一、创建ipfs节点
-
通过
ipfs init在本地计算机建立一个IPFS节点 -
本文有些命令已经执行过了,就没有重新初始化。部分图片拷贝自先前文档,具体信息应以实物为准
ipfs init initializing IPFS node at /Users/CHY/.ipfs generating 2048-bit RSA keypair...done peer identity: QmdKXkeEWcuRw9oqBwopKUa8CgK1iBktPGYaMoJ4UNt1MP to get started, enter:
ipfs cat /ipfs/QmVLDAhCY3X9P2uRudKAryuQFPM5zqA3Yij1dY8FpGbL7T/readme
cd /.ipfscd ~/.ipfscd /.ipfs ls blocks datastore version config keystore $ open ./- 执行ipfs init初始化节点之后,会生成一个.ipfs的文件夹,用于存储相关的信息,比如节点ID、环境配置信息、数据存储等
- 如果使用的是MAC电脑,使用shift+command+. 可以查看隐藏文件
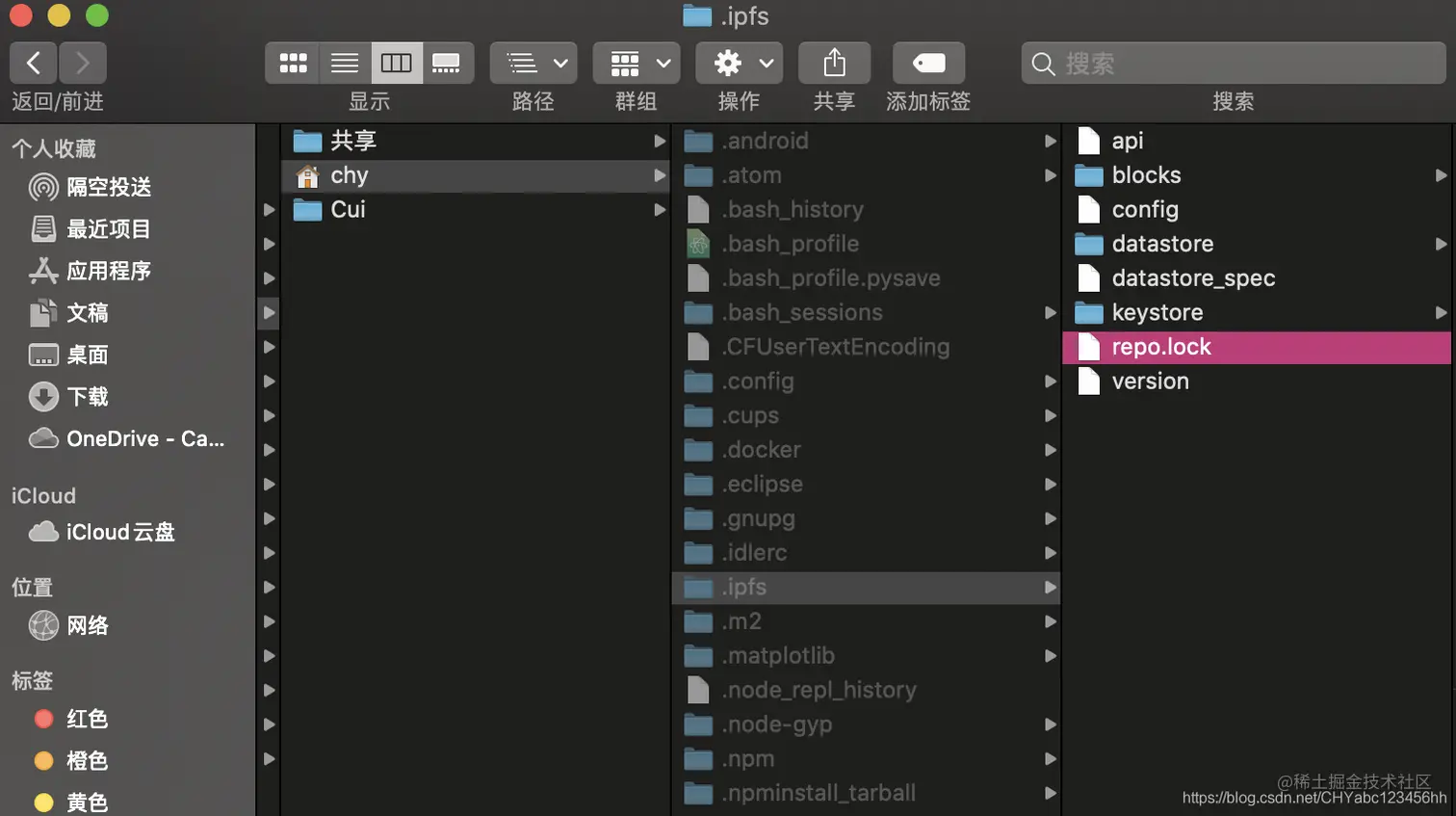
- 通过ipfs id查看创建的节点id的信息

二、启动节点服务器
- 使用命令ipfs daemon启动节点服务器
- 一旦启动当前界面会处于监听状态,需要新建标签页

三、简单验证
-
使用如下命令,进行简单测试
ipfs cat /ipfs/QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG/readme
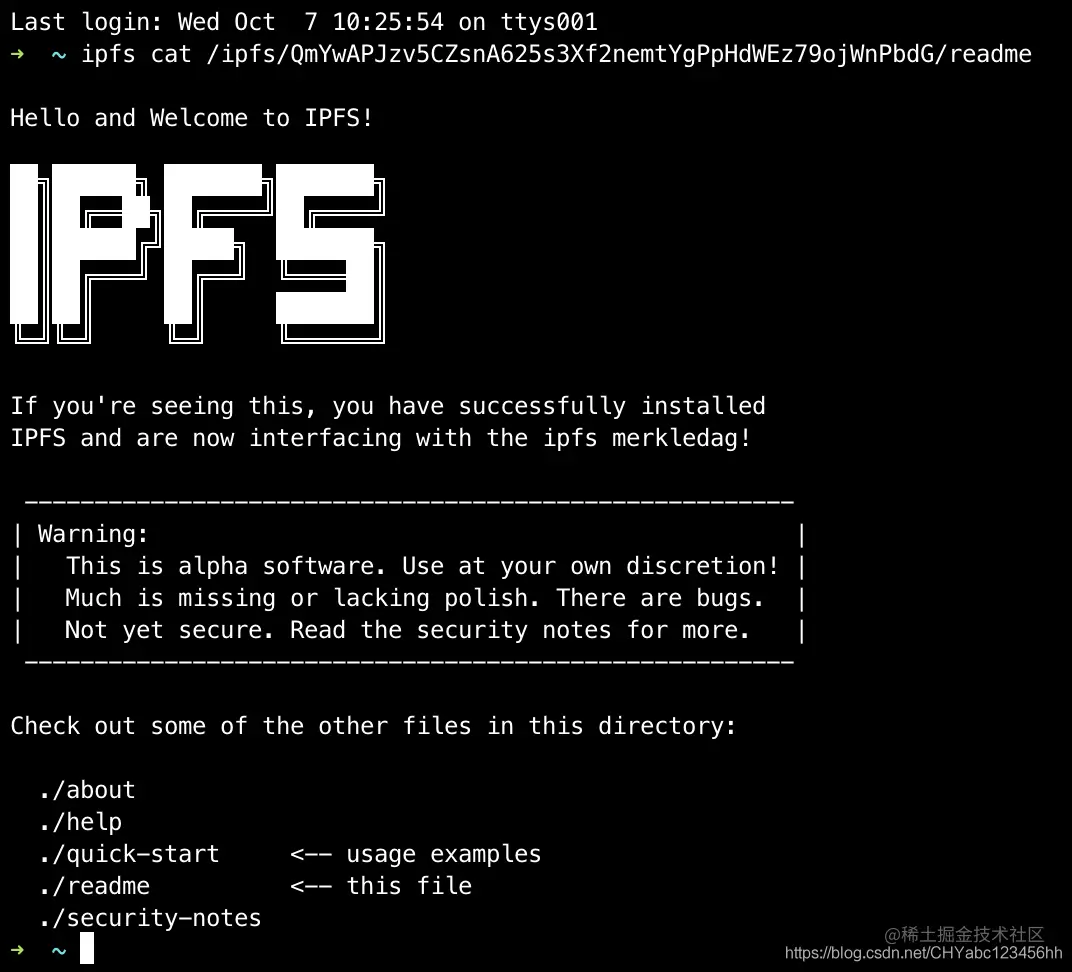
- 浏览器输入下面的网址:http://localhost:5001/webui会看到一个漂亮的
UI界面

四、相关问题详解
1. ipfs的存储位置
- IPFS的数据存储,个人用户的数据存储在自己个人的硬盘上,也就是本地硬盘存储。存储后,会在IPFS网络广播,“我存储哈希为Qm...的数据了”,因为哈希的唯一性,如果数据的分割方法一定,那么同样的数据在网络存储中只会有一份,也就是只在本地节点存储。当有用户检索该数据时,检索数据的hash值就是key,节点会首先在DHT表(key/value存储)中查询有无该key,如果没有,到与key异或距离最近的K桶里查找,如果该K桶中的某个节点有key对应的value则返回,否则返回它认为存有value值的最可能节点,以此递归,最终找到key对应的value。然后请求节点与value(也就是节点ID)建立连接,并请求数据,同时将该key/value键值对存储到自己的DHT表中。请求节点将接收到的数据存储到ipfs缓存中,数据检索成功。该请求节点在缓存数据有效期内,同样可以为ipfs网络,提供该数据,作为原始数据的备份。
2. ipfs的冗余备份措施
- IPFS采用了Erasure coding的冗余备份措施,集群中有n份原始数据和m份校验数据,即共有n+m份备份数据。
3. 修改节点默认存储空间
ipfs节点默认存储空间为10个G
方式一:可打开终端执行下面的命令
export EDITOR=/usr/bin/vim ipfs config edit
- 找到下图使用红色的框标定的内容,修改自己想要的大小
- PS:输入
i可以开始编辑,编译完毕后按esc键,再输入:,再次输入wq保存并且退出
方式二 采用web界面进行修改
- 修改对应的信息,然后点击保存

ipfs的节点掉线,对于整个组织的影响
- IPFS的容错机制会保证数据被复制了足够数量并存放在不同的地区,即使某一个地方的数据由于不可抗力的因素被完全销毁,通过其他地区的备份也可以实现完整恢复数据,极大的保证了存储在IPFS上的数据的安全性
- 采用MerkleDAG,因为它具有以下特点:1.内容可寻址:所有内容都是被多重hash校验和来唯一识别的,包括links。2.无法篡改:所有的内容都用它的校验和来验证。如果数据被篡改或损坏,IPFS会检测到。3.重复数据删除:重复内容并只存储一次。
在IPFS网络中,数据的存储可能是有重复的。重复的数量与用户上传的时候采用的IPFS进行分块的方法有关。 - 之前提到过数据在IPFS存储是以块的形式存储的。在ipfs提供的数据分割方式有很多种。在ipfs源码种core/commands/add.go代码中描述了切割的方法:
-
默认模式,块的大小是256kb,也就是256 * 1024 bytes,对应的size=262144。命令不需要加参数,即ipfs add 文件。
-
指定块大小模式。命令是ipfs add --chunker=size-1000。其中后边的1000可以是任意小于262144的数。
-
rabin可变块大小切割模式。命令是ipfs add --chunker=rabin-[min]-[avg]-[max] 文件。其中min,avg,max的值分别值最小块大小,平均块大小,最大块大小的意思,值在小于262144自行设定。
The chunker option, '-s', specifies the chunking strategy that dictates how to break files into blocks. Blocks with same content can be deduplicated. The default is a fixed block size of 256 * 1024 bytes, 'size-262144'. Alternatively, you can use the rabin chunker for content defined chunking by specifying rabin-[min]-[avg]-[max] (where min/avg/max refer to the resulting chunk sizes). Using other chunking strategies will produce different hashes for the same file.
ipfs add ipfs-logo.svg ipfs add --chunker=size-2048 ipfs-logo.svg ipfs add --chunker=rabin-512-1024-2048 ipfs-logo.svg
- 同一个文件存储在ipfs中,因为存储是选用的文件切割方法不同,返回的hash值却不一样。所以说IPFS的块存储没有重复的,而IPFS块文件拼凑的数据可能有重复的。也就是说同一个文件可以根据不同的文件切割方法在IPFS网络中重复的存储多次。
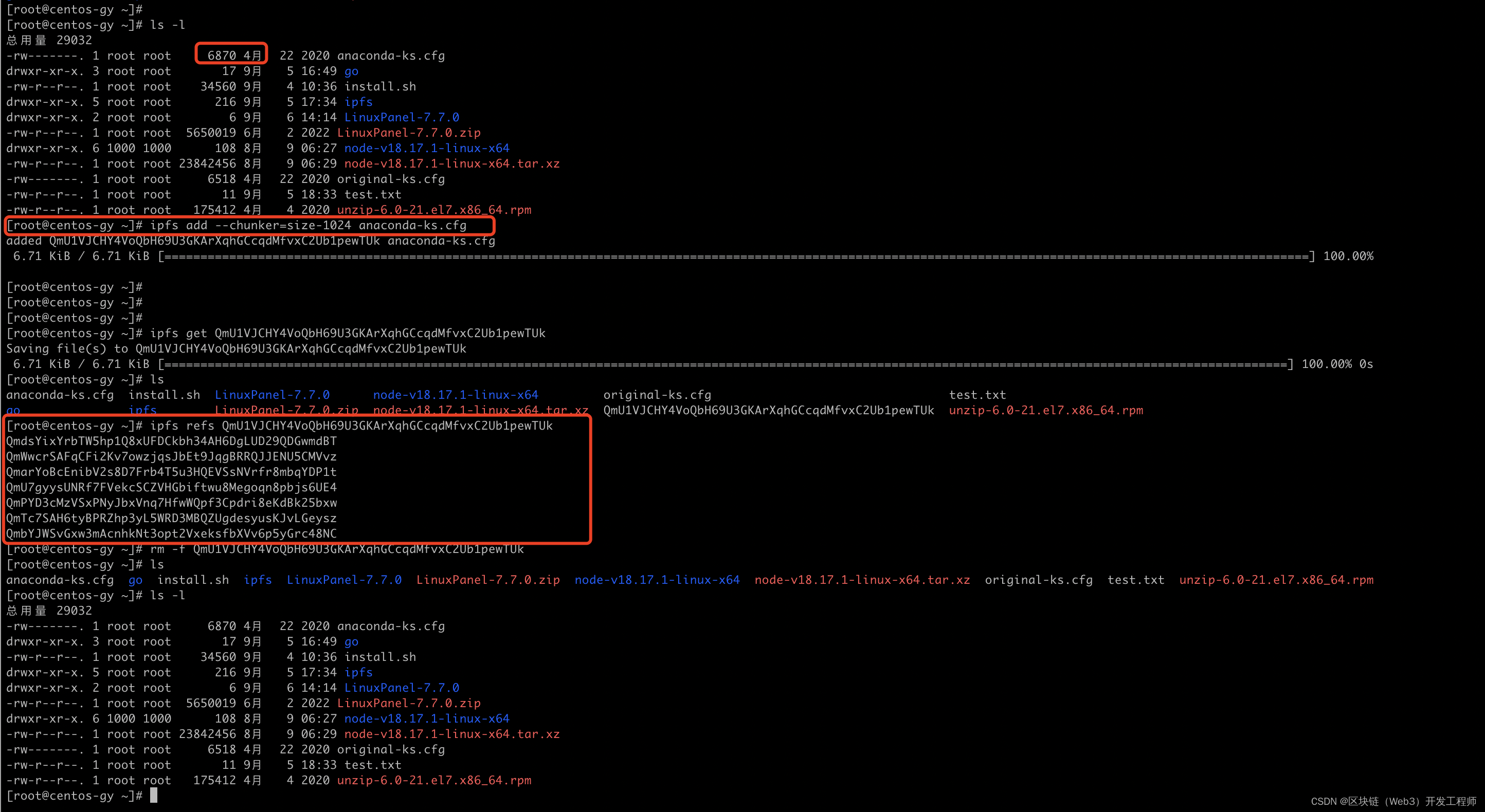
如上图,测试了一个6.8K的文件存储,存储设定1024B为一个分片,分片完后,可以查到这个文件分为了7个分片。
- 备份是如何实现的呢?假如一部非常火的电影,大家都习惯性的将该电影存储到自己的电脑E盘或其它硬盘存储中,全世界如果有1亿的人存储了这个电影,这不是对存储的极大浪费吗?在ipfs网络中,该电影只被存储在一个节点中,当有用户需要读取的时候,会产生新的备份。就是谁使用数据,这个数据就会复制到谁那里。当一个节点加入IPFS网络时,这个节点会提供一部分硬盘空间(缺省为10G,可以配置)给整个网络使用。那么通常情况下,在存储文件的时候,您自己提供的这部分硬盘空间总是最快的,因为不需要跨网。当存储完毕后,网络上任意节点都可以访问这个文件。当另一个节点访问的时候,那个节点往往会复制一份您的数据到他的缓存空间。这样整个网络中就有两份拷贝了。试想,当有很多人对这个文件感兴趣,那么网络中的拷贝数会越来越多。
- 需要提出的是:拷贝一般都是缓存,也就是说是临时存储的。时间一长就被自动删除掉了。这种临时缓存非常好地解决了分布式数据分发的问题,比如说一个社会热点往往呈现出预热期、火热期和退潮期等阶段,利用IPFS,数据的分布和拷贝数与这些时期是完全匹配的。访问的人越多,拷贝数就越多,但热度下来了,拷贝数就会降下来,从而自然地实现空间利用率和存取效率的平衡。如果想让这个文件永久存储,那么必须将其设为固定的样式,即存储在硬盘中。
4. ipfs的使用
上传txt文件

上传其他格式的文件
- docx
- jpg
- mp4
- mp3
注意事项
- 对于下载的文件需要进行格式的准换,否则不可用。这个转化的方式可以手工进行转化,也可以使用命令的方式。
- 也可以指定下载的文件名称,加上
-o 文件名,也可以加上-a : 压缩成.tar格式,-C :压缩成.gz格
ipfs get QmZJBKrLFPvn8zEatZsxSJTtJkCFm4YeMwChDLRPPPerZ6 -o 1.pdf

- 使用命令open hh.pdf 打开pdf文件,此处open的用法是Linux自带功能,和ipfs无关
docx

mp3
jpg

mp4

上传整个文件夹
- 此处上传的整个文件夹里面的文件和先前测试使用的是相同的文件,所以他们的哈希值是一致的,这个就是ipfs要求的避免相同的文件被用户上传多次。

查看上传的文件中包含的子文件

查看被引用的hash
- 被引用的hash概念:一般指文件夹下面有多少个文件,这个文件夹的名称就被引用多少次,hash就是应用该文件名的文件hash

如果上传的是一个文件夹,那么将文件夹拉回到本地,里面的文件是正常的存储格式,无需进行格式转化

进入web可视化界面,将哈希序列输入到搜索框,进行文件的查询,如果文件不支持预览,需要点击downloading进行下载查看
发现的问题
- 使用root用户和普通用户,使用ipfs id查看自己的节点信息,还不一样。


而且,这两个节点之间还不能互相交换文件,不隶属于同一个集群。

参考链接
- 使用ipfs完成一个图片上传的案例
- IPFS:分布式文件存储
- IPFS