十个问题带你走进计算机组成的世界
你知道 a = 1 + 2 这条代码是怎么被 CPU 执行的吗?
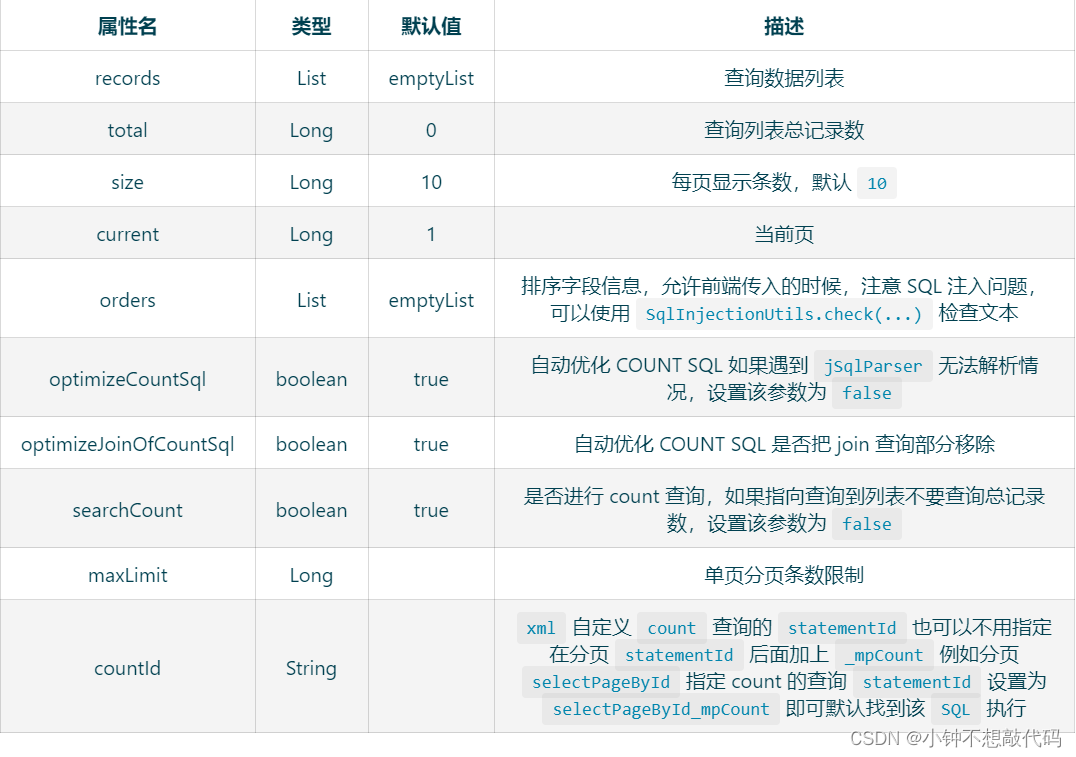
在计算机中,数据和指令是分开区域存放的,存放指令的区域的地方称为正文段,存放数据的区域称为数据段。
例如下图中,数据1和数据2存储在数据存放区域,取数指令和"加法"指令存放在指令存放区域。
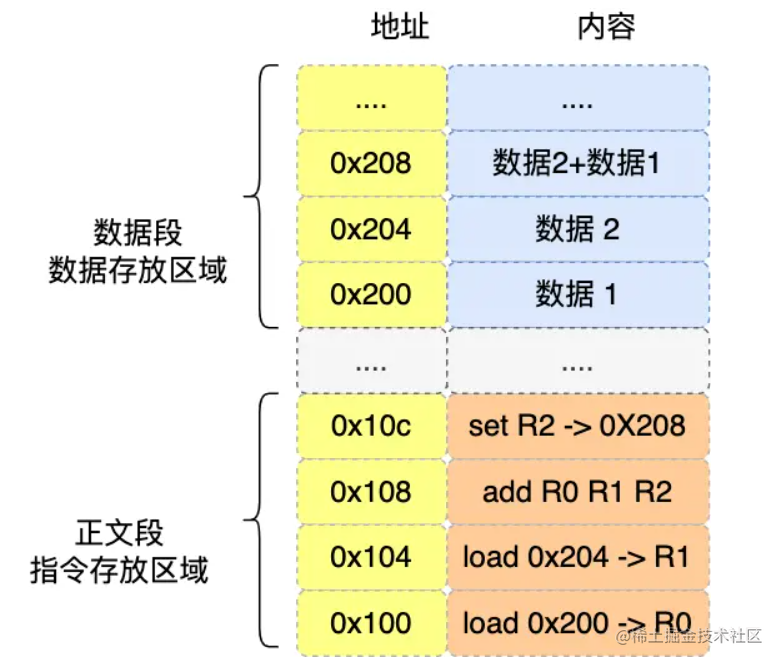
程序在编译完成后,在执行这个程序的时候,程序计数器的地址会被设置为0x100,然后依次执行正文段中的四条指令。
- 0x100中
load 0x200 ->R0指令是将0x200中数据1放入寄存器R0中。 - 0x104中
load 0x204 ->R1指令是将0x204中数据2放入寄存器R1中。 - 0x108中
add R0 R1 R2指令是将寄存器R0中的数据1和寄存器R1中的数据2相加并存入寄存器R2中。 - 0x10c中
set R2 -> 0x208指令是将寄存器R2的数据放入地址0x208内存,也就是变量a的地址。
大概内容就是:程序执行的时候,CPU会根据程序计数器(PC)里的内存地址,将内存中的需要执行的指令从内存中读取到指令寄存器(IR)中,然后指令寄存器(IR)分析该指令是什么指令,如果是计算类指令,就把指令交给逻辑运算单元(ALU)处理,如果是存储类型指令,就交给控制单元(CU)处理,然后接着根据指令长度自增,顺序读取下一条指令,直到这个程序结束。
软件用了那么多,你知道软件的 32 位和 64 位之间的区别吗? 32 位的操作系统可以运行在 64 位的电脑上吗?64 位的操作系统可以运行在 32 位的电脑上吗?如果不行,原因是什么?
64位和32位软件,实际上代表指令是64位和32位的。
- 如果32位指令在64位机器上执行,需要一套兼容机制,就可以做到兼容运行了。但是如果64位指令在32位上执行,就比较难了,因为32位的寄存器存不下64位的指令。
- 操作系统其实也是一种程序,我们也会看到操作系统会分为32位操作系统和64位操作系统,其代表意义就是操作系统中程序的指令是多少位,比如64位操作系统,指令也就是64位,因此不能装在32位机器上。
总之,硬件的64位和32位指的是CPU的位宽,软件的64位和32位指的是指令的位宽。
64 位相比 32 位 CPU 的优势在哪吗?64 位 CPU 的计算性能一定比 32 位 CPU 高很多吗?
64位相比32位CPU的优势主要体现在两个方面:
- 64位CPU计算超过32位的数据只需要一次就可以,而32位的CPU计算超过的数据,要分为多个步骤进行计算,效率就会比64位CPU差,但是一般大部分的程序很少会计算那么大的数字,所以只有运算超过32位大数字的时候,64位CPU的优势才能体现出来,否则和32位的计算性能差距不大。
- 一般64位CPU的地址总线是48位(下述原因),而32位CPU的地址总线是32位,所以64位CPU可以寻址更大的物理内存空间。如果一个32位CPU的地址总线是32位,那么该CPU最大寻址能力是
4G(2^32),即使你加了8G大小的物理内存,也还是只能寻址到4G大小的地址,而如果一个64位CPU的地址总线是48位,那么该CPU最大的寻址能力是2^48,远超于32位CPU最大寻址能力。
为什么64位的CPU的地址总线为48位呢?
因为当前版本的AMD64架构就规定了只用48位地址;一个表示虚拟内存地址的64位指针只有低48位有效并带符号扩展到64位——换句话说,其高16位必须是全1或全0,而且必须与低48位的最高位(第47位)一致,否则通过该地址访问内存会产生#GP异常(general-protection exception)。
只用48位的原因很简单:因为现在还用不到完整的64位寻址空间,所以硬件也没必要支持那么多位的地址。
机械硬盘、固态硬盘、内存这三个存储器,到底和 CPU L1 Cache 相比速度差多少倍呢?
从寄存器、CPU Cache,到内存、硬盘,这样一层一层下来的存储器,访问速度越来越慢,存储容量越来越大,价格也越来越便宜,而且每个存储器只和相邻的一层存储器设备打交道,于是这样就形成了存储器的层次结构。
- CPU L1 Cache 随机访问延时是1纳秒,内存则是100纳秒,所以CPU L1 Cache 比内存快
100倍左右 - SSD随机访问延迟是150微秒,所以CPU L1 Cache比SSD快
150000倍左右 - SSD比机械硬盘快
70倍左右 - 内存比机械硬盘快
100000倍左右 - CPU L1 Cache 比机械硬盘快
10000000倍左右
有了内存,为什么还需要 CPU Cache?
上个问题提到,CPU访问L1 Cache速度比访问内存快100倍,这就是为什么CPU里会有L1~L3 Cache的原因,目的就是把Cache作为CPU与内存之间的缓存层,以减少对内存的访问频率。
CPU 是怎么读写数据的?
CPU 从内存中读取数据到 Cache 的时候,并不是一个字节一个字节读取,而是一块一块的方式来读取数据的,这一块一块的数据被称为 CPU Cache Line(缓存块),所以 CPU Cache Line 是 CPU 从内存读取数据到 Cache 的单位。
至于 CPU Cache Line 大小,在 Linux 系统可以用下面的方式查看到,你可以看我服务器的 L1 Cache Line 大小是 64 字节,也就意味着 L1 Cache 一次载入数据的大小是 64 字节。
什么是软中断?
中断处理程序应该要短且快,这样才能减少对正常进程运行调度地影响,而且中断处理程序可能会暂时关闭中断,这时如果中断处理程序执行时间过长,可能在还未执行完中断处理程序前,会丢失当前其他设备的中断请求。
Linux系统为了解决中断处理程序执行过长和中断丢失的问题,将中断过程分为了两个阶段,分别为上半部分和下半部分。
- 上半部分用来快速处理中断,一般会暂时关闭中断请求,主要负责处理跟硬件紧密相关或者时间敏感的事情。
- 下半部分用来延迟处理上半部未完成的工作,一般以[内核线程]的方式运行。
eg:
网卡收到网络包后,通过 DMA 方式将接收到的数据写入内存,接着会通过硬件中断通知内核有新的数据到了,于是内核就会调用对应的中断处理程序来处理该事件,这个事件的处理也是会分成上半部和下半部。
上部分要做的事情很少,会先禁止网卡中断,避免频繁硬中断,而降低内核的工作效率。接着,内核会触发一个软中断,把一些处理比较耗时且复杂的事情,交给「软中断处理程序」去做,也就是中断的下半部,其主要是需要从内存中找到网络数据,再按照网络协议栈,对网络数据进行逐层解析和处理,最后把数据送给应用程序。
所以,中断处理程序的上部分和下部分可以理解为:
上半部直接处理硬件请求,也就是硬中断,主要是负责耗时短的工作,特点是快速执行。下半部是由内核触发,也就是说软中断,主要是负责上半部未完成的工作,通常都是耗时比较长的事情,特点是延迟执行;
为什么负数要用补码表示?
如果负数不是使用补码的方式表示,则在做基本对加减法运算的时候,需要多一步操作来判断是否未负数,如果为负数,还得把加法反转成减法,或者把减法反转成加法,就非常不好了,所以为了性能考虑,应该尽量简化这个运算过程。
而用了补码的表示方式,对于负数的加减法操作,实际上是和正数加减法操作一样的。
计算机是怎么存小数的?
计算机是以浮点数的形式存储小数的,大多数计算机都是IEEE 754 标准定义的浮点数格式,包含三个部分:
- 符号位:表示数字是正数还是负数,为0表示正数,为1表示负数。
- 指数位:指定了小数点在数据中的位置,指数可以是负数,也可以是正数,指数位的长度越长则数值的表示范围就越大;
- 尾数位:小数点右侧的数字,也就是小数部分,比如二进制
1.0011 x 2^(-2),尾数部分就是0011,而且尾数的长度决定了这个数的精度,因此如果要表示精度更高的小数,则就要提高尾数位的长度;
用 32 位来表示的浮点数,则称为单精度浮点数,也就是我们编程语言中的 float 变量,而用 64 位来表示的浮点数,称为双精度浮点数,也就是 double 变量。
为什么 0.1 + 0.2 == 0.3 吗?
不等于,0.1和0.2这两个数字用二进制表达会是一个一直循环的二进制数,比如0.1的二进制表示为0.00011 0011 0011...(0011无限循环),对于计算机而言,0.1无法精确表达,这是浮点数计算造成精度损失的根源。
因此,IEEE 754标准定义的标准数只能根据精度舍入,然后用【近似值】来表示该二进制,那么意味着计算机存放的小数可能不是一个真实值。
0.1+0.2并不等于完整的0.3,这主要是因为这两个小数无法用【完整】的二进制来表示,只能根据精度舍入,所以计算机里只能采用近似数的方式来保存,那两个近似数相加,得到的必然也是一个近似数。








![[JAVAee]IP数据包的组包与分包](https://img-blog.csdnimg.cn/4afcfdd09e824e4fbda1ee410ed9ee80.png)

