提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
- 前言
- 一、Requests是什么?
- 二、使用步骤
- 1.引入库
- 2.创建一个Faker对象:
- 3.设置要访问的目标网站的URL:
- 4.定义HTTP请求头部:
- 6.发送HTTP GET请求:
- 7.获取网站的响应内容:
- 完整代码:
- 总结
前言
放假了,下午没什么课我就没去,我还要英语补考啊啊啊啊。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Requests是什么?
Requests是一个Python HTTP库,在Apache License 2.0 許可证下发行。这个档案的目标是使HTTP請求更簡單,更人性化。Requests是沒有預設包含在Python內的最流行的Python庫之一,因此有人建議將其預設隨Python一起發布。
–wiki百科
二、使用步骤
1.引入库
代码如下(示例):
import requests
2.创建一个Faker对象:
代码如下(示例):
fake = Faker()
使用Faker库创建一个名为fake的对象,以便后续生成随机的用户代理头部。
3.设置要访问的目标网站的URL:
代码如下(示例):
url = "http://www.abkj.org"
将变量url设置为要访问的网站的URL。在这个示例中,URL是"http://www.abkj.org"。
4.定义HTTP请求头部:
"User-Agent": fake.user_agent()在头部中设置了一个"User-Agent"字段,其值通过调用fake.user_agent()来生成一个随机的用户代理字符串。用户代理字符串通常包含了关于浏览器和操作系统的信息,模拟浏览器的行为是为了使网站认为请求是由真实浏览器发出的。
headers字典用于存储HTTP请求头部的信息。
6.发送HTTP GET请求:
response = requests.get(url, headers=headers) 使用requests库发送一个HTTP GET请求到指定的URL(在这里是"http://www.abkj.org"),并附带上述定义的HTTP头部信息。
7.获取网站的响应内容:
print(response.text)使用response.text属性来获取网站的响应内容,并将其打印到控制台。这行代码会将网站的HTML内容输出到屏幕上。
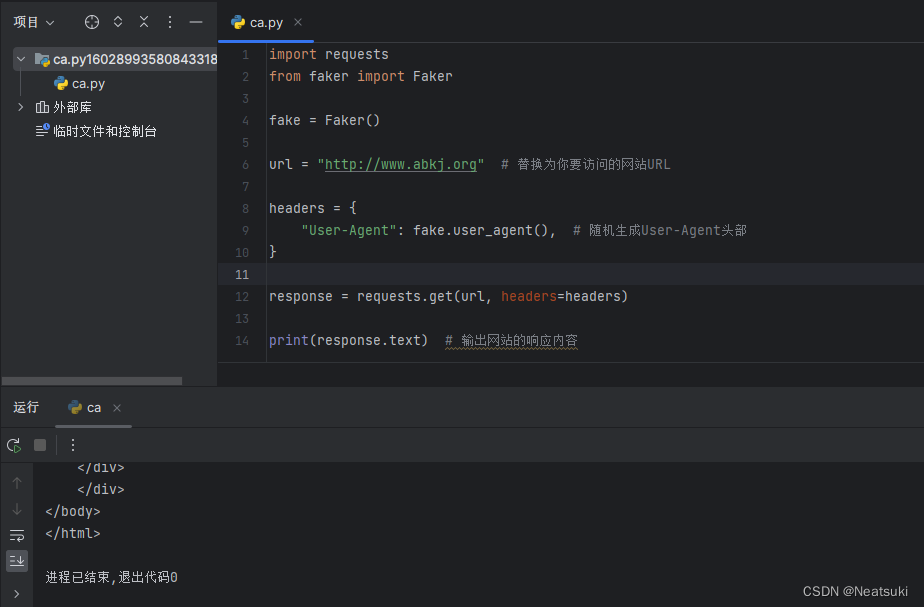
完整代码:
import requests
from faker import Faker
fake = Faker()
url = "http://www.abkj.org" # 替换为你要访问的网站URL
headers = {
"User-Agent": fake.user_agent(), # 随机生成User-Agent头部
}
response = requests.get(url, headers=headers)
print(response.text) # 输出网站的响应内容
总结
以上就是今天要讲的内容,本文仅仅简单介绍了requests的使用,瑞思拜!!






![[uni-app] 海报图片分享方案 -canvas绘制](https://img-blog.csdnimg.cn/71f0bc27fe5f47ad9bf9aca5cdf0b053.png)