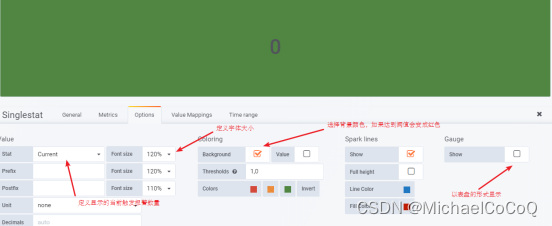
相关知识链接
- attention1
- attention2
引言
- 本文主要详解 transformer 的算法结构以及理论解释,代码实现以及具体实现时候的细节放在下一篇来详述。
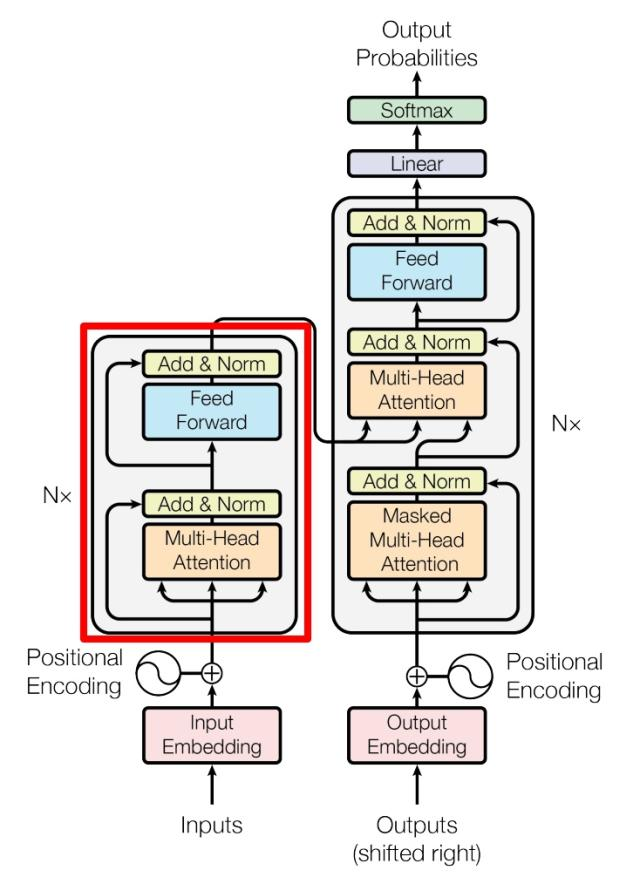
- 下面就通过上图中 transformer 的结构来依次解析
输入部分(Encode 侧)
- input 输出主要包含 两个部分:embedding 的输入数据, 数据位置的 embedding
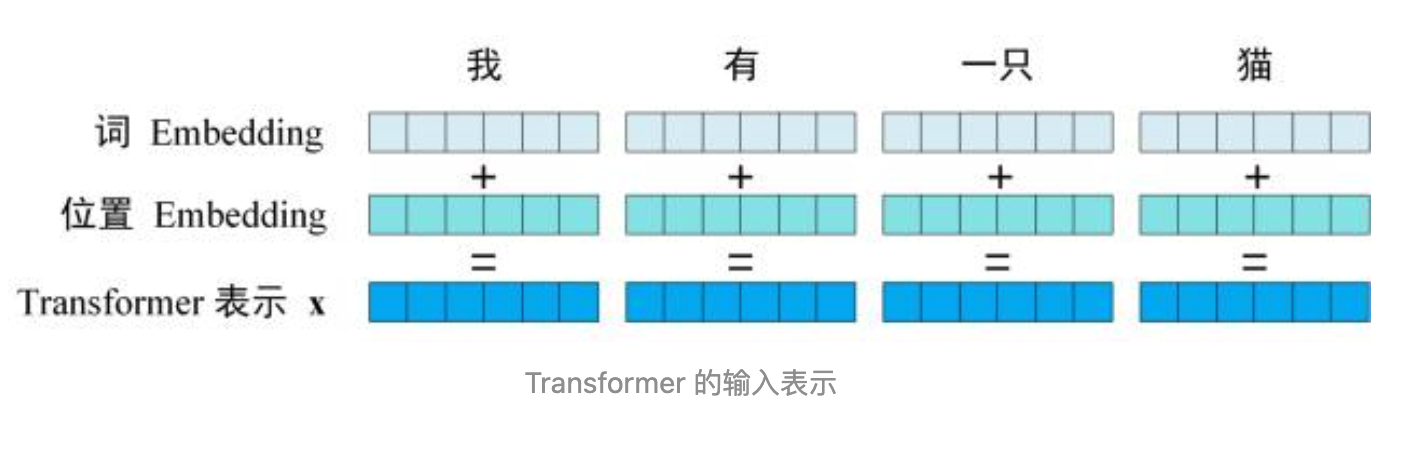
- 关于输入数据的 embedding 有很多种方式,比如word2vec,GloVe,FastText 等(注意embedding 和热编码,向量化不一回事)
- 关于位置的 embedding,因为 transformer使用的全局信息而不是单纯的利用单词的之间的顺序信息,所以位置信息十分重要,transformer 使用位置 embedding 来保存单词在序列中的相对或者绝对位置
- 位置 embedding 用 PE 表示,PE 可以通过训练得到(比如 bert 的位置信息),也可以使用自定义公式得到,transformer 使用的是公式
P E ( p o s , 2 i ) = S i n ( p o s / 10000 0 ( 2 i / d ) ) PE_(pos, 2i) = Sin(pos/100000^(2i/d)) PE(pos,2i)=Sin(pos/100000(2i/d))
P E ( p o s , 2 i + 1 ) = C o s ( p o s / 10000 0 ( 2 i / d ) ) PE_(pos, 2i+1) = Cos(pos/100000^(2i/d)) PE(pos,2i+1)=Cos(pos/100000(2i/d)) - pos 表示 0 - N; i 表示 嵌入维度比如是 512 维,i 就表示 0 - 511
- 看上图,首先位置和词的 embedding维度要一致因为后面要相加;其次就是 N表示位置的个数,上述公式将向量的维度划分为奇数行和偶数行,偶数使用 sin 函数编码,奇数采用 cos 函数编码并按照原始行号拼接
- 位置 embedding 用 PE 表示,PE 可以通过训练得到(比如 bert 的位置信息),也可以使用自定义公式得到,transformer 使用的是公式
- 为什么要用这个编码方式呢?
- 可以让模型更容易计算出相对位置,比如 PE(pos+k,2i)可以通过计算 PE(pos,2i)得到,类比 sin(A+B)展开
- 使用这样的方式可以让模型能适应比训练集更长的句子,比如训练集中最长的句子是 20,现在来了一个 长度 21 的也能够根据公式计算出第 21 位的 embeding(注:当单词 embeding 后无论原始数据多长嵌入后的长度是一定的,但是未出现过的位置信息不确定但是不影响 embeding 的维度这样才能保证单词和位置embeding 可以相加)
P E ( p o s + k , 2 i ) = P E ( p o s , 2 i ) ∗ P E ( k , 2 i + 1 ) + P E ( p o s , 2 i + 1 ) ∗ P E ( k , 2 i ) PE(pos+k,2i) = PE(pos,2i) * PE(k,2i+1) + PE(pos,2i+1) * PE(k,2i) PE(pos+k,2i)=PE(pos,2i)∗PE(k,2i+1)+PE(pos,2i+1)∗PE(k,2i)
P E ( p o s + k , 2 i + 1 ) = P E ( p o s , 2 i + ! ) ∗ P E ( k , 2 i + 1 ) − P E ( p o s , 2 i ) ∗ P E ( k , 2 i ) PE(pos+k,2i+1) = PE(pos,2i+!) * PE(k,2i+1) - PE(pos,2i) * PE(k,2i) PE(pos+k,2i+1)=PE(pos,2i+!)∗PE(k,2i+1)−PE(pos,2i)∗PE(k,2i)
- 这就是encode 侧的 input 输入了
self-attention&multi-head attention
- 此部分文章开头链接attention2有详细讲解,本文不做细讲,也可以参考下面两个参考资料也是剖析的比较通俗易懂。
- 参考 1
- 参考 2
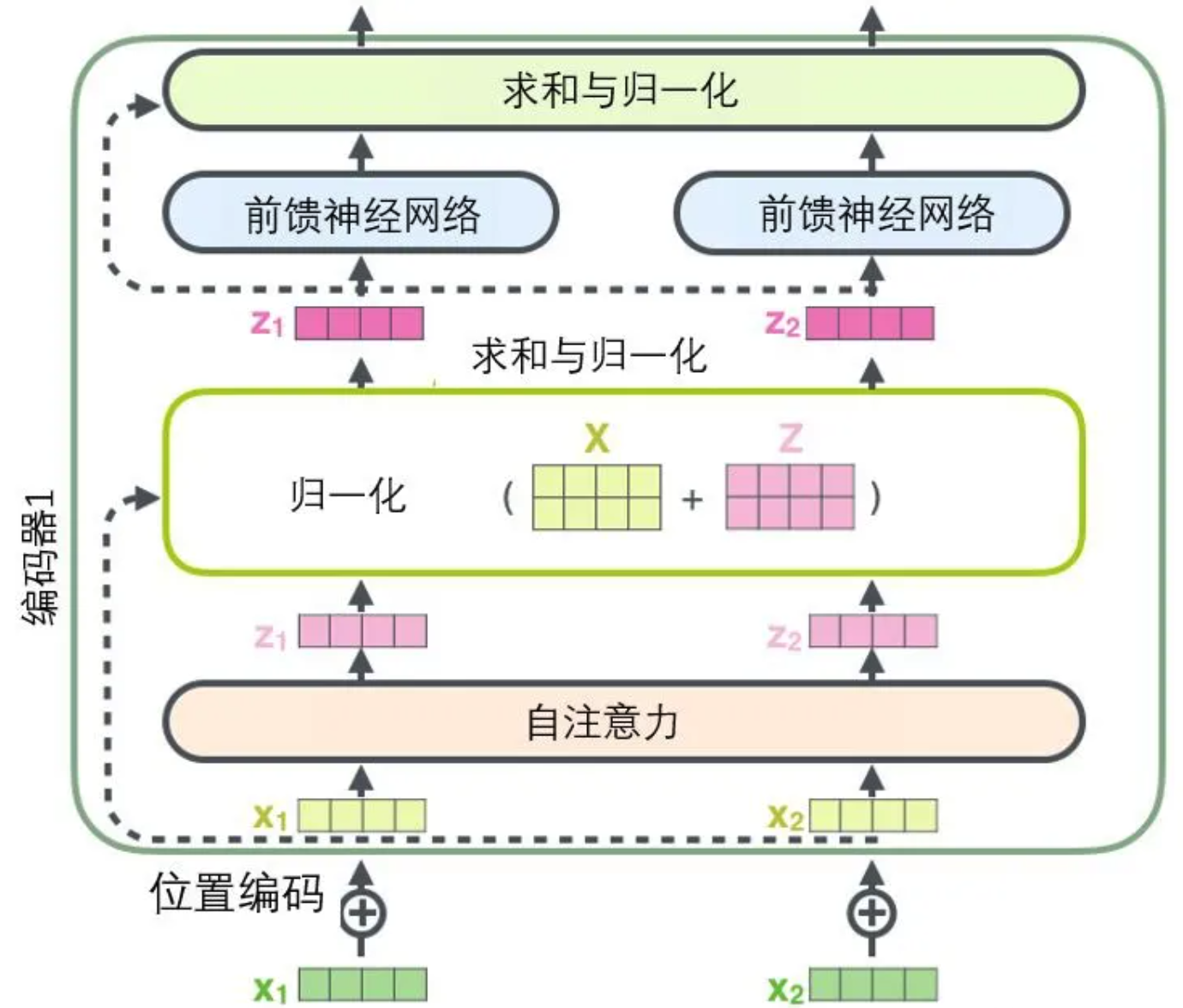
Add & Norm
- Add 和 Norm 层是由Add 和 Norm 两部分构成的计算公式如下:
L a y e r N o r m ( X + M u l t i H e a d A t t e n t i o n ( X ) ) LayerNorm(X + MultiHeadAttention(X)) LayerNorm(X+MultiHeadAttention(X))
L a y e r N o r m ( X + F e e d F o r w a r d ( X ) ) LayerNorm(X + FeedForward(X)) LayerNorm(X+FeedForward(X))- X表示多头或者前馈神经网络的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)。
- X + MultiHeadAttention(X)是一种残差连接,通常用于解决多层网络梯度消失和梯度爆炸的问题,可以让网格只关注当前差异的部分,在 ResNet 中经常用到,公式简单表达就是
输出 = 输入 + F ( 输入 ) 输出 = 输入 + F(输入) 输出=输入+F(输入) - 输入就是当前层的输入,输出就是表示当前层的输出,F(输入)是当前层的变换函数,这样相加来让网络学习输入与输出的差异,可以更方便的学习残差部分
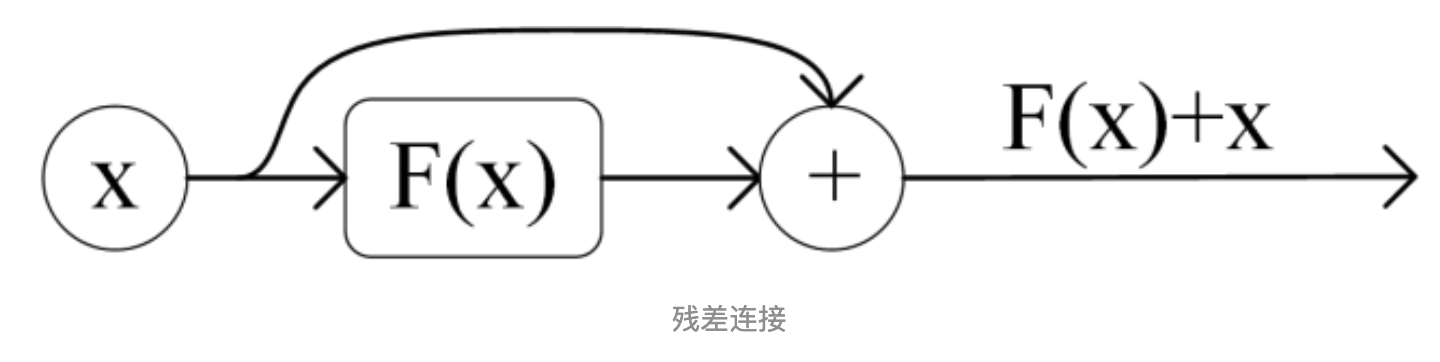
- 梯度消失:反向传播中梯度逐渐变小并趋近于零,这样梯度信息变得非常微弱从而让浅层网络难以有效的学习和更新(通常发生在激活函数为 sigmoid 或者 tanh 的网络中因为这些函数再输入较小或者较大的时候梯度接近于零)
- 梯度爆炸:与梯度爆炸相反,梯度逐渐增大并变得非常大导致参数更新过大,网络不稳定甚至无法收敛(通常在网络层之间连接的时候,可能是犹豫网络权重初始化不当,学习率过大,激活函数选择等原因)
Feed Forward 前馈神经网络
- 前馈神经网络层结构相对比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,公式如下
m a x ( 0 , X W 1 + b 1 ) W 2 + b 2 max(0, XW1 + b1)W2 +b2 max(0,XW1+b1)W2+b2 - 作用主要是对输入的词向量映射到输出的词向量,这其中会对多头提取的信息输入进一步处理,以提取更丰富的语意信息
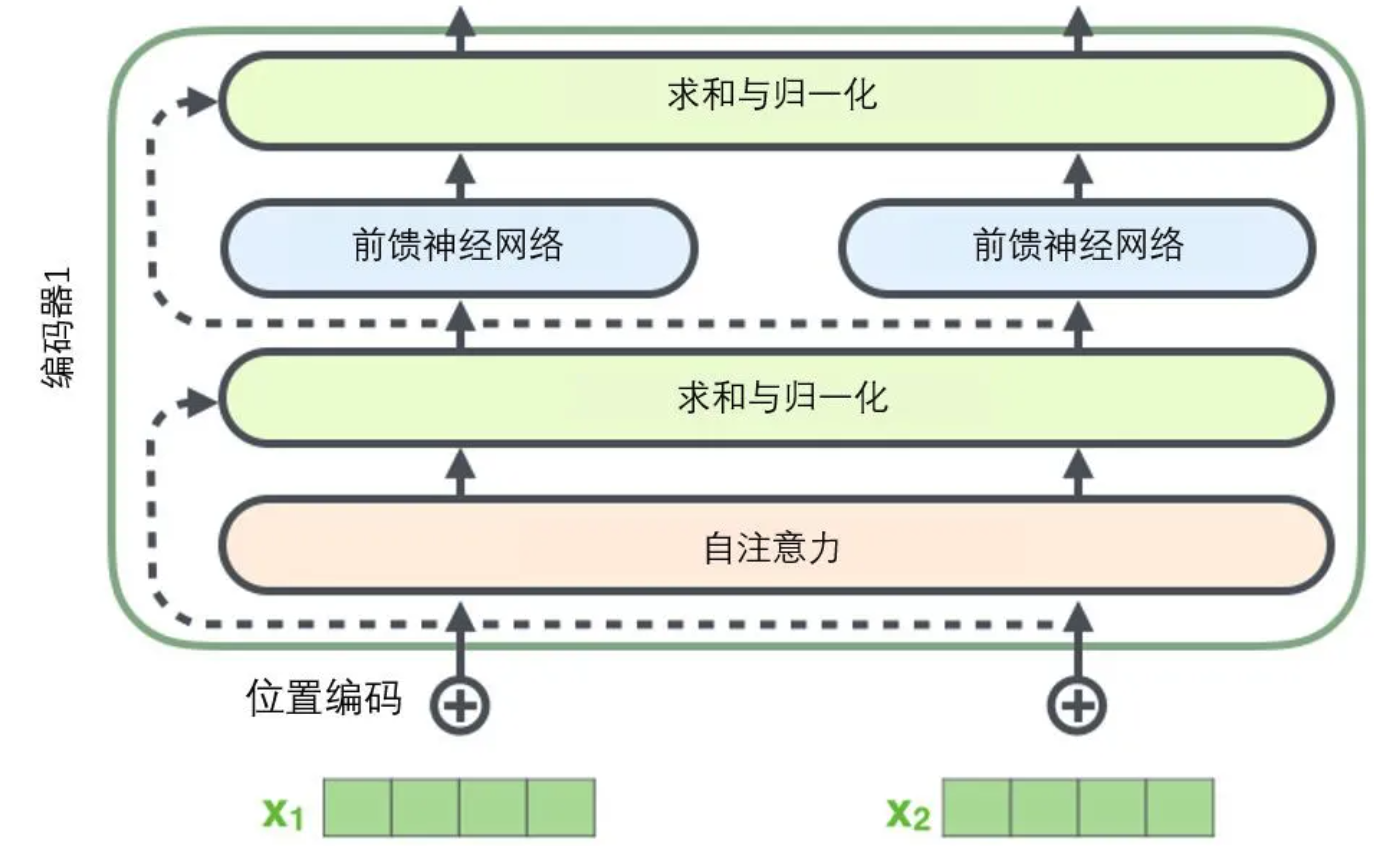
- encode 侧的流程图就如下图所示
Decode 侧
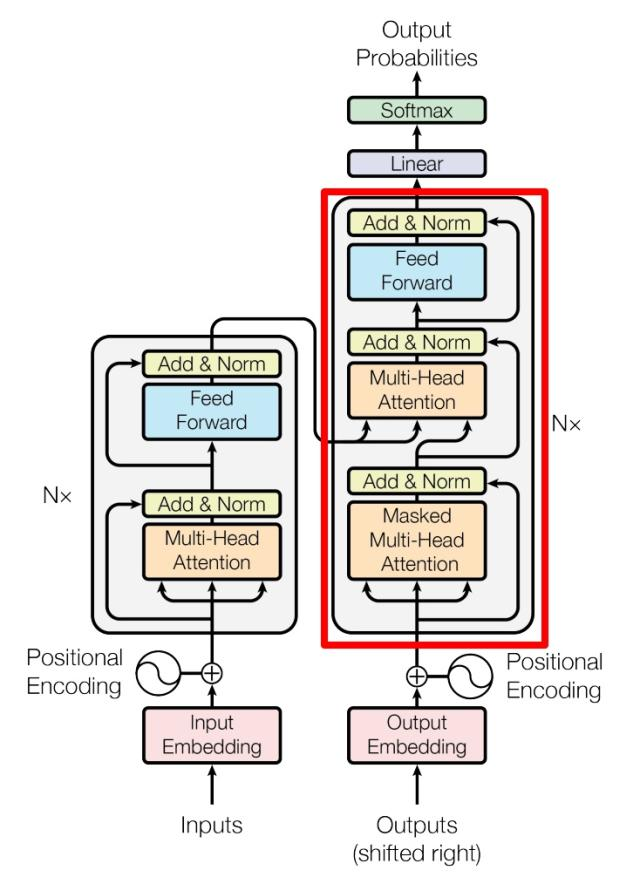
- decode部分和 encode 部分相似,但是也存在一些区别
- decode 侧有两个 multi-head attention 层
- decode 的第一个多头采用了 mask 操作,而第二个多头的 k,v 矩阵使用的是 encode 侧编码信息矩阵c(encode 的输出)计算,而 q 则是第一个 decode 侧的多头的输出计算
- 最后包含一个softmax 层计算下一个翻译单词的概率(假设是翻译任务)
decode 侧第一个多头(下图来自不同来源,仅供参考)
-
这里要捋一捋思路哈,比如:在 encode 侧是对中文"我有一只猫"进行位置+特征 embedding 后进过一系列提取信息后,传入了 decode 侧来翻译成英文,那么英文预测也是一个序列需要一个一个预测,所以就要用到 mask操作来防止第 i 个单词知道第 i+1 个单词之后的意思,具体详解如下:

- 流程就是:首先输入< Begin >作为 decode 侧的开始标志预测第一个单词,得到 I 后,然后将"< Begin > I"作为下一次预测的输入,以此类推
- 具体操作其实是加了一个 与输入矩阵形状相同的mask 矩阵,这样就可以把每一次计算当前时间后的信息盖住;
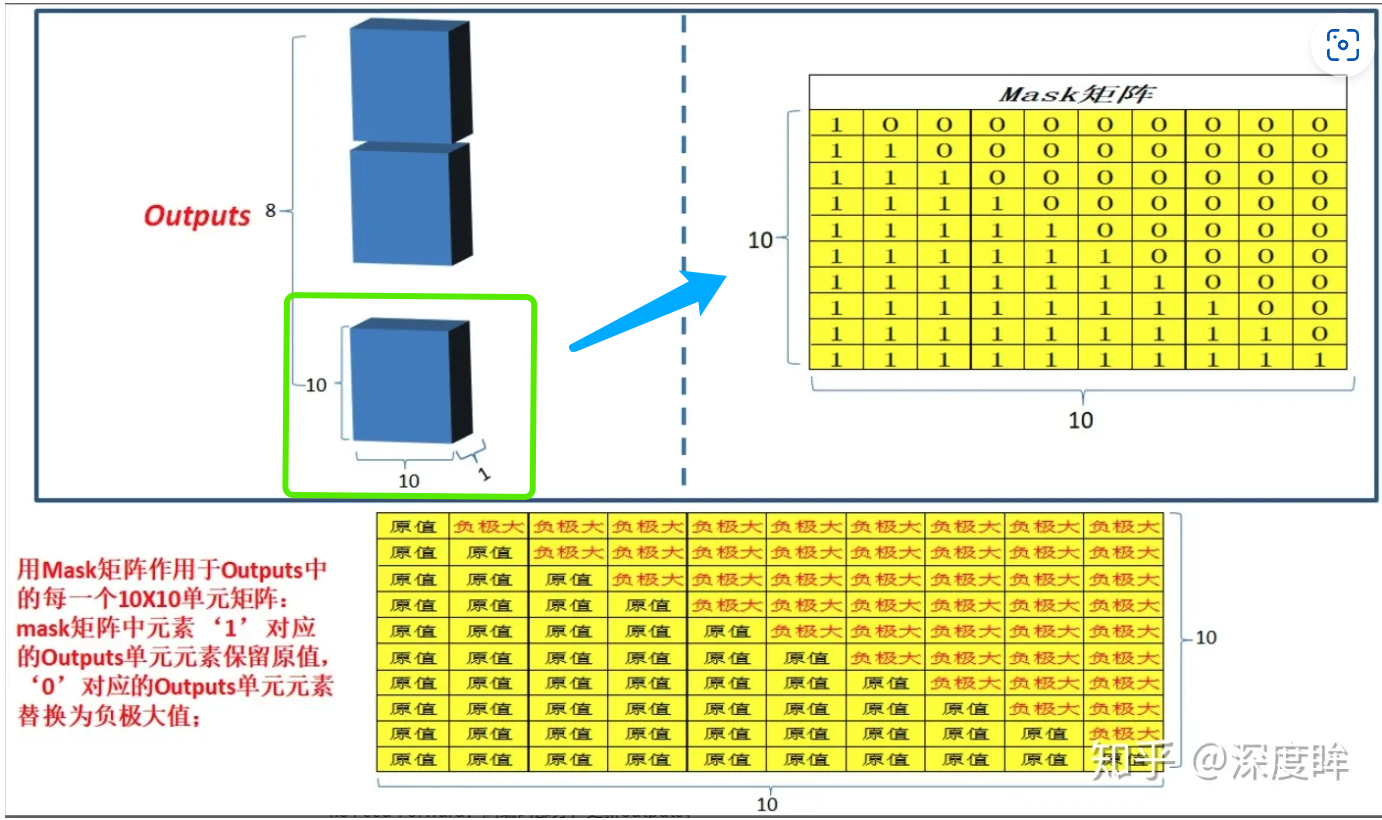
- 然后的操作就是和之前的自注意力一样,通过输入矩阵 x 计算得到 q,k,v 矩阵然后计算 q 和 k转置的乘积,但是再softmax 之前需要乘以mask 矩阵,如下图所示
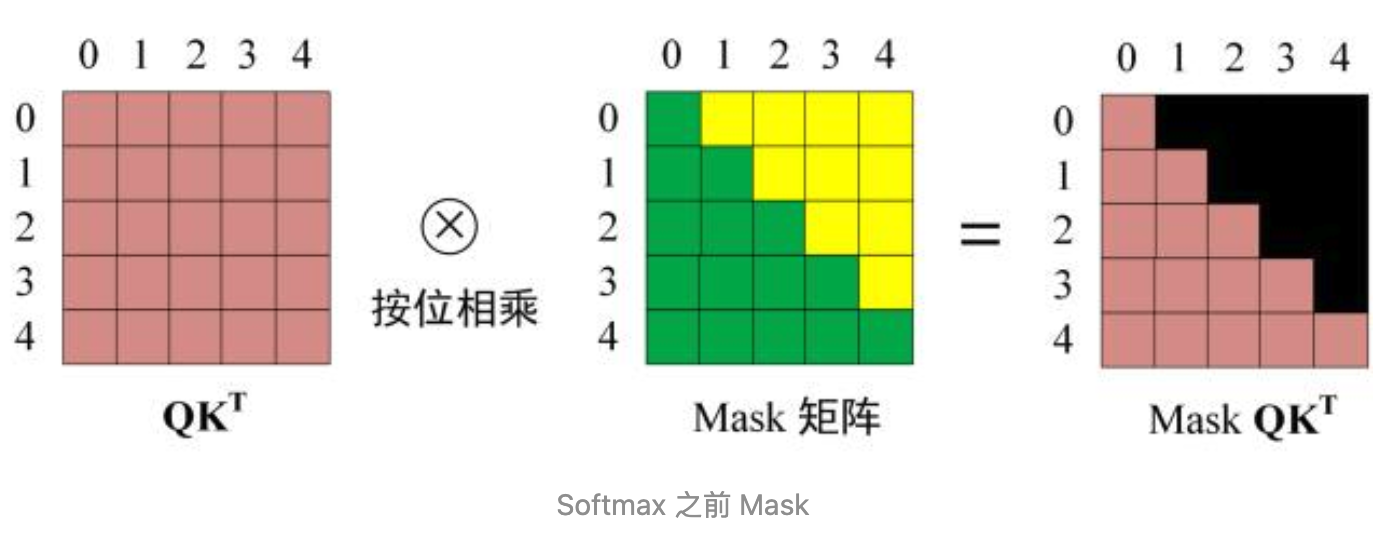
- 得到的 mask QK^T进行 softmax 就会发现单词 0 那一行 1234 的位置都是 0,因为我们设置的是负无穷映射后就成 0 了,再去与矩阵 v 得到矩阵 z
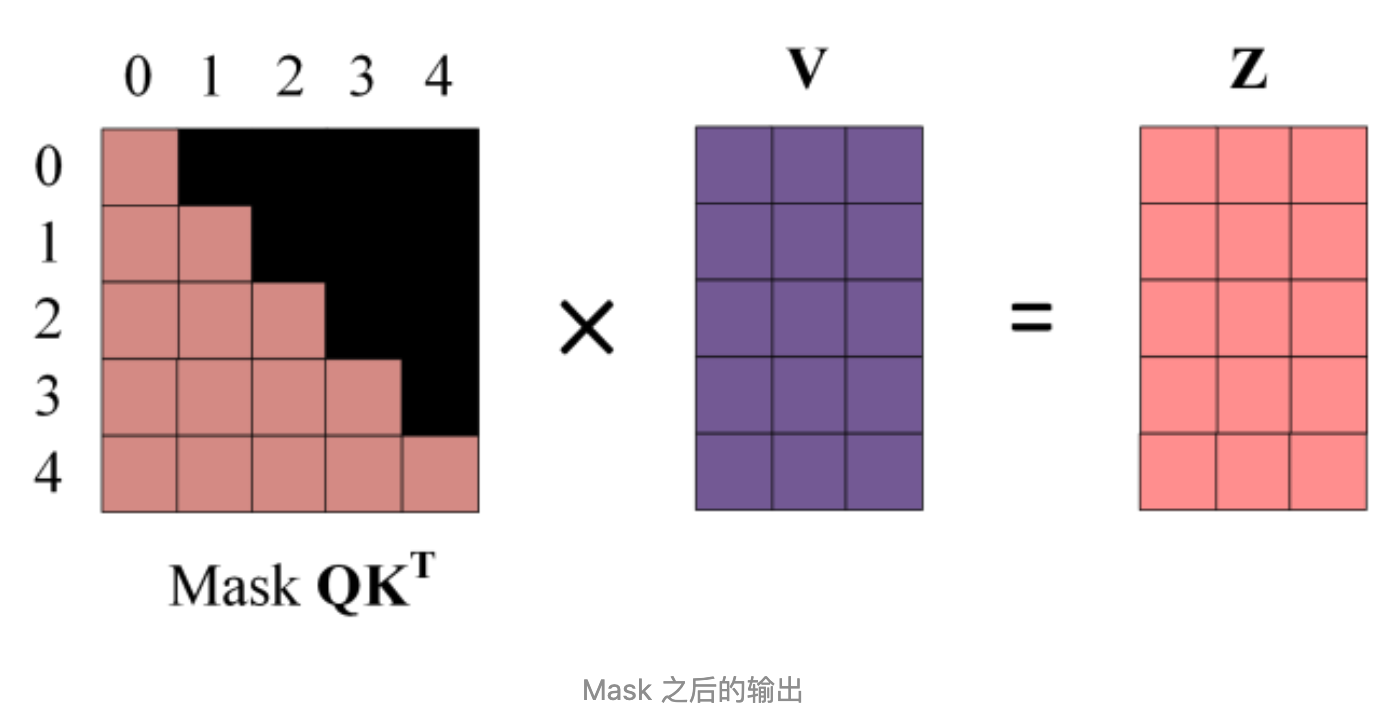
-
此处我有一个一直没看懂的疑问,为啥要加 mask,我查阅了很多文章都是说为了让模型预测第 i+1 的时候只能使用 i+1 前的信息,但是场景类似于完型填空,因为self attention 是使用的上下文信息是全文的,所以它是提前知道信息的,所以需要加 mask,但是比如这个翻译,是怎么提前看到的呢?搞了半天才明白一个重点,就是上面讲述的 decode 侧的输入,train 的时候decode 侧输入的是正确答案,所以要 mask
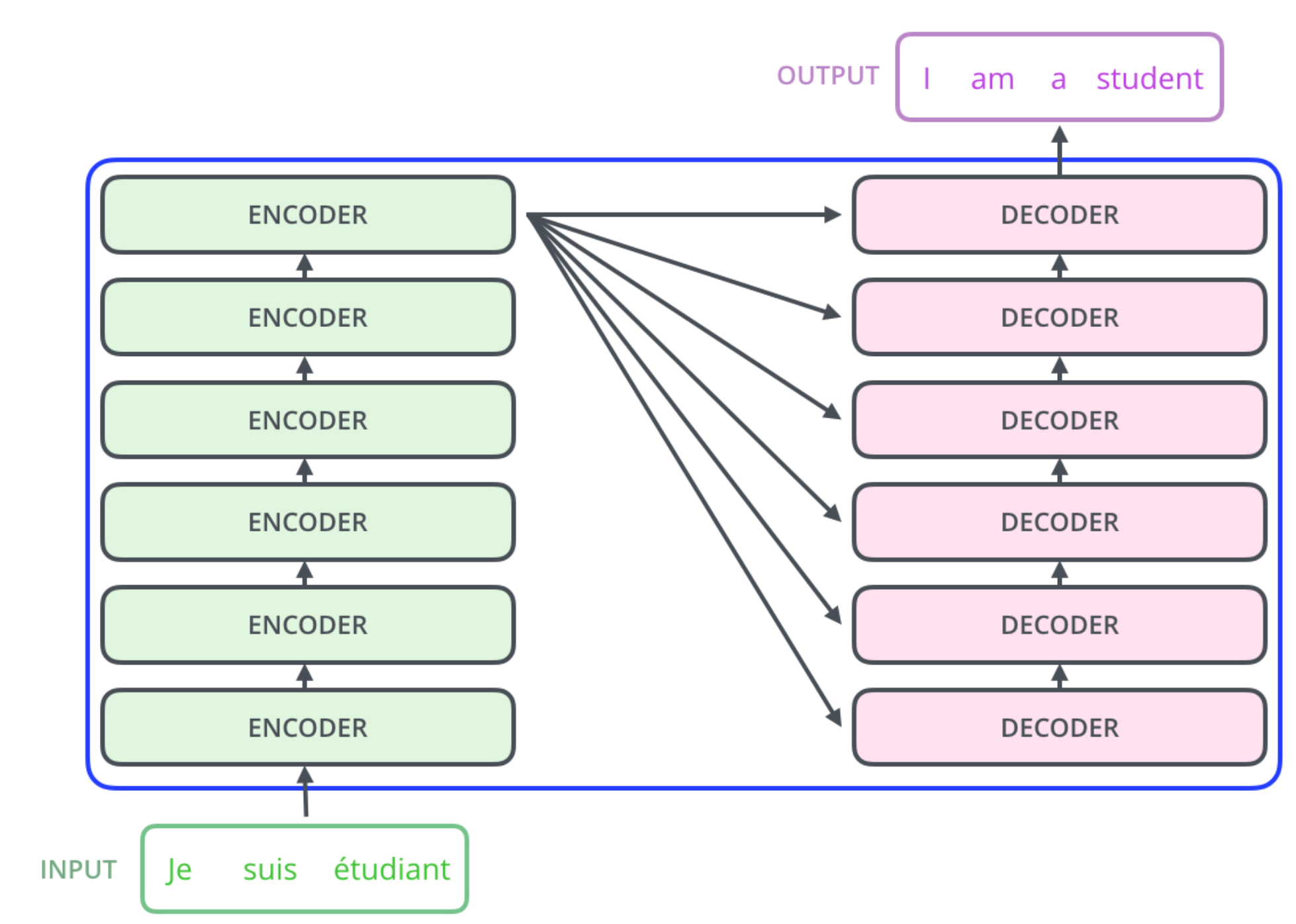
- 补:train 的时候使用的 teacher forcing,啥意思呢就是mask 后让预测,不管预测是对是错都会在预测下一个的时候使用前一个预测的正确答案防止错误一个把模型预测方向带偏,但是 test 模型下就没有正确答案了,这时使用的就是走完所有 decode 流程的预测词来进行下一个预测了,而不是走一层(看下图,其实就是多头铺平了),也就是走过完整多头的预测结果
- 关于transforer 的并行问题,可以并行参考
mask参考 1
mask参考 2
decode 侧第二个多头
- 这个多头的区别就是输入,自注意力的 k,v 矩阵使用的 encode 侧输出的编码信息矩阵 c,第一个多头提供的输出计算 q,(train 的时候)此处的 q 就是加了掩码的正确信息,而 kv 是原始信息,好处就是 q 这边的每一个信息都可以利用上 encode 侧的所有信息,这些信息是不需要 mask 的
softmax 预测输出
- 此部分图片 softmax参考
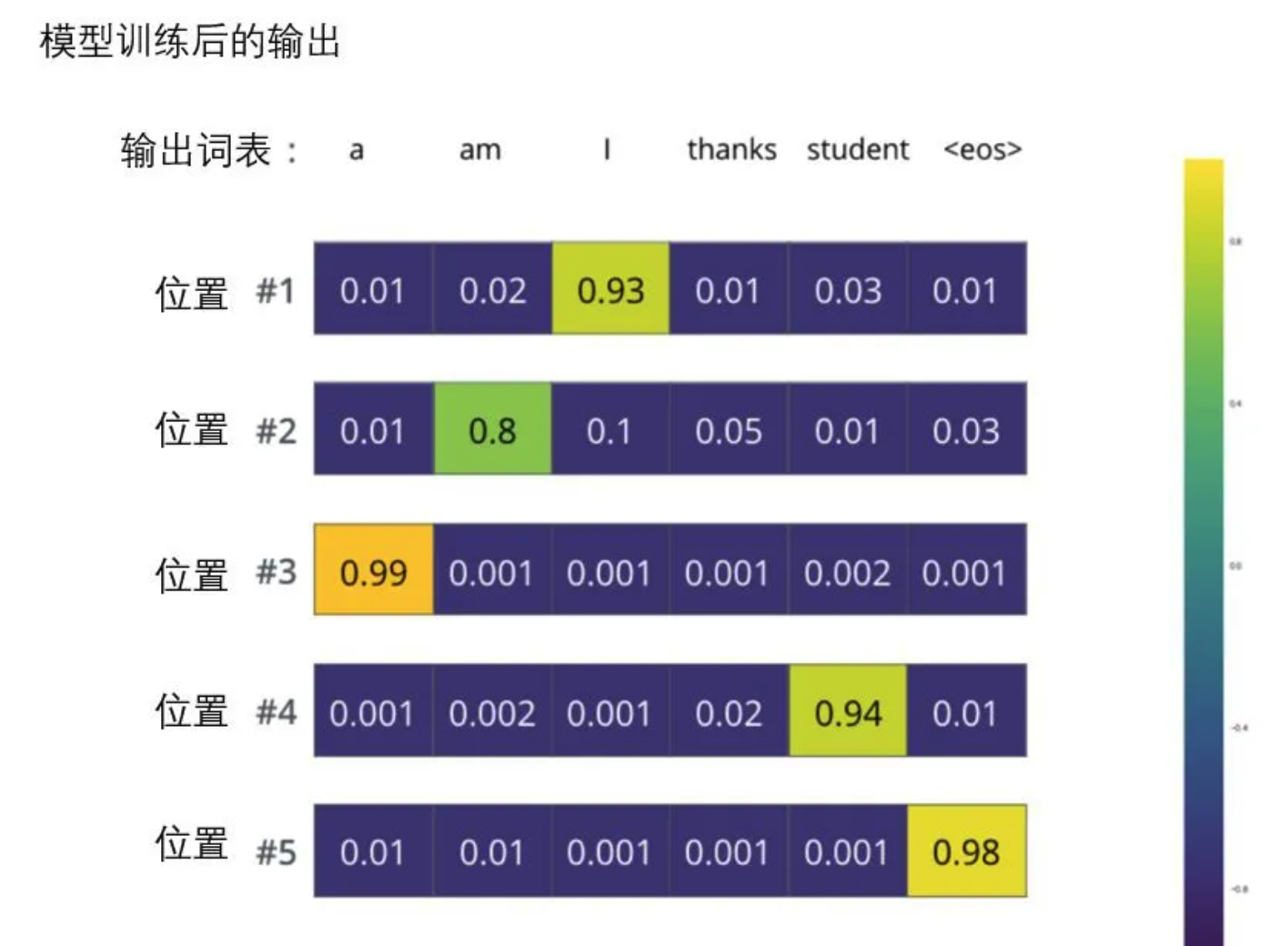
- 还可以看此篇 有动图更生动形象,因为 gif 我这个编辑器不支持插入。。。
结尾
- 上述基本就是个人对 transformer 原理的一个理论梳理,还有很多细节没有展开,也不太理解,可能在后面的代码篇会对细节增加一些补充,仅供参考
- 最后再次祝自己金九银十能找到一个理想的工作!!!冲鸭~
![[acwing周赛复盘] 第 120 场周赛20230909](https://img-blog.csdnimg.cn/c0a7734816574bd9bf11ece5ab4772bc.png)