当想下载清华大学鹏城实验室10m土地利用数据的时候,发现他们的下载方式很奇怪,只能一页页的点名称全选 ,然后批量下载,再一个个的加入浏览器下载,当一次下载过多就回卡顿和下载失败,所以就有了想用python进行下载的想法。
1 获取headers
F12打开控制台,看Network界面,然后随机下载一个文件
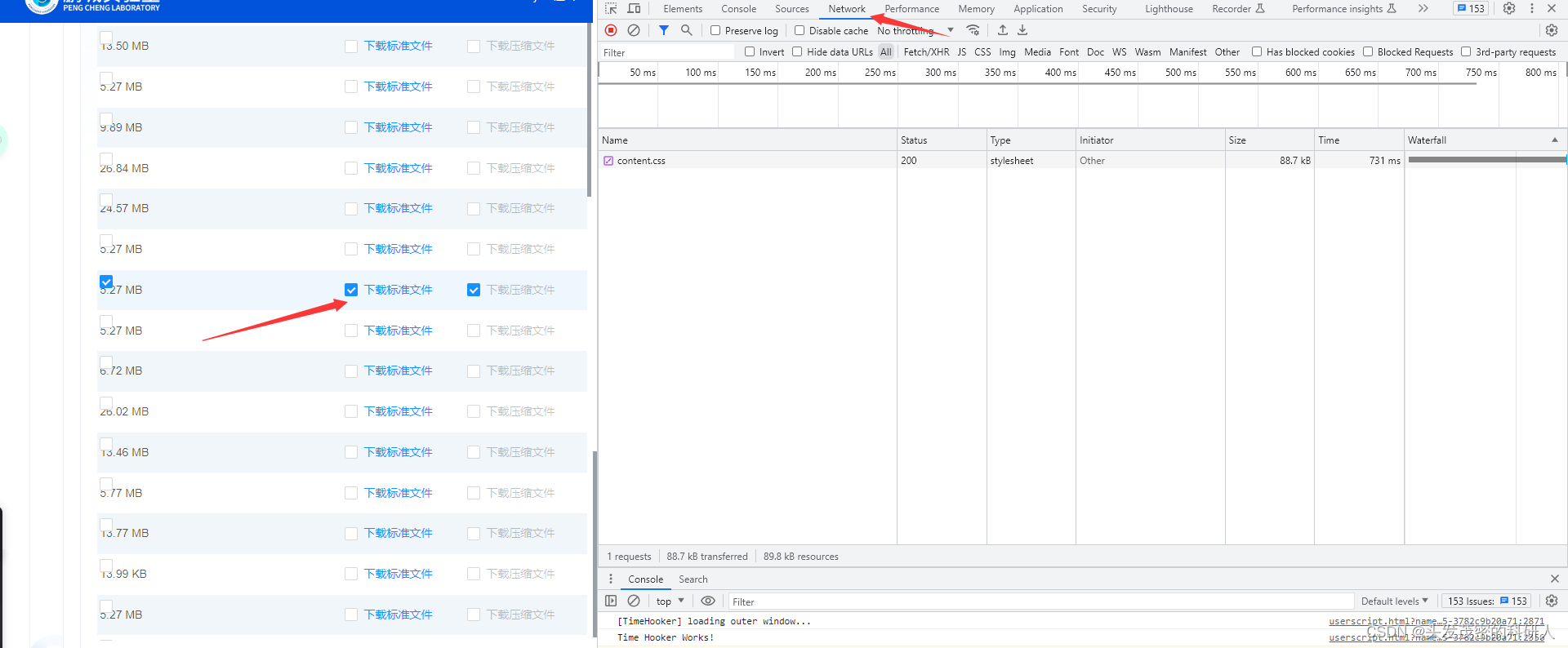
点击下载后,可以看到下载文件名,就可以得到自己的headers,这一步主要是为了获得“Authorization”进行身份认证
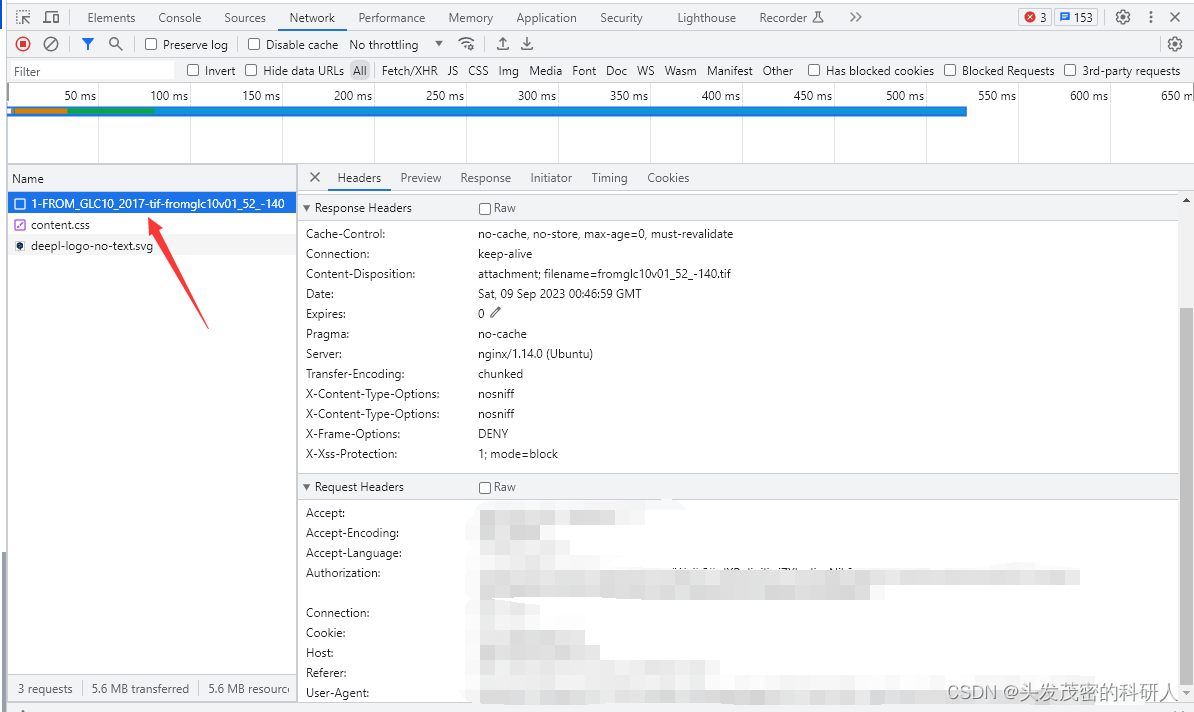
然后返回网页,查看网页源代码,发现文件的命名方式为“1-FROM_GLC10_2017-tif-fromglc10v01_”+经纬度,那我们就以“1-FROM_GLC10_2017-tif-fromglc10v01_”在源代码中搜索,可以获取所有的文件名

2 下载代码
代码只能下载有命名规律的文件,无规律的文件请自行排查下载
from http import cookiejar
from urllib import request
import os
import re
import numpy as np
from subprocess import call
from multiprocessing import Pool
#填入自己获取的headers
headers={"Accept":"",
"Authorization":"",
"Referer":"",
"User-Agent":""
}
#返回从网页源码中获取的文件名
def filename():
password_manager = request.HTTPPasswordMgrWithDefaultRealm()
password_manager.add_password(None, "http://data.starcloud.pcl.ac.cn", '账号', '密码')#自行修改
cookie_jar = cookiejar.CookieJar()
opener = request.build_opener(request.HTTPBasicAuthHandler(password_manager),request.HTTPCookieProcessor(cookie_jar))
request.install_opener(opener)
url="http://data.starcloud.pcl.ac.cn/zh/resource/1"
myrequest = request.Request(url,headers=headers)
response = request.urlopen(myrequest)
html=response.read()
names=re.findall(r'1-FROM_GLC10_2017-tif-fromglc10v01.*?"', html.decode('utf-8'))
names=np.array(names)
return names
#下载链接的构成为download_url+文件名
def download(name):
download_url="http://data.starcloud.pcl.ac.cn/api/resourceFile/download/"
name=name.split('"')[0]
fileurl=download_url+name
request1 = request.Request(fileurl,headers=headers)
response1 = request.urlopen(request1)
#自行修改下载文件夹
filepath=os.path.join("E:/Download/2017_10m",fileurl.split("tif-")[-1]+".tif")
if os.path.exists(filepath):#判断文件是否存在
print(name + "exist")
else:
f = open(filepath,'wb')
f.write(response1.read())
f.close()
print(name+"下载完成!")
def main():
names=filename()
po=Pool(5)
po.map_async(download,names)
po.close()
po.join()
if __name__ == '__main__':
files = os.listdir("E:/Download/2017_10m") # 获取当前文件夹下的所有文件
file_num = len(filename())
while len(files)!=file_num: #python可能未下载完就中断,加个文件数判定
print("未完全下载")
main()
files = os.listdir("E:/Download/2017_10m")