第三十二章 linux-模块的加载过程二
文章目录
- 第三十二章 linux-模块的加载过程二
- HDR视图的第二次改写
- 模块导出的符号
HDR视图的第二次改写
在这次改写中,HDR视图中绝大多数的section会被搬移到新的内存空间中,之后会根据这些section新的内存地址再次改写图1·2中的HDR视图,使其中section header table中各entry的sh_addr指向新的也是最终的内存地址。
load_module->layout_and_allocate->layout_sections
static void layout_sections(struct module *mod, struct load_info *info)
{
static unsigned long const masks[][2] = {
/* NOTE: all executable code must be the first section
* in this array; otherwise modify the text_size
* finder in the two loops below */
{ SHF_EXECINSTR | SHF_ALLOC, ARCH_SHF_SMALL },
{ SHF_ALLOC, SHF_WRITE | ARCH_SHF_SMALL },
{ SHF_WRITE | SHF_ALLOC, ARCH_SHF_SMALL },
{ ARCH_SHF_SMALL | SHF_ALLOC, 0 }
};//标记了SHF_ALLOC的section定义了四种类型:
//code、only-data、read-write data和small data。
unsigned int m, i;
//遍历Section header table
for (i = 0; i < info->hdr->e_shnum; i++)
info->sechdrs[i].sh_entsize = ~0UL;
pr_debug("Core section allocation order:\n");
for (m = 0; m < ARRAY_SIZE(masks); ++m) {
for (i = 0; i < info->hdr->e_shnum; ++i) {
Elf_Shdr *s = &info->sechdrs[i];
const char *sname = info->secstrings + s->sh_name;
if ((s->sh_flags & masks[m][0]) != masks[m][0]
|| (s->sh_flags & masks[m][1])
|| s->sh_entsize != ~0UL
|| strstarts(sname, ".init"))
continue;
s->sh_entsize = get_offset(mod, &mod->core_size, s, i);
pr_debug("\t%s\n", sname);
}
switch (m) {
case 0: /* executable */
mod->core_size = debug_align(mod->core_size);
mod->core_text_size = mod->core_size;
break;
case 1: /* RO: text and ro-data */
mod->core_size = debug_align(mod->core_size);
mod->core_ro_size = mod->core_size;
break;
case 3: /* whole core */
mod->core_size = debug_align(mod->core_size);
break;
}
}
pr_debug("Init section allocation order:\n");
for (m = 0; m < ARRAY_SIZE(masks); ++m) {
for (i = 0; i < info->hdr->e_shnum; ++i) {
Elf_Shdr *s = &info->sechdrs[i];
const char *sname = info->secstrings + s->sh_name;
if ((s->sh_flags & masks[m][0]) != masks[m][0]
|| (s->sh_flags & masks[m][1])
|| s->sh_entsize != ~0UL
|| !strstarts(sname, ".init"))
continue;
s->sh_entsize = (get_offset(mod, &mod->init_size, s, i)
| INIT_OFFSET_MASK);
pr_debug("\t%s\n", sname);
}
switch (m) {
case 0: /* executable */
mod->init_size = debug_align(mod->init_size);
mod->init_text_size = mod->init_size;
break;
case 1: /* RO: text and ro-data */
mod->init_size = debug_align(mod->init_size);
mod->init_ro_size = mod->init_size;
break;
case 3: /* whole init */
mod->init_size = debug_align(mod->init_size);
break;
}
}
}
在为那些需要移动的section分配新的内存空间地址之前,内核需要决定出HDR视图中哪些section需要移动,如果移动的话要移动到什么位置。内核代码中layout_sections函数用来做这件事,在layout_sections函数中,内核会遍历HDR视图中的每一个section,对每一个标记有SHF_ALLOC的section,将其划分到两大类section当中:CORE和INIT。为了完成这种分类,layout_sections函数首先为标记了SHF_ALLOC的section定义了四种类型:code、only-data、read-write data和small-datao任何一个标记了SHF_ALLOC的section必定属于这四类中的一类。之后,对应每一个分类,函数都会遍历Section header table中的所有项,将section name不是以".init"开始的section划归为CORE section,并且修改HDR视图中Section header table中对应entry的sh_entsize,用以记录当前section在COREsection中的偏移量。
mod->core_size = debug_align(mod->core_size);
同时用struct module结构中的成员变量core size记录下到当前正在操作的section为止CORE section的空间大小。
mod->core_size = debug_align(mod->core_size);
对于CORE section中的code section,内核用struct module结构中的core text size来记录。
mod->core_text_size = mod->core_size;
对于INIT section的分类,和CORE section的划分基本一样,不同的地方在于属于INIT section的section,其name必须以与nit"开始,内核用struct module结构中的成员变量init size来记录当前INITsection空间的大小。
mod->init_size = debug_align(mod->init_size);
对于INIT section中的code section,内核用struct module结构中的init text size来记录。在对section进行搬移之前,接下来会有个对符号表的处理,内核代码中通过调用layout_symtab函数来完成。Linux的内核源码中根据是否启用了内核配置选项CONFIG_KALLSYMS给出了layout_symtab函数的两种不同的定义。
在启用了CONFIG_KALLSYMS选项的L皿源码树基础上编译内核模块,会导致内核模块也会保留模块中的所有符号,这些符号都放在ELF符号表section中。由于在内核模块的ELF文件中,符号表所在的section没有SHFALLOC标志,所以上面提到的layout_secttons函数不会把符号表section划到CORE section或者是INITsecuon中,这也是为什么要通过另外一个函数layout_symtab来把符号表搬移到CORE section内存区中的原因。
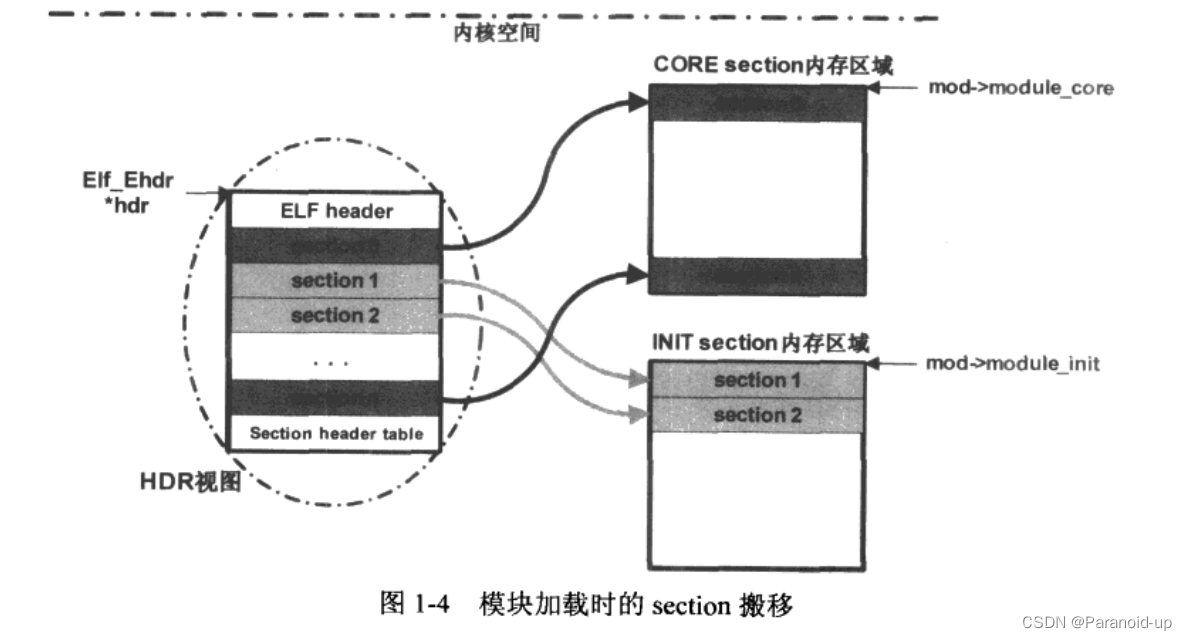
在对内核模块ELF文件中的section进行了CORE和INIT的划分之后,内核调用vmalloc相关的函数为CORE section和INITsection分配对应的内存空间,基地址分别记录在mod->module_core和mod->module_init中,然后把对应的section数据搬移到其在CORE section和INITsection内存空间的最终位置上。显然,在把各section搬移到其新的内有地址之后,内核需要改写HDR视图中的Section header table中对应entry的shaddr,以使其指向新的地址。注意,由于ci时“gnu.linkoncethismodule”section是一个带有SHF_ALLOC标志的可写数据section,也会被搬移到CORE section内存空间中,所以必须更新mod变量使之指向新的内存地址。
load_module->layout_and_allocate->move_module
static int move_module(struct module *mod, struct load_info *info)
{
int i;
void *ptr;
/* Do the allocs. */
ptr = module_alloc_update_bounds(mod->core_size);
/*
* The pointer to this block is stored in the module structure
* which is inside the block. Just mark it as not being a
* leak.
*/
kmemleak_not_leak(ptr);
if (!ptr)
return -ENOMEM;
memset(ptr, 0, mod->core_size);
mod->module_core = ptr;
if (mod->init_size) {
ptr = module_alloc_update_bounds(mod->init_size);
/*
* The pointer to this block is stored in the module structure
* which is inside the block. This block doesn't need to be
* scanned as it contains data and code that will be freed
* after the module is initialized.
*/
kmemleak_ignore(ptr);
if (!ptr) {
module_memfree(mod->module_core);
return -ENOMEM;
}
memset(ptr, 0, mod->init_size);
mod->module_init = ptr;
} else
mod->module_init = NULL;
/* Transfer each section which specifies SHF_ALLOC */
pr_debug("final section addresses:\n");
for (i = 0; i < info->hdr->e_shnum; i++) {
void *dest;
Elf_Shdr *shdr = &info->sechdrs[i];
if (!(shdr->sh_flags & SHF_ALLOC))
continue;
if (shdr->sh_entsize & INIT_OFFSET_MASK)
dest = mod->module_init
+ (shdr->sh_entsize & ~INIT_OFFSET_MASK);
else
dest = mod->module_core + shdr->sh_entsize;
if (shdr->sh_type != SHT_NOBITS)
memcpy(dest, (void *)shdr->sh_addr, shdr->sh_size);
/* Update sh_addr to point to copy in image. */
shdr->sh_addr = (unsigned long)dest;
pr_debug("\t0x%lx %s\n",
(long)shdr->sh_addr, info->secstrings + shdr->sh_name);
}
return 0;
}
这里之所以要对HDR视图中的某些section做这样的搬移,是因为在模块加载过程结束时,系统会释放掉IIDR视图所在的内存区域,不仅如此,在模块初始化工作完成后,INITsection所在的内存区域也会被释放掉。由此可见,当一个模块被成功加载进系统,初始化工作完成之后,最终留下的仅仅是CORE section中的内容,因此CORE section中的数据应是模块在系统中整个存活期会使用到的数据。
如此处理之后,我们在图1·2的基础上得到了图1·4:
模块导出的符号
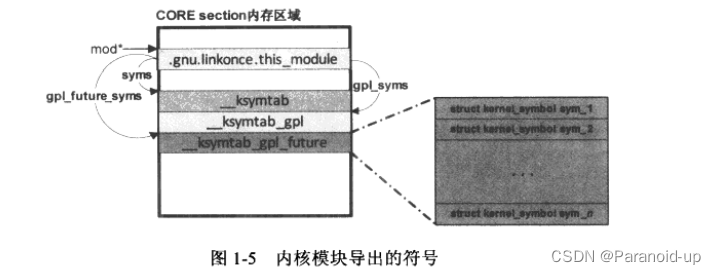
如果一个内核模块向外界导出了自己的符号,那么将由模块的编译工具链负责生成这些导出符号section,而且这些section都带有SHFALLOC标志,所以在模块加载过程中会被搬移到CORE section区域中。如果模块没有向外界导出任何符号,那么在模块的ELF文件中,将不会产生这些section。
显然,内核需要对模块导出的符号进行管理,以便在处理其他模块中那些“未解决的引用”符号时能够找到这些符号。内核对模块导出的符号的管理使用到了structmodule结构中如下的成员变量:
struct module {
。。。。
#ifdef CONFIG_UNUSED_SYMBOLS
/* unused exported symbols. */
const struct kernel_symbol *unused_syms;
const unsigned long *unused_crcs;
unsigned int num_unused_syms;
/* GPL-only, unused exported symbols. */
unsigned int num_unused_gpl_syms;
const struct kernel_symbol *unused_gpl_syms;
const unsigned long *unused_gpl_crcs;
#endif
#ifdef CONFIG_MODULE_SIG
/* Signature was verified. */
bool sig_ok;
#endif
/* symbols that will be GPL-only in the near future. */
const struct kernel_symbol *gpl_future_syms;
const unsigned long *gpl_future_crcs;
unsigned int num_gpl_future_syms;
。。。。
}
在把HDR视图中的section搬移到最终的CORE section和INIT section之后,内核通过对HDR视图中Section header table的查找,获得“__ksymtab",“__ksymtab_gpl”和”__ksymtab_gpl_future”section在CORE section中的地址,将其记录在mod->syms、mod->gpl_syms和mod->gpl_future_syms中。
- find_symbol
在模块加载过程中,find_symbol是个非常重要的函数,顾名思义,它用来查找一个符号。该函数的原型如下:
const struct kernel_symbol *find_symbol(const char *name,
struct module **owner,
const unsigned long **crc,
bool gplok,
bool warn)
{
struct find_symbol_arg fsa;
fsa.name = name;
fsa.gplok = gplok;
fsa.warn = warn;
if (each_symbol_section(find_symbol_in_section, &fsa)) {
if (owner)
*owner = fsa.owner;
if (crc)
*crc = fsa.crc;
return fsa.sym;
}
pr_debug("Failed to find symbol %s\n", name);
return NULL;
}
在深入到这个函数内部之前,有必要先介绍几个数据结构,这几个数据结构将在find_symbol函数中用到。
//对应要查找的每一个符号表section,换句话说,对要查找的每个符号表section,内核代码都要为之产生一个struct symsearch类型的实例。
struct symsearch {
const struct kernel_symbol *start, *stop;
const unsigned long *crcs;
enum {
NOT_GPL_ONLY,
GPL_ONLY,
WILL_BE_GPL_ONLY,
} licence;
bool unused;
};
struct symsearch用来对应要查找的每一个符号表section,换句话说,对要查找的每个符号表section,内核代码都要为之产生一个struct symsearch类型的实例。结构体中的成员变量和stop分别指向对应section的开始和结束地址,bool型的unused成员用来表示内核是否配置了CONFIG_UNUSED_SYMBOLS选项,不过这个选项是“非主流”的,长远看这个选项最终会消失,因此本书只在这里提一下,在后续的章节中将忽略所有该选项被启用时才起作用的代码·另一个比较重要的成员是型的licence,GPL_ONLY表示符号只提供给满足GPL协议的模块使用,NOT_GPL_ONLY表示不一定要只给满足GPL协议的模块使用,WILL_BE_GPLONLY表示将来只提供给满足GPL协议的模块使用。再提醒一下·NOT_GPL_ONLY符号由EXPORT_SYMBOL负责导出,GPLONLY符号由EXPORT_SYMBOL_GPL负责导出,WILL_BE_GPL_ONLY符号由EXPORT_SYMBOL_GPL_FUTURE负责导出。
//查找符号的标识参数
struct find_symbol_arg {
/* Input */
const char *name;
bool gplok;
bool warn;
/* Output */
struct module *owner;
const unsigned long *crc;
const struct kernel_symbol *sym;
};
find_symbol_arg用做查找符号的标识参数,可以看到其大部分数据成员与find_symbol函数原型中的参数完全一致,其中的kernel_symbol是一个用以表示内核符号构成的数据结构,在前面的“EXPORT_SYMBOL的内核实现”一节中介绍过。
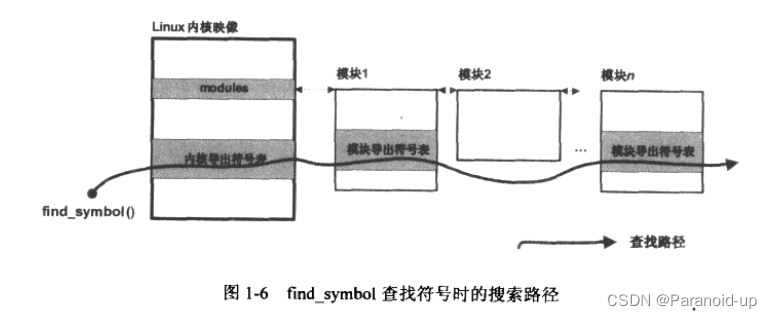
find_symbol函数首先构造被查找模块的标识参数№,然后通过each-symbol来查找符号。each_symbol是用来进行符号查找的主要函数,为节约篇幅起见,这里不再摘录其源代码,而是直接讲述其主要功能框架。
总体上,each_symbol函数可以分成两个部分:第一部分是在内核导出的符号表中查找对应的符号,如果找到,就通过返回该符号的信息,否则,再进行第二部分的查找:第2部分是在系统中己加载的模块(系统中所有己成功加载的模块都以链表的形式保存在一个全局变量modules中)的导出符号表中查找对应的符号,如果找到就通过返回该符号的信息,否则函数返回false。图1·6展示了find-symbol在查找一个符号时的搜索路径:
第一部分在对内核符号表进行查找时,首先构造一个struct symsearch类型的数组arr。
bool each_symbol_section(bool (*fn)(const struct symsearch *arr,
struct module *owner,
void *data),
void *data)
{
struct module *mod;
static const struct symsearch arr[] = {
{ __start___ksymtab, __stop___ksymtab, __start___kcrctab,
NOT_GPL_ONLY, false },
{ __start___ksymtab_gpl, __stop___ksymtab_gpl,
__start___kcrctab_gpl,
GPL_ONLY, false },
{ __start___ksymtab_gpl_future, __stop___ksymtab_gpl_future,
__start___kcrctab_gpl_future,
WILL_BE_GPL_ONLY, false },
#ifdef CONFIG_UNUSED_SYMBOLS
{ __start___ksymtab_unused, __stop___ksymtab_unused,
__start___kcrctab_unused,
NOT_GPL_ONLY, true },
{ __start___ksymtab_unused_gpl, __stop___ksymtab_unused_gpl,
__start___kcrctab_unused_gpl,
GPL_ONLY, true },
#endif
};
if (each_symbol_in_section(arr, ARRAY_SIZE(arr), NULL, fn, data))
return true;
list_for_each_entry_rcu(mod, &modules, list) {
struct symsearch arr[] = {//构造一个struct symsearch类型的数组arr
{ mod->syms, mod->syms + mod->num_syms, mod->crcs,
NOT_GPL_ONLY, false },
{ mod->gpl_syms, mod->gpl_syms + mod->num_gpl_syms,
mod->gpl_crcs,
GPL_ONLY, false },
{ mod->gpl_future_syms,
mod->gpl_future_syms + mod->num_gpl_future_syms,
mod->gpl_future_crcs,
WILL_BE_GPL_ONLY, false },
#ifdef CONFIG_UNUSED_SYMBOLS
{ mod->unused_syms,
mod->unused_syms + mod->num_unused_syms,
mod->unused_crcs,
NOT_GPL_ONLY, true },
{ mod->unused_gpl_syms,
mod->unused_gpl_syms + mod->num_unused_gpl_syms,
mod->unused_gpl_crcs,
GPL_ONLY, true },
#endif
};
if (mod->state == MODULE_STATE_UNFORMED)
continue;
if (each_symbol_in_section(arr, ARRAY_SIZE(arr), mod, fn, data))
return true;
}
return false;
}
注意这里的__start__ksymtab、__start__kcrctab和_stop__ksymtab等变量己经在前面的“EXPORT_SYMBOL的内核实现”一节中交代过,它们在内核的链接脚本中定义,由链接器负责产生,由内核源码负责声明,现在到了使用它们的时候了。
接下来函数通过调用each_symbol_in_section查询内核的导出符号表,
each_symbol_in_section的核心代码如下(经过适当改写):
each_symbol_section->each_symbol_in_section
static bool each_symbol_in_section(const struct symsearch *arr,
unsigned int arrsize,
struct module *owner,
bool (*fn)(const struct symsearch *syms,
struct module *owner,
void *data),
void *data)
{
unsigned int j;
for (j = 0; j < arrsize; j++) {
if (fn(&arr[j], owner, data))
return true;
}
return false;
}
为了在内核的导出符号表中查找某一指定的符号名,each_symbol_insection函数使用了两层循环:外层j引导的for循环用来遍历符号可能所在的内核导出符号表中的各section:内层i引导的for循环用来遍历外层j引导for循环所指定的section中的每个struct kernel_symbol类型的元素。对于每个kernel_symbol,都会调用find_symbol_in_setion函数。
为了清楚地理解内核加载模块时如何处理“未解决的引用”符号,有必要仔细分析一下find_symbol_in_section函数的主要功能。因为对Linux下的设备驱动程序员而言,几乎每天都在和这个功能打交道,清楚地理解其内核机制,将来一旦在加载模块时出现相关问题,也可以将其快速定位并最终解决。另外,对于带“GPL”后缀的符号名,在写驱动程序的内核模块时常常会遇到,然而其背后到底蕴涵着怎样的设计理念呢?通过分析find_symbol_in_section函数,就可以得到所需的答案:
static bool find_symbol_in_section(const struct symsearch *syms,
struct module *owner,
void *data)
{
struct find_symbol_arg *fsa = data;
struct kernel_symbol *sym;
sym = bsearch(fsa->name, syms->start, syms->stop - syms->start,
sizeof(struct kernel_symbol), cmp_name);
if (sym != NULL && check_symbol(syms, owner, sym - syms->start, data))
return true;
return false;
}
函数首先用strcmp函数来比较kernel_symbol结构体中的name与№中的name(正在查找的符号名,即要加载的内核模块中出现的“未解决的引用”的符号)是否匹配,如果不匹配,那么函数直接返回false。
fsa->gplok和fsa->warn的设定最早是在find_symbol函数中,是通过后者的函数参数传入的。fsa->wam主要用来控制警告信息的输出。fsa->gplok用来表示当前的模块是不是满足GPL协议(GPL module或non-GPL module),fsa->gplok=true表明这是个GPL module,否则就是non-GPL modulee内核判断一个模块是否GPL兼容,要使用到本章后面的“模块的信息”部分中的内容。
对于一个non-GPLmoduie而言,它不能使用内核导出的属于GPL_ONLY的那些符号,所以即使要查找的符号匹配上一个属于GPL_ONLY的符号,也不能认为查找成功。但是如果要查找的符号匹配上一个属于WILL_BE_GPL_ONLY的符号,因为这个导出的符号“将要成为GPL_ONLY”,所以即使现在还不是GPL_ONLY,查找姑且算是成功的,不过即便如此,内核对模块将来对该符号的成功使用没有保障,所以应该给出一个警告信息。对于一个GPL module而言,一切好说,可以使用内核导出的所有符号。
函数如果成功查找到符号,利用传进来的d指针将符号相关信息传给上层调用的函数。
至此,find_symbol的第一部分,即在内核导出的符号表中查找指定的符号己经结束。如果指定的符号没有出现在内核导出的符号表中,那么将进入find_symbol函数的第二部分。
下面开始介绍find_symbol的第二部分,在系统己经加载的模块导出的符号表中查找符号。内核为达成此目的,需要在加载一个内核模块时完成下面两件事。
第一,模块成功加载进系统之后,需要将表示该模块的struct module类型变量mod加入到modules中,后者是一个全局的链表变量,用来记录系统中所有己加载的模块。
list_for_each_entry_rcu(mod, &modules, list) ->list_entry_rcu
第二,模块导出的符号信息记录在mod的相关成员变量中,这个过程的详细描述参见本章前面的“模块导出的符号”部分。
each_symbol用来在系统所有己加载的模块导出的符号中查找某一指定符号,其核心代码片段如下:
list_for_each_entry_rcu(mod, &modules, list) {
struct symsearch arr[] = {//构造一个struct symsearch类型的数组arr
{ mod->syms, mod->syms + mod->num_syms, mod->crcs,
NOT_GPL_ONLY, false },
{ mod->gpl_syms, mod->gpl_syms + mod->num_gpl_syms,
mod->gpl_crcs,
GPL_ONLY, false },
{ mod->gpl_future_syms,
mod->gpl_future_syms + mod->num_gpl_future_syms,
mod->gpl_future_crcs,
WILL_BE_GPL_ONLY, false },
#ifdef CONFIG_UNUSED_SYMBOLS
{ mod->unused_syms,
mod->unused_syms + mod->num_unused_syms,
mod->unused_crcs,
NOT_GPL_ONLY, true },
{ mod->unused_gpl_syms,
mod->unused_gpl_syms + mod->num_unused_gpl_syms,
mod->unused_gpl_crcs,
GPL_ONLY, true },
#endif
};
if (mod->state == MODULE_STATE_UNFORMED)
continue;
if (each_symbol_in_section(arr, ARRAY_SIZE(arr), mod, fn, data))
return true;
相对于find_symbol的第一部分〈在内核导出的符号表中查找某一符号),第二部分唯一的区别在于构造的arr数组。函数在全局链表modules中遍历所有己加载的内核模块,对其中的每一模块都构造一个新的arr数组,然后在其中查找特定的符号。
![[附源码]计算机毕业设计Python“小世界”私人空间(程序+源码+LW文档)](https://img-blog.csdnimg.cn/48cba93da3ad4beea55a442403d4d1b9.png)





![[附源码]计算机毕业设计Python创新创业管理系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/1413f1e2805f4ba3b4f1fa8119f1868a.png)