背景需求:
同事提出给word批量“添加电子公章(png图片)的需求
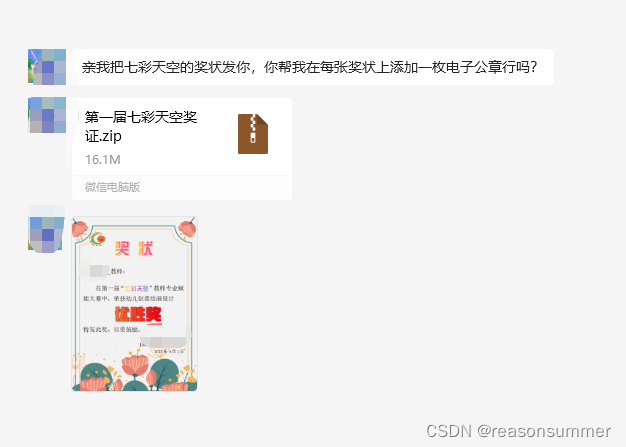
解压文件后,发现:
1、每份WORD文件名是一位老师的证书,需要打开每一份word,插入一个空白电子公章png。
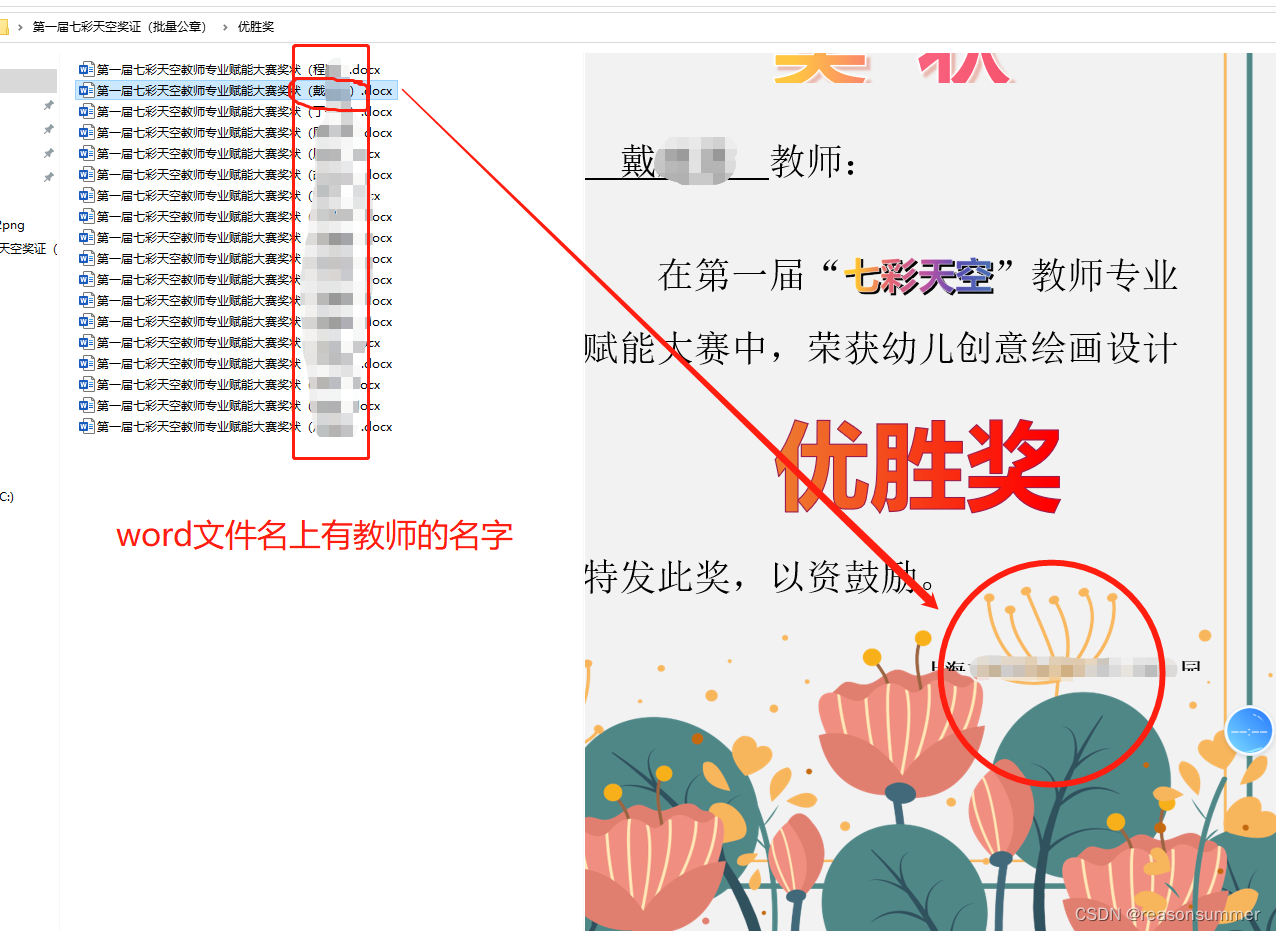
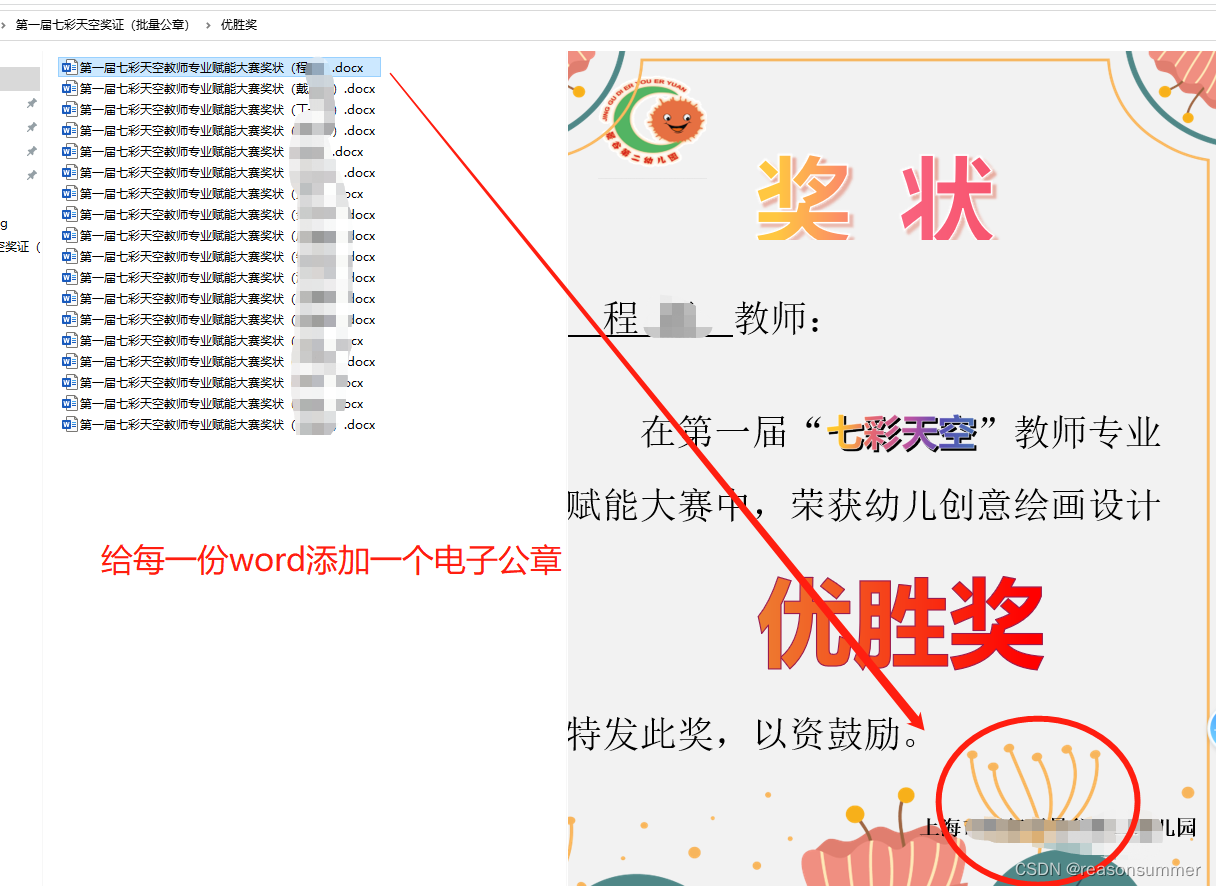 2、每个word文件名包含教师的名字。
2、每个word文件名包含教师的名字。
解题思路:
1、这是同事自己设计的word证书模板,应该是她一个个把名字复制黏贴的(每个word里面已经有名字了)。
2、按同事的需求,我需要打开无数个WORD,然后将电子公章复制并拖动到指定位置,然后保存。(容易遗漏、手动贴公章pngt图片的位置会不同)
3、因为前期做过“大班毕业证书”打印的py程序,所以我觉得最好的方法是“先做一个带公章的word模板+{{name}}”,然后批量生成,而不是一个个插入图片(其实也有程序可以在批量word的指定位置插入图片)
操作流程:
1、用天若OCR,识别教师姓名
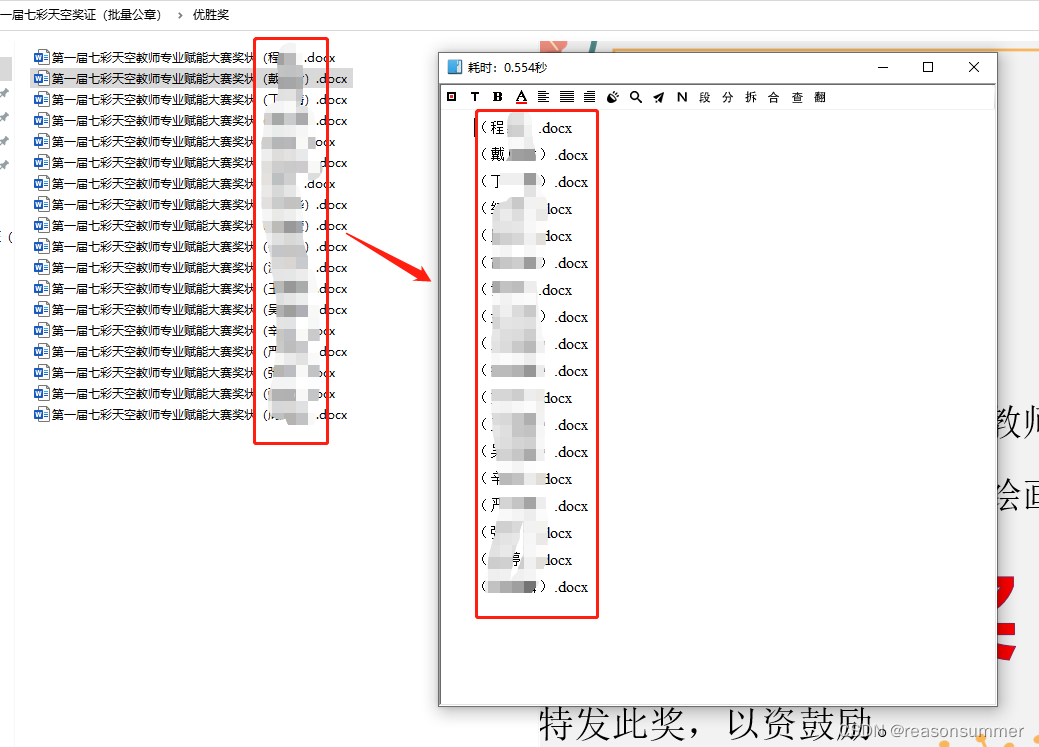
2、复制到EXCEL,分栏,只提取名字,原模板中教师两个名字,中间需要空格,手动按空格。

3、docx模板制作
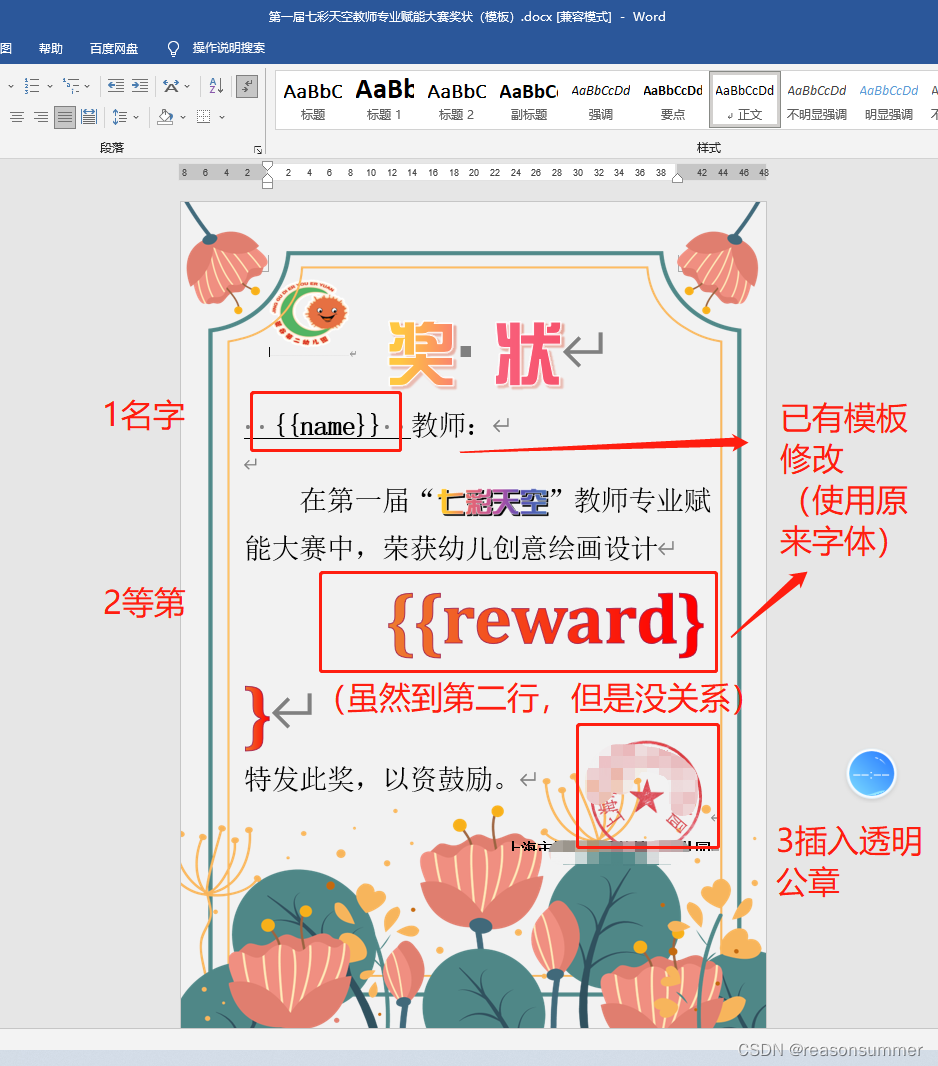
素材位置

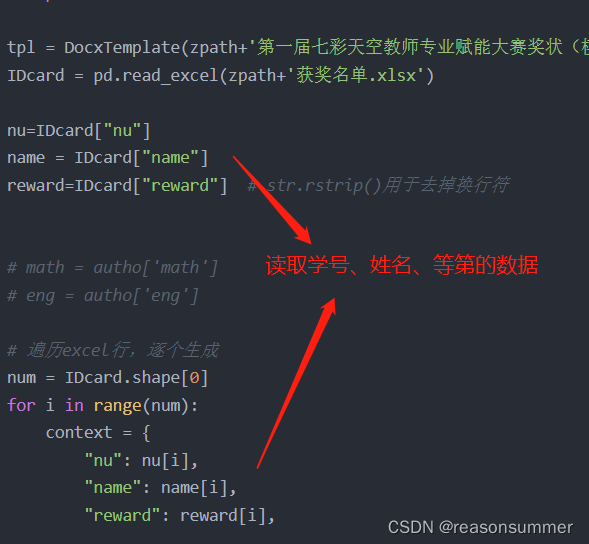
代码展示
# -*- coding:utf-8 -*- 1
'''
目的:教师获奖证书
作者:阿夏
日期:2023年9月6日 13:38
'''
# 一、导入相关模块,设定excel所在文件夹和生成word保存的文件夹
from docxtpl import DocxTemplate
import pandas as pd
import os
import time
#
zpath=os.getcwd()+'\\'
zpath=r'C:\Users\jg2yXRZ\OneDrive\桌面\第一届七彩天空奖证(批量公章)'+'\\'
file_path=zpath+r'\零时Word'
# 二、遍历excel,逐个生成word(form.docx是前面的模板)
try:
os.mkdir(file_path)
except:
pass
tpl = DocxTemplate(zpath+'第一届七彩天空教师专业赋能大赛奖状(模板).docx')
IDcard = pd.read_excel(zpath+'获奖名单.xlsx')
nu=IDcard["nu"]
name = IDcard["name"]
reward=IDcard["reward"] # str.rstrip()用于去掉换行符
# math = autho['math']
# eng = autho['eng']
# 遍历excel行,逐个生成
num = IDcard.shape[0]
for i in range(num):
context = {
"nu": nu[i],
"name": name[i],
"reward": reward[i],
}
tpl = DocxTemplate(zpath+'第一届七彩天空教师专业赋能大赛奖状(模板).docx')
tpl.render(context)
# tpl.save(file_path+r"\{} 的身份证.docx".format(name[i]))
#
tpl.save(r"C:\Users\jg2yXRZ\OneDrive\桌面\第一届七彩天空奖证(批量公章)\零时Word\{}_{}_第一届七彩天空教师专业赋能大赛奖状_({}).docx".format('%02d'%nu[i],reward[i],name[i]))
# from docx2pdf import convert
# # docx 文件另存为PDF文件
# inputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\第一届七彩天空奖证'册/零时Word/{}_第一届七彩天空教师专业赋能大赛奖状_({}).docx".format('%02d'%nu[i],name[i]) # 要转换的文件:已存在
# # print('----------第5步:删除临时文件夹------------')
# import shutil
# shutil.rmtree('D:/test/03办公类/11毕业册/零时Word') #递归删除文件夹,即:删除非空文件夹
代码重点:
终端运行:
直接运行,不用输入参数(不显示任何运行过程)
结果展示:
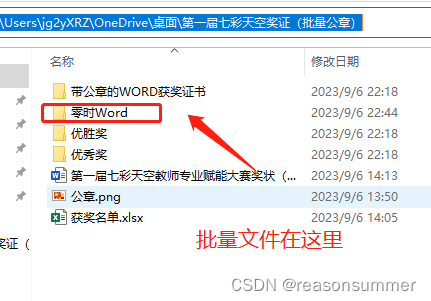
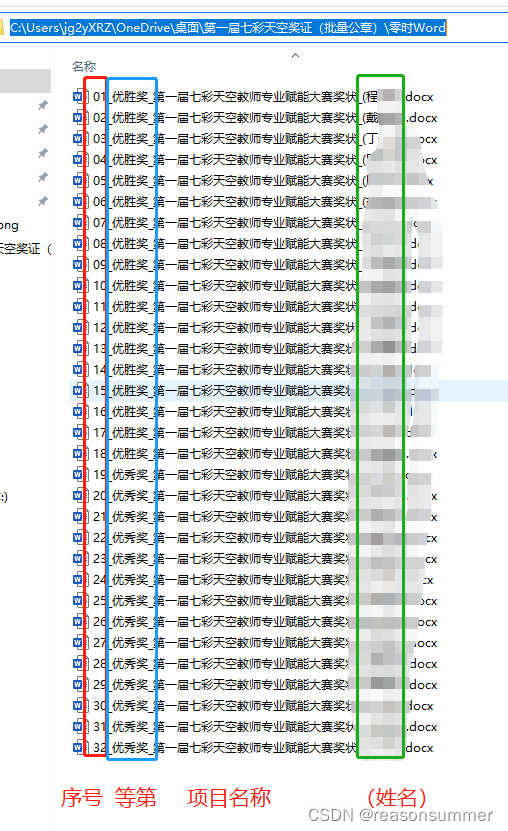
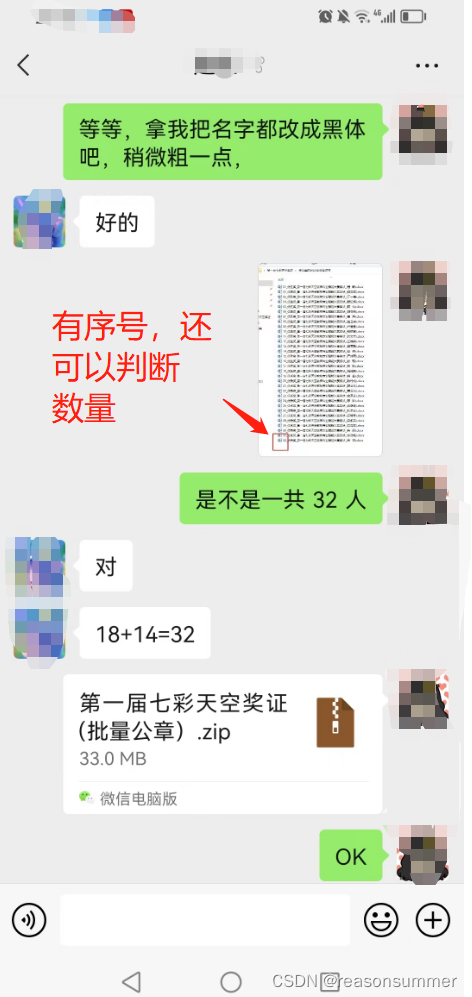
证书效果展示:


可以看到:
教师名字不同,获奖内容不同(优胜、优秀)、公章位置统一
感悟:
用“大班毕业证书”的py代码,略作修改,很快就实现了“教师园级证书”的批量制作
1、它再一次让人从机械重复中摆脱出来(不需要手动一个个黏贴图片)
2、它能实现快速反复修改(名字本来是宋体小四不加粗,我第2次改成了宋体小四加粗),因而能够提升效果、优化质量。(如果手动制作的话,不愿意再改批量做第二次了。)
技术提升效率,需求改变思维。
在忙的要死的阶段里,我是多么迫切希望尽可能减少消耗性重复劳动,获取时间,去做更有价值的事情。

![java八股文面试[数据库]——数据库锁的种类](https://img-blog.csdnimg.cn/img_convert/c148b1baee7458a8bd8633784d707845.png)
![开店星小程序上架教程和后台Request failed with status code 500[undefined]问题处理](https://img-blog.csdnimg.cn/0ffa63b0c751464ea616546541f65253.jpeg)


![[SSM]MyBatisPlus高级](https://img-blog.csdnimg.cn/c80537e7433f46ea882c0f98da3fe269.png)