如何关闭一个 TCP 连接
可能大家第一反应是「杀掉进程」不就行了吗?
是的,这个是最粗暴的方式,杀掉客户端进程和服务端进程影响的范围会有所不同:
• 在客户端杀掉进程的话,就会发送 FIN 报文,来断开这个客户端进程与服务端建立的所有 TCP 连接,这种方式影响范围只有这个客户端进程所建立的连接,而其他客户端或进程不会受影响。
• 而在服务端杀掉进程影响就大了,此时所有的 TCP 连接都会被关闭,服务端无法继续提供访问服务。
所以,关闭进程的方式并不可取,最好的方式要精细到关闭某一条 TCP 连接。
有一种思路是伪造一个四元组相同的 RST 报文,RST表示重置。在TCP/IP协议中,RST是TCP连接中一种重要的报文标志,用于终止连接或重置连接。当TCP连接发生问题时,需要使用一些特殊的标志来控制连接状态。在TCP协议中,当一条TCP连接需要中断时,可以发送一个带有RST标志的TCP报文,以重置连接并终止数据传输。
「伪造 RST 报文来关闭 TCP 连接」,也叫TCP 重置攻击。
tcp重置攻击是用伪造的Tcp重置包干扰用户和网站的连接
要伪造一个有用的 RST 报文,关键是要拿到对方下一次期望收到的序列号。
有两个关闭一个 TCP 连接的工具:tcpkill 和 killcx。
这两个工具都是通过伪造 RST 报文来关闭指定的 TCP 连接,但是它们拿到正确的序列号的实现方式是不同的。
• tcpkill 工具是在双方进行 TCP 通信时,拿到对方下一次期望收到的序列号,然后将序列号填充到伪造的 RST 报文,并将其发送给对方,达到关闭 TCP 连接的效果。
什么是线程同步
线程同步,指一个线程发出某一功能调用时,在没有得到结果之前,该调用不返回。同时其它线程为保证数据一致性,不能调用该功能。 线程同步简单说就是线程排队

工作内存和主内存
主内存是Java内存模型的一部分,是多个线程共享的内存区域。Java程序中的每个变量都存储在主内存中。工作内存是每个线程私有的内存区域。每个线程都有自己的工作内存,线程之间不能直接访问对方的工作内存。
我们在Java中开启一个线程,最终也是交给CPU去执行。 具体的流程是:我们在使用Java线程,内部会调用操作系统(OS)的内核线程(Kernel-Level Thread),这种线程是操作系统内核(Kernel)直接支持的,内核通过调度器,对线程进行调度,并将线程交给各个CPU内核去处理。
Java内存模型规定了所有对共享变量的读写操作都必须在本地内存中进行,需要先从主内存中拿到数据,复制到本地内存,然后在本地内存中对数据进行修改,再刷新回主内存。
单核cpu上多线程仍然会存在线程安全问题,因为单核cpu仍然存在线程切换,在执行非原子操作的时候,仍然存在线程问题,比如i++操作。
单核多线程指的是单核CPU轮流执行多个线程,通过给每个线程分配CPU时间片来实现,只是因为这个时间片非常短(几十毫秒),所以在用户角度上感觉是多个线程同时执行.
在单核 CPU 上,多线程实际上是通过时间片轮转算法来实现的,即操作系统将 CPU 时间划分成多个时间片,每个线程在一个时间片内执行一段时间,然后被操作系统挂起,切换到另一个线程继续执行,如此往复,直到所有线程都执行完毕。
阻塞和等待的区别
sleep()方法是定义在Thread上的native方法, 在设定时间段内(精度取决于CPU)阻塞线程的执行, 但是并不更改线程的锁持有情况.
wait/notify机制
wait()方法是定义在Object上的方法, 是java语言级的方法, 需要在同步块或者同步方法中进行调用, 会释放锁, 并进入锁对象的等待队列, 需要等到其他线程调用notify()方法释放锁后(实际上该线程同步块运行结束后才会释放锁), 重新竞争锁.
进入waiting状态是线程主动的, 而进入blocked状态是被动的. 阻塞原则上是为了解决同一个资源竞争(修改)而存在的,而等待是为了多线程间通信而设计的。
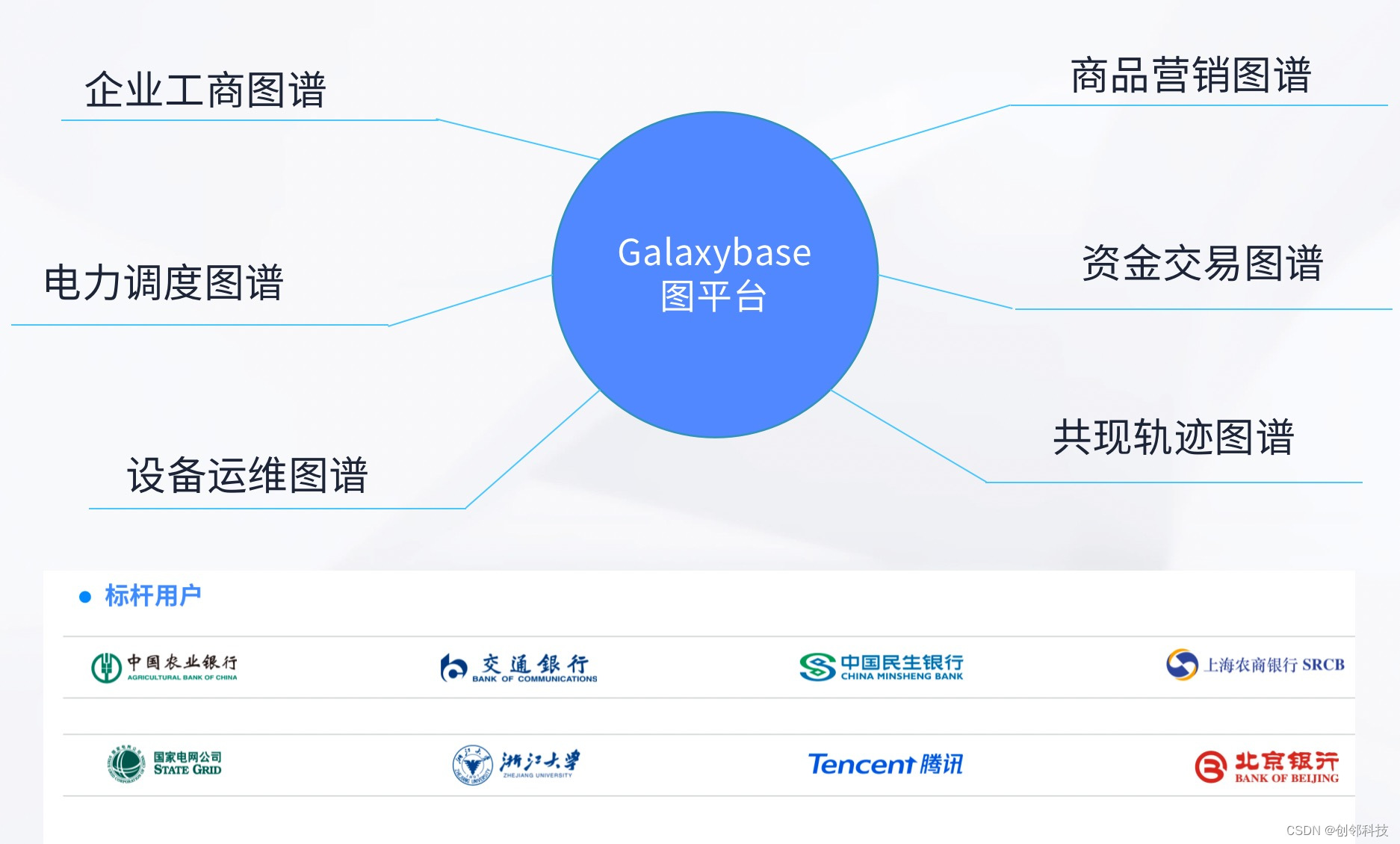
b树的查找
B 树的子树大小排序规则,因此在 B 树中查找数据时,一般需要这样:
从根节点开始,如果查找的数据比根节点小,就去左子树找,否则去右子树
和子树的多个关键字进行比较,找到它所处的范围,然后去范围对应的子树中继续查找
以此循环,直到找到或者到叶子节点还没找到为止
3阶的B-Tree的查找过程:
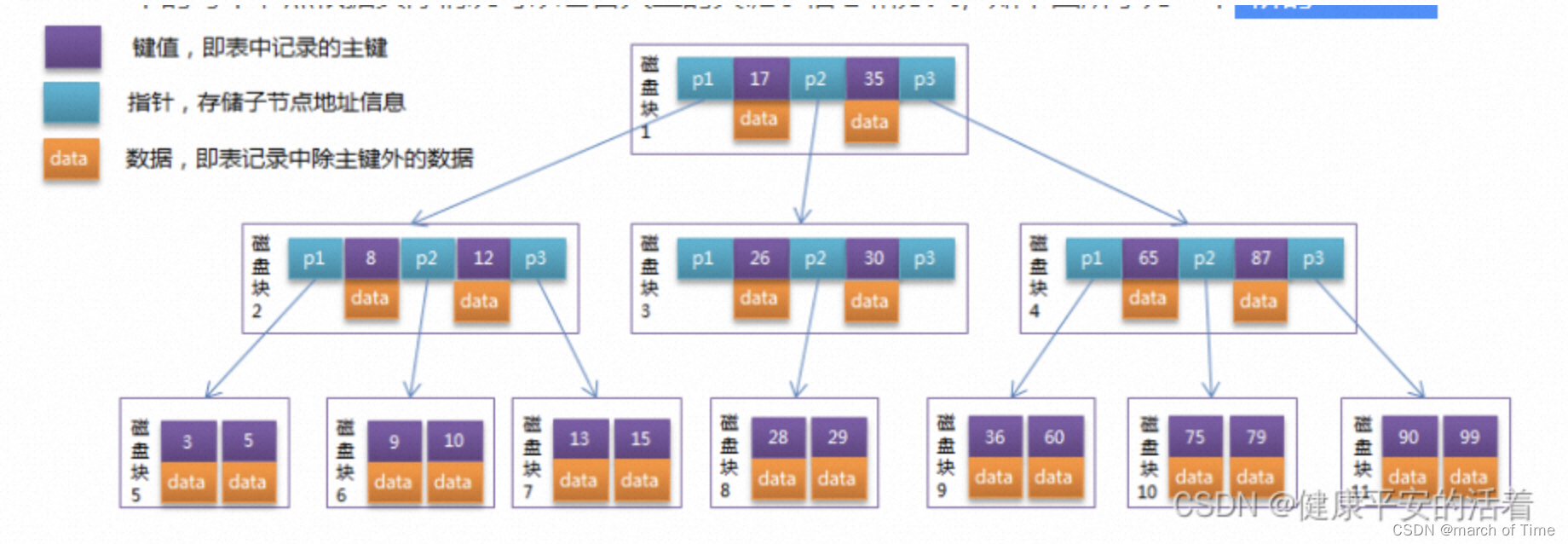
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
4 阶 B 树表示每个节点最多有 4 个子树、3 个关键字,最少有 2 个子树、一个关键字。
在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。(可以理解为父辈点那一层只存储索引,可以存储更多的信息,父辈基数大,下一级的子节点存储数据就可以存储多个数据,多个数据快;高度变低了,上一辈基数大,下一辈孩子多)
b+树:
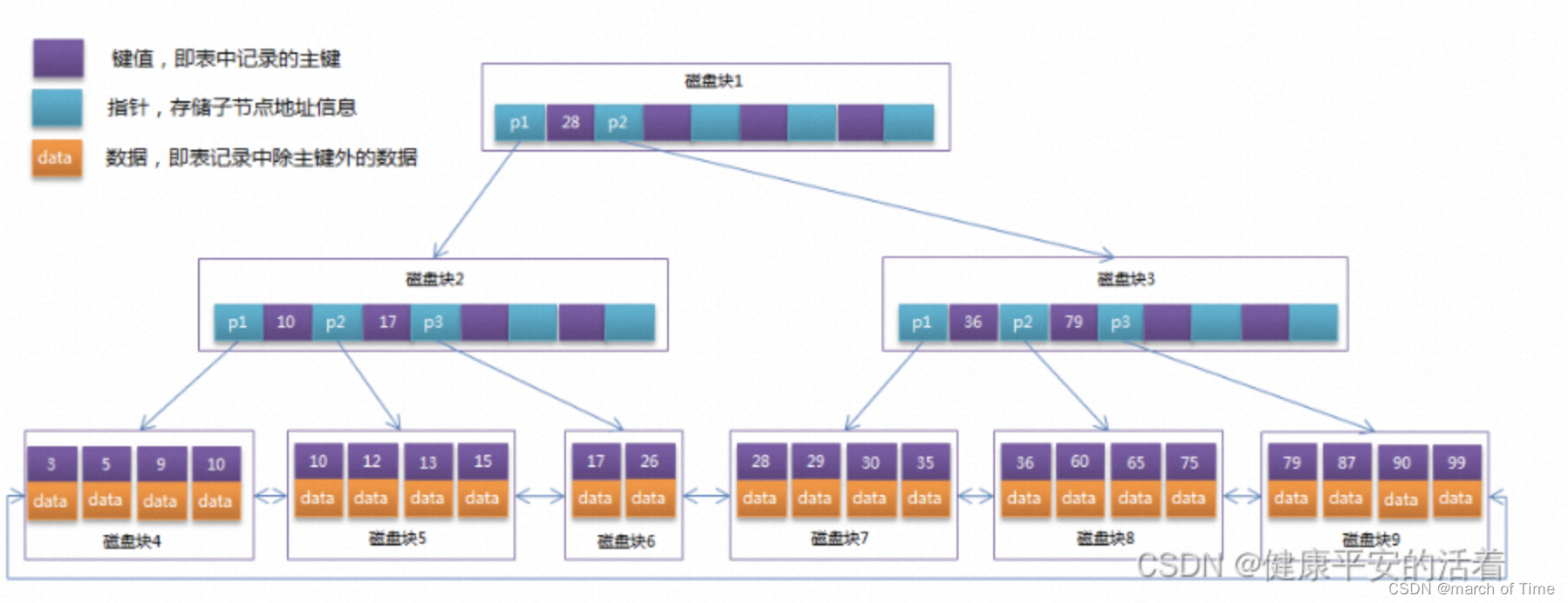
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找
B+Tree的特点
1.关键字数和子树相同(B 树是关键字数比子树数少一)
在 B 树中,节点的关键字用于在查询时确定查询区间,因此关键字数比子树数少一;而在 B+ 树中,节点的关键字代表子树的最大值,因此关键字数等于子树数。
2.非叶子节点仅用作索引,它的关键字和子节点有重复元素。所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。除叶子节点外的所有节点的关键字,都在它的下一级子树中同样存在,最后所有数据都存储在叶子节点中。
根节点的最大关键字其实就表示整个 B+ 树的最大元素。
3.叶子节点用指针连在一起
叶子节点包含了全部的数据,并且按顺序排列,B+ 树使用一个链表将它们排列起来,这样在查询时效率更快。
由于 B+ 树的中间节点不含有实际数据,只有子树的最大数据和子树指针,因此磁盘页中可以容纳更多节点元素,也就是说同样数据情况下,B+ 树会 B 树更加“矮胖”,因此查询效率更快。(父一辈基数大,这一辈孩子就多,就能实现人口数据多,相比父辈基数少,这一辈孩子也会少,需要迭代好3,4代才能实现人口变多,增加迭代次数,相对于这里磁盘I/0的次数)
4.B+ 树的查找必会查到叶子节点,更加稳定。有时候需要查询某个范围内的数据,由于 B+ 树的叶子节点是一个有序链表,只需在叶子节点上遍历即可,不用像 B 树那样挨个中序遍历比较大小。