目录
一:KNN原理
二:数据处理
三:超参调试、模型保存及使用
四:鸢尾花种类预测 详细步骤
一:KNN原理
从训练集中找到跟待测数据最近的k条记录
根据这些记录的分类决定新数据的分类
主要因素包括有:K邻居数目、训练集大小(数据集[训练集]长度的开平方)
1)计算距离:欧式距离 n个影响因素 p
2)找邻居:圈定一个距离待测数据最近的K个相邻对象
3)做分类:根据这些记录做出分类
详细见下面这篇文章
KNN算法原理
二:数据处理
文件读取数据
特征数据、标签数据 --> DataFrame、数据洗牌、重置index
数据格式转换numpy ndarray 维度转换
详细见下面这篇文章
鸢尾花数据集处理
三:超参调试、模型保存及使用
超参调试
1:K 小于数据集[训练集]长度开平方
2:权重weight
3:p 维度*2--欧式距离的次方数加和
4:网络模型交叉数据验证 best_param
模型保存及使用
joblib
dump
load
对于测试集的创建--feature+label
详细见下面这篇文章
KNN搜索最优超参数
四:鸢尾花种类预测 详细步骤
4.1 加载数据
# 加载数据 鸢尾花load_iris
iris_datasets = load_iris()4.2 提取特征数据
# 特征数据
iris_data = iris_datasets['data']4.3 提取标签数据
# 标签数据
iris_target = iris_datasets['target']4.4 数据集划分
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.2, random_state=6)4.5 选择算法
# 选择算法 -- 有监督的分类问题
# KNN K近邻算法(近朱者赤近墨者黑)
# 创建算法
knn_model = KNeighborsClassifier(n_neighbors=3)4.6 构建模型
# 构建基于训练集的模型
knn_model.fit(X_train, y_train)4.7 模型评分
# 模型评分
score = knn_model.score(X_test, y_test)
print(score)输出结果:0.9333333333333333
4.8 调参优化
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.5, random_state=6)
# 选择算法 -- 有监督的分类问题
# KNN K近邻算法(近朱者赤近墨者黑)
# 创建算法
knn_model = KNeighborsClassifier(n_neighbors=3)
# 构建基于训练集的模型
knn_model.fit(X_train, y_train)
# 模型评分
score = knn_model.score(X_test, y_test)
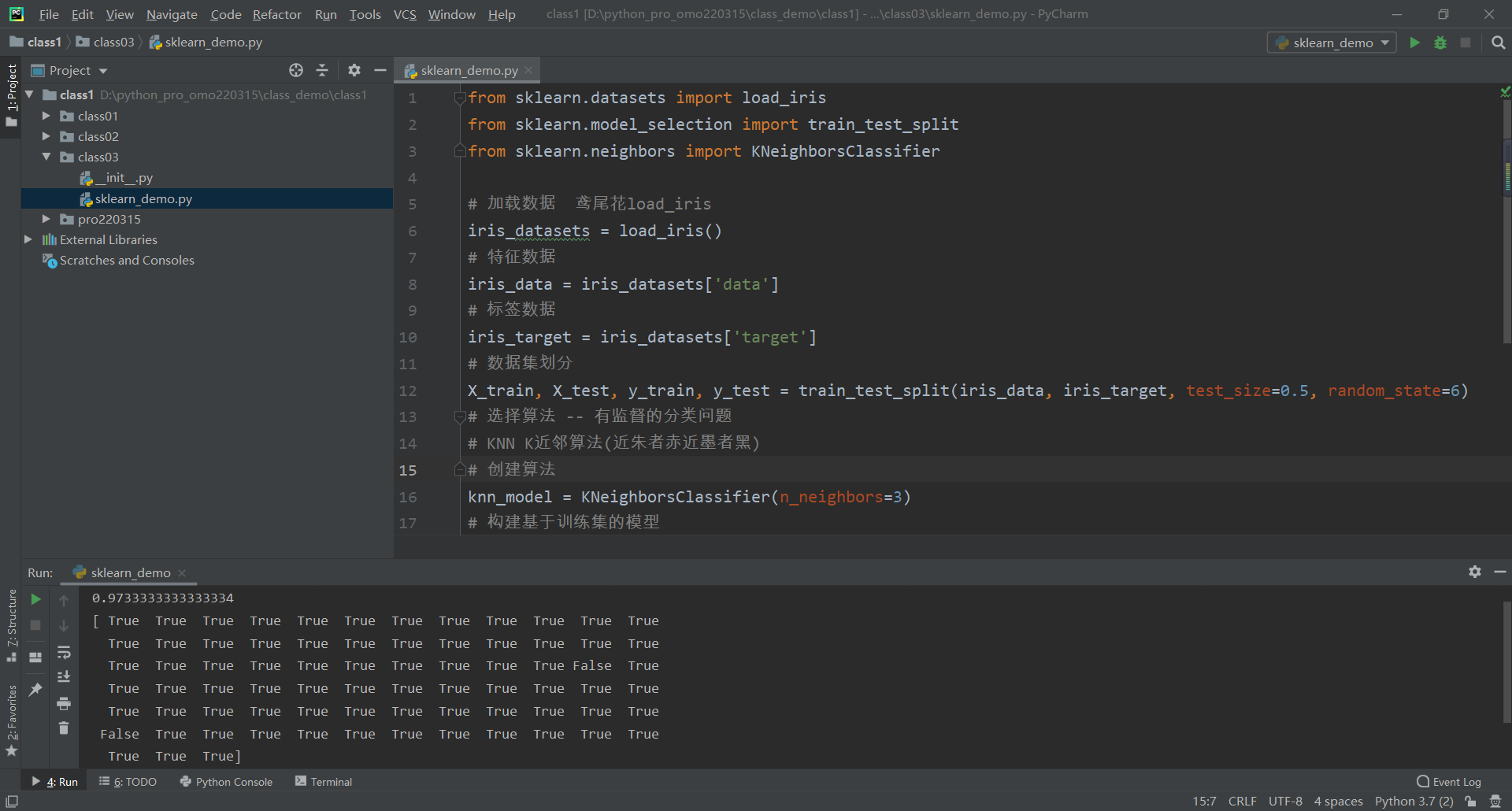
print(score)将test_size设置为0.5的时候,模型评分较高,评分结果如下
0.97333333333333344.9 模型预测
# 模型预测
predict_y = knn_model.predict(X_test)
print(predict_y == y_test)[ True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True True True True True False True
True True True True True True True True True True True True
True True True True True True True True True True True True
False True True True True True True True True True True True
True True True]可以看出False预测错误就两个,模型评分还是比较高的
4.10 完整源码分享
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载数据 鸢尾花load_iris
iris_datasets = load_iris()
# 特征数据
iris_data = iris_datasets['data']
# 标签数据
iris_target = iris_datasets['target']
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.5, random_state=6)
# 选择算法 -- 有监督的分类问题
# KNN K近邻算法(近朱者赤近墨者黑)
# 创建算法
knn_model = KNeighborsClassifier(n_neighbors=3)
# 构建基于训练集的模型
knn_model.fit(X_train, y_train)
# 模型评分
score = knn_model.score(X_test, y_test)
print(score)
# 模型预测
predict_y = knn_model.predict(X_test)
print(predict_y == y_test)
![[CocosCreator]封装行为树(一)](https://img-blog.csdnimg.cn/202ee5b1a395497fbf8371fd31938ce2.png)









![[C++]类和对象【中】](https://img-blog.csdnimg.cn/fb7efb77258e4cef80c5f2616d527f4e.png)