人其实很难抵制诱惑,人只能远离诱惑,所以千万不要高看自己的定力。

文章目录
- 一、LT和ET模式
- 1.理解LT和ET的工作原理
- 2.通过代码来观察LT和ET工作模式的不同
- 3.ET模式高效的原因(fd必须是非阻塞的)
- 4.LT和ET模式使用时的读取方式
- 二、Reactor
- 1.tcpServer.hpp
- 1.1 连接结构体
- 1.2 初始化服务器
- 1.3 事件派发器
- 1.4 回调函数
- 1.5 epoller.hpp
- 2.protocol.hpp
- 2.1 解析出一个完整的报文
- 2.2 应用层协议定制
- 2.3 序列化和反序列化
- 3.main.cc
- 3.1 业务逻辑处理
- 3.2 Reactor服务器运行结果
- 4.总结Reactor模式
一、LT和ET模式
1.理解LT和ET的工作原理
1.
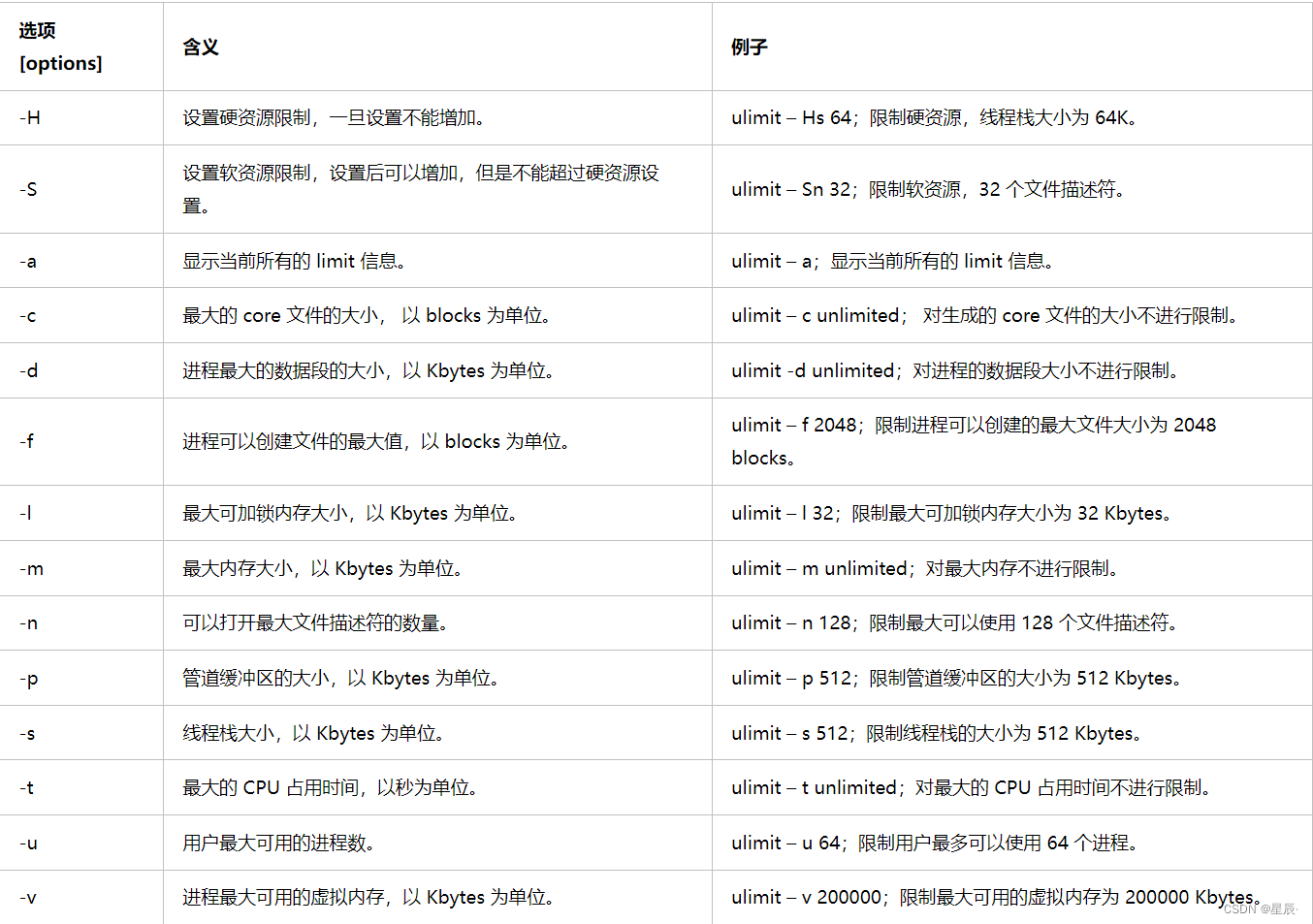
多路转接接口select poll epoll所做的工作其实都是事件通知,只向上层通知事件到来,处理就绪事件的工作并不由这些API来完成,这些接口在进行事件通知时,有没有自己的策略呢?
其实是有的,在网络编程中,select poll 只支持LT工作模式,而epoll除了LT工作模式外,还支持ET工作模式,不同的工作模式对应着不同的就绪事件通知策略,LT模式是这些IO接口的默认工作模式,ET模式是epoll的高效工作模式。
2.
下面来举一个例子帮助大家理解ET和LT模式的区别(送快递的例子)
新上任的快递员小李要给学24宿舍楼的张三送快递,张三买了很多的快递,估摸着有6-7个快递,小李到了学24的楼底,然后就给楼上的张三打电话,通知张三下来拿快递,但是张三正在和他的狐朋狗友开黑打游戏呢,于是张三就嘴上答应着我马上下去,但始终就不下去,老实人小李见张三迟迟不下来拿快递,又给张三打电话,让张三下来拿快递,但张三嘴上又说,我马上下去拿快递,真的马上,但过了一会儿张三依旧还是不下来,小李又只能给张三打电话,张三啊,你的快递到了,你赶快下来取快递吧,终于张三和自己的狐朋狗友推完对面的水晶了,下楼来取快递了,但是张三一个人只拿走了3个快递,还剩下三个快递,张三也没办法了,张三一个人一次只能拿这么多快递啊,于是张三就拿着他的三个快递上楼了,继续和他的舍友开黑打游戏。结果没一会儿,小李又给张三打电话,说张三啊,你的快递没拿完呢,你买了6样东西,你只拿了3样,还剩3个包裹你没拿呢,张三又嘴上说,好的好的,我马上下去拿,但其实又重复着前面的动作,好一会儿才下楼拿走了剩余的3个包裹,当包裹全部被拿走之后,小李才不会给张三打电话了。
老油条快递员小王恰巧也要给学24宿舍楼的张三送快递,恰巧的是,张三这次又买了6个快递,所以小王也碰巧要给张三送6个包裹。小王到了张三楼底下,给张三打了一个电话,说 张三啊,我只给你打一次电话,你现在要是不下来取快递,我后面是不会给你打电话的,除非你又买了新的快递,我手上你的快递数量变多的时候,我才会稍微好心的再给你打一个电话,否则其他情况下,我只会打一次,你要是不下来取快递,那我就不管你了,我给其他客户送快递去了。张三一听,这不行啊,我要是现在不下来取快递,这个快递员以后就不给我打电话了,那我下楼找不到快递员,拿不到我的快递怎么办,所以张三就立马下楼取快递去了。张三一次拿不了这么多快递啊,但张三又不能漏下一些快递,因为小王下一次不会再给张三打电话了,所以张三刚到楼上放下手中的三个快递,又立马返回楼下取走剩余的三个快递了。
3.
在上面的这两个例子中,其实小李的工作模式就是水平触发Level Triggered模式,简称LT模式,小王的工作模式就是边缘触发Edge Triggered模式,简称ET模式,也是多路转接接口高效的模式。
LT对应epoll的工作方式就是,当epoll检测到sock上有就绪的事件时,epoll_wait会立马返回通知程序员事件就绪了,程序员可以选择只读取sock缓冲区的部分数据,剩下的数据暂时不读了,等下次调用recv的时候再读取sock缓冲区中的剩余数据,下次怎么调用recv呢?当然也是通过epoll_wait通知然后再进行调用啦,所以只要sock中的数据程序员没有一次性拿走,那么后续再调用epoll_wait时,epoll_wait依旧会进行就绪事件的通知,告诉程序员来读取sock中的剩余数据,而这样的方式就是LT模式,即只要底层有数据没读完,后续epoll_wait返回时就会一直通知用户读取数据。
而ET对应的工作方式是,如果底层有数据没读完,后续epoll_wait不会通知程序员事件就绪了,只有当底层数据增多的时候,epoll_wait才会再通知一次程序员,否则epoll_wait只会通知一次。
2.通过代码来观察LT和ET工作模式的不同
1.
在前一篇文章中我们写过epoll_server,当然epoll_server的默认工作模式也是LT模式,在下面的代码中我将处理就绪事件的接口HandlerEvent( )屏蔽掉了,当客户端连接到来时,服务器的epoll_wait一定会检测到listensock上的读事件就绪了,所以epoll_wait会返回,告知程序员要处理数据了,但如果程序员一直不处理数据的话,那epoll_wait每次都会告知程序员要处理数据了,所以从显示器的输出结果来看,epoll_wait返回后,根据返回值n,一定是进入到了default分支中,并且每次epoll_wait都会告知程序员事件就绪,所以显示器会一直疯狂打印have events ready,因为只要底层有事件就绪,对于listensock来说,只要内核监听队列有就绪的连接,那就是就绪,epoll_wait就会一直通知程序员事件就绪了,赶快处理吧。(就像小李一样,只要张三不拿走快递,小李就会一直给张三打电话)

2.
在添加listensock到epoll底层的红黑树中时,不仅仅关心listensock的读事件,同时还让listensock的工作模式是ET,只要将EPOLLIN和EPOLLET按位或即可。
所以当连接到来时,可以看到服务器只会打印一次have event ready,只要没有新连接到来,那么epoll_wait只会通知程序员一次事件就绪,除非到来了新连接,那就说明内核监听队列中就绪的连接变多了,换言之就是listensock底层的数据变多了,此时epoll_wait才会再好心提醒一次程序员,事件就绪了,你赶快处理吧。反过来就是,只要后续listensock底层的数据没有增多,那么epoll_wait就不会在通知程序员了。
而由于我们设置的timeout是阻塞式等待,所以你可以看到,只要没有新连接到来,服务器就会阻塞住,epoll_wait调用不会再返回,也就不会再通知程序员。而反观LT模式,虽然每次epoll_wait都是阻塞式等待,但epoll_wait每次都会返回,每次都会告知程序员,这就是两者的不同。边缘触发只会触发一次,水平触发会一直触发。

3.ET模式高效的原因(fd必须是非阻塞的)
1.
为什么ET模式是高效的呢?这是非常重要的一个面试题,许多的面试官在问到网络环节时,都会让我们讲一下select poll epoll各自的用法,epoll的底层原理,三个接口的优缺点,还有就是epoll的两种工作模式,以及ET模式高效的原因,ET模式高效的原因也是一个高频的问题。
2.
ET模式下,只有底层数据从无到有,从有到多的时候,才会通知上层一次,通知的机制就是rbtree+ready_queue+cb,所以ET这种通知机制就会倒逼程序员一次将底层的数据全部读走,如果不一次读走,就可能造成数据丢失,你无法保证对方一定会继续给你发数据啊,如果无法保证这点,那就无法保证epoll_wait还会通知你下一次,如果无法保证这一点,那就有可能你只读取了sock的部分数据,但后续epoll_wait可能不会再通知你了,从而导致后续的数据你永远都读不上来了,所以你必须一次将底层的数据全部读走。
如何保证一次将底层的数据全部读走呢?那就只能循环读取了,如果只调用recv一次,是无法保证一次将底层的数据全部读走的。所以我们可以打个while循环一直读sock接收缓冲区中的数据,直到读取不上来数据,但这里其实就又有一个问题了,如果sock是阻塞的,循环读读到最后一定会没数据,而此时由于sock是阻塞的,那么服务器就会阻塞在最后一次的recv系统调用处,直到有数据到来,而此时服务器就会被挂起,服务器一旦被挂起,那就完蛋了~
服务器被挂起,那就无法运行了,无法给客户提供服务了,这就很有可能造成很多公司盈利上的损失,所以服务器一定不能停下来,更不能被挂起,需要一直运行,以便给客户提供服务。而如果使用非阻塞文件描述符,当recv读取不到数据时,recv会返回-1,同时错误码被设置为EAGAIN和EWOULDBLOCK,这俩错误码的值是一样的,此时就可以判断出,我们一次把底层的数据全部都读走了。
所以在工程实践上,epoll以ET模式工作时,文件描述符必须设置为非阻塞,防止服务器由于等待某种资源就绪从而被挂起。
3.
解释完ET模式下fd必须是非阻塞的原因后,那为什么ET模式是高效的呢?可能有人会说,因为ET模式只会通知一次,倒逼程序员将数据一次全部读走,所以ET模式就是高效的,如果这个问题满分100分的话,你这样的回答只能得到20分,因为你的回答其实仅仅只是答案的引线,真正最重要的部分你还是没说出来。
倒逼程序员一次将数据全部读走,那不就是让上层尽快取走数据吗?尽快取走数据后,就可以给对方发送一个更大的16位窗口大小,让对方更新出更大的滑动窗口大小,提高底层数据发送的效率,更好的使用TCP延迟应答,滑动窗口等策略!!!这才是ET模式高效的最本质的原因!!!
因为ET模式可以更好的利用TCP提高数据发送效率的种种策略,例如延迟应答,滑动窗口等。
之前在讲TCP的时候,TCP报头有个字段叫做PSH,其实这个字段如果被设置的话,epoll_wait就会将此字段转换为通知机制,再通知一次上层,让其尽快读走数据。
4.LT和ET模式使用时的读取方式
二、Reactor
1.tcpServer.hpp
1.1 连接结构体
1.
我们知道socket套接字在通信的时候,每个sock在内核都会创建接收缓冲区和发送缓冲区,这样的缓冲区常常开辟在堆上,不会像临时变量char buffer[1024]随着栈帧空间的销毁而销毁,这能更好的存储网络中收到的数据 和 即将要发送到网络中的数据,如果用栈上的空间来存储网络收发的数据,则数据极有可能被销毁掉,因为只要变量所在栈帧销毁,则变量中的数据在下次变量重新开辟时,就会由原来存储的网络数据变为未初始化过的随机数据了。
所以为了让每个sock都有自己的收发缓冲区,我们不再使用原来编写服务器时,用一个char buffer[1024]来存储sock上的网络数据,而是改用一个Connection结构体来代表一个通信的sock,这个结构体内部包含通信的套接字描述符_sock,以及sock所对应的_inbuffer和_outbuffer。
除此之外,该结构体还包括了三个回调方法_recver,_sender,_excepter,分别表示sock对应的读方法,写方法,异常方法,func_t是一个包装器类型,包装内容为函数指针,返回值是void,参数是Connection指针类型,这三个参数其实就是Reactor反应堆模式的神来之笔所在,后面总结Reactor时,就知道为什么要这么设计Connection了,同时也知道为什么Reactor叫反应堆模式了。实现Reactor网络库,这个Connection是关键所在。
该结构体还包括了一个额外的服务器类型的指针,在某些场景下,比如Connection结构体和TcpServer服务器两个类是分文件的,此时如果在Connection的回调方法中,想要调用一下TcpServer类中的方法时,这个回指指针会帮我们拿到TcpServer中的方法,今天我们是不需要的,因为今天两个类都放到了tcpServer.hpp中
Connection还实现了两个函数,一个是注册函数,一个是关闭sock的函数,注册函数用于将外部实现的sock对应的读方法,写方法,异常方法,注册到sock所在的结构体Connection中。

1.2 初始化服务器
1.
initServer接口还是先将listensock创建出来,将服务器的ip地址和port端口号都bind绑定好,然后设置服务器为监听状态,既然是Reactor网络库,则使用的多路转接接口一定是epoll,所以还需要调用epoll_create创建epoll模型,与sock相同的是,今天的epoll所对应的接口,我们也做了封装,将其单独实现到epoller.hpp中,作为一个组件来使用。
当服务器开始运行时,一定会有大量的Connection结构体对象需要被new出来,那么这些结构体对象需不需要被管理呢?当然是需要的,所以在服务器类里面,定义了一个哈希表_connections,用sock来作为哈希表的键值,sock对应的结构体connection作为键值所对应的value值,也就是哈希桶存储的值,今天是不会出现哈希冲突的,所以每个键值下面的哈希桶只会挂一个value值,即一个Connection结构体.
初始化服务器时,第一个需要被添加到哈希表中的sock,一定是listensock,所以在initServer方法中,先把listensock添加到哈希表里面,添加的同时还要传该listensock所对应的关心事件的方法,对于listensock来说,只需要关注读方法即可,其他两个方法设为nullptr即可。
2.
在AddConnection中,要判断events是否有EPOLLET,如果有,则文件描述符必须是非阻塞,所以要将sock设置为非阻塞,设置的方式也简单,只要通过fcntl来实现即可,同样的,我们把fcntl也封装成了一个SetNonBlock()方法来使用。Reactor中epoll的工作模式是ET,这也是Reactor网络库高效的原因。
接下来就是new一个连接结构体,然后将结构体的字段填充好,比如设置好回调方法的值,结构体中的文件描述符值等等。连接结构体创建好后,我们还需要调用封装好的AddEvent接口,将sock及其关心的事件交给epoll来监视,最后别忘了把new好的结构体交给哈希表来管理。
2.
在代码实现上,给AddConnection传参时,用到了一个C++11的知识,就是bind绑定的使用,一般情况下,如果你将包装器包装的函数指针类型传参给包装器类型时,是没有任何问题的,因为包装器本质就是一个仿函数,内部调用了被包装的对象的方法,所以传参是没有任何问题的。
但如果你要是在类内传参,那就有问题了,会出现类型不匹配的问题,这个问题真的很恶心,而且这个问题一报错就劈里啪啦的报一大堆错,因为function是模板,C++报错最恶心的就是模板报错,一报错人都要炸了。话说回来,为什么是类型不匹配呢?因为在类内调用类内方法时,其实是通过this指针来调用的,如果你直接将Accepter方法传给AddConnection,两者类型是不匹配的,因为Accepter的第一个参数是this指针,正确的做法是利用包装器的适配器bind来进行传参,bind将Accepter进行绑定,前两个参数为绑定的对象类型 和 给绑定的对象所传的参数,因为Accepter第一个参数是this指针,所以第一个参数就可以固定传this,后面的一个参数不应该是现在传,而应该是调用Accepter方法的时候再传,只有这样才能在类内将类成员函数指针传给包装器类型。
不过吧还有一种不常用的方法,就是利用lambda表达式来进行传参,lambda可以捕捉上下文的this指针,然后再把lambda类型传给包装器类型,这种方式不常用,用起来也怪别扭的,function和bind是适配模式,两者搭配在一起用还是更顺眼一些,lambda这种方式了解一下就好。

1.3 事件派发器
1.
事件派发器是真正服务器要开始运行了,服务器会将就绪的每个连接都进行处理,首先如果连接不在哈希表中,那就说明这个连接中的sock还没有被添加到epoll模型中的红黑树,不能直接进行处理,需要先添加到红黑树中,然后让epoll_wait来拿取就绪的连接再告知程序员,这个时候再进行处理,这样才不会等待,而是直接进行数据拷贝。
Loop中处理就绪的事件的方法非常非常的简单,如果该就绪的fd关心的是读事件,那就直接调用该sock所在连接结构体内部的读方法即可,如果是写事件那就调用写方法即可。有人说那如果fd关心异常事件呢?其实异常事件大部分也都是读事件,不过也有写事件,所以处理异常的逻辑我们直接放到读方法和写方法里面即可,当有异常事件到来时,直接去对应的读方法或写方法里面执行对应的逻辑即可。
假设某个异常事件发生了,那么这个异常事件会自动被内核设置到epoll_wait返回的事件集中,这个异常事件一定会和一个sock关联,比如客户端和服务器用sock通信着,突然客户端关闭连接,那么服务器的sock上原本关心着读事件,此时内核会自动将异常事件设置到该sock关心的事件集合里,在处理sock关心的读事件时,读方法会捎带处理掉这个异常事件,处理方式为服务器关闭通信的sock,因为客户端已经把连接断开了,服务器没必要维护和这个客户端的连接了,服务器也断开就好,这样的逻辑在读方法里面就可以实现。
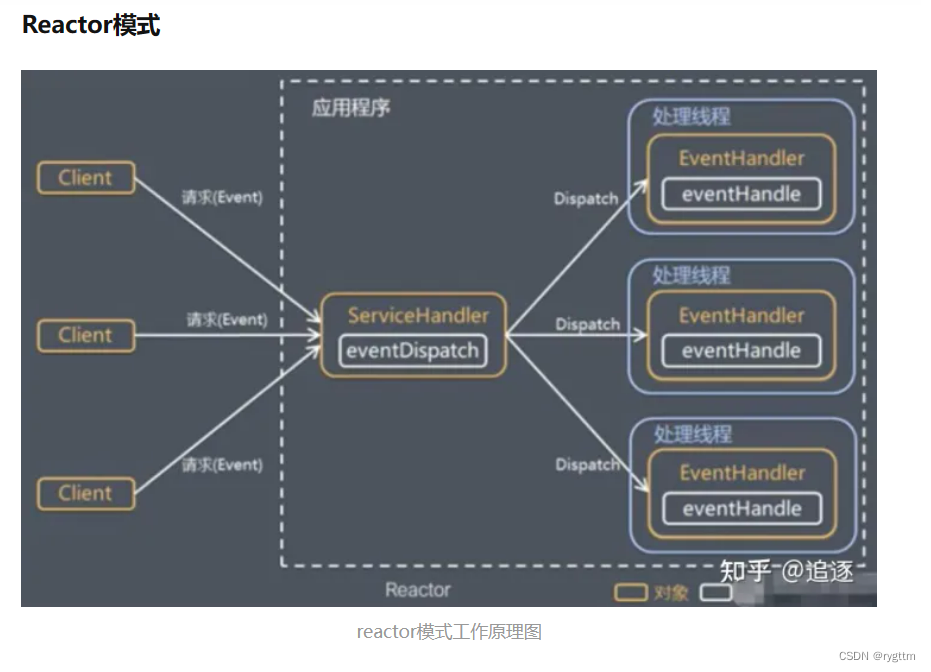
2.
像下面这样的事件派发器就是典型的Reactor反应堆模式,当连接到来时,直接调用对应的sock所在Connection中的回调方法来进行处理即可,这就像是化学反应一样,当连接请求或通信的网络数据到来时,代码就像产生化学反应一样,自动调用连接对应的listensock 或 通信对应的sock所在的方法进行处理即可,就像是一个化学反应堆,这也是为什么这样的网络库叫Reactor的原因,因为每个sock都有自己对应的读 写 异常方法。
listensock对应的_recver方法就是Accepter函数,通信sock对应的_recver方法就是Recver函数,通信sock对应的_sender方法就是Sender函数。

1.4 回调函数
1.
当listensock底层有连接到来时,epoll_wait告知程序员有事件到来后,则应该调用listensock对应的_recver回调方法,这个回调方法,在将listensock添加到连接结构体时,我们就已经将Accepter绑定给listensock的_recver回调方法了。
进入Accepter之后就开始读取listensock的底层连接了,但你能保证一次就把listensock底层的数据全部读取上来吗?你accept系统调用,一次最多就只能拿取一个连接,万一listensock底层有很多连接呢?今天epoll是ET模式,如果你只读取一次的话,且恰好后面没有新连接到来呢?那没有被拿取上来的连接所对应的客户端就无法和服务器通信了,这个问题就是你服务器产生的,我客户端和你好好的通信着,结果你服务器不受理我的连接请求,那就说明你服务器代码有bug。
所以在Accepter中必须循环读取listensock底层的数据,确保一次将listensock底层的数据全部读走,所以Accepter中必须得打死循环进行读取,循环读我们也不怕服务器被挂起,因为ET模式下所有的文件描述符都被我们设置成了非阻塞,当accept拿上来通信的连接后,下一步要做的就是将这个连接添加到_connections哈希表中,在AddConnection中,会构建sock对应的connection结构体,然后将结构体中的字段填充好,将回调方法设置到结构体的成员变量里面,另外AddConnection中还会将sock和其关心的事件设置到epoll模型的红黑树当中,让epoll帮忙监视程序员所关心的fd的就绪情况。
对于listensock来讲,只关心读事件,所以在给AddConnection传参的时候,后两个方法就不传了,但对于通信的sock来讲,后两个方法将来也是要调用的,所以也要传,这里在传参的时候,由于参数是成员函数,所以也要使用bind固定参数的方式来进行传参。
当accept系统调用返回值小于0,同时错误码被设置为EAGAIN或EWOULDBLOCK时,则说明accept已经将本轮listensock下就绪的数据全部读完了,此时就可以break跳出死循环了。如果错误码被设置为EINTR,则说明进程可能由于执行某种到来信号对应的handler方法,导致这里的accept系统调用被中断,则此时应该继续循环读取listensock底层的数据,所以直接continue即可,还有另一种可能,就是accept系统调用真的出错了,此时的做法也break跳出循环即可。

2.
Recver这里还是和之前一样的问题,也是前面在写三个多路转接接口服务器时,一直没有处理的问题,你怎么保证你一次就把所有数据全部都读上来了呢?如果不能保证,那就和Accepter一样,必须打死循环来进行读取,当recv返回值大于0,那我们就把读取到的数据先放入缓冲区,缓冲区在哪里呢?其实就在conn参数所指向的结构体里面,结构体里会有sock所对应的收发缓冲区。然后就调用外部传入的回调函数_service,对服务器收到的数据进行应用层的业务逻辑处理。
当recv读到0时,说明客户端把连接关了,那这就算异常事件,直接回调sock对应的异常处理方法即可。
当recv的返回值小于0,同时错误码被设置为EAGAIN或EWOULDBLOCK时,则说明recv已经把sock底层的数据全部读走了,则此时直接break跳出循环即可,也有可能是被信号给中断了,则此时应该继续执行循环,另外一种情况就是recv系统调用真的出错了,则此时也调用sock的异常方法进行处理即可。
业务逻辑处理方法应该在本次循环读取到所有的数据之后再进行处理。

3.
之前写服务器时,我们从来没处理过写事件,写事件和读事件不太一样,关心读事件是要常设置的,但写事件一般都是就绪的,因为内核发送缓冲区大概率都是有空间的,如果每次都要让epoll帮我们关心读事件,这其实是一种资源的浪费,因为大部分情况下,你send数据,都是会直接将应用层数据拷贝到内核缓冲区的,不会出现等待的情况,而recv就不太一样,recv在读取的时候,有可能数据还在网络里面,所以recv要等待的概率是比较高的,所以对于读事件来说,常常都要将其设置到sock所关心的事件集合中。
但写事件并不是这样的,写事件应该是偶尔设置到关心集合中,比如你这次没把数据一次性发完,但你又没设置该sock关心写事件,当下次写事件就绪了,也就是内核发送缓冲区有空间了,epoll_wait也不会通知你,那你还怎么发送剩余数据啊,所以这个时候你就应该设置写事件关心了,让epoll_wait帮你监视sock上的写事件,以便于下次epoll_wait通知你时,你还能够继续发送上次没发完的数据。
这个时候可能有人会问,ET模式不是只会通知一次吗?如果我这次设置了写关心,但下次发送数据的时候,还是没发送完毕(因为内核发送缓冲区可能没有剩余空间了),那后面ET模式是不是就不会通知我了呀,那我还怎么继续发送剩余的数据呢?ET模式在底层就绪的事件状态发生变化时,还会再通知上层一次的,对于读事件来说,当数据从无到有,从有到多状态发生变化时,ET就还会通知上层一次,对于写事件来说,当内核发送缓冲区剩余空间从无到有,从有到多状态发生变化时,ET也还会通知上层一次,所以不用担心数据发送不完的问题产生,因为ET是会通知我们的。
在循环外,我们只需要通过判断outbuffer是否为空的情况,来决定是否要设置写事件关心,当数据发送完了那我们就取消对于写事件的关心,不占用epoll的资源,如果数据没发送完,那就设置对于写事件的关心,因为我们要保证下次写事件就绪时,epoll_wait能够通知我们对写事件进行处理。

4.
下面是异常事件的处理方法,我们统一对所有异常事件,都先将其从epoll模型中移除,然后关闭文件描述符,最后将conn从哈希表_connecions中移除。
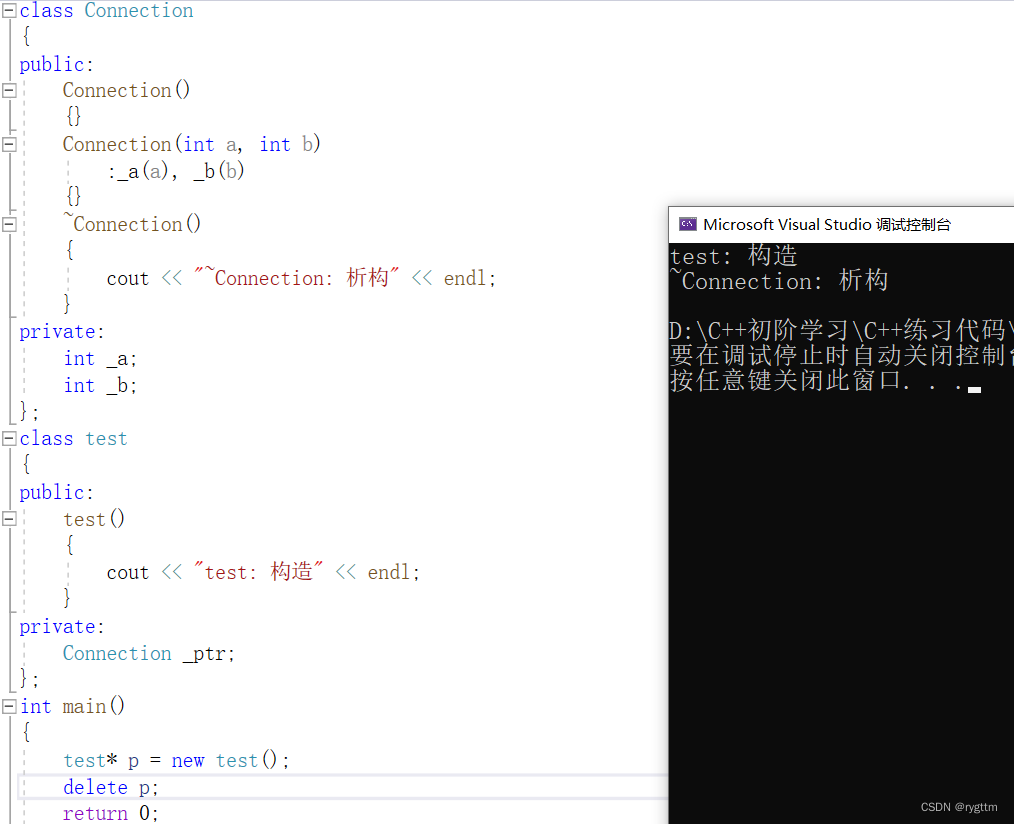
值得注意的是,conn指针指向的连接结构体空间,必须由我们自己释放,有人说,为什么啊?你哈希表不是都已经erase了么?为什么还要程序员自己再delete连接结构体空间呢?
这里要给大家说明一点的是,所有的容器在erase的时候,都只释放容器自己所new出来的空间,像哈希表这样的容器,它会new一个节点,节点里面存储着conn指针和指向下一个节点的指针,当调用哈希表的erase时,哈希表只会释放它自己new出来的节点空间,至于这个节点空间里面存储了一个Connection类型的指针,并且这个指针变量指向一个结构体空间,这些事情哈希表才不会管你呢,容器只会释放他自己开辟的空间,这个空间里面放着一个指针变量,还有可能有其他变量,那容器就只会释放这些变量所在结构体的空间,这个结构体一定是容器开辟出来用于存放使用者希望存储的一些东西,比如今天的Connection指针,当然也有可能存储其他变量,对于哈希表来说,还可能存储链表节点类型的指针,因为哈希表是vector挂单链表的方式来实现的。
所以我们要自己手动释放conn指向的空间,如果你不想自己手动释放conn指向的堆空间资源,则可以存储智能指针对象,这样在哈希表erase时,其实就是delete存储Connection类型指针的结构体,这样就会调用该结构体的析构函数,像这样的结构体内部的析构函数,我们是不会自己写的,直接使用编译器默认生成的即可,编译器对内置类型不处理,对自定义类型会调用该类的析构函数,也就是调用智能指针对象的析构函数,在析构函数内部就会释放conn所指向的连接结构体的动态内存了。
这样搞起来其实还是很麻烦的,所以我们就自己手动释放就好了,如果不手动释放那就会造成内存泄露。

5.
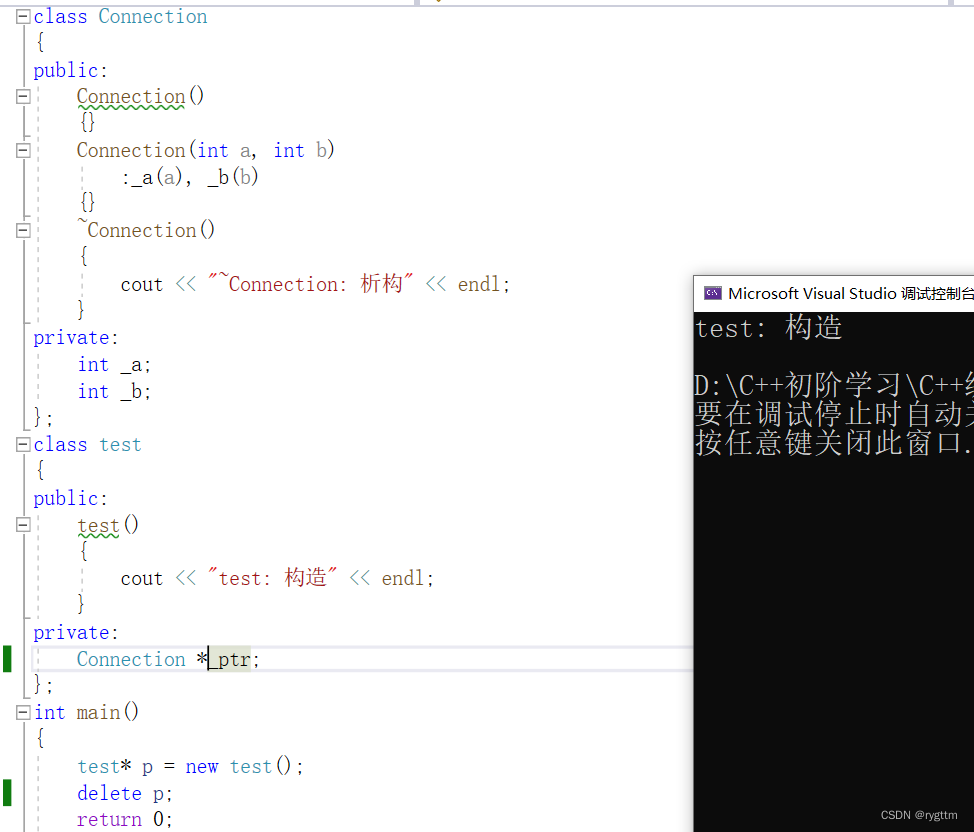
下面这篇文章的第五部分的第二个标题,讲述了编译器默认生成的析构函数对于对象的成员变量的处理策略,对于内置类型不处理,对于自定义类型会调用该类的析构函数。
值得注意的是,就算是自定义类型的指针,他其实也是被编译器当作内置类型了,并不会调用指针类型的析构函数。
当析构函数被调用完毕之后,delete的目标堆空间就会被释放,归还给操作系统。
【C++】类和对象核心总结
下面是当指针为自定义类型时,编译器默认生成的析构函数不会调用对应的析构函数,和内置类型处理策略一样的证明过程。
1.5 epoller.hpp
下面是封装的epoll的各个接口,没什么难度,我这里也不会赘述,因为之前我们已经写过简单版的LT模式epoll服务器了,对于epoll接口的使用肯定没什么难度了,所以屏幕前的老铁们可以简单看一下代码实现,今天的重点是前面Reactor的实现,不是这些小组件是怎么实现的。

2.protocol.hpp
2.1 解析出一个完整的报文
1.
其实在tcpServer.hpp讲解完毕之后,Reactor网络库的重点就已经实现完毕了,也就是网络IO层面上的处理连接到来,处理网络数据传输的工作,已经大功告成了。
下面的protocol.hpp只是在Reactor网络库的基础上接入了服务器的应用层,比如如何处理黏包问题,应用层如何定制协议,添加或去掉应用层协议报头,对报文的序列化和反序列化等等工作全部都属于应用层的事情。
但其实早在以前我们讲协议定制和序列化反序列化的时候,也就是实现网络版本计算器的时候,我们就已经实现过这些工作了,所以protocol.hpp就是从当时的代码直接拷贝过来的,仅仅只是对解析报文这个代码作了修改。
所以如果有老铁忘记了当时怎么定制的协议,那就可以回头再重新看看当时的文章。
协议定制+序列化和反序列化
2.
下面的接口是用来解析sock在应用层的_inbuffer数据的,由于TCP是面向字节流的,所以如何解析出一个完整报文的问题,就必须由应用层来做。
我们当时定过协议,协议报头和有效载荷之间有LINE_SEP也就是\r\n,有效载荷的尾部也\r\n,协议报头表示有效载荷的字节大小,所以在字节流的_inbuffer中,解析出一个完整报文的逻辑就可以是这样的:
为了安全起见,先把输出型参数text设置为空串,然后在inbuffer中找LINE_SEP的迭代器位置,找到之后,将报头部分substr截取出来,再将其stoi转换为整数,这样就得到了有效载荷的大小,然后再将截取出来的报头,调用其类内函数size(),得到报头的字节大小,最后再加上两个LINE_SEP的大小,这些字节大小作和之后,就可以得到一个完整报文的字节大小了。
最后一步就是直接从0开始截取total_len大小个字节,将截取到的字串放到输出型参数text里面即可。然后再将0到total_len字节的数据从inbuffer中删除即可,其实就是覆盖数据。这样我们就从大批的字节流数据中截取出了一个完整的报文。

2.2 应用层协议定制
其实关于应用层协议的这些代码在之前网络版本计算器都已经讲过了,这里我就言简意赅的说一下,如果有懵逼的老铁,请移步我原来写的那篇文章。
移步:协议定制+序列化和反序列化
1.
下面是应用层报头的添加与去除,报头添加时,其实只要在报头和有效载荷间,以及有效载荷尾部,都加上LINE_SEP,报头的内容就是有效载荷的长度。
报头去除时,先以第一个LINE_SEP作为分隔符,截取头部字符串,这样就得到了有效载荷的长度大小,然后从第一个LINE_SEP位置开始截取子串,截取长度为有效载荷的长度即可,这样就得到了完整的有效载荷。

2.3 序列化和反序列化
1.
下面是序列化反序列化的工作,主要用到的就是我们自己写的方案和json的方案,企业内部自己一般会使用protobuf,对外使用json。json我也不会,只能简单的使用一下,没有系统的学过,所以下面我只能说说我们自己的序列化和反序列化方案,不过值得注意的是,实际在公司使用中,对于序列化和反序列化是有现成的解决方案的,程序员绝对不会自己去写!但今天我们作为学习者自己写肯定更能理解序列化和反序列化究竟是作的一个什么样的工作,对学习者肯定是大有好处的。
2.
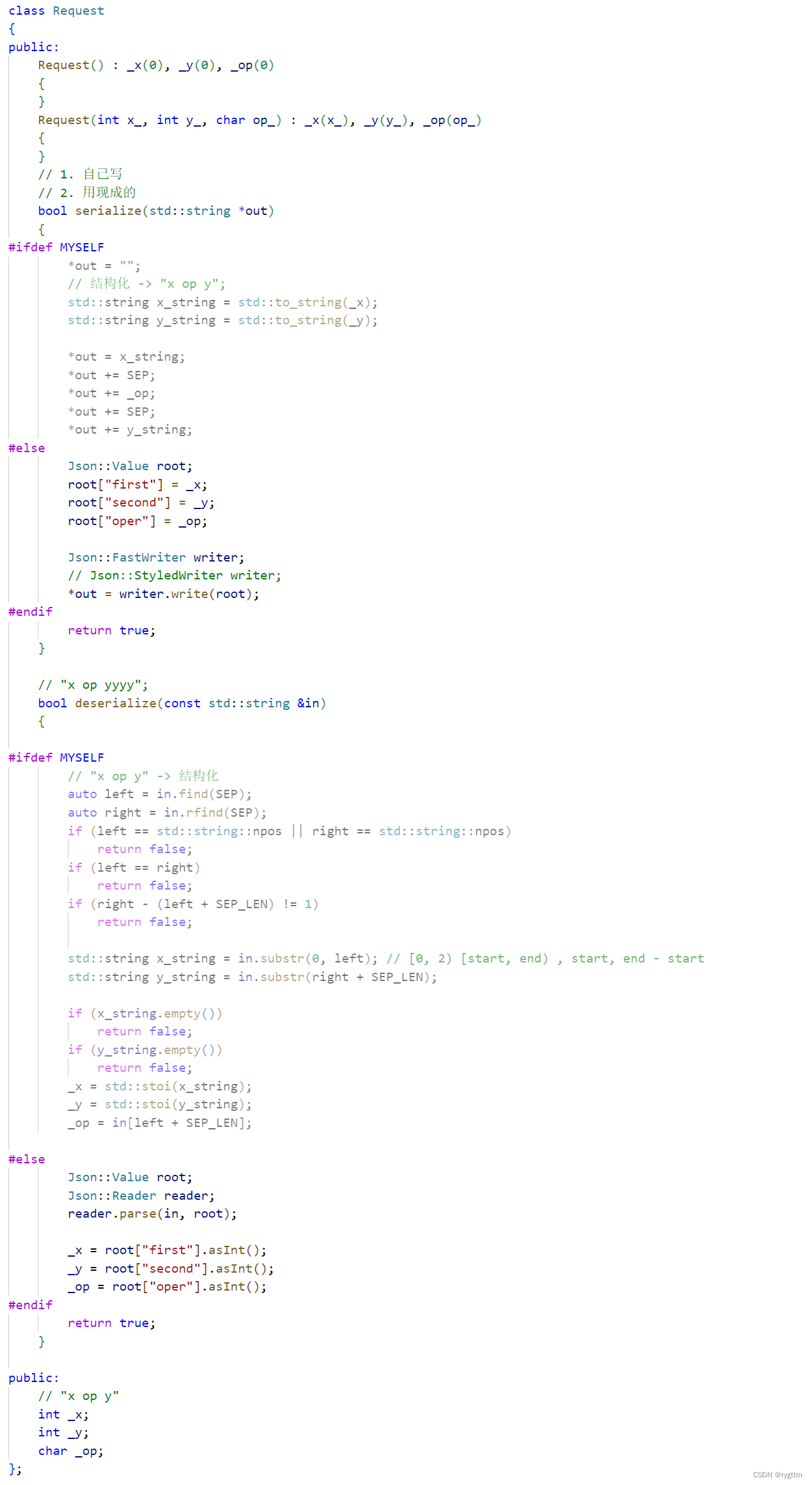
对于请求报文的序列化,其实就是将结构体Request中的_x _op _y等字段都拼接成一个字符串,这样就完成了序列化的工作,但不是仅仅序列化就完了,能序列化就一定得能反序列化,所以,在拼接字符串时,_x和_op,_op和_y之间都得有一个SEP作为分隔符,方便对到来的请求报文进行反序列化。(结构化数据 → 字节流数据)
反序列化其实主要就是字符串操作,将字符串中的_x _y _op截取出来,分别转换为int int char类型,赋值给结构体Request的三个成员变量里面,这样就完成了反序列化的工作。(字节流数据 → 结构化数据)
3.
对于响应报文的序列化,只要将int类型的退出码和计算结果转换为string类型,中间在拼接一个SEP字段,这样就从结构化转为了序列化的数据。
反序列化的工作也很简单,只要将字符串中的退出码和结果部分截取子串出来,然后再将其转为int类型,这样就从序列化转为了结构化的数据。

3.main.cc
3.1 业务逻辑处理
1.
下面是整个Reactor服务器的调用逻辑,先初始化服务器,然后执行事件派发接口Dispatcher。
服务器的应用层提供的服务是计算服务,所以在构建服务器对象时,要将上层的处理逻辑函数calculate也传到服务器对象内部。
在服务器执行Recver方法时,收到数据后,会调用回调函数,执行流就会执行calculate方法,进行读到的数据的业务处理。

2.
calculate就是业务逻辑处理方法,在方法内部打一个while循环,只要能够解析出一个完整的报文,那就可以进入循环,对拿到的报文作应用层的逻辑处理,当_inbuffer中的数据被拿的导致剩余数据无法构成一个完整报文时,也就是ParseOnePackage出错时,我们此时选择退出循环,将已经处理好的请求报文,也就是构建出了响应报文全部发送到客户端,有人说怎么把全部的响应报文发送给客户端呢?其实很简单,在ParseOnePackage内部每次处理好一个请求报文后,相对应的响应报文会被放到conn内部的发送缓冲区_outbuffer中,所以当跳出循环时,_outbuffer中已经存放了很多就绪的响应报文了,此时只要在调用conn内部的sender方法进行发送即可。所以这么来看的话,这个conn是不是很有用呢?整个贯穿了Reactor代码实现的所有模块。
在ParseOnePackage内部也很简单,因为我们在protocol.hpp内部已经将请求/响应报文的序列化反序列化,应用层报文的报头和有效载荷分离,添加报头等工作全部做好了,所以在ParseOnePackage内部只需要调用对应protocol.hpp内部实现的方法即可。比如先去掉报头,然后调用反序列化接口得到一个结构化的请求,将结构化的请求和一个未初始化的结构化响应进行cal处理,在cal处理内部其实就是作相应的计算工作,计算工作完成后,将结果填充到结构化的响应报文中即可,然后对响应报文作序列化,添加报头等工作,最后只要将完整的响应报文放到outbuffer中即可,等到循环结束时,统一将所有的响应报文发送给对方。

3.2 Reactor服务器运行结果
1.
客户端我们自己也就不写了,之前讲协议定制的时候,我们自己已经实现过calclient和calserver了,所以这里直接拿calclient作为客户端来使用。
从运行结果可以看出,正常的数据计算请求,服务器是能够给我们返回对应的计算结果的,并且当客户端发生异常时,比如ctrl+c断开TCP连接,服务器也能够对异常事件做出相对应的处理,比如服务器也关闭对应的tcp连接,同时释放sock对应的所有资源,例如sock对应的connection结构体,将sock移除epoll模型,移除哈希表,关闭sock文件描述符等处理。

4.总结Reactor模式
1.
我个人对于Reactor的理解,Reactor主要围绕事件派发和自动反应展开的,就比如连接请求到来,epoll_wait提醒程序员就绪的事件到来,应该尽快处理,则与就绪事件相关联的sock会对应着一个connection结构体,这个结构体我觉得就是反应堆模式的精华所在,无论是什么样就绪的事件,每个sock都会有对应的回调方法,所以处理就绪的事件很容易,直接回调connection内的对应方法即可,是读事件就调用读方法,是写事件就调用写方法,是异常事件,则在读方法或写方法中处理IO的同时,顺便处理掉异常事件。
所以我感觉Reactor就像一个化学反应堆,你向这个反应堆里面扔一些连接请求,或者网络数据,则这个反应堆会自动匹配相对应的处理机制来处理到来的事件,很方便,同时由于ET模式和EPOLL,这就让Reactor在处理高并发连接时,展现出了不俗的实力。
2.
我们今天所实现的服务器是半同步半异步的,半同步是说Reactor既保证了就绪事件的通知,同时又负责了IO,半异步指的是,今天的服务器还实现了业务处理。