文章目录
- 1. 并发 & 并行 、同步 & 异步
- 1.1 并发 & 并行
- 并发 Concurrency
- 并行 Parallelism
- 1.2 同步 & 异步
- 同步 Synchronous
- 异步 Asynchronous
- 2. CPU密集型计算 & IO密集型计算
- 2.1 CPU密集型(CPU-bound)
- 2.2 IO密集型(I/O-bound)
- 3. 单线程编程 & 多线程编程
- 3.1 (单线程)异步编程 Asynchronous Programming
- 3.2 多线程编程 Multi-threading
- 4. Python中并发编程
- 4.1 为什么要引入并发编程?
- 4.2 引入并发编程的意义
- 4.3 程序提速的方法
- 4.4 Python对并发编程的支持
- 4.5 Python并发编程的三种方式及使用场景
- 4.6 怎样根据任务选择对应技术?
- 5. GIL 全局解释器锁
- 5.1 Python速度慢的两大原因
- 5.2 GIL是什么?
- 5.3 为什么有GIL这个东西?
- 5.4 怎样规避GIL带来的限制?
- 6. Python中的代码实战
- 6.1 单线程 & 多线程
- Python 创建多线程的方式
- 传统单线程版本
- 多线程版本
- 6.2 生产者 & 消费者
- 多组件的Pipeline技术架构
- 生产者消费者爬虫的架构
- 多线程数据通信的 queue.Queue
- 代码编写实现生产者消费者爬虫
- 单线程版本
- 多线程版本
- 6.3 Python线程安全问题以及解决方案
- 线程安全概念介绍
- Lock用于解决线程安全问题
- 用法一:try-finally 模式
- 用法二:with 模式
- 实例代码演示问题以及解决方案
- 6.4 好用的线程池 - ThreadPoolExecutor
- 线程池的原理
- 使用线程池的好处
- ThreadPoolExecutor的使用语法
- 使用线程池改造爬虫程序
- 6.5 在Web服务中使用线程池加速
- Web服务的架构以及特点
- 使用线程池ThreadPoolExecutor加速
- 代码用Flask实现Web服务并实现加速
- 6.6 使用多进程 multiprocessing 加速程序的运行
- 有了多线程threading,为什么还要用多进程multiprocessing
- 多进程multiprocessing:知识梳理
- 代码实战:单线程、多线程、多进程对比CPU密集计算速度
- 6.7 在Flask服务中使用进程池加速
- 6.8 Python异步IO实现并发爬虫
- 什么是协程
- Python 异步IO库介绍:asyncio
- 异步代码
- 6.9 在异步IO中使用信号量控制爬虫并发度
- 使用方式一
- 使用方式二
- 在异步IO中加入并发度限制
1. 并发 & 并行 、同步 & 异步
1.1 并发 & 并行
- 是一个比较宽泛的概念,它单纯的代表计算机能够同时执行多项任务,至于计算机怎么做到“并发” 则有许多不同的形式。
并发 Concurrency
-
单核计算机实现并发:通过分配时间片的方式,让一个任务执行一段时间,然后切换到另一个任务再运行一段时间,不同的任务会这样交替往复的一直执行下去,这个过程也被称作是进程或者线程的上下文切换(context switching)。

并行 Parallelism
- 多核计算机实现并发:在不同的核心上真正并行地执行任务,而不用通过分配时间片的方式运行,这种情况也就是我们所说的并行。

1.2 同步 & 异步
- 同步和异步是两种不同的编程模型
同步 Synchronous
- “同步” 代表需要等到必须前一个任务执行完毕之后,才能进行下一个任务。
- 在同步中没有并发或者并行的概念。

异步 Asynchronous
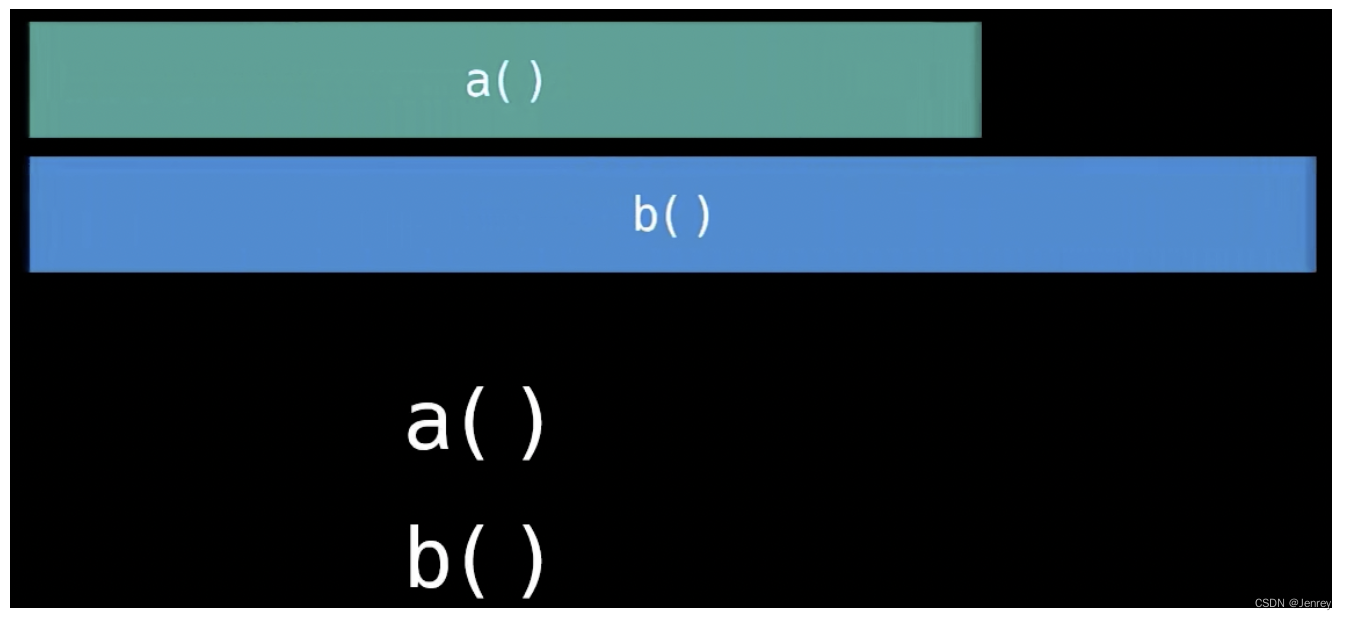
- 异步则代表不同的任务之间并不会相互等待
- 在执行任务A的时候,也可以同时运行任务B
- 一个典型实现异步的方式则是通过多线程编程(Multithreading)
- 特别注意,在Python中由于受到GIL的限制,并不会出现下图所示的执行效果。而其他编程语言在多核CPU环境下,每个线程就会被分配到独立的核心上运行,实现真正的并行。但如果使用单核心处理器或者通过设置亲和力(Affinity)强制将线程绑定到某个核心上,操作系统则会通过分配时间片的方式来执行这些线程,这些线程则是在并发地执行。
import threading
"""在Python中,无论单核还是多核CPU,都可以看到下面发生了某一个CPU核心的时间片切换,证明只能并发执行,不能并行执行,即不能利用多CPU核心(受到GIL限制)。
Print from thread 0.
Print from thread 1.
Print from thread 1.
Print from thread 1.
Print from thread 1.
Print from thread 1.
Print from thread 0.
Print from thread 0.
Print from thread 0.
Print from thread 0.
Print from thread 2.
Print from thread 2.
Print from thread 2.
Print from thread 2.
Print from thread 2.
"""
def my_thread(index):
for _ in range(5):
print("\nPrint from thread %s." % index)
if __name__ == "__main__":
for index in range(3):
thread = threading.Thread(target=my_thread, args=(index,))
thread.start()
2. CPU密集型计算 & IO密集型计算
单词bound就是 受限制 的意思。
2.1 CPU密集型(CPU-bound)
- 任务的运行受到cpu的限制,CPU占用率能达到顶峰,而读写操作不会花费大量的时间。
- CPU密集型也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高。
- 例如:压缩、解压缩、加密、解密、正则表达式搜索。
2.2 IO密集型(I/O-bound)
-
任务的运行受到IO的限制,IO是你程序运行的瓶颈。
-
IO密集型指的是系统运行大部分的状况是CPU在等I/O(硬盘/内存/网络)的读/写操作,CPU占用率较低。
-
简而言之,如果你的程序依赖大量的外部数据源,比如内存、磁盘、网络,那么它就是IO密集型。否则如果只在CPU中进行计算那么就是CPU密集型。
-
例如:文件处理程序、网络爬虫程序、读写数据库程序。
3. 单线程编程 & 多线程编程
3.1 (单线程)异步编程 Asynchronous Programming
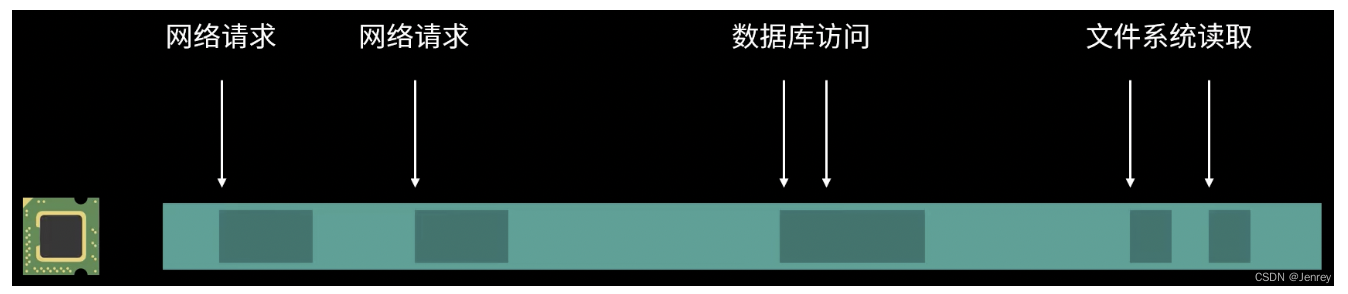
- 对于 I/O 密集的应用程序,比如Web应用就会经常执行网络操作、数据库访问,这类应用就非常适合使用异步编程的方式。
# 单线程的并发,这里是异步编程的方式
import asyncio
async def main():
print("hello")
await asyncio.sleep(1)
print("world")
asyncio.run(main())
- 反之,如果使用多线程的方式则会浪费不少的系统资源。因为每个线程的绝大多数时间都是在等待这些 I/O 操作。线程自身也会占用额外的内存,线程的切换也会有额外的开销,更不用说线程之间的资源竞争问题。
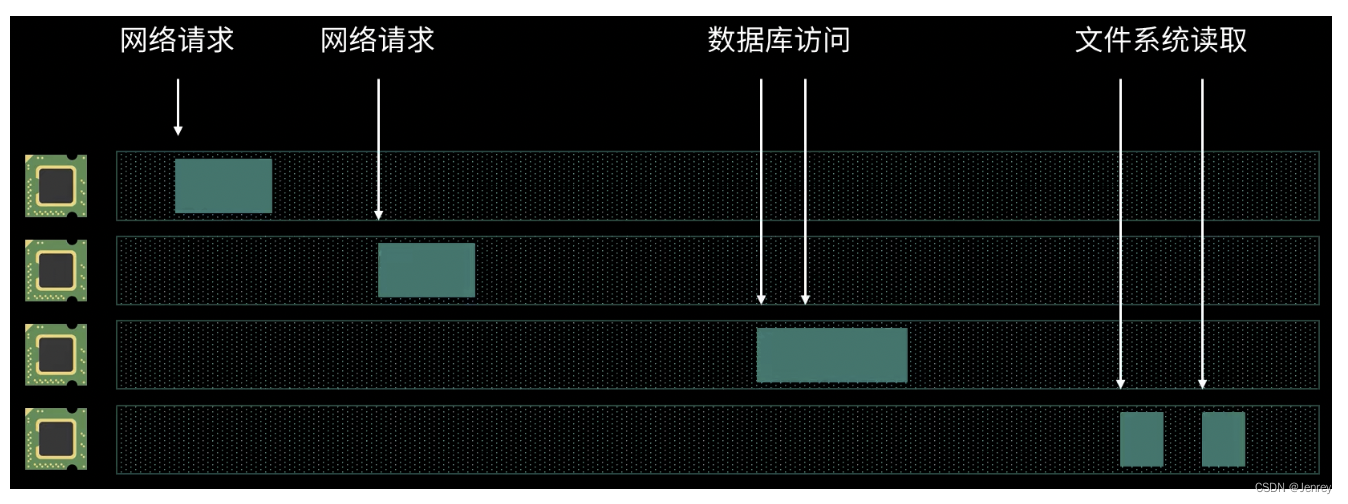
3.2 多线程编程 Multi-threading
- 多线程编程则非常适合于计算量密集的应用。例如视频图像处理、科学计算等等。
- 多线程编程能够让每一个 CPU 核心发挥最大的功效,而不是消耗在空闲的等待上。
4. Python中并发编程
4.1 为什么要引入并发编程?
- 场景1:一个网络爬虫,按顺序爬取花了1小时,采用并发下载减少到20分钟!
- 场景2:一个APP应用,在它的后台服务中请求了大量的外部资源,优化前每次打开页面需要3秒,采用异步并发提升到每次200毫秒;
4.2 引入并发编程的意义
- 引入并发,就是为了提升程序运行速度。
- 学习并掌握并发编程,是 高级别 + 高薪资 程序员的必备能力
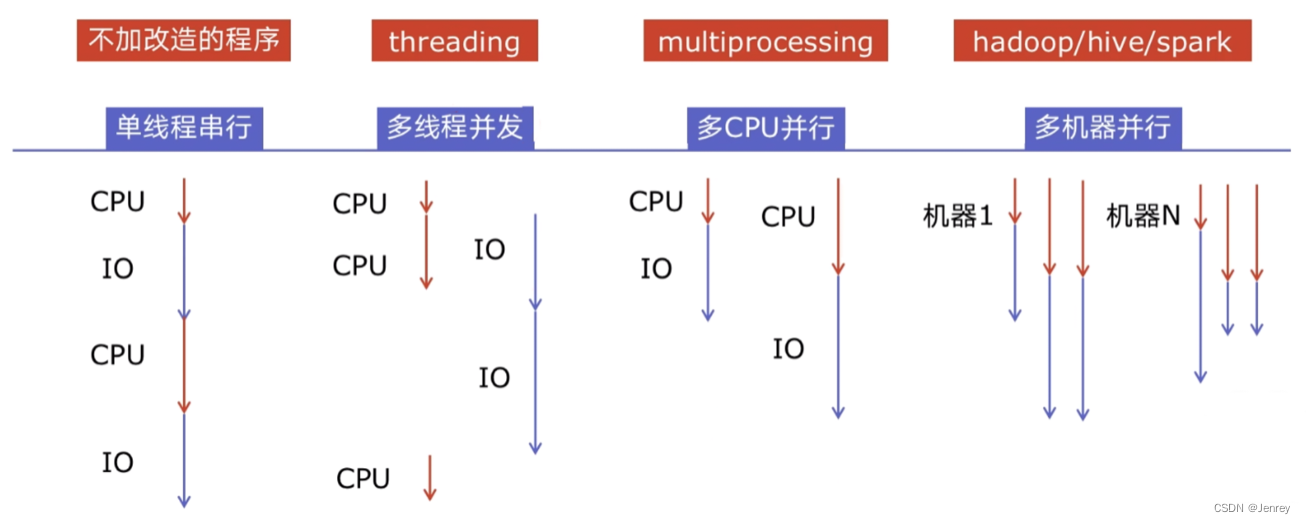
4.3 程序提速的方法
- 单线程串行:初级的程序都是单线程串行运行的。
- 多线程并发:这种原理上还是一个CPU来进行运行的。有一个知识点咱们电脑中的CPU和IO这两个它们是可以同时并行进行的,IO的执行例如读取内存、磁盘、网络它们的过程中是不需要CPU参与的,这样CPU可以释放出来执行其他task,实现并发的加速。
- 多CPU并行:多个CPU核心同时真正的并行执行。
- 多机器并行:在大数据时代,用多个机器执行。
CPU在程序IO的时候是不做什么事情的,所以这就是可以提速的切入点。
4.4 Python对并发编程的支持
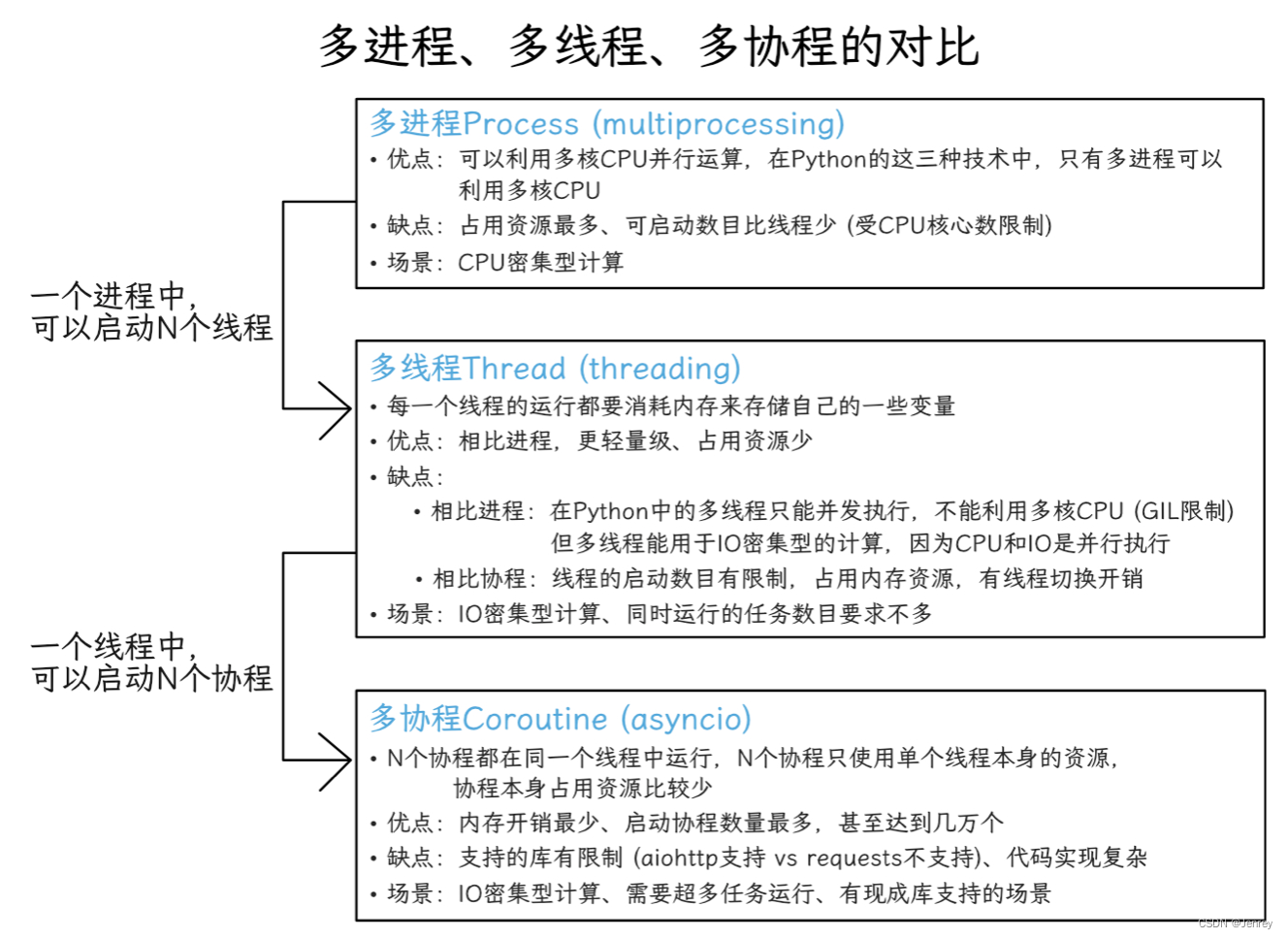
- 多线程:
threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成,而是让CPU切换到其他task,进行多线程的并发执行。 - 多进程:
multiprocessing,利用多核CPU的能力,真正的并行执行任务。 - 多协程:也称异步IO:
asyncio,该模块比较新,在单线程中利用CPU和IO可以同时执行的原理,实现函数异步执行。
对于上面这些模块,Python提供了一些辅助:
- 使用Lock对资源加锁,防止冲突访问。
- 使用Queue实现不同 线程 / 进程 之间的数据通信,实现 生产者-消费者 模式。
- 使用 线程池Pool / 进程池Pool ,简化 线程/进程 的任务提交、等待结束、获取结果。
- 使用
subprocess启动外部程序的进程,并进行输入输出交互
4.5 Python并发编程的三种方式及使用场景
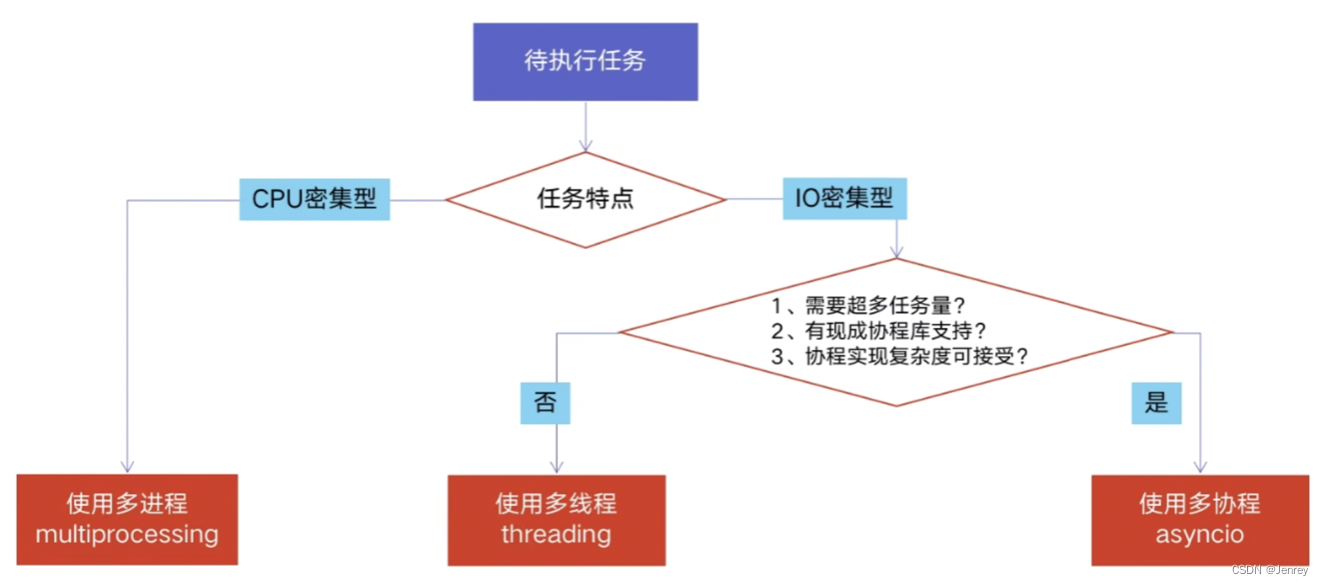
4.6 怎样根据任务选择对应技术?
5. GIL 全局解释器锁
5.1 Python速度慢的两大原因
-
相比 C / C++ / JAVA,Python确实慢,在一些特殊场景下,Python比 C++ 慢100~200倍。
-
由于速度慢的原因,很多公司基础架构代码依然用 C / C++ 开发,比如各大公司阿里/腾讯/快手的推荐引擎、搜索引擎、存储引擎等底层对性能要求高的模块。
-
Python速度慢的两大原因:
- 动态类型语言,边解释边执行
- GIL,无法利用多核CPU并发执行
5.2 GIL是什么?
-
全局解释器锁(英语:Global Interpreter Lock,缩写GIL)
-
是计算机程序设计语言解释器(Python)用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。简单来说,就是一把锁,这把锁在任意时刻只允许一个 Python 进程使用 Python 解释器。
-
即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。所以我们用Python开发多线程的程序,在同一时间只能执行一个线程。

-
由于GIL的存在,即使电脑有多核CPU,单个时刻也只能使用1个核心,相比并发加速的C++ / JAVA所以慢。
对C++和JAVA来说,如果开启了多线程并且在多核CPU下,那么这个多线程会并行执行;如果是单核CPU下,即使是JAVA的多线程也是并发执行的。
5.3 为什么有GIL这个东西?
-
简而言之:Python设计初期,为了规避并发问题引入了GIL,现在想去除却去不掉了!
-
GIL为了解决多线程之间 数据完整性 和 状态同步 问题
-
Python中对象的管理,是使用引用计数器进行的,引用数为0则释放对象。平时写的 Python 代码,引用计数是在你调用变量的时候自动增加的,不需要你去手动加 1。
-
GIL 锁住的东西,都是不需要你的代码直接交互的东西。
- GIL 锁用来保护指向当前进程状态的指针
- 当两个线程同时提高同一个对象的引用计数时,(如果没有 GIL 锁)那么引用计数只会被提高了 1 次而不是 2 次。
-
Python支持多线程编程后,为了避免引用计数等出现线程安全问题,就引入了 GIL。注意,即使有了GIL锁,我们对共享资源obj仍需使用Lock加锁。即使同一时间只有一个线程在运行,但是两个线程同时修改同一个变量时,也会发生并发冲突。如下图所示:
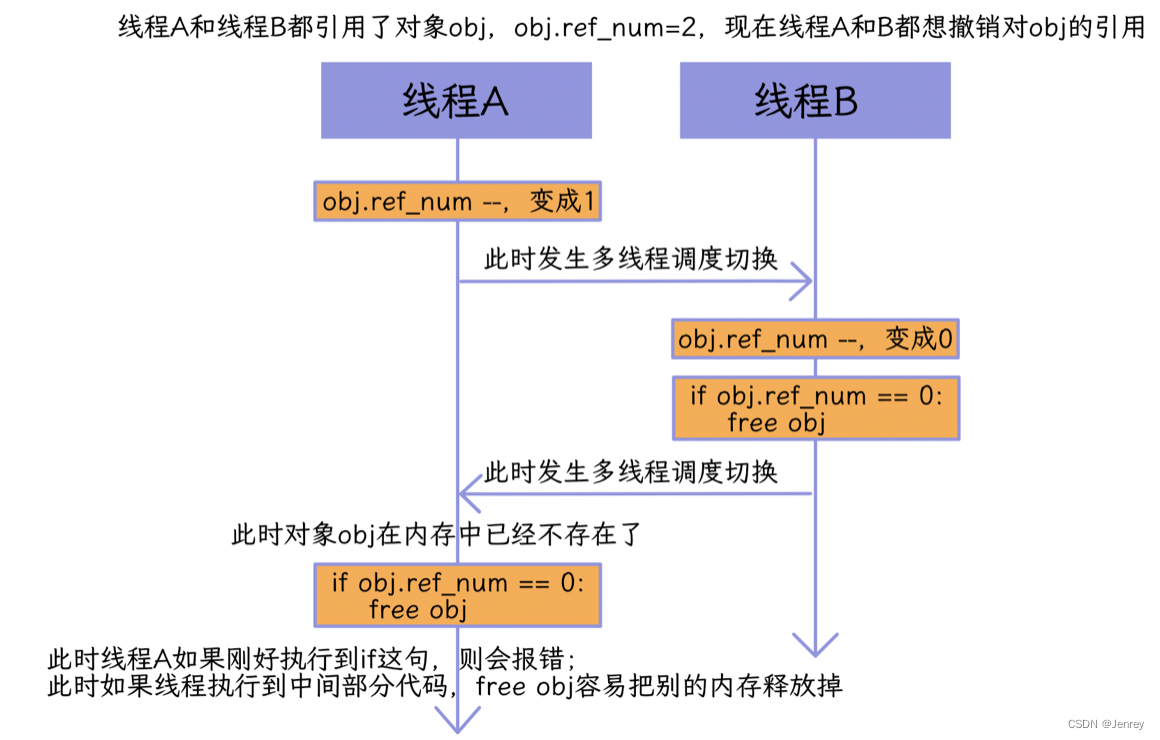
-
GIL确实有好处,简化了Python对共享资源的管理;
-
5.4 怎样规避GIL带来的限制?
- GIL带来的限制是:在任意时刻只允许有一个线程在运行,无法使用多核CPU的优势。
- GIL的存在也是有意义的
- 场景一:多线程 threading 机制依然是有用的,用于IO密集型计算。
因为 I/O(read、write、send、recv、etc.)期间,线程会释放GIL,实现CPU和IO的并行,因此多线程用于IO密集型计算依然可以大幅提升速度。
但是多线程用于CPU密集型计算时,只会更加拖慢速度,因为只有CPU一个核心在运行,同时经常会发生多线程的切换,多线程的切换会带来额外开销,那么就会拖慢CPU的执行速度。 - 场景二:使用 multiprocessing 的多进程机制,利用多核CPU的优势,实现真正的并行计算。所以为了应对GIL的问题,Python提供了 multiprocessing
- 场景一:多线程 threading 机制依然是有用的,用于IO密集型计算。
6. Python中的代码实战
6.1 单线程 & 多线程
- Python创建多线程的方法
- 改写爬虫程序,变成多线程爬取
- 速度对比:单线程爬虫VS多线程爬虫
Python 创建多线程的方式
# 1、准备一个函数
def my_func(a,b):
do_craw(a,b)
# 2、创建一个子线程
import threading
t = threading.Thread(target=my_func, args=(100,200)) # 注意传入函数名而不是调用,args是元组
# 3、启动线程
t.start()
# 4、等待结束
# 如果不关心线程的结束,可以不用写,让线程一直运行即可
# 如果想知道线程什么时候结束就可以用join方法,这个方法会一直等待线程的结束
t.join()
传统单线程版本
import time
import requests
# 要爬取的网页URL
urls = [f"https://www.cnblogs.com/#p{page}" for page in range(1, 50 + 1)]
def craw(url: str):
r = requests.get(url)
print(url, len(r.text))
def single_thread():
for url in urls:
craw(url)
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
print("single thread cost:", end - start, "seconds")
多线程版本
import threading
import time
import requests
# 要爬取的网页URL
urls = [f"https://www.cnblogs.com/#p{page}" for page in range(1, 50 + 1)]
def craw(url: str):
r = requests.get(url)
print(url, len(r.text))
def multi_thread():
threads = []
for url in urls:
threads.append(threading.Thread(target=craw, args=(url,)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == "__main__":
start = time.time()
multi_thread()
end = time.time()
print("multi thread cost:", end - start, "seconds")
6.2 生产者 & 消费者
- 多组件的Pipeline技术架构
- 生产者消费者爬虫的架构
- 多线程数据通信的 queue.Queue
- 代码编写实现生产者消费者爬虫
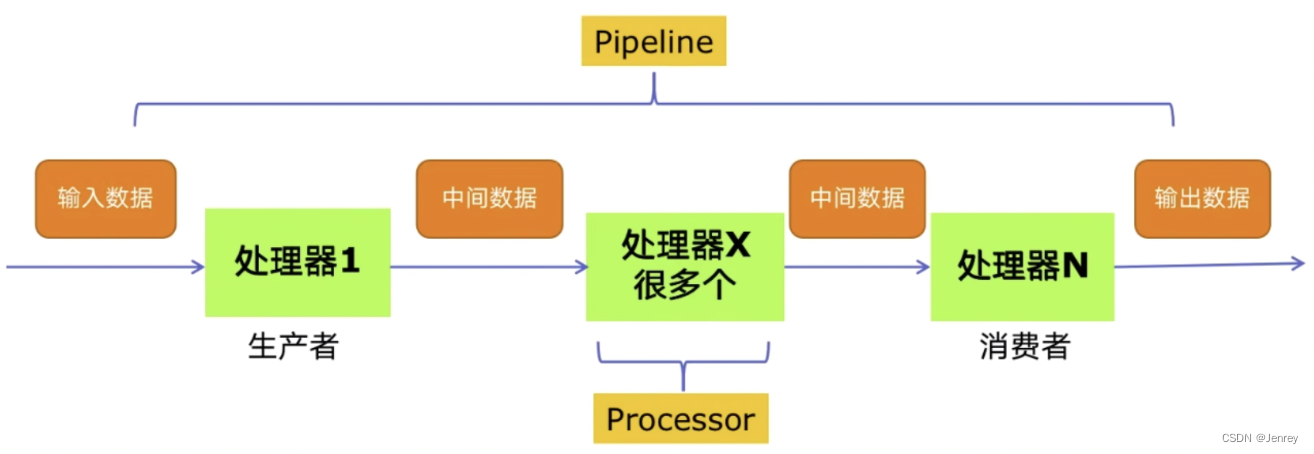
多组件的Pipeline技术架构
复杂的事情一般都不会一下子做完,而是会分很多中间步骤一步步完成
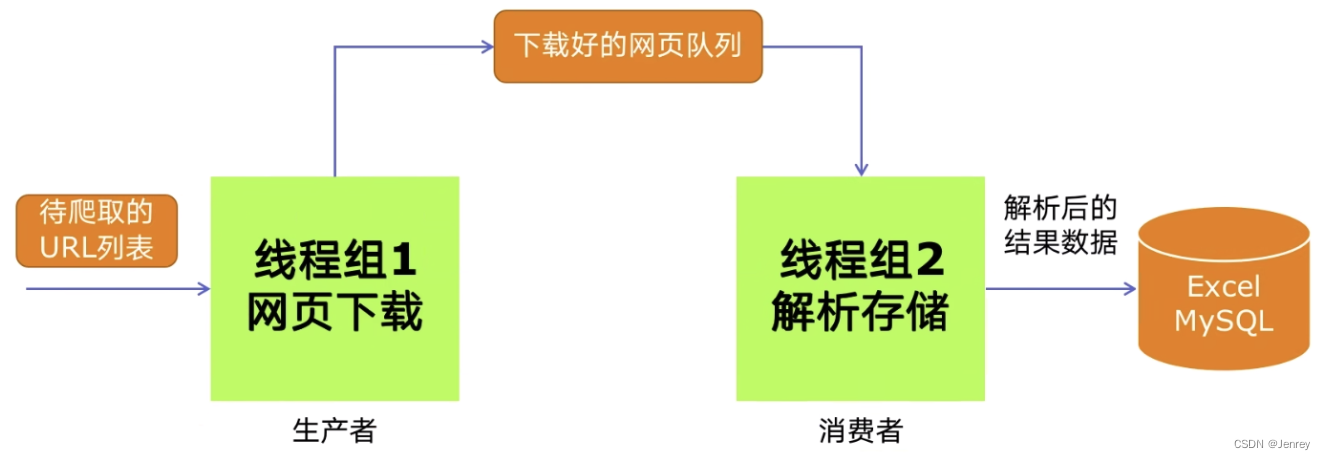
生产者消费者爬虫的架构
多线程数据通信的 queue.Queue
queue.Queue 可以用于多线程之间的、线程安全的数据通信。
线程安全:指的是多个线程并发同时的访问数据,不会出现冲突。
# 1、导入类库
import queue
# 2、创建Queue
q = queue.Queue()
# 3、添加元素, 阻塞的方法
q.put(item)
# 4、获取元素,阻塞的方法
item = q.get()
# 5、查询状态
# 查看元素的多少
q.qsize()
# 判断是否为空
q.empty()
# 判断是否已满
q.full()
代码编写实现生产者消费者爬虫
单线程版本
from typing import List, Tuple
import requests
from bs4 import BeautifulSoup
# 要爬取的网页URL
urls = [f"https://www.cnblogs.com/#p{page}" for page in range(1, 50 + 1)]
def craw(url: str) -> str:
"""生产者
:return 返回网页的HTML
"""
r = requests.get(url)
return r.text
def parse(html: str) -> List[Tuple[str, str]]:
"""Processor: 获取网页中所有的文章及URL"""
soup = BeautifulSoup(html, "html.parser")
links = soup.find_all("a", class_="post-item-title")
return [(link["href"], link.get_text()) for link in links]
if __name__ == "__main__":
"""消费者"""
for result in parse(craw(urls[2])):
print(result)
多线程版本
import queue
import random
import threading
import time
from typing import List, Tuple
import requests
from bs4 import BeautifulSoup
# 要爬取的网页URL
urls = [f"https://www.cnblogs.com/#p{page}" for page in range(1, 50 + 1)]
def craw(url: str) -> str:
"""获取网页的HTML
:param url: 要获取的URL
:return: 返回网页的HTML
"""
r = requests.get(url)
return r.text
def parse(html: str) -> List[Tuple[str, str]]:
"""Processor: 获取网页中所有的文章及URL"""
soup = BeautifulSoup(html, "html.parser")
links = soup.find_all("a", class_="post-item-title")
return [(link["href"], link.get_text()) for link in links]
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
"""生产者"""
while True:
url = url_queue.get() # 获取元素,阻塞的方法
html = craw(url)
html_queue.put(html)
print(threading.current_thread().name, f"craw {url}", "url_queue.size=", url_queue.qsize())
time.sleep(random.randint(1, 2)) # 随机睡眠1或2秒
def do_parse(html_queue: queue.Queue, fout):
"""消费者"""
while True:
html = html_queue.get()
results = parse(html)
for result in results:
fout.write(str(result) + "\n")
print(threading.current_thread().name, "results.size", len(results), "html_queue.size=", html_queue.qsize())
time.sleep(random.randint(1, 2)) # 随机睡眠1或2秒
if __name__ == "__main__":
url_queue = queue.Queue() # 队列大小为无限
html_queue = queue.Queue() # 队列大小为无限
for url in urls:
url_queue.put(url)
# 启动生产者线程
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{idx}")
t.start()
fout = open("data.txt", "w")
# 启动消费者线程
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse{idx}")
t.start()
6.3 Python线程安全问题以及解决方案
线程安全概念介绍
- 线程安全:指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
- 线程不安全:由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全
Lock用于解决线程安全问题
只要第一个线程拿到锁了,即使发生了线程切换,第二个线程因为没有锁,也无法进入到被锁住的代码段,只有当第一个线程把锁释放,第二个线程才能进来。
我们可以把一大段可能出现问题的代码段放在锁里,这样就保证了在多线程情况下,即使线程发生了切换,也不会造成线程不安全的问题。
用法一:try-finally 模式
import threading
lock = threading.Lock()
lock.acquire()
try:
# do something
finally:
lock.release()
用法二:with 模式
import thread
lock = thread.Lock()
with lock:
# do something
实例代码演示问题以及解决方案
# 线程不安全
import threading
import time
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
if account.balance >= amount:
time.sleep(0.1) # 加上这句会一直出现“余额-600”问题,因为sleep语句一定会导致当前线程的阻塞(或者进行远程调用也会导致当前线程阻塞),从而进行线程的切换
print(threading.current_thread().name, "取钱成功")
account.balance -= amount
print(threading.current_thread().name, "余额", account.balance)
else:
print(threading.current_thread().name, "取钱失败, 余额不足")
if __name__ == "__main__":
account = Account(1000)
t1 = threading.Thread(name="t1", target=draw, args=(account, 800))
t2 = threading.Thread(name="t2", target=draw, args=(account, 800))
t1.start()
t2.start()
第一个线程进入if语句,此时还没有减去amount,遇到sleep语句发生线程切换,切换到第二个线程,线程二进入if语句,遇到sleep语句发生线程切换,切换到第一个线程,执行减去amount操作并结束第一个线程,然后继续执行线程二的减去amount操作,最后结果一定是余额-600
# 不加sleep
t1 取钱成功
t2 取钱成功
t2 余额 200
t1 余额 -600
# 加上sleep
t1 取钱成功
t1 余额 200
t2 取钱成功
t2 余额 -600
解决线程不安全的问题:
即使拿到锁的第一个线程在sleep,被切换到第二个线程,但第二个线程拿到不锁,所以就没法进入被锁住的代码,所以系统重新切换回第一个线程,然后第一个线程往下执行最后结束,然后第二个线程获取了锁,等到进入代码的时候balance不够提取的余额了,所以取钱失败。
# 线程安全
import threading
import time
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
with lock:
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name, "取钱成功")
account.balance -= amount
print(threading.current_thread().name, "余额", account.balance)
else:
print(threading.current_thread().name, "取钱失败, 余额不足")
if __name__ == "__main__":
account = Account(1000)
t1 = threading.Thread(name="t1", target=draw, args=(account, 800))
t2 = threading.Thread(name="t2", target=draw, args=(account, 800))
t1.start()
t2.start()
t1 取钱成功
t1 余额 200
t2 取钱失败, 余额不足
一旦我们开始多线程编程的开发,就会遇到线程不安全的问题,如果这个问题我们不处理的话,会造成非常严重的Bug,并且这个Bug还不好排查。
6.4 好用的线程池 - ThreadPoolExecutor
线程池的原理
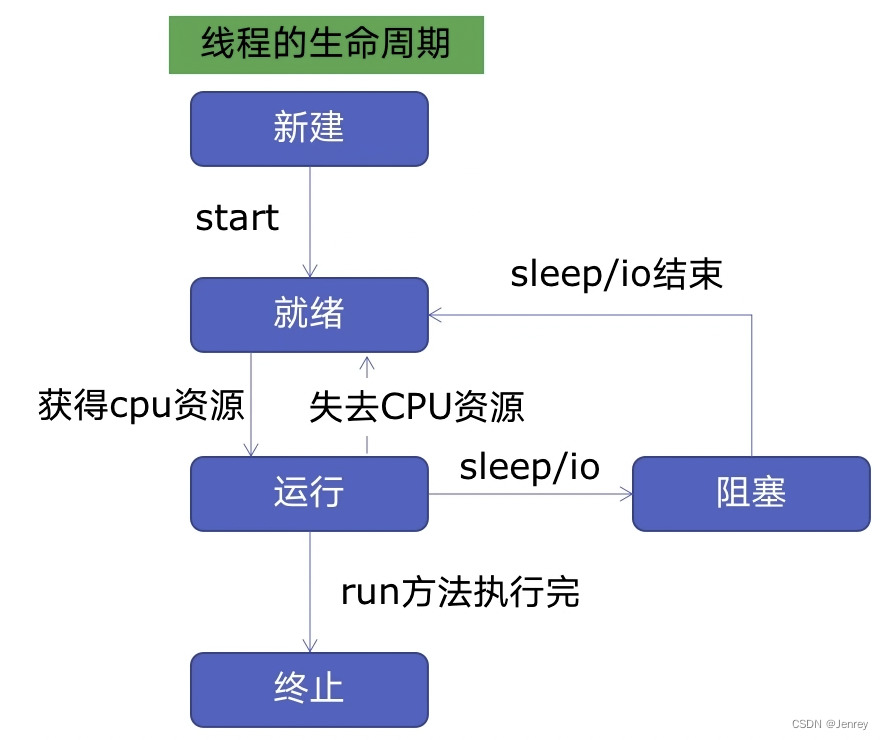
- 一个线程包含以下几个状态:新建、就绪、运行、阻塞、终止
- 新建:线程在新增的时候,这个线程处于完全不动的状态,然后我们调用
start()方法,此时线程就会进入就绪状态。 - 就绪:进入就绪状态的线程此时并没有真正的运行,因为一个线程的运行是需要系统进行调度的,系统进行调度让此线程获得CPU的资源,此时线程就进入运行状态了。
- 运行:线程在运行的过程中,可能会失去CPU资源,重新进入就绪状态;也有可能自身遇到了
sleep()或者IO进入阻塞的状态。 - 阻塞:当对应的 sleep/IO 完成以后,就会再次回到就绪状态,等待系统的调度。
- 终止:当run方法执行完以后,或者线程被终止,就进入了终止的状态。
- 新建:线程在新增的时候,这个线程处于完全不动的状态,然后我们调用
- 新建线程系统需要分配资源、终止线程系统需要回收资源,如果可以重用线程,则可以减去新建/终止的开销。
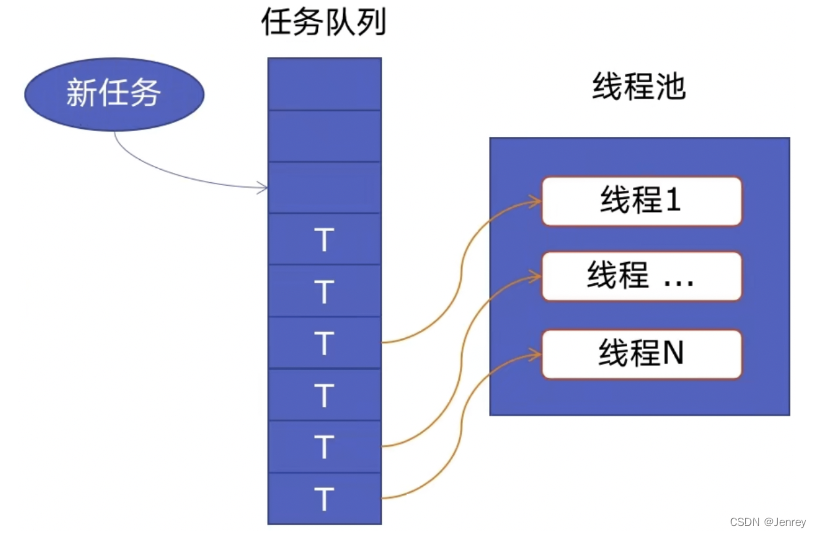
- 下图是线程池流转图
- 一个线程池主要由两部分组成:
- 线程池本身:里面是提前预先建好的线程,这些线程会被重复的使用
- 任务队列:当有新的任务时,并不是直接创建一个线程,而是放在这个任务队列里,然后线程池里已经提前创建好的这些线程会挨个取出任务队列里的任务,进行执行。当这个任务执行完毕,会取下一个任务进行执行;如果说没有在任务队列中发现任务,则线程回到线程池中,并不销毁,放在池里等待下一个任务的到来。
- 通过任务队列以及可重用的线程就实现了线程池这么一个功能。
- 一个线程池主要由两部分组成:
使用线程池的好处
- 提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源;
- 适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短;
- 防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题;
- 代码优势:使用线程池的语法比自己新建线程、执行线程更加简洁
ThreadPoolExecutor的使用语法
from concurrent.futures import ThreadPoolExecutor, as_completed
# 用法一, 使用map
with ThreadPoolExecutor() as pool:
# craw是函数名,urls是很多个参数的参数列表, results是线程池执行完返回的结果列表
# 咱们之前只能使用queue的方式间接的获取结果不能使用return的方式, 现在可以了
results = pool.map(craw, urls)
for result in results:
print(result)
- map函数,很简单,注意map的结果和入参是顺序对应的
- future模式,更强大,注意如果使用as_completed顺序是不定的
# 用法二, 使用submit
with ThreadPoolExecutor() as pool:
# url是单个参数
futures = [pool.submit(craw, url) for url in ulrs]
# 遍历方式一, 会按照url的顺序依次获取future对象, 会按顺序等待线程执行结束并返回
for future in futures:
print(future.result()) # 获取线程执行的结果
# 遍历方式二, as_completed函数会实现只要线程有结果就先进行返回,而不是按顺序返回
for future in as_completed(futures):
print(future.result())
使用线程池改造爬虫程序
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from bs4 import BeautifulSoup
urls = [f"https://www.cnblogs.com/#p{page}" for page in range(1, 50 + 1)]
def craw(url: str) -> str:
r = requests.get(url)
return r.text
def parse(html: str):
soup = BeautifulSoup(html, "html.parser")
links = soup.find_all("a", class_="post-item-title")
return [(link["href"], link.get_text()) for link in links]
with ThreadPoolExecutor() as pool:
htmls = pool.map(craw, urls)
htmls = list(zip(urls, htmls))
for url, html in htmls:
print(url, len(html))
print("craw over")
with ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(parse, html)
futures[future] = url
# 按顺序打印结果
#for future, url in futures.items():
# print(url, future.result())
# as_completed函数是哪个任务先执行完成就先返回哪个任务
for future in as_completed(futures):
url = futures[future]
print(url, future.result())
6.5 在Web服务中使用线程池加速
Web服务的架构以及特点
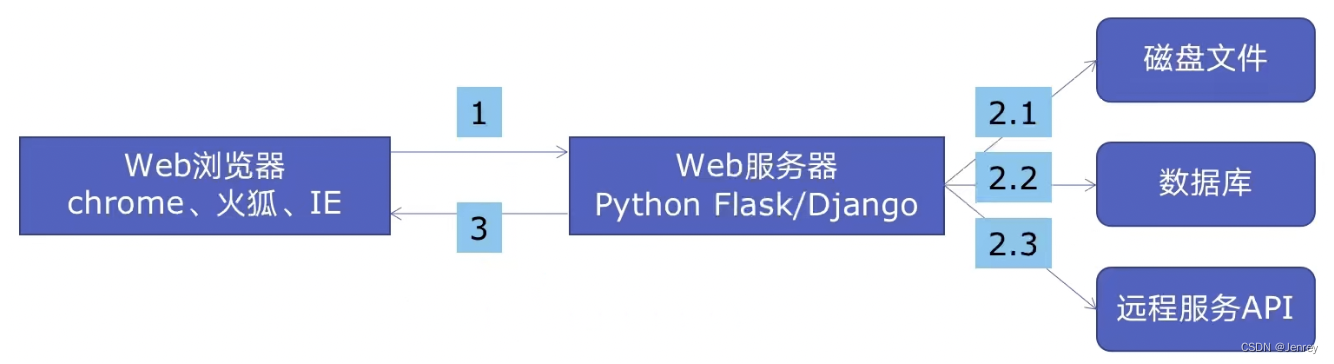
Web后台服务的特点:
- Web服务对响应时间要求非常高,比如要求200MS返回
- Wb服务有大量的依赖IO操作的调用,比如磁盘文件、数据库、远程API
- Web服务经常需要处理几万人、几百万人的同时请求,这就意味着我们不能够无限制的创建线程,因为线程是耗费系统资源的。
使用线程池ThreadPoolExecutor加速
使用线程池ThreadPoolExecutor的好处:
- 方便的将磁盘文件、数据库、远程API的IO调用并发执行
- 线程池的线程数目不会无限创建(导致系统挂掉),具有防御功能
代码用Flask实现Web服务并实现加速
import json
import time
from flask import Flask
app = Flask(__name__)
def read_file():
time.sleep(0.1)
return "file result"
def read_db():
time.sleep(0.2)
return "db result"
def read_api():
time.sleep(0.3)
return "api result"
@app.route("/")
def index():
result_file = read_file()
result_db = read_db()
result_api = read_api()
return json.dumps(
{
"result_file": result_file,
"result_db": result_db,
"result_api": result_api,
},
)
if __name__ == "__main__":
app.run()
上面运行时间在 “0.631s” 左右。下面进行改造
import json
import time
from flask import Flask
from concurrent.futures import ThreadPoolExecutor, as_completed
app = Flask(__name__)
pool = ThreadPoolExecutor() # 初始化全局pool对象
def read_file():
time.sleep(0.1)
return "file result"
def read_db():
time.sleep(0.2)
return "db result"
def read_api():
time.sleep(0.3)
return "api result"
@app.route("/")
def index():
result_file = pool.submit(read_file)
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps(
{
"result_file": result_file.result(),
"result_db": result_db.result(),
"result_api": result_api.result(),
},
)
if __name__ == "__main__":
app.run()
改造后,花费时间在"0.324"左右,与sleep最长的时间有关,因为3个read是并发运行,几乎是同时运行。
6.6 使用多进程 multiprocessing 加速程序的运行
有了多线程threading,为什么还要用多进程multiprocessing
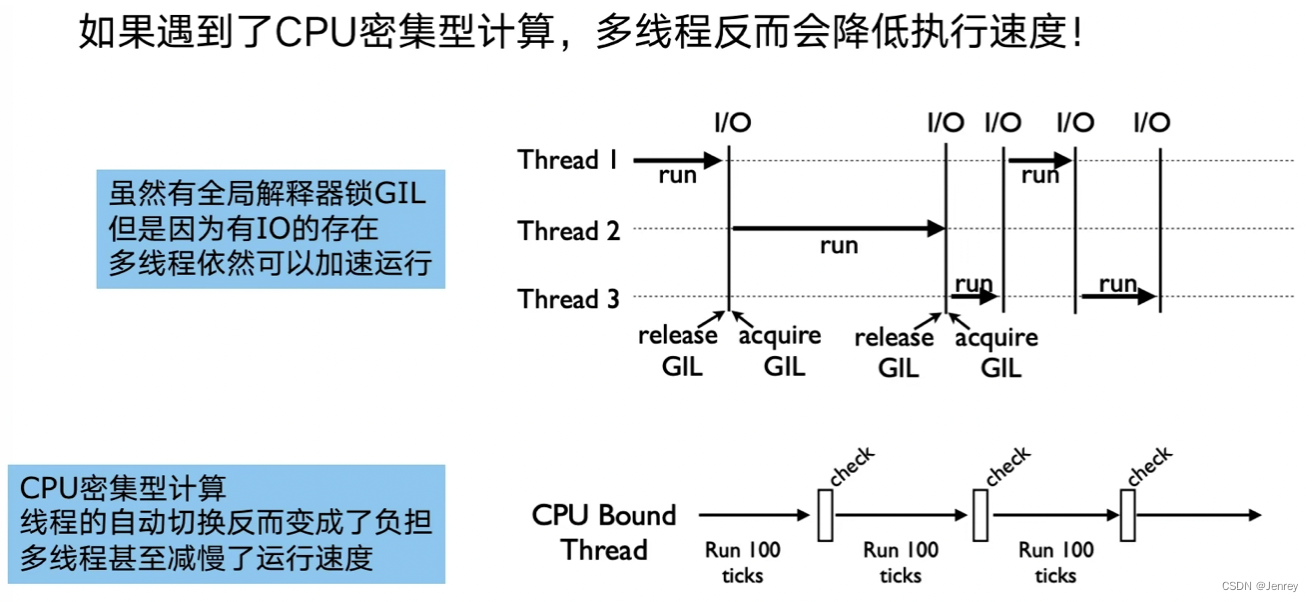
multiprocessing 模块就是python为了解决GIL缺陷引入的一个模块,原理是用多进程在多CPU上并行执行。所以在系统中会运行多个python的解释器进程,它们真正的在并行计算,但是也会有些额外的负担。
多进程multiprocessing:知识梳理
多进程与多线程语法几乎完全一样,只要改个类名即可,这是python官方为了让大家无缝方便的迁移来提供的易用性。

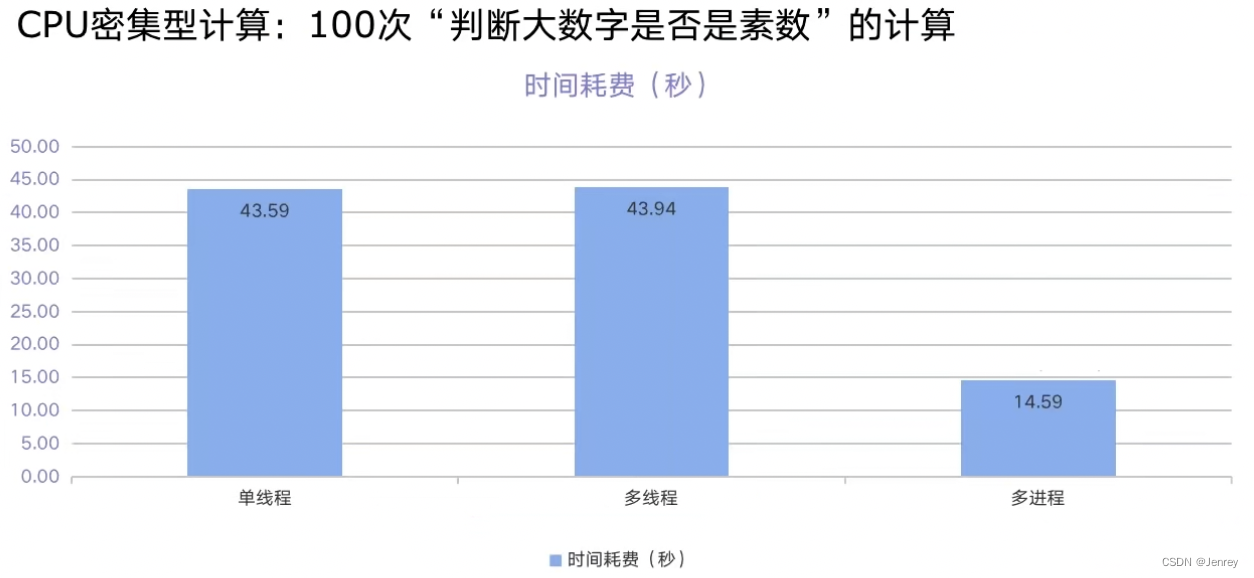
代码实战:单线程、多线程、多进程对比CPU密集计算速度
import math
import time
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
PRIMES = [112272535095293] * 100
def is_prime(n):
"""判断是否是素数"""
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def single_thread():
for number in PRIMES:
is_prime(number)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
if __name__ == "__main__":
start = time.time()
single_thread()
end = time.time()
print("single_thread, cost:", end - start, "seconds")
start = time.time()
multi_thread()
end = time.time()
print("multi_thread, cost:", end - start, "seconds")
start = time.time()
multi_process()
end = time.time()
print("multi_process, cost:", end - start, "seconds")
single_thread, cost: 48.56204795837402 seconds
multi_thread, cost: 49.71490502357483 seconds
multi_process, cost: 17.311036109924316 seconds
6.7 在Flask服务中使用进程池加速
import json
import math
from concurrent.futures import ProcessPoolExecutor
from flask import Flask
app = Flask(__name__)
def is_prime(n):
"""判断是否是素数"""
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
@app.route("/is_prime/<numbers>")
def api_is_prime(numbers):
number_list = [int(x) for x in numbers.split(",")]
results = process_pool.map(is_prime, number_list)
return json.dumps(dict(zip(number_list, results)))
if __name__ == "__main__":
process_pool = ProcessPoolExecutor()
app.run()
- 多进程的每一个进程之间的环境是完全隔离的,所以当我们定义这个pool的时候它所依赖的这些函数必须都已经声明完了,所以就暗含着创建进程池必须放在结尾。
- 放到结尾还不行,必须放在
__main__里面。 - 对比多线程,多线程使用是非常灵活的,定义在哪里都可以,因为它们共享当前进程的所有的环境。
6.8 Python异步IO实现并发爬虫
注意:异步程序本来就是单线程的,但是用一个至尊超级循环 + IO多路复用原理,来提升效率
什么是协程
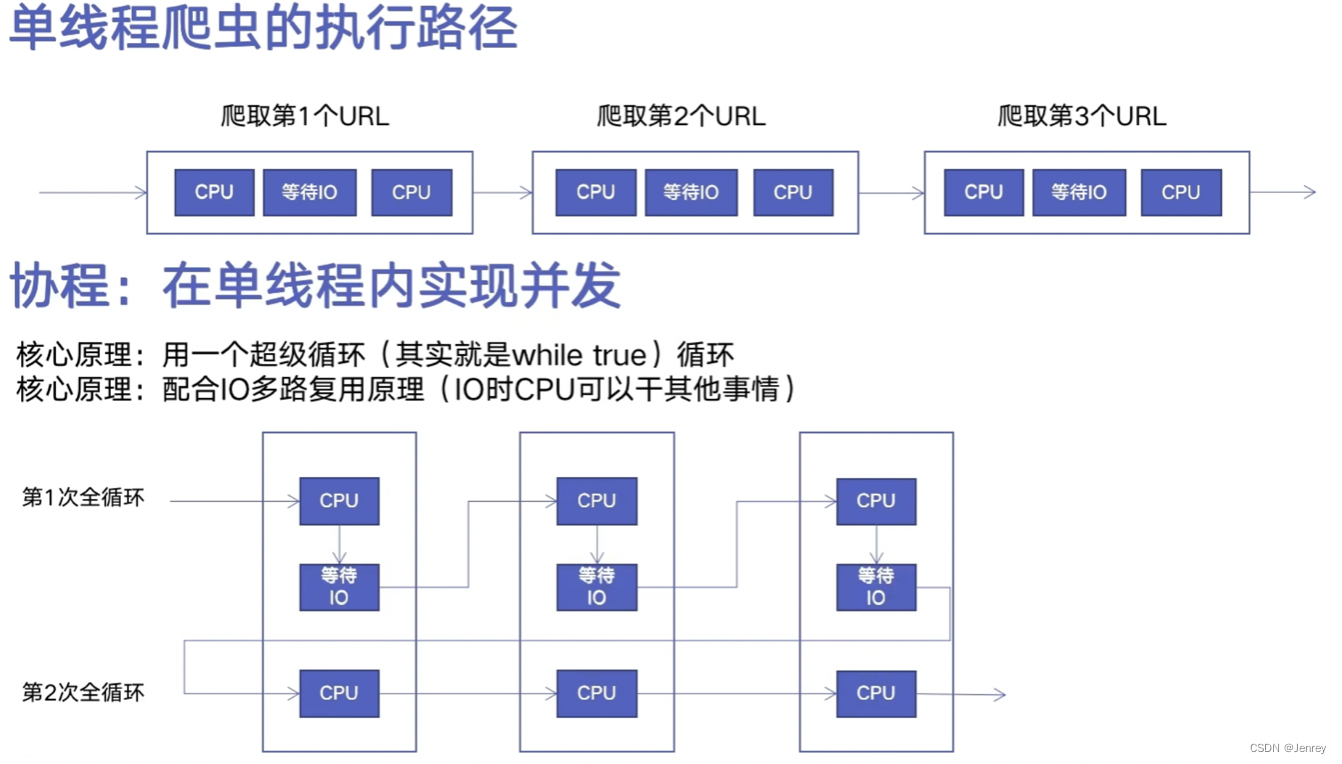
- 协程可以在单线程内实现并发。
- 整体上还是单线程执行的,但是原理就是超级循环,在CPU遇到IO的时候不会等待,而是切换到下一个任务继续执行,而执行完一遍所有的任务后,会回来继续执行一遍任务,挨个轮询的进行。
- 《the one loop》
至尊循环驭众生
至尊循环寻众生
至尊循环引众生
普照众生欣欣荣
Python 异步IO库介绍:asyncio
import asyncio
# 获取事件循环
loop = asyncio.get_event_loop()
# 定义协程
async def myfunc(url):
await get_url(url)
# 创建task列表
tasks = [loop.create_task(myfunc(url)) for url in urls]
# 执行爬虫事件列表,即执行这些tasks列表并等待它们的完成
loop.run_until_complete(asyncio.wait(tasks))
async说明这个函数是个协程,协程就是在异步IO里执行的函数,与普通函数的不同是需要用超级循环来调度的。await代表IO,即表示CPU遇到这个IO不进行阻塞,而是让超级循环直接进入下一个task的执行- 注意:要用在异步IO编程中,依赖的库必须支持异步IO特性。
- 千万注意
await的时候不能阻塞,不然的话单线程就不能并发的执行了。requests不支持异步,需要用aiohttp、httpx等。
异步代码
注意所有的异步对象要加上 async 开头。
import asyncio
import time
import aiohttp
urls = [f"https://www.cnblogs.com/sitehome/p/{page}" for page in range(1, 50 + 1)]
# 定义协程函数,即可以在超级循环里跑的函数
async def async_craw(url: str):
print("craw url:", url)
async with aiohttp.ClientSession() as session: # 创建一个异步的对象
async with session.get(url) as resp: # 请求url
result = await resp.text()
print(f"craw url: {url}, {len(result)}")
# 获取超级循环
loop = asyncio.get_event_loop()
# 创建task列表
tasks = [loop.create_task(async_craw(url)) for url in urls]
# 等待所有tasks的完成
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time seconds:", end - start)
single thread cost: 9s
multi_thread cost: 0.6
use time seconds: 0.3962697982788086
大部分情况下,单线程异步爬虫是要快于多线程爬虫的,这是因为在多线程的时候需要经常的进行多线程的调度切换,这本身是耗费时间的,单线程异步是没有线程切换的开销。
6.9 在异步IO中使用信号量控制爬虫并发度
- 信号量(英语:Semaphore)又称为信号量、旗语,是一个同步对象,用于保持在0至最大值之间的一个计数值。
- 当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;
- 当线程完成一次对semaphore对象的释放(release)时,计数值加一。
- 当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态
- semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态。
使用方式一
sem = asyncio.Semaphore(10)
# ... later
async with sem:
# work with shared resource
使用方式二
sem = asyncio.Semaphore(10)
# ... later
await sem.acquire()
try:
# work with shared resource
finally:
sem.release()
在异步IO中加入并发度限制
import asyncio
import time
import aiohttp
urls = [f"https://www.cnblogs.com/sitehome/p/{page}" for page in range(1, 50 + 1)]
# 声明并发度为10
semaphore = asyncio.Semaphore(10)
# 定义协程函数,即可以在超级循环里跑的函数
async def async_craw(url: str):
async with semaphore: # 包裹的代码都在信号量的控制之内,即前10个爬取完才会进入到下10个爬取
print("craw url:", url)
async with aiohttp.ClientSession() as session: # 创建一个异步的对象
async with session.get(url) as resp: # 请求url
result = await resp.text()
await asyncio.sleep(5)
print(f"craw url: {url}, {len(result)}")
# 获取超级循环
loop = asyncio.get_event_loop()
# 创建task列表
tasks = [loop.create_task(async_craw(url)) for url in urls]
# 等待所有tasks的完成
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("use time seconds:", end - start)