一、背景
完善的监控系统可以提高应用的可用性和可靠性,在提供更优质服务的前提下,降低运维的投入和工作量,为用户带来更多的商业利益和客户体验。下面就带大家彻底搞懂监控系统,使用Prometheus +Grafana搭建完整的应用监控系统。
二、监控系统简介
1.1 什么是监控系统?
监控系统顾名思义就是监控服务器、应用系统以及其他第三方组件运行状态的系统。对于平台系统而言,监控系统就是我们第三只眼,监控系统会实时跟踪应用平台的运行状态,如果有应用系统出现问题或是服务器内存爆满,我们通过监控系统就可以快速定位问题所在,甚至可以设置预警,对一些将要出现的问题进行提前预防处理,及时避免问题的发生。
1.2 监控系统的作用
监控是运维系统的基础,我们衡量一个公司/部门的运维水平,看他们的监控系统就可以了。监控系统的作用不言而喻,能帮我们快速定位问题,减少故障,容量规划,性能优化等。
1)定位故障:在发生故障时,我们可以通过查看监控系统的各项指标数据,辅助故障分析和定位。
2)减少故障率:对于即将可能产生的故障能够及时发出预警信息,做好提前预防处理。
3)容量规划:为服务器、中间件以及应用集群的容量规划提供数据支撑。
4)性能调优:JVM垃圾回收次数、接口响应时间、慢SQL等等都可以监控优化。
总而言之,一个完善的监控系统可以提高应用的可用性和可靠性,在提供更优质服务的前提下,降低运维的投入和工作量,为用户带来更多的商业利益和客户体验。
1.3 常见的监控对象和指标都有哪些?
应用系统的监控主要分为指标监控和日志监控两大部分:
(1)指标监控主要是对一定时间段内性能指标进行测量,然后再通过时间序列的方式,进行处理、存储和告警。
(2)日志监控则可以提供更详细的上下文信息,通常通过 ELK 技术栈来进行收集、索引和图形化展示。
指标监控可以说是系统监控最核心的功能。主要有服务器资源、应用监控、数据库中间件等。
- 服务器资源监控:CPU使用率、内存使用率、磁盘使用率、磁盘读写的吞吐量、网络出入流量等等。
- 数据库监控:TPS、QPS、数据库连接数、慢SQL、InnoDB缓冲池命中率等。
- Redis监控:内存使用率、缓存命中率、key值总数、Redis响应请求时间、客户端连接数、持久性指标等。
- MQ消息监控:连接数、队列数、生产速率、消费速率、消息堆积量等等。
- 应用监控:包括HTTP请求,JVM,线程池等。
日志监控则更能清楚的记录系统运行时的详细状态,虽然指标监控,可以帮助迅速定位发生瓶颈的位置,不过只有指标的话往往还不够。比如,同样的一个接口,当请求传入的参数不同时,就可能会导致完全不同的性能问题。所以,除了指标外,我们还需要对这些指标的上下文信息进行监控,而日志正是这些上下文的最佳来源。
1.4 监控系统的架构
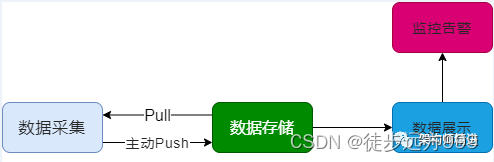
一个完整的监控系统通常由数据采集、数据传输、数据存储、数据展示、监控告警等多个模块组成。
- 数据采集,采集的方式有很多种,包括日志埋点进行采集,JMX标准接口输出监控指标,被监控对象提供REST API进行数据采集(如Hadoop、ES),系统命令行,统一的SDK进行侵入式的埋点和上报等。
- 数据传输,将采集的数据以TCP、UDP或者HTTP协议的形式上报给监控系统,有主动Push模式,也有被动Pull模式。
- 数据存储,有使用MySQL、Oracle等关系数据库存储的,也有使用时序数据库RRDTool、OpentTSDB、InfluxDB存储的,还有使用HBase存储的。
- 数据展示,数据指标的图形化展示。
- 监控告警,灵活的告警设置,以及支持邮件、短信、IM等多种通知通道。
三、当前流行的监控系统
目前大部分厂商都采用自研或是基于开源组件的方式搭建自己的监控平台。当然也有很多非常流行的开源监控系统,其中,最流行的莫过于Zabbix和Prometheus。下面就对这两个监控系统进行介绍,同时总结下各自的优劣势。
2.1 Zabbix
Zabbix 1998年诞生,核心组件采用C语言开发,Web端采用PHP开发。它属于老牌监控系统中的优秀代表,功能全面,使用广泛,是最优秀的监控解决方案之一。
2.1.1 Zabbix的优势
产品成熟:由于诞生时间长且使用广泛,拥有丰富的文档资料以及各种开源的数据采集插件,能覆盖绝大部分监控场景。
采集方式丰富:支持Agent、SNMP、JMX、SSH等多种采集方式,以及主动和被动的数据传输方式。
2.1.2 Zabbix的劣势
Zabbix需要在被监控主机上安装Agent,所有的数据都存在数据库里,产生的数据很大,瓶颈主要在数据库。
2.2 Prometheus
随着微服务架构和容器的兴起,Zabbix对容器监控显得力不从心。为解决监控容器的问题 Prometheus 应运而生。
Prometheus 是一套开源的系统监控报警框架,采用Go语言开发。得益于Google与k8s的强力支持,自带云原生的光环,天然能够友好协作,使得Prometheus 在开源社区异常火爆。
2.2.1 Prometheus优点
(1)提供多维度数据模型和灵活的查询方式
通过将监控指标关联多个 tag,来将监控数据进行任意维度的组合,并且提供简单的 PromQL 查询方式,还提供 HTTP 查询接口,可以很方便地结合 Grafana 等 GUI 组件展示数据。
(2)基于时序数据库,支持服务器节点的本地存储
通过 Prometheus 自带的时序数据库,可以完成每秒千万级的数据存储;不仅如此,在保存大量历史数据的场景中,Prometheus 可以对接第三方时序数据库和 OpenTSDB 等。
(3)定义了开放指标数据标准
以基于 HTTP 的 Pull 方式采集时序数据,只有实现了Prometheus监控数据才可以被 Prometheus 采集、汇总、并支持 Push 方式向中间网关推送时序列数据,能更加灵活地应对多种监控场景。
(4)支持通过静态文件配置和动态发现机制发现监控对象
自动完成数据采集。Prometheus 目前已经支持 Kubernetes、etcd、Consul 等多种服务发现机制。
(5)易于维护
可以通过二进制文件直接启动,并且提供了容器化部署镜像。
(6)集群支持
支持数据的分区采样和集群部署,支持大规模集群监控。
2.2.2 Prometheus缺点
Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。
由于Prometheus采用的是Pull模型拉取数据,意味着所有被监控的endpoint必须是可达的,需要合理规划网络的安全配置。
指标众多,需进行适当裁剪。
2.3 综合对比
下表通过多维度展现了各自监控系统的优缺点:
综合来看,Zabbix 的成熟度更高,上手更快,但灵活性较差。而且,监控数据的复杂度增加后,Zabbix 做进一步定制难度很高,即使做好了定制,也没法利用之前收集到的数据了(关系型数据库造成的问题)。
Prometheus 基本上是正相反,上手难度大一些,但由于定制灵活度高,数据也有更多的聚合可能,起步后的使用难度远小于 Zabbix。
如果监控的是物理机,用 Zabbix 没毛病,Zabbix 在传统监控系统中,尤其是在服务器相关监控方面,占据绝对优势;但如果是云环境的话,除非是 Zabbix 玩的非常溜,可以做各种定制,否则还是 Prometheus 吧,毕竟人家就是干这个的。
Prometheus 号称下一代监控系统,已经成为主导及容器监控方面的标配,并且在未来可见的时间内被广泛应用。
四、使用Prometheus+grafana搭建监控系统
4.1 下载
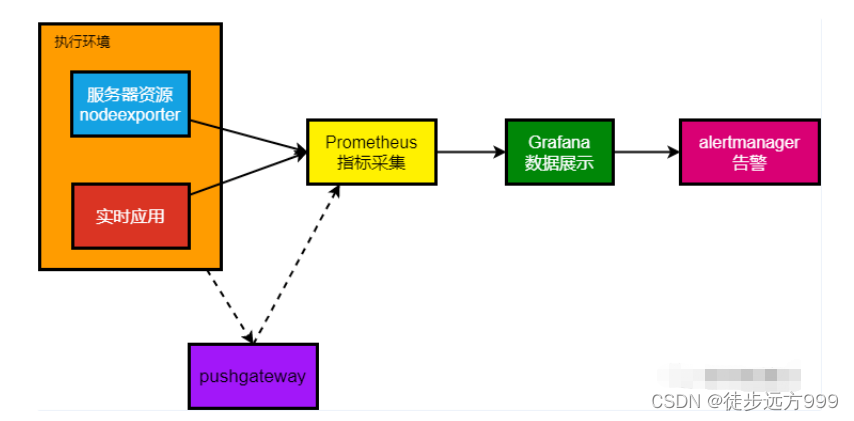
Prometheus需要下载prometheus(Prometheus主服务)、node_exporter(服务器监控)、mysqld_exporter(Mysql数据库监控-可选)、pushgateway(数据网关-可选)、alertmanager(告警组件-可选)
下载地址:https://prometheus.io/download/
Grafana为数据展示界面,下载地址:https://grafana.com/grafana/download
4.2 架构图
4.3 安装 Prometheus Server
Prometheus 的架构设计中,Prometheus Server 主要负责数据的收集,存储并且对外提供数据查询支持。下面开始安装Prometheus Server。
step1:首先,下载prometheus,并上传到服务器
解压到/usr/local/prometheus目录下:tar -zxvf prometheus-2.37.0.linux-amd64.tar.gz -C /usr/local/prometheus# 修改目录名:cd /usr/local/prometheusmv prometheus-2.37.0.linux-amd64 prometheus-2.37.0
setp2:启动prometheus Server 服务。prometheus启动非常简单,只需要一个命令即可,进入到/usr/local/prometheus/prometheus-2.37.0后执行如下命令:
#进入prometheus目录cd /usr/local/prometheus/prometheus-2.37.0#执行启动脚本./prometheus --web.enable-admin-api --config.file=prometheus.yml
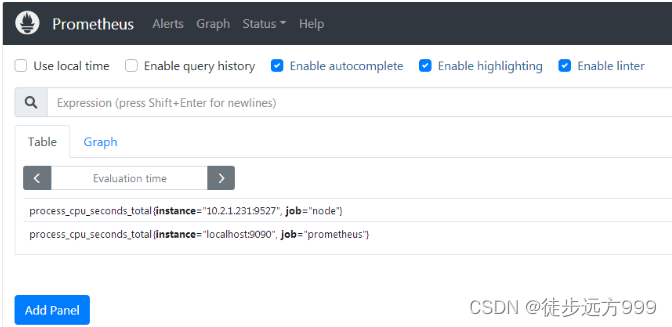
step3:验证prometheus是否启动成功,prometheus默认端口为:9090,我们在浏览器中输入:http://10.2.1.231:9090/graph,进入prometheus数据展示页面,说明prometheus启动成功。
4.4 安装 Node Exporter
实际的监控样本数据的由 Exporter 负责收集,如node_exporter 就是负责服务器的资源信息,同时提供了对外访问的HTTP服务地址(通常是/metrics)给prometheus拉取监控样本数据。下面开始安装node_exporter。
step1:首先,下载node_exporter,并上传到服务器
# 解压到/usr/local/prometheus目录下:tar -zxvf node_exporter-1.3.1.linux-amd64.tar.gz -C /usr/local/prometheus# 修改目录名:cd /usr/local/prometheusmv node_exporter-1.3.1.linux-amd64 node_exporter-1.3.1
step2:启动node_exporler,输入如下命令启动:
#node_exportercd /usr/local/prometheus/node_exporter-1.3.1#执行启动命令,指定数据访问的url./node_exporter --web.listen-address 10.2.1.231:9527
step3:验证node_exporler是否启动成功,我们在浏览器中输入上面指定的地址:http://10.2.1.231:9527/metrics,可以看到当前 node_exporter 获取到的当前主机的所有监控数据。说明node_exporler启动成功。
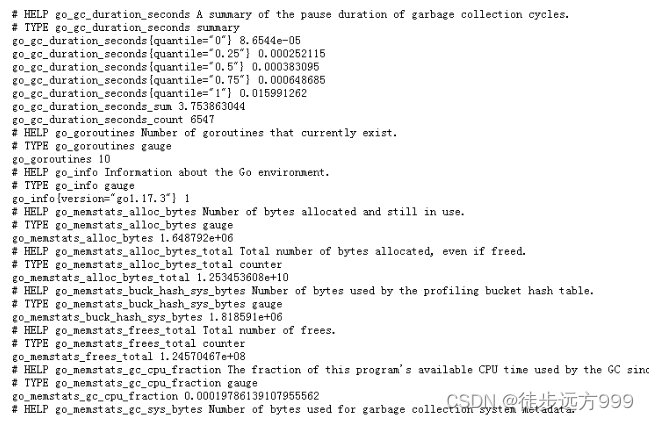
step4:最后,配置prometheus,将新增加的node配置到prometheus。
修改prometheus-2.37.0 文件夹下的prometheus.yml文件。增加新的node配置,具体配置如下:
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] # 采集node exporter监控数据 - job_name: 'node' static_configs: - targets: ['10.2.1.231:9527']
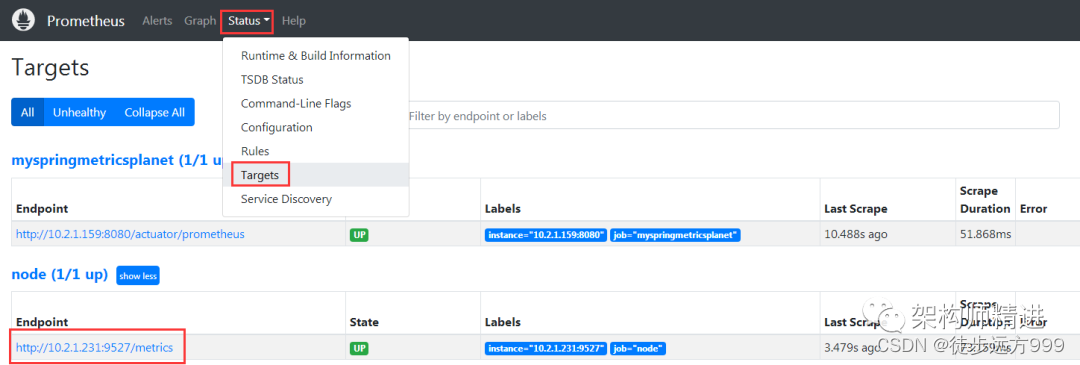
修改完prometheus.yml 文件后,重新启动prometheus。再次访问prometheus数据展示页面,选择status | target,可以看到新的node已经添加进来了。
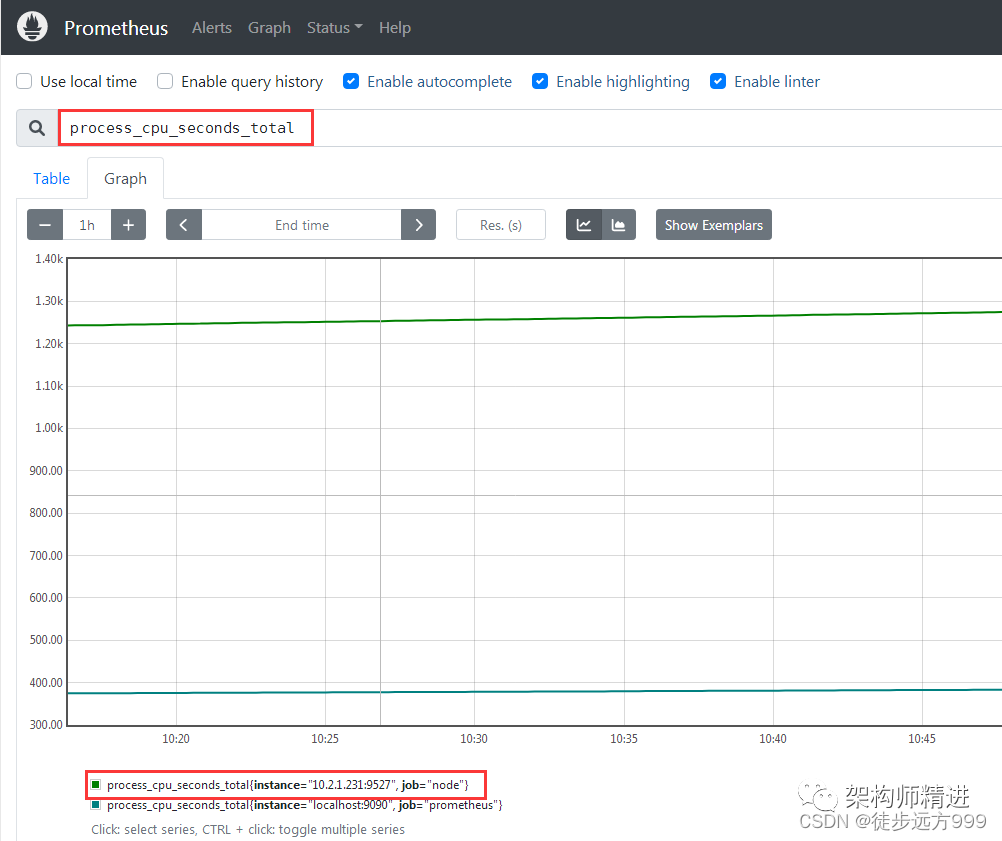
在Graph 页面,在查询框中输入: process_cpu_seconds_total
3.5 安装grafana
前面已经把prometheus和node exporter 安装并集成成功。prometheus虽然有自带的数据展示界面,但是不够全面也不直观。接下来集成grafana 完成数据展示。
下载地址:https://grafana.com/grafana/download
step1:首先,下载Grafana,并上传到服务器。
# 下载grafanawget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.0.3.linux-amd64.tar.gz# 解压到tar -zxvf grafana-enterprise-9.0.3.linux-amd64.tar.gz -C /usr/local/prometheus# 修改目录名:cd /usr/local/prometheusmv ngrafana-enterprise-9.0.3.linux-amd64 grafana-9.0.3
step2:启动Grafana,输入如下命令:
#grafanacd /usr/local/prometheus/grafana-9.0.3/bin#执行启动命令,指定数据访问的url./grafana-server --homepath /usr/local/prometheus/grafana-9.0.3 web
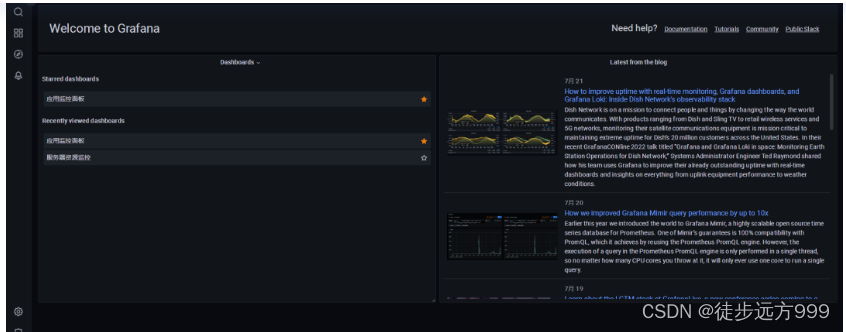
step3:验证是否安装成功,Grafana默认端口:3000。在浏览器中输入:http://10.2.1.231:3000/ 输入默认账号密码:admin\admin。能正常进入Grafana,说明Grafana安装成功。
step4:配置prometheus数据源,点击 设置 | Data Source ,按照操作添加prometheus数据源。
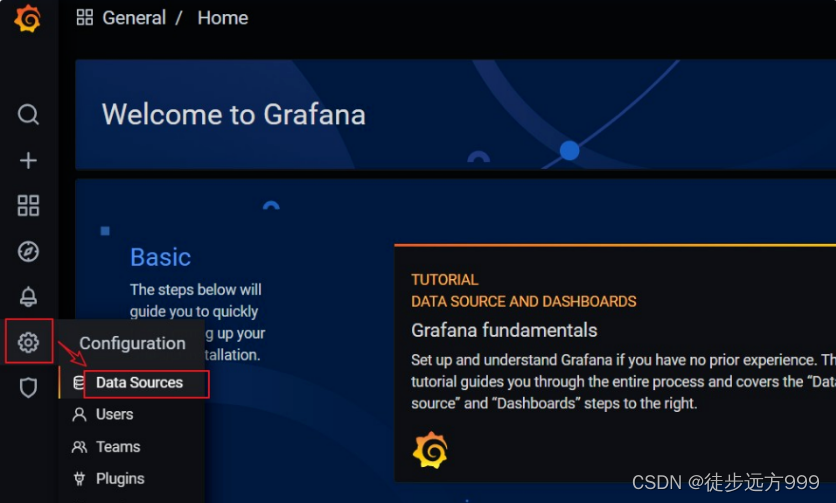
点击add data source,后选择prometheus数据源。
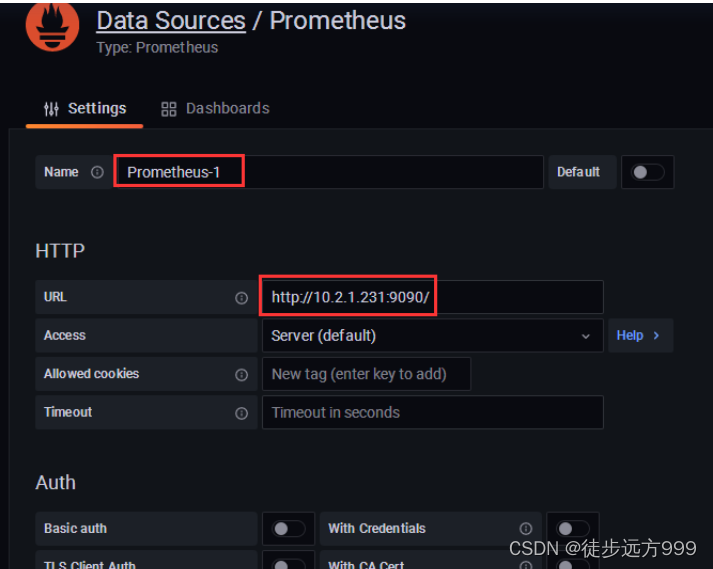
输入data source 的名字以及prometheus的地址:http://10.2.1.231:9090/ 后点击Save&Test 即可。
step5:创建仪表盘 Dashboard
Grafana 支持手动创建仪表盘 Dashboard 和自动导入Dashboard模板两种方式,手动一个个添加Dashboard 比较繁琐,Grafana 社区鼓励用户分享 Dashboard,通过https://grafana.com/dashboards 网站,可以找到大量可直接使用的Dashboard模板。
Grafana 中所有的Dashboard 通过 JSON 进行共享,下载并且导入这些 JSON 文件,就可以直接使用这些已经定义好的 Dashboard:
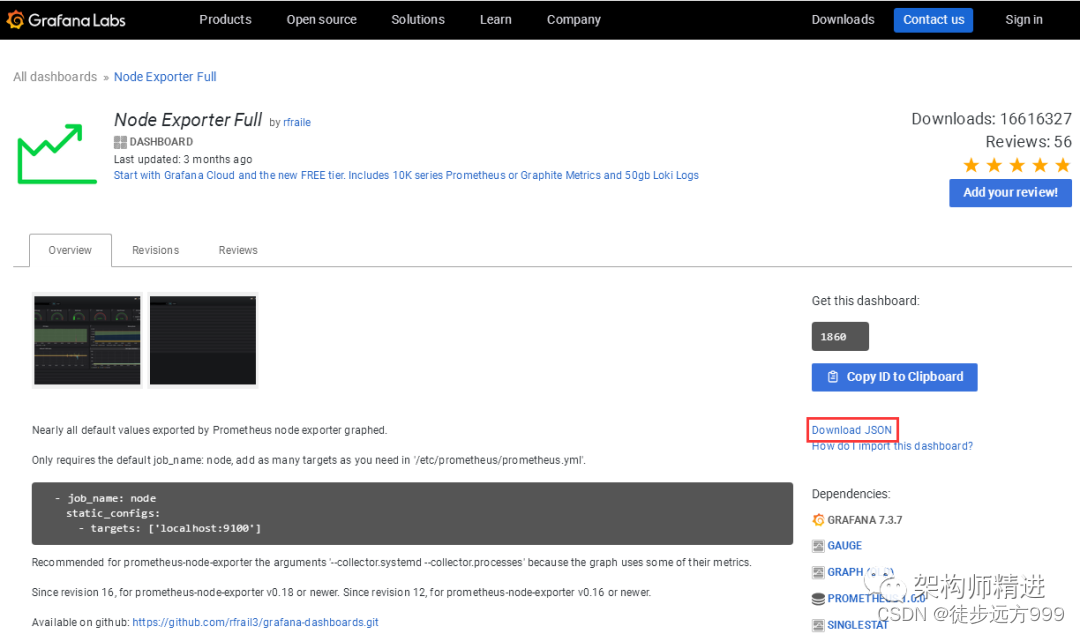
选择自己喜欢的模板后,点击 Download JSON下载对应的json 文件。然后在Grafana系统中导入相应的json即可。
接下来回到Grafana页面,点击DashBoards|Import
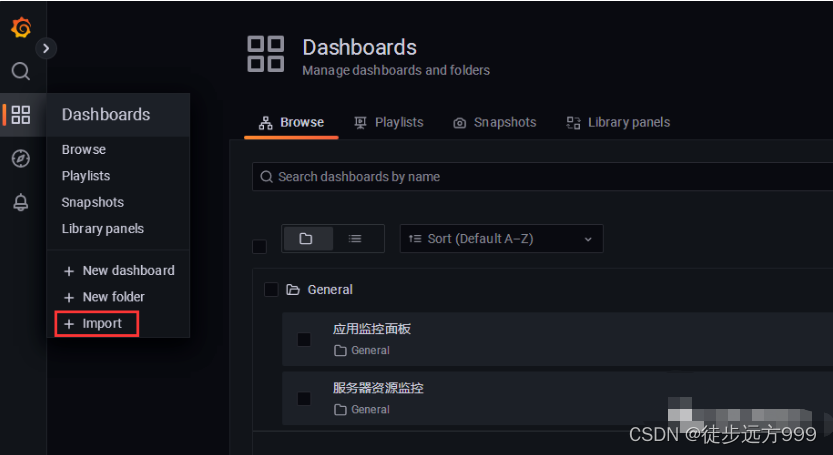
选择之前下载好的json文件,导入即可。
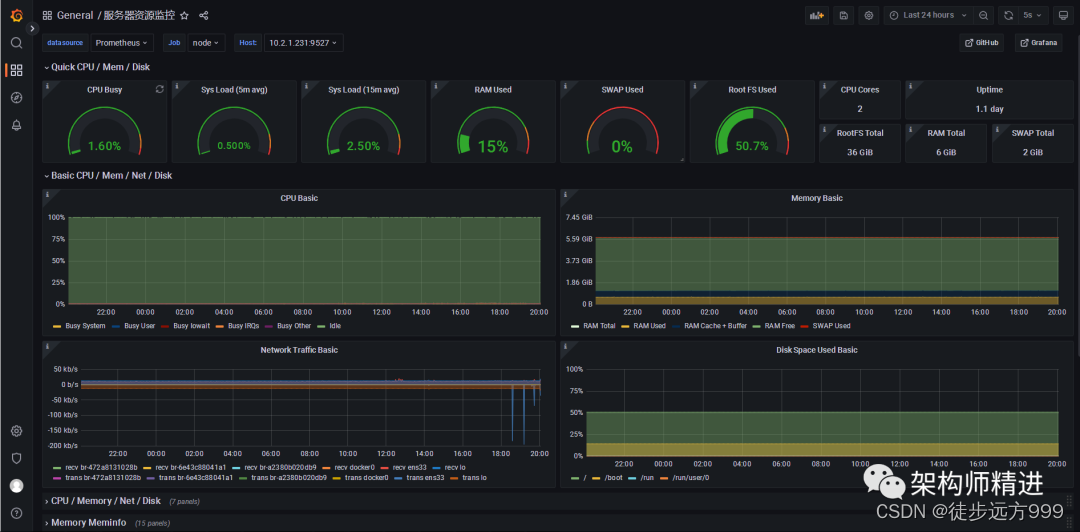
点击Import后,我们就可以看到详细的服务器资源监控数据。如下图所示:
参考文章
五、Prometheus告警规则
1、与AlertManager关联
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.94.71:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "/app/prometheus/rules/*.rules" #告警规则位置
2、添加监控Alertmanager,让Prometheus去收集Alertmanager的监控指标
- job_name: 'alertmanager'
#覆盖全局配置,每15秒收集一次信息
scrape_interval: 15s
static_configs:
- targets: ['192.168.94.71:9093']
3、配置告警规则,创建告警文件
cat /opt/prometheus/rules/temp.rules
cat /opt/prometheus/rules/temp.rules
groups:
- name: test-rules
rules:
#对任何实例超过1分钟无法联系的情况发出警报
- alert: InstanceDown #告警规则的名称
expr: up == 0 #基于PromQL表达式告警出发条件,用于计算是否有时间序列满足改条件
for: 2m #评估等待时间,用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
labels: #自定义标签,允许用户指定要附加到告警上的一组附加标签
status: warning
annotations: #用于指定一组附加信息,比如用于描述告警详细信息,当中内容会在告警产生时作为参数一同发送到AlertManager
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: job {{$labels.job}} has been down"
- name: node-cpu
rules:
- alert: NodeCpuUsage
expr: (100 - (avg by (instance) (rate(node_cpu_seconds_total{job=~".*",mode="idle"}[2m])) * 100)) > 90
for: 15m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: CPU usage is above 90% (current value is: {{ $value }}"
- alert: NodeMemUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 90
for: 15m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: MEM usage is above 90% (current value is: {{ $value }}"
- alert: NodeDiskUsage
expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev|snap).*"} / node_filesystem_size_bytes) * 100 > 90
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: Disk usage is above 80% (current value is: {{ $value }}"
- alert: NodeFDUsage
expr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 80
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: File Descriptor usage is above 80% (current value is: {{ $value }}"
- alert: NodeLoad15
expr: avg by (instance) (node_load15{}) > 20
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: Load15 is above 100 (current value is: {{ $value }}"
- alert: NodeAgentStatus
expr: avg by (instance) (up{}) == 0
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: Node Agent is down (current value is: {{ $value }}"
- alert: NodeProcsBlocked
expr: avg by (instance) (node_procs_blocked{}) > 100
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: Node Blocked Procs detected!(current value is: {{ $value }}"
- alert: NodeTransmitRate
expr: avg by (instance)(floor(irate(node_network_transmit_bytes_total{device!="lo"}[2m])/ 1024 / 1024)) > 100
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: Node Transmit Rate is above 100MB/s (current value is: {{ $value }}"
- alert: NodeReceiveRate
expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{device="eth0"}[2m]) / 1024 / 1024)) > 100
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: Node Receive Rate is above 100MB/s (current value is: {{ $value }}"
- alert: NodeDiskReadRate
expr: avg by (instance) (floor(irate(node_disk_bytes_read{}[2m]) / 1024 / 1024)) > 50
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: Node Disk Read Rate is above 50MB/s (current value is: {{ $value }}"
- alert: NodeDiskWriteRate
expr: avg by (instance) (floor(irate(node_nfsd_disk_bytes_written_total{}[2m]) / 1024 / 1024)) > 50
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: Node Disk Write Rate is above 50MB/s (current value is: {{ $value }}"
- alert: Domain
expr: domain_expiry_days < 30
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{{$labels.instance}}: 域名剩余时间小于三十天,请及时续费 (current value is: {{ $value }}"
4、重载配置文件
curl -X POST http://localhost:9090/-/reload
六、配置邮箱报警
1、使用配置文件定义告警
# cat alertmanager.yaml
global:
resolve_timeout: 5m
smtp_smarthost: 'xxx' #邮件服务器
smtp_from: 'xxx' #发邮件的邮箱
smtp_auth_username: 'xxx' #发邮件的邮箱用户名
smtp_auth_password: 'xxx' #发邮件的邮箱密码
smtp_require_tls: false #进行tls验证
smtp_hello: 'xxx'
route:
group_by: ['alertname']
# 当收到告警的时候,等待group_wait配置的时间,看是否还有告警,如果有就一起发出去
group_wait: 5s
# 上次告警信息发送成功,此时又来了一个新的告警数据,则需要等该 group_interval 配置的时间才可以发送出去
group_interval: 5s
# 如果上次告警信息发送成功,且问题没有解决,则等待 repeat_interval 配置的时间再次发送告警数据
repeat_interval: 5m
# 全局报警组,这个参数必选(定义告警接收器)
receiver: 'email'
receivers:
# 选择告警接收器
- name: 'email'
email_configs:
# 收邮件的邮箱
- to: 'xxx, xxx'
# 如果报警恢复,也发送邮件
send_resolved: true
webhook_configs:
- url: 'http://api.aiops.com/alert/api/event/prometheus/0a099b8d-49dd-403d-8c97-9878ed75fc39'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
2、使用模板定义告警信息
创建告警信息模板
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
<h2>@告警通知</h2>
告警程序:prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情:{{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
<h2>@告警恢复</h2>
告警程序: prometheus_alert <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
告警时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- end }}
修改AlertManager配置文件
...
templates:
- '/opt/alertmanager/template/*.temp'
receivers:
# 选择告警接收器
- name: 'email'
email_configs:
# 收邮件的邮箱
- to: 'xxx, xxx'
html: '{{ template "email.heml" .}}'
# 如果报警恢复,也发送邮件
send_resolved: true