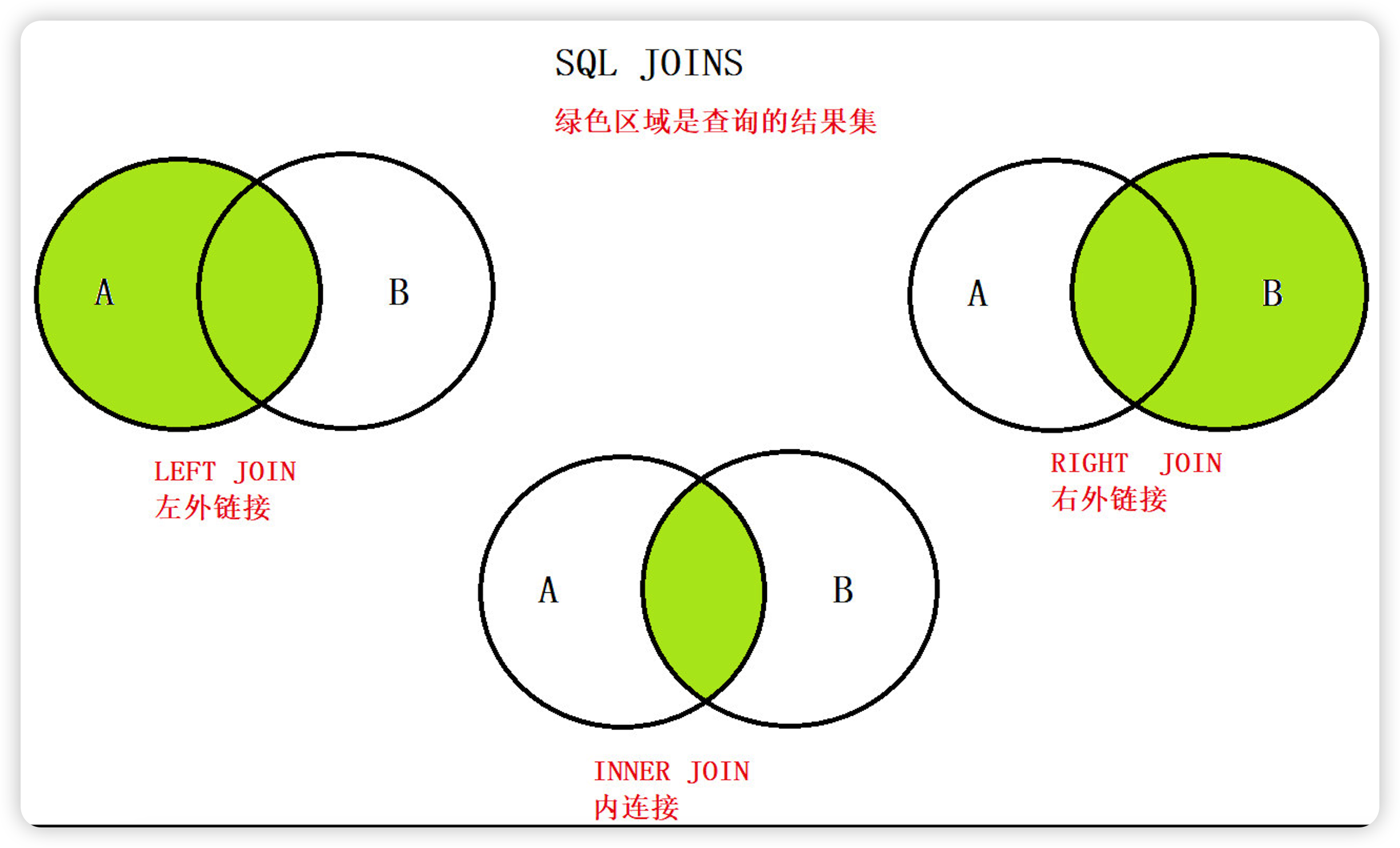
JOIN 是 MySQL 用来进行联表操作的,用来匹配两个表的数据,筛选并合并出符合我们要求的结果集。
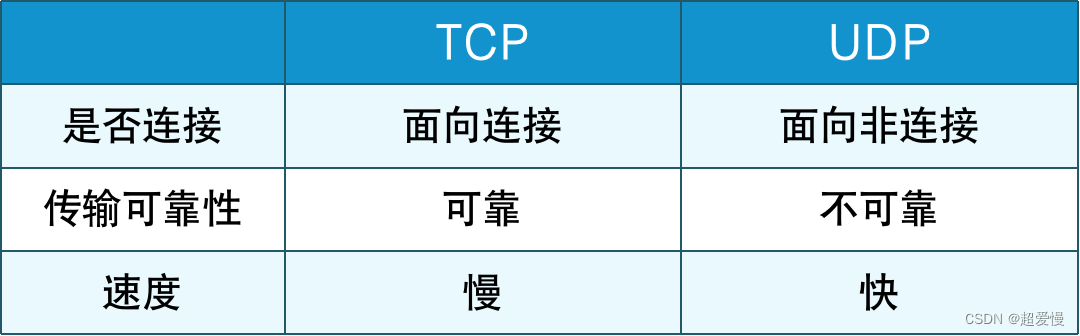
JOIN 操作有多种方式,取决于最终数据的合并效果。常用连接方式的有以下几种:
什么是驱动表 ?
-
多表关联查询时,第一个被处理的表就是驱动表,使用驱动表去关联其他表.
-
驱动表的确定非常的关键,会直接影响多表关联的顺序,也决定后续关联查询的性能
驱动表的选择要遵循一个规则:
-
在对最终的结果集没有影响的前提下,优先选择结果集最小的那张表作为驱动表
3) 三种JOIN算法
1.Simple Nested-Loop Join( 简单的嵌套循环连接 )
-
简单来说嵌套循环连接算法就是一个双层for 循环 ,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果.
-
这种算法是最简单的方案,性能也一般。对内循环没优化。
-
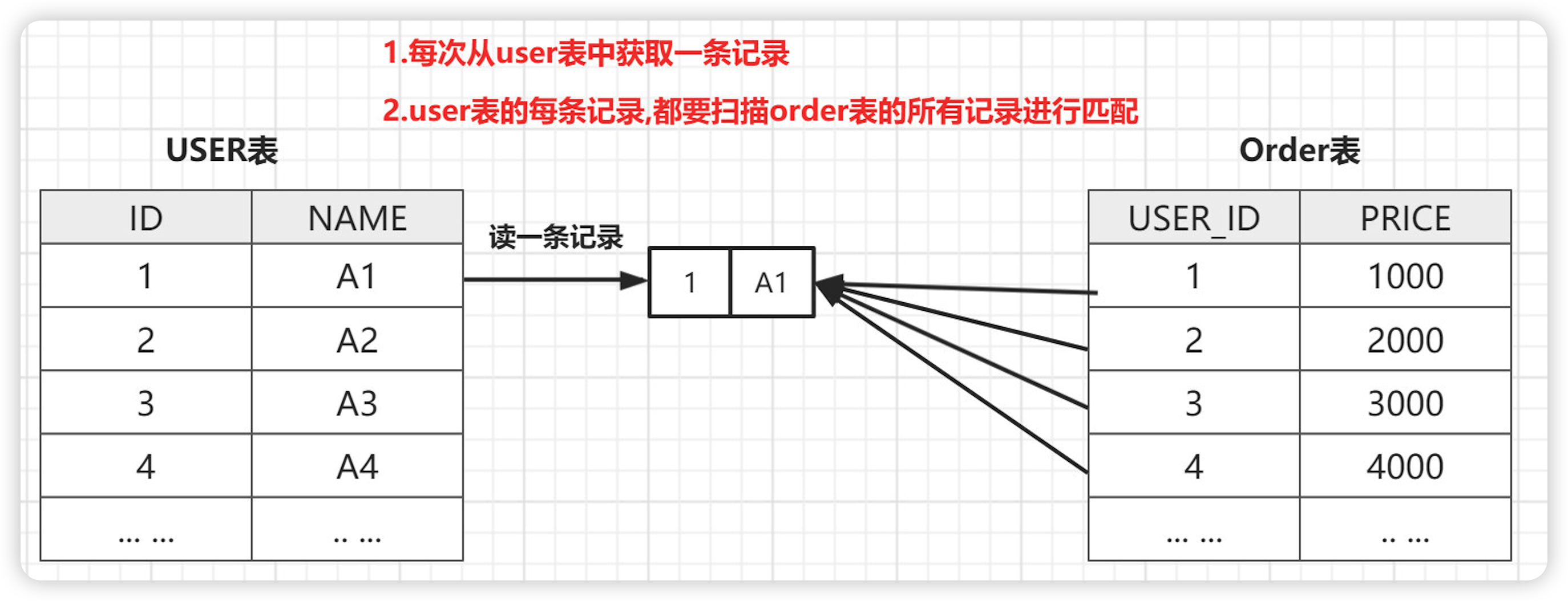
例如有这样一条SQL:
-- 连接用户表与订单表 连接条件是 u.id = o.user_id select * from user t1 left join order t2 on t1.id = t2.user_id; -- user表为驱动表,order表为被驱动表
-
转换成代码执行时的思路是这样的:
for(user表行 uRow : user表){ for(Order表的行 oRow : order表){ if(uRow.id = oRow.user_id){ return uRow; } } } -
匹配过程如下图
-
SNL 的特点
-
简单粗暴容易理解,就是通过双层循环比较数据来获得结果
-
查询效率会非常慢,假设 A 表有 N 行,B 表有 M 行。SNL 的开销如下:
-
A 表扫描 1 次。
-
B 表扫描 M 次。
-
一共有 N 个内循环,每个内循环要 M 次,一共有内循环 N * M 次
-
-
2) Index Nested-Loop Join( 索引嵌套循环连接 )
-
Index Nested-Loop Join 其优化的思路: 主要是为了减少内层表数据的匹配次数 , 最大的区别在于,用来进行 join 的字段已经在被驱动表中建立了索引。
-
从原来的
匹配次数 = 外层表行数 * 内层表行数, 变成了匹配次数 = 外层表的行数 * 内层表索引的高度,极大的提升了 join的性能。 -
当
order表的user_id为索引的时候执行过程会如下图:
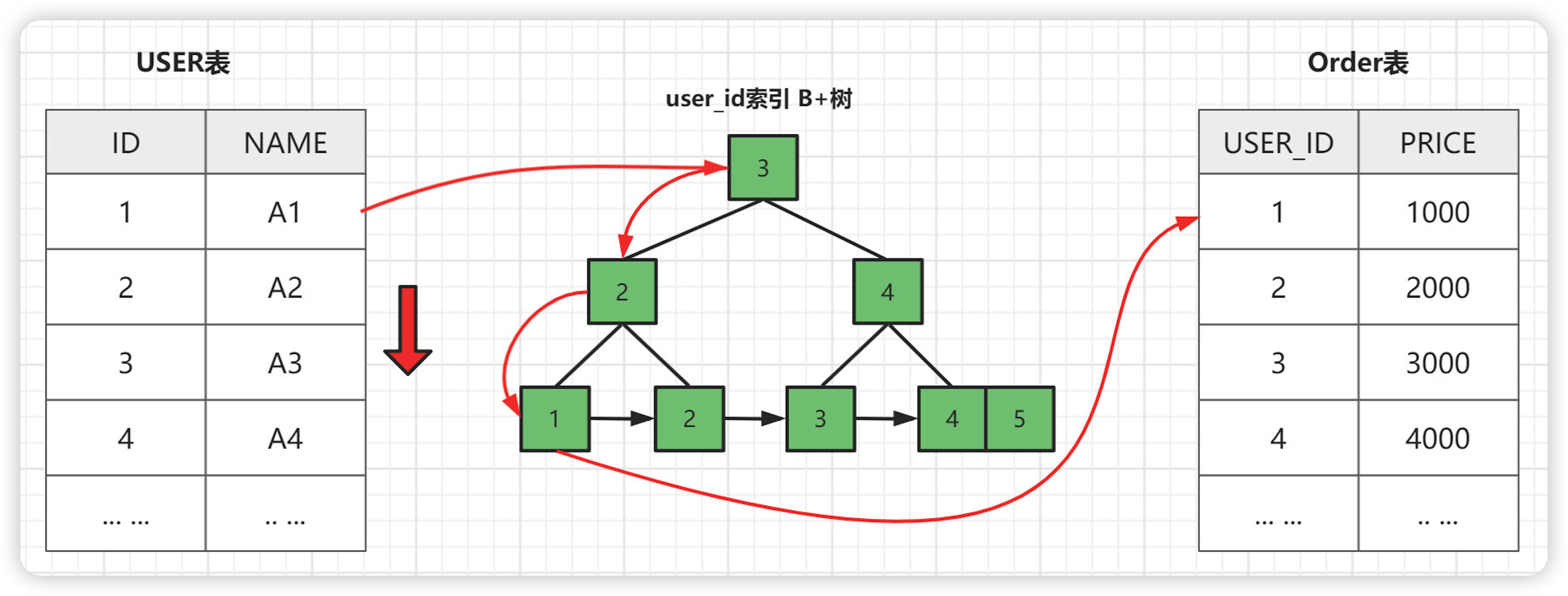
注意:使用Index Nested-Loop Join 算法的前提是匹配的字段必须建立了索引。
3) Block Nested-Loop Join( 块嵌套循环连接 )
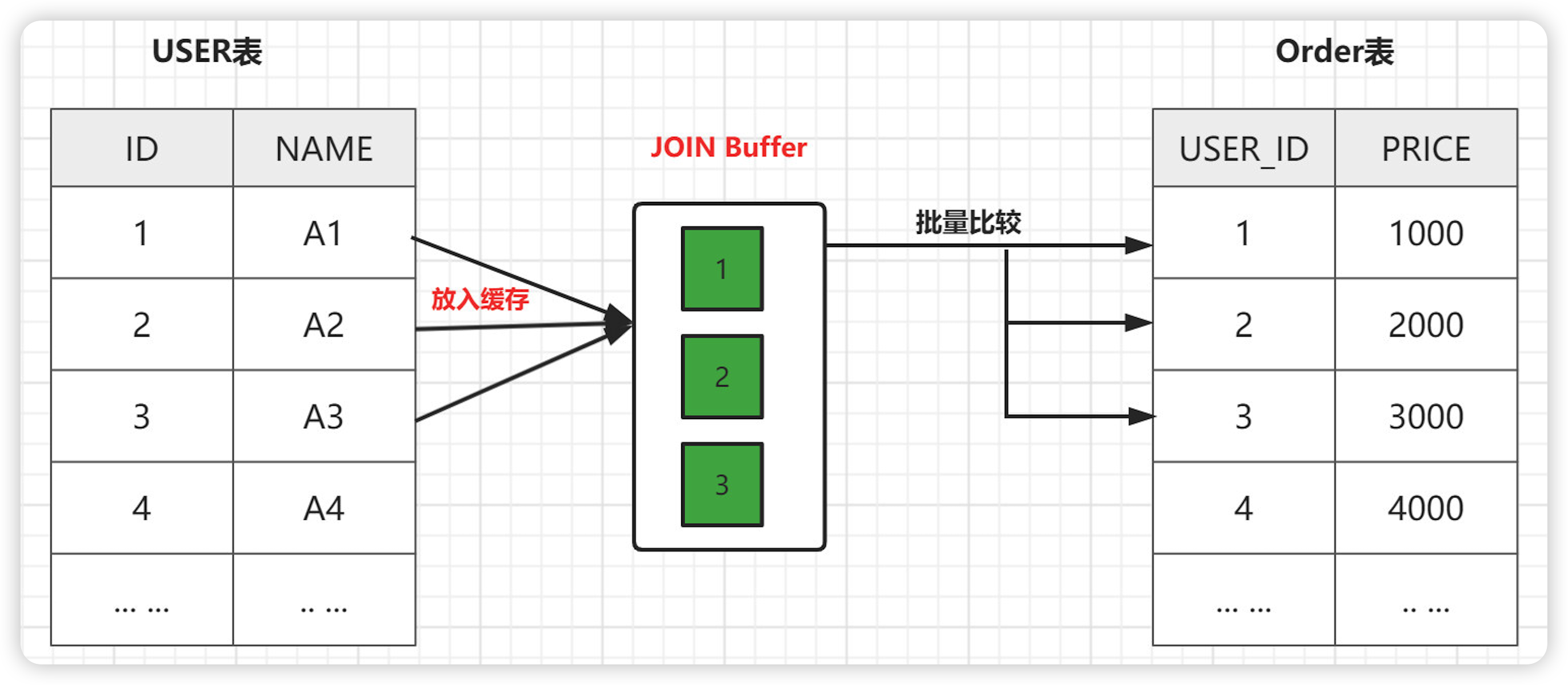
如果 join 的字段有索引,MySQL 会使用 INL 算法。如果没有的话,MySQL 会如何处理?
因为不存在索引了,所以被驱动表需要进行扫描。这里 MySQL 并不会简单粗暴的应用 SNL 算法,而是加入了 buffer 缓冲区,降低了内循环的个数,也就是被驱动表的扫描次数。
-
在外层循环扫描 user表中的所有记录。扫描的时候,会把需要进行 join 用到的列都缓存到 buffer 中。buffer 中的数据有一个特点,里面的记录不需要一条一条地取出来和 order 表进行比较,而是整个 buffer 和 order表进行批量比较。
-
如果我们把 buffer 的空间开得很大,可以容纳下 user 表的所有记录,那么 order 表也只需要访问一次。
-
MySQL 默认 buffer 大小 256K,如果有 n 个 join 操作,会生成 n-1 个 join buffer。
mysql> show variables like '%join_buffer%'; +------------------+--------+ | Variable_name | Value | +------------------+--------+ | join_buffer_size | 262144 | +------------------+--------+ mysql> set session join_buffer_size=262144; Query OK, 0 rows affected (0.00 sec)
4) JOIN优化总结
-
永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量)
-
为匹配的条件增加索引(减少内层表的循环匹配次数)
-
增大join buffer size的大小(一次缓存的数据越多,那么内层包的扫表次数就越少)
-
减少不必要的字段查询(字段越少,join buffer 所缓存的数据就越多
知识来源:马士兵教育