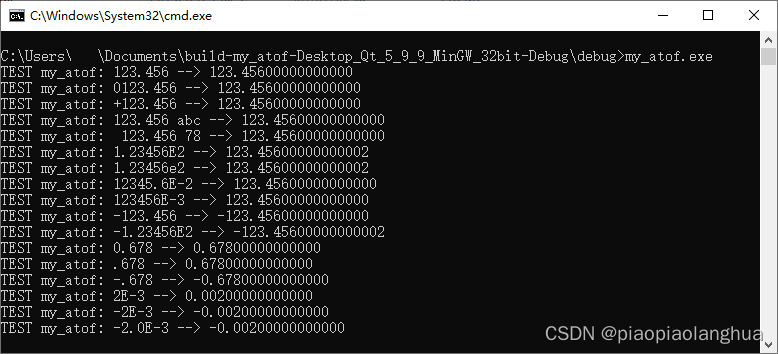
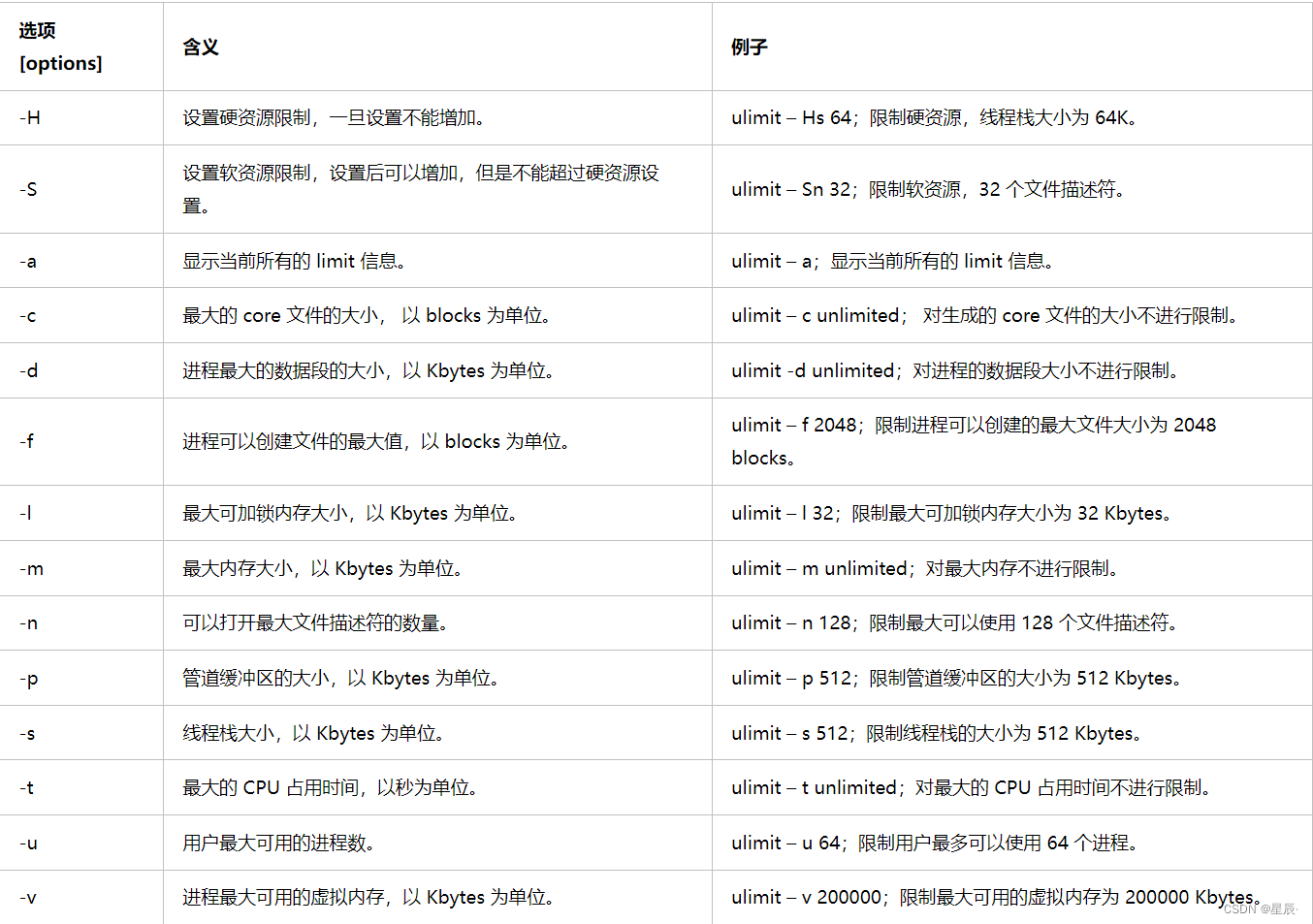
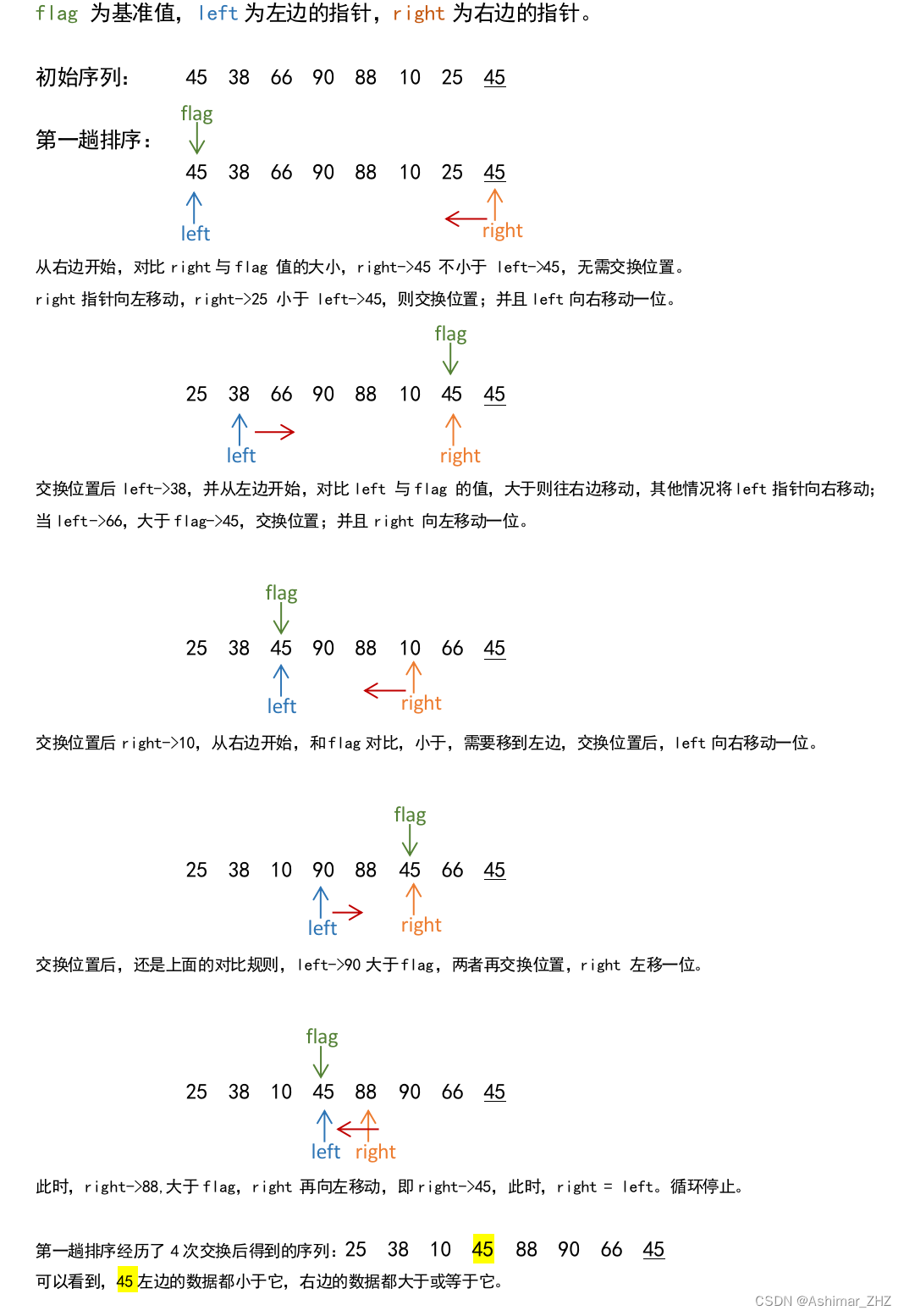
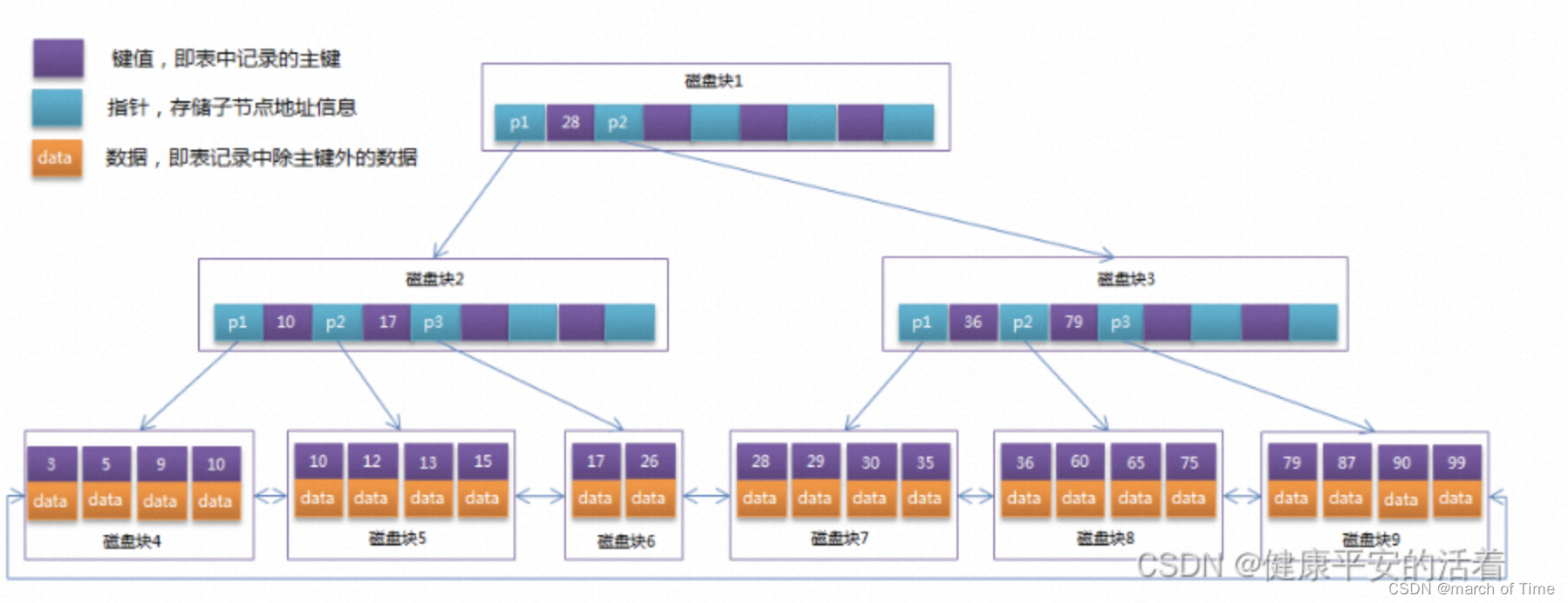
// 引入标准输入输出流库,用于输出操作
#include <iostream>
// 引入标准库中的stdlib,包含了rand()函数和其他相关函数
#include <cstdlib>
// 引入标准库中的time,包含了time()函数和其他相关函数
#include <ctime>
// 定义常量DL为3,表示链表每个节点占用的字符宽度
#define DL 3
// 使用宏定义一个字符串化运算符,用于将数字转化为字符串
#define STR(n) #n
// 使用宏定义一个格式化字符串,用于输出特定长度的整数,例如"%3d"表示输出的整数占用三个字符长度
#define DIGIT_LEN_STR(n) "%" STR(n) "d"
// 定义一个结构体Node,表示链表中的节点
struct Node {
int data; // 节点的数据域,存储节点的值
Node* next; // 指向下一个节点的指针
};
// 定义一个函数,用于创建一个新的节点,并返回该节点的指针
Node* getNewNode(int val) {
// 动态分配一个新的Node内存空间,并返回其指针
Node* p = new Node;
// 设置新节点的数据域为传入的值
p->data = val;
// 将新节点的next指针设置为nullptr,表示该节点为链表的末尾
p->next = nullptr;
// 返回新节点的指针
return p;
}
// 定义一个函数,用于在链表的指定位置插入一个新的节点
Node* insert(Node* head, int pos, int val) {
// 创建一个新的头节点new_head,并创建一个新的节点node
Node new_head, *p = &new_head, *node = getNewNode(val);
// 将new_head的next指针指向当前的head,形成一个新的链表
new_head.next = head;
// 通过循环移动p指针到指定位置的前一个节点
for (int i = 0; i < pos; i++) {
p = p->next;
}
// 将node的next指针指向p的下一个节点,实现插入操作
node->next = p->next;
// 将p的下一个节点设置为node,完成插入操作
p->next = node;
// 返回新的链表的头节点的指针
return new_head.next;
}
// 定义一个函数,用于清空链表中的所有节点,释放其内存空间
void clear(Node* head) {
// 如果链表为空,则直接返回
if (head == nullptr) {
return;
}
// 定义两个指针p和q,p用于遍历链表,q用于保存下一个节点
Node *p = head, *q;
// 当p非空时,执行以下操作
while (p) {
// 保存p的下一个节点为q
q = p->next;
// 释放p的内存空间
delete p;
// 将p移动到下一个节点
p = q;
}
}
// 输出链表函数开始
void output_linklist(Node* head, int flag = 0) {
// 初始化计数器n为0
int n = 0;
// 遍历链表,计算链表中节点的数量,并累加到n中
for (Node* p = head; p; p = p->next) {
n += 1;
}
// 输出每行的前缀,表示节点的位置,使用特定长度的整数格式化字符串输出n的值,并在后面加上空格
for (int i = 0; i < n; i++) {
std::cout << i << " ";
}
// 输出换行符,表示一行的结束
std::cout << std::endl;
// 遍历链表,输出每个节点的值和它连接的下一个节点,使用字符串化运算符将整数转化为字符串并输出,最后输出箭头符号"->"表示连接关系
for (Node* p = head; p; p = p->next) {
std::cout << p->data << "->";
}
// 输出换行符,表示一行的结束
std::cout << std::endl;
// 如果flag等于0,则输出一个额外的换行符
if (flag == 0) {
std::cout << std::endl;
}
// 输出链表函数结束
}
// 定义一个函数,用于在链表中查找指定值的节点
int find(Node* head, int val) {
// 定义一个指针p,指向链表的头节点
Node* p = head;
// 初始化计数器n为0
int n = 0;
// 遍历链表,直到p为空(链表结束)
while (p) {
// 如果当前节点的值等于目标值val
if (p->data == val) {
// 调用output_linklist函数输出整个链表,参数为head和1(表示需要输出找到的节点)
output_linklist(head, 1);
// 计算找到的节点在链表中的位置,长度为n*(DL+2)+2
int len = n * (DL + 2) + 2;
// 输出一些空格,用于画出一个矩形框来标记找到的节点
for (int i = 0; i < len; i++) std::cout << " ";
// 输出一个竖线,用于标记找到的节点在矩形框中的位置
std::cout << "^\n";
// 再输出一些空格,用于画出矩形框的底部
for (int i = 0; i < len; i++) std::cout << " ";
// 输出一个竖线,用于标记矩形框的底部
std::cout << "|\n";
// 如果找到目标值,则返回1,表示成功找到
return 1;
}
// 每遍历一个节点,计数器n加1
n += 1;
// 将指针p移动到下一个节点
p = p->next;
}
// 如果未找到目标值,则返回0,表示未找到
return 0;
}
// 主函数开始
int main() {
// 使用当前时间作为随机数种子,保证每次运行程序时生成的随机数不同
srand(time(0));
// 定义常量MAX_OP为7
#define MAX_OP 7
// 初始化一个空的链表,头节点为nullptr
Node* head = nullptr;
// 循环执行MAX_OP次操作,每次插入一个随机位置的随机值节点到链表中
for (int i = 0; i < MAX_OP; i++) {
// 生成一个随机位置(范围为i+1,保证位置从0开始)和一个随机值(范围为0-99)
int pos = rand() % (i + 1), val = rand() % 100;
// 输出插入操作的信息
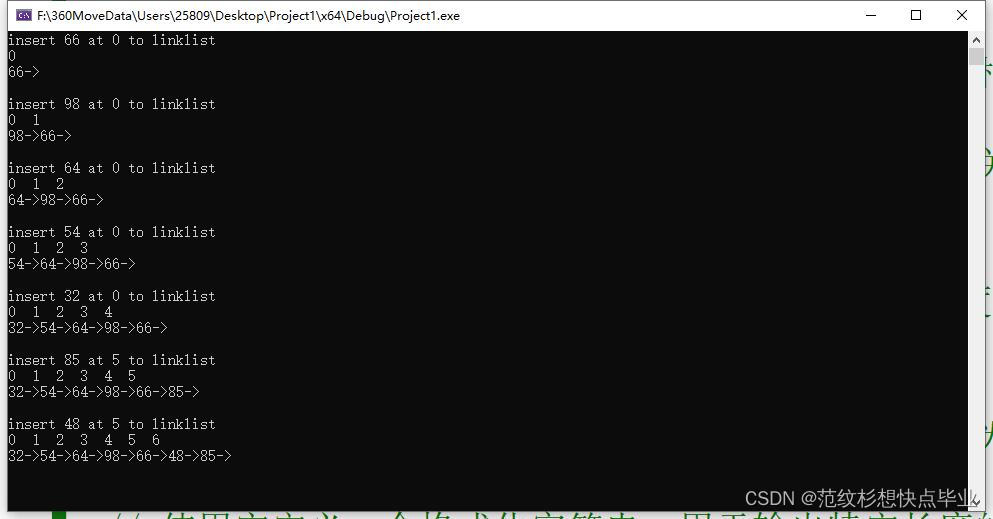
std::cout << "insert " << val << " at " << pos << " to linklist" << std::endl;
// 将新节点插入到指定位置,并更新头节点指针head
head = insert(head, pos, val);
// 输出当前链表的内容
output_linklist(head);
}
// 从标准输入中读取一个整数val
int val;
while (std::cin >> val) {
// 在链表中查找值为val的节点,如果没有找到则返回0,表示未找到
if (!find(head, val)) {
// 如果未找到,则输出not found信息
std::cout << "not found" << std::endl;
}
}
// 清空链表,释放内存空间
clear(head);
// 主函数结束,返回0表示程序正常退出
return 0;
}这段代码实现了一个简单的链表数据结构,并提供了插入、查找和输出链表的功能。
首先,代码中定义了一些宏,其中DL被定义为3,用于表示链表节点中的整数占用的位数。STR(n)用于将一个数值表达式n转换为字符串,DIGIT_LEN_STR(n)用于计算一个整数的位数并转换为字符串。
接下来,定义了一个结构体Node,表示链表的节点。每个节点包含一个整数数据成员data和一个指向下一个节点的指针next。
然后,定义了一个函数getNewNode(int val),用于创建一个新的节点,并初始化其数据成员为给定的值val,并将指针next初始化为nullptr。
接下来,定义了函数insert(Node* head, int pos, int val),用于在链表中插入一个新的节点。该函数首先创建一个新的节点,然后使用一个临时头节点new_head来处理插入位置。它通过循环遍历链表,找到指定位置的前一个节点,然后将新节点插入到该节点之后。最后返回更新后的链表头节点。
接下来,定义了函数clear(Node* head),用于清空链表。该函数通过遍历链表并逐个删除节点来释放内存空间。
接下来,定义了函数output_linklist(Node* head, int flag = 0),用于输出链表的内容。该函数首先计算链表的长度,然后依次输出每个节点的数据和指向下一个节点的箭头符号。如果flag的值为0,则在最后输出一个换行符。
接下来,定义了函数find(Node* head, int val),用于在链表中查找指定的值。该函数遍历链表,如果找到了与给定值相等的节点,则输出该节点及其后的所有节点,并在其前面输出一个标记符号"^"和"|",然后返回1表示找到了目标值。如果遍历完整个链表都没有找到目标值,则返回0表示未找到。
最后,在主函数中,首先使用随机数生成器初始化随机数种子,然后通过循环随机生成插入操作和输出操作。每次循环中,随机生成一个插入位置和插入的值,然后调用insert函数将新节点插入到指定位置,并输出更新后的链表内容。循环结束后,从标准输入中读取一个整数,然后调用find函数在链表中查找该整数。如果找到了目标值,则返回1;否则返回0,表示未找到。
总结起来,这段代码实现了一个简单的链表数据结构,并提供了插入、查找和输出链表的功能。
运行结果