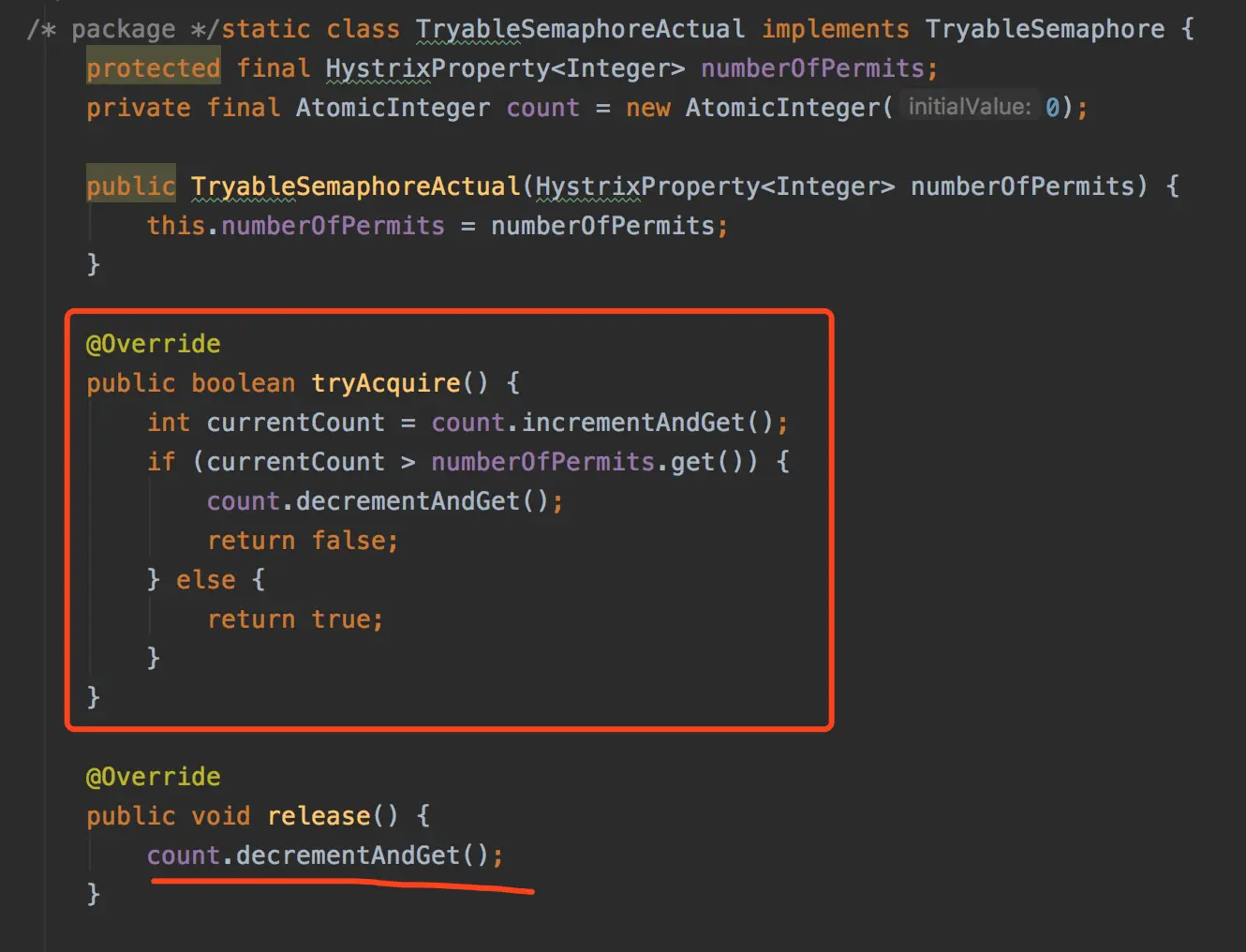
C/C++内存分区
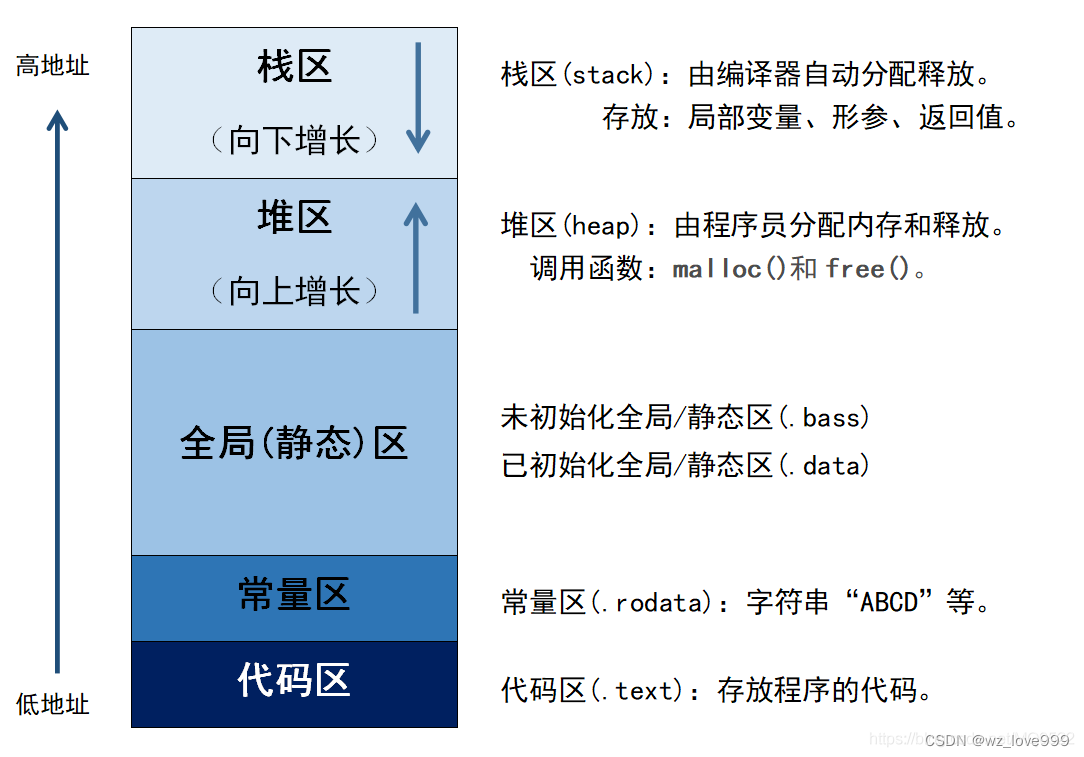
在C/C++这种高级语言的层面看,一个程序的内存分区可以被分为:(从低地址到高地址)代码区、常量区、静态区(已初始化(BSS段)、未初始化(Data段))、堆区、共享区、栈区、内核空间
本文将介绍代码区、常量区、静态区的作用,以及静态区中BSS段与Data段的作用。
代码区
代码区顾名思义用于存放程序的代码。进程被加载到内存后,CPU读取的时候是在代码区找到每一个代码语句,再去其他区域找数据。
常量区
也称为文本区(text),用于存放各种字符串常量和数字常量,以及全局的常量数据。
const int g_i = 100;
int main()
{
const char* str = "Hello";
const int c_i = 200;
}
静态区
静态区分为BSS段和Data段。
BSS段
存储未主动初始化的全局变量和静态变量,包括编译器手动设置的零值初始化变量。
Data段
存储主动初始化的全局变量和静态变量。
定义字符串常量会占用程序大小吗?
先来看几个程序,可以体现常量字符串在内存占用的情况。g++编译后,通过size工具可以查看程序各个分区的大小,text代表常量区,Data和BSS分别位于静态区。
int main()
{
return 0;
}
text data bss dec hex filename
1418 544 8 1970 7b2 ./a.out
在没有任何字符串常量的情况下的内存占用。
int main()
{
const char* str = "0123456789";
return 0;
}
text data bss dec hex filename
1445 544 8 1997 7cd ./a.out
定义了一个指向10个字符的字符串指针的内存占用。1445 - 1418 = 27, 一共多了27个字节。
其实27包括了 10个字符的字节 + 17 个不知道哪里来的(编译器优化、数据填充和对齐)
int main()
{
const char* str = "0123456789";
const char* str1 = "0123456789";
return 0;
}
text data bss dec hex filename
1445 544 8 1997 7cd ./a.out
仍然是1445,因为这个字符串已经存储在text段了,所以后续定义的指针都可以指向这个地址。
无需再分配空间,因为text段的内容只可读不可写。
除非使用类似内存映射的机制,将可执行程序文件的内存映射到当前进程的虚拟地址空间便可修改。
int main()
{
const char* str = "0123456789";
const char* str1 = "012345678";
return 0;
}
text data bss dec hex filename
1455 544 8 2007 7d7 ./a.out
奇怪的是,str1只有9个字符,但是text段却增长了10个字节?其实是因为末尾的\0。
并且可以验证得出:str1字符串不是str的子串,而是会分配一个新的字符串。
自此也解决问题:如果程序中定义了很多常量,如字符串,会不会增加程序的占用?
答案是会的。而单纯的宏定义不会,只有宏被使用了,替换后才会实例化字符串。
#define Hello "Hello"
int main()
{
const char* str = "0123456789";
const char* str1 = "012345678";
return 0;
}
text data bss dec hex filename
1455 544 8 2007 7d7 ./a.out
#define Hello "Hello"
int main()
{
const char* str = "0123456789";
const char* str1 = "012345678";
const char* strHello = Hello;
return 0;
}
text data bss dec hex filename
1477 544 8 2029 7ed ./a.out
这里相比上面增加了22,其实是包括了 6 + 编译器因为优化而填充的字节数。