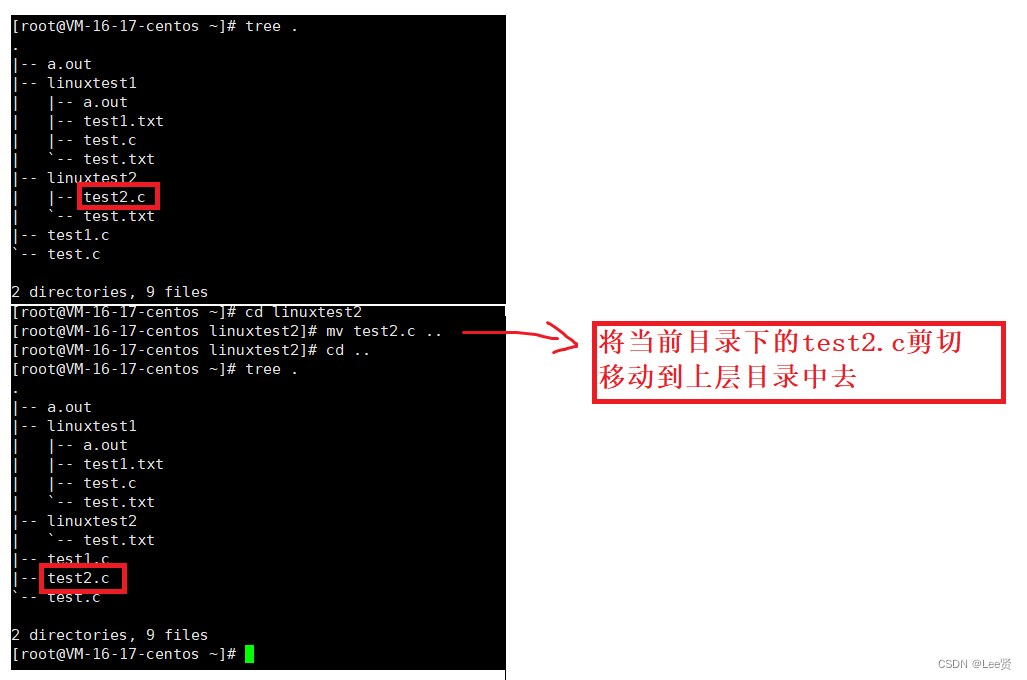
一:选择排序
场景:找出一个班上身高最高的人你会怎么找?A B C D A B
选择排序的思路和插入排序非常相似,也分已排序和未排序区间。但选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。但是不像插入排序会移动数组 选择排序会每次进行交换,如以下例子:
4 5 6 3 2 1
第一次: 1 5 6 3 2 4
第二次: 1 2 6 3 5 4
1.时间复杂度:O(N^2)
2.空间复杂度:O(n)
3.交换次数
4.稳定性:不稳定
二:冒泡排序
核心思路:冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复n次,就完成了n个数据的排序工作。
举例说明:4 5 6 3 2 1,从小到大排序。 1 2 3 4 5 6
进行排序:什么样的情况下不做任何交换了呢,那就是所有的数都在它应该在的位置;O(n)
1.时间复杂度:O(n^2)
2.空间复杂度:O(n)
3.交换次数:挺大的
4.稳定性:稳定
package Sort2;
import java.util.Arrays;
/**
* 冒泡排序
*/
public class BubbleSort {
public static void main(String[] args) {
int data[] = { 4, 5, 6, 3, 2, 1 };
int n = data.length;
//n-1:这里是因为判断两个数是只比较一次 例如: 1 2 比较次数只会比一次
for (int i = 0; i < n - 1; i++) { //排序的次数
//优化:如果所有的数都排好了,不需要交换了,就不需要冒泡了,所以直接退出
boolean flag = false;
// n-1-i:要减掉i是因为每次冒泡排序都会将后面的值确定,所以i就是后面已经排好的数字,所以就不需要再比较了,所以得减掉
for (int j = 0; j < n - 1 - i; j++) { //具体冒泡 n - 1 - i,6,5,4,3,2,1
if (data[j] > data[j + 1]) {
//交换
int temp = data[j]; //用了第三个变量,不用第三个变量
data[j] = data[j + 1];
data[j + 1] = temp;
flag = true;
//异或实现
// data[j] = data[j] ^ data[j+1];
// data[j+1] = data[j] ^ data[j+1];
// data[j] = data[j] ^ data[j+1];
}
}
if(!flag) break;
}
System.out.println(Arrays.toString(data));
}
}
/**
* 下面是交换的时候如果不用第三方变量存储的话如何交换
*/
// a:2 b:3
// 3 2 => a:3 b:2
// 用加减
//a = a + b => a = 3+2 =5;
//b = a - b => b = 5-3 =2;
//a = a - b => a = 5-2 =3;2.1 如何进行简单的优化:
1. 在交换的时候会需要第三方变量,会占空间,所以可以用异或交换。
2. 当排好序了就不需要继续循环了,所以加flag作为标签。
2.2 如何实现异或交换?
异或操作可以实现交换两个数字的值的原因是因为异或操作具有以下几个性质:
- 任何数和0异或的结果仍然是这个数本身:a ^ 0 = a
- 任何数和自身异或的结果是0:a ^ a = 0
- 异或操作满足交换律:a ^ b = b ^ a 利用这些性质,我们可以通过异或操作实现交换两个数字的值,具体步骤如下: 假设有两个变量a和b,它们的初始值分别为a0和b0。
- 第一步:通过将a与b异或,将结果保存在a中:a = a ^ b。 此时,a的值为a0 ^ b0,b的值保持不变。
- 第二步:再将a与b异或,将结果保存在b中:b = a ^ b。 在这一步中,我们可以将上一步得到的a的值(a0 ^ b0)再与b0异或,得到的结果就是a0,即原始的a的值。 同时,由于异或操作满足交换律,所以b = (a0 ^ b0) ^ b0 = a0 ^ (b0 ^ b0) = a0 ^ 0 = a0。 此时,a的值保持不变,b的值变为a0。
- 第三步:最后将a与b异或,将结果保存在a中:a = a ^ b。 在这一步中,我们将上一步得到的a的值a0 ^ b0与上一步得到的b的值(a0)异或,得到的结果就是b0。
public class SwapNumbers {
public static void main(String[] args) {
int a = 10;
int b = 20;
System.out.println("交换前:");
System.out.println("a = " + a);
System.out.println("b = " + b);
// 使用异或操作交换a和b的值
a = a ^ b;
b = a ^ b;
a = a ^ b;
System.out.println("交换后:");
System.out.println("a = " + a);
System.out.println("b = " + b);
}
}三: 快速排序

45 28 80 90 50 16 100 10
基准数:一般就是取要排序序列的第一个。
第一次排序基准数:45
从后面往前找到比基准数小的数进行对换: 10 28 80 90 50 16 100 45
从前面往后面找比基准数大的进行对换: 10 28 45 90 50 16 100 80
10 28 16 90 50 45 100 80
10 28 16 45 50 90 100 80
以基准数分为3部分,左边的比之小,右边比之大:
{10 28 16} 45 {50 90 100 80}
到此第一次以45位基准数的排序完成。
1.时间复杂度:nlogn 最坏的情况就是O(n^2)
2.空间复杂度:O(n)
3.稳定性:不稳定
4.快排和归并的对比:
(1)归并排序的处理过程是由下到上的,先处理子问题,然后再合并。
(2)快排其实就是从上到下,先分区,在处理子问题,不用合并。 其优化就是优化基准数,提供一个取三个数中间的思路.
package Sort2;
public class QuiklySort {
public static void qSort(int data[], int left, int right) {
int base = data[left]; // 就是我们的基准数,取序列的第一个,不能用data[0]
int ll = left; // 表示的是从左边找的位置
int rr = right; // 表示从右边开始找的位置
while (ll < rr) {
// 从后面往前找比基准数小的数
while (ll < rr && data[rr] >= base) {
rr--;
}
//这里有个小技巧,如果ll < rr为true,说明 data[rr] >= base = false,就找到比基准数小的,就要交换
if (ll < rr) { // 表示是找到有比之大的
int temp = data[rr];
data[rr] = data[ll];
data[ll] = temp;
ll++;
}
// 从前面往后找比基准数大的数
while (ll < rr && data[ll] <= base) {
ll++;
}
if (ll < rr) {
int temp = data[rr];
data[rr] = data[ll];
data[ll] = temp;
rr--;
}
}
// 肯定是递归 分成了三部分,左右继续快排,注意要加条件不然递归就栈溢出了
//ll:循环终止时为基准数在最中间,然后将ll左右两部分继续递归
if (left < ll)
qSort(data, left, ll - 1);
if (ll < right)
qSort(data, ll + 1, right);
}
}
各种排序比较:

这么多种排序算法我们究竟应该怎么选择呢?
1.分析场景:稳定还是不稳定
2.数据量:数据量小的时候选什么?比如就50个数,优先选插入(5000*5000=25000000)
3.分析空间: 综上所述,没有一个固定的排序算法,都是要根据情况分析的。但是如果你不会分析的情况下 选择归并或者快排。
四:计数排序
如何对一个省200万学生的高考成绩(假设成绩最多只有2位小数,0~900范围)进行排序,用尽可能高效的算法。
package sorttest;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.io.Writer;
/**
* 如何对一个省200万学生的高考成绩(假设成绩最多只有2位小数,0~900范围)进行排序,用尽可能高效的算法。
* 计数排序
*/
public class CountSort {
public static void main(String[] args) throws Exception {
String str = null;
String fileName = "D:\\JavaCode\\tulin\\src\\sorttest\\200w.txt";
InputStreamReader isr = new InputStreamReader(new FileInputStream(fileName), "UTF-8");
BufferedReader br = new BufferedReader(isr);
int data[] = new int[2100002];
int i = 0;
//遍历所有的数据存到数组中
while ((str = br.readLine()) != null) {
double a = Double.valueOf(str);
a = a * 100;
data[i++] = (int) a;
// System.out.println((int) a);
}
System.out.println("开始值为" + i);
long start = System.currentTimeMillis();
countSort(data, 0, data.length - 1);
System.out.println("结束时间为" + (System.currentTimeMillis() - start) + "ms");
}
public static void countSort(int data[], int min, int max) throws Exception {
int counts[] = new int[max + 1];
//将所存的数字按照数组下标存储计数,
for (int i = 0; i < data.length; i++) {
counts[data[i]]++;
}
File file = new File("D:\\JavaCode\\tulin\\src\\sorttest\\200w-csort.txt");
Writer out = new FileWriter(file);
//同时从0开始遍历,所以也默认排好序,直接输出
for (int i = 0; i <= max; i++) {
if (counts[i] > 0) {
for (int j = 0; j < counts[i]; j++) {
out.write(((double) (i / 100.0)) + "\r\n");
}
}
}
out.close();
}
}