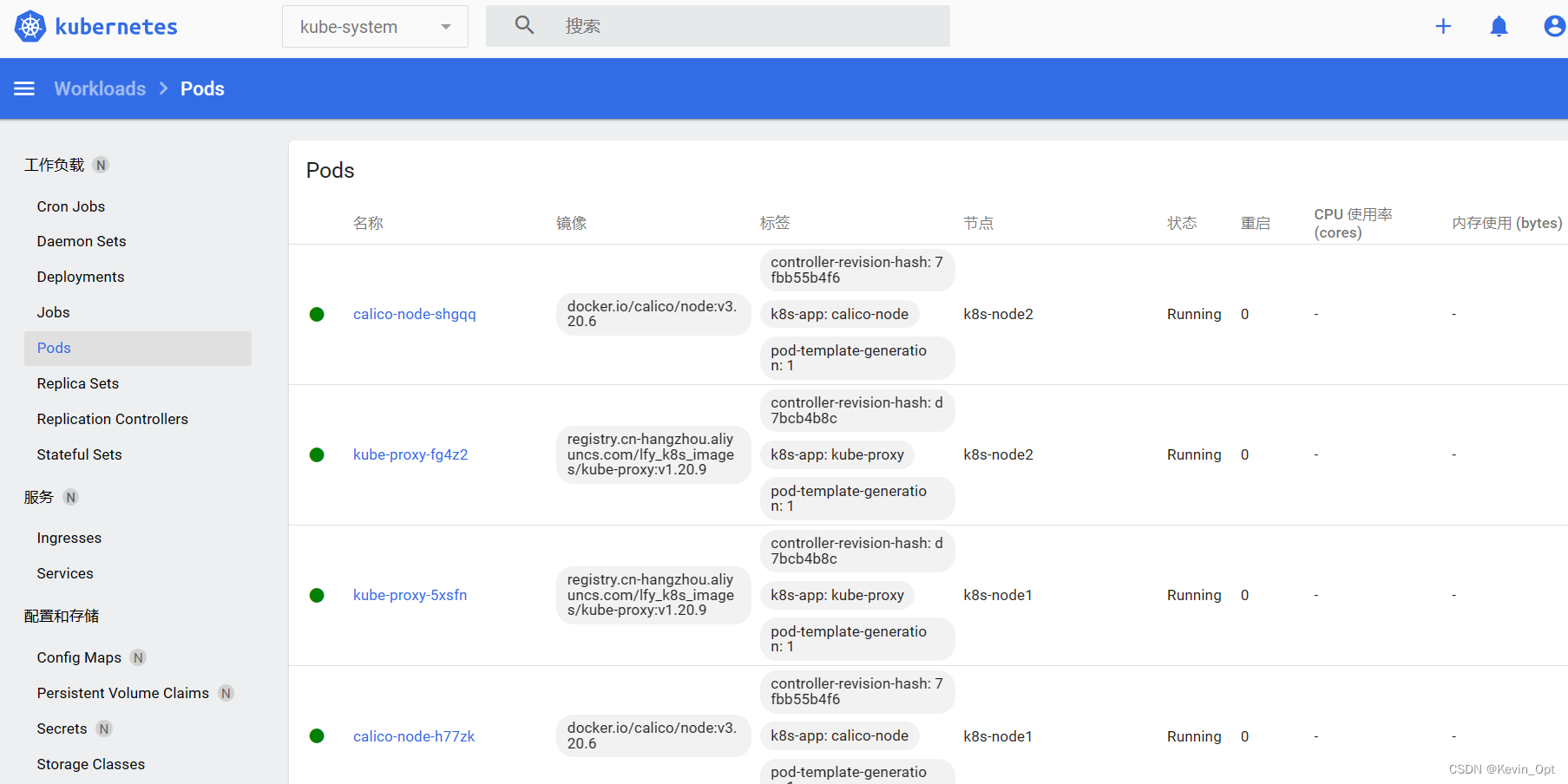
jieba库,python提供的中文分词函数库的第三方库,它可以将一段中文文本分割成中文词语序列。
安装jieba库
pip install jieba
jieba的三个模式
-
全模式 - - -
jieba.lcut(s,cut_all=True)- - - 速度非常快,但有冗余数据 -
精确模式(最常用) - - -
jieba.lcut(s)- - - 适合文本分析 -
搜索引擎模式 - - -
jieba.lcut_for_search(s)- - - 在精确模式的基础上,对长词进行切分,适合用于搜索引擎分词三种模式都返回一个list类型
jieba.add_word(w) - - - 向分词字典中添加新词w
jieba.del_word(w) - - - 将词典中的词语w删除
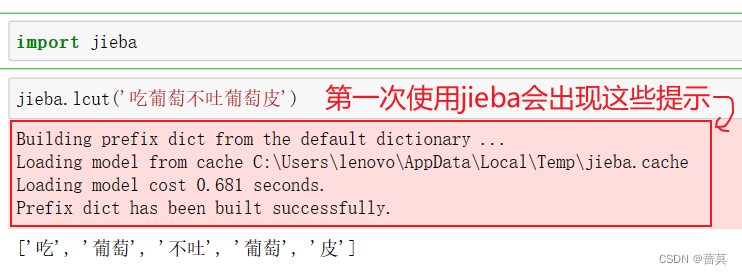
import jieba
jieba.lcut('吃葡萄不吐葡萄皮')
# ['吃', '葡萄', '不吐', '葡萄', '皮']
jieba.lcut('你们谁吃葡萄不吐葡萄皮?',cut_all=True)
# ['你们', '谁', '吃', '葡萄', '不', '吐', '葡萄', '皮', '?']
jieba.lcut_for_search('你们谁吃葡萄不吐葡萄皮?')
# ['你们', '谁', '吃', '葡萄', '不吐', '葡萄', '皮', '?']
jieba.add_word('吃葡萄不吐葡萄皮')
jieba.lcut('你们谁吃葡萄不吐葡萄皮?')
# ['你们', '谁', '吃葡萄不吐葡萄皮', '?']
其他常用方法
-
分词方法:jieba.cut(),可以将文本分成词语的列表,支持多种分词模式,如精确模式、全模式、搜索引擎模式等。
返回一个可迭代的生成器对象,使用list函数将其变为列表 -
jieba.add_word(word, freq=None, tag=None): 向词典中添加新词,freq表示词频,tag表示词性。
-
获取停用词:jieba.analyse.set_stop_words(stop_words_path),可以获取停用词列表,对于语义分析来说,停用词可以过滤掉一些无意义的词语。
-
关键词提取:jieba.analyse.extract_tags(sentence, topK=20, withWeight=False),可以提取文本中的关键词,并按照权重排序输出
topK表示返回关键词的个数,withWeight表示是否返回权重值import jieba.analyse jieba.analyse.set_stop_words(stop_words_path) jieba.analyse.extract_tags() -
Tokenize方法:jieba.tokenize(unicode_sentence, mode=‘default’, HMM=True),可以返回每个词的位置、长度和词语本身,可用于索引分词等功能。
-
jieba.load_userdict(file_name): 加载用户自定义的词典文件。


![[JAVAee]IP数据包的组包与分包](https://img-blog.csdnimg.cn/4afcfdd09e824e4fbda1ee410ed9ee80.png)