轻量容器引擎Docker
Docker是什么
Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目。
它基于 Google 公司推出的 Go 语言实现,项目后来加入了 Linux 基金会,遵从了 Apache 2.0 协议,项目代码在GitHub 上进行维护
Docker 自开源后受到广泛的关注和讨论,以至于 dotCloud 公司后来都改名为 Docker Inc,Redhat 已经在其 RHEL6.5 中集中支持 Docker;Google 也在其 PaaS 产品中广泛应用。
Docker 项目的目标是实现轻量级的操作系统虚拟化解决方案,Docker 的基础是 Linux 容器(LXC)等技术。
Docker的前生LXC
Linux Container容器是一种内核虚拟化技术,可以提供轻量级的虚拟化,以便隔离进程和资源。
LXC为Linux Container的简写,可以提供轻量级的虚拟化,以便隔离进程和资源,而且不需要提供指令解释机制以及全虚拟化的其他复杂性,相当于C++中的NameSpace,容器有效地将由单个操作系统管理的资源划分到孤立的组中,以更好地在孤立的组之间平衡有冲突的资源使用需求。
与传统虚拟化技术相比,它的优势在于:
- 与宿主机使用同一个内核,性能损耗小;
- 不需要指令级模拟;
- 不需要即时(Just-in-time)编译;
- 容器可以在CPU核心的本地运行指令,不需要任何专门的解释机制;
- 避免了准虚拟化和系统调用替换中的复杂性;
- 轻量级隔离,在隔离的同时还提供共享机制,以实现容器与宿主机的资源共享
Linux Container提供了在单一可控主机节点上支持多个相互隔离的server container同时执行的机制,Linux Container有点像chroot,提供了一个拥有自己进程和网络空间的虚拟环境,但又有别于虚拟机,因为lxc是一种操作系统层次上的资源的虚拟化。
LXC与docker的关系
docker并不是LXC替代品,docker底层使用了LXC来实现,LXC将linux进程沙盒化,使得进程之间相互隔离,并且能够可控限制各进程的资源分配,在LXC的基础之上,docker提供了一系列更强大的功能。
Docker 的特点
容器化越来越受欢迎,因为容器是:
- 灵活:即使是最复杂的应用也可以集装箱化。
- 轻量级:容器利用并共享主机内核。
- 可互换:可以即时部署更新和升级。
- 便携式:可以在本地构建,部署到云,并在任何地方运行。
- 可扩展:可以增加并自动分发容器副本。
- 可堆叠:可以垂直和即时堆叠服务。
为什么使用Docker
作为一种新兴的虚拟化方式,Docker 跟传统的虚拟化方式相比具有众多的优势。
首先,Docker 容器的启动可以在秒级实现,这相比传统的虚拟机方式要快得多,其次,Docker 对系统资源的利用率很高,一台主机上可以同时运行数千个 Docker 容器。
Docker的优势
具体说来,Docker 在如下几个方面具有较大的优势。
更高效的利用系统资源
由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,Docker对系统资源的利用率更高,无论是应用执行速度,内存消耗以及文件存储速度,都要比传统虚拟机技术更高效,因此,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。
更快速的启动时间
传统的虚拟机技术启动应用服务往往需要数分钟,而Docker容器应用,由于直接运行与宿主内核,无须启动完整的操作系统,因此可以做到秒级,甚至毫秒级的启动时间,大大的节约了开发,测试,部署的时间。
一致的运行环境
开发过程中一个常见的问题是环境一致性问题,由于开发环境,测试环境,生产环境不一致,导致有些bug并未在开发过程中被发现,而Docker的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性。
持续交付和部署
对于开发和运维人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。
使用Docker可以通过定制应用镜像来实现持续集成,持续交付,部署,开发人员可以通过Dockerfile来进行镜像构建,并结合持续集成系统进行集成测试,而运维人员则可以在生产环境中快速部署该镜像,甚至结合持续部署系统进行自动部署
更轻松的迁移
由于Docker确保了执行环境的一致性,使得应用的迁移更加容易,Docker可以在很多平台上运行,无论是物理机,虚拟机,公有云,私有云,甚至是笔记本,其运行结果是一致的,因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
缺点
隔离性
基于hypervisor的虚机技术,在隔离性上比容器技术要更好,它们的系统硬件资源完全是虚拟化的,当一台虚机出现系统级别的问题,往往不会蔓延到同一宿主机上的其他虚机,但是容器就不一样了,容器之间共享同一个操作系统内核以及其他组件,所以在收到攻击之类的情况发生时,更容易通过底层操作系统影响到其他容器。
性能
不管是虚机还是容器,都是运用不同的技术,对应用本身进行了一定程度的封装和隔离,在降低应用和应用之间以及应用和环境之间的耦合性上做了很多努力,但是随机而来的,就会产生更多的网络连接转发以及数据交互,这在低并发系统上表现不会太明显,而且往往不会成为一个应用的瓶颈(可能会分散于不同的虚机或者服务器上),但是当同一虚机或者服务器下面的容器需要更高并发量支撑的时候,也就是并发问题成为应用瓶颈的时候,容器会将这个问题放大,所以,并不是所有的应用场景都是适用于容器技术的。
存储方案
容器的诞生并不是为OS抽象服务的,这是它和虚机最大的区别,这样的基因意味着容器天生是为应用环境做更多的努力,容器的伸缩也是基于容器的这一disposable特性,而与之相对的,需要持久化存储方案恰恰相反。 这一点docker容器提供的解决方案是利用volume接口形成数据的映射和转移,以实现数据持久化的目的,但是这样同样也会造成一部分资源的浪费和更多交互的发生,不管是映射到宿主机上还是到网络磁盘,都是退而求其次的解决方案。
对比传统虚拟机
| 特性 | Docker 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为 MB | 一般为 GB |
| 性能 | 接近原生 | 弱于 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
Docker版本
随着Docker的不断流行与发展,docker公司(或称为组织)也开启了商业化之路,Docker 从 17.03版本之后分为 CE(Community Edition) 和 EE(Enterprise Edition),我们来看看他们之前的区别于联系。
版本区别
Docker EE
Docker EE由公司支持,可在经过认证的操作系统和云提供商中使用,并可运行来自Docker Store的、经过认证的容器和插件。
Docker EE提供三个服务层次:
| 服务层级 | 功能 |
|---|---|
| Basic | 包含用于认证基础设施的Docker平台 Docker公司的支持 经过 认证的、来自Docker Store的容器与插件 |
| Standard | 添加高级镜像与容器管理 LDAP/AD用户集成 基于角色的访问控制(Docker Datacenter) |
| Advanced | 添加Docker安全扫描 连续漏洞监控 |
大家可在该页查看各个服务层次的价目:https://www.docker.com/pricing
Docker CE
Docker CE是免费的Docker产品的新名称,Docker CE包含了完整的Docker平台,非常适合开发人员和运维团队构建容器APP
Docker公司认为,Docker CE和EE版本的推出为Docker的生命周期、可维护性以及可升级性带来了巨大的改进。
版本说明
在此之前docker的最新版本更新到docker17.13,而在1.13的基础之上,在2017年的3月1号开始,版本的格式变为如下
| 项目 | 说明 |
|---|---|
| 版本格式 | YY.MM |
| stable版本 | 每个季度发行 |
| edge版本 | 每个月发行 |
| 当前CE版本 | 17.03.0-ce |
小结
- Docker从17.03开始分为企业版与社区版,社区版并非阉割版,而是改了个名称;企业版则提供了一些收费的高级特性。
- EE版本维护期1年;CE的stable版本三个月发布一次,维护期四个月;另外CE还有edge版,一个月发布一次。
Docker使用场景
- Web 应用的自动化打包和发布。
- 自动化测试和持续集成、发布。
- 在服务型环境中部署和调整数据库或其他的后台应用。
- 从头编译或者扩展现有的OpenShift或Cloud Foundry平台来搭建自己的PaaS环境
Docker安装
卸载旧版本
较旧的 Docker 版本称为 docker 或 docker-engine ,如果已安装这些程序,请卸载它们以及相关的依赖项。
yum remove docker \\
docker-client \\
docker-client-latest \\
docker-common \\
docker-latest \\
docker-latest-logrotate \\
docker-logrotate \\
docker-engine
安装Docker依赖环境
在新主机上首次安装 Docker Engine-Community 之前,需要设置 Docker 仓库,之后,可以从仓库安装和更新 Docker。
yum install -y yum-utils \\
device-mapper-persistent-data \\
lvm2
设置 Docker 安装地址
在新主机上首次安装 Docker Engine-Community 之前,需要设置 Docker 仓库,之后,可以从仓库安装和更新 Docker,使用以下命令来设置稳定的仓库**(阿里云)**
sudo yum-config-manager \\
--add-repo \\
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装 Docker Engine-Community
安装最新版本的 Docker Engine-Community 和 containerd
sudo yum install -y docker-ce docker-ce-cli containerd.io
如果提示接受 GPG 密钥,请选是。
Docker 安装完默认未启动,并且已经创建好 docker 用户组,但该用户组下没有用户。
Docker 镜像加速
阿里云镜像获取地址:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors,登陆后,左侧菜单选中镜像加速器就可以看到你的专属地址了:
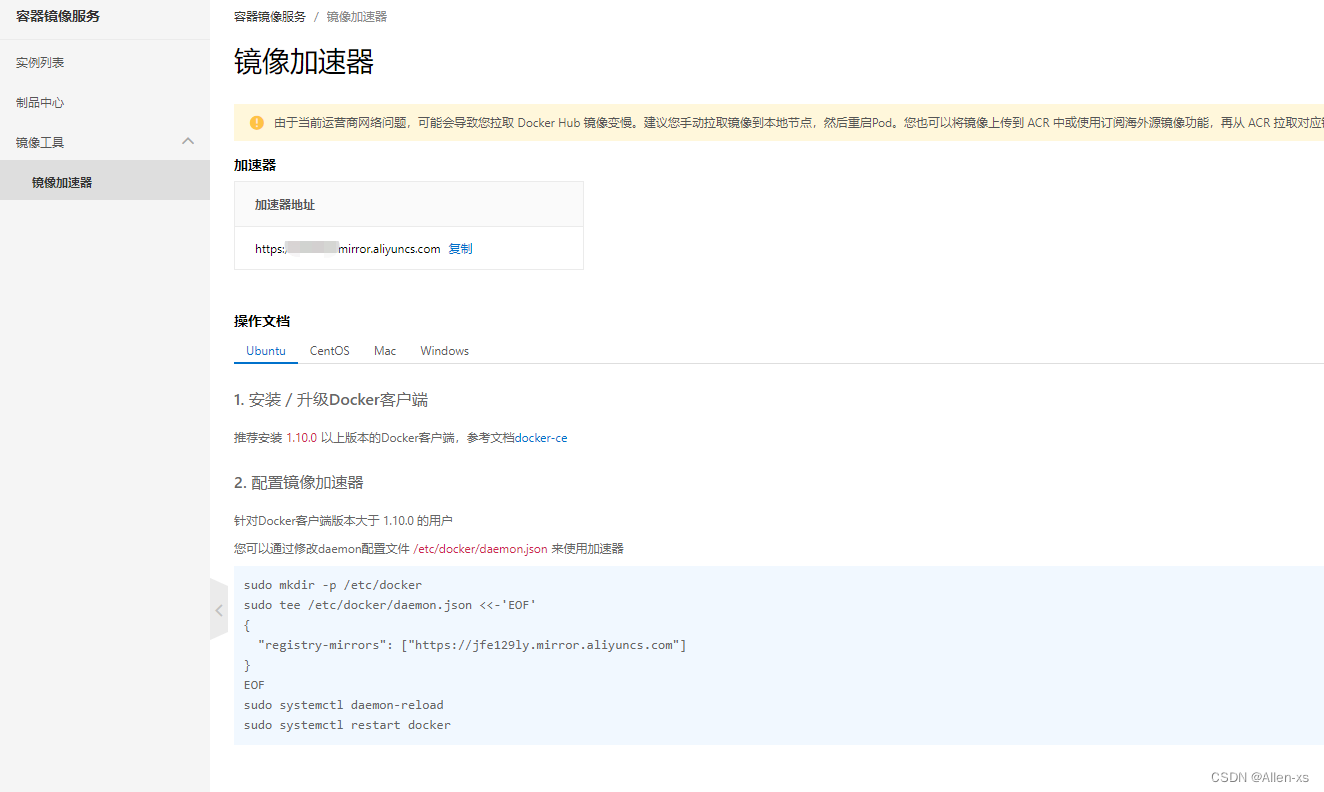
配置daemon.json
可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://xxxxx.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
启动 Docker
service docker start
验证docker服务
通过运行 hello-world 映像来验证是否正确安装了 Docker Engine-Community
docker run hello-world
运行该代码后首先会从仓库拉取
hello-world镜像,然后运行该镜像,运行后会输出一个Hello from Docker!

开启Docker自动补全
使用docker时无法自动补全镜像名和其他参数,这样使用效率大大降低,下面是解决方法
bash-complete
yum install -y bash-completion
刷新文件
source /usr/share/bash-completion/completions/docker
source /usr/share/bash-completion/bash_completion
测试
输入
docker p后docker会将可选项列出来
docker p

Docker架构
Docker总体架构为c/s架构,模块之间松耦合,包含了Client, Daemon, Registry, Graph, Driver, Libcontainer以及Docker Container
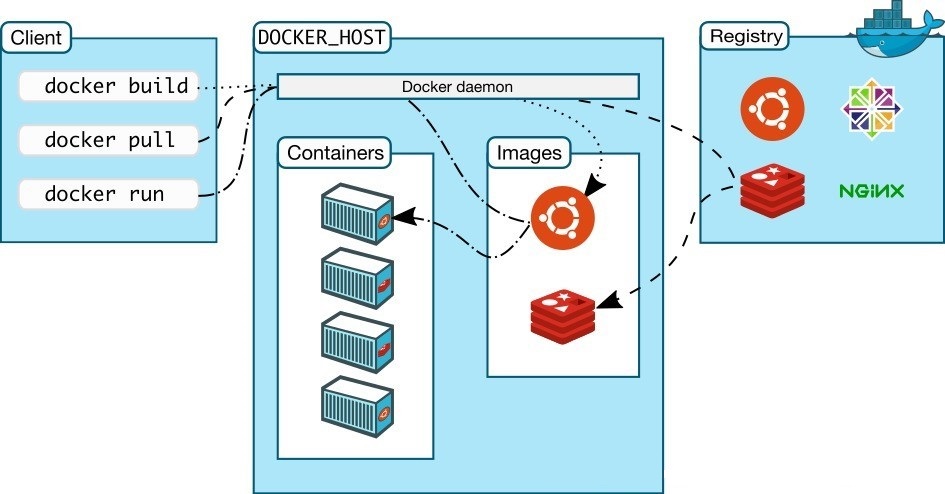
Docker的组件
Docker Client是用户界面,它支持用户与Docker Daemon之间通信Docker DaemonDocker最核心的后台进程,运行于主机上,处理服务请求Docker registry是中央registry,支持拥有公有与私有访问权限的Docker容器镜像的备份Docker Containers负责应用程序的运行,包括操作系统、用户添加的文件以及元数据Docker Images是一个只读模板,用来运行Docker容器DockerFile是文件指令集,用来说明如何自动创建Docker镜像
Docker 基本概念
Docker 包括三个基本概念:
镜像
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等),镜像不包含任何动态数据,其内容在构建之后也不会被改变。
分层存储
镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由多层文件系统联合组成。
Union FS
联合文件系统是(Union FS)是linux的存储技术,也是Docker镜像的存储方式, 它是分层的文件系统,将不同目录拉到同一个虚拟目录下,下图展示了Docker用Union FS 搭建的分层镜像:(比如最下层是操作系统的引导,上一层是Linux操作系统,再上一层是Tomcat,jdk,再上一层是应用代码)
这些层是只读的,加载完后这些文件会被看成是同一个目录,相当于只有一个文件系统。
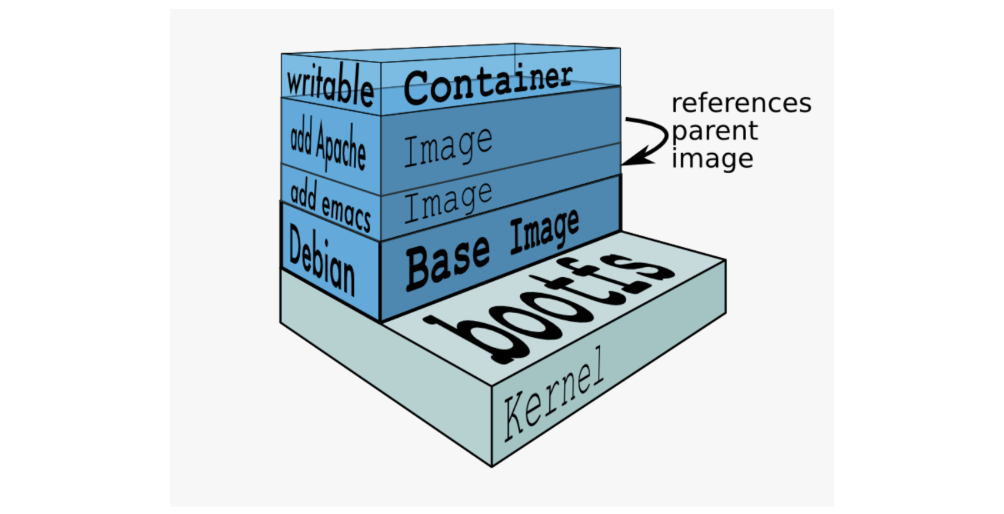
我们可以通过docker info查看镜像的一些信息,可以看到存储驱动用的并不是Union FS 而是overlay2,overlay也是一个联合文件系统,所以上述主要介绍联合文件系统的概念,至于这些存储驱动的演变过程和优缺点

镜像构建时,会一层层构建,前一层是后一层的基础,每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。(比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除,在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像,因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉)
容器
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体,容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间,因此容器可以拥有自己的root文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。
容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样,这种特性使得容器封装的应用比直接在宿主运行更加安全,也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机。
前面讲过镜像使用的是分层存储,容器也是如此,每一个容器运行时,是以镜像为基础层,在其上创建一个当前容器的存储层,我们可以称这个为容器运行时读写而准备的存储层为容器存储层。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡,因此,任何保存于容器存储层的信息都会随容器删除而丢失。
仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。
一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本,我们可以通过<仓库名>:<标签>的格式来指定具体是这个软件哪个版本的镜像,如果不给出标签,将以latest作为默认标签。
以 Ubuntu 镜像为例,ubuntu是仓库的名字,其内包含有不同的版本标签,如,14.04,16.04,我们可以通过ubuntu:14.04,或者ubuntu:16.04来具体指定所需哪个版本的镜像,如果忽略了标签,比如ubuntu,那将视为ubuntu:latest
仓库名经常以三段式路径形式出现,比如demo.com/nginx-proxy:tag,前者往往意味着 Docker Registry 多用户环境下的用户名,后者则往往是对应的软件名,但这并非绝对,取决于所使用的具体 Docker Registry 的软件或服务
Docker部署微服务
场景介绍
我们使用Docker完成一个微服务的搭建过程
整体架构如下
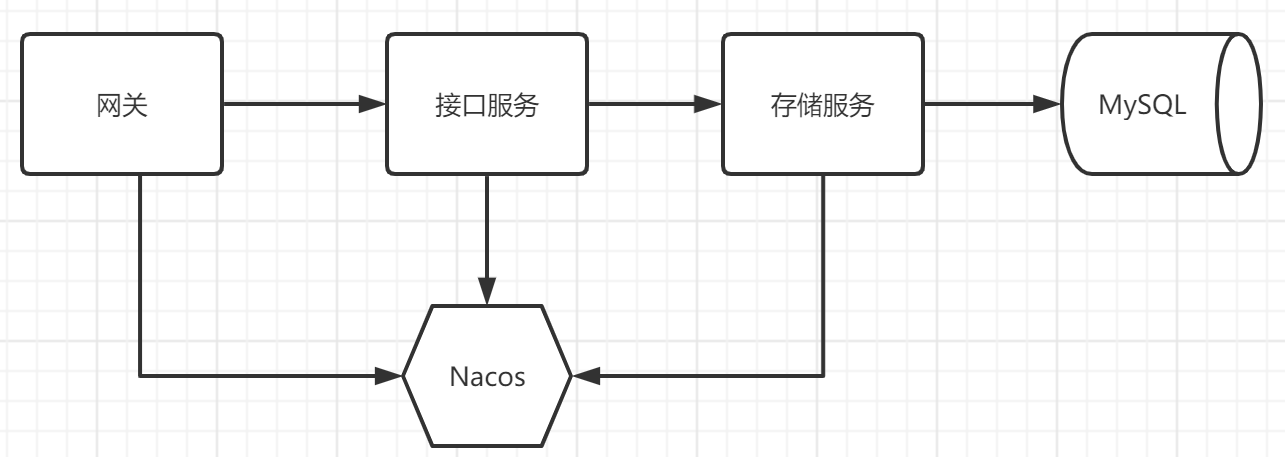
使用多个微服务进行项目部署测试
整体服务说明
我们总共涉及到三个微服务以及两个中间件
| 服务名称 | 描述 |
|---|---|
| mysql | 数据库服务 |
| nacos | 注册中心 |
| learn-docker-gateway | 网关服务 |
| learn-docker-web | API接口服务 |
| learn-docker-storage | 存储服务 |
配置文件提取
因为我们在开发中需要频繁修改
application.yml文件我们将配置项配置到pom文件中打包时自动打到配置文件,这样可以用一个pom文件控制多个不同的服务的配置文件项的修改
pom文件定义属性
我们需要在总
pom文件定义全局配置,例如nacos、mysql等配置
<properties>
<mysql.addr>192.168.64.153:3306</mysql.addr>
<nacos.addr>192.168.64.153:8848</nacos.addr>
</properties>
配置编译选项
在子项目的pom文件的
build构建配置中使用<filtering>true</filtering>配置,这样就可以将我们的总pom中的配置编译进配置文件了
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</build>
配置文件配置
在子项目的
application.yml配置文件中注意使用@xxx@占位符来配置编译占位配置,下面的配置就是用了@@占位符编译后会将pom中的配置编译到配置文件中
server:
port: @project.server.prot@
spring:
application:
name: learn-docker-storage
######################### 数据源连接池的配置信息 #################
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://@db.addr@/employees?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
initialSize: 10
minIdle: 20
maxActive: 100
maxWait: 60000
#### nacos 配置#######
cloud:
nacos:
server-addr: @nacos.addr@
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.demo.module.p
编译测试
配置完后编译项目后,可以进入target目录下查看编译后的配置文件
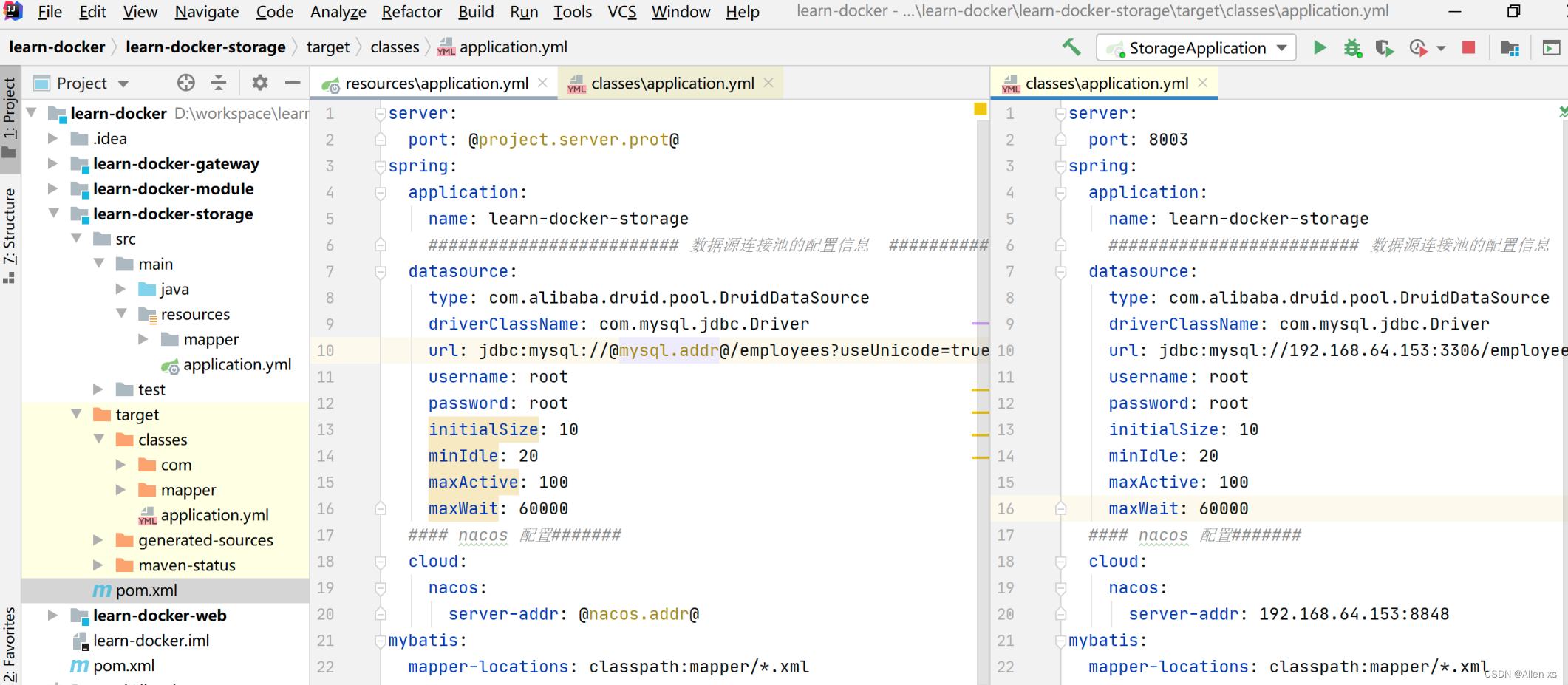
我们看到maven已经帮我们将配置编译进了配置文件中了
安装MySQL
MySQL简介
MySQL 是世界上最受欢迎的开源数据库。凭借其可靠性、易用性和性能,MySQL 已成为 Web 应用程序的数据库优先选择。
查找MySQL镜像
我们可以使用 docker search 镜像名称,命令来搜索镜像
docker search mysql
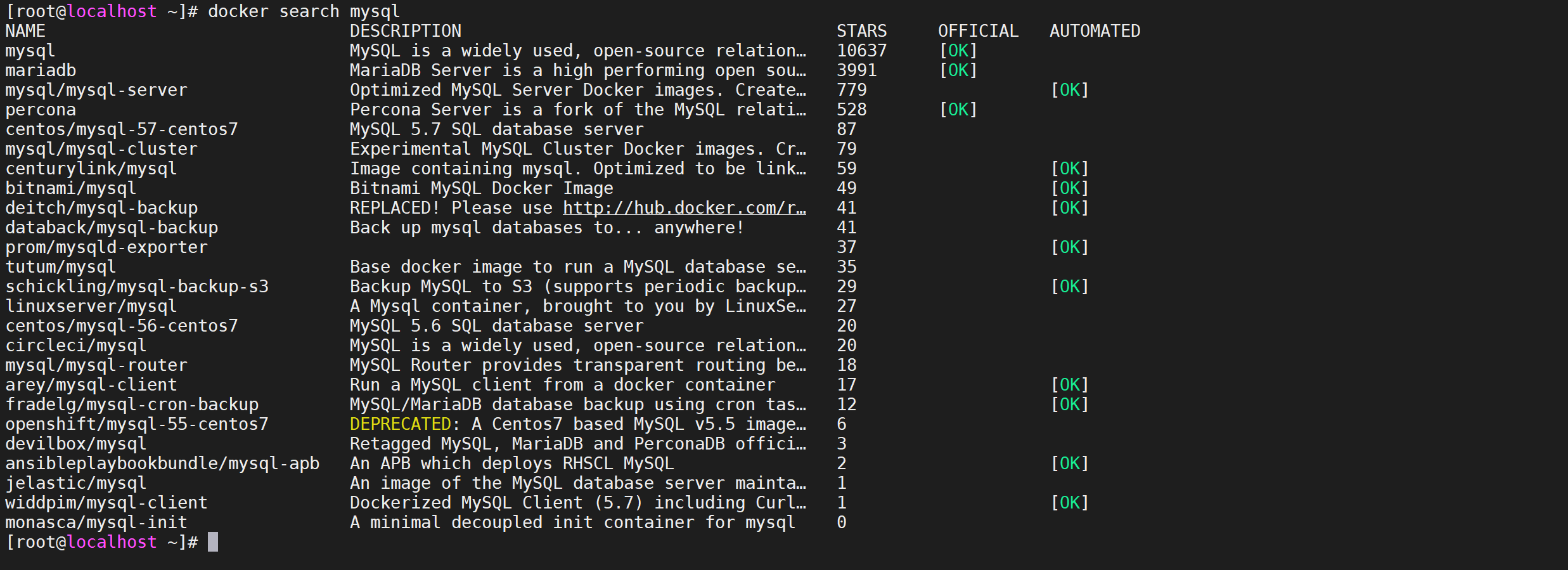
参数解释
搜索出来的有这么多镜像,怎么选择呢
- NAME: 镜像仓库源的名称
- DESCRIPTION: 镜像的描述
- OFFICIAL: 是否 docker 官方发布
- stars: 类似 Github 里面的 star,表示点赞、喜欢的意思。
- AUTOMATED: 自动构建。
根据参数,我们一般选择 官方发布的,并且stars多的。
下载镜像
可以使用
docker pull 镜像名称来拉取镜像,我们选择了第一个Mysql的镜像,我们把它给拉取下来
docker pull mysql
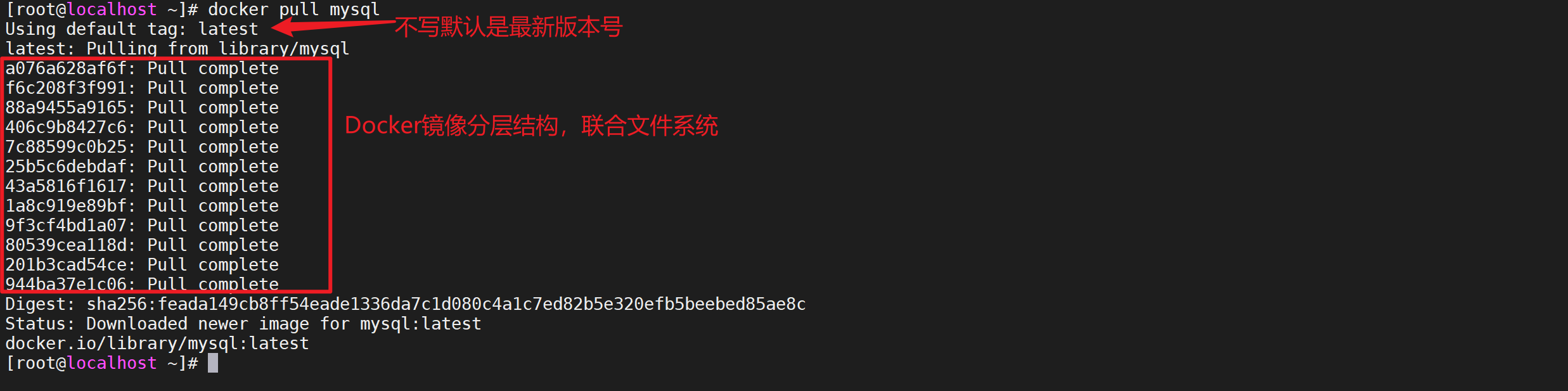
注意事项
- 如果不写版本号默认拉取最新的版本好
latest。 - 拉取的时候是多个层一起拉取的,这样可用让其他镜像复用分层
- 如果拉取的镜像不写仓库地址默认就是
docker.io/library/
下载指定版本的镜像
我们上面下载的镜像不符合我们的预期,我们需要Mysql5.7的镜像
查找指定镜像
可以登录
https://hub.docker.com
https://hub-stage.docker.com地址搜索镜像
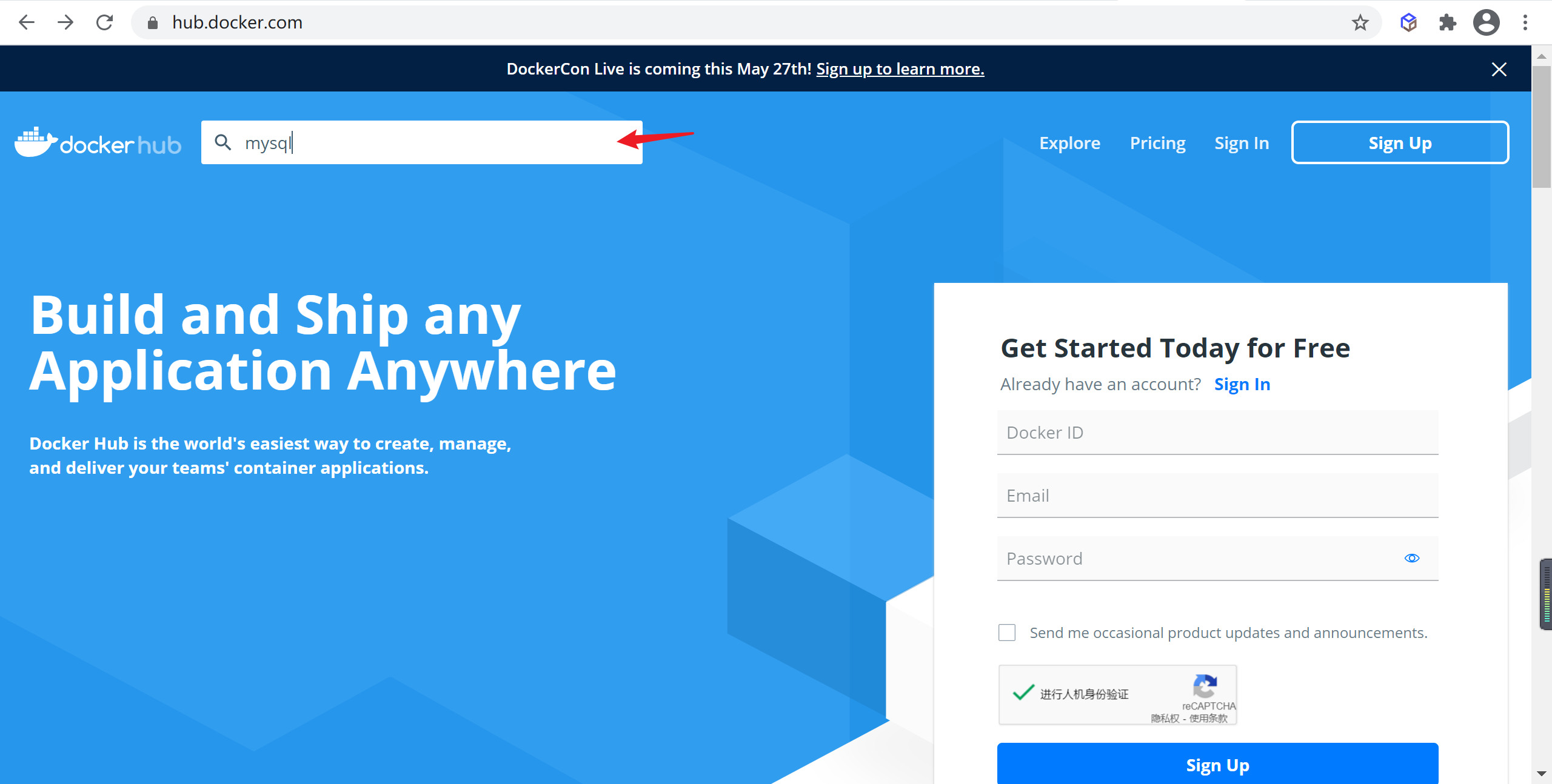
输入需要搜索的镜像名称,并选择对应镜像名称
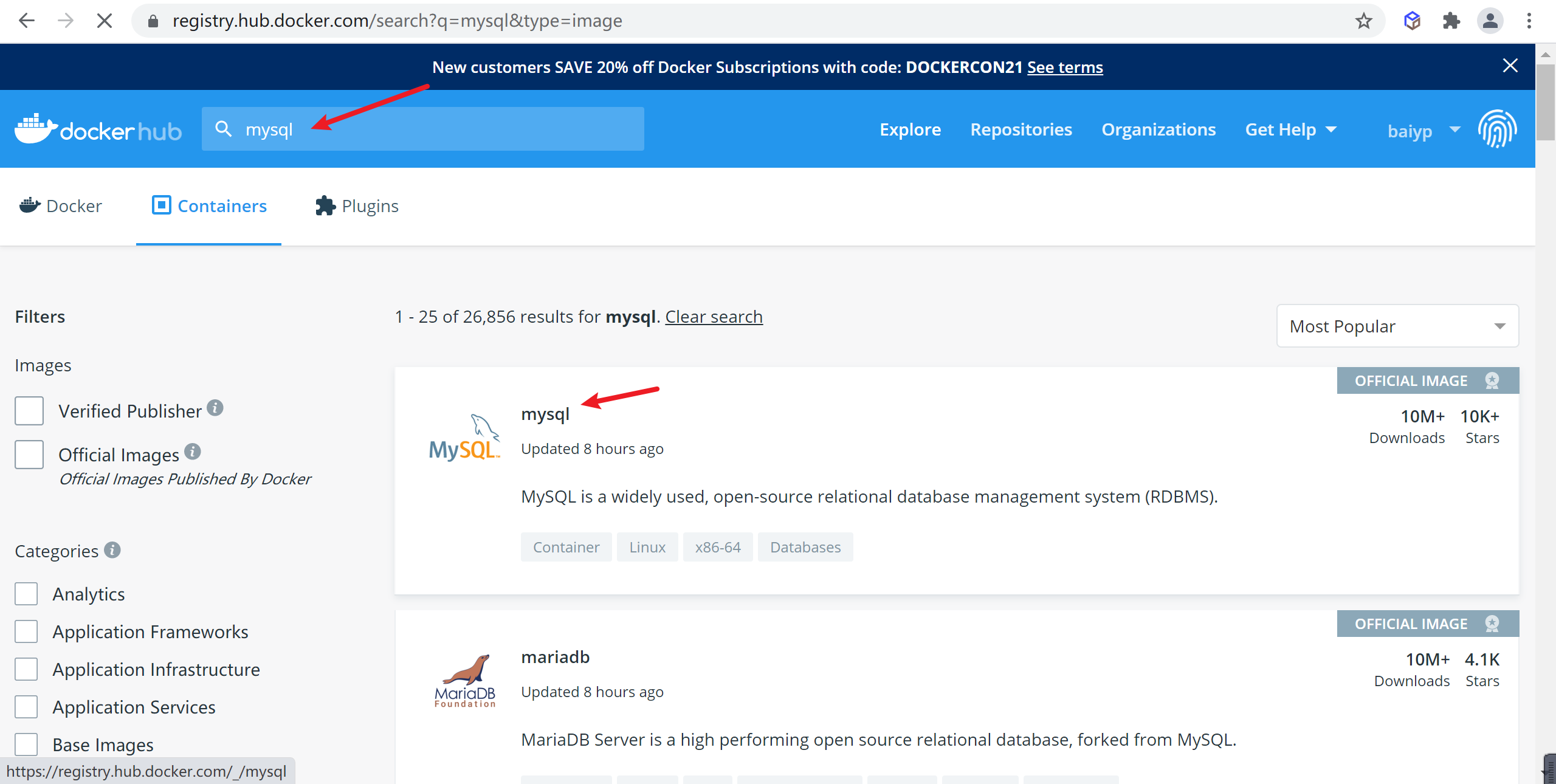
选择
tag标签,这个就是版本的信息
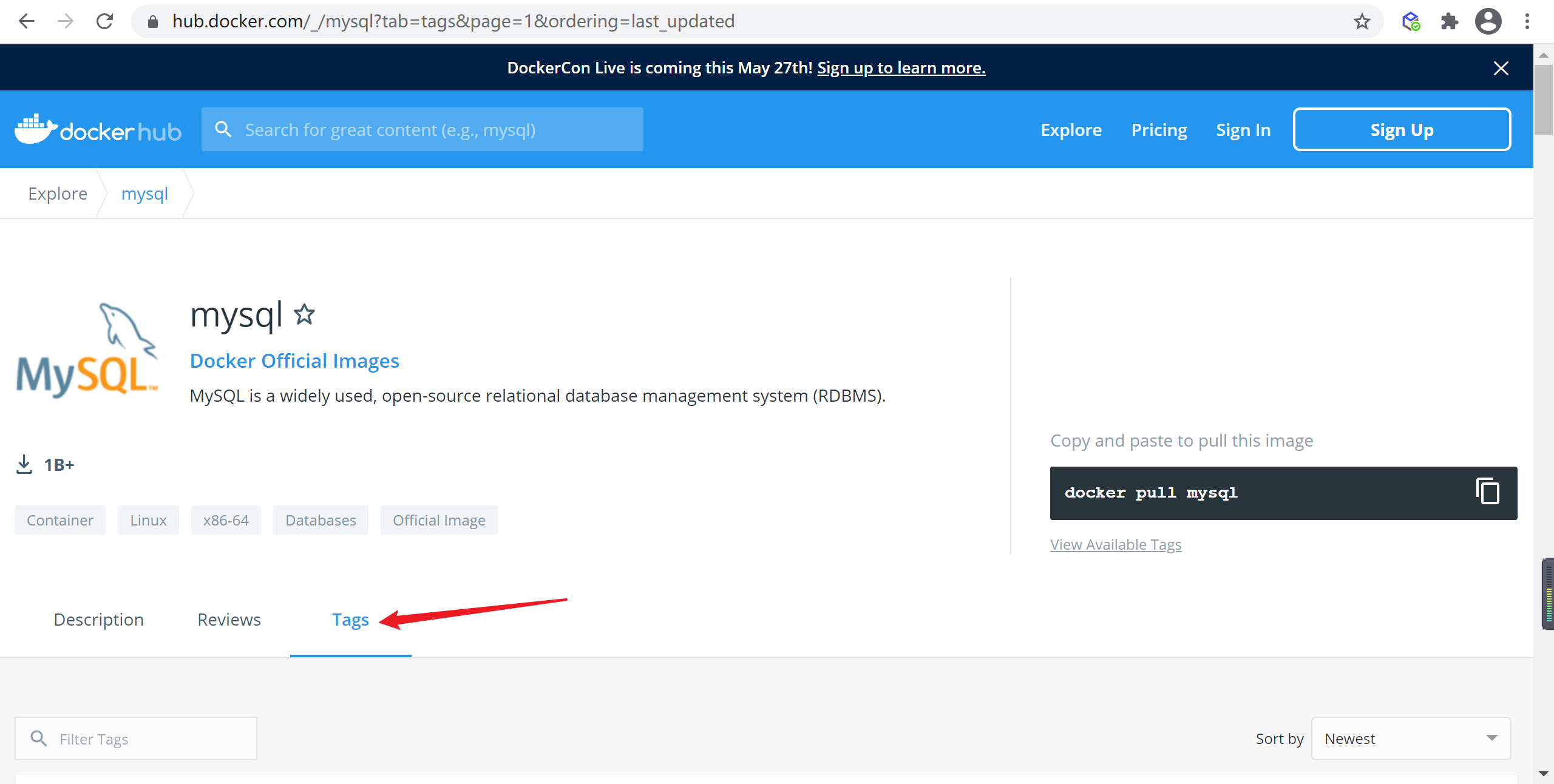
找到符合的版本 的mysql镜像,这里我们选择
5.7.33
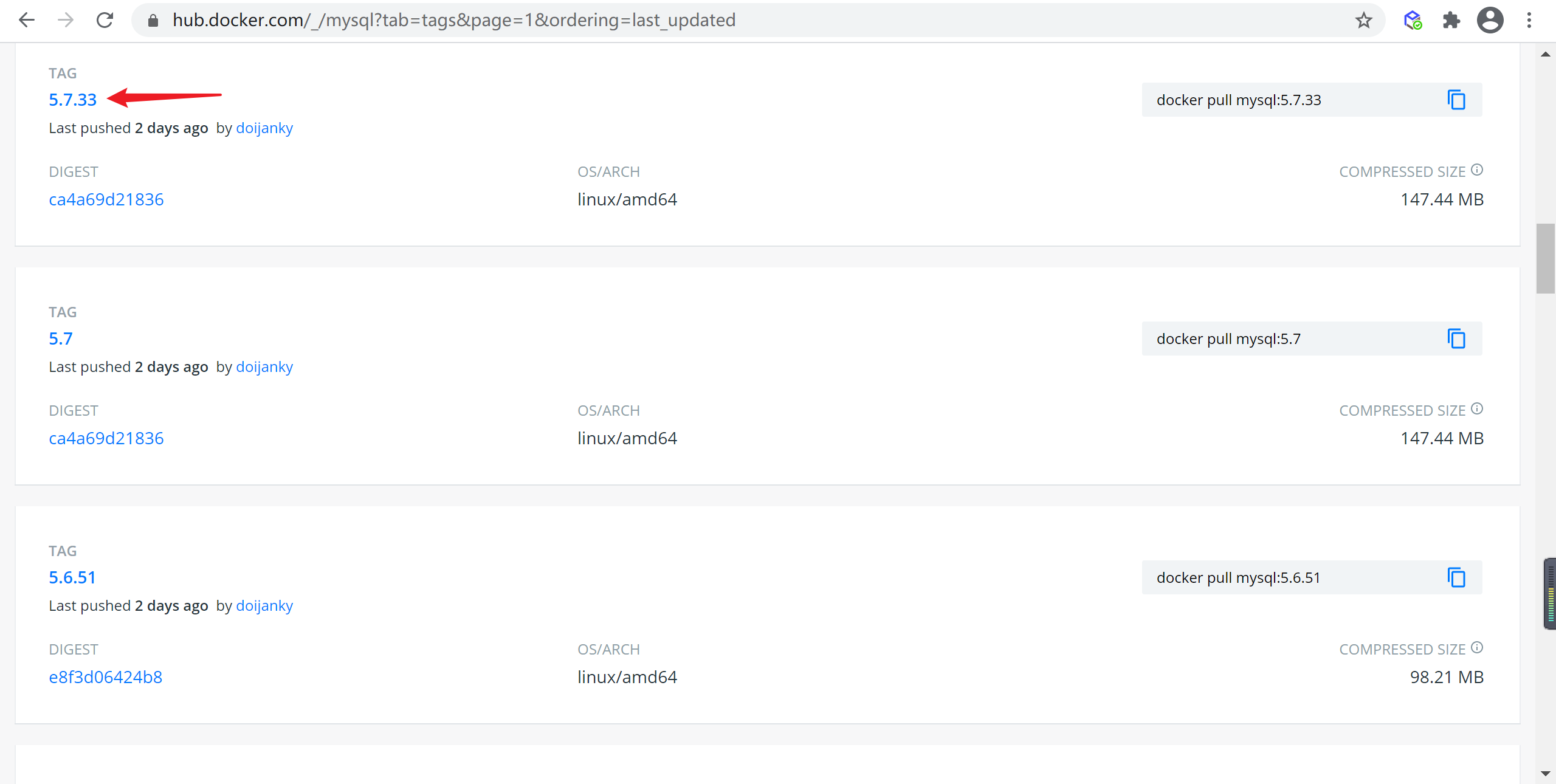
下载指定版本镜像
刚才我们已经找到了
5.7.33版本的Mysql的镜像,我们使用docker pull命令下载,镜像后面跟的是tag也就是版本名称
docker pull mysql:5.7.34
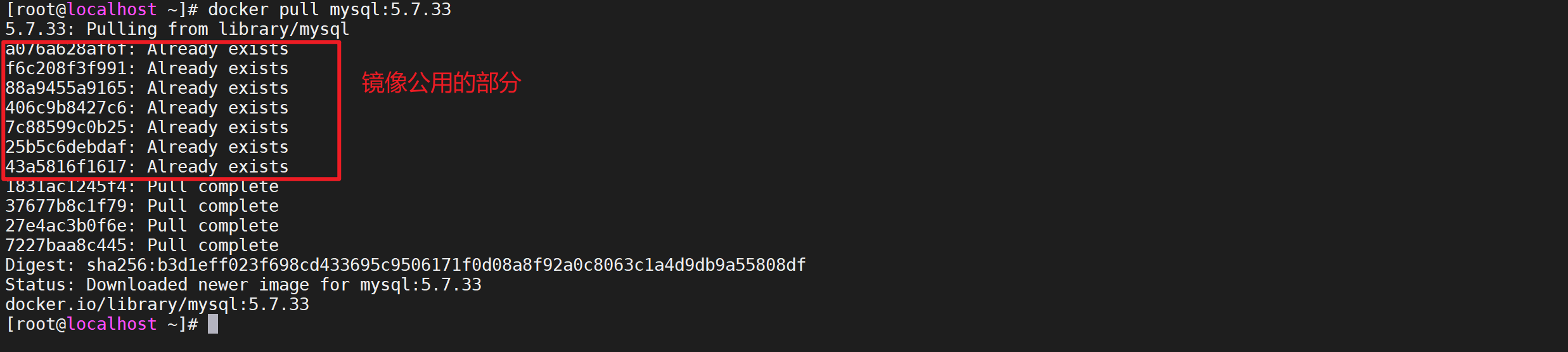
我们发现,我们的新拉取的mysql镜像共用了 部分分层
查看镜像
安装完镜像后,我们需要看一下我们的本地镜像,使用
docker images可用查看本地镜像
docker images

这里有两个镜像,一个是最新版本的一个是我们刚才下载的
5.7.33版本的
MySQL配置
配置MySQL忽略大小写
创建MySQL挂载目录,等会会解释什么是挂载路径
# 创建MySQL配置的文件夹
mkdir -p /tmp/etc/mysql
# 编辑my.cnf配置文件
vi /tmp/etc/mysql/my.cnf
配置MySQL忽略大小写,在我们创建的MySQL配置文件挂载点的目录的my.cnf文件加入如下内容
[mysqld]
lower_case_table_names=1
创建MySQL数据目录
因为默认MySQL启动后他的文件是在容器中的,如果我们删除容器,数据也将会消失,我们需要将数据挂载出来。
#创建mysql存储的目录
mkdir -p /tmp/data/mysql
启动MySql
使用
docker run启动容器
docker run -d -p 3306:3306 -v /tmp/etc/mysql:/etc/mysql/mysql.conf.d/ -v /tmp/data/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=root --name mysql mysql:5.7.38

到这里MySQL已经后台运行了
参数解释
- -d:是指容器后台运行,如果不加
-d,当用户断开客户端时容器会结束运行 - -p:将容器的3306端口映射到主机的3306端口,用来暴漏端口的
- -v:这个命令是用来挂载目录的,将本地目录挂载到容器中,这样容器操作的就是本地目录
- -e:这个命令是配置环境参数的,这里
MYSQL_ROOT_PASSWORD=root指的是用root用户运行mysql,可以登录Docker容器通过ENV命令查看 - –name:这个命令是配置Mysql的容器名称的,如果不配置,默认是随机生成的名字
检查MySQL运行状态
现在并不能确认MySQL的运行状态,我们需要去看下
查看容器运行状态
使用
docker ps可以看到运行中的容器
docker ps
执行命令后,我们看到mysql的服务已经起来了

查看MySQL运行日志
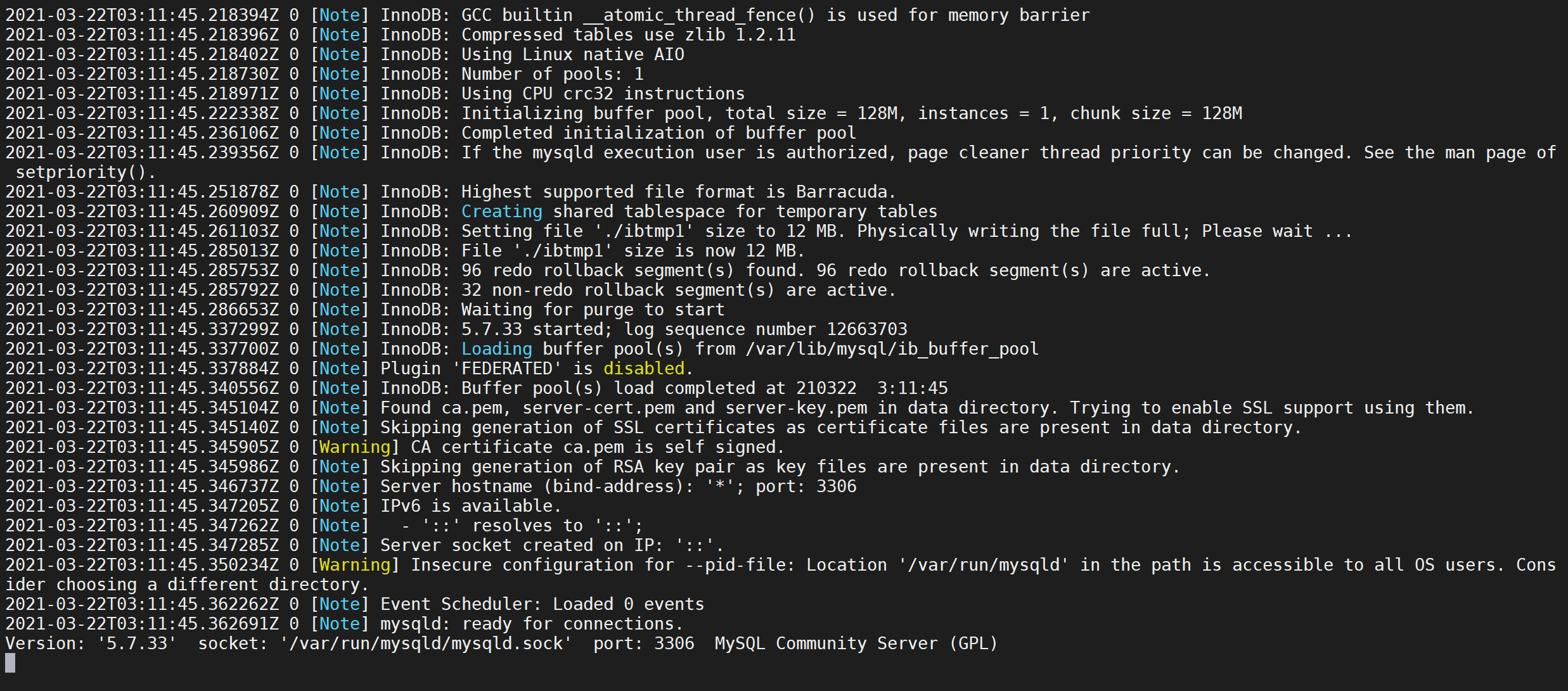
现在MySQL容器起来了,并不代表MySQL已经成功启动,我们需要使用
docker logs命令查看MySQL的日志
docker logs -f mysql
该命令可以查看容器日志
-f是追踪打印日志,可以看到MySQL已经启动了
客户端连接MySQL
因为我们已经暴漏端口了,可以使用客户端工具连接MySQL
检查配置的大小写参数是否生效
SHOW VARIABLES LIKE '%case_table%';

查看容器挂载的配置文件
可以通过
docker exec -ti mysql /bin/bash命令登录容器,检查挂载的配置文件情况
# 登录容器
docker exec -ti mysql /bin/bash
该命令含义是在mysql容器中以

我们可以看到我们修改的配置文件已经被挂载到了docker内部,这里面用到了exec命令,主要是在docker容器中运行命令,下面我们介绍下
命令格式
主要是在deocker容器中运行命令
docker exec [options] container command [arg...]
命令参数
| 名称 | 简写 | 描述 |
|---|---|---|
| –detach | -d | 后台运行模式,在后台执行命令相关命令 |
| –detach-keys | 覆盖容器后台运行的一些参数信息 | |
| –env | -e | 设置环境变量 |
| –interactive | -i | 展示容器输入信息STDIN |
| –privileged | 为命令提供一些扩展权限 | |
| –tty | -t | 命令行交互模式 |
| –user | -u | 设置用户名(format: <name |
| –workdir | -w | 指定容器内的目录 |
查看挂载的数据文件
可以看下挂载的数据文件是否存在
cd /tmp/data/mysql/ && ll
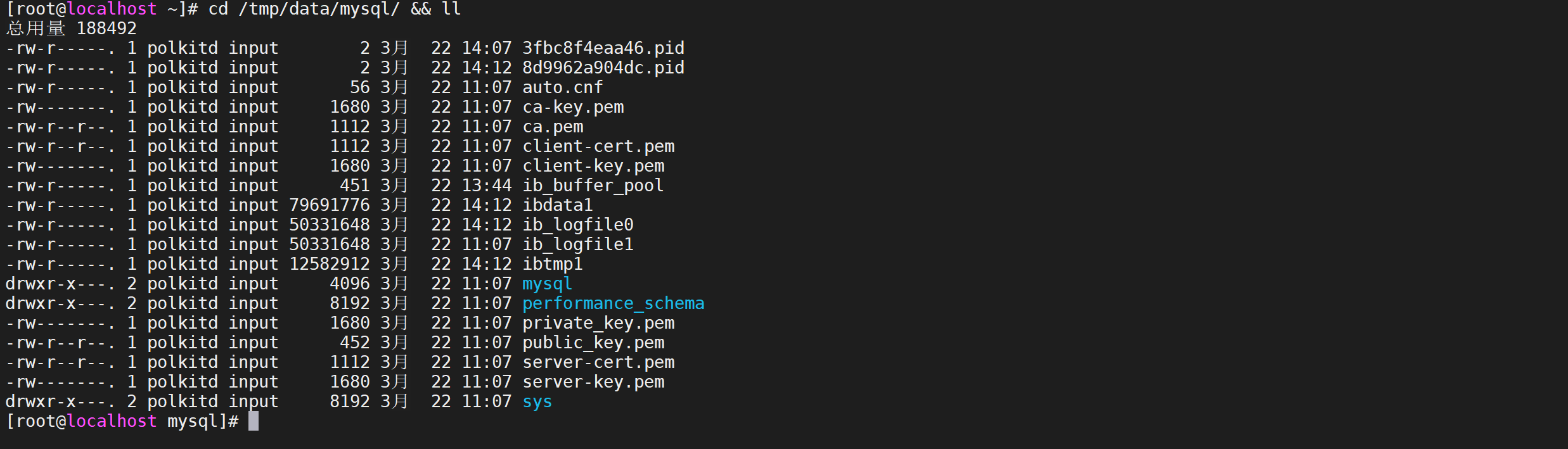
我们看到数据文件已经写入了
MySQL准备数据
MySql需要导入一些数据用来操作,我们用MySQL官方提供的数据库来操作
下载并导入数据
下载MySQL测试数据库
到测试数据官网 下载数据库文件
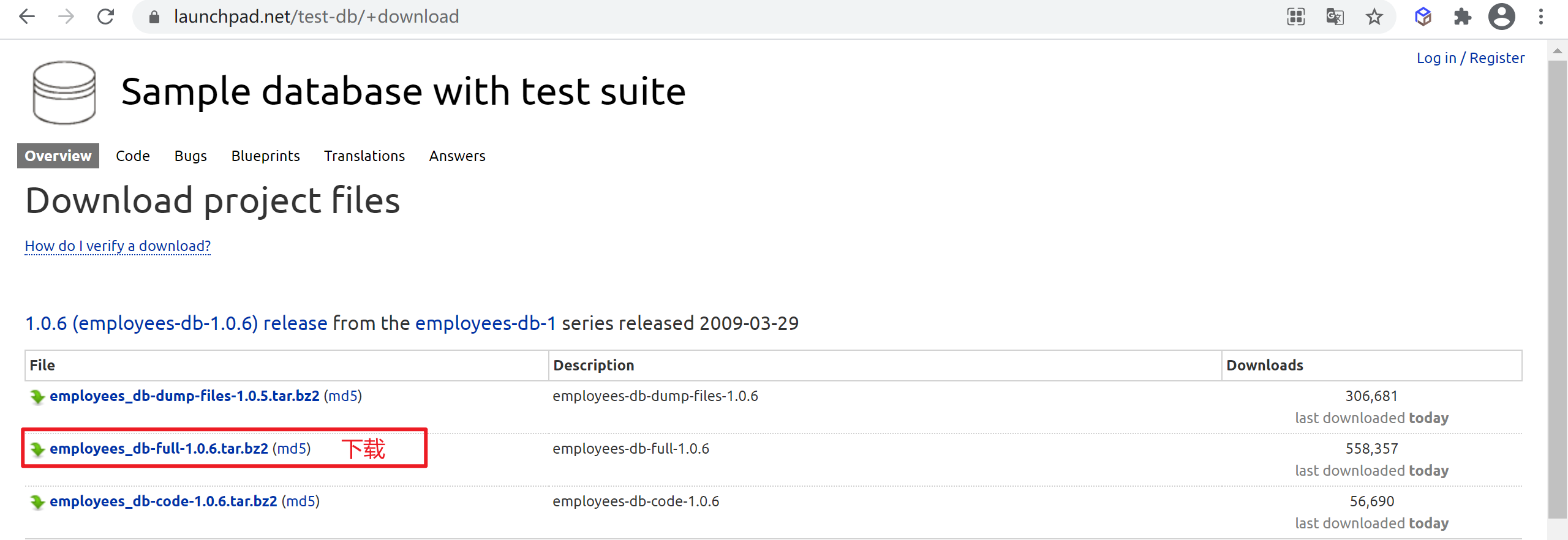
直接导入无法导入,需要编辑
employees.sql文件的一些地方
set storage_engine = InnoDB;修改为:set default_storage_engine = InnoDB;select CONCAT('storage engine: ', @@storage_engine) as INFO;修改为:select CONCAT('storage engine: ', @@default_storage_engine) as INFO;
.....
set default_storage_engine = InnoDB;
-- set storage_engine = MyISAM;
-- set storage_engine = Falcon;
-- set storage_engine = PBXT;
-- set storage_engine = Maria;
select CONCAT('storage engine: ',@@default_storage_engine) as INFO;
.....
导入测试数据
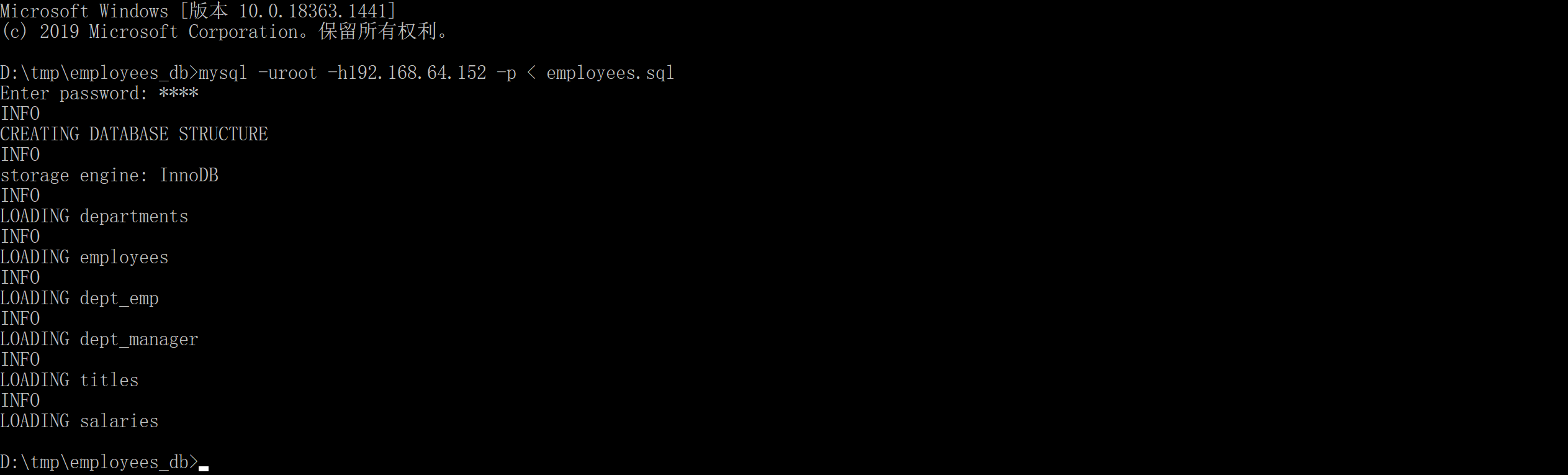
下载解压后,在本地执行命令导入到mysql服务器
mysql -uroot -h192.168.64.152 -p < employees.sql
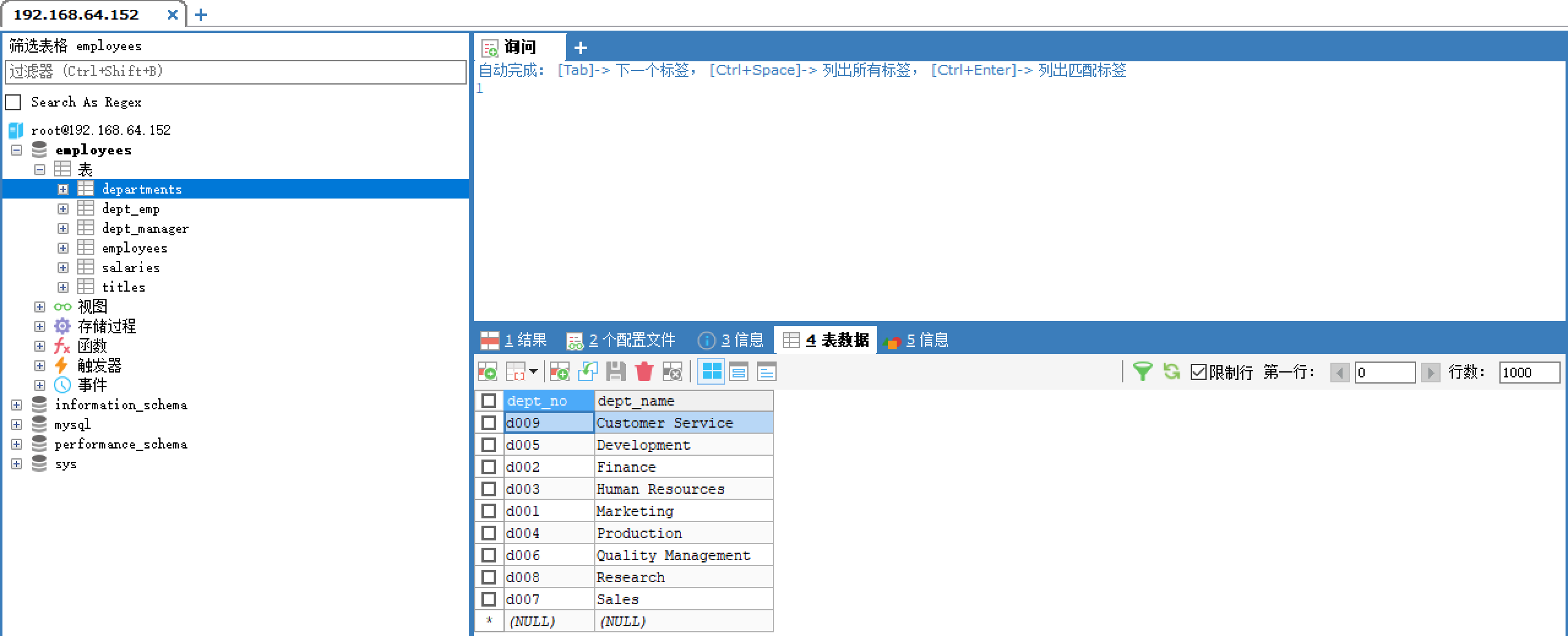
客户端检查数据
在登陆客户端就能看到数据库以及表了
安装部署nacos
Nacos是阿里巴巴开源的一款支持服务注册与发现,配置管理以及微服务管理的组件。用来取代以前常用的注册中心(zookeeper , eureka等等),以及配置中心(spring cloud config等等),Nacos是集成了注册中心和配置中心的功能,做到了二合一。
直接运行服务
可以直接用docker 启动服务,镜像不存在会自动拉取
docker run -d -p 8848:8848 --name nacos --env MODE=standalone nacos/nacos-server
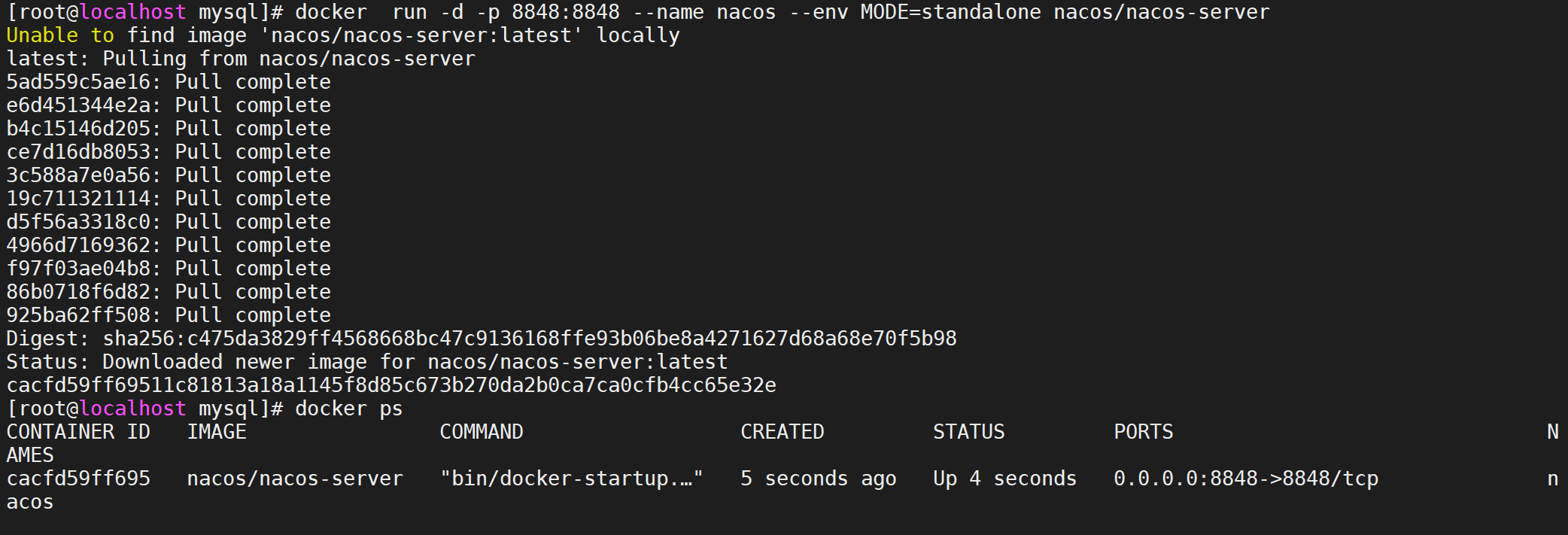
运行容器后可以稍等下,等待nacos启动成功,受环境限制启动可能有些慢
登录页面测试
可以登录服务器测试以下
用户名:nacos 密码:nacos
微服务打包镜像
我们准备将一个微服务打包成Docker镜像,在各种服务器中进行运行,改为服务支持进行查询用户信息
提前说明
因为我们刚开始进行学习Docker,先从单个微服务开始学习,我们就先部署
learn-docker-storage服务,后面随着深入在慢慢增加其他的微服务
访问测试
在idea中运行
learn-docker-storage
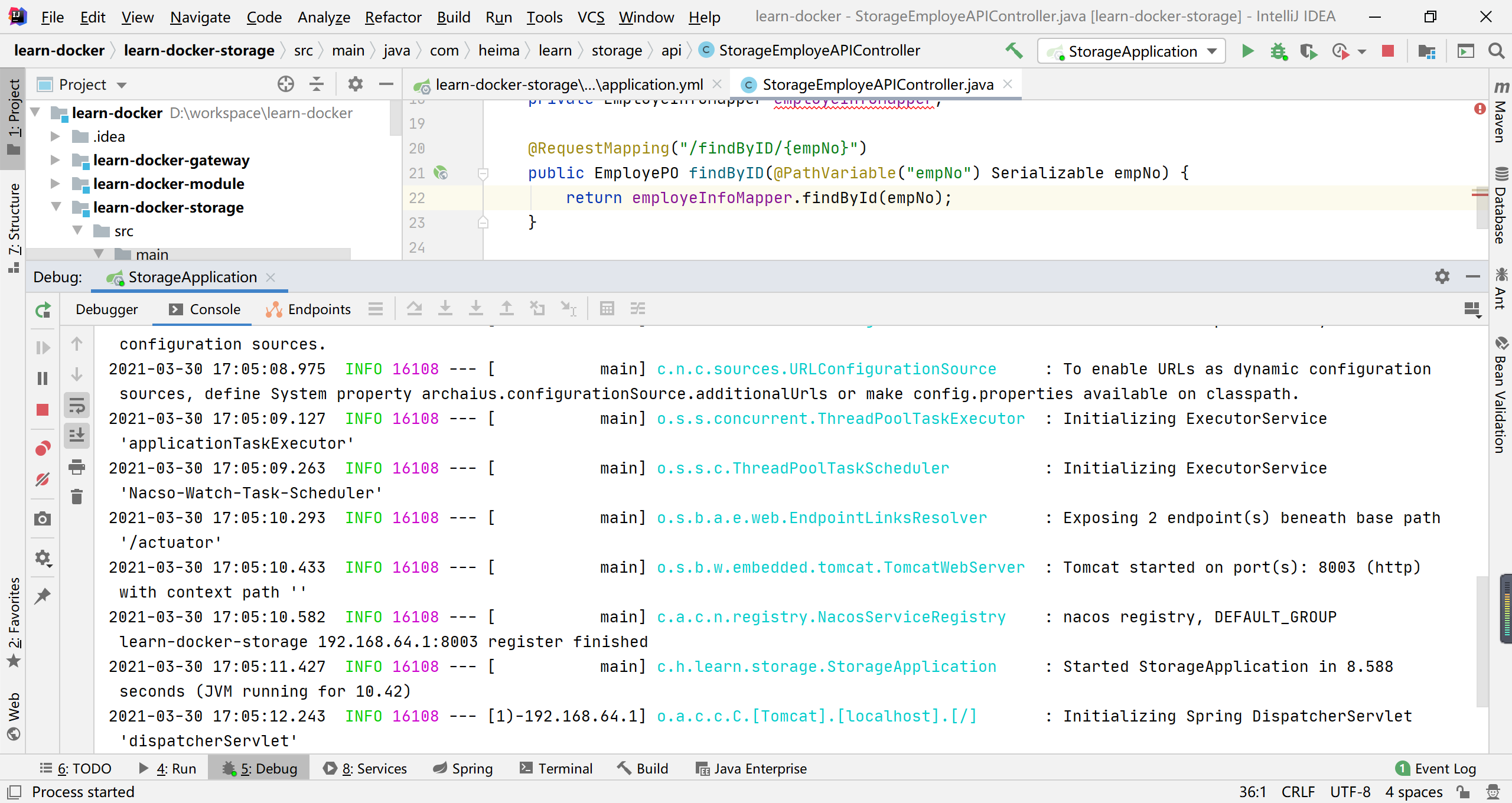
我们配置的端口是8003,我们可以直接访问
http://localhost:8003/storage/employe/findByID/10001

打包上传微服务
将
learn-docker-storage服务打包后上传到服务器
注意配置项
这里需要检查下maven配置的编译属性是否正确
<mysql.addr>192.168.64.153:3306</mysql.addr>
<nacos.addr>192.168.64.153:8848</nacos.addr>
我们发现是我们容器中启动的地址
上传打包后的微服务
将target目录中打包完成的微服务上传到服务器

创建DockerFile
Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。
创建一个Dockerfile文件
vi Dockerfile
具体内容如下
FROM openjdk:8-jdk-alpine
VOLUME /tmp
ADD learn-docker-storage-2.0-SNAPSHOT.jar app.jar
EXPOSE 8003
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
命令解释
- FORM:定制的镜像都是基于 FROM 的镜像,这里的 openjdk 就是定制需要的基础镜像,后续操作都是基于openjdk
- VOLUME:挂载一个数据卷,这里因为没有名称,所以是一个默认的数据卷(后面详细解释)
- ADD:添加一层镜像到当前镜像,这里就是添加SpringBootTest镜像到当前层,并改名app.jar
- EXPOSE:暴漏端口,因为我们的自己的端口是8003,所以我们暴漏8003
- ENTRYPOINT:设定容器启动时第一个运行的命令及其参数,这里就是容器以启动就执行 java -jar /app.jar
打包镜像
写好DockerFile后就需要用
docker build命令来构建我们的镜像了,这样就可以将我们的微服务打包成一个镜像了
构建命令格式
构建一个镜像需要使用以下命令
docker bulid -t 仓库名/镜像名:tag .
参数解释
-
-t: 镜像的名字及标签,一般命名规则是 仓库名/镜像名:tag,
- 仓库名:一般是私服或者dockerhub等地址,如果忽略默认就是dockerhub的地址
docker.io.library/ - 镜像名称:就是我们的自己的服务名称,可以随意命名
- tag:就是我们的版本号
- 仓库名:一般是私服或者dockerhub等地址,如果忽略默认就是dockerhub的地址
-
.:这个
.表示当前目录,这实际上是在指定上下文的目录是当前目录,docker build命令会将该目录下的内容打包交给 Docker 引擎以帮助构建镜像。
实战操作
一般来说,应该会将 Dockerfile 置于一个空目录下,或者项目根目录下,如果该目录下没有所需文件,那么应该把所需文件复制一份过来。
一般大家习惯性的会使用默认的文件名 Dockerfile,以及会将其置于镜像构建上下文目录中。
当前目录的结构如下

构建镜像
进入Dockerfile的目录,通过如下命令构建镜像
docker build -t learn-docker-storage:0.0.1 .
构建完成如果出现
Successfully说明已经构建成功了,
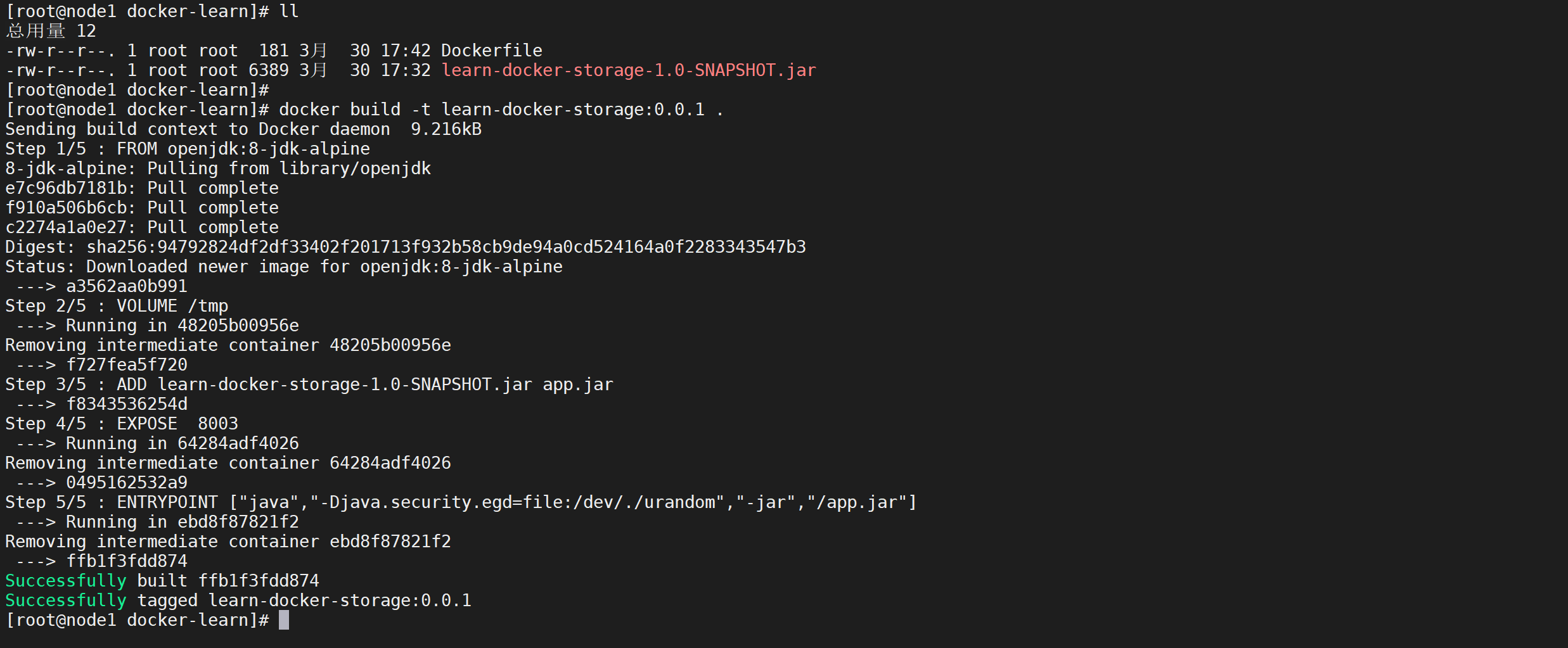
查看构建的镜像
使用
docker images命令查看我们构建完成的镜像
docker images
我们可以看到我们的镜像就在第一个位置

运行镜像
刚才已经打包完成了镜像,现在我们运行我们自己的镜像
# 运行容器
docker run -d -p 8003:8003 learn-docker-storage:0.0.1
# 查看运行中的容器
docker ps

参数最后的
learn-docker-storage:0.0.1是镜像的名称,如果启动容器可以使用镜像名称或者镜像ID
参数解释
- -d:后台运行
- -p:映射端口,将宿主机的8080端口映射到docker内部的8080端口上
查看启动日志
使用
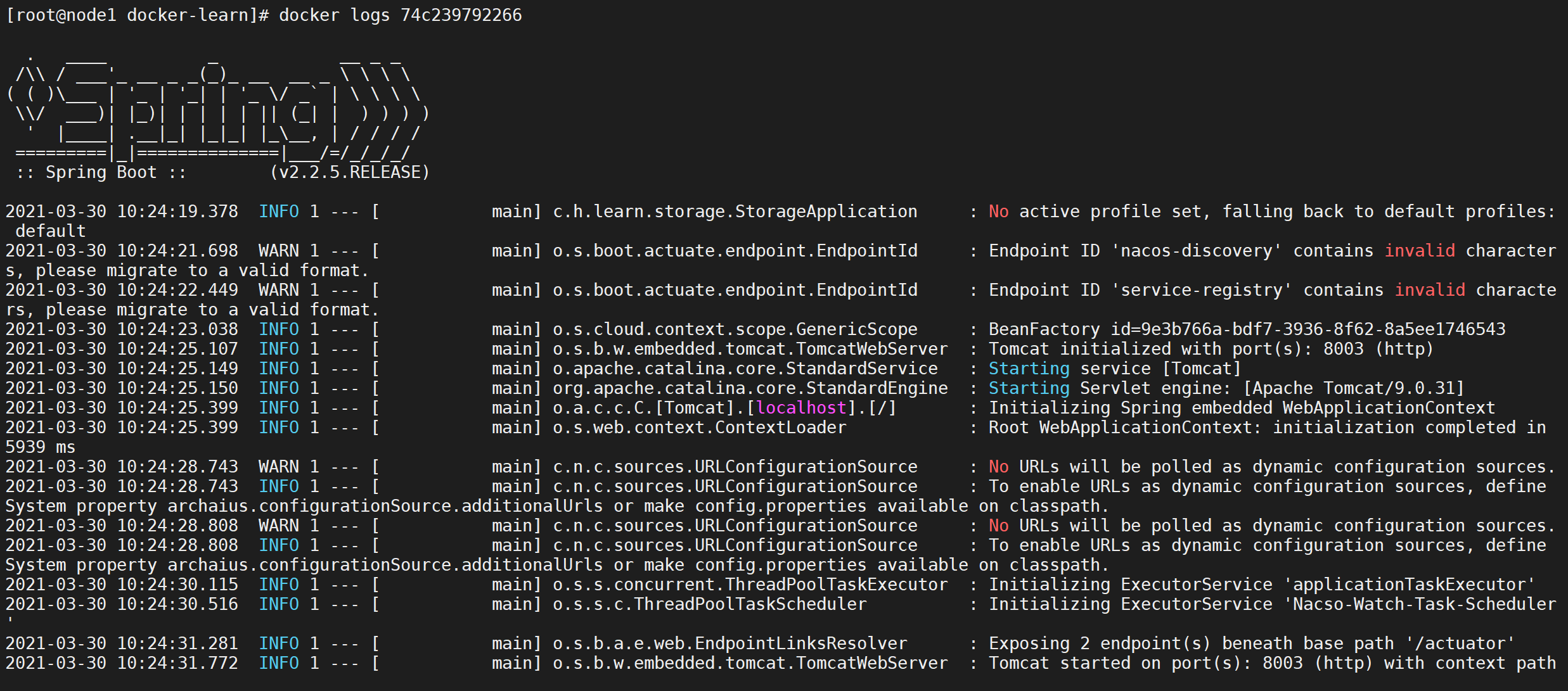
docker logs 容器ID来查看启动日志
docker logs -f 74c239792266
尝试访问服务
通过
curl命令来访问服务
curl http://192.168.64.153:8003/storage/employe/findByID/10001 | python -m json.tool

我们发现服务调用成功了,我们基本实现了微服务改造为docker方式并运行
删除容器
要删除一个容器首先需要将一个容器停止掉
停止容器
我们要把刚才运行的容器停止掉,使用
docker stop 容器ID停止一个容器
docker stop 3752f7088a04

停止容器后,我们在通过进程查看是看不到容器的,但是容器还是存在我们的服务中的
查看全部容器
通过
docker ps只能看到运行中的容器,但是我们停止的容器是看不到的,可以加上-a查看所有的容器
docker ps -a
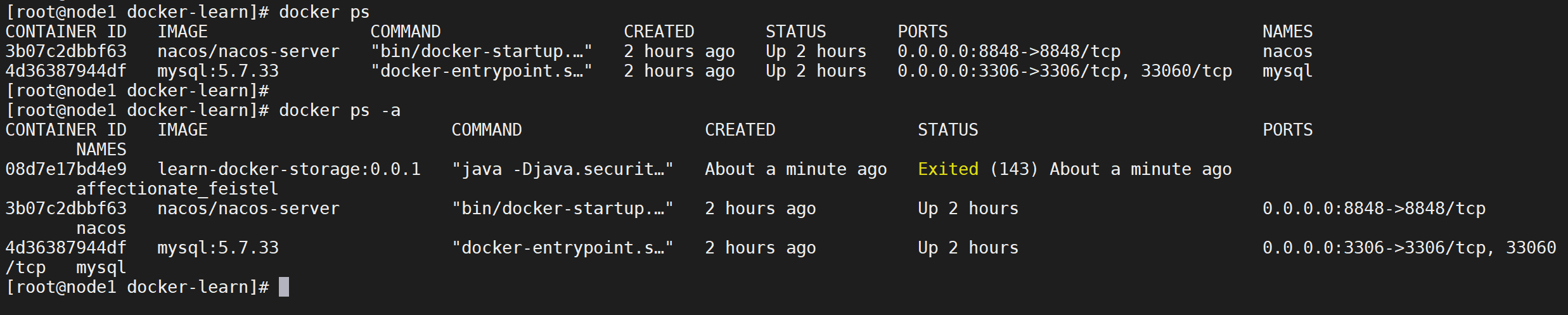
我们可以看到 加上
-a参数可以看到刚才已经停止掉的容器
启动停止的容器
想要启动一个停止的容器可以使用
docker start 容器ID
docker start 3752f7088a04

这样就把刚才已经停止的容器启动了
删除容器
已经停止的容器可以使用
docker rm 容器ID删除容器,但是对于运行中的容器可以加上-f参数强制删除
docker rm -f 3752f7088a04
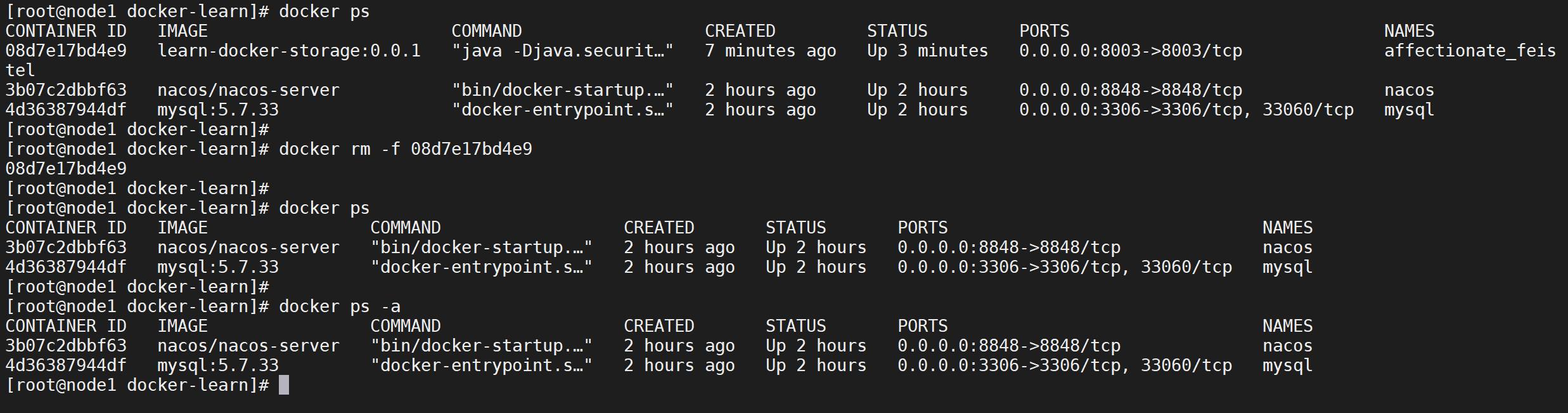
这样可以将一个运行的容器强制删除,如果停止的容器可以通过通过
docker rm删除
docker rm 3752f7088a04
这个时候就把容器给删除掉了
日志挂载优化
存储卷优化
什么是存储卷
“卷”是容器上的一个或多个“目录”,此类目录可绕过联合文件系统,与宿主机上的某个目录“绑定(关联)”;
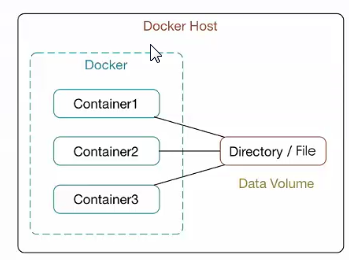
在Docker中,要想实现数据的持久化(所谓Docker的数据持久化即数据不随着Container的结束而结束),需要将数据从宿主机挂载到容器中。
Docker管理宿主机文件系统的一部分,默认位于 /var/lib/docker/volumes 目录中;(最常用的方式)
存储卷优化写入速度
Docker镜像由多个只读层叠加而成,启动容器时,docker会加载只读镜像层并在镜像栈顶部加一个读写层;
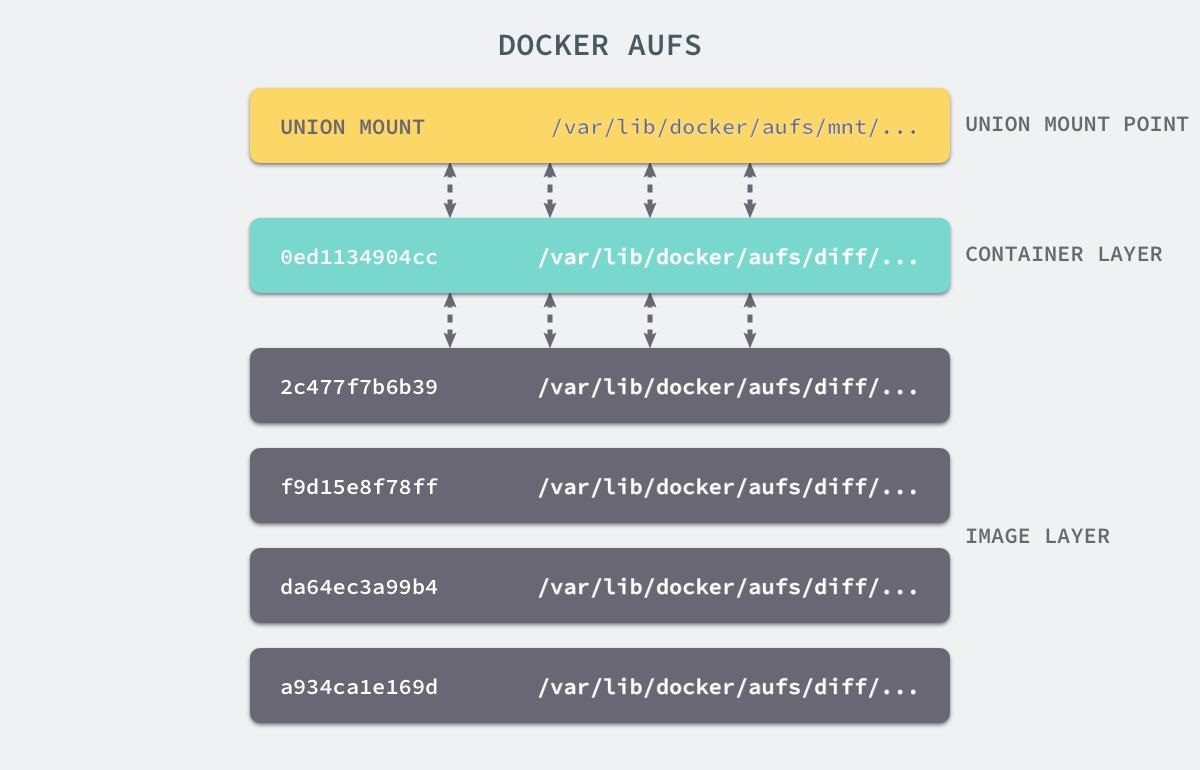
如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件版本仍然存在,只是已经被读写层中该文件的副本所隐藏,此即“写时复制(COW)”机制。
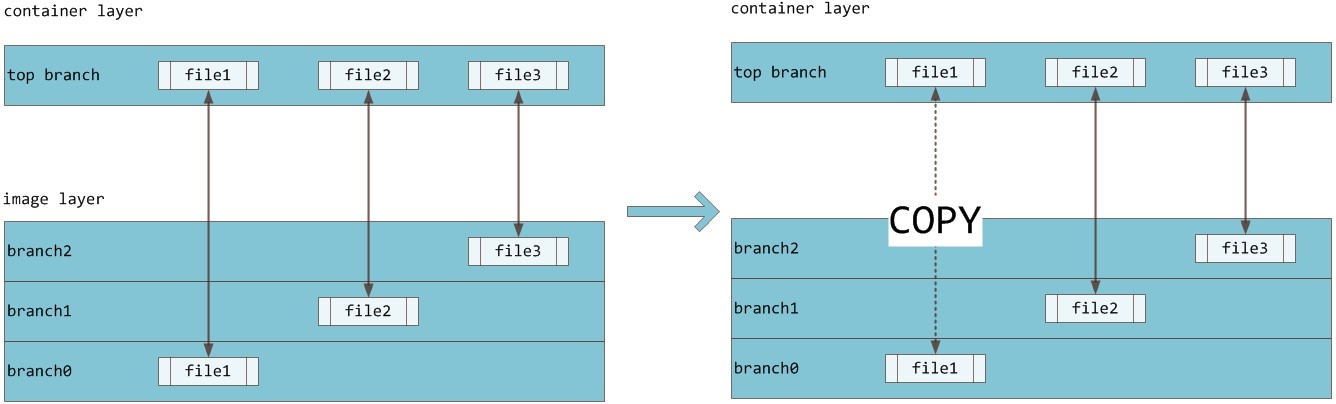
为了避免这种情况,构建Dockerfile的时候应该加入一个存储卷
Dockerfile增加存储卷
增加存储卷
编写Dockerfile增加存储卷,增加日志存储卷
/logs,这会是一个匿名存储卷
FROM openjdk:8-jdk-alpine
VOLUME /tmp /logs
ADD learn-docker-storage-1.0-SNAPSHOT.jar app.jar
EXPOSE 8003
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
构建镜像
因为我们原来已经构建了镜像,这次使用版本号是
0.0.2
#构建镜像
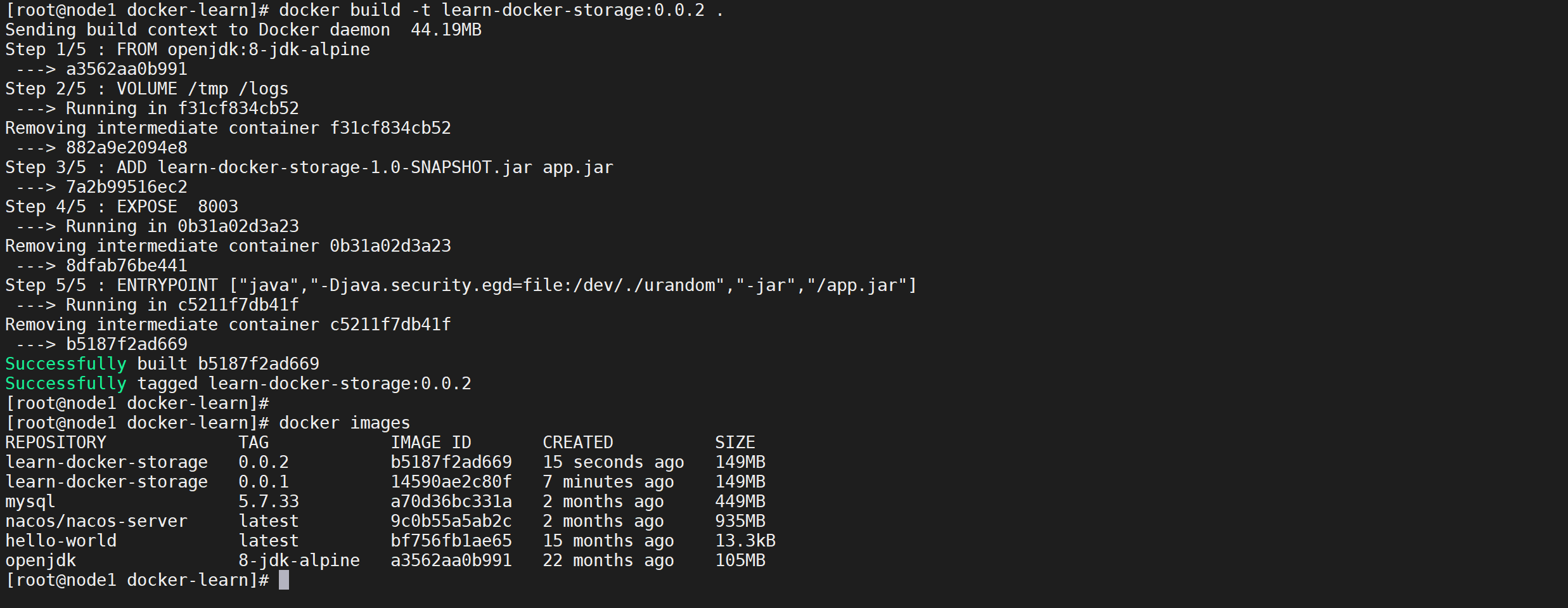
docker build -t learn-docker-storage:0.0.2 .
# 查看镜像列表
docker images
运行容器
通过run命令运行容器
# 运行容器
docker run -d -p 8003:8003 learn-docker-storage:0.0.2
# 查看运行中的容器
docker ps

查看存储卷
通过
docker volume ls可以看到存储卷
docker volume ls

查看容器信息
我们发现都是匿名的存储卷,如何来确定都是那个呢,可以通过
docker inspect 容器ID来查看存储新鲜
docker inspect 2041965c3e87|grep Mounts -A20
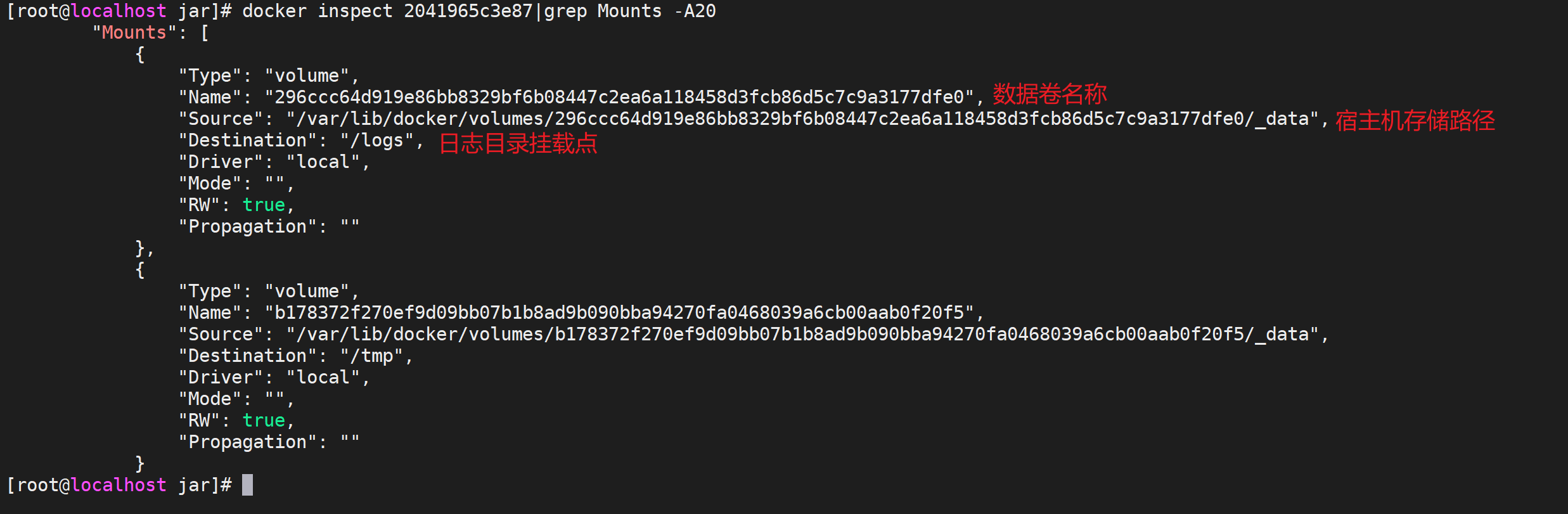
通过这个命令可以看到数据卷的名称以及宿主机的存储路径,我们可以直接到宿主机打印日志
# 进入文件挂载目录
cd /var/lib/docker/volumes/d35de1b7e4631908b05635db4c1f114ab3aafbdf25a9843c068696e66a779c75/_data
# 输出日志
tail -f learn-docker-storage.log
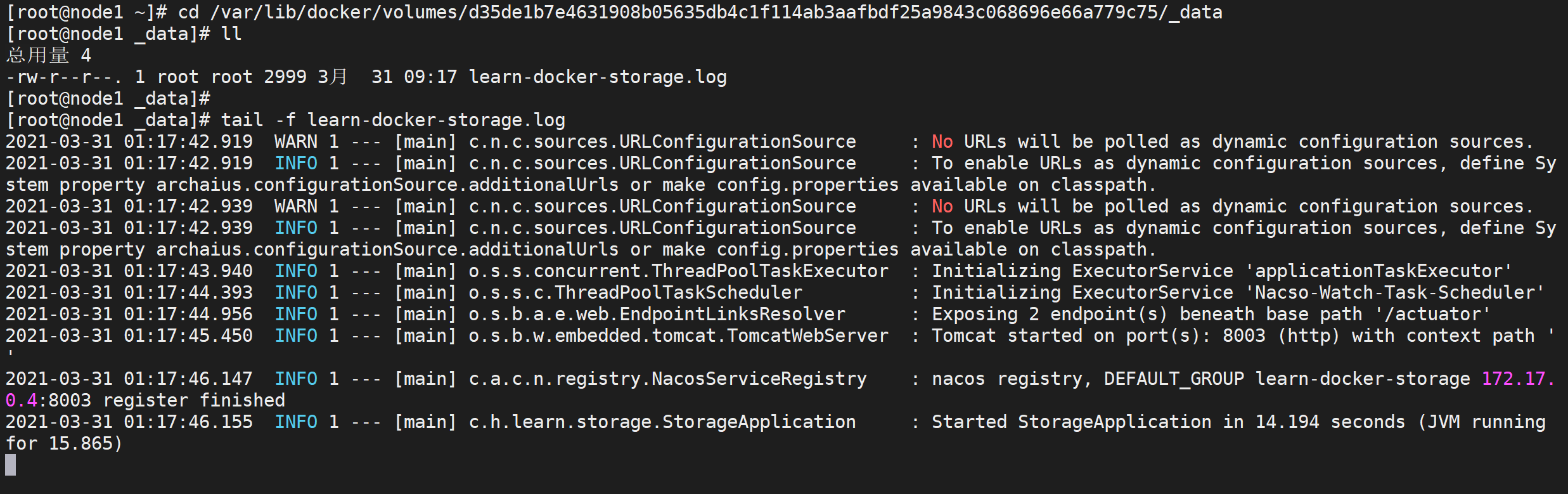
这样就看到了我们的日志文件
验证存储卷
删除容器检查存储卷释放消失
# 查看运行的容器列表
docker ps
#删除容器
docker rm -f 2041965c3e87
#查看所有的容器列表(运行+停止)
docker ps -a

我们看到容器已经被删除了,检查我们的存储卷
docker volume ls

发现存储卷还存在,数据还是存在的,并且数据也存在
# 查看存储卷列表
docker volume ls
# 查看存储卷详情
docker inspect 296ccc64d919e86bb8329bf6b08447c2ea6a118458d3fcb86d5c7c9a3177dfe0
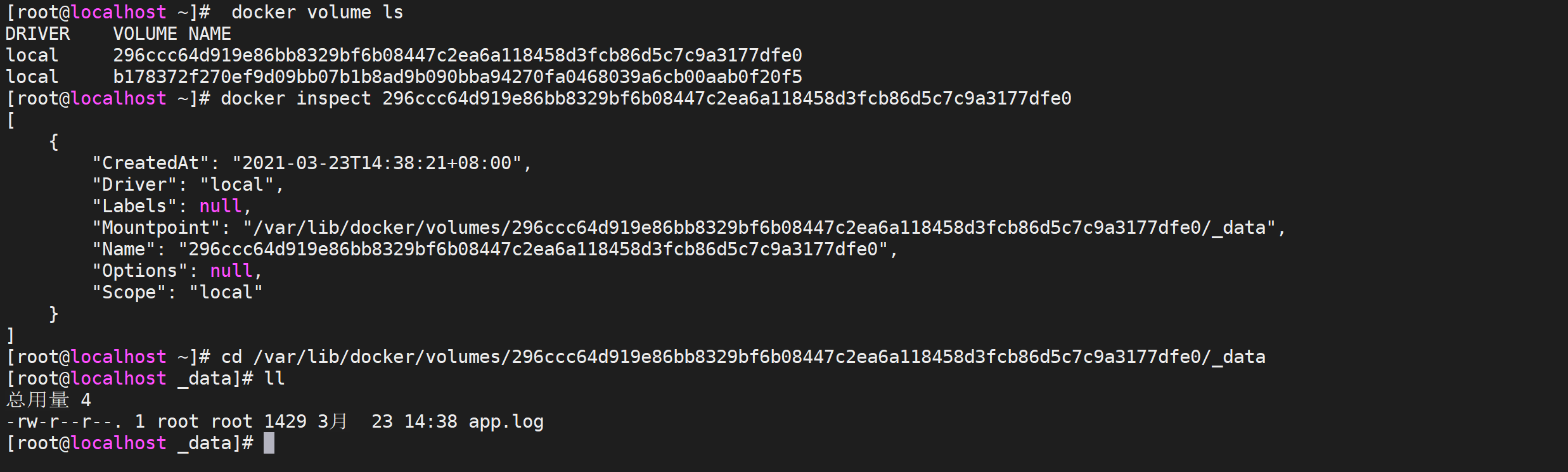
重新运行镜像启动一个新的容器
# 运行容器
docker run -d -p 8080:8080 e1222496c69f
# 查看运行中的容器
docker ps

启动容器后查看存储卷列表
# 查看存储卷列表
docker volume ls

我们发现有创建了两个存储卷,查看容器详情
docker inspect 2041965c3e87|grep Mounts -A20
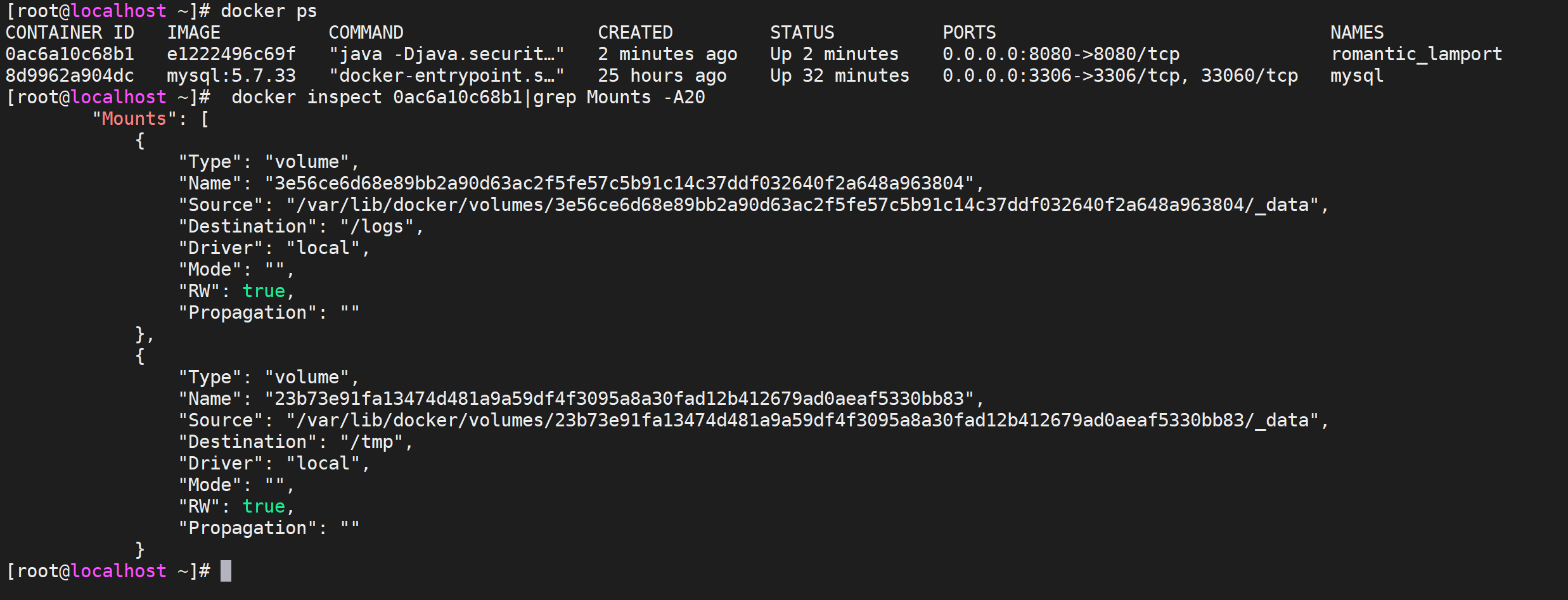
我们发现新启动的容器新开了一个匿名存储卷
bind挂载共享存储
什么是bind
Bind mounts模式和Volumes非常相似,不同点在于Bind mounts模式是将宿主机上的任意文件或文件夹挂载到容器,而Volumes本质上是将Docker服务管理的一块区域(默认是/var/lib/docker/volumes下的文件夹)挂载到容器。
共享存储
经过上面的测试,我们发现每一个容器都是单独用一个存储卷,用于临时文件没有问题的,但是如果要让容器都用同一个存储路径怎么办呢,这个时候就用到了 bind挂载了,可以使用
-v进行挂载挂载刚才的存储卷。
# 级联创建文件夹
mkdir -p /tmp/data/logs
# 运行容器,指定挂载路径
docker run -d -v /tmp/data/logs:/logs \\
-p 8003:8003 --name learn-docker-storage \\
learn-docker-storage:0.0.2
这里面
--name是指定docker容器的名称,我们操作容器就可以使用名称进行操作了

然后使用
docker inspect命令来检查容器详情
docker inspect learn-docker-storage|grep Mounts -A20
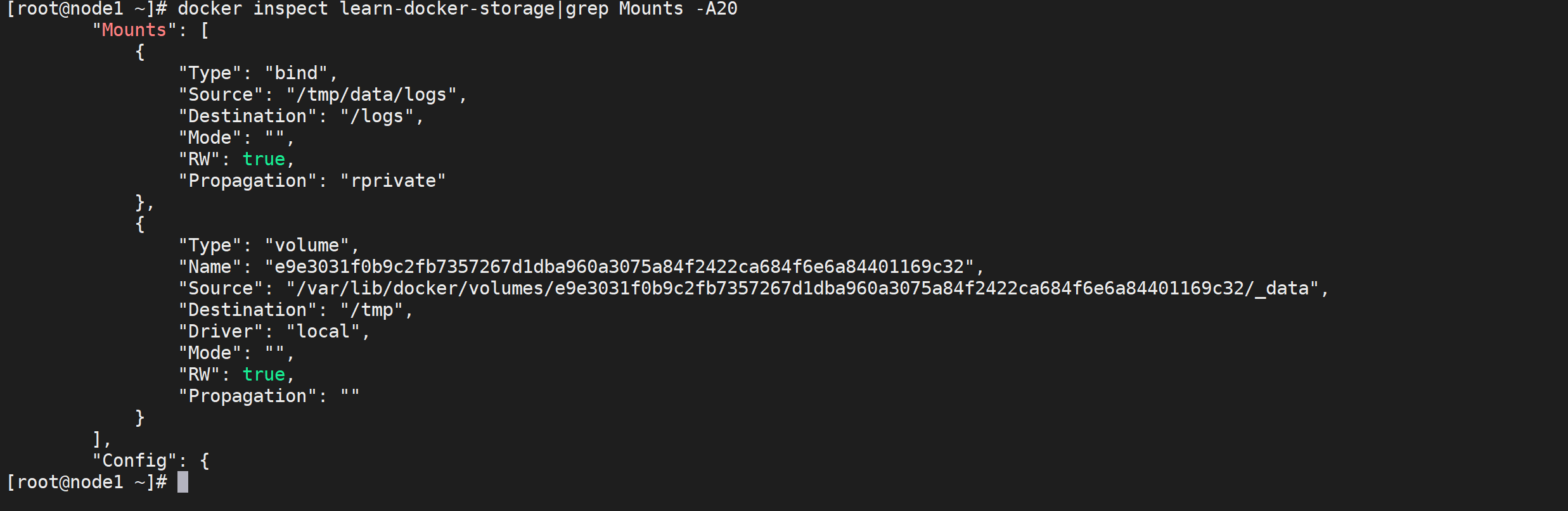
我们发现挂载日志的挂载方式已经变了,由原来的volume变为了bind,并且挂载路径变为了我们自己定义的路径,进入目录查看
# 进入目录并浏览目录文件
cd /tmp/data/logs/&&ll
# 打印日志详情
tail -f learn-docker-storage.log
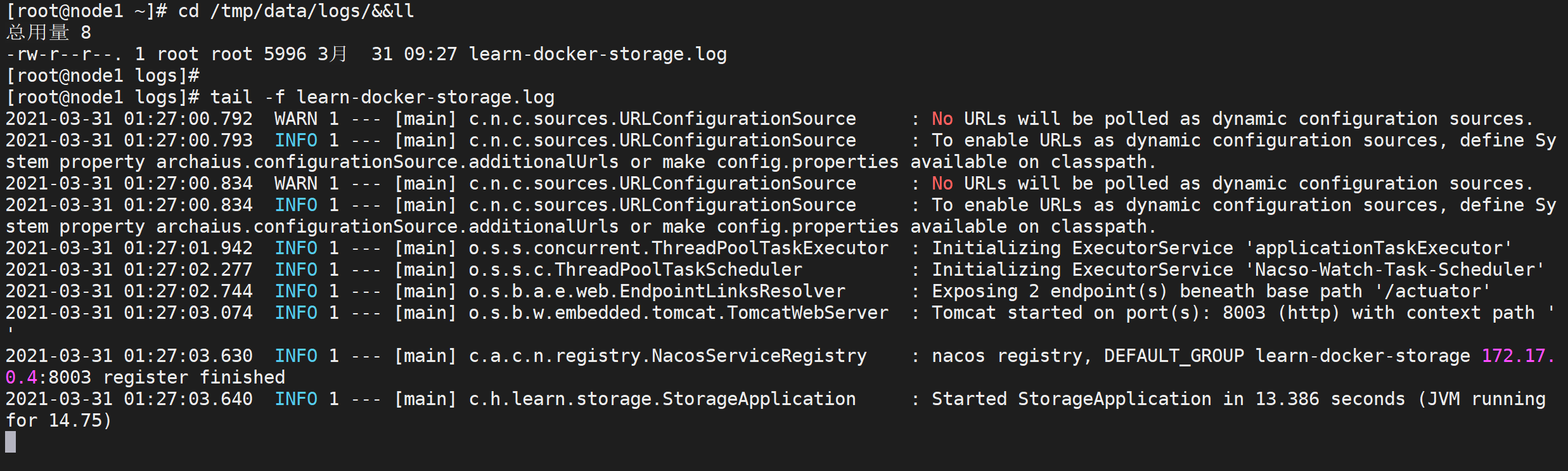
验证共享存储
我们也按照上面步骤验证下bind方式挂载的存储,先删除容器,检查日志文件是否存在
# 停止并删除容器
docker rm -f learn-docker-storage
# 查看容器已经被删除了
docker ps -a
# 进入日志挂载路径查看日志是否存在
cd /tmp/data/logs/&&ll
我们发现容器被删除但是日志文件还存在本地

启动一个新的容器
# 运行容器,指定挂载路径
docker run -d -v /tmp/data/logs:/logs \\
-p 8003:8003 --name learn-docker-storage \\
learn-docker-storage:0.0.2
# 查看日志文件
cat learn-docker-storage.log
我们发现新的容器的日志文件追加进来了
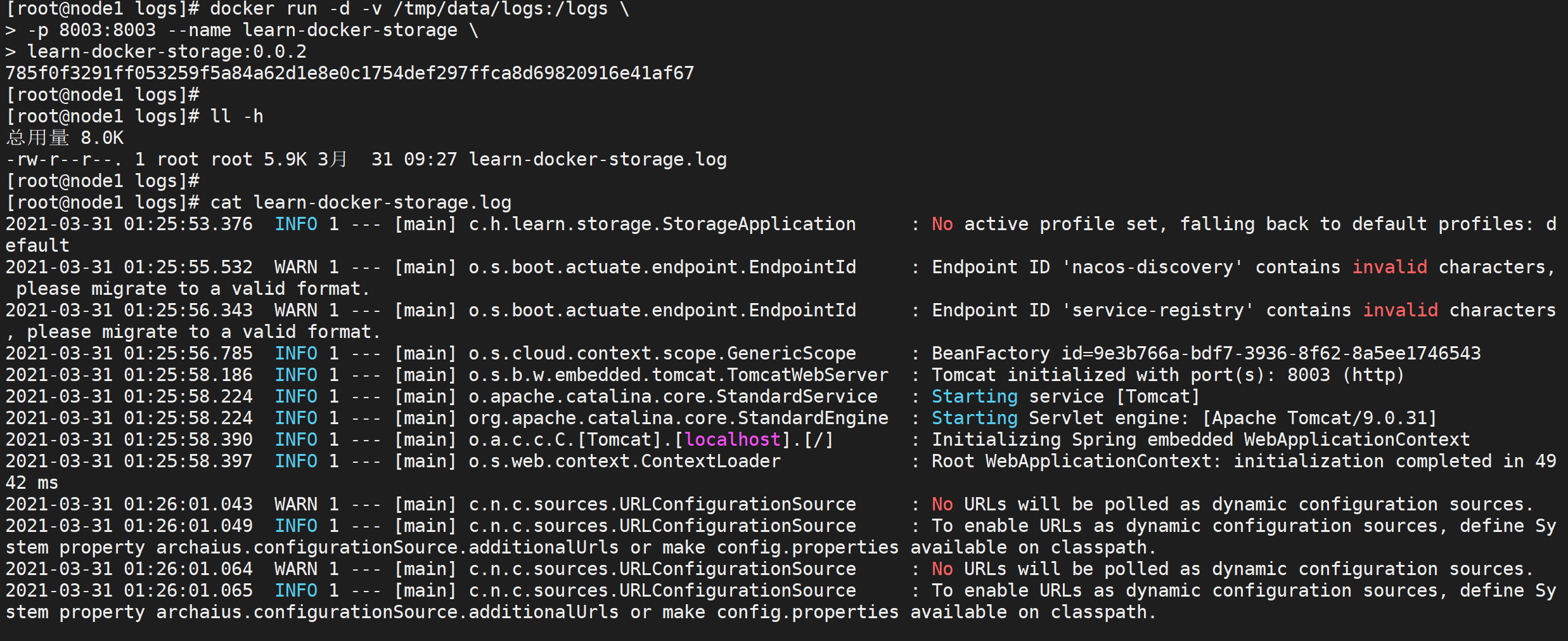
我们发现日志已经追加,我们让不同的容器挂载同一个目录了
volume和bind的区别
对于多个容器需要共享访问同一数据目录,或者需要持久化容器内数据(如数据库)时,我们都是采用挂载目录形式(bind mounts),将宿主机的某一目录挂载到容器内的指定目录,这种方式能解决问题,但这种方式也一直有一些缺点
- 容器在不同的服务器部署需要根据实际磁盘挂载目录修改路径
- 不同操作系统的文件和目录权限会搞得你昏头转向,火冒三丈 ?
bind mount和volume其实都是利用宿主机的文件系统,不同之处在于volume是docker自身管理的目录中的子目录,所以不存在权限引发的挂载的问题,并且目录路径是docker自身管理的,所以也不需要在不同的服务器上指定不同的路径,你不需要关心路径。

清理volume挂载
volume挂载方式,会生成很多匿名的目录,我们可以找到对应的没有使用的volume进行删除
docker volume ls

通过查看我们发现里面,有很多的volume,我们可以找到没有用的删除
docker volume rm volume_name
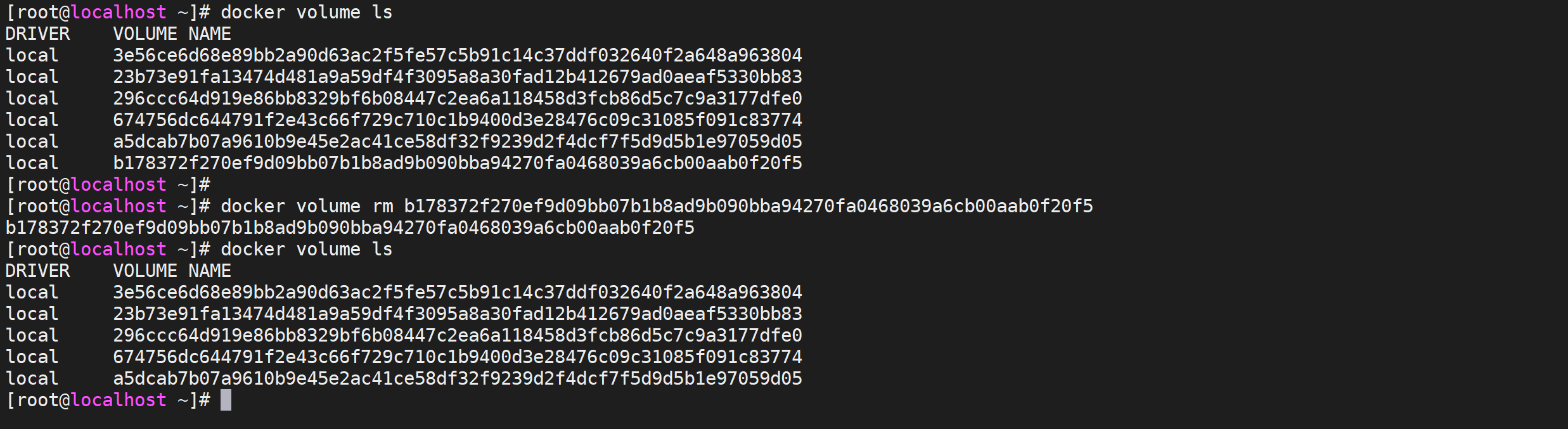
还可以通过命令将没有引用的全部volume清除掉,但是这个命令很危险
docker volume prune
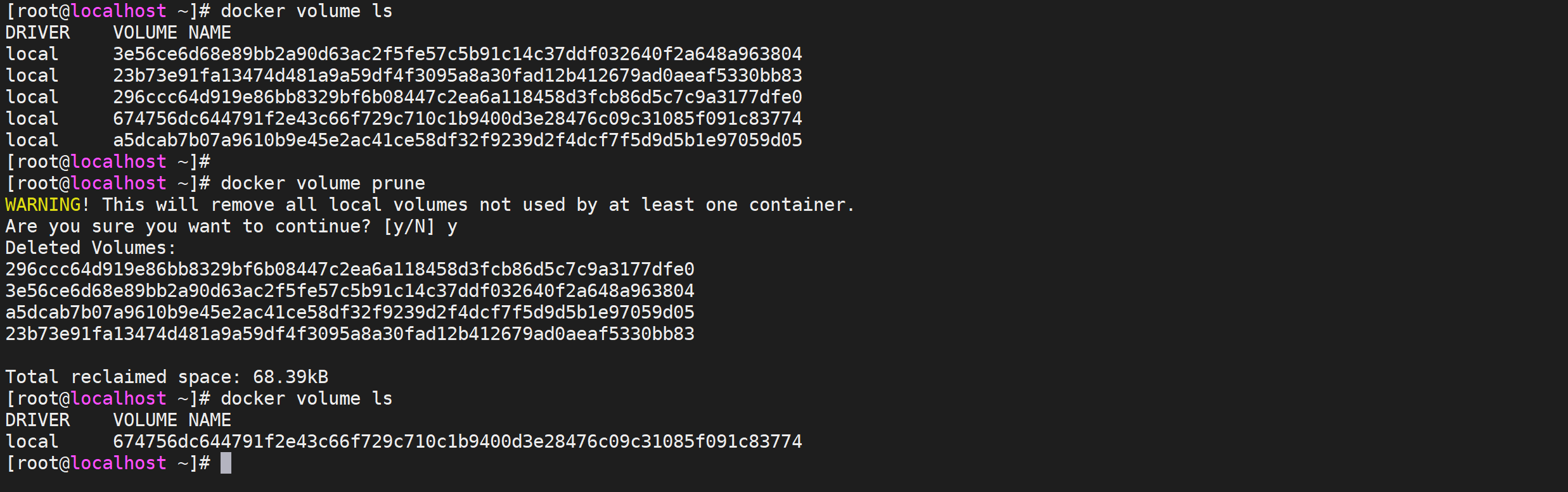
这样就将我们服务器上无效的volume清除掉了
网络优化
Docker网络原理
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关,因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
Docker网桥是宿主机虚拟出来的,并不是真实存在的网络设备,外部网络是无法寻址到的,这也意味着外部网络无法通过直接Container-IP访问到容器,如果容器希望外部访问能够访问到,可以通过映射容器端口到宿主主机(端口映射),即docker run创建容器时候通过 -p 或 -P 参数来启用,访问容器的时候就通过[宿主机IP]:[容器端口]访问容器。
Docker网络模式
| Docker网络模式 | 配置 | 说明 |
|---|---|---|
| host模式 | –net=host | 容器和宿主机共享Network namespace。 |
| container模式 | –net=container:NAME_or_ID | 容器和另外一个容器共享Network namespace。 kubernetes中的pod就是多个容器共享一个Network namespace。 |
| none模式 | –net=none | 容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth pair 和网桥连接,配置IP等。 |
| overlay模式 | – driver overlay | Docker跨主机通信模式,使用分布式计算机架构后需要使用overlay网络模式 |
| bridge模式 | –net=bridge | (默认为该模式) |
host模式
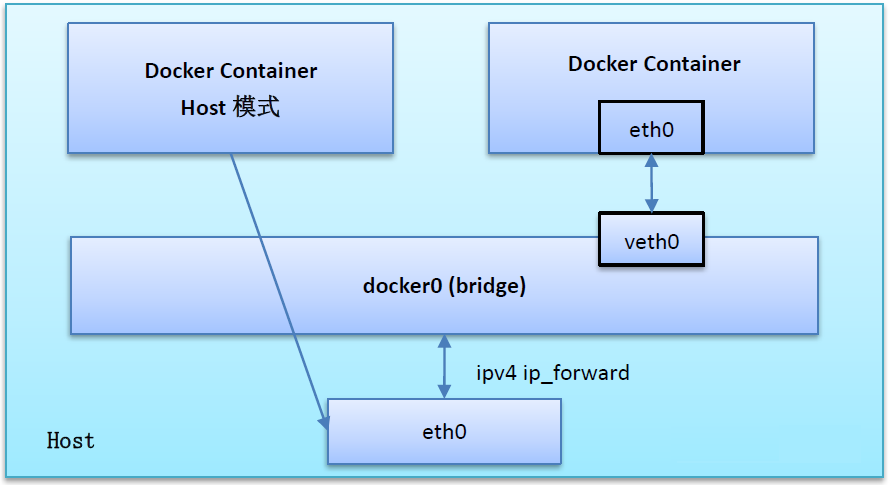
如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。
容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口,但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
使用host模式的容器可以直接使用宿主机的IP地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,不需要进行NAT,host最大的优势就是网络性能比较好,但是docker host上已经使用的端口就不能再用了,网络的隔离性不好。
Host模式如下图所示
container模式
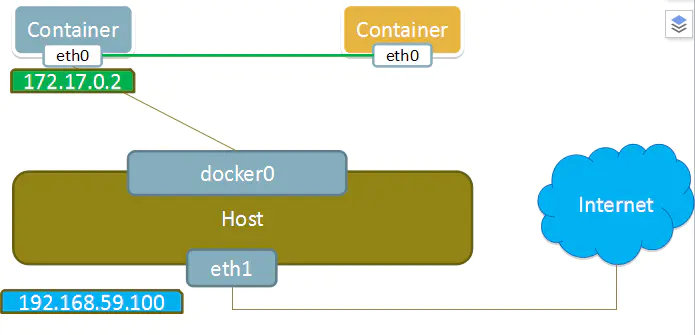
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享
新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等,同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的,两个容器的进程可以通过 lo 网卡设备通信
Container模式示意图
none模式
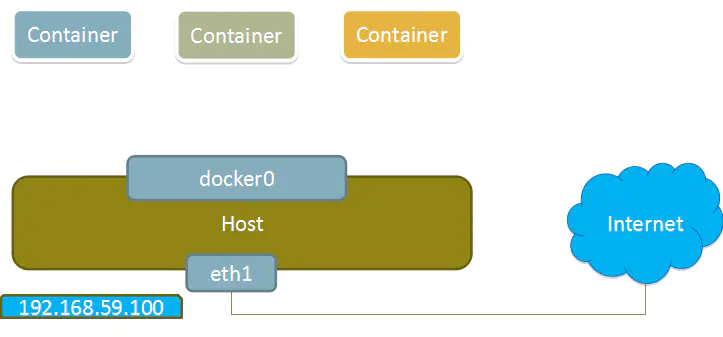
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置,也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
这种网络模式下容器只有lo回环网络,没有其他网卡,none模式可以在容器创建时通过–network=none来指定,这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
None模式示意图
overlay模式
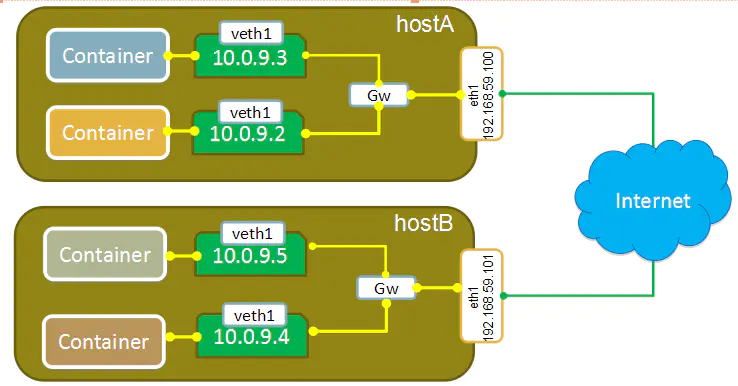
容器在两个跨主机进行通信的时候,是使用overlay network这个网络模式进行通信,如果使用host也可以实现跨主机进行通信,直接使用这个物理的ip地址就可以进行通信,overlay它会虚拟出一个网络比如10.0.9.3这个ip地址,在这个overlay网络模式里面,有一个类似于服务网关的地址,然后把这个包转发到物理服务器这个地址,最终通过路由和交换,到达另一个服务器的ip地址。
bridge模式
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上,虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中
从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关,在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show命令查看
bridge模式是docker的默认网络模式,不写–net参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。
bridge模式如下图所示
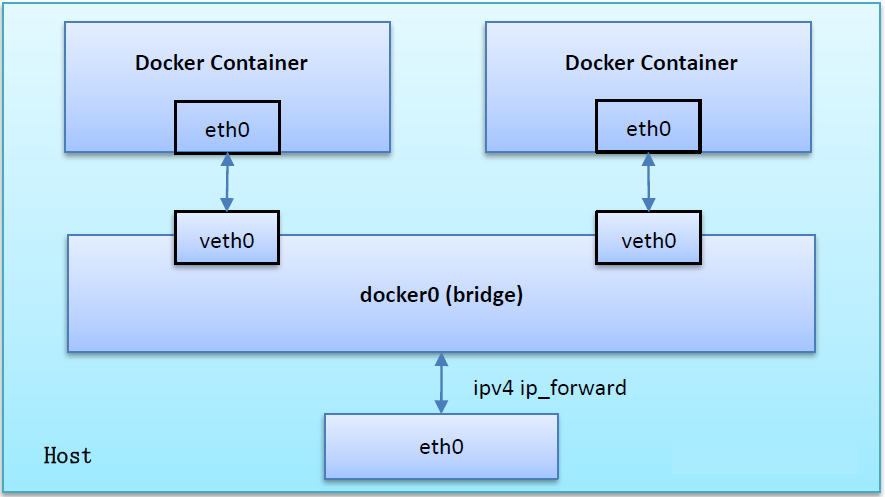
我们的网络结构
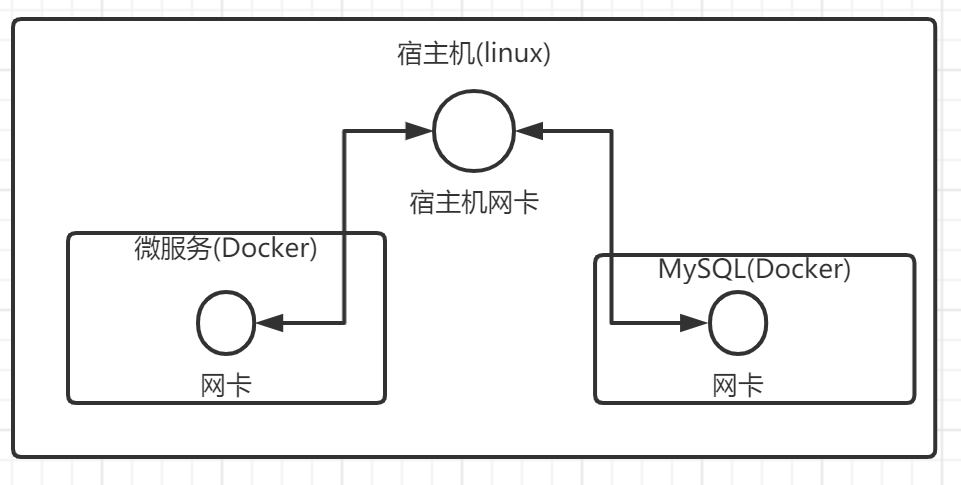
下图是我们自己的网络结构,我们是通过宿主机访问Mysql容器的,刚才我们学过,默认Docker已经接入了一个名字叫
bridge的桥接网络
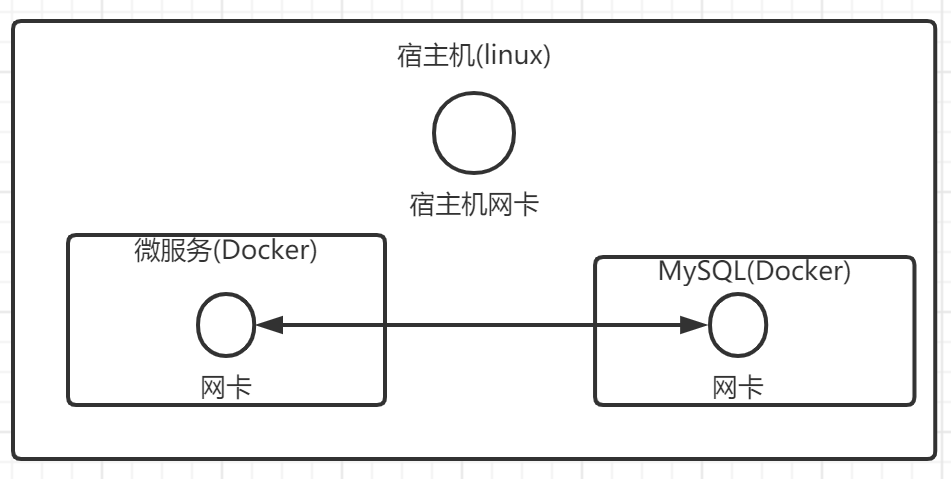
我们可以让我们的网络直接接入桥接网络,例如下图
创建网络
查看网络列表
可以通过
docker network ls命令查看网络列表
# 查看网络列表
docker network ls

上面就是容器默认几种网络
创建一个桥接网络
默认容器启动会自动默认接入
bridge的桥接网络,为了区分我们的服务也防止各种网络问题,我们创建一个专用网络,可以通过docker network create 网络名称来创建一个默认的桥接网络
# 创建一个桥接网络
docker network create learn-docker-network
# 查看网络列表
docker network ls

服务接入网络
停止并删除原有容器
停止和删除我们的微服务以及mysql服务
# 删除当前运行中的容器
docker rm -f learn-docker-storage nacos mysql
创建MySQL
因为我们的微服务依赖MySQL先启动MySQL并接入网络,因为MySQL不需要通过宿主机访问,所有也不需要映射端口了,–network 是配置接入哪一个网络
docker run -d \\
-v /tmp/etc/mysql:/etc/mysql/mysql.conf.d/ \\
-v /tmp/data/mysql:/var/lib/mysql \\
-e MYSQL_ROOT_PASSWORD=root \\
--name mysql --network=learn-docker-network \\
mysql:5.7.38

这样我们就把我们的MySQL服务启动起来了并且加入了learn-docker-network的网络
创建Nacos
我们的nacos是需要暴漏端口的,因为我们需要外部能够看到nacos页面,但是我们也需要我们的nacos连接到当前网络
docker run -d \\
--network=learn-docker-network \\
--name nacos --env MODE=standalone \\
nacos/nacos-server

查看网络详情
可以通过
docker network inspect 网络名称可以查看当前的网络的详细信息
docker network inspect learn-docker-network|grep Containers -A 20
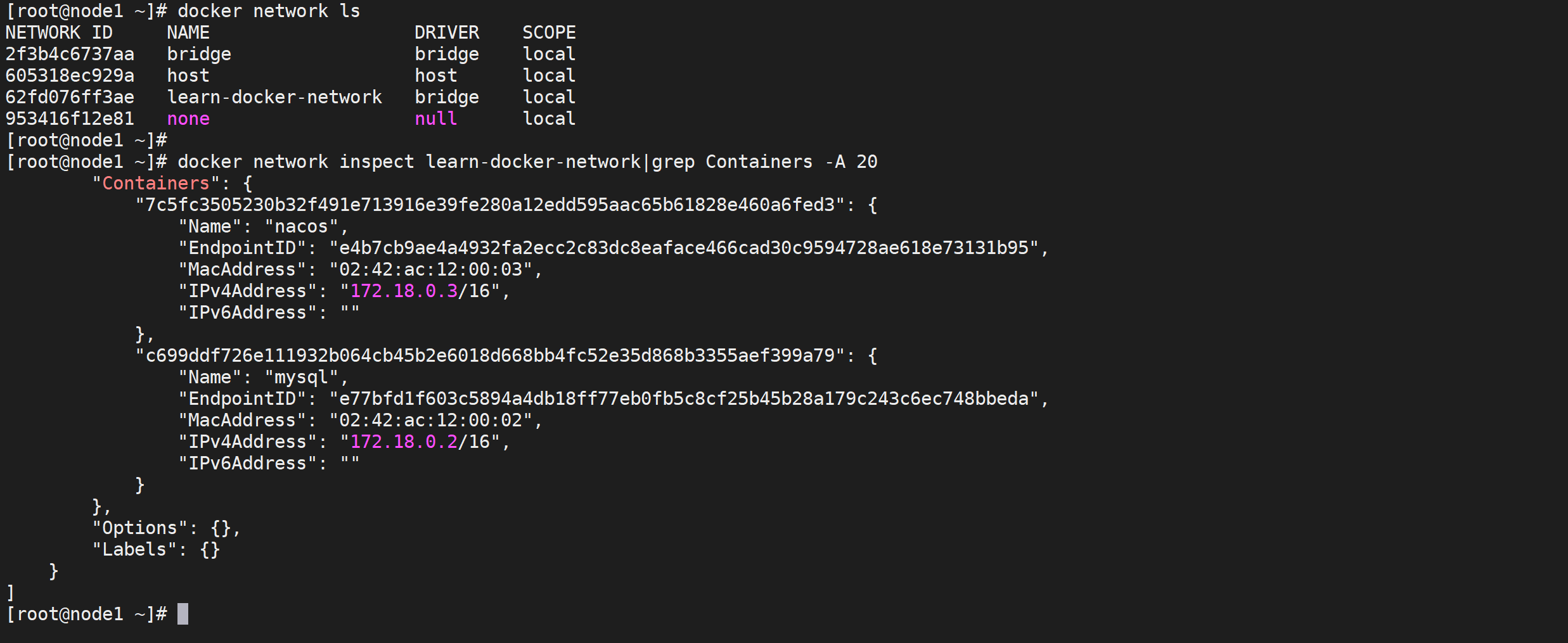
修改微服务配置
因为需要使用自定义网络访问mysql容器以及nacos容器,需要修改微服务数据库连接地址,
docker 网络访问 可以通过IP或者通过服务名称都是可以的,这里我们通过服务名称访问,因为我们使用了maven打包的方式,我们只需要将pom文件修改就可以
<properties>
<mysql.addr>mysql:3306</mysql.addr>
<nacos.addr>nacos:8848</nacos.addr>
</properties>
修改完成后进行编译项目
这里将数据库连接地址改为mysql容器的服务名称
mysql,nacos的连接地址变为了nacos
重新打包服务
将打包的文件上传服务器后按照上面步骤同上面打包,打包版本为 0.0.3
docker build -t learn-docker-storage:0.0.3 .

创建微服务
下面就按部就班的创建微服务就可以,只是注意需要加入网络,这里这个端口需要映射外网访问
docker run -d \\
-v /tmp/data/logs:/logs \\
-p 8003:8003 \\
--name learn-docker-storage \\
--network=learn-docker-network \\
learn-docker-storage:0.0.3
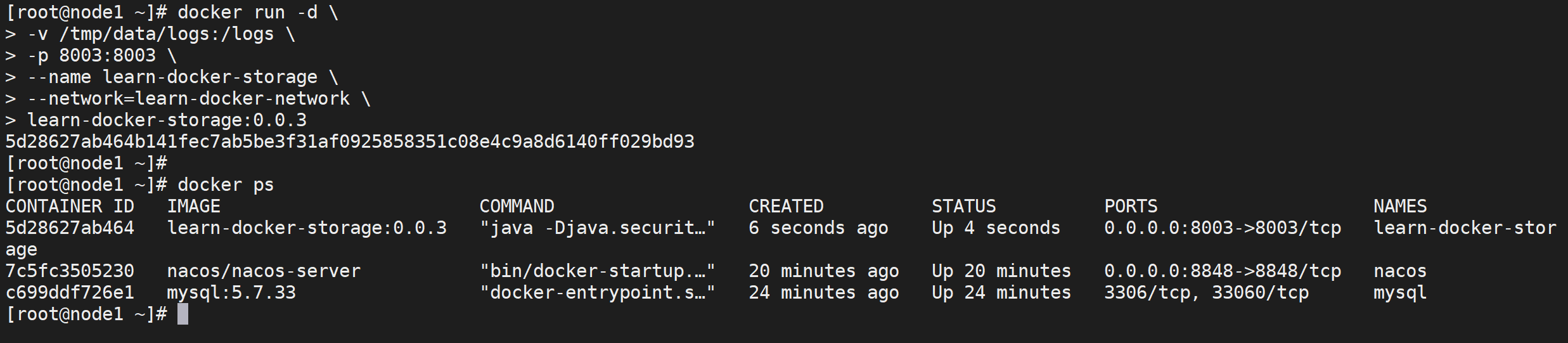
测试微服务
到现在微服务已经启动,我们尝试访问以下
curl http://192.168.64.153:8003/storage/employe/findByID/10001 | python -m json.tool

访问测试数据没有问题,到现在我们服务已经搭建完成,并且使用网络进行了优化