【学而不思则罔,思而不学则殆】
2023.9.9

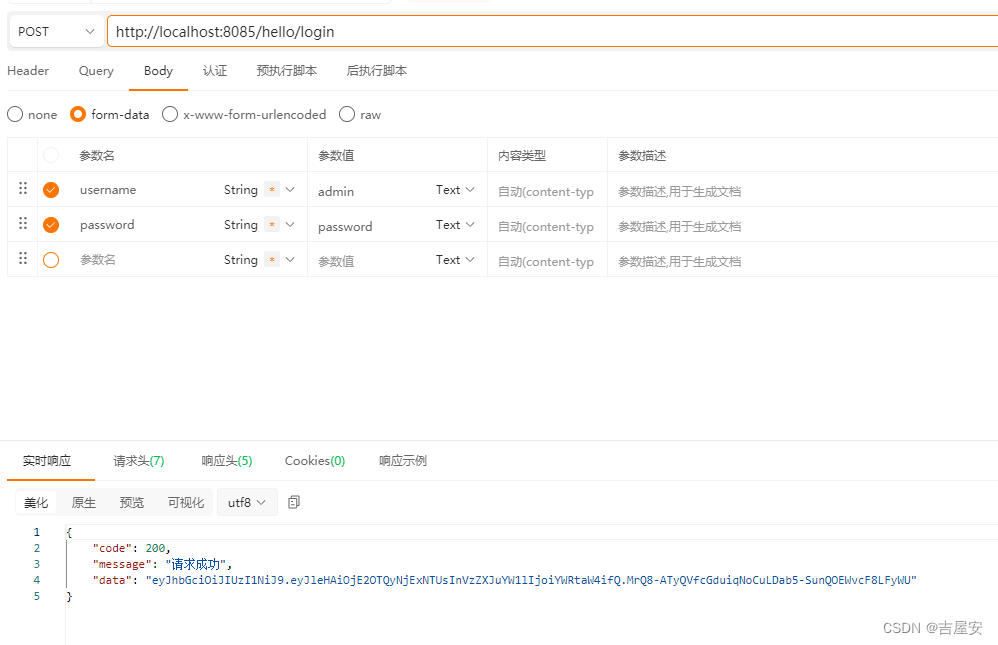
原因一:数据质量有问题
数据决定了算法的上限,在大模型时代,这句话仍然管用(比如open AI对数据的标注要求就非常高)数据的问题主要有这几方面:
- 1. 不同类别的样本数量很不平衡
这是一个非常常见的问题,可能不同类型之间的样本数量差异就和现实世界贫富差异一样大。,虽然有很多算法可以适应这种情况,但最好还是要做一下处理,理想情况下,我们希望不同类别的样本数量比较接近,此时可以进行上采样或下采样,或更改损失函数(如对少样本进行加权)。 - 2. 原始数据有很多低质量数据
当样本比较均衡,模型训练性能还是比较差时,可能就是训练数据中有很多bad case。要找出这部分数据进行分析,看能否进行修正(有些bad case是自然形成的,不是错误生成的,此时就不能修正)
对于文本,bad case就是有很多错别字,多字,少字等错误情形;对于图像,bad case就是有很多目标模糊,不完整,像素太小等情形。这些数据就算你标注的很好,但是因为噪音太多,也会导致模型训练效果不好,所以数据预处理是很有必要的,对这些低质量数据进行修正能够有效提高算法性能。 - 3. 有很多数据的标注质量不高
一是标错,二是标对了,但标的不好。
在分类问题中,标错就是进行了错误的打标;标的不好,比如图像标注没有按贴近目标边缘进行标注,边缘留出了很多空间,甚至还把其它目标的内容给框选了。 - 4. 打标的标准不清晰,有很多标注混淆的样本
举个例,比如命名实体识别任务中,“刹车”这个词被标注了两次,一次标注为“部件”,一次标注为“状态”,你自己都分不清它应该为什么类别,算法怎么做呢?
要有一个清洗的标注规范,不要有模棱两可的数据,否则这部分数据会成为模型性能的瓶颈,从混淆矩阵中来看,他们就是容易互相混淆的数据。
💡留一个问题:
若是一个样本你也实在分不清如何打标怎么办?这部分数据要不要去掉,要不要打标?
/
原因二:模型参数没设置好
网上很多开源模型,用默认参数跑一遍,基本都能得到不错的效果,但很多时候我们还是要结合自己的数据和硬件配置,进行调整,一些常见的参数如下:
- batch_size:
这个呢主要影响的是训练的速度,一般不会影响性能。在GPU显存允许下,尽量设置更大的batch_size - epoch:
这个参数若设置的太小,会导致模型训练欠拟合;若设置的太大,会导致模型过拟合,前者是训练阶段的性能都很差,后者是模型训练阶段很优秀,但预测阶段很垃圾(这就是模型把数据中的噪声都学到了)
如何判断过拟合or欠拟合?用学习曲线。 - 损失函数:
(待补充) - 激活函数:
(待补充)
💡留一个问题:
若预测数据中也有和训练阶段类似的噪声,那么过拟合模型会不会预测得很好,相当于对有数据有噪声也没有问题?
/
原因三:选的模型不厉害
很多时候,我们都会产生这样的疑问:
- 这个模型性能这么差,是不是我选的模型不够高大上?要不要用牛逼的模型试一下?
- 哇,这个不是最新的,XXX年的模型性能都这么好,要不要用更牛逼的模型试一下?
有没有共鸣?😂
目前各个任务方向都有很多模型可供选择,从规则方法到统计学习,到深度学习,甚至到大模型。模型实现本身不再是一个问题,如何选择场景合适的才是问题,这需要你仔细分析自己的应用场景特点。
就比如在NLP领域,大模型有大模型的牛逼,word2vec也还有它的适合场景,bert类算法在NLU领域仍有一席之地一样,很多时候杀鸡不需要牛刀。
很多时候,只要你的数据处理的质量比较高,那么不同量级模型的差距并不会特别大,有时候模型参数提升了好几个数量级,但是算法性能确只是提升几个点,这中间,要评估一下成本和性能的平衡。
因此,个人认为,算法模型没有最牛逼的,只有最适合的,什么是最适合的:在性能能达到一定要求时,选择更轻量级。