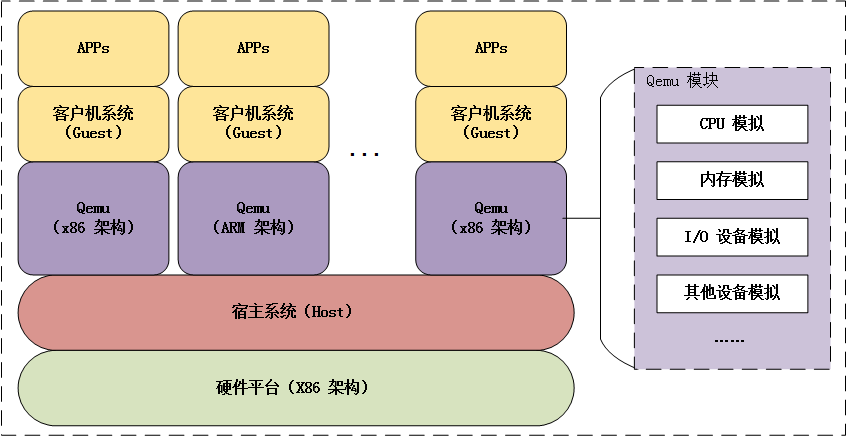
要了解 Hash冲突,那首先我们要先了解 Hash 算法和 Hash 表。
Hash算法
Hash 算法,就是把任意长度的输入,通过散列算法,变成固定长度的输出,这个输出结果是散列值。
Hash表
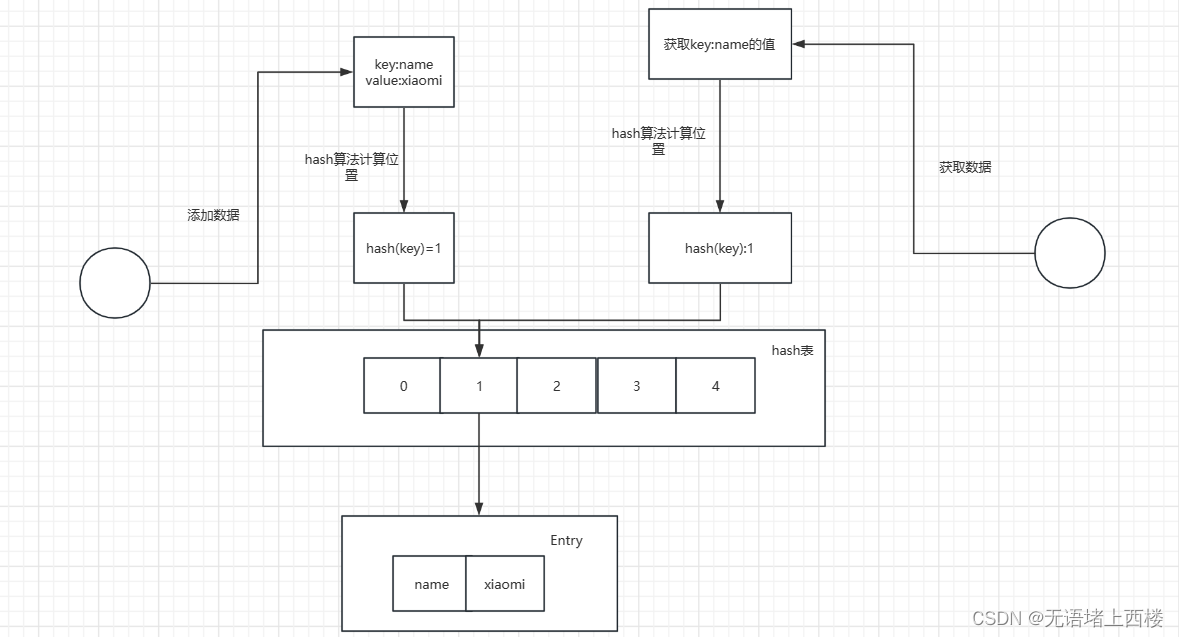
Hash 表又叫做“散列表”,它是通过 key 直接访问在内存存储位置的数据结构,在具体实现上,我们通过 hash 函数把 key 映射到表中的某个位置,来获取这个位置的数据,从而加快查找速度。
 hash冲突
hash冲突
所谓 hash 冲突,是由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,所以总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突。
解决hash 冲突
通常解决 hash 冲突的方法有 4 种。
开放定址法
开放定址法,也称为线性探测法,就是从发生冲突的那个位置开始,按照一定的次序从 hash 表中找到一个空闲的位置,然后把发生冲突的元素存入到这个空闲位置中。ThreadLocal 就用到了线性探测法来解决 hash 冲突的。
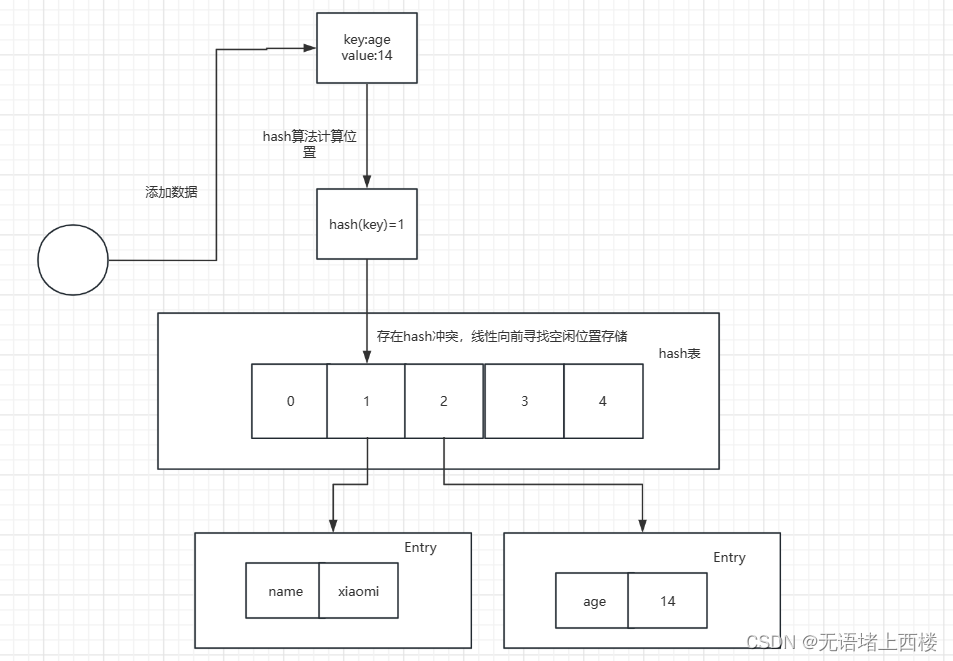
在 hash 表索引 1 的位置存了一个 key=name,当再次添加 key=age时,hash 计算得到的索引也是 1,这个就是 hash 冲突。而开放定址法, 就是按顺序向前找到一个空闲的位置来存储冲突的 key。
链式寻址法
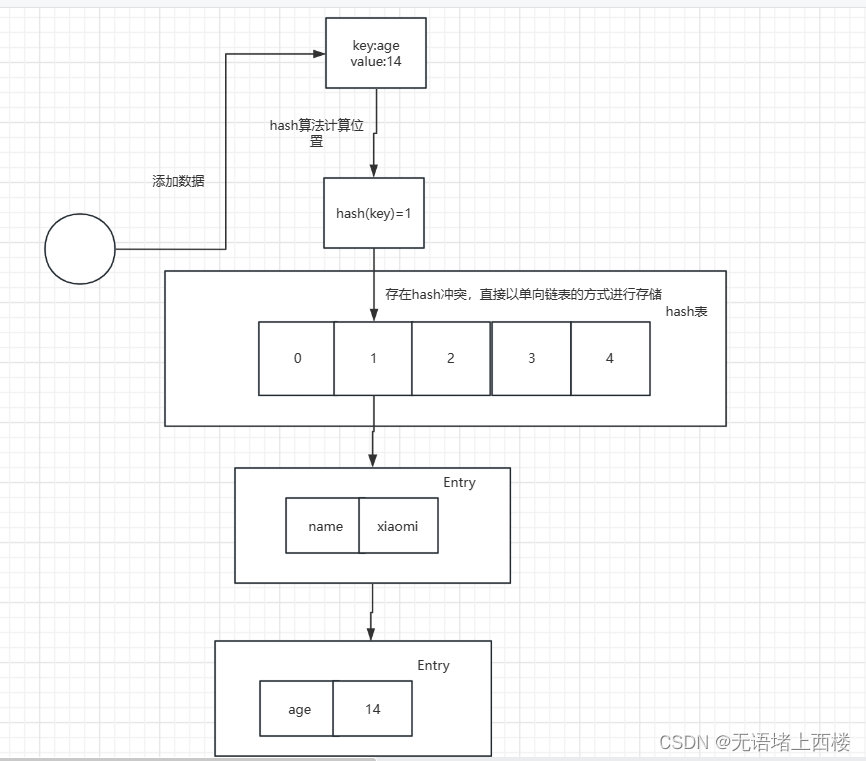
链式寻址法,这是一种非常常见的方法,简单理解就是把存在 hash 冲突的 key,以单向链表的方式来存储,比如 HashMap 就是采用链式寻址法来实现的。
再 hash 法
再 hash 法,就是当通过某个 hash 函数计算的 key 存在冲突时,再用另外一个 hash 函数对这个 key 做 hash,一直运算直到不再产生冲突。这种方式会增加计算时间,性能影响较大。
建立公共溢出区
建立公共溢出区, 就是把 hash 表分为基本表和溢出表两个部分,凡事存在冲突的元素,一律放入到溢出表中。
HashMap
HashMap 在 JDK1.8 版本中,通过链式寻址法+红黑树的方式来解决 hash 冲突问题,其中红黑树是为了优化 Hash 表链表过长导致时间复杂度增加的问题。当链表长度大于 8 并且 hash 表的容量大于 64 的时候,再向链表中添加元素就会触发转化。