(一)LLM专栏
大模型相关技术原理以及实战经验:liguodongiot/llm-action
1 ColossalAI

(1)参考资料:700 亿参数 LLaMA2 训练加速 195%,基础大模型最佳实践再升级
(2)开源地址:https://github.com/hpcaitech/ColossalAI
(3)描述:
- Colossal-AI提供开箱即用的 8 到 512 卡 LLaMA2 训练、微调、推理方案
- 对 700 亿参数训练加速 195%,并提供一站式云平台解决方案,极大降低大模型开发和落地应用成本。
(二)文生图
1 Stable Diffusion

(1)参考资料:Stable Diffusion导论/安装教程
万字保姆级教程!Stable Diffusion完整入门指南
(2)开源地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
(3)描述:
Stable Diffusion是2022年发布的深度学习文本到图像生成模型,它是一种潜在扩散模型,它由创业公司Stability AI与多个学术研究者和非营利组织合作开发。目前的SD的源代码和模型都已经开源,在Github上由AUTOMATIC1111维护了一个完整的项目,正在由全世界的开发者共同维护。由于完整版对网络有一些众所周知的需求,国内有多位开发者维护着一些不同版本的封装包。开源社区为SD的普及做出了难以磨灭的贡献。
2 InvokeAI

(1)参考资料:集多个AI绘画开源模型于一体的工作台#invokeAI使用测评
(2)开源地址:https://github.com/invoke-ai/InvokeAI
(3)描述:
invokeAI是一个在网页上使用的AI绘画生成界面,通俗点讲,它其实是嵌套在生成模型上的一个网页外观。不同的生成模型例如stable diffusion和Dream booth等,通过导入invokeAI内,可以将不同模型的界面替换成invokeAI的界面,从而统一工作环境。
3 Fooocus
(1)参考资料:重磅开源工具Fooocus!让SD跟Midjourney一样简单易用!
(2)开源地址:https://github.com/lllyasviel/Fooocus
(3)描述:
基于SDXL模型在SDwebui的基础上进行了改进,提供了一系列强大功能,并提供直观易懂的界面。这款开源免费软件自动化了许多内部优化和质量改进,无需用户处理繁琐的技术参数,使得用户可以全情投入到绘图交互中。
(4)使用教程:
- 本地部署 Fooocus 低显存玩转SDXL
4 HCP-Diffusion-webui
(1)参考资料:中山大学开源Diffusion模型统一代码框架,推动AIGC规模化应用
(2)开源地址:https://github.com/7eu7d7/HCP-Diffusion-webui
(3)描述:
- 统一架构:搭建 Diffusion 系列模型统一代码框架
- 算子插件:支持数据、训练、推理、性能优化等算子算法,如 deepspeed, colossal-AI 和 offload 等加速优化
- 一键配置:Diffusion 系列模型可通过高灵活度地修改配置文件即可完成模型实现
- 一键训练:提供 Web UI,一键训练、推理
(三)文生视频
文生视频: 任务、挑战及现状
1 Gen-2

(1)参考资料:Gen2:一个可以用文本、图像或视频片段生成新视频的多模态AI系统
(2)开源地址:/
(3)描述:
Gen2支持多种模式,让你可以根据不同的需求和创意生成不同风格的视频。比如:
- 文本到视频:只用文本提示就能生成任何风格的视频。
- 文本+图像到视频:用一张图像和一段文本提示生成视频。
- 图像到视频:只用一张图像就能生成视频(变化模式)。
- 风格化:将任何图像或文本提示的风格转移到你的视频上。
- 故事板:将草图变成完全风格化和动画化的渲染。
- 遮罩:在你的视频中隔离主题,并用简单的文本提示修改它们。
- 渲染:将未纹理的渲染变成逼真的输出,通过应用一个输入图像或文本提示。
- 定制:通过定制模型来释放Gen2的全部力量,获得更高保真度的结果。
2 Text2Video-Zero
(1)参考资料:【AIGC-AI视频生成系列-文章1】Text2Video-Zero
(2)开源地址:https://github.com/Picsart-AI-Research/Text2Video-Zero
(3)描述:
- zero-shot 实现文本-视频生成扩散模型,仅仅使用现有的扩散模型如Stable-Diffusion。
- 丰富了基于生成的图像帧的latent 特征空间进行运动动态编码,并使用跨帧注意力来重新编程帧级别的Self-Attention,以保持生成场景和背景的一致性。
- 该方法并不局限于文本到视频的合成,而是也适用于其他任务,例如条件和内容专用的视频生成,以及pix2pix,文本引导的视频编辑。
体验Demo:ModelScope Text To Video Synthesis
(四)文生音乐
举世无双语音合成系统 VITS 发展历程
1 Retrieval-based-Voice-Conversion
(1)参考资料:
(2)开源地址:https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
(3)描述:
- 一个基于VITS的简单易用的语音转换(变声器)框架
- 一种利用专门的神经网络将一个人的声音转换为另一个人的声音的方法。该方法依赖于先进的VITS模型,它是一种用于将文本转换为语音的尖端系统。即使在数据和计算能力有限的情况下,Retrieval-based Voice Conversion也能够创建逼真且富有表现力的语音转换。
2 Grad-SVC
(1)参考资料:https://www.bilibili.com/video/BV1pu4y1C7YC/
(2)开源地址:https://github.com/PlayVoice/Grad-SVC
(3)描述:
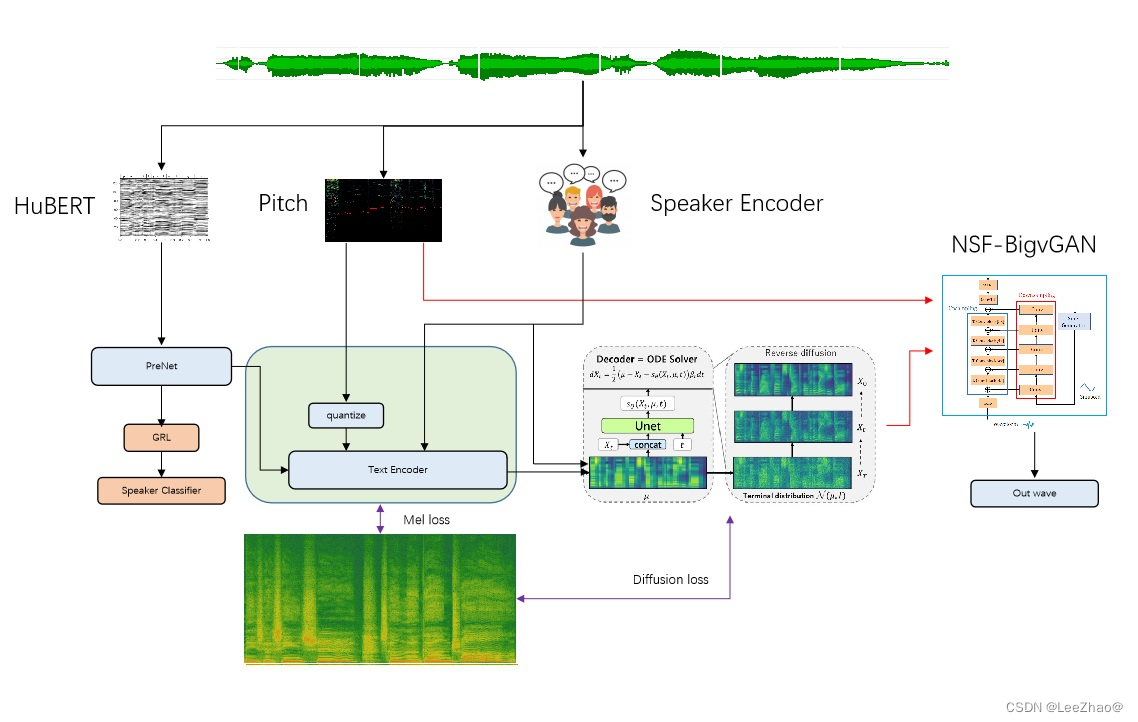
3 dc-comix-tts
(1)参考资料:/
(2)开源地址:https://github.com/lakahaga/dc-comix-tts
(3)描述:
- 端到端的离散代码表达TTS与Mixer的协作