文章目录
- 前言
- 储存系统与技术
- 材料
- 高速储存器缓冲储存器(Cache)
- 材料,局部性,访问方式
- Cache全相联映射
- Cache交换与一致性
- 单核CPU一致性处理
- 多核CPU的MESI协议
- 主储存器(内存)
- 主要技术指标
- 容量
- 带宽
- 内存模组与内存颗粒
- 辅助储存器(外存)
- 类型、工作原理、技术指标
- 地址计算(重点)
- CHS编址模型
- LBA与CHS编址互换
- NCQ技术
- 总线技术
- 总线概述
- PCI总线
- PCI-E总线
- USB总线
- I 2 I^2 I2C总线(Inter Integrated Circuit)
- 接口技术(重点)
- 串行接口与应用
- 定时和计数技术
- 红外
- WiFi
- 中断技术
- 中断概述
- 中断处理
- 实模式中断处理
- 保护模式中断处理
- 8259:可编程中断控制器(重点)
- 高级可编程中断控制器
前言
学校这学期开了一门《汇编语言与接口技术》,这篇文章是接口技术部分。前面还有一部分微机原理,在汇编语言笔记里,本文介绍更加高层次的计算机组成原理。
汇编语言笔记
接口技术笔记TODO
储存系统与技术
除了计算以外,其他都是选择填空。

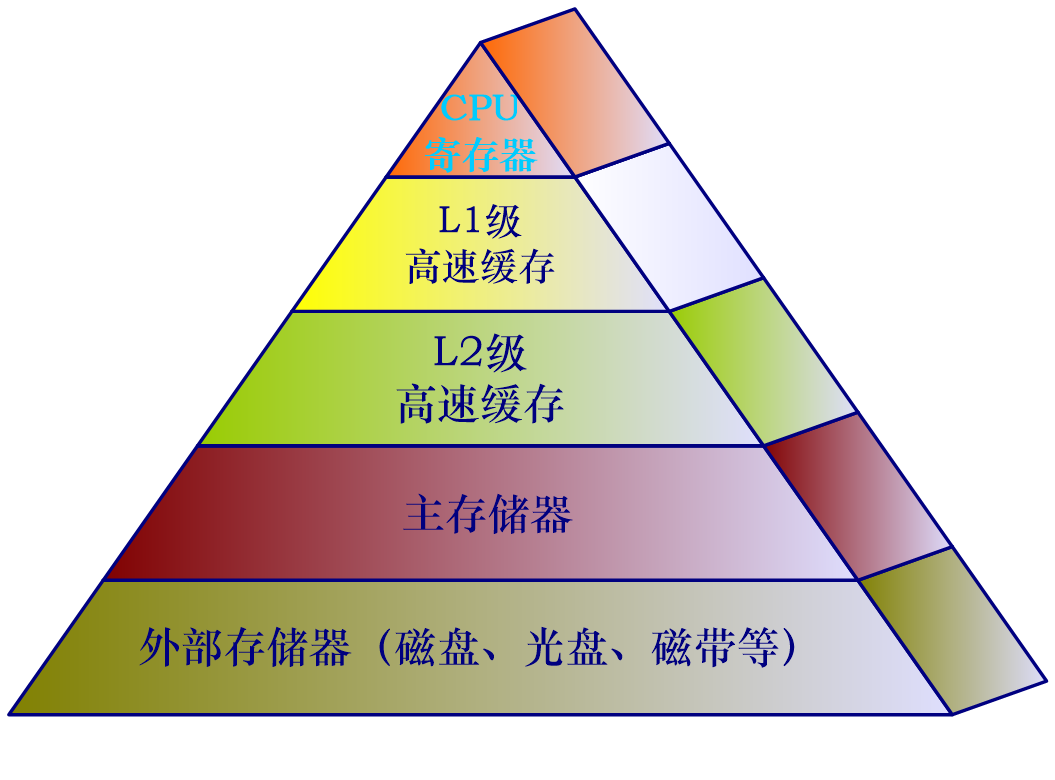
储存层次已经是老生常谈了,越往上,速度越快,成本越高,容量越小。速度快的,用于频繁访问的数据,比如程序的局部变量,速度慢的,用于偶尔访问的数据,比如一个文档。
因为是逐层的,所以内存和外存的关系,可以推广到高层和底层的关系,cache和内存的关系很像内存和外存的关系,比如cache也有交换机制。这些都是后话了,这里简单提一嘴。
材料
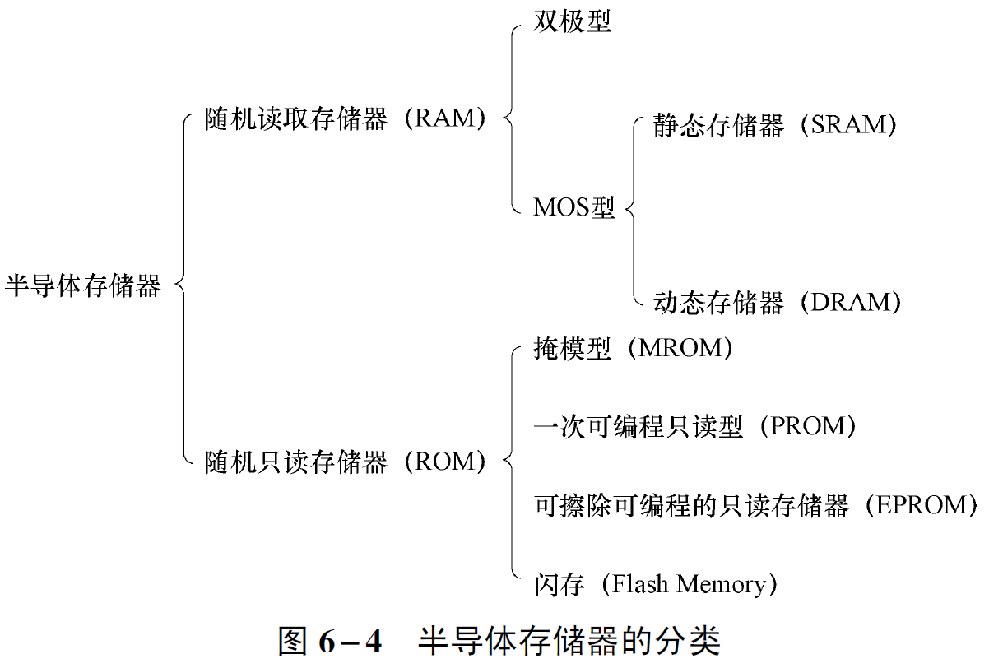
RAM分类如下:
- 双极性。用于Cache
- MOS型。
- SRAM(Static RAM)。用于cache
- DRAM(Dynamic RAM)。需要定期刷新,用于内存
ROM分类如下:
- MROM(Mask ROM)。制造的时候写入数据
- PROM(Programmable ROM)。支持一次编程
- EPROM(Erasable PROM)。可擦除,支持多次重头编程
- Flash。闪存。
高速储存器缓冲储存器(Cache)
Cache记录了主存中需要频繁访问的一小部分数据。
材料,局部性,访问方式
从制作材料来说:
- cache由SRAM制成。
- 内存由DRAM制成
SRAM读取速度比DRAM更快,用于制作cache,SRAM成本高,所以cache都很小。
那小小的cache为什么能支撑如此频繁的访问呢?原因就在于局部性原理:
- 时间局部性。相邻的时间内,程序会集中访问一个数据。
- 空间局部性。程序更倾向于访问空间上相邻的区域。
cache的访问结构有两种,从本质上来说,贯通查找是串行,旁路读出是并行:
- 贯通查找式(Look Through)。CPU先访问cache,如果cache中没有,再去内存中访问。cache平均访问时间 = cache访问时间+(1-命中率)×未命中时主存访问时间
- 旁路读出式(Look Aside)。读取方式类似于操作系统的快表TLB,CPU同时去cache和内存中找数据,如果cache里有那就最好,即使cache里没有,查找速度也比贯通查找要快,已经节省了读Cache的时间。cache平均访问时间 = 命中率×cache访问时间+(1-命中率)×未命中时主存访问时间
Cache全相联映射
Cache映射方式有三种,我们只介绍全相联映射。本节具体谈一下Cache的访问机制。
Cache中的内容是内存的一个子集,因此Cache中数据块大小和内存中一致。而在Cache与内存之间,通过目录表记录cache块与内存块之间的映射关系(下图中的M1与C1,M2与C2的对应关系)。内存和Cache存放数据本身,而目录表存放映射关系,记录了内存中的哪些数据块被存到cache中了。
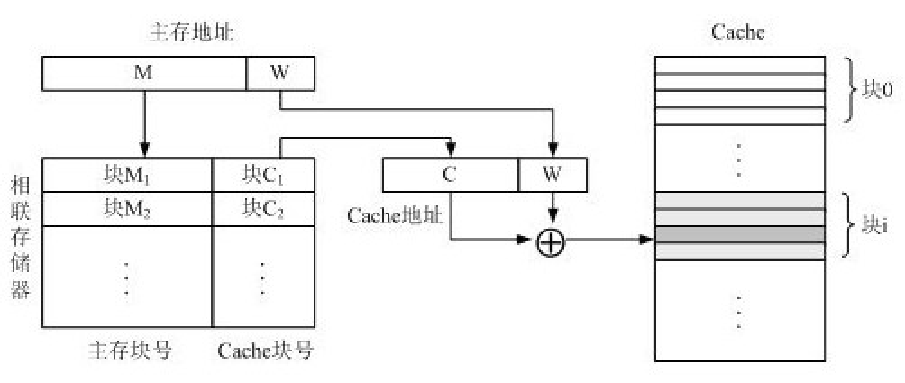
CPU读数据的时候,是不会区分cache与内存的,他只是提供一个内存地址,即我们要访问某个内存数据块M。那么第一步是要检查cache中是否已经有M的数据,检查就要用到目录表。全相联映射的做法是,遍历目录表,看看M是否在目录表中,有的话就是hit,直接把M的内存地址转换成cache中的地址。之后再加上偏移量就是我们要的数据。
如果M没有记录在目录表中,就是miss,此时就去内存中找数据。
Cache交换与一致性
cache的miss和缺页中断类似,发生miss后cache会从主存调块。如果cache中没有空闲的行,就会进行替换。替换方法同操作系统中缺页中断的替换方法,比如FIFO,LRU等,还有一个额外的随机算法。
写cache的时候,会对内容进行修改,就会影响到后面的交换。比如修改了cache,替换这一块数据前就得先回写到内存中去。此类问题统称为数据一致性问题。
单核CPU一致性处理
- miss。直接把写的内容写到内存。写完后有的计算机会把数据块调入cache。
- hit。
- 直写式。写cache的同时,写内存。缺点在于,写完内存之前,cache不能用,会拖慢写入速度。
- 回写式。实际上,没必要频繁写内存,只需要在被置换出去前写一次内存就够了,为此,需要一个dirty位,1代表cache的数据被写过(修改过),则这一行被交换出去的时候需要先写一次内存,把cache的修改同步到内存。如果没修改过,那就不用同步内存。回写式比较快,但是机制比较复杂。
多核CPU的MESI协议
多核,每个CPU都有一个cache,如果两个cpu都把一个内存块数据调到cache里,进行不同的修改,再写回去就会冲突。因此要更复杂的协议,即MESI协议。
MESI协议将数据段定义为4种状态(倒着来):
- I(Invalid)。无效缓存段。仅在内存中,还没有cache使用这个数据段。
- S(share)。共享缓存段。一个内存块在多个cache里都有拷贝,多个处理器共享。
- E(exclusive)。独占缓存段。一个内存块仅被一个cache使用,且没有被修改。
- M(modify)。修改缓存短。一个内存块仅被一个cache使用,且已经被修改。退出M状态前要先进行回写。
针对这些状态,有如下规则:
- 独占可写。当数据处于M和E的时候,才可以写。
- 共享只读。数据处于S时,只读。只要不让多个CPU同时写,就不会出现不一致问题。
主储存器(内存)
内存使用DRAM材料。
主要技术指标
容量
存储单元数量=行数×列数×数据深度×L(Bank的数量)
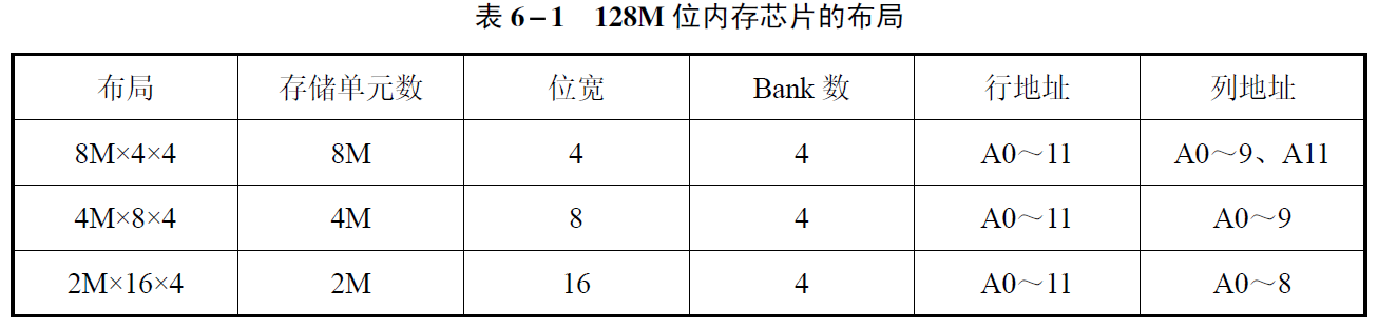
上面的三个布局都是128M,以第一个为例:
- 行地址是0-11,所以行为 2 12 2^{12} 212
- 列地址是0-9与11,列为 2 11 2^{11} 211
- 位宽(数据深度)=4
- bank数=4
所以 2 12 × 2 11 × 2 2 × 2 2 = 2 27 = 2 7 × 2 20 = 128 M B 2^{12}\times 2^{11}\times 2^{2}\times 2^{2}=2^{27}=2^7\times 2^{20}=128MB 212×211×22×22=227=27×220=128MB
带宽
带宽=总线宽度×总线频率/8(B/s)
PC100 SDRAM 外频100MHz时,带宽=64×100/8=800(MB/s)
PC133 SDRAM 外频133MHz时,带宽=64×133/8=1 064(MB/s)
DDR DRAM 外频100MHz时,带宽=64×100×2/8=1.6(GB/s)
SDRAM是普通内存,就用带宽公式即可。但是DDR DRAM是双通道的,所以要翻个倍。
内存模组与内存颗粒
内存颗粒可以理解为内存的储存单元。分为SDRAM和DDR DRAM两种材料,DDR的速度要翻一倍。之所以速度翻倍,是因为SDRAM一个时钟周期只在上升沿传一次数据,而DDR在上升沿和下降沿都会传输一次数据,所以翻倍(Double Date Rate SDRAM)。
现在市面上不单纯卖内存颗粒,而是把相关的控制芯片,颗粒,各种元件焊在一个PCB上组成一个内存模组,俗称内存条,只暴露出接口。
辅助储存器(外存)
类型、工作原理、技术指标
类型:
- 机械硬盘HHD。使用ATA标准
- PATA接口(Parallel ATA)。我们俗称的ATA接口就是PATA接口,速度慢,抗干扰差,逐渐被取代。
- SATA接口(Serial ATA)。支持热插拔
- IDE接口。这是个很大的概念,有时指代PATA,有时候指代SATA
- SCSI接口。淘汰。
- 固态硬盘SSD。接口与HHD相同,但是采用FLASH介质,读写速度不受储存位置影响,很快。但是FLASH材质坏块无法修复,且有擦写次数限制,寿命有限。
工作原理(机械硬盘):
- 盘面(一个盘片两个盘面)
- 磁道
- 扇区。注意,扇区从1开始编址,其他从0开始。
0磁头0柱面1扇区存放了磁盘的主引导区,MBR。
技术指标:
- 容量。
- 转速。很大程度上决定了访问速度
- 缓存。缓存在磁盘读写的初期提供较快的速度,缓存用光以后速度会降下来。
- 访问时间
- 寻道时间。磁头寻道
- 潜伏时间。磁头在磁道上,等待目标扇区转过来的时间
- 访问时间。磁头在目标扇区上访问数据的时间
地址计算(重点)
CHS编址模型
ATA接口采用CHS编址模型:C(柱面)H(磁头)S(扇区):
- 柱面从0开始,总共nC个
- 磁头从0开始,总共nH个
- 扇区从1开始,总共nS个
总共有nC×nH×nS个扇区,每个扇区512B。
下图中,柱面,磁头,扇区的数字都是二进制编址的位数,IED总共有28位,即有
2
28
2^{28}
228个扇区,则总空间为
2
28
×
2
9
B
=
2
7
×
2
30
=
128
G
2^{28}\times 2^{9}B=2^{7}\times 2^{30}=128G
228×29B=27×230=128G。如果是十进制(1G=1000M),则硬盘上限是
2
37
1
0
9
=
137
G
\dfrac{2^{37}}{10^{9}}=137G
109237=137G
LBA与CHS编址互换
LBA(Logical Block Address)是线性的逻辑地址,CHS是物理地址。
在<C,H,S>编址模式中,范围如下:
- 0≤C≤nC−1
- 0≤H≤nH−1
- 1≤S≤nS
如果是1柱面,则代表当前访问的内容在(0,1]柱面之间。CHS转LBA公式:
最后-1是因为S从1开始编址,导致基地址会虚高1个扇区。
L = [ ( C × n H + H ) × n S ] + S – 1 L=[(C×nH + H)×nS]+S–1 L=[(C×nH+H)×nS]+S–1
LAB转CHS公式:
S需要额外+1,因为从1开始编址的
C不需要求模,因为除完以后不可能大于nC了,求不求模都一样。注意,这里的除,是C语言中的整除。
S = L % n S + 1 H = ( L ÷ n S ) % n H C = ( L ÷ n S ÷ n H ) \begin{gather} S =L\%nS+1 \\ H =(L÷nS)\%nH \\ C =(L÷nS÷nH) \\ \end{gather} S=L%nS+1H=(L÷nS)%nHC=(L÷nS÷nH)
例题:

2 11 × 2 4 × 2 6 × 2 9 B = 2 30 B = 1 G B 2^{11}\times 2^{4}\times 2^6 \times 2^9B=2^{30}B=1GB 211×24×26×29B=230B=1GB如果折算成10进制,就是 ( 1024 1000 ) 3 G B (\dfrac{1024}{1000})^3GB (10001024)3GB
逻辑盘块2K,513号(从0开始)对应的逻辑地址为513×2K,对应的LBS地址为 L = 513 × 2 K 512 = 513 × 4 = 2052 L=\dfrac{513\times2K}{512}=513\times 4=2052 L=512513×2K=513×4=2052。接下来计算SHC:
- S = 2052 m o d 64 + 1 = 5 S=2052\mod 64+1=5 S=2052mod64+1=5
- H = ( 2052 / 64 ) m o d 16 = 0 H=(2052/ 64)\mod 16=0 H=(2052/64)mod16=0
- C = ( 2052 / 64 / 16 ) = 2 C=(2052/ 64 / 16)=2 C=(2052/64/16)=2
结果为CHS=<2,0,5>
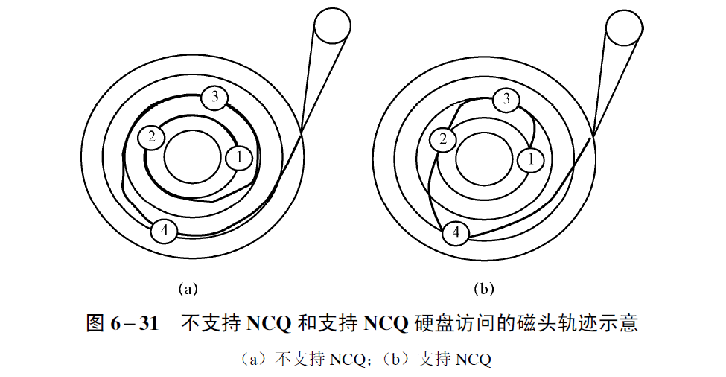
NCQ技术
如果磁盘按照FIFO算法去寻道,可能会花费很久的时间。
NCQ技术对请求序列重新排列,使得数据传输更快速,磁头移动的路径更短:
总线技术
全是概念。

总线概述
PCI总线
PCI-E总线
USB总线
I 2 I^2 I2C总线(Inter Integrated Circuit)
接口技术(重点)

串行接口与应用
8.9

1MB数据,没说有效数据,所以就直接
1
M
×
8
9600
\dfrac{1M\times 8}{9600}
96001M×8即可。
有效数据传输率=数据传输效率,是百分比,与异步串行帧格式有关。这里应该还有个起始位,所以是70%
定时和计数技术
红外
WiFi
中断技术