目录
一、分区概念
二、表分区的优点
三、分区策略
一、分区概念
随着时间的发展,一个表的数据会越来越多,当数据量增大的时候我们一般采取建立索引优化索引的方式提高查询速度,但是数据量再次增大即使是索引也无法提高速度,这时候我们可以选择表分区,当然也可以通过分表、分库的方式,但是分表、分库会导致程序上的更改,代价比较大,当然也有其他的优化方式,本文不做讨论,本文主要来说一下分区。
分区顾名思义就是将一个表或索引划分不同的区域,将非常大的表或索引分解成更小、 更易于管理的叫做分区的片断。不只是表可以分区,索引也可以分区。每个分区是一个独立的对象,具有其自己的名称和存储特征(可选的)。分区表采取分而治之的方式,降低每次查询的数据量,从而加快数据库的查询速度。
打个比方,假设一个人事经理有一只大箱子,其中包含雇员的文件夹。每个文件夹列出了雇员的雇用日期。现实中经常会查询在一个特定月份雇用的雇员。要满足这些要求的一种方法是,对雇员的雇佣日期创建索引,它指向分散在箱子中的这些文件夹的位置。相比之下,分区策略将使用许多更小的箱子,每个小箱子仅包括在一个给定月份内雇用的雇员的文件夹。
使用更小的箱子具有几个优势。当要检索在 6 月份雇用的员工的文件夹时,人事经理只需检索 6 月份的箱子。此外,如果任何小箱子损坏,则并不影响其他小箱子保持可用。办公室搬家也会变得更容易,因为他不必移动一个很大的箱子,而只需移动几个小箱子。
二、分区的优点
1、数据安全
分区表中的某个分区不可用并不意味着整个对象不可用。当部分分区不可用时,查询优化器自动从查询计划中删除未引用的分区,而查询不会受影响。
2、维护方便
已分区对象具有多个分片,可以将其作为一个整体来管理,也可以单独管理各个分片。如重建索引或表,可以一次只移动一个表分区。DDL 语句也可以单独操作某个分区,而不是整个表或索引。并且在删除数据的时候可以直接删除一个分区。
3、并行操作
在一些 OLTP 系统中,分区可以减少对共享资源的争用。例如,DML 被分散到很多段,而不只是一个段。
4、数据查询
数据被存储到多个文件上,每次可以查询更好的数据块获取需要的数据,减少了I/O负载,查询速度提高。
三、分区策略
1、分区键
了解分区策略之前,先了解一下什么是分区键,分区键是一个列或列集,以确定分区表中的每一行应该所在的分区。有了分区键,数据库在拿到每行数据时,才能准确无误的将数据分配的某个分区,这个键必须非常明确,不能模凌两可。
2、分区策略
Oracle 分区提供了几个分区策略,来控制数据库如何将数据放置到分区。基本策略有范围分区、 列表分区、和哈希分区等。
1)范围分区
在范围分区中,数据库基于分区键的值范围将行映射到各个分区。范围分区是最常见的分区类型,通常与日期一起使用。下面是个销售表,需要创建为分区表time_range_sales,分区键为time_id。

CREATE TABLE time_range_sales(
prod_id NUMBER(6),
cust_id NUMBER,
time_id DATE,
channel_id CHAR(1),
promo_id NUMBER(6),
quantity_sold NUMBER(3),
amount_sold NUMBER(10, 2)
);
PARTITION BY RANGE (time_id) (
PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('01-JAN-1999', 'DD-MON-YYYY')),
PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('01-JAN-2000', 'DD-MON-YYYY')),
PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('01-JAN-2001', 'DD-MON-YYYY')),
PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE)
);那么各个的数据分布就如下图所示:

范围分区键值确定各个范围分区的高值,被称为跃点。在上图中,分区SALES_1998 包含分区键 time_id 值小于跃点 01-JAN-1999 的行。
如果数据超出跃点怎么办?数据库会创建自动创建间隔分区,用来存储超出跃点的数据。上图中分区 SALES_2001 包含分区键 time_id 值大于或等于 01-JAN-2001 的行。
2)列表分区
当分区键不方便排序时,可以通过使用列表来分组和组织相关的数据集。例如time_range_sales表中的channel_id,这个值是间断不连续的值,此时可以使用列表分区的方式进行分类。
CREATE TABLE list_sales (
prod_id NUMBER(6),
cust_id NUMBER,
time_id DATE,
channel_id CHAR(1),
promo_id NUMBER(6),
quantity_sold NUMBER(3),
amount_sold NUMBER(10, 2)
)
PARTITION BY LIST (channel_id)(
PARTITION even_channels VALUES (2,4),
PARTITION odd_channels VALUES (3,9)
);这时候数据分区会是如下的情况:

3)哈希分区
在哈希分区中,基于分区键的哈希值来确定如何映射到各区上的,因此,分区的数量会直接影响数据的分布,所以使用哈希分区时,需要指定分区数量。当更改分区数量时,所有的数据会重新分布。我们针对time_range_sales使用prod_id作为分区键,使用哈希分区重新创建表:
CREATE TABLE hash_sales (
prod_id NUMBER(6),
cust_id NUMBER,
time_id DATE,
channel_id CHAR(1),
promo_id NUMBER(6),
quantity_sold NUMBER(3),
amount_sold NUMBER(10, 2)
) PARTITION BY HASH (prod_id) PARTITIONS 2;这时候数据分区会是如下的情况:
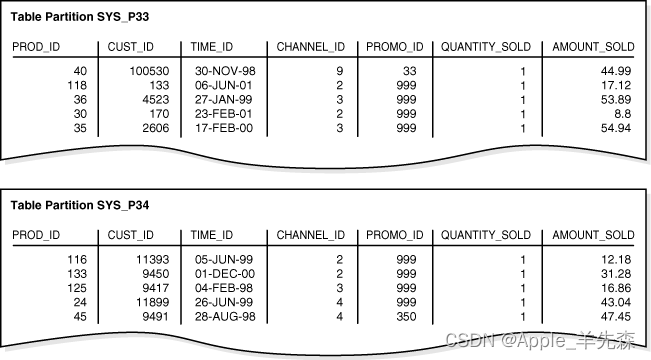
需要注意的时,哈希分区不能自己指定数据的分区位置,并且需要提前规划好分区数量。