JUC编程中锁引发的“见解”
一大早就在想锁是干嘛的?什么情况下要用锁?想了很多,下面的所有表述都是就是我的思考流程,欢迎所有人一起讨论、更正。
文章目录
- JUC编程中锁引发的“见解”
- 1、什么是JUC编程?
- 2、JUC编程中什么情况下需要使用锁?
- 3、什么是JMM?
- 3.1 JMM内存模型
- 3.2 缓存一致性问题
- 3.3 处理器优化和指令重排序
- 3.4 共享内存问题
- 4、分布式锁的使用
- 4.1为什么并发编程一般会使用分布式锁,不用本地锁?
- 4.2 redis分布式锁
1、什么是JUC编程?
首先你得知道什么是juc编程,JUC 编程是指 Java 并发编程,其中 “JUC” 是 “Java Util Concurrency” 的缩写。
那既然都提到了JUC编程是并发编程了,那就不由得大家考虑了,并行和并发的区别是什么?为什么不叫并行编程?
我觉得吧,并行就是指多个任务同时执行,并发就是指多个线程同时抢占同一资源,所谓的并发量就是指你这一个应用程序在同一时间可以处理的并发任务或者请求数量,有了应用程序并发量的考虑才会有了我们的JUC编程。
2、JUC编程中什么情况下需要使用锁?
在Java并发编程中,需要使用锁(如Java的 synchronized 关键字或 java.util.concurrent 包中提供的锁类)来管理多个线程对共享资源的访问,以确保线程安全。以下是一些常见的情况,其中需要使用锁:
-
多个线程修改共享变量:当多个线程同时访问和修改共享变量时,需要使用锁来保护这些变量,以防止数据竞争和不一致状态的发生。
-
临界区保护:某些关键部分的代码,称为临界区,需要被一次只允许一个线程访问。锁可以用于实现对临界区的互斥访问,确保一次只有一个线程可以执行临界区内的代码。
-
协同多线程操作:在多线程环境下,有时需要协调多个线程的操作,以确保它们按照期望的顺序执行。锁可以用于实现这种协同,例如使用
wait()和notify()或await()和signal()方法。 -
生产者-消费者问题:在生产者-消费者问题中,生产者线程生成数据并将其放入共享队列,而消费者线程则从队列中取出数据。锁可以用于控制对队列的并发访问,以防止数据竞争和队列溢出。
-
避免死锁:锁还可以用于避免死锁情况的发生。通过谨慎地管理锁的获取和释放顺序,可以减少死锁的风险。
-
保护不可变对象:在多线程环境下,不可变对象通常是线程安全的。但如果多个线程都要修改某个不可变对象的状态,就需要使用锁来保护它,以确保线程安全。
-
线程间通信:在多线程应用程序中,线程之间可能需要进行通信或同步。锁和条件变量可以用于线程之间的有效通信和同步。
总之,锁就是对共享资源的保护,没有共享资源还要个球的锁。
3、什么是JMM?
既然都提到了共享资源了,那么我也想提一下我学到的JMM,JMM 是Java内存模型( Java Memory Model),简称JMM。记得它是Java内存模型,并不是JVM(java 虚拟机)。它两就像雷锋与雷峰塔的关系,有关系吗?没有关系。
3.1 JMM内存模型
哦嚯,都知道了JMM是Java内存模型了,那多少得知道它大概长什么样吧,下面是我了解的大概的模型图。

CPU Register
CPU Register也就是 CPU 寄存器。CPU 寄存器是 CPU 内部集成的,在寄存器上执行操作的效率要比在主存上高出几个数量级。
CPU Cache Memory
CPU Cache Memory也就是 CPU 高速缓存,相对于寄存器来说,通常也可以成为 L2 二级缓存。相对于硬盘读取速度来说内存读取的效率非常高,但是与 CPU 还是相差数量级,所以在 CPU 和主存间引入了多级缓存,目的是为了做一下缓冲。
Main Memory
Main Memory 就是主存,主存比 L1、L2 缓存要大很多。注意:部分高端机器还有 L3 三级缓存。
3.2 缓存一致性问题
上面图中间得那三个不是狗盆是缓存!既然上面都提到了CPU的执行效率比主内存效率要高很多,所以就得有解决办法,那就是用高速缓存来作为缓冲,给它一个缓冲区,就和其他缓存产品思想差不多,我觉得吧包括消息队列的队列削峰也差不多就是这种想法,这种鸟玩意(狗头保命)。既然解决了效率快慢的问题,但是还有一个问题没解决,那就是缓存一致性。出刀快没用,咋们还要准!所以我又去了解了一下缓存一致性的解决办法。
见下图:
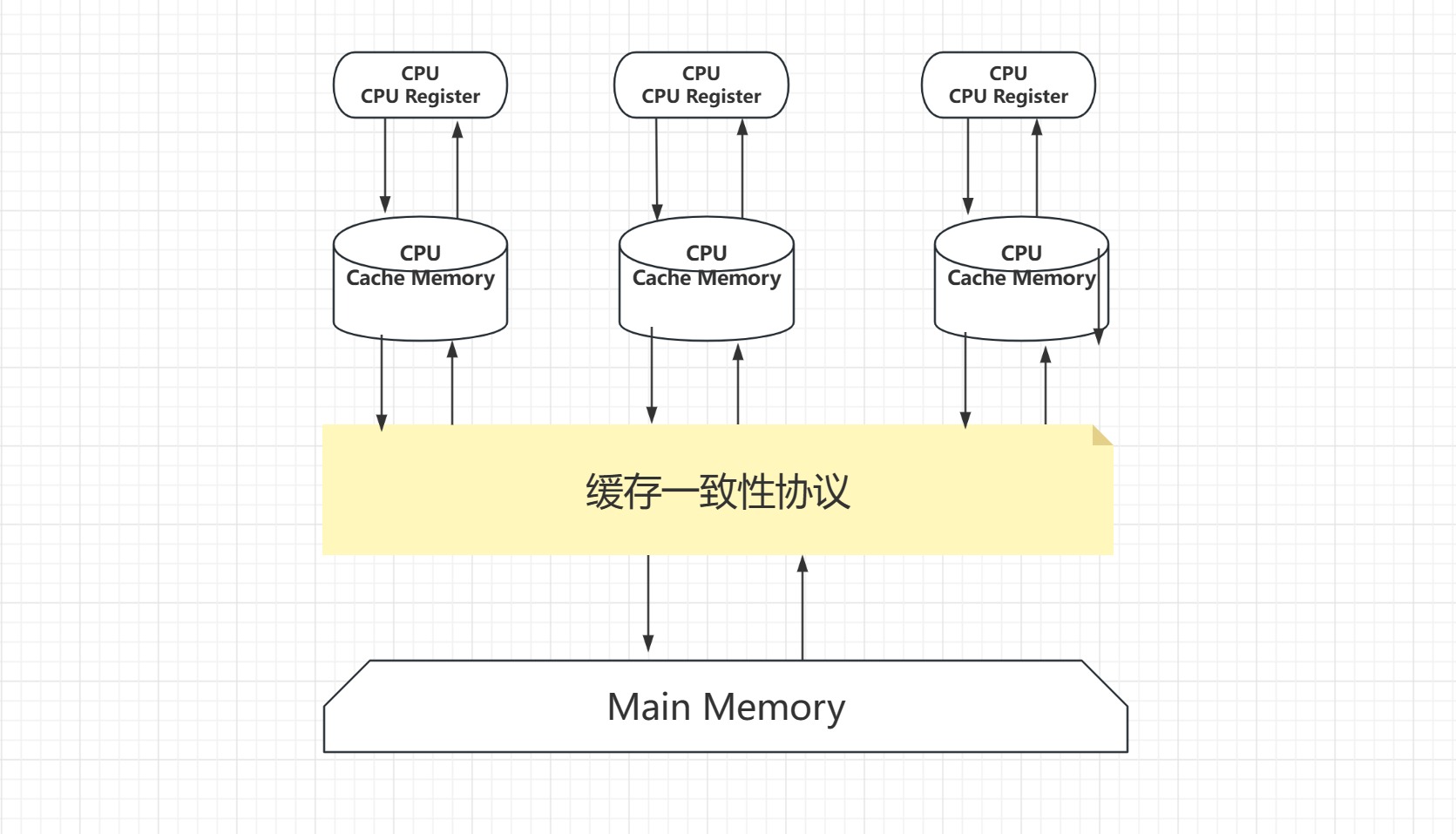
发现什么了吗?就是多了个协议,既然你不和我一致,但是咋们有需要沟通,那么我们就签订一个协议来解决/
3.3 处理器优化和指令重排序
上面是加了高速缓存优化了CPU和主内存的速率不匹配问题,但是我们还可以进一步优化处理器,因为为了使处理器内部的运算单元能够最大化被充分利用,处理器会对输入代码进行乱序执行处理,这就是处理器优化。
处理器重排序通常包括以下三种类型:
- 写重排序:将写操作的执行顺序与程序中的顺序不一致。这可能会导致一个线程的写操作在另一个线程的写操作之前执行,从而破坏了数据的一致性。
- 读重排序:将读操作的执行顺序与程序中的顺序不一致。这可能会导致一个线程读取到了过时的数据,因为它的读操作在另一个线程的写操作之前执行。
- 内存屏障(Memory Barriers):处理器可能会插入内存屏障来控制指令的执行顺序,以确保某些操作不会被重排序。
下面是一个简单的Java代码示例,演示了处理器重排序可能导致的问题:
public class ReorderingExample {
private static int x = 0;
private static int y = 0;
private static int a = 0;
private static int b = 0;
}
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
a = 1;
x = b;
});
Thread thread2 = new Thread(() -> {
b = 1;
y = a;
});
thread1.start();
thread2.start();
try {
thread1.join(); //
thread1.join()是一个线程同步方法,它的作用是等待thread1线程执行完毕后再继续执行当前线程(通常是主线程)的代码。
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("x = " + x);
System.out.println("y = " + y);
}
在这个示例中,两个线程分别修改了a和b的值,并且x和y的值分别被设置为b和a。理论上,x和y的值应是0和1。然而,由于处理器的重排序,实际的输出可能是x = 0和y = 0,这违反了我们的预期。
要解决这种问题,可以使用volatile关键字或内存屏障等机制来告诉处理器不要进行重排序。这样可以确保代码的执行顺序与程序员的预期一致。
3.4 共享内存问题
好了好了,想远了,我们前面想说的其实是共享内存问题,那么怎么共享内存的呢,我再去修改一下我画的图。
如下:
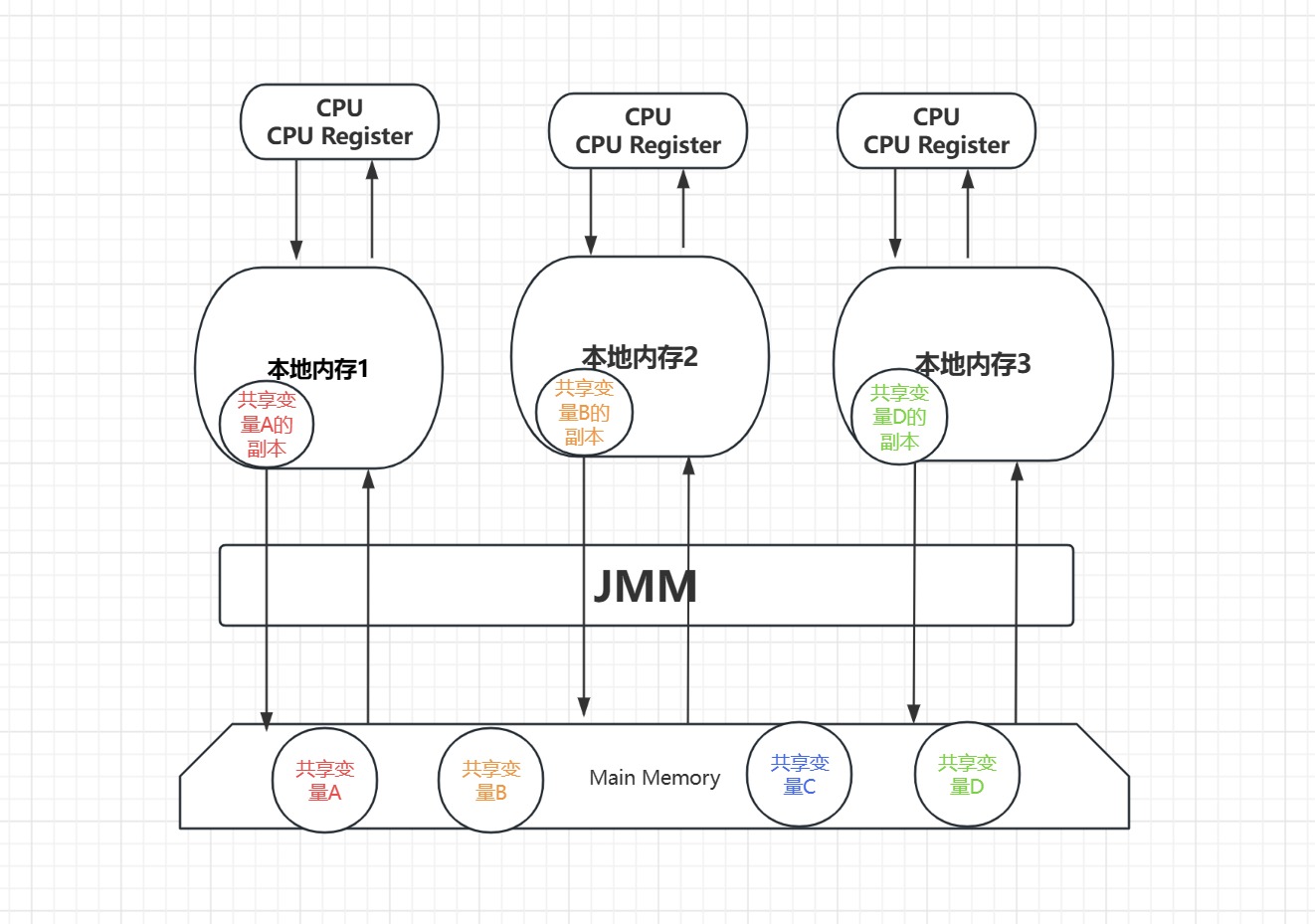
具体逻辑也很麻烦,我也一时间说不清楚。就是假设有四个变量A,B,C,D,为了实现共享,就把他们都存在了主内存中,但是,既然共享了,就说明允许多个线程进行共同的操作修改。但是这里的修改通常是首先在自己的本地内存对变量创建一个副本存在自己的本地内存,把副本修改完之后再写入到主内存。一般会涉及到JMM中操作的三个特性:
- 原子性:原子性就不用说了,多个操作不能够再分割,得看成一个整体,防止别的线程见缝插针。
- 可见性:是指当一个线程修改了共享变量的值后,其他线程能够立即看到这个修改。
- 有序性:有序性就是让处理器不要耍小聪明去进行重排序,保证代码按照我们想要的顺序执行。
4、分布式锁的使用
首先回想一下JUC中有那些锁,怎么加锁来保证咋们的并发量?
- 偏向锁(Biased Locking):偏向锁是一种针对加锁操作的优化手段。它假定大多数情况下,锁总是由同一线程多次获得,因此在第一次获得锁后,会将锁标记为“偏向”于获得它的线程。这意味着之后该线程再次请求这个锁时,无需争夺锁,提高了性能。只有在其他线程竞争锁时,偏向锁会升级为轻量级锁或重量级锁。
- 轻量级锁(Lightweight Lock):轻量级锁是一种在多线程竞争时,为了减小锁操作的开销而使用的锁。它基于CAS(Compare-And-Swap)操作,尝试原子地将锁标记从偏向状态升级为轻量级锁状态。如果锁竞争激烈,轻量级锁会升级为重量级锁。
- 重量级锁(Heavyweight Lock):重量级锁是传统的锁实现,它使用操作系统的互斥量来控制多线程对共享资源的访问。当多个线程竞争锁时,其中一个线程会获得锁,其他线程则进入阻塞状态。
- 公平锁(Fair Lock):公平锁保证线程按照请求锁的顺序获得锁,即先到先得。虽然公平锁会增加竞争的开销,但它确保不会出现线程饥饿的情况。
- 悲观锁(Pessimistic Locking):悲观锁假定并发访问的情况下会出现冲突,因此总是在访问共享资源之前先获取锁,确保资源独占。Synchronized 和 ReentrantLock 就是悲观锁的实现。
- 乐观锁(Optimistic Locking):乐观锁假定并发访问的情况下不会出现冲突,因此不会阻塞线程,而是在更新操作时检查数据版本号等标识是否发生变化。乐观锁通常使用版本号或时间戳来实现,例如,CAS 操作就是一种乐观锁的实现。
- ReentrantLock:可重入锁,与synchronized类似,但提供了更多的功能,如可中断、可定时等。
- ReentrantReadWriteLock:可重入读写锁,支持多个线程同时读取共享数据,但只允许一个线程写入数据。
- StampedLock:一个更加灵活的读写锁,支持乐观读、悲观读、写入操作。
- Semaphore:信号量,用于控制同时访问某个资源的线程数量。
- CountDownLatch:倒计数器,用于等待多个线程完成某个任务。
- CyclicBarrier:循环屏障,用于等待多个线程都达到某个状态后再一起继续执行。
- Phaser:分阶段屏障,更高级的屏障,可以分为多个阶段,每个阶段可以有不同数量的参与者。
- Exchanger:用于两个线程之间交换数据的同步点。
- LockSupport:线程阻塞工具,可以用来阻塞和唤醒线程。
是不是很多?很难理解?那就去学JUC编程吧,兄弟们,我也是菜鸟,我也想成为并发编程的高手。
下面我想说一下我了解到的一个问题:
4.1为什么并发编程一般会使用分布式锁,不用本地锁?
并发编程中通常使用锁来保护共享资源或临界区,以确保多个线程或进程之间的操作是有序的。在单机环境下,本地锁(例如Java中的synchronized关键字或ReentrantLock)通常足够,可以用于同步线程之间的访问。但在分布式系统中,使用本地锁可能会遇到一些问题,因此更常使用分布式锁。以下是一些原因:
-
多节点协调:在分布式系统中,不同节点上的线程可能需要协调和同步操作。本地锁只在单个JVM进程内有效,不能用于多个JVM之间的协调。因此,分布式锁允许在不同节点上协调并发操作。
-
多个进程或服务:分布式系统通常由多个进程或服务组成,这些进程可能运行在不同的服务器上。本地锁只在单个进程内有效,不能用于不同进程之间的同步。
-
资源竞争:分布式系统通常有多个节点同时访问共享资源(如数据库、文件、缓存等),本地锁不能处理不同节点之间的资源竞争问题。
-
故障容忍:分布式锁通常设计为故障容忍的,即使某个节点或锁服务发生故障,也不会导致死锁或数据不一致。
-
水平扩展:分布式锁可以轻松水平扩展,以处理高并发的情况,而本地锁的性能受限于单个进程。
虽然本地锁在单机环境下具有高性能和低开销的优势,但在分布式系统中,通常需要考虑并发访问多个节点和资源竞争的情况,这时使用分布式锁更为合适。分布式锁通常基于分布式存储或协调服务实现,如ZooKeeper、Redis等,它们提供了一种可靠的方式来管理锁,确保在分布式环境中的线程安全和同步。因此,选择本地锁还是分布式锁取决于具体的应用场景和需求。
所以说不用学本地锁了?别想多了兄弟们,本地锁都玩不明白不理解怎么去玩分布式锁(再次狗头保命),下面就说一下我了解到的Redis锁吧。
4.2 redis分布式锁
先说一下我做项目遇到的一个实际的问题
云桌面开发redis一人一台,公用一个数据库,公司用的框架也有问题没有做并发管理,跑定时任务就会出现数据重复执行多次的情况。。
如果多台电脑共享一个数据库,并且这些电脑的应用程序运行在不同的进程或服务器上,那么通常情况下本地锁是无法有效工作的,因为本地锁只在单个进程内有效。所以啊,就考虑redis分布式锁了。
-
引入Redis客户端依赖 在项目的依赖管理中引入Redis客户端的依赖,例如使用Spring Data Redis或者Jedis等。
-
获取锁 在定时任务执行前,尝试获取锁。可以使用Redis的SETNX命令(SET if Not eXists)来实现。如果返回值为1,则表示获取到了锁,可以执行定时任务;如果返回值为0,则表示锁已被其他线程或进程持有,需要等待。
-
执行定时任务 在获取到锁之后,执行定时任务的逻辑。
-
释放锁 定时任务执行完毕后,需要手动释放锁,以便其他线程或进程可以获取到锁。可以使用Redis的DEL命令来删除锁。
下面是一个示例代码,演示如何使用Redis分布式锁解决定时任务多次调用的问题:
@Autowired private RedisTemplate<String, String> redisTemplate; public void scheduledTask() { // 尝试获取锁 boolean lockAcquired = redisTemplate.opsForValue().setIfAbsent("task_lock", "locked", 60, TimeUnit.SECONDS); if (lockAcquired) { try { // 执行定时任务的逻辑 // ... } finally { // 释放锁 redisTemplate.delete("task_lock"); } } else { // 未获取到锁,直接返回 return; } }在上述示例中,我们使用了RedisTemplate来操作Redis。首先,通过
setIfAbsent方法尝试获取锁,设置了一个60秒的锁过期时间。如果返回值为true,表示获取到了锁,执行定时任务的逻辑;如果返回值为false,表示锁已被其他线程或进程持有,直接返回。在定时任务执行完毕后,通过
delete方法手动释放锁。请注意,使用Redis分布式锁时需要考虑锁的过期时间和异常情况下的锁释放,以确保系统的稳定性和正确性。
重点:1、这样的Redis的分布式锁其实在设置锁过期时间之前出现断电问题是会造成程序死锁的,除非保证设置锁(同时设置锁的过期时间)和释放锁的原子性(一般采用Lua脚本,一般怕误删别人的锁的时候会在获取锁的时候设置一个uuid进行判断是不是自己的锁,但是可能在判断完是自己的锁的时候准备释放时,网络波动,没来得及释放,别人抢占了锁,后来就会释放别人的锁)
2、 上面加锁最后的代码就完美了吗?假想这样一个场景,如果过期时间为30S,A线程超过30S还没执行完,但是自动过期了。这时候B线程就会再拿到锁,造成了同时有两个线程持有锁。这个问题可以归结为”续约“问题,即A没执行完时应该过期时间续约,执行完成才能释放锁。怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续约”。其实,解锁出现的删除非自己锁,也属于“续约”问题。 推荐使用Redission提供的分布式锁lock,他会有一个看门狗机制,自动设置缓存过期时间。
ps: synchronized是本地锁,只能锁住当前线程,在分布式服务中,得用分布式锁。
好啦,就想到这么多了兄弟们,写到这里了,学的越多觉得自己越菜,越想学,陷入了一个循环。不多说了,继续学去了。











![[NLP]LLM---大模型指令微调中的“Prompt”](https://img-blog.csdnimg.cn/30633f862e0e4de8ba02fe17f604cd46.png)