0 概述
论文:A literature review on one‑class classification and its potential applications in big data
发表:Journal of Big Data
在严重不平衡的数据集中,使用传统的二分类或多分类通常会导致对具有大量实例的类的偏见。在这种情况下,对少数类实例的建模和检测是非常困难的。一分类(OCC)是一种检测与已知类实例相比较的异常数据点的方法,可以用于解决与严重不平衡数据集相关的问题,这在大数据中尤其常见。我们对近十年来出版的与OCC相关的文献作品进行了详细的调查。我们将不同的工作分为三类: 异常值检测、新颖性检测、深度学习和OCC。我们仔细检查和评估有关OCC的选定作品,以便在综述中呈现出方法、手段和应用领域的良好横截面。讨论了OCC中常用的离群值检测技术和新颖性检测技术。我们观察到,在与OCC相关的文献中,有一个领域在很大程度上被忽略了,那就是OCC在大数据中的应用背景及其固有的相关问题,如严重的类失衡、类稀缺、噪声数据、特征选择和数据约简。我们认为这项综述将受到大数据领域研究人员的欢迎。
1 引言
大数据的五个v是体积(volume)、种类(variety)、价值(value)、准确性(veracity)和速度(velocity)。巨大的大数据量带来了独特的挑战,例如,在二分类问题中,与负类的实例数量相比,正类(感兴趣的类)的实例数量微不足道。这就带来了一些问题,如如何处理大数据中非常高的类别不平衡,大数据中积极类别实例的类别稀缺性[1-4],以及对消极类别(兴趣较少的类别)的建模偏差。多样性表明大数据可以有多个来源的数据。价值通常被认为是大数据最重要的方面,这是因为挖掘如此庞大的数据语料库应该产生对最终用户具有实际业务价值的结果。大数据中的准确性通常是指大数据集中数据点的真实性,例如,缺失的数据点如何处理?如何清理数据集?数据点有多准确?速度表示数据输入的速度,以及它可能如何改变大数据量的特征。有限的实时数据是否比低速的大量数据更好?
虽然我们不打算在本文中关注大数据的每个方面,但我们关注的是一分类(OCC)如何帮助归因于大数据的特定问题。其中包括严重的类不平衡、类稀有、为提高数据质量而进行的数据清理、特征选择和数据量减少。为此,清楚地理解数据挖掘和机器学习领域中的单分类领域是很重要的。在本文中,我们重点探讨了在一分类中所做的各种工作。此外,我们还评论了在OCC与大数据方面是否已经做了足够的工作,为研究人员提供了解决上述大数据问题的技术。我们认为,当前对OCC方法的调查将为解决大数据遇到的一些具体问题提供深入的见解。
在具有正类和负类实例的二分类问题中,传统的机器学习算法旨在区分这两个类,并建立一个预测模型,该模型可以准确地对这两个类的未标记(以前未见过)实例进行分类。然而,在类不平衡的情况下,与正类(感兴趣的类)中的实例数量相比,负类中的实例数量不成比例地高。在这种情况下,典型的分类器将倾向于具有较多实例的类,即负类。当类失衡严重时,使用传统的二分类器对正类进行准确分类是非常具有挑战性的,有时甚至是不切实际的。例如,在银行非法交易的调查中,积极事例(非法交易)的数量远远少于消极事例(合法交易)的数量,因此存在严重的类不平衡。在这种情况下,如果积极实例上的数据可用,而消极实例上的数据要么不可用,要么未标记,那么如何执行基于分类的预测建模?为了解决这样的问题,可以使用基于单分类(OCC)概念的方法。
单分类是多类或二分类的一种特定类型,其中通过检查和分析一个类(通常是感兴趣的类)的实例来解决分类问题。在OCC问题场景中,正类的标记实例要么不可用,要么数量不足,无法训练传统的机器学习者。重新审视对合法/非法银行交易进行分类的问题,OCC可以用来将以前看不见的交易分类为合法或非法。我们将在下一节中进一步讨论OCC。在本研究中,我们对过去10-11年(即2010-2021年)的文献中关于OCC的方法、方法和算法进行了综述。综述的目的是提供不同的方法和途径的OCC和它的应用综述在过去10-11年的一个很好的横截面,并不意味着是一个详尽的综述所有相关工作。
在我们的调查工作中,观察到异常值检测和新颖性检测是一分类的主要应用领域。此外,我们还在单分类的背景下基于深度学习的使用对综述作品进行了分类。离群点检测和新颖性检测在概念和应用上有细微的差别。在新颖性检测中,在测试数据集中检测异常,而训练数据集中不包含任何异常数据点。在异常点检测中,训练数据集可能包含正常和异常数据点,任务是确定两者之间的边界。边界随后应用于测试数据集,测试数据集也可能包含正常和异常数据点。
本文的其余部分结构如下。“一分类”一节提供了OCC及其主要类型的进一步详细信息。“调研成果总结”部分从离群值检测、新颖性检测、深度学习在OCC中的应用等方面对OCC的调研成果进行了详细的总结。本节还讨论了以前关于OCC的调查论文,以及本文与那些论文的不同之处。“讨论”部分提供了对调查工程和整体OCC问题的讨论。结语部分对本文进行总结,并对今后的工作提出建议。
2 一分类
在一些真实世界的数据集中,标记的例子只能用于一个类。由于未标记样本的数量可能很大,这增加了标准分类方法的学习时间,这主要是由于数据集的规模很大。此时,解决分类问题的解决方案之一是采用一类分类,将看不见的交易分类为合法(正常)或非法(异常)。由于单类分类仅由一个类的实例执行,因此需要更复杂的解决方案才能获得准确的结果。单类分类(OCC)是一种特定类型的多分类或二元分类任务,仅由一个类的实例完成。其他类样本要么不可用,要么数量不够,无法训练更传统的(非OCC)分类器。在某些情况下,采集的样本数量不能令人满意。
为了阐明OCC的概念,我们考虑一些例子。考虑一些具体的问题,比如向客户发放信用卡。在此示例中,提供信用卡的组织需要评估新客户的申请或现有客户的行为,以接受或拒绝它们。由于大多数客户偿还贷款,很少有人违约,我们没有一个可接受的违约比例,数据集非常不平衡。又如,在涡轮机或海上平台的健康监测中,设备状态的正常数据非常丰富。然而,异常状态很少发生,专家们对检测这些罕见情况很感兴趣。可以引用其他类似的例子来解释OCC的使用和重要性。
假设训练集的样本充足的类作为目标类,而异常类实例非常稀疏或不可用。异常类的不可用性可能导致测量困难,或者收集样本的成本高。在一些单分类算法中,寻找训练集上的决策边界是一个目标。OCC的主要特点是它可以通过单类学习来区分一个类对象和其他对象。这意味着即使没有其他类的示例,OCC也是适用的。此外,由于OCC的目标之一是识别目标类样本的隐藏异常值,因此产生鲁棒决策边界是OCC的基本部分。单类分类器的目标可以通过不同的类型来获得,例如分配一个类标签,考虑一个类周围的区域,或者一个对象属于(和不属于)一个类。使用OCC的流行原因之一是它在检测异常对象或异常值或可疑模式方面的效力。仅使用目标类对象进行训练,使OCC成为离群点检测和新颖性检测的实用选择。
缺乏来自单分类的实例可能会破坏分类过程。只有一个训练有素的类使得其示例之间的决策边界区分变得困难。此外,单个类实例给特征选择带来了问题[5,6],因为与传统的二元或多类问题相比,我们只需要处理一个类。因此,在类之间找到具有适当分离的最佳特征子集是一项繁重的工作。由于没有离群值实例,训练集只包含目标实例,使得数据边界非凸[7]。因此,与更传统或传统的多/二分类问题相比,需要额外的实例数量来训练模型。在典型的单类分类中,决定接受一个数据点为内样点还是离群点是基于两个参数:一个是计算样本到目标类的距离的参数,另一个是用户定义的比较距离和接受或拒绝该对象为内样点的阈值限制[8]。Khan等人[9]基于分类器的模型、被分析的数据类型和特征的时间关系对OCC技术进行了分类。分类器的模型分为基于密度的、基于边界的和基于重构的三种类型。
基于密度的单类分类方法基于估计训练数据密度来执行,该密度与阈值(模型参数)进行比较。这些类型的方法适用于具有大量训练样本的良好采样数据。高斯法、混合高斯法和帕森密度法被归类为基于密度的方法。在基于边界的方法中,建立了一个封闭的边界和内层周围的边界,这使得边界的优化成为建模的挑战。任何在边界外的样本都被认为是一个离群值。一类支持向量机(OCSVM)是基于支持向量机(svm)的一种基于核的方法。OCSVM是通过开发一个超平面来构建的,该超平面使离原点距离最大化,并将离群点与内线点分离[10]。另一种基于核的一类分类方法是支持向量数据描述(SVDD),它构建一个半径最小的超球,该超球由目标样本组成,任何在超球之外的样本都被视为离群值[11]。与基于密度的方法相比,基于边界的方法需要更少的数据样本来获得相似的性能。在基于重构的方法中,在生成模型时需要特定领域的历史数据(先验知识)作为假设。异常样本通常不符合模型中嵌入的历史数据假设,因此,任何具有高重构误差的样本都被认为是异常样本。在该方法中,输入模式被表示为输出,重构误差被最小化。基于 k k k均值聚类的一类分类器[12],基于主成分分析(PCA)的一类分类器[13],基于学习向量量化(LVQ)的一类分类器[14],以及Auto-Encoder[15]或多层感知器(multilayer Perceptron (MLP)[16]方法都是基于重构的模型。
基于集成的单类分类器是多个单类分类器的组合,以共同受益于每个分类器。Desir 等人[17] 提出了单类随机森林 (OCRF),它增强了一些弱分类器,并集成了人工离群点生成过程,将单分类变为二元学习器。基于一类聚类的集成(OCClustE)从特征空间构建聚类[18]。这种方法大大减少了处理时间。一类线性规划(One-Class Linear Programming, OCLP)是一种检测不相似表示的有效方法[19]。OCLP方法的优点是减少了测试对象的数量。基于图的OCSVM半监督一类分类方法用于检测正常样本较少的异常肺音[20]。作者建立了一个谱图来显示样本之间的关系。[21]对基于极限学习(ELM)的单类分类进行了全面比较,其中包括两种基于边界的方法和基于重建的方法。Krawczyk和Wozniak提出了增量学习和遗忘的加权单类支持向量机[22]。在增量学习中,定期使用数据来增加模型知识,从而改变先前的决策边界。该方法可用于数据流建模和分析。
3 已有工作概述
本节总结了一组关于单分类的精选著作。精选组是在过去十年(2010-2021)的OCC相关作品中获得的。虽然不打算对所有OCC相关作品进行详尽的调查,但我们试图呈现一个很好的横截面(据我们所知)在过去十年中出版的单分类作品。根据概述工作的重点和方法,我们将其分为三类: 异常值检测和OCC、新颖性检测和OCC、深度学习和OCC。
3.1 异常值检测和OCC
Bartkowiak[7]提出了一个在计算机系统调用中检测异常模式(或伪装者)的案例研究。该数据集表示50个用户,每个用户有15000个系统调用序列。系统调用的集合被抽象为两个集合,即50个块(A部分)和100个块(B部分),每个块包含100个调用。在A部分中没有假面者,而在B部分中,一些区块被20个冒充假面者的用户的区块所取代。这里的OCC问题是检测这些伪装块。对一个用户的异常块进行了详细的分析,该用户的异常块大约有20个。在伪装器检测中,使用OCC对数据密度建模来建立决策边界。构造基于经典高斯分布、鲁棒高斯分布和支持向量机。作者表明,在案例研究的背景下,应用OCC方法监测异常事件是可行的。研究还表明,重建方法可能是有用的,因为用户调查了大约一半的植入块(伪装者)需要被检测到。除了案例研究之外,本文还讨论了统计方法和机器学习方法在网络异常检测中的优势。如果实际的外来(未经授权的)用户参与数据集并被检测到,该研究可能会对伪装者检测有更可靠的吸引力。此外,具有大量用户和系统调用的案例研究将有助于改进工作的泛化性。
Leng 等人[23]提出了一种基于极端学习机(ELM)的单类分类器,其中神经网络的隐层不需要调整,输出权重通过分析计算得出,因此学习时间相对较短。他们将自己提出的方法与自动编码器神经网络进行了比较,并采用重构方法建立了单类分类器。离群点检测分析 对七个 UCI 数据集和三个人工生成的数据集进行了离群点检测分析。虽然随机特征映射和内核都可用于所提议的分类器,但后者比前者能产生更好的结果。主要比较研究 基于 ELM 的模型和自动编码器神经网络之间的主要比较研究表明,前者有一个分析解决方案,可以获得更好的泛化性能,而且在网络学习时间相对较短的情况下也是如此。而且网络学习时间相对较短。这项研究的一个缺点是,研究中调查的数据集相对较少。本研究的不足之处在于,研究中调查的数据集规模相对较小,因此在如何将所建议的方法扩展到更大的规模方面还存在研究空白。特别是由于神经网络以学习速度相对较慢而臭名昭著。作者基于 ELM 的 方法如何在大数据中有效发挥作用?
Gautam等人[21]提出了六种OCC方法,分为两类: 三种基于重建的OCC方法和三种基于边界的OCC方法。所提出的OCC方法基于ELM和在线顺序极限学习机(OSELM)。作者讨论了OCC的在线和离线方法。在四种离线方法中,两种方法执行随机特征映射,另外两种方法执行核特征映射。案例研究数据集由两个人工创建的数据集和来自不同领域的八个基准数据集组成,用于评估OCC模型的性能。作者指出,所提出的分类器比十个传统的OCC和两个基于elm的分类器性能更好。在OCC背景下,ELM也被其他研究使用,例如Dai等[24]和Leng等[23]。 虽然作者使用了一些基准数据集,但他们的分析和结论也是基于人工生成的数据集。
Dreiseitl等[25]研究了一类支持向量机在黑色素瘤异常预后检测中的异常值检测。一类分类旨在模拟未获得转移状态的黑色素瘤患者的分布,在这种情况下,这是黑色素瘤患者的正常类别(病例)。案例研究数据来自维也纳医科大学皮肤学系。清洗后的数据集包括270个血清学血液测试,其中包括37名转移性疾病患者和233名无转移性疾病患者。将一类支持向量机方法与常规两类支持向量机和人工神经网络(ANN)算法进行了比较。使用WEKA数据挖掘工具对这些进行了调查[26]。他们的实证工作表明,一类支持向量机是标准分类算法的一个很好的替代方案,在这种情况下,只有少数病例来自感兴趣的类别,即在这种情况下,转移性疾病的患者。当一类支持向量机模型在少数类中使用的案例数少于一半时,一类支持向量机模型的性能优于两类支持向量机模型。本研究的一个潜在问题是案例研究的数据集规模非常小,以及他们的方法是否可扩展到更大的数据集,如大数据。
Mouro- miranda等[27]提出了一种用一类支持向量机(OCSVM)对患者脑活动进行分类的方法。该方法分析了功能性磁共振成像(fMRI)对抑郁症患者悲伤面部表情的反馈。他们检查了这些患者的功能磁共振成像,将他们与健康(非抑郁)患者进行比较,并得出结论,抑郁患者的功能磁共振成像反应被归类为异常值。数据集包括19名抑郁症患者和19名非抑郁症患者。OCSVM分类显示,健康患者边界与抑郁症汉密尔顿评定量表之间存在很强的相互联系。此外,OCSVM在患者中发现了两个亚类。这些子类别是根据患者对治疗的反应进行分类的。为了将个体划分为抑郁和健康,该算法使用了两种类型的大脑数据,如全脑和大脑区域的体素(体素大小是图像的空间3D分辨率),它提取了大约500个全脑特征和348个区域特征。考虑脑区域图像并使用OCSVM对患者进行治疗,使本研究成为OCC在医疗保健中应用的一个值得注意的工作。案例研究的数据集非常小,很难得出广泛的泛化结论,特别是在大数据的背景下。
Bartkowiak和Zimroz[28]研究了行星齿轮箱(安装在斗轮挖掘机上)的振动信号并检测到离群数据。他们从分割的振动信号频谱中收集了两个数据集,分别作为“好”数据集和“坏”数据集。在齿轮箱处于不良状态时,产生的谐波信号较多,信噪比较高,而在齿轮箱处于良好状态时,谐波和信噪比相对较低。好的数据集的样本数为951,有15个属性。他们应用神经尺度技术(一种可视化方法)将属性减少到两个特征,因此,数据可以绘制在x-y平面上。为了估计数据的分布,作者使用了三种方法,包括Parzen窗口,支持向量数据描述(SVDD)和混合高斯。由于这些方法都是边界方法,所以对好的数据建立一类决策边界,用坏的数据对模型进行检验。结果表明,在测试数据集上,模型识别出98%是坏的,即异常值。这项工作是在机械系统中发现异常值作为故障的一个很好的例子,因为这些信息在系统诊断中是有用的。
Desir等人[29]提出了一项实证研究,研究了他们之前提出的一类随机森林(OCRF)[17]的行为,该方法基于随机森林学习器和一种新的离群值生成过程。后者既减少了要创建的人工异常值的数量,也减少了生成异常值的特征空间的大小。在[29]中,作者在几个UCI数据集的背景下,对OCRF与一些参考的一类分类算法(即高斯密度模型、Parzen估计器、高斯混合模型和一类支持向量机)进行了比较案例研究。他们的工作表明,带有离群值生成的ocf方法的性能与上述参考算法相似或更好。此外,他们提出的解决方案在高维特征空间中表现出稳定的性能,而其他一些OCC算法可能表现不佳。虽然没有在[29]中进行探讨,但我们认为他们的方法可以潜在地用于大数据,其中大量特征通常是一个有问题的问题。
Krawczyk等[18]提出了一种基于加权单类支持向量机(OCSVM)的多分类器系统,并对目标类中的数据点进行聚类。多分类器系统构建一个分类器的集合,在这种情况下,它是基于从目标类的实例池派生的集群构建的分类器。作者提出了“一个弹性和高效的框架来完成这项任务,它只需要选择几个组件,即聚类算法、个体分类器模型和融合方法[18]。” 基于多个基准数据集(包括来自UCI库的19个数据集)的实证案例研究表明,该方法优于几种OCC方法,包括单类和多类问题的OCSVM。作者没有与SVDD进行比较,SVDD是一种有效的OCC方法,基于我们对调查中探索的各种研究的观察。此外,所有的案例研究数据集的规模都相对较小,这就把模型的可扩展性问题摆在了前面。
Lang等人[20]提出了一种使用基于图的半监督OCSVM的新方法。应用领域是异常肺音的检测,在远程医疗中肺部疾病的诊断和患者监护中具有重要意义。该方法利用少量标记的正常实例和大量未标记的实例来描述正常的肺音并检测异常的肺音。构建了一个谱图来表示所有样本之间的关系,这丰富了只有少数标记的正态样本所提供的信息。然后,建立了基于图的半监督OCSVM模型,并给出了求解方法。利用谱图中的信息,提高了识别和泛化的效果,这是有效检测异常肺音的关键。”[20]。该方法的性能随着未标记异常实例数量的增加而提高。
Krawczyk和Woźniak[22]解决了处理数据流的问题,特别是在存在概念漂移的情况下。讨论了OCC在数据流分析中是一个很有前途的研究方向,可用于单类实例的二值分类、离群值检测和新颖性检测。提出了一种新的加权OCSVM,该算法可以处理逐渐的概念漂移。所提出的OCC可以使其决策边界适应新的传入数据,因为它还采用了一种遗忘方案,提高了分类器跟踪模型变化的能力。此外,本文还提出了不同的增量学习和遗忘策略,并在几个案例研究的背景下进行了评估。主要结论是所提出的OCC对于存在概念漂移的数据流分类问题具有有效的可用性。在大数据概念漂移的背景下,观察所提出的解决方案的有效性将是一件有趣的事情。与其他流行的OCC方法的比较将为所提出的方法提供更强的验证。
Das等人[30]在智能家居中应用传感器网络监测痴呆症患者活动的背景下研究了OCC。监测这些事件总是与检测错误相关联,在[30]的背景下,这意味着(痴呆症患者)没有正确完成一项活动。活动完成和错误问题被表述为异常值检测的一类分类。个案研究的基础是监测诸如吸尘、除尘、浇花、接电话等常见家庭活动的完成情况或缺乏情况。完全完成一项活动的问题被认为是一个异常值。不同类型的运动检测和压力检测振动传感器用于数据收集。提出的分类模型,检测实时活动错误(DERT),是由580个数据点组成的无错误数据(即一个类)训练的。基于OCSVM的DERT表现优于简单的基线离群值检测方法。所提议的方法的验证需要通过与其他OCC技术(包括SVDD)的比较研究来支持。
Deng等人[31]重点研究了物联网传感器数据中的异常值检测问题。他们开发了一类支持塔克机(OCSTuM),这是一种涉及塔克分解技术的无监督异常值检测方法。塔克分解通过产生一个核心张量和因子矩阵来表示张量。案例研究数据存在高维问题,需要将特征子集选择作为解决方案的一部分。作者提出了一种应用遗传算法改进OCSTuM的特征选择和离群点检测的方法(称为GA-OCSTuM)。他们的工作涉及多个数据集,包括Montes传感器数据集、TAO项目传感器数据集、日常和体育活动数据集(DSAD)、开放采样设置中的气体传感器阵列数据集(GSAOSD)和南佛罗里达大学步态数据集(USFGD)。OCC训练数据集是干净的,没有任何异常值,但测试数据混合了5%的异常值样本。将所提算法与基线方法(如OCSVM)进行比较。实证结果表明,GA-OCSTuM方法在所有数据集上都优于基线方法(包括SVDD、R-SVDD、OCSVM和OCSTuM)。在OCC离群值检测的背景下,研究中考虑的数据集与其说是一个大数据问题,不如说是一个高维问题。此外,已知遗传算法(GAs)的计算性能较慢,并且该研究并未揭示遗传算法对所提出的GA-OCSTuM解决方案的时间性能的影响。
Gautam等人[32]开发了一种基于深度核的单类分类器(DKRLVOC)模型,通过一对自编码器的帮助来减少对象方差并改善特征学习。该方法在18个数据集和2个真实数据集上进行了测试,其中包括fMRI数据集检测阿尔茨海默氏症和病理图像数据集检测乳腺癌。提出的基于最小方差嵌入深度核的一类分类方法包括三层:基于最小方差嵌入核的自编码器、基于核的自编码器和基于核的OCC。该方法与三种基于核的极限学习机方法OCKELM、VOCKELM[33]和ML-OCKELM进行了比较。关于这些模型的更多细节见[32]。实证结果表明,对于较小的生物医学数据集,所提出的方法在F1得分方面表现最好。对于中等规模的生物医学数据集,本文方法的有效性高于ML-OCKELM和OCKELM,但低于VOCKELM。这组作者在小型和中型生物医学数据集的背景下比较了不同的模型,这让人们对他们推荐的方法如何在更大的数据集(如大数据)上执行产生了一些怀疑。
Kauffmann等人[34]开发了一种方法,一类深度泰勒分解(OCDTD),用于解释一类支持向量机中的异常值。在异常值检测过程之后,提供解释性解释是有益的,这表明这些输入负责产生异常值。这种解释最大限度地发挥了由神经网络创建的结构的优势。在他们的方法中,OCSVM被输入到一个“神经化”的过程中,以揭示异常值解释的结构。随后,将结构馈送到深度泰勒分解中,并将预测反向传播到显示有效生成异常值的输入。在生成离群值时最具影响力的特征表示为热图。为了最大化使用神经网络的优势,应用了分层相关传播技术,其中应用了一组传播规则来向后传播预测[35]。鉴于神经网络环境中使用了反向传播,计算时间性能研究将为实验结果和研究分析提供更好的见解。
Aguilera等人[36]在OCC背景下提出了k- strong - strengths (kSS)算法[37]的两种变体。这两种算法分别被命名为OCC-kSS和Global Strength Classifier (gSC),并使用抑郁症和厌食症基准数据集进行评估。此外,作者在kSS方法的背景下引入了质量,作为确定社交媒体数据中抑郁症和厌食症文本相关性的措施。算法使用四个数据集进行评估,分别为Dep2017、Dep2018、Anx2018和Anx2019,这些数据集来自2017-2109版本的eRisk共享任务。结果表明,gSC算法总体上优于OCC-kSS算法。这项工作缺乏与其他现有OCC方法的比较,特别是本文中讨论的几个方法。
Wang等人[38]使用KDD入侵检测数据集(简称NSL-KDD)的修改版本,提出了一种在网络入侵检测系统(NIDS)背景下进行异常检测的组合方法。该方法结合子空间聚类(SSC)和OCSVM进行NIDS异常检测,并与K-means、DBSCAN和SSC- ea方法进行比较[39]。基于真阳性率、假阳性率和ROC曲线(两个阈值),作者证明了他们的方法比其他三种方法产生更好的性能。据报道,该方法的计算时间高于K-means和DBSCAN。KDD数据集及其变体在网络安全和入侵检测方面有点过时。在该领域有更多的当前数据集供研究人员探索,然而,在他们的研究中没有这样做。
在桥梁自主结构健康监测的背景下,Favarelli和Giorgetti[40]提出了一种机器学习方法,用于从振动数据中自动检测桥梁结构中的异常。他们提出了两种异常检测方法:一类分类器神经网络OCCNN和OCCNN2。案例研究数据基于一座桥梁结构(Z-24)的加速度测量数据数据库[40]。OCCNN采用粗边界估计和细边界估计两步方法检测正常运行条件下特征空间的正常类边界。OCCNN2是基于将OCCNN方法的两步方法与自关联神经网络(ANN)相结合[40]。将这两种方法与现有的一些异常检测方法进行了比较,包括:主成分分析、核主成分分析、高斯混合模型(GMM)和神经网络。与其他方法相比,OCCNN方法具有更好的准确性和F1分数;然而,OCCNN2方法在响应性、准确性和F1分数方面表现最佳。
Mahfouz等[41]提出了一种基于OCSVM的网络入侵检测模型,该模型在正常网络流量样本上进行训练,形成n维特征空间中正常数据具有高概率密度的区域。随后,不出现在或代表这些(正常)区域内的数据样本被标记为异常(即入侵)。虽然他们对网络指令异常检测的定义并不新颖,但本文的主要贡献在于创建并用于案例研究的网络入侵数据集。作者实现了现代蜂蜜网络(MHN),一个集中式服务器来管理和收集来自蜜罐的数据[41]。他们使用Excel创建了一个数据集工具,将来自不同蜜罐的独立网络监视器的数据聚合到一个数据集中。训练和测试数据分割为70:30,所提出模型的准确率略低于98%。作者没有将他们的方法与现有的几种网络入侵异常检测方法进行比较。
在初步研究中,Zaidi和Lee[42]讨论了软件开发中现有的bug分类方法无法为bug报告分配新添加的开发人员。
“Bug分类是一个软件工程问题,其中一个开发人员被分配到一个Bug报告中。“[42]。作者引用了现有的方法,这些方法使用社交网络分析、主题建模、挖掘存储库、机器学习和深度学习来完成开发人员分配给bug报告的任务。但是,这些方法不能将新添加的开发人员分配给bug报告。他们的实证研究使用了Eclipse[43]和Mozilla[44]软件项目中的Bug报告数据。利用正样本建立OCSVM模型,实现对负样本的检测。作者声明他们的经验结果是可以接受的,并且对于分配新添加的开发人员到bug报告的挑战性问题进行额外的研究是有保证的。
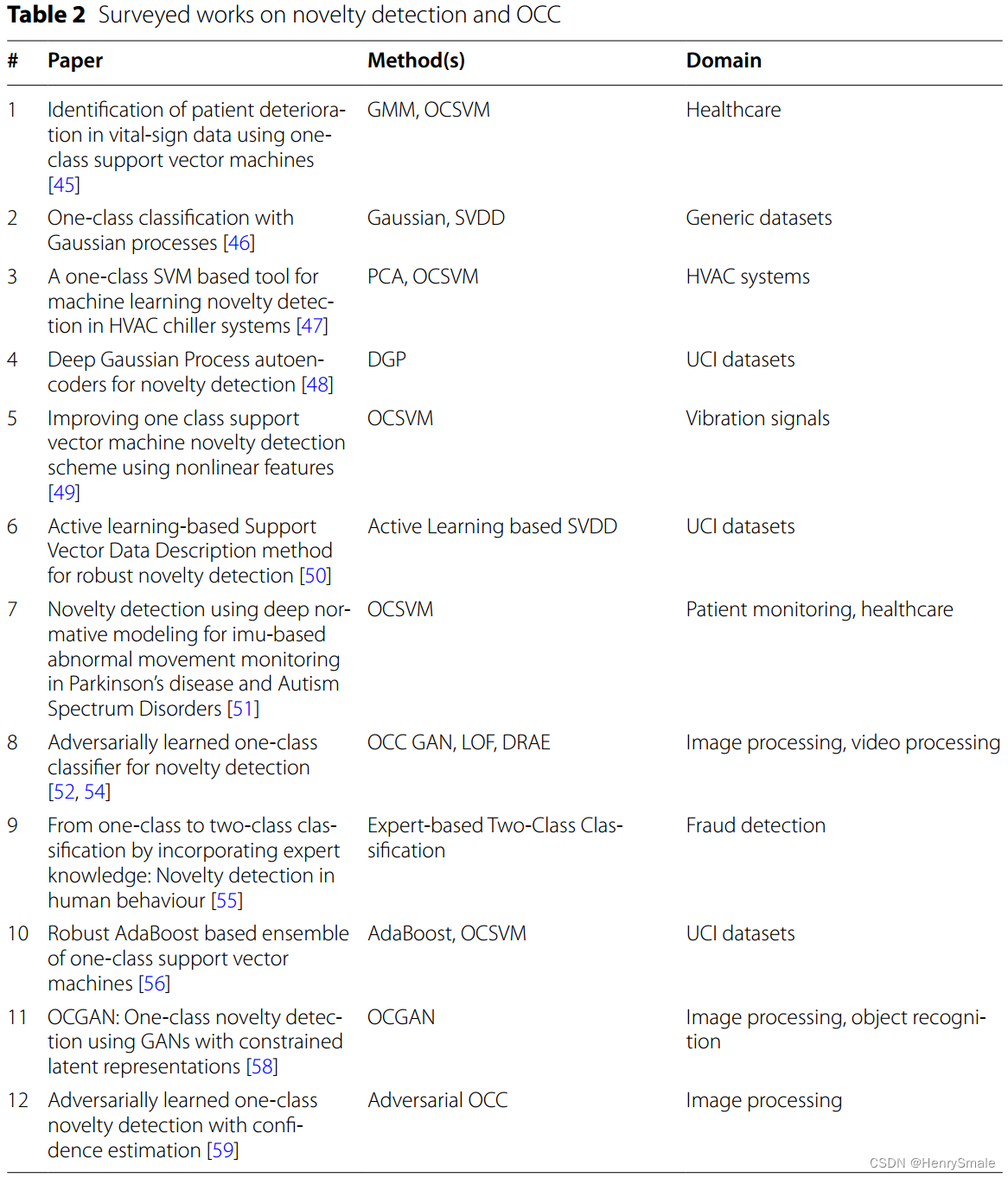
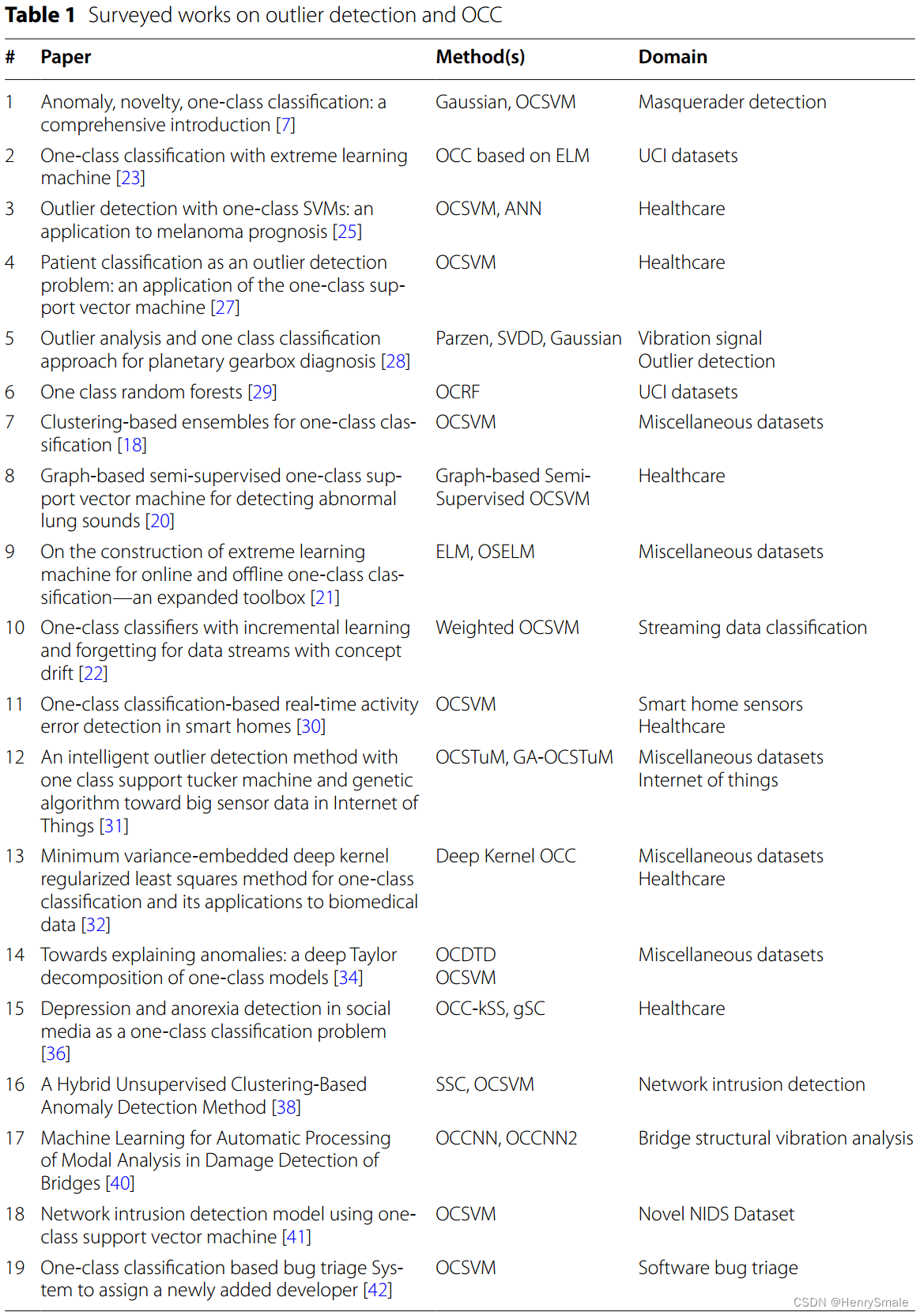
表1总结了OCC和离群值检测综述工作的关键信息。
3.2 新颖性检测和OCC
如前所述,异常值检测和新颖性检测在概念和应用上有着微妙的区别。在新颖性检测中,在测试数据集中检测异常,而训练数据集中不包含任何异常数据点。在离群点检测中,训练数据集可能同时包含正常和异常数据点,任务是确定两者之间的边界,然后将该边界应用于同样可能包含正常和异常数据点的测试数据集。
Clifton等[45]利用改进的OCSVM方法在基于生命体征健康数据(如呼吸频率、血氧饱和度、心率等)识别患者恶化的背景下进行新颖性检测。新颖性检测模型通过正常数据进行训练,然后对测试数据进行检测,将测试数据分类为正常或异常。训练数据是通过监测19名患者收集的,产生了1500个实例的数据集。用该方法对高斯混合模型(GMM)和OCSVM两种模型进行了测试,结果表明OCSVM优于GMM模型。案例研究数据是从降压单元(SDU)收集的,它的急性程度低于重症监护病房的数据。数据集的规模很小,这对所得结果和结论的泛化产生了一些怀疑。
Kemmler等[46]提出了一种基于高斯过程回归和近似高斯分类的单类分类新颖性检测框架。将该方法与SVDD的新颖性检测方法和Parzen密度估计方法进行了比较。实验使用来自多个领域的数据集,并使用不同的图像核函数。案例研究结果表明,该方法的性能与其他两种方法相似,甚至优于其他两种方法。他们的方法的应用,特别是基于高斯过程回归的OCC分数,将是理解大数据中的类稀缺性问题的一个有趣的研究。
Beghi等[47]研究了一种用于HVAC系统新颖性检测的OCSVM方法。预先监测可能出现的故障有助于节省成本和能源。在如此的系统中,异常的数据很少,而且通常是不可用的。研究了冷凝器结垢、制冷机泄漏、蒸发器水流量减少和冷凝器水流量减少四种故障类型。调查的案例研究数据来自美国采暖、制冷和空调工程师协会(ASHRAE)。作者将主成分分析(PCA)与OCSVM模型相结合,观察到与单独使用OCSVM相比,主成分分析与OCSVM相结合的AUC性能有所提高。作者没有与文献中的其他新颖性检测方法进行比较,这限制了其工作在更广泛意义上的推广和应用有效性。
Domingues等[48]提出了一种基于深度高斯过程(Deep Gaussian Processes, DGP)的自动编码器配置的无监督新异检测建模方法。所提出的DGP自编码器通过使用随机特征展开来逼近DGP层,并通过对随后的近似模型进行随机变分推理来训练。DGP自编码器可以对复杂的数据分布进行建模,并有助于提出一种新颖性检测的评分方法。在7个UCI数据集和4个来自国际航空服务提供商的数据集的背景下,将所提出的模型与隔离森林和鲁棒密度估计方法进行了比较。实证结果表明,该模型优于其他两种方法。虽然作者在多个数据集上进行了实验,但其中大多数数据集的规模相对较小,因此无法深入了解他们的方法在大数据上的性能。
Sadooghi和Khadem[49]在OCSVM中引入了预处理步骤以提高其性能。他们的工作背景是旋转系统轴承振动信号的新颖性检测。预处理包括一种新的去噪方案、特征提取、向量化、归一化和降维,每一项都使用详细的系统方法实现。案例研究来自case Western Reserve大学轴承数据中心、Tarbiat Modares大学试验台数据和PRONOSTIA平台数据。要了解这些数据资源的更多细节,请参考[49]。本文提出的系统方法表明,非线性特征本身可以有效地提高新颖性检测的性能,包括显著提高OCSVM的分类率(在某些情况下可达到95%至100%)。所提出的OCSVM修正方案似乎与案例研究的领域紧密耦合,并且没有确定这些方案在其他领域的应用,这限制了它们在其他领域的应用。
Yin等人[50]研究并提出了一种基于主动学习的方法来改进新颖性检测背景下的SVDD。SVDD是目前应用最广泛的新颖性检测方法之一,对其进行改进是本文的一个很好的研究方向。然而,当数据量太大或数据质量差时,SVDD可能会表现不佳。用少量的标记样本描述数据分布在机器学习中有它的好处,例如,可以保证有限的数据是无噪声和高质量的。提出的基于主动学习的SVDD方法可以减少标记数据的数量,推广数据的分布,并利用局部密度来指导选择过程,减少噪声的影响。案例研究数据包括三个UCI数据集(电离层、Splice和图像分割)和田纳西东部过程基准数据。 实证结果表明,基于主动学习的SVDD在UCI数据集上具有明显的优势。主动学习是基于用专家(“专家”)标记的数据取代未标记的数据,但几乎没有提供关于基于专家的数据标记过程的信息。此外,虽然本文的目标是将主动学习与SVDD结合起来以提高其在大型数据集上的性能,但没有进行关于改变数据集大小和调查基于SVDD的主动学习性能的研究。
Mohammadian等[51]研究了一种基于OCSVM的新颖检测方法,用于检测帕金森和自闭症患者的异常活动。在帕金森和自闭症谱系障碍(ASD)疾病中,使用可穿戴和惯性测量单元(IMU)传感器进行患者监测已经引起了相当大的关注。早期发现病人不寻常的身体活动对他们的护理和治疗至关重要。本文采用深度规范建模的方法,弥补了OCSVM在大数据和噪声数据中表现不佳的不足。由于标记数据的限制,生成正常模型来展示患者的正常运动,正常运动模型的大(实质性)变化被认为是异常。在步态冻结(FOG)和典型运动(SMMs)数据集上对该方法进行了测试,结果表明该模型在相对较大的数据中是新颖性检测的替代选择,并且具有实时非典型运动检测的潜力。作者指出,他们的方法仅限于基于距离的新颖性检测方法,因此不适用于基于密度的新颖性检测方法。
Sabokrou等人[52]提出了一种生成式对抗网络(GAN)[53],用于不同图像和视频数据集背景下的新颖性检测。作者提出了OCC问题的端到端深度网络。该体系结构由R和d两个模块组成。R模块对输入进行细化,并在学习过程中逐渐注入判别规则,以创建积极和新奇的实例(内线和离群值),而第二个模块(检测器)将积极和新奇的实例分离开来。他们的方法用两个图像数据集进行了研究,包括MNIST和Caltech-256数据集。此外,他们还研究了一个视频数据集UCSDPed2。对于图像数据集,与局部离群因子(LOF)和区分重建自动编码器(DRAE)方法相比,该方法显示出更高的f1分数。对于视频数据集,视频数据中的行人被认为是正类,其他任何东西都被认为是异常。该异常检测方法与一些新颖性检测方法具有可比性。在Sabokrou等人[54]的相关工作中,提出了一种对抗训练模型来检测端到端深度学习模型中的异常值。他们在图像和视频数据集上测试了他们的方法,并得出结论,所提出的模型可以有效地学习检测异常值。他们的方法在图像/视频数据以外的领域,特别是大数据领域的效果还有待观察。
Oosterlink等人[55]提出了一项新颖性检测的研究,将单类分类与基于专家的两类分类进行了比较。作者研究了一种检测电信公司订阅新的移动家庭计划服务中的欺诈行为的方法。由于欺诈,组织和公司的经济损失可能相当大,对这些交易的检测很有吸引力。一个有效的欺诈检测系统是每个服务提供商公司的关键前提。为了解决这一问题,人类行为跟踪在检测人类活动异常和欺诈检测方面是实用的。作者探讨了将专家制备的合成阴性样品与阳性样品相结合的有效性。这项工作证实,使用专家知识来构建负样本并将一类分类转换为二元分类可以提高分类器的性能。两类专家生成样本方法优于人工生成和传统的一类分类方法。在建模过程中引入专家进行决策可能会导致人为错误,本文未对其对模型性能的影响进行研究。
Xing和Liu[56]提出了一种结合OCSVM的改进AdaBoost算法来提高单类分类的性能。AdaBoost[57]与支持向量机的结合总体上提高了二值和多类分类问题的性能;然而,AdaBoost结合OCSVM并没有提高OCC的性能。提出了一种基于鲁棒AdaBoost的OCSVM集成方法,该方法利用牛顿-拉夫森技术改变AdaBoost的权重。案例研究数据包括两个合成数据集,正弦离群值和平方离群值,以及来自UCI存储库的20个数据集。该方法优于多种单类分类方法,包括AdaBoost OCSVM集成、基于随机子空间方法的OCSVM集成、基于聚类的OCSVM集成和高斯核OCSVM。该方法的平均性能优于大多数其他方法。由于所探索的所有数据集都相对较小,因此所提出的方法的可扩展性需要进一步研究。
Perera等人[58]提出了一种用于新颖性检测的单类GAN (OCGAN)模型,其解决方案基于使用去噪自编码器网络学习类内样本的潜在表示。作者认为,新颖性检测涉及两种类型的表征建模,包括确保类内样本得到很好的表征和确保类外样本得到很差的表征。他们指出,在新颖性检测方面,先前的现有工作尚未解决后者,而这正是他们的主要贡献所在。他们提出的模型考虑了两种类型的表示需求的建模。案例研究数据由四个公开的多类目标识别数据集组成,包括MNIST、FMNIST、COIL100和CIFAR10[58]。对于本文所考虑的四种数据集,该模型的新颖性优于现有的一类新颖性检测方法。不同技术之间的比较工作缺乏对模型性能的统计验证和验证。此外,作者没有讨论所提出的方法对非图像数据集的适用性。
在图像新颖性检测方面,Zhang等[59]提出了“基于置信度估计的对抗学习一类新颖性检测”模型。作者认为,大多数现有的新颖性检测方法,特别是那些使用深度学习技术的方法,都不是端到端的,并且往往对新颖性检测预测过于自信。该模型包括两个模块:表示模块和检测模块,这两个模块通过对抗性建模来协同训练和学习数据语料库的早期分布。此外,该模型使用基于置信度的估计来确保其预测的更高效率。该模型使用四个公开可用的图像数据集进行检验,即:MNIST, FMINST, COIL100,和CIFAR10,并与现有的几种新颖性检测方法进行比较[59]。作者的结论是,他们提出的模型优于几种现有的一类新颖性检测方法。此外,一项消融研究表明,所提出模型的每个模块在其功能上都是至关重要的。与之前的研究类似,本研究中不同技术之间的比较工作缺乏对模型性能的统计验证和验证。
表2总结了OCC和新颖性检测方面调查工作的关键信息。