文章目录
- 1、得到索引
- 2、高得分框参与匹配,可能会留下有匹配不了的框
- 3、低得分框参与匹配
- 4、处理 unconfirmed 匹配
- 5、创建新的【STrack对象】
- 6、扔掉太久没匹配到框的【STrack对象】
- 7、输出追踪框
1、得到索引
self.args.track_thresh是轨迹阈值。轨迹的得分是iou得分乘以框的置信度。
remain_inds 是高得分的框的索引。
inds_second 是低得分的框的索引(介于0.1到self.args.track_thresh之间)。
remain_inds = scores >= self.args.track_thresh
inds_low = scores > 0.1
inds_high = scores < self.args.track_thresh
inds_second = np.logical_and(inds_low, inds_high)
dets_second = bboxes[inds_second] # 低得分的框
dets = bboxes[remain_inds] # 高得分的框
scores_keep = scores[remain_inds] # # 高得分的框的对应score
scores_second = scores[inds_second] # 低得分的框的对应score
2、高得分框参与匹配,可能会留下有匹配不了的框
detections 中是高得分的框做成的STrack类。
if len(dets) > 0:
'''Detections'''
detections = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets, scores_keep)]
else:
detections = []
之前没确认的STrack是unconfirmed。
之前处于追踪中的STrack是tracked_stracks。【track.is_activated】
''' Add newly detected tracklets to tracked_stracks'''
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
用跟踪着的track和lost的track都参与高分框detections 的匹配。
这一步是关键计算:dists = matching.fuse_score(dists, detections) # !! IOU分数乘以框的置信度分数!!
和所有的检测框计算iou的时候,用的是卡尔曼预测出的框。
''' Step 2: First association, with high score detection boxes'''
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks) # 跟踪着的track和lost的track
# Predict the current location with KF
STrack.multi_predict(strack_pool) # 更新mean和covariance
dists = matching.iou_distance(strack_pool, detections) # 和所有的检测框计算iou,越小越匹配。1就是没有交合。
if not self.args.mot20:
dists = matching.fuse_score(dists, detections) # !! IOU分数乘以框的置信度分数!!
使用matching.linear_assignment进行匹配,之前的【STrack对象】是否能匹配上现在的【检测框】,依靠self.args.match_thresh 作为阈值。matches是配对了的,比如 [(1,2)] 就表示strack_pool中第1个【STrack对象】和detections中第2个检测框匹配上了。
显然,u_track就是剩下的没匹配成功的【STrack对象】序号,比如[4]。
u_detection 就是剩下的没匹配成功的detections中的检测框序号,比如[0]。
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=self.args.match_thresh) # matches是匹配的,u_track是没有匹配的track,u_detection是没有匹配的检测框
对匹配上的matches,如果track.state == TrackState.Tracked,更新【STrack对象】(卡尔曼的更新步骤)。
否则就是track.re_activate(det, self.frame_id, new_id=False)(里面也是卡尔曼的更新步骤)。
for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
track.update(detections[idet], self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
3、低得分框参与匹配
r_tracked_stracks 中是在追踪中的【STrack对象】,而且高分框没匹配上剩下的。
''' Step 3: Second association, with low score detection boxes'''
# association the untrack to the low score detections
if len(dets_second) > 0:
'''Detections'''
detections_second = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets_second, scores_second)]
else:
detections_second = []
r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]
dists = matching.iou_distance(r_tracked_stracks, detections_second)
采用更低的阈值进行选取matching.linear_assignment(dists, thresh=0.5 )。
matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)
能匹配上的依旧激活。
for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
对高分框和低分框都匹配不上的【STrack对象】,放入lost_stracks。
到这里,对上一帧出现的所有【STrack对象】,都已经有了归宿,要么去activated_starcks、要么去refind_stracks、要么来到这里的lost_stracks。
for it in u_track:
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost:
track.mark_lost()
lost_stracks.append(track)
4、处理 unconfirmed 匹配
什么要分高得分框匹配和低得分框匹配?因为可以分得更准。
unconfirmed 是之前的状态不满足:track.state == TrackState.Tracked。
u_detection 中是高得分的框,而且在第一次匹配中没有匹配到【STrack对象】剩下来的。
这里尝试进行将 unconfirmed 与 u_detection 进行匹配,碰碰运气。这样可能匹配上,就不用重新给这个框一个新的ID。
这里使用 thresh=0.7,这些thresh其实都是一个重要的超参,你的检测模型低置信度,那这些thresh超参都需要调整,而不是只调整最开始那个。
'''Deal with unconfirmed tracks, usually tracks with only one beginning frame'''
detections = [detections[i] for i in u_detection]
dists = matching.iou_distance(unconfirmed, detections)
if not self.args.mot20:
dists = matching.fuse_score(dists, detections)
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)
处理匹配上的(matches)。
for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])
对于不确信的u_unconfirmed,这次高分框匹配不到的话,将u_unconfirmed中的【STrack对象】加入到removed_stracks。
for it in u_unconfirmed:
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
5、创建新的【STrack对象】
得分高的框,匹配不到任何已有的【STrack对象】,直接分配一个新的ID让这个框成为【STrack对象】,加入到activated_starcks。
""" Step 4: Init new stracks"""
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
track.activate(self.kalman_filter, self.frame_id)
activated_starcks.append(track)
6、扔掉太久没匹配到框的【STrack对象】
上一帧的【STrack对象】,匹配不到框,就会成为lost_stracks。
在这里遍历lost_stracks中的【STrack对象】,太久都无法找到框匹配,超出定义的buffer_size,会扔到removed_stracks中。
""" Step 5: Update state"""
for track in self.lost_stracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
7、输出追踪框
self.tracked_stracks 中是上一帧的所有【STrack对象】,在这一帧里面,有的被分入unconfirmed中,而unconfirmed中没有匹配高分框的话就会标志被标志移除【见4、处理 unconfirmed 匹配】。所以下面这句话就挑选中上一帧还处于追踪的【STrack对象】。
self.tracked_stracks = [t for t in self.tracked_stracks if t.state == TrackState.Tracked]
下面这句就将这一帧能被追踪的所有【STrack对象List】activated_starcks 加到一起。
在这一帧里面,什么条件才能被加入到activated_starcks:
1、 高分框和上一帧的【STrack对象List】tracked_stracks匹配成功,满足track.state == TrackState.Tracked。
2、低分框和上一帧的【STrack对象List】tracked_stracks匹配成功,以更低松懈阈值匹配,满足track.state == TrackState.Tracked。
3、高分框和上一帧的【STrack对象List】unconfirmed匹配成功,以更低松懈阈值。
4、啥都没落着的高分框,自成一个【STrack对象】,加入到activated_starcks。
self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_starcks)
下面这句就将这一帧能被追踪的所有【STrack对象List】refind_stracks加到一起。
在这一帧里面,什么条件才能被加入到refind_stracks:
1、 高分框和上一帧的【STrack对象List】tracked_stracks匹配成功,不满足track.state == TrackState.Tracked,重新激活。
2、低分框和上一帧的【STrack对象List】tracked_stracks匹配成功,以更低松懈阈值匹配,不满足track.state == TrackState.Tracked,重新激活。
self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)
更新 lost_stracks ,lost_stracks 里面有被追踪起来的就删除掉。
self.lost_stracks = sub_stracks(self.lost_stracks, self.tracked_stracks)
self.lost_stracks.extend(lost_stracks)
self.lost_stracks = sub_stracks(self.lost_stracks, self.removed_stracks)
self.removed_stracks.extend(removed_stracks)
去除重叠对象。
self.tracked_stracks, self.lost_stracks = remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)
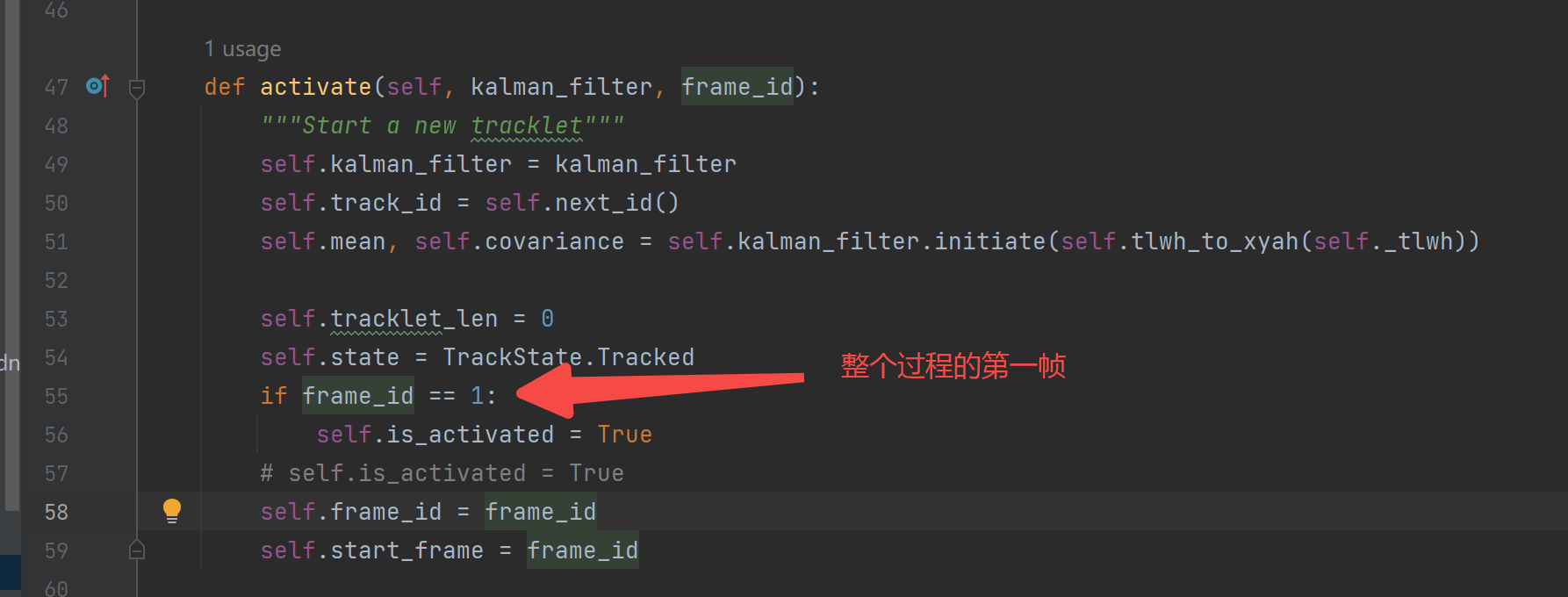
【STrack对象List】中被激活的会输出出去。这里比较坑比的一点是,只有一个帧的高分检测目标框,不会是一个activated的状态(除非是整个过程的第一帧)。
output_stracks = [track for track in self.tracked_stracks if track.is_activated]
坑比的一点,请看vcr: