文章目录
- 前言
- 为什么叫小也
- 本系列适合什么样的人阅读
- 正文
- 单体
- 优点
- 缺点
- CAP
- 为什么CAP不可能全部满足?
- CAP 三选二
- 分布式事务
- 分布式方案——Seata
- XA模式(强一致)
- AT模式(自动补偿,默认模式)
- TCC模式(手动补偿)
- Saga模式(长事务)
- 四种模式的区别
- 分布式锁
- ZooKeeper 实现分布式锁
- Redis 实现分布式锁
- 区别
- 总结
前言
做Java开发多年,一直以来都有想把Java做成一个系列的想法,最近整理自己的笔记发现有很多值得写的内容,但这些内容又往往杂乱不堪。CSDN上有很多高质量的Java博客,但大多不是从一个人成长的角度去写的。而我们——一个技术人员——一个人,是在不断的学习中成长的,这样的过程如果能体现在系列博客中那真的就太好了。于是,终于下定决心,想花一段时间整理成册——或许是几个月,或许是半年,或许是一年不止。希望自己能坚持下去。
为什么叫小也
孩子是我们之所以还努力的原因。
本系列适合什么样的人阅读
阅读本文最好有一定基础,最优人群是:
- 了解Java的基础语法
- 自己本身已经写过代码
- 对Java架构、大数据、轻代码等进阶有兴趣
如果你是个初出茅庐的初学者,对Java技术内容都不甚了解,也不用特别担心,我的另外一个系列你肯定感兴趣——《Java8系列博文合集》(或者访问我的博客园也可以阅读)。
正文
上一章内容大体描述了什么是分布式,以及分布式和微服务等架构的关系。接下来,我们要详细讨论分布式,以及如何在实战实战中使用。
上一章里,小也使用分布式思路帮助叔叔解决了厨房出餐效率的问题。那么,到底什么是分布式?
如果用一句话描述分布式:
将系统分别发布在不同的服务器,就是分布式。
分布式不是一种特指的代码架构,更多的是一种解决问题的方法。比如:我们可以说微服务就使用了分布式的思路,但微服务≠分布式。
在实战中,分布式更强调部署方式,而不是开发。
单体

同样以厨房为例:厨师=软件程序,工作台=服务器硬件。
单个软件运行在单个服务器上,就是单体系统。
在以往,最初的系统结构较为简单时,大多都是单体系统。
优点
- 开发简单,代码集中管理
- 部署便捷,运维成本低
- 测试直观,集成测试无需模拟外部服务
缺点
- 扩展性差,只能整体扩容,无法按需伸缩
- 复杂性高,代码臃肿,依赖关系复杂
- 技术更新难,升级技术栈需全局重构
- 故障隔离差,单点故障可能影响全局
随着社会发展,程序逻辑越来越复杂,单体系统劣势越来越明显,高并发、高可用的呼声越来越大了。在这种情况下,必须出现一种模式解决单体系统的问题。
CAP
CAP 定理(Consistency, Availability, Partition Tolerance)是分布式系统中的一个基本理论,指出在一个分布式系统中,不可能同时满足以下三个特性:
- 一致性(Consistency, C):所有节点访问同一份最新的数据副本。
- 可用性(Availability, A):所有的请求都能收到一个响应,无论数据是否是最新的。
- 分区容忍性(Partition Tolerance, P):系统能够继续运行,即使部分节点之间的通信失败。
为什么CAP不可能全部满足?
回到小也遇到的厨房问题。
厨房最开始只有一位厨师+一个工作台,当出现任何问题,如:工作台损坏或厨师生病,就会导致不能出餐。
小也开始思考这些问题,得出了一系列结论,如果要让饭店良好的运转,应该满足以下要求:
- 一致性:不管是哪位厨师做餐,只要是同一个菜品,厨师出的餐就应该是一样的。
- 可用性:不管是何时何地点餐,厨师都应该及时做出指定的菜品。
- 分区容忍性:不管遇到任何问题,哪怕是某位厨师生病或工作台损坏,都不影响出餐。
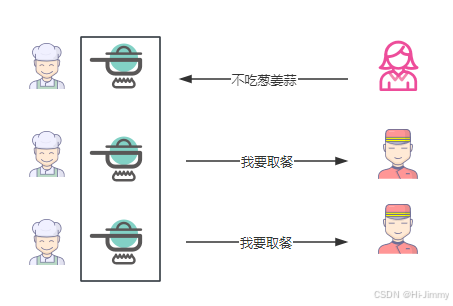
但在实际操作中,小也很快发现了新问题:
一致性与可用性冲突:有一天,三位厨师正在为一桌客人做菜,做了一半时,客人告诉A厨师她不吃葱姜蒜,这时服务员也同时来取餐。A厨师立马停下了加葱姜蒜的手,但还没来得及告诉其他两位厨师,他们的菜已经做好(有葱姜蒜)。如果从一致性角度,厨师出的餐必须符合一致要求——A厨师应该立即告诉其他厨师去掉葱姜蒜重新做——再出餐。但从可用性角度,这时候服务员已经来取餐,不能让客人获取不到。
假设: 存在一个分布式系统同时满足C、A、P
当网络分区发生时:
根据A(可用性),系统必须响应所有请求
根据C(一致性),所有节点数据必须同步更新
但分区导致节点间无法实时通信,无法完成同步
结论:假设不成立,三者无法共存
CAP 三选二
根据CAP定理,分布式系统只能在以下三种方案中选择两者:
- CP(Consistency + Partition Tolerance):保证数据一致性,即使某些节点发生分区故障,系统可能无法响应部分请求。例如:HBase、MongoDB(某些模式)。
- AP(Availability + Partition Tolerance):保证系统高可用性,即使发生分区,数据可能是不一致的。例如:Cassandra、DynamoDB。
- CA(Consistency + Availability):只在没有网络分区时成立,通常单机数据库(如传统的关系型数据库)可以满足。

如果选择:
- CA:就是单体服务,因为没有分区,程序只在一个服务器运行,自然也能保证一致性和可用性。
- CP:使用通信让不同分区间的程序数据保持一致,如:数据库主从,使用加锁方式强制保持一致。但这样就丧失了实时性。
- AP:高并发模式下的系统可以同时允许多人访问,如:12306购票,可以使用缓存技术及时响应用户,但这样就丧失了一致性,导致在出票环节显示无票(痛苦的回忆 TT)。
分布式事务
分布式一旦成型后,还面临一个普遍的问题:任何关键流程一旦分布在不同服务器,就必须保证其所有环节的一致性。
以上文提到的12306购票为例:
提交订单→跳转第三方程序付款→确认付款成功→出票
假设这些程序分布在不同服务器,无论哪个程序出错都将导致订票失败。反过来讲,其中任何一个环节出错都应该终止订票。
分布式事务就是创造一个程序作为监视者,监控流程中的程序,当这些程序出现错误时,将整个订票流程回滚。
分布式方案——Seata
有了以上的理论基础,小也在面对分布式“炒菜”问题时,也有了结论:
如果能有一个人——比如饭店老板——专门控制菜品要求,让客人的需求及时反馈到厨房,同时让厨师按照要求做菜,这样就不会出现菜品不一致的问题。
Seata(Simple Extensible Autonomous Transaction Architecture)是阿里巴巴开源的分布式事务解决方案,提供AT、TCC、Saga 和 XA 四种事务模式,支持跨数据库、跨服务的分布式事务管理。
| 术语 | 说明 |
|---|---|
| TC | Transaction Coordinator(事务协调器):全局事务的调度者(独立部署) |
| TM | Transaction Manager(事务管理器):定义全局事务边界(@GlobalTransactional) |
| RM | Resource Manager(资源管理器):管理分支事务的资源(如数据库连接) |
TC:饭店老板,在饭店里协调客人完成点餐→出餐→吃饭→结账
TM:服务员,负责接待客人,确认其需求并报告给老板协调
RM:厨师,为每个客人出餐
XA模式(强一致)
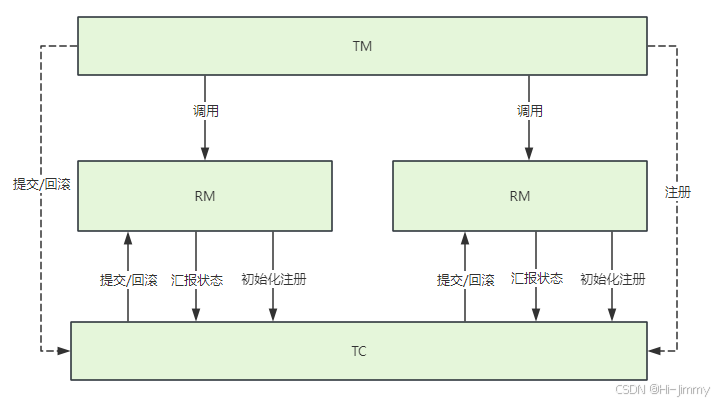
原理:基于数据库XA协议的两阶段提交
适用场景:传统数据库跨库事务(如银行核心系统)
流程:
- TM首先向TC注册
- TM分别调用RM
- RM各自向TC注册
- RM各自执行操作并向TC汇报状态(正常或异常)
- TM从TC处获取各RM执行情况,并向TC提出提交/回滚
- TC要求所有RM执行统一操作:提交/回滚
AT模式(自动补偿,默认模式)
原理:通过代理数据源拦截SQL,生成逆向SQL实现回滚
适用场景:跨数据库事务(如MySQL、Oracle)

流程:
- TM首先向TC注册
- TM分别调用RM
- RM各自向TC注册
- RM各自执行操作并直接提交(commit),将操作记录到undolog表,之后向TC汇报状态(正常或异常)
- TM从TC处获取各RM执行情况,并向TC提出提交/回滚
- TC要求所有RM执行统一操作:如果是提交则保留RM各自的执行结果,如果是回滚则根据undolog的内容进行反向恢复操作
一句话总结:AT是先执行错了都再改回去,XA是必须保证都对再执行。
TCC模式(手动补偿)
原理:通过 Try-Confirm-Cancel 三阶段实现
适用场景:跨境支付(汇率锁定+资金划转)
-
Try阶段:
- 预留资源(如冻结库存)
- 生成预备数据
-
Confirm阶段:
- 提交预备数据(如扣减冻结库存)
-
Cancel阶段:
- 释放预留资源(如解冻库存)
流程:
Try:冻结用户美元账户资金
Confirm:实际扣款并完成人民币入账
Cancel:解冻冻结资金(若汇率波动超阈值)
Saga模式(长事务)
原理:通过状态机编排服务调用,失败时执行补偿操作
适用场景:旅游平台多服务预订(酒店+机票+租车)
流程:
正向操作:预订酒店 → 预订机票 → 租车
补偿操作:若租车失败 → 取消机票 → 取消酒店
四种模式的区别
| 对比维度 | AT(自动补偿) | TCC(手动补偿) | Saga(长事务补偿) | XA(强一致性) |
|---|---|---|---|---|
| 实现原理 | 代理数据源生成逆向SQL回滚 | Try-Confirm-Cancel三阶段手动控制 | 正向服务链 + 逆向补偿链 | 数据库原生XA协议两阶段提交 |
| 一致性级别 | 最终一致性(默认) | 强一致性 | 最终一致性 | 强一致性 |
| 业务侵入性 | 低(仅需数据源代理) | 高(需实现Try/Confirm/Cancel接口) | 中(需定义补偿服务) | 无(数据库驱动实现) |
| 锁机制 | 一阶段提交即释放锁 | Try阶段锁定资源 | 无锁(依赖业务幂等) | 全程持有数据库锁 |
| 性能 | 高(本地事务快速提交) | 中(需多次RPC调用) | 低(长事务延迟高) | 低(两阶段同步阻塞) |
| 隔离性 | 通过全局锁实现读隔离 | 业务自行控制隔离性 | 无隔离(可能脏读) | 完全隔离 |
| 适用场景 | 跨数据库事务(如订单+库存) | 金融交易(如支付扣款) | 长流程业务(如机票预订) | 传统数据库跨库事务(如银行转账) |
| 典型框架 | Seata AT模式 | Seata TCC模式 | Apache ServiceComb Saga | Atomikos、Narayana |
| 补偿方式 | 自动生成反向SQL | 手动编写补偿逻辑 | 手动或配置式补偿 | 数据库自动回滚 |
| 数据一致性保障 | 最终一致性(允许短暂不一致) | 强一致性 | 最终一致性(需补偿成功) | 强一致性 |
分布式锁
小也用分布式事务的思维模式解决了流程上统一性的问题,但又有了新问题。
以前一个厨师的时候,大家点餐都是先来后到,反正就这么一个厨子,按顺序出餐就是了。但现在厨师多了,大家同时点餐时,厨师们有时候需要同时用到某一台厨具,这个时候就产生了竞争。
控制对同一对象/资源使用,就需要用到锁。
以前单体系统的时候,程序在一台服务器上,使用Java的自带锁就可以解决大部分问题,但现在程序分散在不同服务器,要保证业务流程正确的前提下,还要保证对竞争资源的顺序使用,就需要一个跨服务器的分布式锁。
Java架构中常用的分布式锁有:ZooKeeper 和redis。
ZooKeeper 实现分布式锁
利用 ZooKeeper 的 临时顺序节点 和 Watcher 机制 实现公平锁。
-
优点
强一致性:ZAB协议保证数据一致性
自动清理:临时节点自动删除避免死锁
公平锁:按节点顺序获取锁 -
缺点
性能较低:频繁创建节点和触发Watcher有延迟
依赖ZooKeeper集群:需维护ZooKeeper服务
Redis 实现分布式锁
通过 SETNX(或 SET 命令扩展参数)实现互斥锁,配合Lua脚本保证原子性。
-
优点
高性能:内存操作响应快
简单易用:API友好,支持多种客户端 -
缺点
非强一致:主从切换可能导致锁丢失(RedLock缓解但未彻底解决)
锁续期复杂:需处理过期时间与业务执行时间的匹配
区别
| 维度 | ZooKeeper | Redis |
|---|---|---|
| 一致性 | 强一致性(ZAB协议) | 最终一致性(主从同步延迟) |
| 性能 | 低(频繁节点操作和Watcher触发) | 高(内存操作) |
| 死锁处理 | 临时节点自动删除 | 依赖超时机制 |
| 锁类型 | 公平锁 | 非公平锁(Redisson可配置为公平锁) |
| 适用场景 | 需严格一致性的系统(如金融交易) | 高并发且允许短暂不一致的场景(如库存扣减) |
| 运维复杂度 | 需维护ZooKeeper集群 | 单节点简单,RedLock需多实例部署 |
总结
分布式虽然带来了高并发高可用的优点,但同时也带了新问题。以往单体服务的事务、锁机制都可以控制在单一服务器内解决,但现在不得不从多个服务器角度思考。于是,提出了分布式事务和分布式锁。其原理与单体服对应解决方案一致,但由于分布式复杂性,在实际解决时需要考虑不同服务器之间通信和状态同步。













![[首发]烽火HG680-KD-海思MV320芯片-2+8G-安卓9.0-强刷卡刷固件包](https://i-blog.csdnimg.cn/direct/eb76367b3a0b400d88fc778ff1a5990f.jpeg)
