MySQL 增删查改(进阶)
文章目录
- MySQL 增删查改(进阶)
- 01 表的设计
- 表的三大范式
- 02 查询操作进阶
- 新增
- 聚合查询
- count
- sum
- avg
- max
- min
- 分组查询 GROUP BY
- HAVING
- 联合查询/多表查询
- 关键思路
- 引入
- 内连接
- 外连接
- 左外连接:`left join`
- 右外连接:`right join`
- 自连接
- 子连接
- 合并查询
01 表的设计
根据实际的需求场景,明确当前要创建几个表,每个表什么样子,是否存在一定关系
-
梳理清楚 需求中的“实体”
实体:对象 -> 需求中的关键性名词~
-
再确定好 “实体”之间的“关系”
一般来说,每个实体,都需要安排一个表,表的列就对应到实体的各个属性
表的三大范式
-
一对一
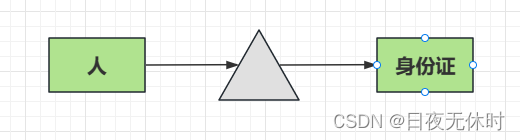
eg:一个人只能有一张身份证,一张身份证只能一个人拥有
student(studentId, name........,accountId); account(accountId, username, password...);student(studentId,name....); account(accountId, username, password, studentId);合并
student-account (studentId, name, username, password) -
一对多
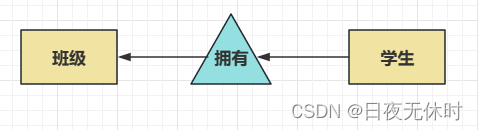
eg:一个学生只能在一个班级,一个班级可以包含多个学生
class(id, name, studentId) 1 MySQL 1,2,3 student(id, name) 1 张三 2 李四 3 王五class(id, name) 1 MySQL student(id, name, classId) 1 张三 1 2 李四 2 3 王五 3由于MySQL不支持数组这样的类型
所以,使用MySQL的时候就需要使用第二种方式来实现,而不是第一种
第一种的写法,像redis这样可以支持数组类型的数据库,就可以使用
-
多对多
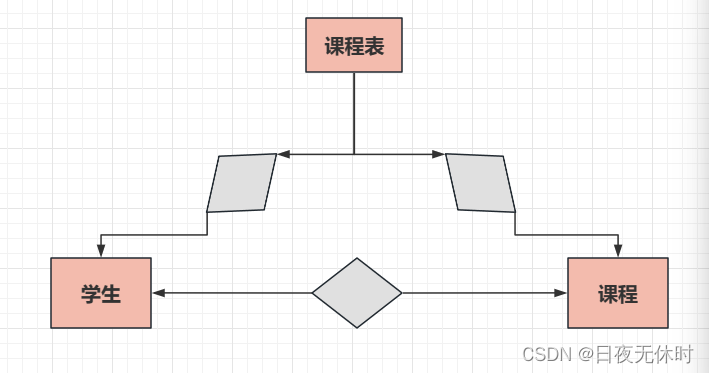
eg:一个学生可以选择多门课,一门课程可以包含多个学生
student(id, name)
1 张三
2 李四
3 王五
course(id, name)
1 语文
2 数学
3 英语
借助一个关联表,表示多对多的关系:
student-course(studentId, courseId)
1 1 张三选了语文课
1 2 张三选了数学课
2 1 李四选了语文课
2 3 李四选了英语课
-
没关系
上述三种关系都没有啥关系,各自独立设计就好~
02 查询操作进阶
新增
查询可以搭配插入使用~
见以下例子:
mysql> create table student (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> create table student2 (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student values (1,'zhangsan'), (2,'lisi'), (3,'wangwu');
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from student;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
| 2 | lisi |
| 3 | wangwu |
+------+----------+
3 rows in set (0.00 sec)
mysql> select * from student2;
Empty set (0.00 sec)
-- !!!!!!!!!!!!!!!!!!!!!!!!!!!!
mysql> insert into student2 select * from student;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from student2;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
| 2 | lisi |
| 3 | wangwu |
+------+----------+
3 rows in set (0.00 sec)
-- 此处要求查询出来的结果集合, 列数/类型 要和插入的这个表匹配
聚合查询
之前所讲的表达式查询,是针对 列 和 列 之间进行运算的~
而聚合查询是相当于 行 和 行 之间进行运算
sql中提供了一些 “聚合函数” 通过聚合函数来完成上述行之间的运算
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT]expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT]expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT]expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT]expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT]expr) | 返回查询到的数据的最小值,不是数字没有意义 |
count
mysql> CREATE TABLE exam_result (
-> id INT,
-> name VARCHAR(20),
-> chinese DECIMAL(3,1),
-> math DECIMAL(3,1),
-> english DECIMAL(3,1)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> -- 插入测试数据
mysql> INSERT INTO exam_result (id,name, chinese, math, english) VALUES
-> (1,'唐三藏', 67, 98, 56),
-> (2,'孙悟空', 87.5, 78, 77),
-> (3,'猪悟能', 88, 98.5, 90),
-> (4,'曹孟德', 82, 84, 67),
-> (5,'刘玄德', 55.5, 85, 45),
-> (6,'孙权', 70, 73, 78.5),
-> (7,'宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.01 sec)
Records: 7 Duplicates: 0 Warnings: 0
mysql> select * from exam_result;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+--------+---------+------+---------+
7 rows in set (0.00 sec)
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
-- 先执行select * ,再针对结果集合进行统计(看看具体有几行)
count(*)得到的结果还可以参加各种算术计算,还可以搭配其他sql使用。
看看下面这两个情况:
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
mysql> select count(name) from exam_result;
+-------------+
| count(name) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)
实际上还是有差别的~
- 如果当前的 列 里面有
null,两种计算方式的count就不同了
mysql> insert into exam_result values (null,null,null,null,null);
Query OK, 1 row affected (0.01 sec)
mysql> select * from exam_result;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | NULL | NULL | NULL | NULL |
+------+--------+---------+------+---------+
8 rows in set (0.00 sec)
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 8 |
+----------+
1 row in set (0.00 sec)
mysql> select count(name) from exam_result;
+-------------+
| count(name) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)
- 指定具体列,是可以去重的~
mysql> select count(math) from exam_result;
+-------------+
| count(math) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)
mysql> select count(distinct math) from exam_result;
+----------------------+
| count(distinct math) |
+----------------------+
| 7 |
+----------------------+
1 row in set (0.00 sec)
sum
把这一列的若干行,进行求和(算术运算),只能针对数值类型使用~
mysql> select sum(chinese) from exam_result;
+--------------+
| sum(chinese) |
+--------------+
| 525.0 |
+--------------+
1 row in set (0.00 sec)
-- null会被排除掉
mysql> select sum(name) from exam_result;
+-----------+
| sum(name) |
+-----------+
| 0 |
+-----------+
1 row in set, 7 warnings (0.00 sec)
mysql> show warnings;
+---------+------+--------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------+
| Warning | 1292 | Truncated incorrect DOUBLE value: '唐三藏' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '孙悟空' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '猪悟能' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '曹孟德' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '刘玄德' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '孙权' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '宋公明' |
+---------+------+--------------------------------------------+
7 rows in set (0.00 sec)
-- MySQL 会尝试把这一列转成 double 如果转成了,就可以进行运算,如果没转成,就会报错
mysql> insert into exam_result values(10, '007', null, null, null);
Query OK, 1 row affected (0.00 sec)
mysql> select sum(name) from exam_result;
+-----------+
| sum(name) |
+-----------+
| 7 |
+-----------+
1 row in set, 7 warnings (0.00 sec)
-- 这里最后的7其实就是name中的007被MySQL尝试转成 double,然后进行运算得出来的
另外,实际上也可以sum(表达式)
mysql> select sum(chinese + math + english) from exam_result;
+-------------------------------+
| sum(chinese + math + english) |
+-------------------------------+
| 1550.0 |
+-------------------------------+
1 row in set (0.00 sec)
这是分成两步走的~
select chinese + math + english,把对应列相加,得到一个临时表- 再把这个临时表的结果进行 行 和 行 相加
avg
相关操作同上
max
相关操作同上
min
相关操作同上
mysql> select avg(chinese) from exam_result;
+--------------+
| avg(chinese) |
+--------------+
| 75.00000 |
+--------------+
1 row in set (0.00 sec)
mysql> select max(chinese) from exam_result;
+--------------+
| max(chinese) |
+--------------+
| 88.0 |
+--------------+
1 row in set (0.00 sec)
mysql> select min(chinese) from exam_result;
+--------------+
| min(chinese) |
+--------------+
| 55.5 |
+--------------+
1 row in set (0.00 sec)
分组查询 GROUP BY
使用group by进行分组,针对每个分组,再分别进行聚合查询
针对指定的列进行分组~把这一列中,值相同的行,分成到一组中 -> 得到若干组,分别使用聚合函数~
下面给例子:
-- 先建一个表
+----+------+----------+--------+
| id | name | role | salary |
+----+------+----------+--------+
| 1 | 张三 | 程序猿 | 10000 |
| 2 | 李四 | 程序猿 | 11000 |
| 3 | 王五 | 程序猿 | 12000 |
| 4 | 赵六 | 产品经理 | 14000 |
| 5 | 田七 | 产品经理 | 9000 |
| 6 | 刘八 | 老板 | 100000 |
+----+------+----------+--------+
mysql> select avg(salary) from emp;
+-------------+
| avg(salary) |
+-------------+
| 26000.0000 |
+-------------+
1 row in set (0.00 sec)
-- 我们可以看出平均薪资26k有点不合理啊,老板一己之力抬高了平均薪资
-- 那么我们可以进行以下操作
mysql> select role, avg(salary) from emp group by role;
+----------+-------------+
| role | avg(salary) |
+----------+-------------+
| 产品经理 | 11500.0000 |
| 程序猿 | 11000.0000 |
| 老板 | 100000.0000 |
+----------+-------------+
3 rows in set (0.00 sec)
那么当我们分组的时候,不进行聚合,那该怎么操作呢?
mysql> select role,salary from emp group by role;
+----------+--------+
| role | salary |
+----------+--------+
| 产品经理 | 14000 |
| 程序猿 | 10000 |
| 老板 | 100000 |
+----------+--------+
3 rows in set (0.00 sec)
-- 如果针对分组之后,不使用聚合函数,此时的结果就是查询出每一组中的某个代表数据
-- 所以往往我们还是要搭配聚合函数使用,否则这里的查询结果,就是没有意义~~
-- 由于role这一列是group by指定的列,每一组所有的记录的role一定是相同的
HAVING
使用group by的时候,还可以搭配条件
需要区分清楚,该条件是分组之前的条件,还是分组之后的条件~~
-
查询每个岗位的平均工资,但是排除张三
直接使用
where即可,where子句一般写在group by前面mysql> select role, avg(salary) from emp where name != '张三' group by role; +----------+-------------+ | role | avg(salary) | +----------+-------------+ | 产品经理 | 11500.0000 | | 程序猿 | 11500.0000 | | 老板 | 100000.0000 | +----------+-------------+ 3 rows in set (0.00 sec) -
查询每个岗位的平均工资,但是排除平均工资超2w的情况
使用
having描述group by子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用where语句,而需要用havinghaving一般写在group by后面
mysql> select role, avg(salary) from emp group by role having avg(salary) < 20000;
+----------+-------------+
| role | avg(salary) |
+----------+-------------+
| 产品经理 | 11500.0000 |
| 程序猿 | 11000.0000 |
+----------+-------------+
2 rows in set (0.00 sec)
-
在
group by,可以完成一个sql同时完成这两类条件的筛选查询每个岗位的平均工资,不算张三,并且保留平均工资小于20k
mysql> select role, avg(salary) from emp where name != '张三' group by role having avg(salary) < 20000; +----------+-------------+ | role | avg(salary) | +----------+-------------+ | 产品经理 | 11500.0000 | | 程序猿 | 11500.0000 | +----------+-------------+ 2 rows in set (0.00 sec)
联合查询/多表查询
这玩意在日常开发中,要克制使用~
前文我们我们所讲的,都是针对一个表,相比之下,有一些查询,是需要一次性从多个表中进行查询~
关键思路
理解“笛卡尔积”工作过程。
笛卡尔积是指在数学中,给定两个集合A和B,它们的笛卡尔积是由A中的元素与B中的元素组成的所有有序对的集合。简而言之,就是将两个集合中的元素按照顺序组合在一起。
举个例子来说明,假设集合A = {a, b},集合B = {1, 2},那么A和B的笛卡尔积为{(a, 1), (a, 2), (b, 1), (b, 2)}。可以看到,分别将A和B中的每个元素依次与另一个集合中的每个元素进行组合,得到的所有有序对就是笛卡尔积。
笛卡尔积在很多领域都有应用,特别是在组合数学、集合论、计算机科学等领域中。它常常用于解决排列组合、集合运算、数据库查询等问题。
总之,笛卡尔积是指将两个集合的元素按照顺序进行组合,构成一个新的集合。通过笛卡尔积,我们可以获得所有可能的组合情况。
笛卡尔积的工作过程如下:
给定两个集合A和B,笛卡尔积的计算过程如下:
- 遍历集合A中的每个元素。
- 对于集合A中的每个元素,都与集合B中的每个元素组合成一个有序对,并将这个有序对添加到笛卡尔积的结果集中。
- 重复步骤2,直到集合A中的所有元素都被遍历完。
举个例子来说明,假设集合A = {a, b},集合B = {1, 2},我们可以按照上述步骤来计算笛卡尔积:
- 遍历集合A中的元素:
- 第一个元素是a。
- 第二个元素是b。
- 对于a,与集合B中的每个元素组合:(a, 1),(a, 2)。
- 对于b,与集合B中的每个元素组合:(b, 1),(b, 2)。
最终得到的笛卡尔积为:{(a, 1), (a, 2), (b, 1), (b, 2)}。
通过这个简单的计算过程,我们就可以得到集合A和集合B的笛卡尔积。无论集合中有多少元素,只要按照这个方法遍历并组合,就能得到所有可能的有序对组成的集合。
再次简单演示:
比如说我们有两张表
class(id, name)
100 mysql100
101 mysql101
102 mysql102
stduent(id, name, classId)
1 zhangsan 100
2 lisi 101
3 wangwu 102
计算笛卡尔积~“排列组合”
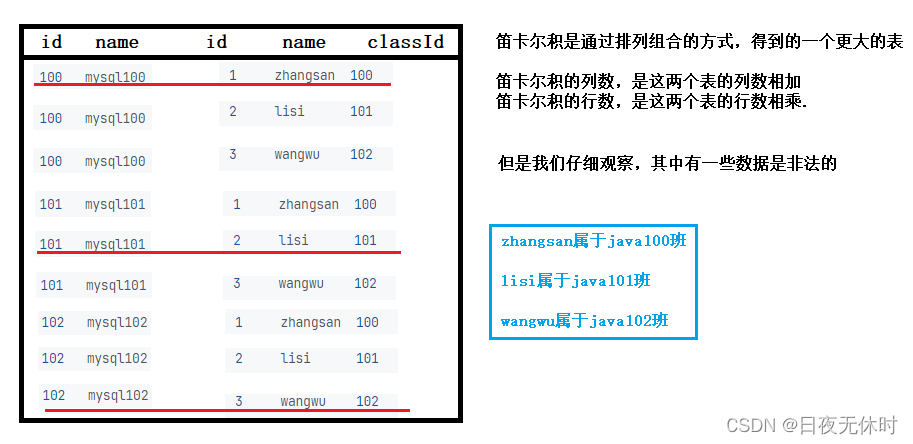
所以说:笛卡尔积是简单无脑的排列组合,把所有可能的情况都穷举了一遍,就包含一些合法的数据也包含非法的无意义的数据,进行多表查询的时候,就需要把有意义的数据筛选出来,无意义的数据,过滤掉~~
但是要是靠我们一直手动标记来过滤无意义数据,是有点不靠谱,那么我们可以通过sql条件来筛选~
where 班级表id = 学生表的classId这种也叫做连接条件~
引入
那么下面我们针对多表查询来展开~
我们先来构造几个表
mysql> create table classes (id int primary key auto_increment, name varchar(20), `desc` varchar(100));
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), qq_mail varchar(20), classes_id int);
Query OK, 0 rows affected (0.01 sec)
mysql> create table course (id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> create table score (score decimal(3,1), student_id int, course_id int);
Query OK, 0 rows affected (0.02 sec)
mysql> insert into classes(name, `desc`) values
-> ('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
-> ('中文系2019级3班','学习了中国传统文学'),
-> ('自动化2019级5班','学习了机械自动化');
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into student(sn, name, qq_mail, classes_id) values
-> ('09982','黑旋风李逵','xuanfeng@qq.com',1),
-> ('00835','菩提老祖',null,1),
-> ('00391','白素贞',null,1),
-> ('00031','许仙','xuxian@qq.com',1),
-> ('00054','不想毕业',null,1),
-> ('51234','好好说话','say@qq.com',2),
-> ('83223','tellme',null,2),
-> ('09527','老外学中文','foreigner@qq.com',2);
Query OK, 8 rows affected (0.00 sec)
Records: 8 Duplicates: 0 Warnings: 0
mysql> insert into course(name) values
-> ('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> insert into score(score, student_id, course_id) values
-> -- 黑旋风李逵
-> (70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-> -- 菩提老祖
-> (60, 2, 1),(59.5, 2, 5),
-> -- 白素贞
-> (33, 3, 1),(68, 3, 3),(99, 3, 5),
-> -- 许仙
-> (67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-> -- 不想毕业
-> (81, 5, 1),(37, 5, 5),
-> -- 好好说话
-> (56, 6, 2),(43, 6, 4),(79, 6, 6),
-> -- tellme
-> (80, 7, 2),(92, 7, 6);
Query OK, 20 rows affected (0.01 sec)
Records: 20 Duplicates: 0 Warnings: 0
创建完毕,我们来看看表里的情况~
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| classes |
| course |
| score |
| student |
+----------------+
4 rows in set (0.00 sec)
-- 学生表:
mysql> desc student;
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| sn | varchar(20) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| qq_mail | varchar(20) | YES | | NULL | |
| classes_id | int(11) | YES | | NULL | |
+------------+-------------+------+-----+---------+----------------+
5 rows in set (0.00 sec)
mysql> select * from student;
+----+-------+------------+------------------+------------+
| id | sn | name | qq_mail | classes_id |
+----+-------+------------+------------------+------------+
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 |
| 2 | 00835 | 菩提老祖 | NULL | 1 |
| 3 | 00391 | 白素贞 | NULL | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 |
| 5 | 00054 | 不想毕业 | NULL | 1 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 |
| 7 | 83223 | tellme | NULL | 2 |
| 8 | 09527 | 老外学中文 | foreigner@qq.com | 2 |
+----+-------+------------+------------------+------------+
8 rows in set (0.00 sec)
-- 班级表
mysql> desc classes;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| desc | varchar(100) | YES | | NULL | |
+-------+--------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
mysql> select * from classes;
+----+-------------------+-----------------------------------------------+
| id | name | desc |
+----+-------------------+-----------------------------------------------+
| 1 | 计算机系2019级1班 | 学习了计算机原理、C和Java语言、数据结构和算法 |
| 2 | 中文系2019级3班 | 学习了中国传统文学 |
| 3 | 自动化2019级5班 | 学习了机械自动化 |
+----+-------------------+-----------------------------------------------+
3 rows in set (0.00 sec)
-- 课程表
mysql> desc course;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
mysql> select * from course;
+----+--------------+
| id | name |
+----+--------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 3 | 计算机原理 |
| 4 | 语文 |
| 5 | 高阶数学 |
| 6 | 英文 |
+----+--------------+
6 rows in set (0.00 sec)
-- 分数表
mysql> desc score;
+------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+--------------+------+-----+---------+-------+
| score | decimal(3,1) | YES | | NULL | |
| student_id | int(11) | YES | | NULL | |
| course_id | int(11) | YES | | NULL | |
+------------+--------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
mysql> select * from score;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 70.5 | 1 | 1 | ----> 李逵的java考70.5
| 98.5 | 1 | 3 | ----> 李逵的计算机原理考98.5
| 33.0 | 1 | 5 |
| 98.0 | 1 | 6 |
| 60.0 | 2 | 1 |
| 59.5 | 2 | 5 |
| 33.0 | 3 | 1 |
| 68.0 | 3 | 3 |
| 99.0 | 3 | 5 |
| 67.0 | 4 | 1 |
| 23.0 | 4 | 3 |
| 56.0 | 4 | 5 |
| 72.0 | 4 | 6 |
| 81.0 | 5 | 1 |
| 37.0 | 5 | 5 |
| 56.0 | 6 | 2 |
| 43.0 | 6 | 4 |
| 79.0 | 6 | 6 |
| 80.0 | 7 | 2 |
| 92.0 | 7 | 6 |
+-------+------------+-----------+
20 rows in set (0.00 sec)
内连接
- 查询许仙同学的成绩(student、score)
-
先把这个两个表进行笛卡尔积
(先取哪个表的记录,和另外的表的所有记录排列组合,都是OK的,只是呈现的顺序不一样罢了)
select * from student,score; -- 数据较多一共160行 不展示 160 rows in set (0.00 sec) -
加上连接条件,筛选出有效数据
学生表的id = 分数表的 student_idselect * from student, score where id = student_id;这种写法不太推荐,因为当前这
student表和score 表没有重复的列~但是不能保证就一定没有重复列。建议写成
表名.列名select * from student, score where student.id = score.student_id; -
结合需求,进一步添加条件,针对结果进行筛选
mysql> select * from student, score where student.id = score.student_id and student.name = '许仙'; +----+-------+------+---------------+------------+-------+------------+-----------+ | id | sn | name | qq_mail | classes_id | score | student_id | course_id | +----+-------+------+---------------+------------+-------+------------+-----------+ | 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 67.0 | 4 | 1 | | 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 23.0 | 4 | 3 | | 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 56.0 | 4 | 5 | | 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 72.0 | 4 | 6 | +----+-------+------+---------------+------------+-------+------------+-----------+ 4 rows in set (0.01 sec) -
针对查询到的列进行精简,只保留需求中关心的列。
mysql> select student.name, score.score from student, score where student.id = score.student_id and student.name = '许仙'; +------+-------+ | name | score | +------+-------+ | 许仙 | 67.0 | | 许仙 | 23.0 | | 许仙 | 56.0 | | 许仙 | 72.0 | +------+-------+ 4 rows in set (0.00 sec)
- 查询所有同学的总成绩,以及同学的个人信息
- 之前这个例子是通过 列 表达式 来完成总成绩的计算
exam_result(id, name, chinese, math, english)
- 之前这个例子是通过 列 表达式 来完成总成绩的计算
但是这个例子我们是按照行来组织的~
此处是多行数据进行加和-聚合函数sum
还需要按照同学进行分组~
基于多表查询和聚合查询的综合运用~
-
先进行笛卡尔积(score表、student表)
select * from student,score; -
指定连接条件(
student.id = score.student_id)select * from student, score where student.id = score.student_id; -
精简 列
select student.name, score.score from student, score where student.id = score.student_id; -
针对上述结果再进行
group by聚合查询mysql> select student.name, sum(score.score) from student, score where student.id = score.student_id group by name; +------------+------------------+ | name | sum(score.score) | +------------+------------------+ | tellme | 172.0 | | 不想毕业 | 118.0 | | 好好说话 | 178.0 | | 白素贞 | 200.0 | | 菩提老祖 | 119.5 | | 许仙 | 218.0 | | 黑旋风李逵 | 300.0 | +------------+------------------+ 7 rows in set (0.00 sec)
-
列出每个同学,每门课程名字和分数(三张表联合查询)
(学生表、课程表、分数表)
-
先算笛卡尔积
select * from student, course, score;一旦表的数据非常大,或者数目非常多,此时得到的笛卡尔积就非常庞大~
因此,如果针对大表进行笛卡尔积(多表查询),就会生成大量的临时结果,这个过程是非常消耗时间的~
所以说,如果多表查询涉及到的表的数目比较多的时候,此时的
sql就会非常复杂,可读性也大大降低。 -
指定连接条件
三个表,涉及两个连接条件~
select * from student, course, score where student.id = score.student_id and score.student_id = course.id; -
精简列
select student.name as studentName, course.name as courseName, score.score from student, course, score where student.id = score.student_id and course.id = score.course_id; +-------------+--------------+-------+ | studentName | courseName | score | +-------------+--------------+-------+ | 黑旋风李逵 | Java | 70.5 | | 黑旋风李逵 | 计算机原理 | 98.5 | | 黑旋风李逵 | 高阶数学 | 33.0 | | 黑旋风李逵 | 英文 | 98.0 | | 菩提老祖 | Java | 60.0 | | 菩提老祖 | 高阶数学 | 59.5 | | 白素贞 | Java | 33.0 | | 白素贞 | 计算机原理 | 68.0 | | 白素贞 | 高阶数学 | 99.0 | | 许仙 | Java | 67.0 | | 许仙 | 计算机原理 | 23.0 | | 许仙 | 高阶数学 | 56.0 | | 许仙 | 英文 | 72.0 | | 不想毕业 | Java | 81.0 | | 不想毕业 | 高阶数学 | 37.0 | | 好好说话 | 中国传统文化 | 56.0 | | 好好说话 | 语文 | 43.0 | | 好好说话 | 英文 | 79.0 | | tellme | 中国传统文化 | 80.0 | | tellme | 英文 | 92.0 | +-------------+--------------+-------+ 20 rows in set (0.00 sec)
外连接
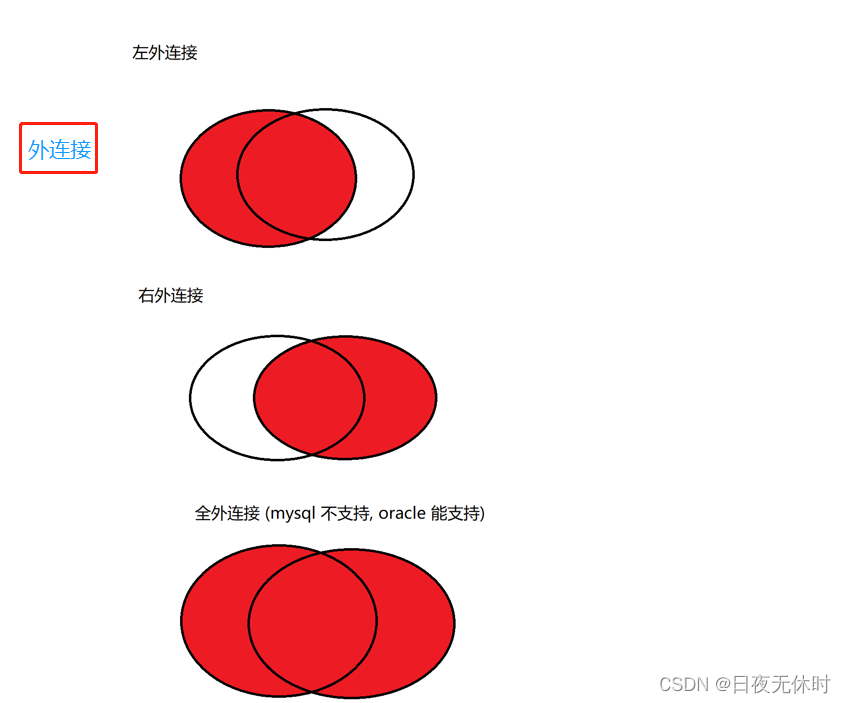
外连接分为左外连接和右外连接。
如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
如果这两个表,里面的记录都是存在对应关系,内连接和外连接的结果是一致的。
如果存在不对应的记录,内连接和外连接就会出现差别。
下面给两个表:
student(id name)
1 张三
2 李四
3 王五
score(student_id score)
1 90
2 80
3 70
student中的每一条记录,都可以在score中找到对应,反之也成立~
但是以下这样的就没法对应~
student(id name)
1 张三
2 李四
3 王五
score(student_id score)
1 90
2 80
4 70
我们创建新的表:>
create database test2 charset utf8;
create table student(id int, name varchar(20));
create table score(id int, score int);
insert into student values (1, '张三'),(2,'李四'),(3,'王五');
insert into score values (1,90),(2,80),(4,70);
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+------+
+------+-------+
| id | score |
+------+-------+
| 1 | 90 |
| 2 | 80 |
| 4 | 70 |
+------+-------+
这种写法就是:内连接
mysql> select * from student, score where student.id = score.id;
+------+------+------+-------+
| id | name | id | score |
+------+------+------+-------+
| 1 | 张三 | 1 | 90 |
| 2 | 李四 | 2 | 80 |
+------+------+------+-------+
2 rows in set (0.00 sec)
这种写法和上面的写法等价,也是得到一样的内连接的结果了
mysql> select * from student join score on student.id = score.id;
+------+------+------+-------+
| id | name | id | score |
+------+------+------+-------+
| 1 | 张三 | 1 | 90 |
| 2 | 李四 | 2 | 80 |
+------+------+------+-------+
2 rows in set (0.00 sec)
select * from student inner join score on student.id = score.id;
左外连接:left join
mysql> select * from student left join score on student.id = score.id;
+------+------+------+-------+
| id | name | id | score |
+------+------+------+-------+
| 1 | 张三 | 1 | 90 |
| 2 | 李四 | 2 | 80 |
| 3 | 王五 | NULL | NULL |
+------+------+------+-------+
3 rows in set (0.00 sec)
左外连接,就是以左侧表为基准~~
保证左侧表的每个数据都会出现在最终结果里.如果在右侧表中不存在,对应的列就填成null
右外连接:right join
mysql> select * from student right join score on student.id = score.id;
+------+------+------+-------+
| id | name | id | score |
+------+------+------+-------+
| 1 | 张三 | 1 | 90 |
| 2 | 李四 | 2 | 80 |
| NULL | NULL | 4 | 70 |
+------+------+------+-------+
3 rows in set (0.00 sec)
右外连接,是以右侧表为基准~~
保证右侧表的每个数据都会出现在最终结果里.如果左侧表中不存在,对应的列就填成 null
自连接
一张表,自己和自己进行笛卡尔积
有时候,需要去进行 行 和 行 之间的比较~~而sql只能进行 列 和 列 之间的比较
sql里写个条件,都是 列 和 列 之间进行比较,但是有时候可能涉及到需求是进行 行 和 行的比较,就可以使用 自连接,把 行的关系转换成 列 的关系~
- 显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
mysql> use test;
Database changed
mysql> select * from course;
+----+--------------+
| id | name |
+----+--------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 3 | 计算机原理 |
| 4 | 语文 |
| 5 | 高阶数学 |
| 6 | 英文 |
+----+--------------+
6 rows in set (0.00 sec)
mysql> select * from score;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 70.5 | 1 | 1 |
| 98.5 | 1 | 3 |
| 33.0 | 1 | 5 |
| 98.0 | 1 | 6 |
| 60.0 | 2 | 1 |
| 59.5 | 2 | 5 |
| 33.0 | 3 | 1 |
| 68.0 | 3 | 3 |
| 99.0 | 3 | 5 |
| 67.0 | 4 | 1 |
| 23.0 | 4 | 3 |
| 56.0 | 4 | 5 |
| 72.0 | 4 | 6 |
| 81.0 | 5 | 1 |
| 37.0 | 5 | 5 |
| 56.0 | 6 | 2 |
| 43.0 | 6 | 4 |
| 79.0 | 6 | 6 |
| 80.0 | 7 | 2 |
| 92.0 | 7 | 6 |
+-------+------------+-----------+
20 rows in set (0.00 sec)
子连接
本质上就是套娃,把多个简单的SQL拼成一个复杂的SQL (违背了一贯的编程规则)
虽然在开发中并不建议大家真的使用子查询,应该使用多个简单Sql替代.但是也还是要了解一下的~
-
单行子查询:返回一行记录的子查询
查询与“不想毕业” 同学的同班同学mysql> select * from student; mysql> select classes_id from student where name = '不想毕业'; mysql> select name from student where classes_id = 1; mysql> select name from student where classes_id = 1 and name != '不想毕业'; +------------+ | name | +------------+ | 黑旋风李逵 | | 菩提老祖 | | 白素贞 | | 许仙 | +------------+ 4 rows in set (0.00 sec) -- 使用子查询可以将以上最后两个sql语句合二为一 mysql> select name from student where classes_id = (select classes_id from student where name = '不想毕业') and name != '不想毕业'; +------------+ | name | +------------+ | 黑旋风李逵 | | 菩提老祖 | | 白素贞 | | 许仙 | +------------+ 4 rows in set (0.00 sec) -
多行子查询:返回多行记录的子查询
in查询“语文”或“英文”课程的成绩信息-- 联合查询 mysql> select * from course, score; mysql> select * from course, score where course.id = score.course_id; mysql> select * from course, score where course.id = score.course_id and (course.name = '语文' or course.name = '英文'); mysql> select score.student_id, course.name, score.score from course, score where course.id = score.course_id and (course.name = '语文' or course.name = '英文'); +------------+------+-------+ | student_id | name | score | +------------+------+-------+ | 1 | 英文 | 98.0 | | 4 | 英文 | 72.0 | | 6 | 语文 | 43.0 | | 6 | 英文 | 79.0 | | 7 | 英文 | 92.0 | +------------+------+-------+ 5 rows in set (0.00 sec)-- 子查询- 先通过课程名字,找到课程id
- 再通过课程id在分数表中进行查询
mysql> select id from course where name = '语文' or course.name = '英文'; mysql> select score.student_id, score.course_id, score.score from score where score.course_id in (4,6); +------------+-----------+-------+ | student_id | course_id | score | +------------+-----------+-------+ | 1 | 6 | 98.0 | | 4 | 6 | 72.0 | | 6 | 4 | 43.0 | | 6 | 6 | 79.0 | | 7 | 6 | 92.0 | +------------+-----------+-------+ 5 rows in set (0.00 sec) -- 一步操作 mysql> select score.student_id, score.course_id, score.score from score where score.course_id in (select id from course where name = '语文' or course.name = '英文'); +------------+-----------+-------+ | student_id | course_id | score | +------------+-----------+-------+ | 1 | 6 | 98.0 | | 4 | 6 | 72.0 | | 6 | 4 | 43.0 | | 6 | 6 | 79.0 | | 7 | 6 | 92.0 | +------------+-----------+-------+ 5 rows in set (0.00 sec)
合并查询
把多个sql查询结果集合,合并到一起~
union关键字
-
查询id小于3,或者名字为“英文”的课程:
mysql> select * from course where id < 3 or name = '英文'; +----+--------------+ | id | name | +----+--------------+ | 1 | Java | | 2 | 中国传统文化 | | 6 | 英文 | +----+--------------+ 3 rows in set (0.00 sec) mysql> select * from course where id < 3 union select * from course where name = '英文'; +----+--------------+ | id | name | +----+--------------+ | 1 | Java | | 2 | 中国传统文化 | | 6 | 英文 | +----+--------------+ 3 rows in set (0.00 sec)使用
union的好处:允许把两个不同的表,查询结果合并在一起。
合并的两个Sq的结果集的列,需要匹配列的个数和类型,是要一致的~~(列名不需要一致)
mysql> create table student1 (id int, name varchar(20)); mysql> create table student2 (studentId int, studentName varchar(20)); mysql> insert into student1 values(1, '张三'), (2, '李四'); mysql> insert into student2 values(1, '张三'), (3, '王五'); mysql> select * from student1 union select * from student2; +------+------+ | id | name | +------+------+ | 1 | 张三 | | 2 | 李四 | | 3 | 王五 | +------+------+ 3 rows in set (0.00 sec) -- 合并的时候,是会去重的~,若是不想去重,可以使用union all mysql> select * from student1 union all select * from student2; +------+------+ | id | name | +------+------+ | 1 | 张三 | | 2 | 李四 | | 1 | 张三 | | 3 | 王五 | +------+------+ 4 rows in set (0.00 sec)
至此,查询的进阶操作到此基本完结撒花,接下来会继续更新~ MySQL索引事务 ~






![[acwing周赛复盘] 第 120 场周赛20230909](https://img-blog.csdnimg.cn/c0a7734816574bd9bf11ece5ab4772bc.png)