1 包装类
1.1 基本数据类型和对应的包装类 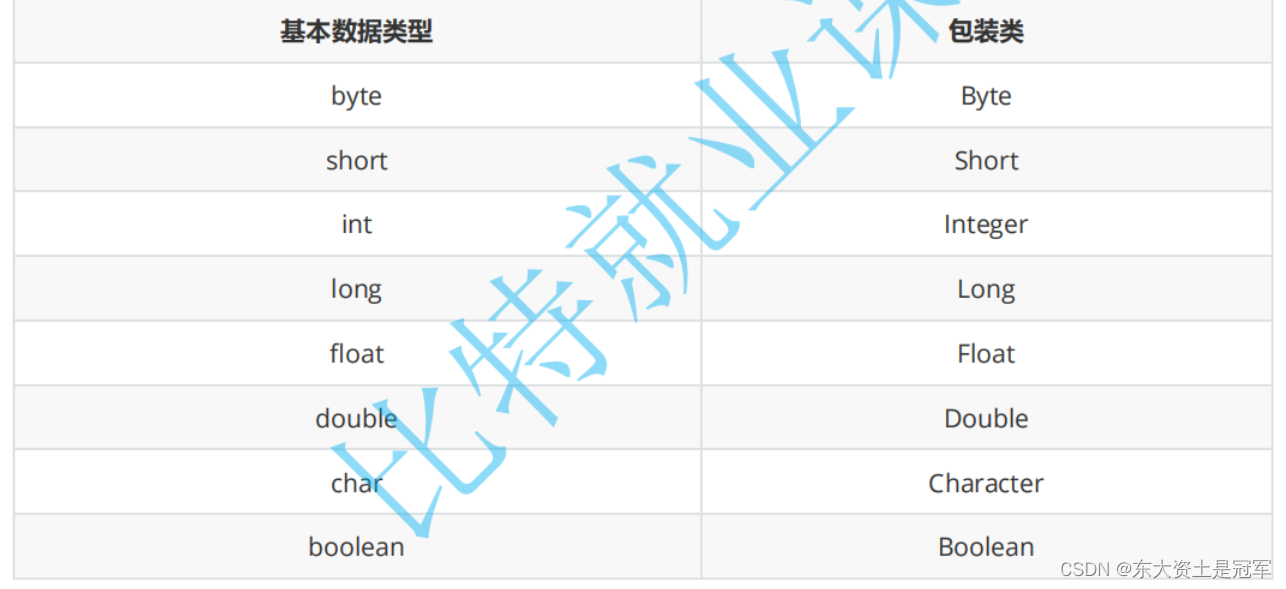
1.2 装箱和拆箱
装包/装箱 : 基本数据类型=>包装类类型
拆箱/拆包 : 包装类型=>基本类型
int i = 10;
// 装箱操作,新建一个 Integer 类型对象,将 i 的值放入对象的某个属性中
Integer ii = Integer.valueOf(i);
Integer ij = new Integer(i); // 显示装箱 底层还是调用Integer.valueOf(i);
// 拆箱操作,将 Integer 对象中的值取出,放到一个基本数据类型中
int j = ii.intValue(); // 显示拆箱1.3 自动装箱和自动拆箱
int i = 10;
Integer ii = i; // 自动装箱
Integer ij = (Integer)i; // 自动装箱
int j = ii; // 自动拆箱
int k = (int)ii; // 自动拆箱【阿里面试题】
public static void main(String[] args) {
Integer a = 127;
Integer b = 127;
Integer c = 128;
Integer d = 128;
System.out.println(a == b);
System.out.println(c == d);
}答案: 
解释: 四行代码都是对应自动装箱操作, 而自动装箱操作底层还是调用Integer.valueOf(i);
cache 是一个提前开辟好的长度为256的数组,
cache[0] 存放的是 -128 (-128 + (- ( -128 ) ) = 0 )
cache[255]存放的是127 (127 + (- ( -128 ) ) = 0 )
也就是说当传入valueOf()的值范围在-128~127之间时, 返回的值都是实现设置好的,因此为true
但128超出范围, 必须new一个新值, 两个值在不同地址上因此只能是false
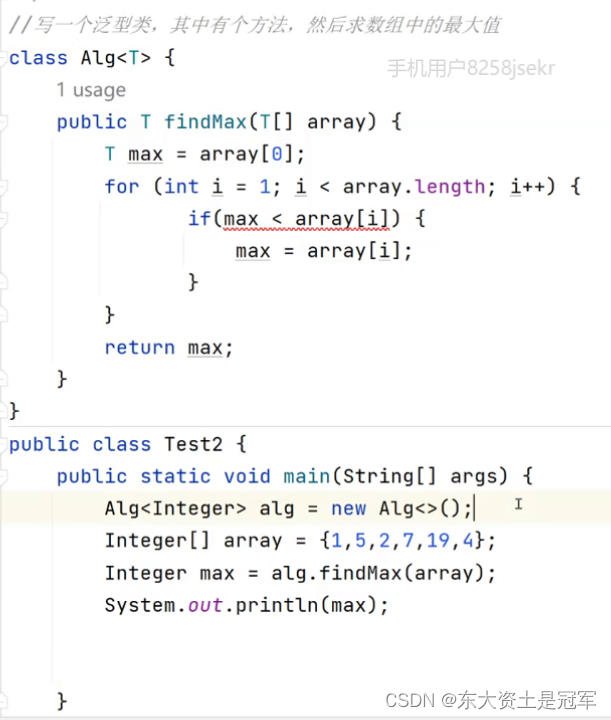
2 什么是泛型
3 引出泛型
- 我们以前学过的数组,只能存放指定类型的元素,例如:int[] array = new int[10]; String[] strs = new String[10];
- 所有类的父类,默认为Object类。数组是否可以创建为Object?
class MyArray {
public Object[] objects = new Object[10];
public Object getPos(int pos) {
return objects[pos];
}
public void setVal(int pos,Object val) {
objects[pos] = val;
}
}
public class TestDemo {
public static void main(String[] args) {
MyArray myArray = new MyArray();
myArray.setVal(0,10);
myArray.setVal(1,"hello");//字符串也可以存放
String ret = myArray.getPos(1);//编译报错
System.out.println(ret);
}
}编译报错地方 必须进行强制类型转化才能输出
String ret = (String)myArray.getPos(1);//编译报错
System.out.println(ret);/**
* @param <T> T是一个占位符,表示当前类是一个泛型类
*
*/
class MyArray2<T> {
//public Object[] objects = new Object[10];
public T[] objects = (T[])new Object[10];
//public T[] objects = new T[10]; //1
public T getPos(int pos) {
return objects[pos];
}
public void setVal(int pos,T val) {
objects[pos] = val;
}
}
public static void main2(String[] args) {
MyArray<Integer> myArray1 = new MyArray<Integer>(); //2
myArray1.setVal(0,48);
myArray1.setVal(1,10);
int val = myArray1.getPos(1); //3
System.out.println(val);
System.out.println("=======");
MyArray<String> myArray2 = new MyArray<>();
myArray2.setVal(0,"hello");
myArray2.setVal(1,"bit");
String ret = myArray2.getPos(1);
System.out.println(ret);
}1.注释 1 处,不能 new 泛型类型的数组意味着: T [] ts = new T [ 5 ]; // 是不对的, 这样写会报错, 报错原因后边说因为泛型不能在运行中被识别, 只能在编译中才能被识别课件当中的代码:T[] array = (T[])new Object[10]; 是否就足够好,答案是未必的。这块问题一会儿介绍。2. 注释 2 处,类型后加入 <Integer> 指定当前类型3. 注释 3 处,不需要进行强制类型转换
泛型存在的意义:
- 在编译的时候, 帮我进行类型的检查
- 在编译的时候, 帮我进行类型的转换
运行的时候是没有泛型概念的, JVM当中是没有泛型的
4. 泛型是如何编译的
4.1 擦除机制
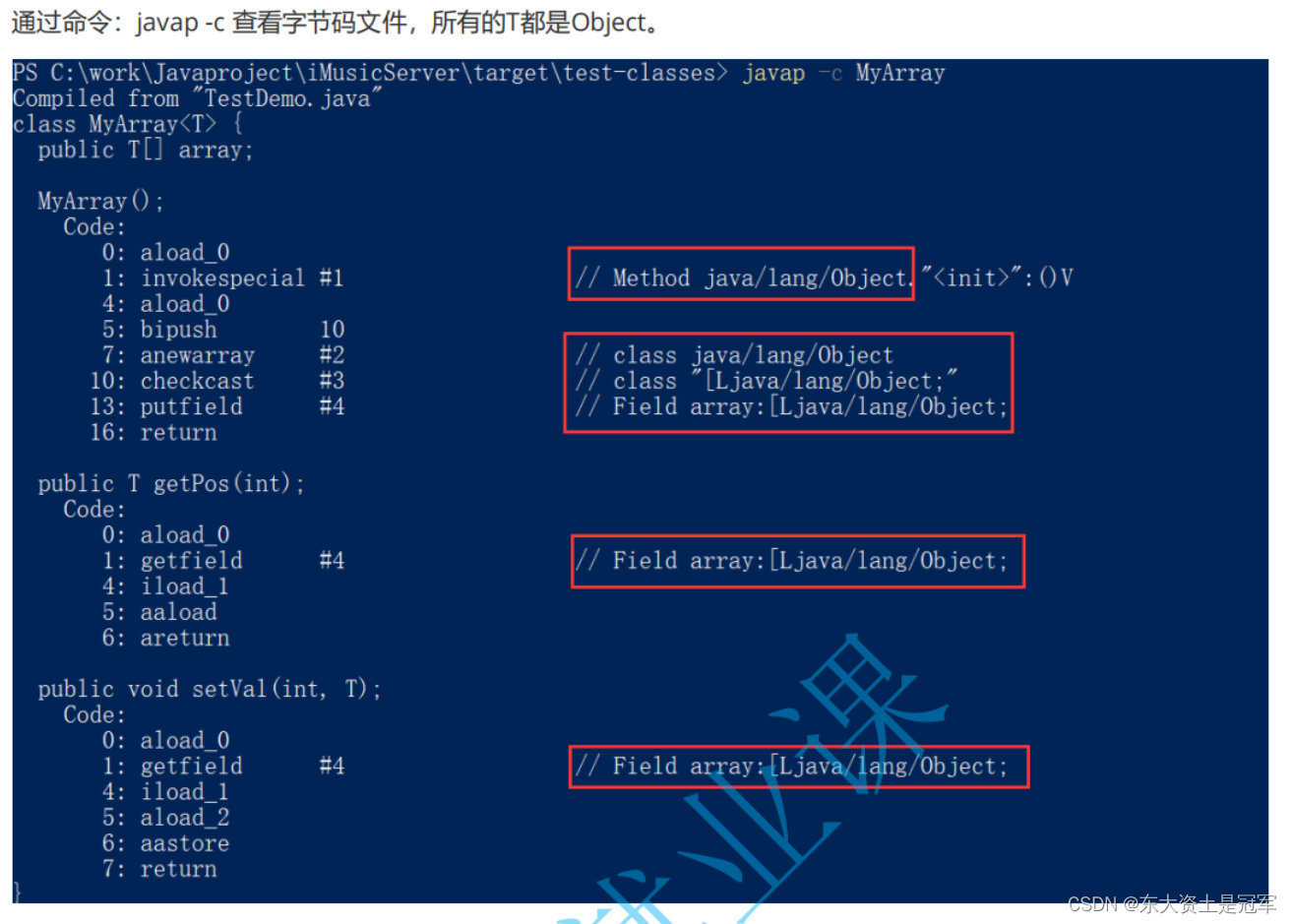
Java的泛型机制是在编译级别实现的。编译器生成的字节码在运行期间并不包含泛型的类型信息。
4.2 提出问题:
4.2.1
为什么,public T[] objects = new T[10]; 是不对的,编译的时候,替换为Object,不是相当于:Object[] ts = new Object[5]吗?那既然会替换为Object为什么会报错呢?
4.2.2 为什么T[] array = (T[])new Object[10 不够好
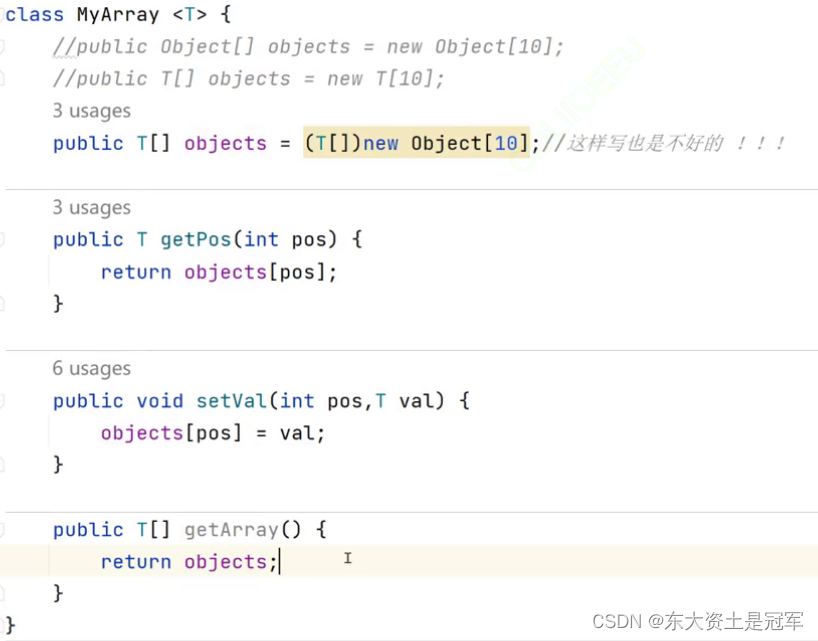


改进方法1: 用Object类型接收
既然不允许强转Object 那就只能用Object类型接收
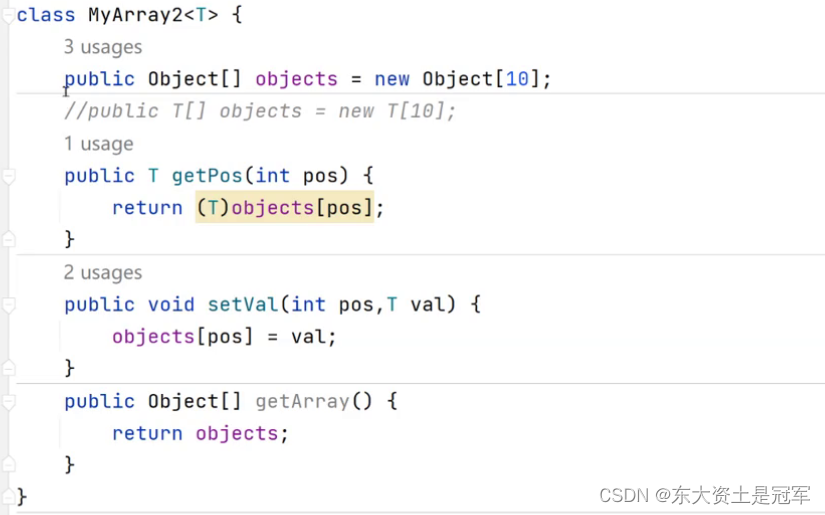
class MyArray2<T> {
//public Object[] objects = new Object[10];
public T[] objects = (T[])new Object[10];
//public T[] objects = new T[10]; //1
public T getPos(int pos) {
return objects[pos];
}
public void setVal(int pos,T val) {
objects[pos] = val;
}
public Object[] getArray() { // 也可以返回T[] 都一样最后也编译成Object[]
return objects;
}
}
public static void main2(String[] args) {
MyArray<Integer> myArray1 = new MyArray<Integer>();
Object[] integers = myArray1.gerArray();
}要是必须用具体Integer类型来接收呢? 更好的
改进方法2: 用反射创建指定类型的数组(了解即可)
改进方法1 myArray1内部创建过程中用是泛型类型数组, 而方法2内部创建过程中直接使用指定类型数组, 当然就不在需要因为擦除机制编译成Object类型了
class MyArray2<T> {
//public Object[] objects = new Object[10];
public T[] objects;
//public T[] objects = new T[10]; //1
/**
* 通过反射创建,指定类型的数组
* @param clazz
* @param capacity
*/
public MyArray(Class<T> clazz, int capacity) {
array = (T[])Array.newInstance(clazz, capacity);
}
public T getPos(int pos) {
return objects[pos];
}
public void setVal(int pos,T val) {
objects[pos] = val;
}
public T[] getArray() {
return objects;
}
}
public static void main2(String[] args) {
MyArray2<Integer> myArray2 = new MyArray2<>(Integer.class,10);
Integer[] integers = myArray2.getArray();
}最佳方法
那在实际工作中通常只需要直接使用Object类型数组就可以了, 只需要注意一下setVal()时存放T类型就可以了, getPos()取数据时候强制类型转换就可以了, 当然也需要用Object类型数组接收getArray()结果
我们以后就用这个方式写代码
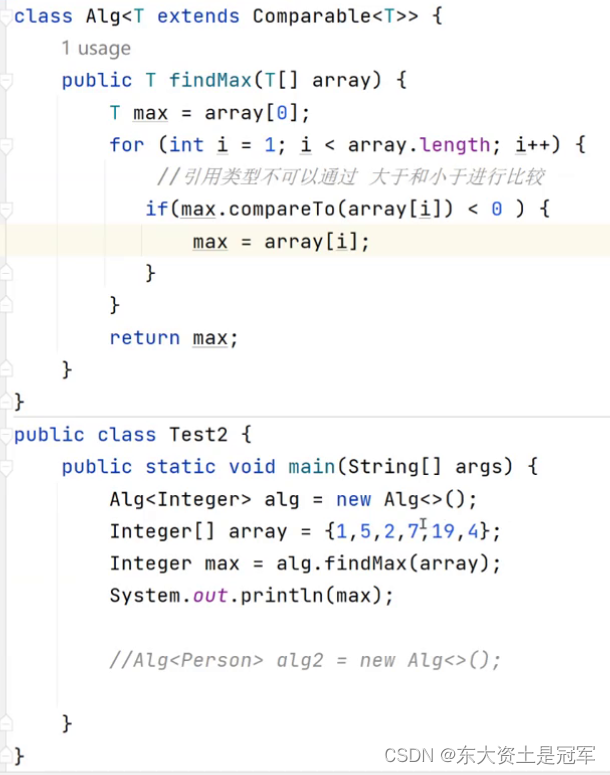
5. 泛型的上界
问题引入 , 红色部分出现的原因?