Pointpillar 论文解读
主要贡献:
- 这篇文章的主要贡献在于 “Fast Encoder”, 也就是将点云稠密的Pillar(上文提到2847个)**输入给网络,**这才是这篇论文的精髓所在, 这大大提升了识别速度, 论文写可以达到62Hz.
- 仅使用2D卷积层进行端到端学习
- PointPillars uses a novel encoder that learn features on pillars (vertical columns) of the point cloud to predict 3D oriented boxes for objects.PointPillars 使用了一种新颖的编码器,它学习点云支柱(垂直列)上的特征来预测对象的 3D 定向框。
- First, by learning features instead of relying on fixed encoders, PointPillars can leverage the full information represented by the point cloud.首先,通过学习特征而不是依赖固定的编码器,PointPillars可以利用点云表示的全部信息。
- Further, by operating on pillars instead of voxels there is no need to tune the binning of the vertical direction by hand.此外,通过对柱子而不是体素进行操作,不需要手动调整垂直方向的分箱。
- Finally, pillars are highly efficient because all key operations can be formulated as 2D convolutions which are extremely efficient to compute on a GPU.最后,支柱非常高效,因为所有关键操作都可以表述为2D卷积,这在GPU上计算非常高效。
- An additional benefit of learning features is that PointPillars requires no hand-tuning to use different point cloud configurations. For example, it can easily incorporate multiple lidar scans, or even radar point clouds.学习特征的另一个好处是 PointPillars 不需要手动调整来使用不同的点云配置。例如,它可以很容易地合并多个激光雷达扫描,甚至雷达点云。

-
点云和图像的区别?
-
两个主要区别:1)点云是一种稀疏表示,而图像密集,2)点云是 3D,而图像是 2D。
-
因此,来自点云的目标检测不容易适用于标准的图像卷积管道。
-
-
数据处理流程是怎样的,点云怎么生成伪图像?
- lidar-based,数据上只使用激光雷达。HDL-64E Velodyne 64线激光雷达。
- 在最常见的范例中,点云组织在体素中,每个垂直列中的体素集被编码为固定长度的、手工制作的特征编码,形成一个伪图像,可以通过标准的图像检测体系结构进行处理。
- 借鉴 Complex YOLO(原论文使用yolo v2,TODO Complex-YOLO v5实现 数据部分 yolov4)
- Pillar Feature Network Pointcloud to Pseudo-Image 点云到伪图像
- l(x,y,z,r), |P| = B
- (xc, yc,zc)、(xp,yp) 扩充pillar中的点,c表示pillar中所有点的算术平均值的距离。p表示与pillar(x,y)中心的偏移量。
- 增强后的liar数据 l 是9维,l(x ,y ,z ,r ,xc ,yc ,zc ,xp , yp)
- 通过对每个样本的非空柱子数量 § 和每个柱子 (N) 的点数量施加限制来创建大小为 (D, P, N ) 的密集张量
- 如果样本或支柱拥有太多的数据来拟合这个张量,则随机抽样数据。
- 相反,如果样本或支柱的数据太少而无法填充张量,则应用零填充。
- pillars -> MLP -> BatchNorm -> ReLU -> 生成(C, P, N ) 大小的张量 -> 对通道的最大操作以创建大小为 (C, P) 的输出张量 -> 创建大小为 (C, H, W ) 的伪图像
- TODO: ??? 注意,线性层可以表述为张量上的 1x1 卷积,从而产生非常高效的计算。
-
数据增强是怎么操作的(离线,在线)?
- 参考SECOND、PIXOR
- create a lookup table of the ground truth 3D boxes for all classes and the associated point clouds that falls inside these 3D boxes,感觉这里类似FastBev的LUT。猜测是使用预定义内参创建查找表。TODO:具体实现过程是怎样的?
- 为所有类创建ground truth 3D 框的查找表以及落在这些 3D 框内的相关点云
- 然后对于每个样本,我们分别随机选择汽车、行人和骑自行车的人的15,0,8个ground truth样本,并将它们放入当前点云中。
- 接下来,单独增强所有的ground truth。
- 每个框都均匀地从 [−π/20, π/20])和 N (0, 0.25) 独立旋转 (x, y 和 z) 轴以进一步丰富训练集。
- 最后,我们执行两组全局增强,共同应用于点云和所有框。
- 首先,在x轴上应用随机镜像翻转
- 然后进行全局旋转和缩放
- 最后,随机噪声,类似2D平移抖动,x, y, z 随机抖动 N (0, 0.2) 。
- 最小框增强效果更好,引入ground truth采样减轻了对每个框增强的广泛需求。
- During the lidar point decoration step, we perform the VoxelNet [31] decorations plus two additional decorations:xp and yp which are the x and y offset from the pillar x, ycenter. These extra decorations added 0.5 mAP to final detection performance and provided more reproducible experiments.
- (xp, yp)提升了0.005map Point Decorations 这个是干啥的?
-
pointpoillarss 的 one-stage 网络结构是怎样的?
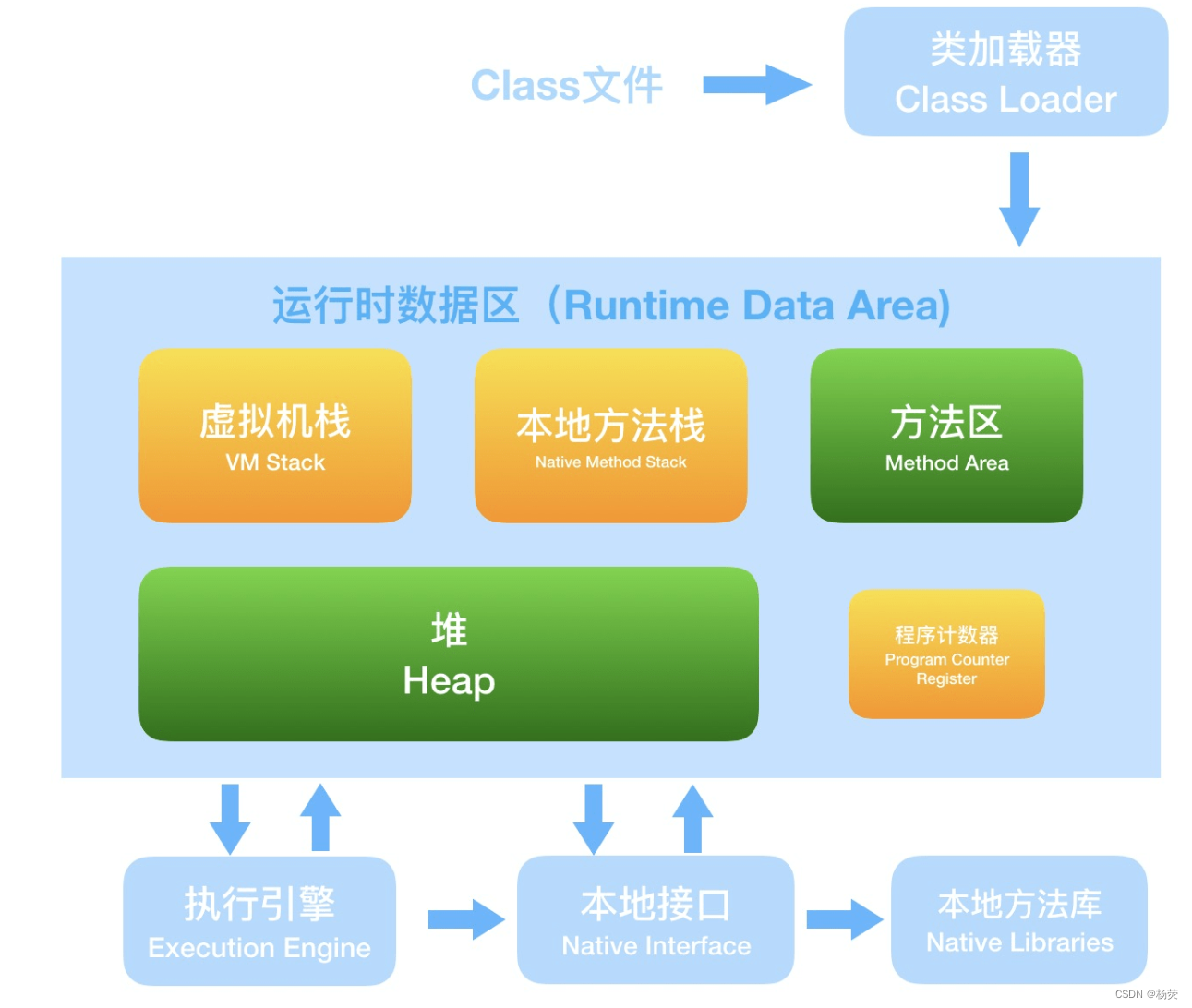
- 三个部分: A Pillar Feature Network, Backbone, and SSD Detection Head.
- 将点云转换为稀疏伪图像的特征编码器网络;
- 二维卷积主干,将伪图像转换为高级表示;pillars怎么提取出dense 2D convolutions ?
- 检测并回归3D框的检测头。
- Backbone主干有两个子网络:

- 一个自上而下的网络,它在相对较小的空间分辨率上产生特征
- 第二个网络执行自上而下上采样和连接特征。自上而下的主干可以用一系列块 Block(S, L, F) 来表征。什么意思?Block具体指什么?
- 一个块有 L 3x3 2D conv 层,具有 F 个输出通道,每个层后跟 BatchNorm 和 ReLU。
- 层内的第一个卷积具有步幅 S/Sin,以确保块在接收到步幅 Sin 的输入blob 后在步幅 S 上运行。
- 块中的所有后续卷积步长为 1。每个自上而下块的最终特征通过上采样和连接进行组合
- 首先,从初始步幅 Sin 对特征进行上采样,Up(Sin, Sout, F) 到最终步幅 Sout(两者都再次测量 wrt。使用具有 F 个最终特征的转置 2D 卷积的原始伪图像)
- 接下来,将 BatchNorm 和 ReLU 应用于上采样的特征。
- 最终输出特征是源自不同步幅的所有特征的串联。
- 下图是BackBone实际用的是RPN.??

- Detection Head
- 与 SSD 类似,我们使用 2D Intersection over Union (IoU) 将先验框与地面ground truth进行匹配。边界框高度和高程不用于匹配;相反,给定一个 2D 匹配,高度和高程成为额外的回归目标。
- 使用SSD目标检测头进行bbox回归,高度z单独回归。
-
loss、optimizer等超参数计算方式,以及使用位置在哪里?
- Network
- 均匀分布随机初始化所有权重
- The encoder network has C = 64 output features.编码器网络有 C = 64 个输出特征。
- The car and pedestrian/cyclist backbones are the same except for the stride of the first block (S = 2 for car, S = 1 for pedestrian/cyclist). 除了第一个块的步幅(汽车的 S = 2,行人/骑自行车者的 S = 1)外,汽车和行人/骑自行车的骨干是相同的。
- Both network consists of three blocks, Block1(S, 4, C), Block2(2S, 6, 2C), and Block3(4S, 6, 4C). 两个网络由三个块组成,Block1(S, 4, C)、Block2(2S, 6, 2C) 和 Block3(4S, 6, 4C)。
- Each block is upsampled by the following upsampling steps: Up1(S, S, 2C), Up2(2S, S, 2C) and Up3(4S, S, 2C).每个块通过以下上采样步骤进行上采样:Up1(S, S, 2C)、Up2(2S, S, 2C) 和 Up3(4S, S, 2C)。
- Then the features of Up1, Up2 and Up3 are concatenated together to create 6C features for the detection head.然后将Up1、Up2和Up3的特征连接在一起,为检测头创建6C特征。
- Loss
- 和SECOND相同。(x, y, z, w, l, h, θ),定位回归残差计算如下:


- 总定位损失为:

- 分类focal loss

- 其中 pa 是锚点的类别概率。我们使用α = 0.25和γ = 2的原始论文设置。
- Ldir = softmax()
- 总loss

- 其中 Npos 是正锚点的数量,βloc = 2,βcls = 1,βdir = 0.2。
- Adam lr=2e-4, 每15 epoch衰减为0.8, 总共160epoch。 batch = 2val, 4test。
- Network
-
实验设置?
- 样本最初分为 7481 个训练和 7518 个测试样本。后分为 3712 个训练样本和 3769 个验证样本
- xy 分辨率:0.16 m,最大支柱数 §:12000,每个支柱的最大点数 (N):100
- 使用与VoxelNet相同的锚点和匹配策略。
- 每个类锚都由一个宽度、长度、高度和 z 中心描述,并在两个方向上应用:0 和 90 度。
- 使用具有以下规则的 2D IoU 将锚点与ground truth匹配。
- 正匹配要么与基本事实框最高,要么高于正匹配阈值,而负匹配低于负阈值。
- 损失中忽略了所有其他锚点。TODO:这段具体是什么意思?怎么实现的?继续看
- axis aligned non maximum suppression (NMS) 轴对齐非最大抑制(NMS) 0.5
- Car.
- x, y, z 范围分别为 [(0, 70.4)、(-40, 40)、(-3, 1)] 米。汽车锚的宽度、长度和高度为 (1.6, 3.9, 1.5) m,z 中心为 -1 m。匹配使用 0.6 和 0.45 的正负阈值。
- Pedestrian & Cyclist.
- x, y, z 范围分别为 [(0, 48)、(-20、20)、(-2.5, 0.5)] 米。
- 行人锚的宽度、长度和高度为 (0.6, 0.8, 1.73) 米,z 中心为 -0.6 米,
- 自行车锚的宽度、长度和高度为 (0.6, 1.76, 1.73) 米,z 中心为 -0.6 米。
- 匹配使用 0.5 和 0.35 的正负阈值。

-
验证时的坐标转换方式和评价指标bbox ,3d,AOS计算方式的具体实现?
- 见最上方计算方式。
-
CUDA下的部署有什么区别?PillarNeXt是否具备可迁移性?
- The main inference steps are as follows.
- First, the point cloud is loaded and filtered based on range and visibility in the images (1.4 ms).
- Then, the points are organized in pillars and decorated (2.7 ms).
- Next, the PointPillar tensor is uploaded to the GPU (2.9 ms), encoded (1.3 ms), scattered to the pseudo-image (0.1 ms), and processed by the backbone and detection heads (7.7 ms).
- Finally NMS is applied on the CPU (0.1 ms) for a total runtime of 16.2 ms.
- Encoding.
- The key design to enable this runtime is the PointPilar encoding.
- For example, at 1.3 ms it is 2 orders of magnitude faster than the VoxelNet encoder (190 ms) [31].
- Recently, SECOND proposed a faster sparse version of the VoxelNet encoder for a total network runtime of 50 ms.
- They did not provide a runtime analysis, but since the rest of their architecture is similar to ours, it suggests that the encoder is still significantly slower; in their open source implementation1 the encoder requires 48 ms.
- The key design to enable this runtime is the PointPilar encoding.
- Slimmer Design.
- 单个 PointNet,输出64维,减少4.5ms
- 上采样特征输出减半到128,减少3.9ms
- 可以通过改变空间分箱的大小来实现速度和准确性之间的权衡。较小的柱子允许更精细的定位并导致更多的特征,而较大的柱子更快,因为更少的非空柱子(加速编码器)和更小的伪图像(加速 CNN 主干)。
- pillar尺寸{0.122,0.162,0.22,0.242,0.282}m2
- 最大柱的数量随分辨率而变化,分别设置为16000、12000、12000、8000、8000。
- The main inference steps are as follows.
-
每个网络层的参数怎么计算?