文章目录
- 1. 找到字符串中所有字母异位词
- 做法一:采用两个数组分别记录字符出现频次
- 做法二:采用diff记录s和p字符串中字符的频次差
- 2. 串联所有单词的子串
- 个人理解,如有异议,欢迎指正!
1. 找到字符串中所有字母异位词
题目链接
两种做法统一思想:
- 字母异位词:只要两个字符串中的字母出现频次是相同的,就代表是字母异位词。
- 为了区分是s中独有的,还是p中独有的,s中的在记录频次时++,p中的记录时–,数组中±抵消为0时代表着这个字符是都有的,也就是满足情况的。
- s记录频次的次数是以p的长度,也就是p的记录频次次数一致。
做法一:采用两个数组分别记录字符出现频次
如果两个数组中字符映射的频次相同的话,代表着是字母异位词。
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int slen=s.size();
int plen=p.size();
if(slen<plen)
return vector<int>();
vector<int>ans;
vector<int>sCount(26);
vector<int>pCount(26);
//分别记录频次,只不过要以p的长度为准
for(int i=0;i<plen;i++)
{
++sCount[s[i]-'a'];
++pCount[p[i]-'a'];
}
if(sCount==pCount)
{
ans.emplace_back(0);
}
for(int i=0;i<slen-plen;i++)
{
--sCount[s[i]-'a'];//滑动窗口左边界右移一个,自然要将去掉的那一个的字母频次--
++sCount[s[i+plen]-'a'];//滑动窗口右边界右移一个,自然要将新添加的那一个的字母频次++
if(sCount==pCount)
ans.emplace_back(i+1);
}
return ans;
}
};
做法二:采用diff记录s和p字符串中字符的频次差
我们不用两个数组映射,只需要一个,并且添加diff记录±抵消情况。如果抵消结果是0,就代表是字母异位词。
经历窗口移动之后由不同词频变成相同词频,也就是代码中的从1->0,-1->0的过程,都需要将diff–,表示词频差的缩小。
class Solution {
public:
vector<int> findAnagrams(string s, string p)
{
int slen=s.size();
int plen=p.size();
if(slen<plen)
return vector<int>();
vector<int>count(26);
vector<int>ans;
for(int i=0;i<plen;i++)
{
count[s[i]-'a']++;
count[p[i]-'a']--;
}
//记录diff就是二者词频差
int diff=0;
for(int i=0;i<26;i++)
{
if(count[i]!=0)
diff++;
}
//全都满足
if(diff==0)
ans.emplace_back(0);
//注意边界
for(int i=0;i<slen-plen;i++)
{
if(count[s[i]-'a']==1)//=1,代表只属于s,和p不同,经历左窗口右移一位,字符就变成相同词频,diff要--。该字母计数--也可理解为图2
diff--;
else if(count[s[i]-'a']==0)//下图1中的c字符,属于新来的,要添加他的映射,自然词频又++
diff++;
--count[s[i]-'a'];//左边界字符取出,自然他的计数--
if(count[s[i+plen]-'a']==-1)
diff--;
else if(count[s[i+plen]-'a']==0)
diff++;
++count[s[i+plen]-'a'];
if(diff==0)
ans.emplace_back(i+1);
}
return ans;
}
};
- 图一:这是记录之后count数组总情况
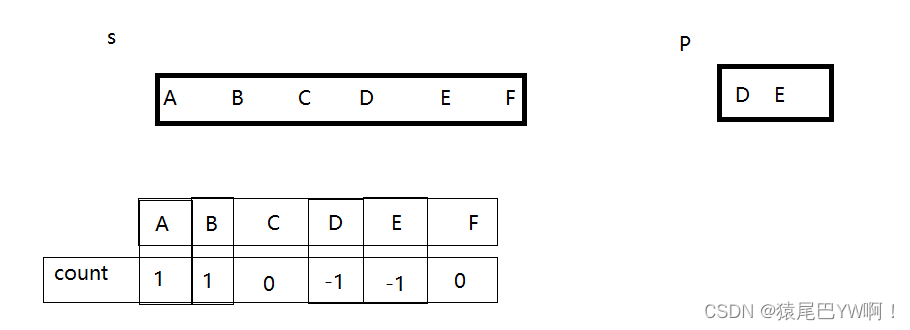 - 图二:帮助理解
- 图二:帮助理解

2. 串联所有单词的子串
题目链接
有了上面第二种做法的思想经验,同样记录词频差,然后将上面的单一字符升级为字符串,数据结构上从count(26)升级为哈希映射的unordered_map<string,int>ht的数据结构,并且采用字符串是否在ht的形式记录上题的词频差。
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
int slen=s.size();
int m=words.size();
int n=words[0].size();
vector<int>ans;
for(int i=0;i<n&&i+m*n<=slen;i++)
{
unordered_map<string,int>ht;
for(int j=0;j<m;j++)//一组几个单词
{
ht[s.substr(i+j*n,n)]++;
}
for(string &word:words)
{
if(--ht[word]==0)
ht.erase(word);
}
for(int start =i;start<slen-m*n+1;start+=n)
{
//判断分组中的右半部分词频是否相同
if(start!=i)
{
//如果是m=3,结出来的就是一组中的第三个单词
string word=s.substr(start+(m-1)*n,n);
//滑动窗口右部分,原来是-1,++先之后为0
//原来不同现在相同
if(++ht[word]==0)//为什么原来是-1就代表右边界呢?因为同上面题第二个解法ht建立映射,遍历s的时候是从左向右截p.size个,规定s中的++,p中的--,所以1的存在就在左边,-1的存在就在右边
ht.erase(word);//同理,ht建立映射引用时,虽然不存在左右的绝对区分(HASHFUNC决定),但是1和-1就代表着左边界还是右边界。
//如果是m=3,结出来的就是一组中的第2个单词
word=s.substr(start-n,n);
//滑动窗口右部分,原来是1,先--之后为0
//原来不同现在相同
if(--ht[word]==0)
ht.erase(word);
}
//p题刚开始的中diff==0,第一个字符开始就可以
//本题中,第一个切割的就可以
//判断分组中的左半部分词频是否相同
if(ht.empty())
ans.emplace_back(start);
}
}
return ans;
}
};
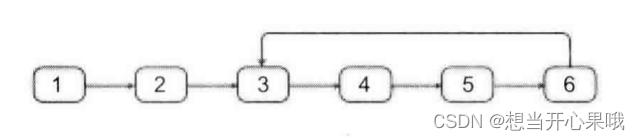
- 举例帮助理解图: