0.引言
在互联网行业,软件工程师面对的产品需求大都是以具象的现实世界事物概念来描述的,遵循的是人类世界的自然语言,而软件世界里通行的则是机器语言,两者间跨度太大,需要一座桥梁来联通,抽象建模便是打造这座桥梁的关键。基于抽象建模,不断地去粗取精,从现实世界到业务模型,从业务模型到设计模型,最终完成现实世界到软件世界的转换。
事实上,服务端开发工程师在大部分工作时间里并不是在写代码,而是在抽象建模。工程师需将业务需求抽象成领域模型、模块、服务和系统,面向对象开发时需抽象出类和对象,面向过程开发时抽象出方法和函数。
某种意义上,软件的本质就是抽象,建模则是系统地实施抽象的过程。作为一种将事物形象化的有效手段,建模可将现实世界中的事物及事物之间的关系准确地表达出来。
1.抽象思维
抽象在中文里可作为动词,也可作为名词。作为动词的抽象是指一种行为,这种行为的结果,就是作为名词的抽象。百度百科对抽象的定义为:人们在实践的基础上,对于丰富的感性材料通过去粗取精、去伪存真、由此及彼、由表及里的加工制作,形成概念、判断、推理等思维形式,以反映事物的本质和规律的方法。
事实上,抽象作为一种高级思维形式,与日常生活关系密切,例如数字,人类初期并没有数字这一概念,原始人类或许能够理解三个苹果和三只鸭子,但不存在数字 “三” 这个概念,在他们的意识里,三个苹果和三只鸭子是没有任何联系的。当人类文明发展到一定阶段,发现了这两者之间存在的一种共性,即 “三”,于是就逐渐形成了数字这个概念。此后,人们就开始用数字对各类事物进行计数。
2.软件世界中的抽象
软件的本质就是抽象,在软件世界里,抽象无处不在,典型如命名抽象、分层抽象、原则抽象。
2.1 命名抽象
作为一名软件工程师,最令你头疼的事情是什么呢?是写代码,看别人的代码,需求评审,还是修 Bug?Quora 和 Ubuntu Forum 曾经针对这个问题进行过广泛地调研,结果显示, 最令软件工程师头疼的事情是命名,没错,就是命名!应用名、包名、类名、方法名、字段名、变量名等等。如果你不曾为命名苦思冥想、反复权衡,也许你还不能算是真正的软件工程师。
关于命名,Stack Overflow 的创始人 Joel Spolsky 曾言:“起一个好名字很难,但这是理所应当的,因为一个好名字需要把要义浓缩在一到两个词(Creating good names is hard, but it should be hard, because a great name captures essential meaning in just one or two words)。” 其实,这个浓缩的过程便是抽象的过程。
很多时候,业务代码的复杂,并非业务本身复杂,而是人为因素造成的,命名混乱就是最常见的因素。虽然不合理的命名并不影响需求的实现,但却加重了认知负荷,随着时间的推移,理解代码的成本会越来越高。同时,命名不合理本质上是抽象不合理,往往影响可复用性。
2.2 分层抽象
在软件开发中,经常会用到各种分层架构,如经典的三层模型(展现层、业务逻辑层、数据层)和 MVC (Model、View、Controller)模型。如图 1 所示为阿里广泛采用四层模型,它包括 View、Service、Manager、DAO 四部分,通过分层将数据访问、通用处理、业务逻辑、终端展示四者解耦,各司其职。View 与用户交互;Service 依赖多个 Manager 和 DAO 实现具体的业务逻辑;Manager 负责通用业务逻辑处理和封装外部服务,它是对 Service 层通用能力的下沉,注重复用性;DAO 负责与底层数据库进行数据交互。分层架构的核心其实就是抽象的分层,每一层的抽象只需要而且只能关注本层相关的信息,从而简化整个系统的设计。

2.3 原则抽象
在面向对象设计和面向对象编程领域,有一个著名的 SOLID(单一功能、开闭原则、里氏替换、接口隔离以及依赖反转)原则,它是由 Robert Martin 在 21 世纪早期提出。在软件设计和开发中,正确地遵循这些设计原则,有助于提升系统的可维护性和可扩展性。
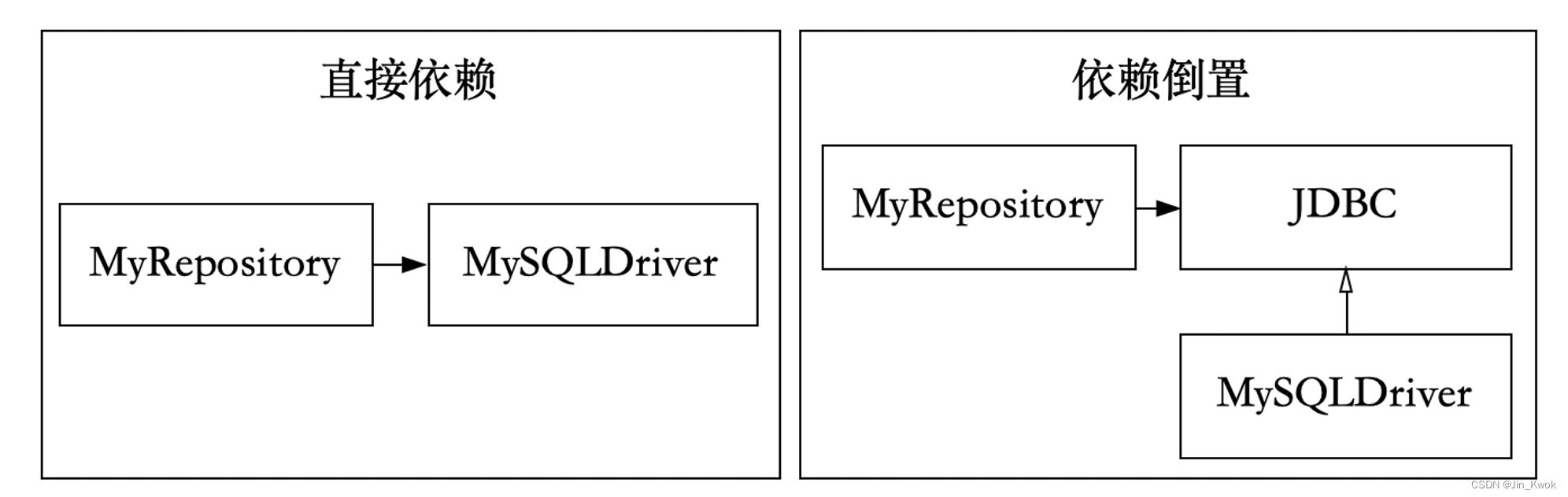
以依赖倒置原则(Dependency Inversion Principle, DIP)为例,其含义为:抽象不应该依赖于细节,细节应当依赖于抽象。换言之,要针对抽象(接口)编程,而不是针对实现细节编程。这样做有什么好处呢?一个软件系统通常可划分为多个层次,上层调用下层,上层依赖于下层,如果上层依赖的是下层的具体实现,那么,当下层实现细节发生变化时,上层往往也需要同步修改,这就加重了不同层之间的耦合度。但是,如果上层依赖的只是下层的抽象而不是细节,就完全不同了,抽象变化的频率极低,让上层依赖于抽象,实现细节也依赖于抽象,即使实现细节不断变动,只要抽象不变,上层就不需要变化,如此一来大大降低了耦合度。
Java 的 JDBC 是依赖倒置原则的一个典型应用场景 。如图 2 所示,如果没有 JDBC 这一层抽象,软件系统将直接依赖具体的数据库(如 MySQL、Oracle 等),与实现细节耦合,当需要切换到另一种数据库时,就需要修改大量代码来适应细节的变化。若系统依赖的是抽象的 JDBC 接口,那么通过调用 JDBC 即可完成数据库操作,而无须再关注 JDBC 背后的数据库,因为所有关系型数据库的连接库都实现了 JDBC 接口,当需要换数据库时,作为抽象的 JDBC 并不会变化,系统也就无需感知变化。
3. 经典抽象案例
如图 3 所示,有这样一个关于 “霸屏” 动效的需求,产品文档(Product Requirement Document,PRD)摘要描述如下:
- ZFB 会员与 KA(Key Account) 商家合作,升级会员等级特权,因此在会员频道首页通过 “霸屏” 动效提示用户并引导其进入新等级特权页面;
- 若用户点击 “看我等级特权” 按钮,则自动跳转到新等级特权页面,引导目标达成,“霸屏” 动效不再出现,以免打扰用户;
- 若用户未点击 “看我等级特权” 按钮,“霸屏” 动效展示 3 秒自动收起。由于引导目标未达成,需继续引导,同时为了防止过度打扰用户,“霸屏” 动效每月最多出现 N 次,N 需支持灵活配置。

我们来简单分析一下这个需求,核心业务目标在于引导用户进入新等级特权页面,同时兼顾用户体验,避免 “霸屏” 动效过度打扰用户。对于服务端而言,需要实现 “疲劳度” 控制逻辑,即:
- 若用户点击按钮:持久化用户点击记录,当用户再次访问该页面时,通过查询点击记录就可以判断该用户是否曾点击按钮。若记录存在,则告知前端不要弹出 “霸屏” 动效。
- 若用户未点击按钮:持久化 “霸屏” 动效对用户的曝光记录,当用户再次访问该页面时,通过查询曝光记录就可以判断该用户是否满足展示 “霸屏” 动效的条件。若当月曝光次数少于 N,则告知前端可弹出 “霸屏” 动效。
3.1 方案一:战术抽象,多快好省,跑步前进
基于上面的需求分析,稍有经验的服务端开发工程师立马就能想出解决方案,如表 1 所示,为每个用户落一条记录即可实现需求。

从实现需求的角度来看,上述设计完全可以满足业务当前的需要。如图 4 所示,曝光、点击记录模型几乎完全是由产品文档(PRD)翻译而来,乍看之下,十分的 “信达雅”,简直不要太完美。
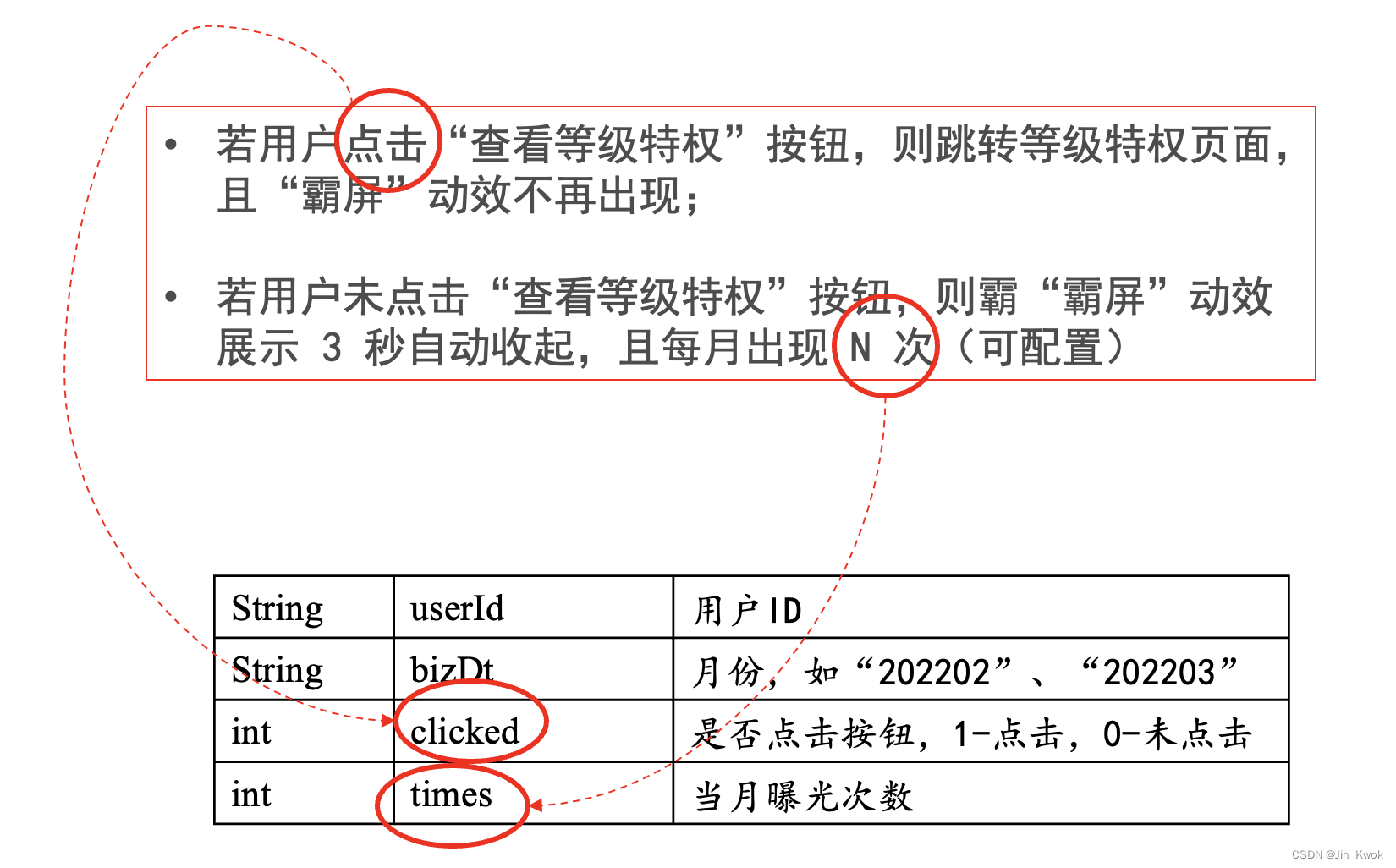
我们再来仔细分析一下,上面的模型真的好么???显然很一般!!!该模型局限于实现当前业务需求,几乎没有进行抽象建模,因此,建立的模型不能准确地刻画业务的本质。这样的模型可扩展性极差,基本就是一锤子买卖。
在笔者看来,直接 “翻译” PRD 是一种战术编程,或者说战术抽象。John Ousterhout 在《A Philosophy of Software Design》一书中提到:几乎每个软件开发组织都至少有一个将战术编程发挥到极致的开发人员,可称之为战术龙卷风(Almost every software development organization has at least one developer who takes tactical programming to the extreme: a tactical tornado)。战术龙卷风有以下几个特点。
- 快速。他们常以腐化系统为代价换取当前最快速的解决方案,几乎没有人能比他们更快地完成任务。
- 高产。他们是高产的程序员,代码量极高,堪称 “卷王”。
- 坑多。他们往往倾向于简单地进行功能堆积,忽视抽象建模,将成本放到未来,由后来人买单。
从战术龙卷风的特点可以看出,战术编程(抽象)是缺乏或者说忽视抽象建模和系统设计的,聚焦于快速交付,系统能用就行,注重短期收益而非长期价值。当然,这并非完全是软件工程师的问题,不合理的评价体系和行业特点亦难辞其咎。
3.2 方案二:深入分析,透过表象,探寻本质
方案一中 “草率” 地进行抽象建模是不可取的,于开发者自身而言,是一种苟且,无能力提升;于软件项目而言,随意堆积一次性代码,将成本放到未来,是一种不负责任的行为。
如果我们深入分析业务,我们会发现,其实有更好的方案,而且并不复杂。如图 5 所示:首先,忽略 PRD 描述中那些无关紧要的细节,可以发现,PRD 涉及两种场景;然后,针对两种场景,进一步抽取共同特征——场景 S : N 次/周期 Q;最后,洞见共同特征背后的本质——周期维度记账。
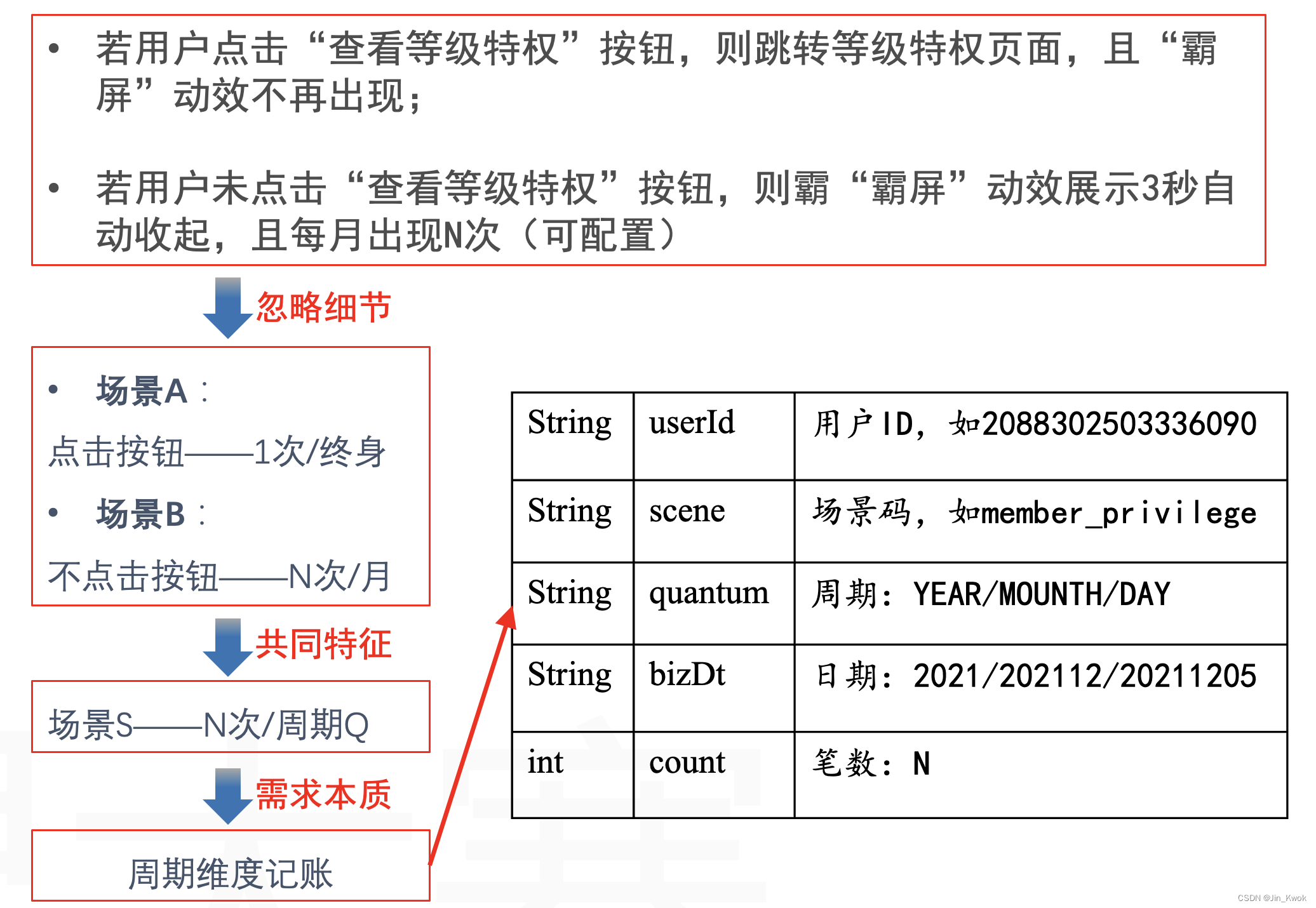
基于【周期维度记账】这一需求本质,我们建立的模型不仅可以满足当前业务的需要:
- 用户点击按钮:DB 里面落一条记录,其中 scene 可设为 “CLICK”。当用户再次进入对应页面时,先根据 userId 和 scene 查询记录,若存在,则说明用户已经点击过按钮,告知前端无需展示“霸屏”动效。
- 用户未点击按钮:DB 里面落一条记录,其中 scene 可设为 “EXPOSE”。当用户再次进入对应页面时,先根据 userId 和 scene(CLICK)查询、判断用户是否点击过按钮,如果没有点击,则根据 userId 和 scene(EXPOSE)查询、判断并更新曝光次数 count。
与此同时,基于【周期维度记账】这一需求本质,我们建立的模型具有更好的可复用性、可扩展性。举两个例子:
- 多周期:基于字段 quantum 和 bizDt,可以支持终身、年、月、周、日等时间维度记账。满足不同业务场景的需要。
- 多场景:基于字段 scene,可以实现不同业务场景的数据隔离,同时支持多个场景,以及数据分析等附加需求。
4. 抽象并非一蹴而就!需要不断假设、验证、完善
如图 6 所示,在人类文明早期,人们基于直观地观测,认为地球是宇宙的中心,因此抽象出了 “地心说” 模型。随着时间的推移和观测手段的进步,人们观察到的天文现象越来越多,逐渐意识到 “地心说” 模型与观测结果存在矛盾,于是,人们开始对 “地心说” 模型进行修正(像极了程序员重构模型),典型如 “本轮-均轮” 模型。
然而,随着更多的天文现象被发现,在 “地心说” 模型的大框架下,无论如何修正都无法自圆其说。在 “地心说” 模型统治人类 “天文世界观” 很长一段时间后,勇敢的先行者推翻了 “地心说” 模型,并提出了在当时看来离经叛道的 “日心说” 模型。

从 “地心说” 模型被提出,到 “日心说” 模型被广泛接受,跨越了 1400 多年的时间。这一史实表明,人们对事物本质的探索是一个过程,而非一蹴而就!!!对于服务端开发而言,我们对需求的认知也是如此,初见之下,我们往往很难直接洞见其本质,而需要不断假设、反复推演,最终才能抽象出较好的模型。
你可能会问——抽象建模如此麻烦,开发时间往往又不充裕,何必苦苦探寻所谓的本质呢?能用不就行了么?
如果你确有上述疑问,不妨换个角度,想一下 “核心竞争力” 的内涵。很多时候,我们并不缺乏解决问题的办法、能力和资源,而缺乏的是对问题的识别、理解、抽象。当一个问题被抽象为足以刻画业务本质的模型,并拆解到软件项目维度的时候,面对确定的任务、清晰的目标,可以解决问题的人就非常多了。
某种程度上,解决问题的能力是重要的基础,但若仅仅是解决问题还远远不足以称为核心竞争力。对于服务端开发工程师而言,抽象建模能力比编程落地能力更重要,因为编程解决问题只是一种普通技能而已,而对具象事物(如业务需求)的高度抽象,探索事物的本质,需要我们从新的角度审视旧的问题,需要有创造性的想象力,这才是真正的难点,当然也是核心竞争力所在。
5. AI 时代,后端开发何去何从?
2022 年 11 月 30 日,OpenAI 发布了一款名为 ChatGPT 的聊天机器人程序,旋即引爆网络,在全球范围内引起巨大反响。紧随其后,各种大语言模型如雨后春笋不断出现。国外如 Google 的 Bard、Anthropic 的 Claude,国内如百度文心一言、阿里通义千问、讯飞星火认知大模型、昆仑万维天工大模型等。
相较于之前的模型,以 ChatGPT 为代表的大语言模型在代码生成、代码解释能力方面有了质的飞跃,很多程序员已经开始借助大语言模型编写、优化代码。AI 时代必将对人类社会的生产、生活带来深刻的变革,简单、重复的任务被 AI 取代是不可避免的。新的时代,程序员需要持续学习,不断夯实自身的能力护城河。
以服务端开发岗位为例,除了抽象建模能力,领域知识是最基础却又最重要的能力,但是,只有当领域知识形成体系时,才可以称之为真正的核心竞争力。那么,如何才能使自己的领域知识体系化呢?
想象一下,为什么你对家所在的小区周边特别了解,随便把你放在一个角落,你都能慢慢摸索出来?究其原因,是因为你脑海中已经形成了小区周边的整体大图,并对关键节点了然于胸。如果把你放到陌生的小区,你可能就懵了,关键节点、整体大图都没有,胡乱摸索,即便你把摸索路上所见到的每一个下水道井盖的情况都搞清楚了,也没什么意义,再过几条街你就忘了。
回到上面抛出的问题,高效学习、知识体系化的关键在于:构建宏观层面的整体大图,并深入理解关键知识点。这些关键点就是这个领域的骨架、支点。缺少骨架和支点自然难以体系化,缺了宏观大图则容易误入歧途。
6. 知识体系化指南

《服务端开发:技术、方法与实用解决方案》 一书是业界首部基于大厂实践体系化、全景式解读服务端开发的书籍。内容取材自阿里和蚂蚁集团的精品内训课程,由资深服务端技术专家、技术讲师、阿里第二届技术讲师课程大赛年度冠军得主、CSDN 博客专家撰写。该书理论与实践结合,全景式、体系化地阐述了服务端开发,该书共 14 章,内容从逻辑上可以分为两大部分:
-
第一部分为第 1~6 章,主题是技术和方法。首先概述服务端开发的职责、技术栈、核心流程和进阶路径,然后从需求分析、抽象建模、系统设计、数据设计、非功能性设计 5 个方面逐一展开,结合案例深入解读服务端开发的实操方法和重难点,为读者清晰呈现服务端开发的全景图。通过学习本篇内容,读者可以快速、体系化地掌握服务端开发的相关知识和方法。
-
第二部分为第 7~14 章,主题是解决方案。针对高并发、高可用、高性能、缓存、幂等、数据一致性等服务端开发的典型问题,结合业务场景进行系统性分析并给出解决方案。此外,就接口设计、日志打印、异常处理、代码编写、代码注释等实施细节给出行业案例和规范。本篇内容如同一本服务端开发问题手册,当读者在实践中遇到问题时,可以从中查找解决方案。
适合哪些读者?
这本书体系化地解读了服务端开发的方方面面,特别提供了针对高并发、高可用、高性能、数据一致性等重难点的行业经典解决方案,极具价值。
- IT 从业人员:服务端开发工程师、客户端开发工程师、产品经理、测试开发工程师等。
- 高校学生:计算机、软件、自动化、电气、通信等专业有志于进入 IT 行业的在校学生。
- 求职面试:不同于一般的“面试宝典”仅仅侧重对某种语言、框架、中间件等进行解读,本书立足于服务端开发的全局视角,体系化解读服务端开发的大厂规范流程和重难点,面试必备。
目前,本书已经在京东、淘宝、当当、拼多多等平台发售。在对应 APP 搜索关键词 “服务端开发”、“服务端开发技术”,即可搜索到该书。
7 引用
本文由原作者授权发表,原文发表于公众号 “互联网技术人进阶之路”,特此声明。










![[uni-app] 海报图片分享方案 -canvas绘制](https://img-blog.csdnimg.cn/71f0bc27fe5f47ad9bf9aca5cdf0b053.png)