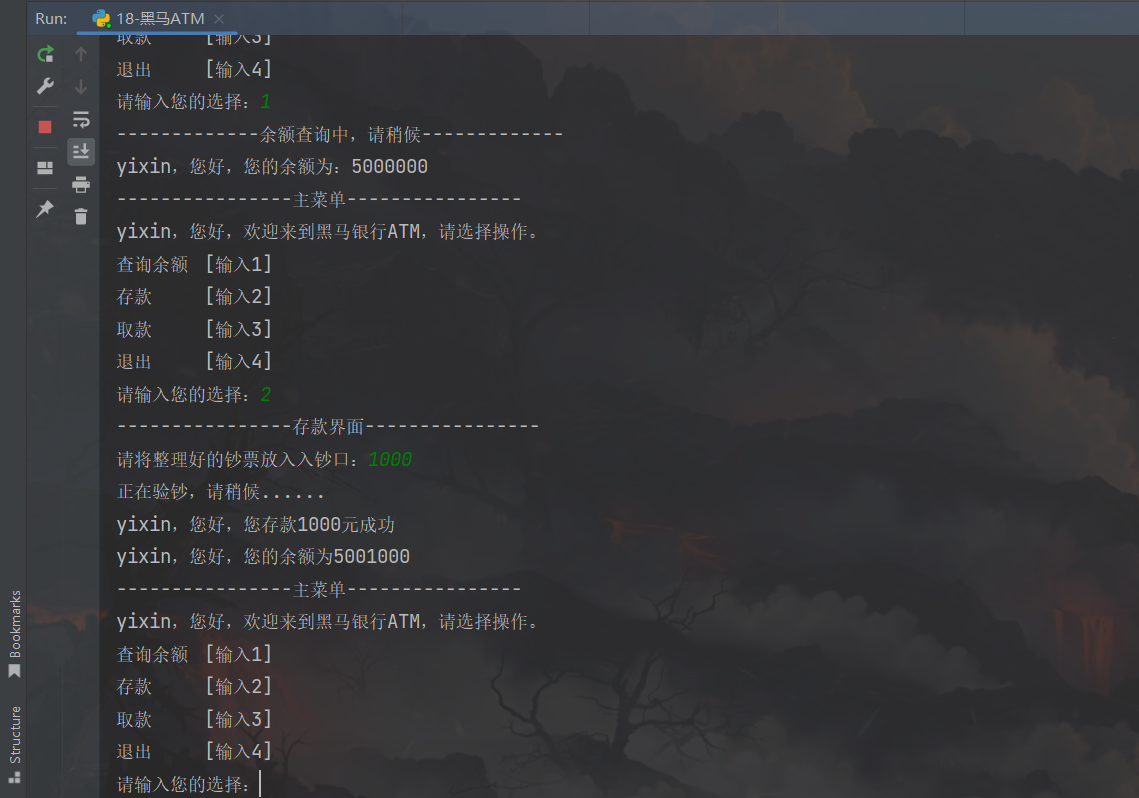
五、Python数据容器
1、练习案例1:列表常用功能练习
有一个列表,内容是:[21, 25, 21, 23, 22, 20],记录的是一批学生的年龄,请通过列表的功能(方法),对其进行:
- 定义这个列表,并用变量接收它
- 追加一个数字31,到列表的尾部
- 追加一个新列表[29, 33, 30],到列表的尾部
- 取出第一个元素(应是:21)
- 取出最后一个元素(应是:30)
- 查找元素31,在列表中的下标位置
代码如下:
mylist = [21, 25, 21, 23, 22, 20]
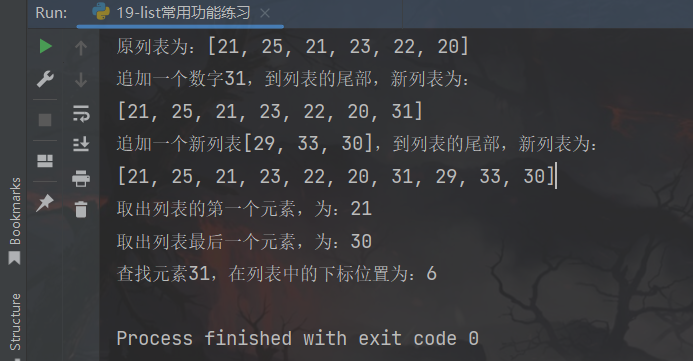
print(f"原列表为:{mylist}")
# 1、追加一个数字31,到列表的尾部
mylist.append(31)
print(f"追加一个数字31,到列表的尾部,新列表为:\n{mylist}")
# 2、追加一个新列表[29, 33, 30],到列表的尾部
mylist.extend([29, 33, 30])
print(f"追加一个新列表[29, 33, 30],到列表的尾部,新列表为:\n{mylist}")
# 3、取出第一个元素(应是:21)
print(f"取出列表的第一个元素,为:{mylist[0]}")
# 4、取出最后一个元素(应是:30)
print(f"取出列表最后一个元素,为:{mylist[-1]}")
# 5、查找元素31,在列表中的下标位置
print(f"查找元素31,在列表中的下标位置为:{mylist.index(31)}")
运行结果:
2、练习案例2:取出列表内的偶数
定义一个列表,内容是:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- 遍历列表,取出列表内的偶数,并存入一个新的列表对象中
- 使用while循环和for循环各操作一次
代码如下:
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
new_list = []
# while 方式
index = 0 # 计数器
while index < len(mylist):
if mylist[index] % 2 == 0:
new_list.append(mylist[index])
index += 1
print(f"通过while循环,从列表:{mylist}中取出偶数,组成新列表:{new_list}")
# 清空new_list
new_list.clear()
# for 方式
for element in mylist:
if element % 2 == 0:
new_list.append(element)
print(f"通过for循环,从列表:{mylist}中取出偶数,组成新列表:{new_list}")
运行结果:

3、练习案例3:元组的基本操作
定义一个元组,内容是:(‘周杰轮’, 11, [‘football’, ‘music’]),记录的是一个学生的信息(姓名、年龄、爱好),请通过元组的功能(方法),对其进行:
- 查询其年龄所在的下标位置
- 查询学生的姓名
- 删除学生爱好中的football
- 增加爱好:coding到爱好list内
代码如下:
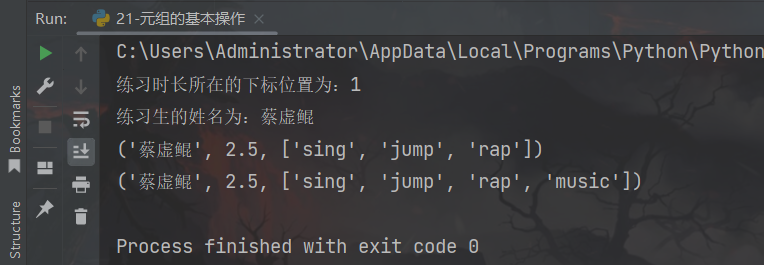
my_tuple = ('蔡虚鲲', 2.5, ['sing', 'jump', 'rap', 'basketball'])
# 1、查询其练习时长所在的下标位置
print(f"练习时长所在的下标位置为:{my_tuple.index(2.5)}")
# 2、查询练习生的姓名
print(f"练习生的姓名为:{my_tuple[0]}")
# 3、删除练习生爱好中的basketball
my_tuple[2].remove("basketball")
print(my_tuple)
# 4、增加爱好:增加music到爱好list内
my_tuple[2].append("music")
print(my_tuple)
运行结果:
4、练习案例4:分割字符串
给定一个字符串:“itheima itcast boxuegu”
- 统计字符串内有多少个"it"字符
- 将字符串内的空格,全部替换为字符:“|”
- 并按照"|"进行字符串分割,得到列表
代码如下:
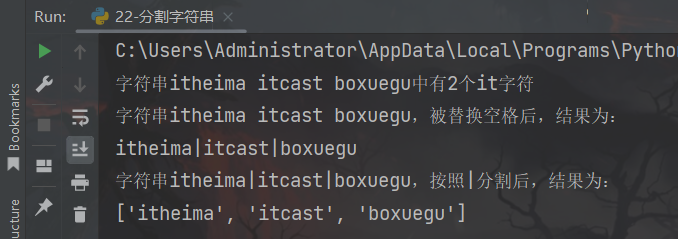
my_str = "itheima itcast boxuegu"
# 1、统计字符串内有多少个"it"字符
print(f"字符串{my_str}中有{my_str.count('it')}个it字符")
# 2、将字符串内的空格,全部替换为字符:"|"
new_str = my_str.replace(" ", "|")
print(f"字符串{my_str},被替换空格后,结果为:\n{new_str}")
# 3、并按照"|"进行字符串分割,得到列表
new_list = new_str.split("|")
print(f"字符串{new_str},按照|分割后,结果为:\n{new_list}")
运行结果:
5、练习案例5:序列的切片实践
有字符串:“万过薪月,员序程马黑来,nohtyP学”,请使用学过的任何方式,得到"黑马程序员"。可用方式参考:
- 倒序字符串,切片取出或切片取出,然后倒序
- split分隔"," replace替换"来"为空,倒序字符串
代码如下:
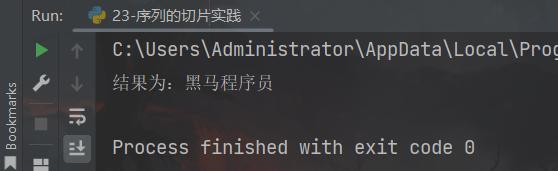
my_str = "万过薪月,员序程马黑来,nohtyP学"
# 1、倒序输出字符串
new_str = my_str[::-1]
# 2、记录字符串首字符的下标位置
index = new_str.index("黑")
# 3、切片得到结果
result = new_str[index:index + len("黑马程序员"):1]
# 4、输出结果
print(f"结果为:{result}")
运行结果:
6、练习案例6:信息去重
有如下列表对象:my_list = [‘黑马程序员’, ‘传智播客’, ‘黑马程序员’, ‘传智播客’, ‘itheima’, ‘itcast’, ‘itheima’, ‘itcast’, ‘best’]
- 定义一个空集合
- 通过for循环遍历列表
- 在for循环中将列表的元素添加至集合
- 最终得到元素去重后的集合对象,并打印输出
代码如下:
my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客', 'itheima', 'itcast', 'itheima', 'itcast', 'best']
my_set = set() # 定义一个空集合
for element in my_list:
my_set.add(element)
print(f"有列表:{my_list}")
print(f"存入集合后的结果为:{my_set}")
运行结果:

7、练习案例7:升职加薪
有如下员工信息,请使用字典完成数据的记录。并通过for循环,对所有级别为1级的员工,级别上升1级,薪水增加1000元。
| 姓名 | 部门 | 工资 | 级别 |
|---|---|---|---|
| 王力鸿 | 科技部 | 3000 | 1 |
| 周杰轮 | 市场部 | 5000 | 2 |
| 林俊节 | 市场部 | 7000 | 3 |
| 张学油 | 科技部 | 4000 | 1 |
| 刘德滑 | 市场部 | 6000 | 2 |
代码如下:
employee_information = {
"王力鸿": {
"部门": "科技部",
"工资": 3000,
"级别": 1
},
"周杰轮": {
"部门": "市场部",
"工资": 5000,
"级别": 2
},
"林俊节": {
"部门": "市场部",
"工资": 7000,
"级别": 3
},
"张学油": {
"部门": "科技部",
"工资": 4000,
"级别": 1
},
"刘德滑": {
"部门": "市场部",
"工资": 6000,
"级别": 2
}
}
print(f"原先的员工信息:\n{employee_information}")
for key in employee_information:
if employee_information[key]["级别"] == 1:
employee_information[key]["级别"] += 1
employee_information[key]["工资"] += 1000
print(f"升职加薪后的员工信息:\n{employee_information}")
运行结果:

8、练习案例8:第六章PPT作业题
幸运数字6:输入任意数字,如数字8,生成nums列表,元素值为1~8,从中选取幸运数字(能够被6整除)移动到新列表lucky,打印nums与lucky。
代码如下:
"""
幸运数字6:输入任意数字,如数字8,生成nums列表,元素值为1~8,
从中选取幸运数字(能够被6整除)移动到新列表lucky,打印nums与lucky。
"""
nums = []
lucky = []
number = int(input("请输入任意数字:"))
for x in range(1, number + 1):
nums.append(x)
print(f"nums列表为{nums}")
for element in nums:
if element % 6 == 0:
lucky.append(element)
print(f"lucky列表的内容为{lucky}")
运行结果:

列表嵌套:有3个教室[[],[],[]],8名讲师[‘A’,‘B’,‘C’,‘D’,‘E’,‘F’,‘G’,‘H’],将8名讲师随机分配到3个教室中。
代码如下(我只能列出部分结果,有其他解法的大佬可以评论区评论下):
"""
列表嵌套:有3个教室[[],[],[]],
8名讲师['A','B','C','D','E','F','G','H'],
将8名讲师随机分配到3个教室中(假设每个教室至少有一名讲师)
"""
teachers = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
new_list = [] # 过渡列表
result = [] # 结果列表
teachers_set = set(teachers) # 先转换成集合,方便后面随机取出元素
index = 0
while index < len(teachers):
new_list.append(teachers_set.pop())
index += 1
print(new_list)
# 将过度列表转换成这种形式[[],[],[]]
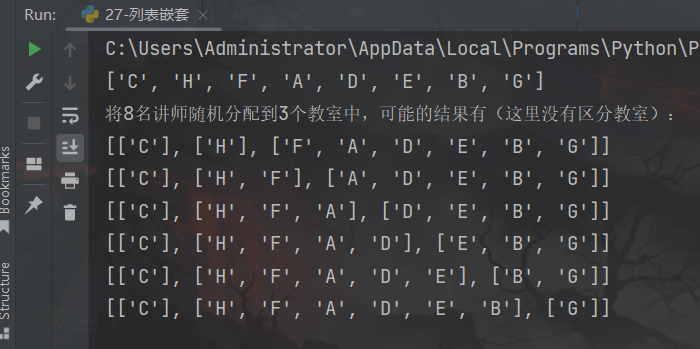
print("将8名讲师随机分配到3个教室中,可能的结果有(这里没有区分教室):")
count = 0
while count < 6:
result = []
result.append(new_list[:1])
result.append(new_list[1:2 + count])
result.append(new_list[2 + count:])
print(result)
count += 1
运行结果:
六、Python文件操作
1、练习案例1:单词计数
通过Windows的文本编辑器软件,将如下内容,复制并保存到:word.txt,文件可以存储在任意位置。
itheima itcast python
itheima python itcast
beijing shanghai itheima
shenzhen guangzhou itheima
wuhan hangzhou itheima
zhengzhou bigdata itheima
通过文件读取操作,读取此文件,统计itheima单词出现的次数。
代码如下:
count = 0 # 计数器
f = open("../data/word.txt", "r", encoding="UTF-8")
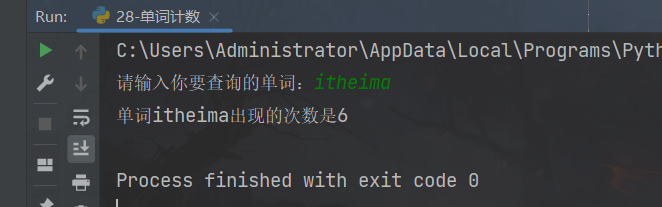
my_word = input("请输入你要查询的单词:")
for line in f:
word_list = line.strip().split(" ") # strip()除去字符串尾部的换行符
for word in word_list:
if word == my_word:
count += 1
print(f"单词{my_word}出现的次数是{count}")
f.close() # 关闭文件
运行结果:
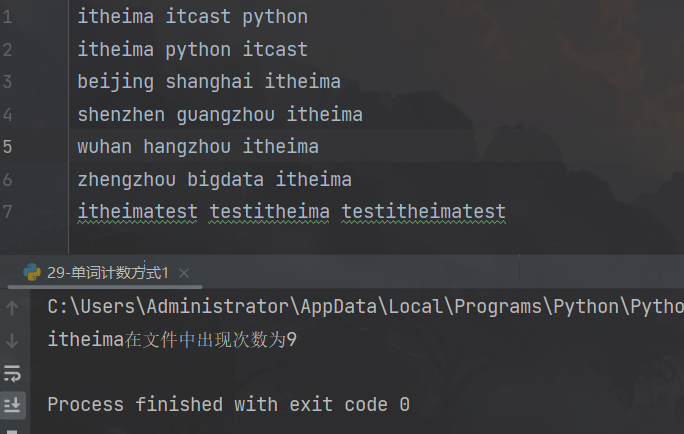
附:老师视频讲的方式1有些问题:如果文件中的某个单词含有“itheima”字段,也会被统计为单词“itheima”,例如单词“itheimatest”。
f = open("../data/word.txt", "r", encoding="UTF-8")
content = f.read()
count = content.count("itheima")
print(f"itheima在文件中出现次数为{count}")
f.close()
所以个人认为还是方式2比较严谨一些。
2、练习案例2:文件备份案例
有一份账单文件,记录了消费收入的具体记录。读取文件,将文件写出到bill.txt.bak文件作为备份;同时,将文件内标记为测试的数据行丢弃。
代码如下(有错误):
file_read = open("../data/bill.txt", "r", encoding="UTF-8")
file_write = open("../data/bill.txt.bak", "w", encoding="UTF-8")
for line in file_read:
if "测试" not in line:
file_write.write(line)
file_read.close()
file_write.close()
运行结果:
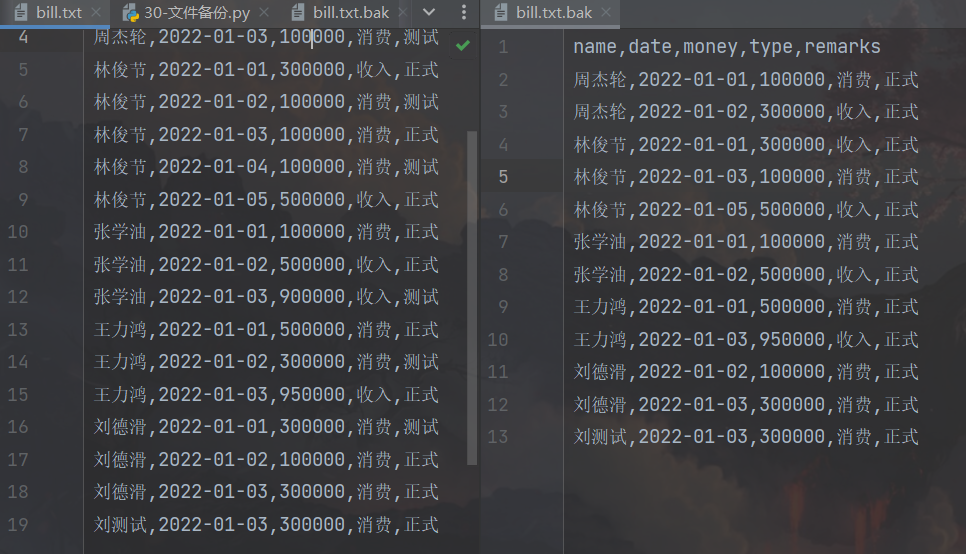
没看讲解之前,我是这样写的:如果“测试”没有在读出来的行中,就将此行写入备份文件。但是这样有一个问题,如果有个人叫“刘测试”,他的数据又是“正式”的,那我不会将他写入备份文件,这就和需求不一样了。
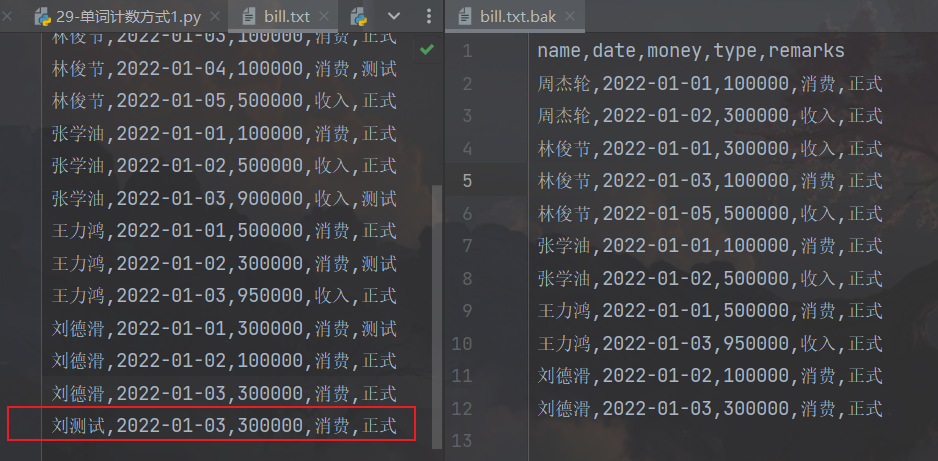
解决方法:还是精确到remark的位置,然后判断该位置是否为“测试”。修改后的代码如下:
file_read = open("../data/bill.txt", "r", encoding="UTF-8")
file_write = open("../data/bill.txt.bak", "w", encoding="UTF-8")
for line in file_read:
word_list = line.strip().split(",")
if word_list[-1] != "测试":
file_write.write(line)
file_read.close()
file_write.close()
七、Python异常、模块与包
1、练习案例1:自定义工具包
创建一个自定义包,名称为:my_utils (我的工具),在包内提供2个模块:
str_util.py (字符串相关工具,内含:)
- 函数:
str_reverse(s),接受传入字符串,将字符串反转返回 - 函数:
substr(s, x, y),按照下标x和y,对字符串进行切片
file_util.py(文件处理相关工具,内含:)
- 函数:
print_file_info(file_name),接收传入文件的路径,打印文件的全部内容,如文件不存在则捕获异常,输出提示信息,通过finally关闭文件对象 - 函数:
append_to_file(file_name, data),接收文件路径以及传入数据,将数据追加写入到文件中
代码如下:
str_util.py
"""
字符串相关工具
"""
def str_reverse(s):
"""
反转字符串
:param s: 待反转的字符串
:return: 反转后的字符串
"""
return s[::-1]
def substr(s, x, y):
"""
按照下标x和y,对字符串进行切片
:param s: 待切片的字符串
:param x: 切片的开始下标
:param y: 切片的结束下标
:return: 切片后得到的字符串
"""
return s[x:y]
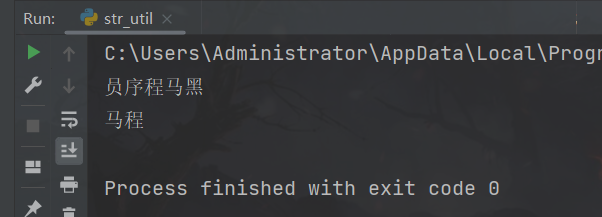
if __name__ == '__main__':
print(f"{str_reverse('黑马程序员')}")
print(f"{substr('黑马程序员', 1, 3)}")
file_util.py
"""
文件处理相关工具
"""
def print_file_info(file_name):
"""
将给定路径的文件的内容输出到控制台中
:param file_name:待读取的文件的路径
:return:None
"""
f = None
try:
f = open(file_name, "r", encoding="UTF-8")
print(f"文件的全部内容如下:\n{f.read()}")
except Exception as e:
print(f"程序出现异常了,原因是:{e}")
finally:
if f: # 如果报异常了,这里的f就是None,就没有必要执行f.close()了
f.close()
def append_to_file(file_name, data):
"""
将指定的内容追加到指定的文件中
:param file_name: 待写入的文件
:param data: 写入的内容
:return: None
"""
f = open(file_name, "a", encoding="UTF-8")
f.write(data)
f.write("\n")
f.close()
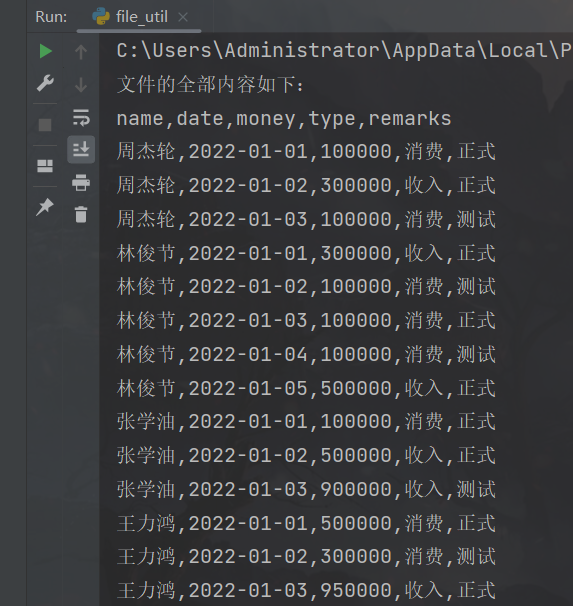
if __name__ == '__main__':
print_file_info("../data/bill.txt")
append_to_file("../data/test_append.txt", "测试函数功能")
效果展示:
八、Python数据可视化
1、练习案例1:折线图可视化
代码如下:
"""
折线图开发
"""
import json
from pyecharts.charts import Line
from pyecharts.options import *
# 数据预处理
f_us = open("data/美国.txt", "r", encoding="UTF-8")
us_data = f_us.read()
f_jp = open("data/日本.txt", "r", encoding="UTF-8")
jp_data = f_jp.read()
f_in = open("data/印度.txt", "r", encoding="UTF-8")
in_data = f_in.read()
# 删除不符合JSON规范的开头和结尾
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
us_data = us_data[:-2]
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
jp_data = jp_data[:-2]
in_data = in_data.replace("jsonp_1629350745930_63180(", "")
in_data = in_data[:-2]
# JSON转python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,截取2020年的数据(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]
# 获取确认数据,用于y轴,截取2020年的数据(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]
# 生成图表
line = Line() # 构建折线图对象
# 添加x轴数据
line.add_xaxis(us_x_data)
# 添加y轴数据
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False))
# 设置全局选项
line.set_global_opts(
# 设置标题
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)
# 调用render方法,生成图表
line.render()
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()
效果展示:

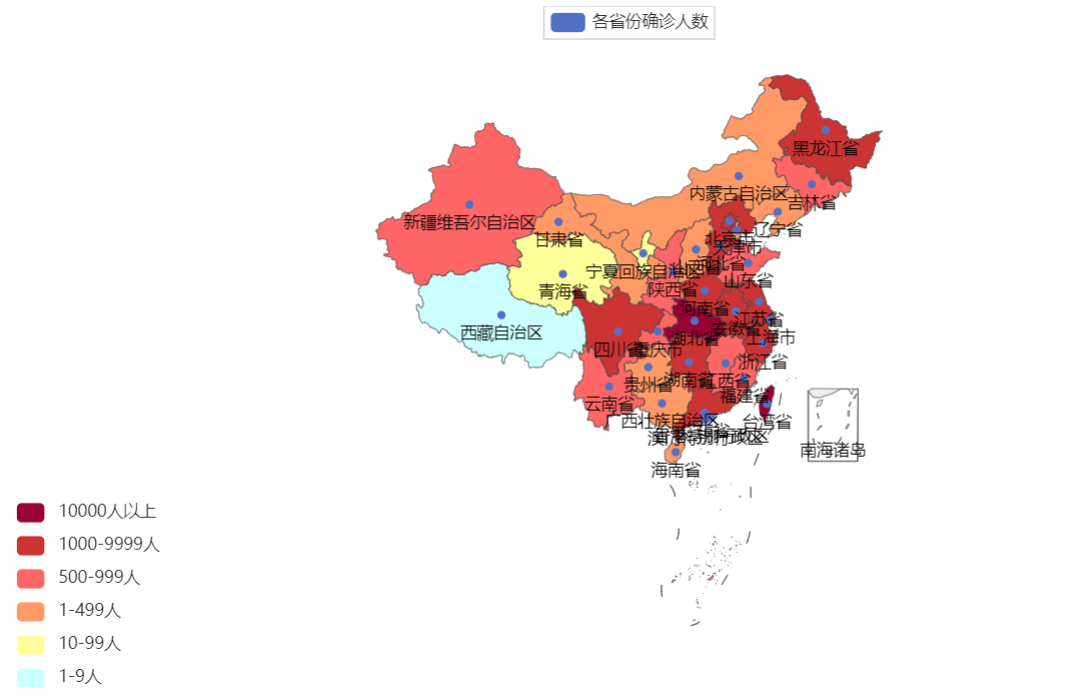
2、练习案例2:地图可视化
全国疫情情况可视化地图
代码如下:
"""
全国疫情可视化地图开发
"""
import json
from pyecharts.charts import *
from pyecharts.options import *
# 读取数据文件
f = open("data/疫情.txt", "r", encoding="UTF-8")
data = f.read()
# 关闭文件
f.close()
# 取到各省数据
# 将字符串json转换为python的字典
data_dict = json.loads(data)
# 从字典中取出省份的数据
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并将各个省的数据都封装到列表内
data_list = [] # 绘图要用到的数据列表
for province_data in province_data_list:
province_name = province_data["name"]
province_confirm = province_data["total"]["confirm"]
data_list.append((province_name, province_confirm))
print(data_list)
# 创建地图对象
my_map = Map()
# 添加数据
my_map.add("各省份确诊人数", data_list, "china")
# 设置全局变量,定制分段的视觉映射
my_map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min": 1, "max": 9, "label": "1-9人", "color": "#CCFFFF"},
{"min": 10, "max": 99, "label": "10-99人", "color": "#FFFF99"},
{"min": 100, "max": 499, "label": "1-499人", "color": "#FF9966"},
{"min": 500, "max": 999, "label": "500-999人", "color": "#FF6666"},
{"min": 1000, "max": 9999, "label": "1000-9999人", "color": "#CC3333"},
{"min": 10000, "label": "10000人以上", "color": "#990033"},
]
)
)
# 绘图
my_map.render()
效果展示:
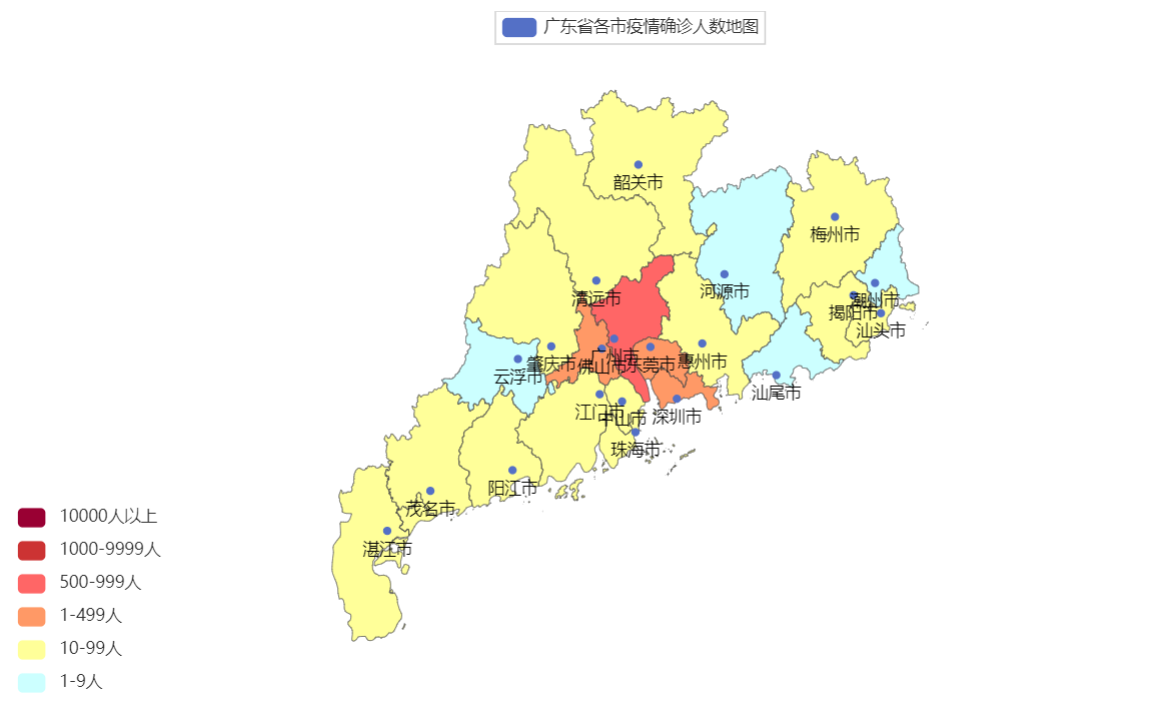
广东省疫情可视化地图
代码如下:
# 打开文件,获取数据
import json
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
f = open("data/疫情.txt", "r", encoding="UTF-8")
data = f.read()
# 关闭文件
f.close()
# 将json文件数据转换成python字典
data_dict = json.loads(data)
# 得到广东省的数据
data_gd = data_dict["areaTree"][0]["children"][7]["children"]
# 取出省内各市的名称以及各市的确诊人数,组合成二元组列表
data_list_gd = []
for city in data_gd:
city_name = city["name"] + "市"
city_confirm = city["total"]["confirm"]
data_list_gd.append((city_name, city_confirm))
data_list_gd.append(("云浮市", 2))
# 绘图
map_gd = Map()
map_gd.add("广东省各市疫情确诊人数地图", data_list_gd, "广东")
# 设置全局变量,定制分段的视觉映射
map_gd.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min": 1, "max": 9, "label": "1-9人", "color": "#CCFFFF"},
{"min": 10, "max": 99, "label": "10-99人", "color": "#FFFF99"},
{"min": 100, "max": 499, "label": "1-499人", "color": "#FF9966"},
{"min": 500, "max": 999, "label": "500-999人", "color": "#FF6666"},
{"min": 1000, "max": 9999, "label": "1000-9999人", "color": "#CC3333"},
{"min": 10000, "label": "10000人以上", "color": "#990033"},
]
)
)
map_gd.render("广东省各市疫情确诊人数地图.html")
效果展示:
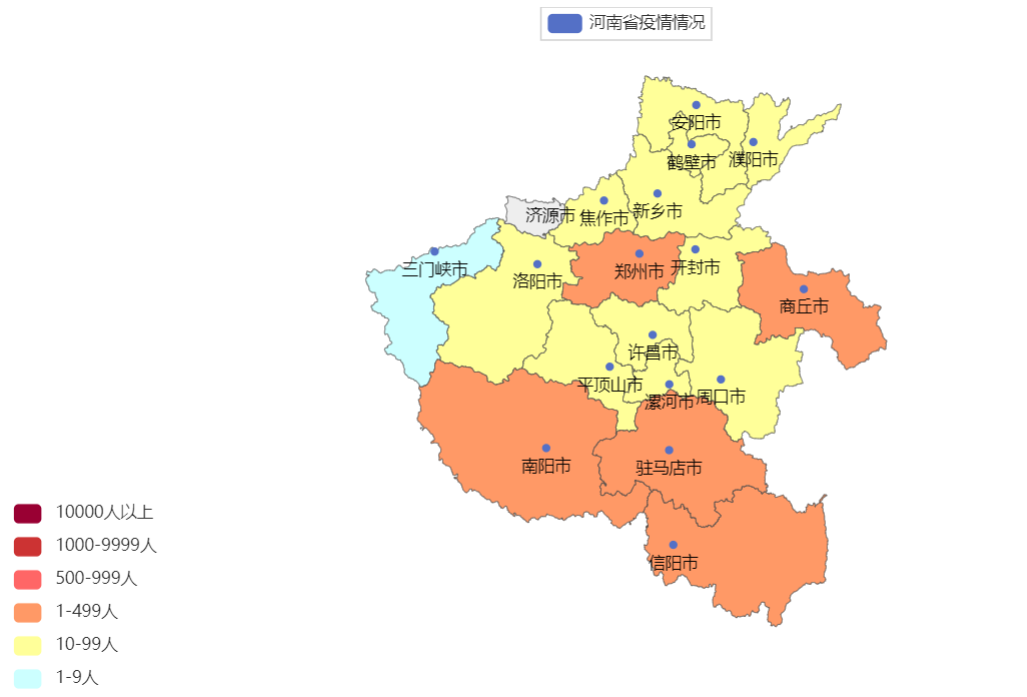
河南省疫情可视化地图
代码如下:
# 读取文件
import json
from pyecharts.charts import *
from pyecharts.options import VisualMapOpts
f = open("data/疫情.txt", "r", encoding="UTF-8")
data = f.read()
# 关闭文件
f.close()
# 获取河南省数据
# json数据转换为python字典
data_dict = json.loads(data)
# 取到河南省数据
cities_data = data_dict["areaTree"][0]["children"][3]["children"]
# 准备数据为元组并放入list
data_list = []
for city_data in cities_data:
city_name = city_data["name"] + "市"
city_confirm = city_data["total"]["confirm"]
data_list.append((city_name, city_confirm))
# 构建地图
hena_map = Map()
hena_map.add("河南省疫情情况", data_list, "河南")
# 设置全局变量,定制分段的视觉映射
hena_map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min": 1, "max": 9, "label": "1-9人", "color": "#CCFFFF"},
{"min": 10, "max": 99, "label": "10-99人", "color": "#FFFF99"},
{"min": 100, "max": 499, "label": "1-499人", "color": "#FF9966"},
{"min": 500, "max": 999, "label": "500-999人", "color": "#FF6666"},
{"min": 1000, "max": 9999, "label": "1000-9999人", "color": "#CC3333"},
{"min": 10000, "label": "10000人以上", "color": "#990033"},
]
)
)
hena_map.render()
效果展示:
3、练习案例3:动态柱状图
通过pyechars可以实现数据的动态显示, 直观的感受1960~2019年全世界各国GDP的变化趋势
代码如下:
"""
GDP动态柱状图
"""
from pyecharts.charts import *
from pyecharts.options import *
from pyecharts.globals import *
# 读取数据
f = open("data/1960-2019全球GDP数据.csv", "r", encoding="GB2312")
data_lines = f.readlines()
# 关闭文件
f.close()
# 删除表头
data_lines.pop(0)
# 将数据转换成字典存储,格式为:{ 年份:[[国家,GDP], [国家,GDP], ......], 年份:[[国家,GDP], [国家,GDP], ......], ...... }
data_dict = {} # 定义一个字典对象
for line in data_lines:
year = int(line.split(",")[0]) # 年份
country = line.split(",")[1] # 国家
gdp = float(line.split(",")[2]) # gdp数值
try:
data_dict[year].append([country, gdp])
except KeyError:
data_dict[year] = []
data_dict[year].append([country, gdp])
# 创建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT})
# 排序年份
sorted_year_list = sorted(data_dict.keys())
for sorted_year in sorted_year_list:
data_dict[sorted_year].sort(key=lambda element: element[1], reverse=True)
# 取出该年份GDP前8名的国家
year_data = data_dict[sorted_year][0:8]
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0]) # x轴添加国家
y_data.append(country_gdp[1] / 100000000) # y轴添加gdp数据
# 构建柱状图
bar = Bar()
x_data.reverse()
y_data.reverse()
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right"))
bar.reversal_axis() # 反转x轴和y轴
bar.set_global_opts(
title_opts=TitleOpts(title=f"{sorted_year}年全球GDP前8的国家")
) # 设置标题
timeline.add(bar, str(sorted_year)) # 将bar对象添加到时间线中
# 设置时间线自动播放
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=False
)
# 绘制柱状图
timeline.render("1960-2019全球GDP前8国家.html")
效果展示:

九、面向对象
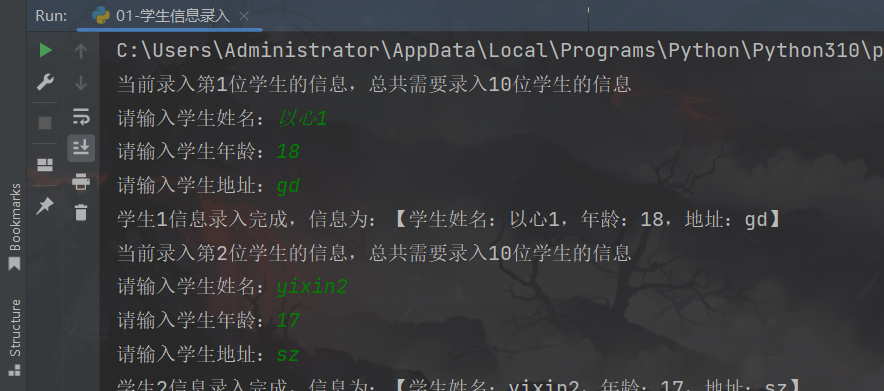
1、练习案例1:学生信息录入
开学了,有一批学生信息需要录入系统,请设计一个类,记录学生的:姓名、年龄、地址,这3类信息。
- 通过 for 循环,配合 input 输入语句,并使用构造方法,完成学生信息的键盘录入
- 输入完成后,使用 print 语句,完成信息的输出
代码如下:
"""
学生信息录入
"""
# 创建类
class Student:
name = None
age = None
address = None
# 使用构造方法
def __init__(self):
self.name = input("请输入学生姓名:")
self.age = int(input("请输入学生年龄:"))
self.address = input("请输入学生地址:")
# for循环录入信息并输出
for i in range(1, 11):
print(f"当前录入第{i}位学生的信息,总共需要录入10位学生的信息")
# 创建类对象
stu = Student()
print(f"学生{i}信息录入完成,信息为:【学生姓名:{stu.name},年龄:{stu.age},地址:{stu.address}】")
运行结果:
2、练习案例2:设计带有私有成员的手机
设计一个手机类,内部包含:
私有成员变量:__is_5g_enable,类型bool,True表示开启5g,False表示关闭5g
私有成员方法:__check_5g(),会判断私有成员__is_5g_enable的值
- 若为True,打印输出:5g开启
- 若为False,打印输出:5g关闭,使用4g网络
公开成员方法:call_by_5g(),调用它会执行
调用私有成员方法:__check_5g(),判断5g网络状态,打印输出:正在通话中
通过完成这个类的设计和使用,体会封装中私有成员的作用
- 对用户公开的,
call_by_5g()方法 - 对用户隐藏的,
__is_5g_enable私有变量和__check_5g私有成员
代码如下:
"""
设计带有私有成员的手机
"""
# 创建类
class Phone:
__is_5g_enable = False
def __check_5g(self):
if self.__is_5g_enable is True:
print("5g开启")
else:
print("5g关闭,使用4g网络")
def call_by_5g(self):
self.__check_5g()
print("正在通话中")
# 创建类对象
phone = Phone()
phone.call_by_5g()
运行结果:

3、练习案例3:数据分析案例
某公司,有2份数据文件,现需要对其进行分析处理,计算每日的销售额并以柱状图表的形式进行展示。
数据内容:
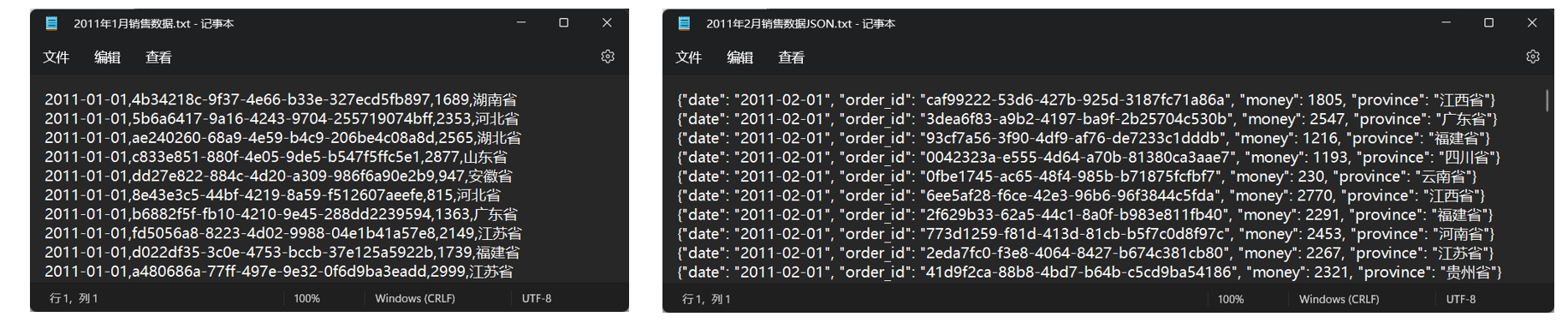
- 1月份数据是普通文本,使用逗号分割数据记录,从前到后分别是(日期,订单id,销售额,销售省份)
- 2月份数据是JSON数据,同样包含(日期,订单id,销售额,销售省份)
需求分析:
代码如下:
file_define.py
"""
和文件相关的类定义
"""
import json
from data_define import Record
# 先定义一个抽象类用来做顶层设计,确定有哪些功能需要实现
class FileReader:
def read_data(self) -> list[Record]:
""" 读取文件的数据,读到的每一条数据都转换为Record对象,将它们都封装到list内返回 """
pass
class TextFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
# 复写父类的方法
def read_data(self) -> list[Record]:
record_list: list[Record] = []
f = open(self.path, "r", encoding="UTF-8")
for line in f.readlines():
line = line.strip() # 消除读取到的每一行数据中的\n
data_list = line.split(",")
record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])
record_list.append(record)
f.close() # 关闭文件
return record_list
class JsonFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
# 复写父类的方法
def read_data(self) -> list[Record]:
record_list: list[Record] = []
f = open(self.path, "r", encoding="UTF-8")
for line in f.readlines():
data_dict = json.loads(line)
record = Record(data_dict["date"], data_dict["order_id"], int(data_dict["money"]), data_dict["province"])
record_list.append(record)
f.close() # 关闭文件
return record_list
if __name__ == '__main__':
text_file_reader = TextFileReader("data/2011年1月销售数据.txt")
json_file_reader = JsonFileReader("data/2011年2月销售数据JSON.txt")
list1 = text_file_reader.read_data()
list2 = json_file_reader.read_data()
for l1 in list1:
print(l1)
for l2 in list2:
print(l2)
data_define.py
"""
数据定义的类
"""
class Record:
def __init__(self, date, order_id, money, province):
self.date = date # 订单日期
self.order_id = order_id # 订单ID
self.money = money # 订单金额
self.province = province # 销售金额
def __str__(self):
return f"{self.date},{self.order_id},{self.money},{self.province}"
main.py
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
from pyecharts.options import *
from file_define import *
text_file_reader = TextFileReader("data/2011年1月销售数据.txt")
json_file_reader = JsonFileReader("data/2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将两个月的数据合并成一个list存储
all_data: list[Record] = jan_data + feb_data
# 开始进行数据计算,使用字典进行操作
# {'2011-01-01': 59242, '2011-01-02': 58479, '2011-01-03': 52336, ...}
data_dict = {}
for record in all_data:
if record.date in data_dict.keys():
# 当前日期已经有记录了,所以和老记录做累加即可
data_dict[record.date] += record.money
else:
data_dict[record.date] = record.money
# print(data_dict)
# 可视化图表开发
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys())) # 添加x轴的数据
bar.add_yaxis("销售额", list(data_dict.values()), label_opts=LabelOpts(is_show=False)) # 添加y轴数据
bar.set_global_opts(
title_opts=TitleOpts(title="每日销售额"),
xaxis_opts=AxisOpts(axislabel_opts={"rotate": 45})
)
bar.render("每日销售额柱状图.html")
效果展示:
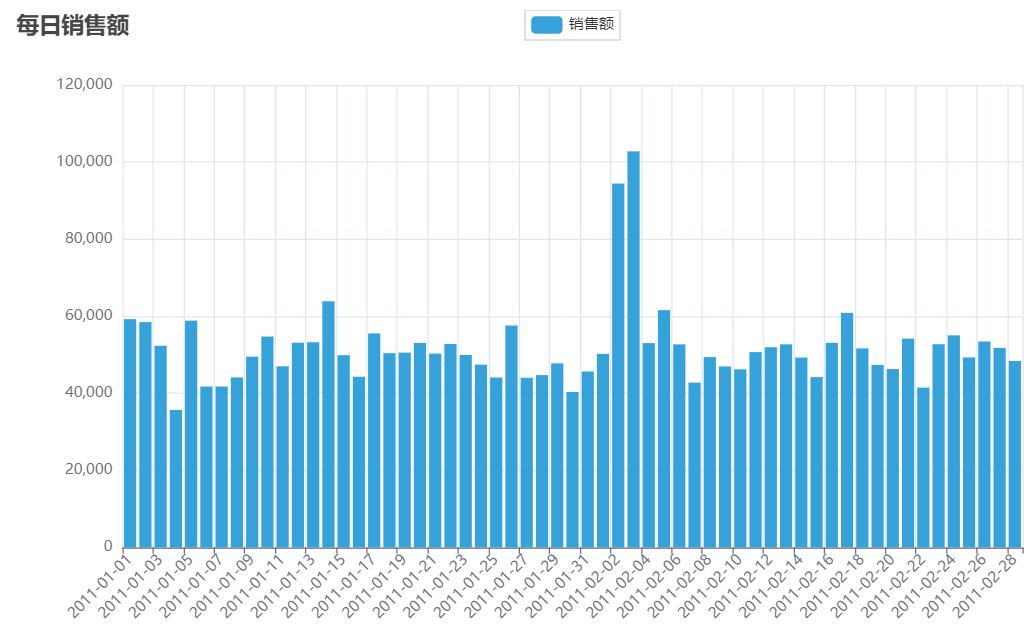
十、PySpark
1、练习案例1:WordCount案例
读取文件,统计文件内,单词的出现数量
代码如下:
from pyspark import SparkConf, SparkContext
import os
# 构建执行环境入口对象
os.environ['PYSPARK_PYTHON'] = "C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test1")
sc = SparkContext(conf=conf)
# 读取数据文件
rdd = sc.textFile("../../data/word.txt")
# 取出全部单词
word_rdd = rdd.flatMap(lambda x: x.split(" "))
word_tuple_rdd = word_rdd.map(lambda word: (word, 1))
result_rdd = word_tuple_rdd.reduceByKey(lambda a, b: a + b)
print(result_rdd.collect())
sc.stop()
运行结果:

2、练习案例2:城市销售分析统计案例
使用Spark读取文件进行计算:
- 各个城市销售额排名,从大到小
- 全部城市,有哪些商品类别在售卖
- 北京市有哪些商品类别在售卖
代码如下:
import json
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test2")
sc = SparkContext(conf=conf)
# 读取文件得到rdd
file_rdd = sc.textFile("../../data/orders.txt")
# 取出一个个JSON字符串,转换成字典
json_str_rdd = file_rdd.flatMap(lambda x: x.split("|"))
dict_rdd = json_str_rdd.map(lambda x: json.loads(x))
# TODO 需求1:城市销售额排名
# 取出城市和销售额,组成二元组(城市, 销售额)
city_money_rdd = dict_rdd.map(lambda x: (x["areaName"], int(x["money"])))
# 按城市分组,按销售额聚合
city_result_rdd = city_money_rdd.reduceByKey(lambda a, b: a + b)
# 按销售额聚合结果进行排序
result1_rdd = city_result_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1)
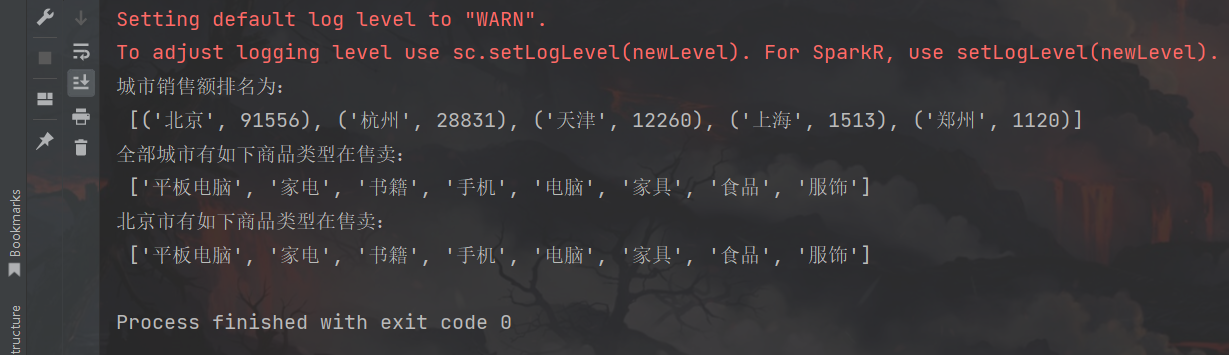
print("城市销售额排名为:\n", result1_rdd.collect())
# TODO 需求2:全部城市有哪些商品类型在售卖
result2_rdd = dict_rdd.map(lambda x: x['category']).distinct()
print("全部城市有如下商品类型在售卖:\n", result2_rdd.collect())
# TODO 需求3:北京市有哪些商品类型在售卖
result3_rdd = dict_rdd.filter(lambda x: x['areaName'] == "北京").map(lambda x: x['category']).distinct()
result3_rdd.saveAsTextFile("../../data/test")
print("北京市有如下商品类型在售卖:\n", result3_rdd.collect())
sc.stop()
运行结果:
3、练习案例3:搜索引擎日志分析
读取文件转换成RDD,并完成:
- 打印输出:热门搜索时间段(小时精度)Top3
- 打印输出:热门搜索词Top3
- 打印输出:统计黑马程序员关键字在哪个时段被搜索最多
- 将数据转换为JSON格式,写出为文件
代码如下:
from pyspark import SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("last_test")
conf.set("spark.default.parallelism", "1")
sc = SparkContext(conf=conf)
# 读取文件转换成RDD
file_rdd = sc.textFile("../../data/search_log.txt")
# TODO 需求1:热门搜索时间段Top3(精度为小时)
result1 = file_rdd.map(lambda x: (x.split("\t")[0][:2], 1))\
.reduceByKey(lambda a, b: a + b)\
.sortBy(lambda x: x[1], ascending=False, numPartitions=1)\
.take(3)
print("热门搜索时间段Top3为:", result1)
# TODO 需求2:热门搜索词Top3
result2 = file_rdd.map(lambda x: (x.split("\t")[2], 1))\
.reduceByKey(lambda a, b: a + b).sortBy(lambda x: x[1], ascending=False, numPartitions=1)\
.take(3)
print("热门搜索词Top3为:", result2)
# TODO 需求3:统计黑马程序员关键字在什么时段被搜索最多
result3 = file_rdd.map(lambda x: x.split("\t"))\
.filter(lambda x: x[2] == "黑马程序员")\
.map(lambda x: (x[0][:2], 1))\
.reduceByKey(lambda a, b: a + b)\
.sortBy(lambda x: x[1], ascending=False, numPartitions=1)\
.take(1)
print("黑马程序员关键字在以下时段被搜索最多:", result3)
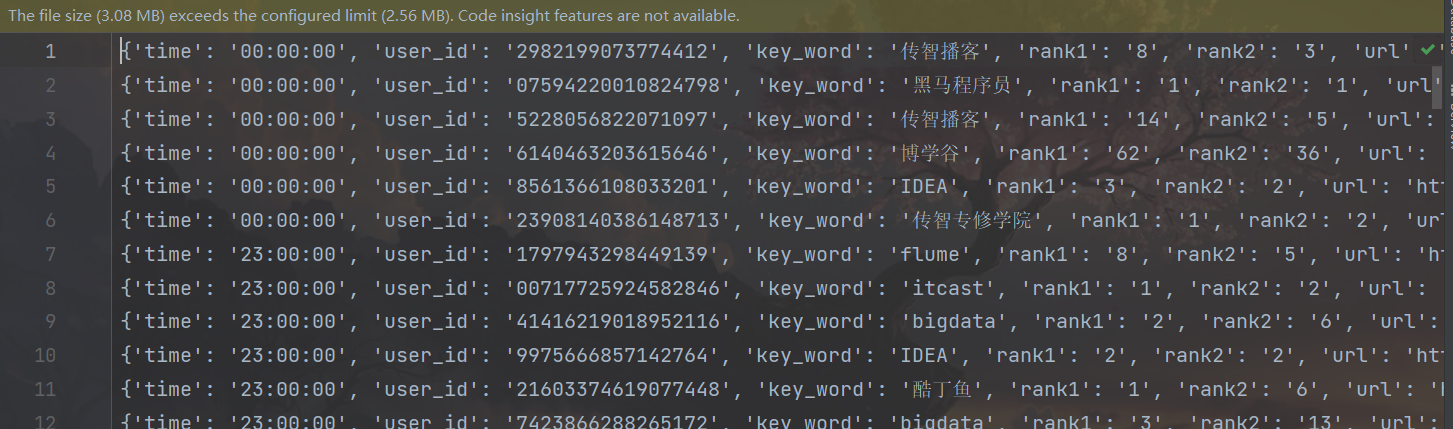
# TODO 需求4:将数据转换成JSON格式,输出到文件中
file_rdd.map(lambda x: x.split("\t"))\
.map(lambda x: {"time": x[0], "user_id": x[1], "key_word": x[2], "rank1": x[3], "rank2": x[4], "url": x[5]})\
.saveAsTextFile("../../output_json")
sc.stop()
运行结果: