ZMFF: Zero-shot multi-focus image fusion
(ZMFF: Zero-shot 多聚焦图像融合)
(本论文的先导片:ZERO-SHOT MULTI-FOCUS IMAGE FUSION)
这是我们之前的扩展工作。在ZMFF,我们做一些改动和改进相比原来的框架。首先,用源图像代替深度图像先验网络(INet)的输入噪声,使训练过程更加稳定。该方法能够为INet提供最有价值的指导信息,对清晰融合图像的先验信息进行建模,从而提高了融合图像的性能。其次,我们使用深度掩模先验网络(mask prior networks (MNet))来估计每个源图像的对应聚焦图,而不是仅估计一个掩模。有了这个设计,我们可以很容易地扩展我们的框架,以适应情况下有两个以上的源图像,并获得更好的性能。最后, 我们在合成和真实的MFF数据集上进行了大量的实验,消融研究和相应的详细分析,有效地证明了所有这些网络重构大大提高了IMNet的通用性和灵活性。
相关工作
Deep image prior(DIP)
最近,Ulyanov等人提出的深度图像先验(DIP),使用一个精心设计的“hour-glass”生成器来捕捉低级图像统计,表明图像先验不一定需要从大规模的数据集。相反,深层网络的结构也可以捕获输入图像的统计特性的深之前解决一些标准低层次的图像恢复问题(如图像超分辨率、图像去噪、图像完成,等等)没有任何训练数据。最近,研究基于这项工作取得了很大进展领域的图像恢复。Gandelsman等人提出了基于耦合DIP的图像分解任务的通用框架,Ren等人将DIP应用于图像去模糊,并获得了视觉上有利的结果。Uezato等人提出使用类似网络的编码器-解码器来利用引导图像的多尺度特征,并使用深度解码器来生成输出图像。更进一步,深度生成先验(DGP)提出了一种通过在大规模自然图像数据集上训练的生成对抗网络(GAN)来捕获丰富图像先验的有效方法。一般来说,在真实数据集极其缺乏的情况下,深度图像先验确实可以提供很大帮助。
方法
MFF problem formulation
MFF可以看作是源图像𝐼𝑖∈
R
𝑀
×
𝑁
×
𝐶
R^{𝑀 ×𝑁 ×𝐶}
RM×N×C根据聚焦图
𝐼
𝑖
𝐼^𝑖
Ii𝑚∈
R
𝑀
×
𝑁
R^{𝑀 ×𝑁 }
RM×N的加权平均,𝑀和𝑁分别表示源图像的高度和宽度,𝐶 表示源图像的通道数,𝑖∈{1,…,K},K表示源图片的数目。融合图像𝐼𝑓∈
R
𝑀
×
𝑁
×
𝐶
R^{𝑀 ×𝑁 ×𝐶}
RM×N×C可以计算为: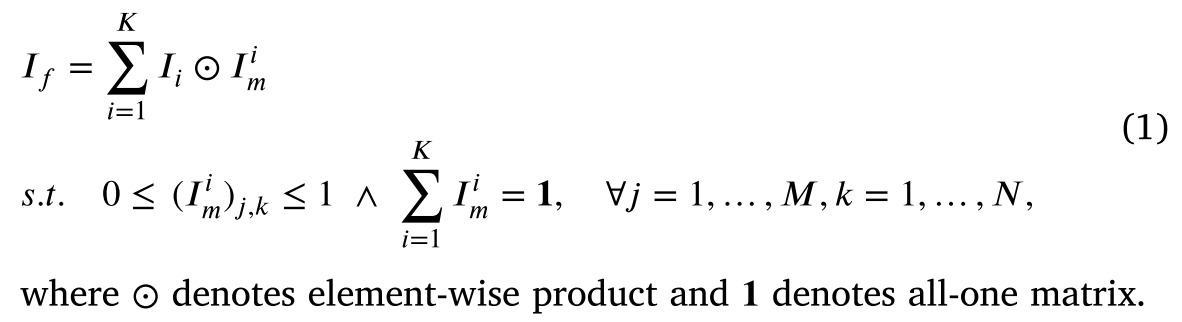 如上所述,许多MFF方法深深依赖于手工制作的先验。本文基于MFF任务的固有性质,即估计待恢复数据所需的先验信息隐藏在输入数据中,探讨了深度神经网络作为图像先验信息的能力,并将其应用于多聚焦图像对的融合。该方法使用两个生成网络,分别对干净融合图像的深度先验𝐼𝑓和源图像对应的焦点图
𝐼
𝑖
𝐼^𝑖
Ii𝑚进行建模𝐼𝑖。虽然估计融合图像或焦点地图会导致最后的结果,和似乎冗余估计焦点地图,同时融合图像。为了满足self-supervised学习,要求我们将Double-DIP的理念,把融合图像和集中映射到变量估计。
如上所述,许多MFF方法深深依赖于手工制作的先验。本文基于MFF任务的固有性质,即估计待恢复数据所需的先验信息隐藏在输入数据中,探讨了深度神经网络作为图像先验信息的能力,并将其应用于多聚焦图像对的融合。该方法使用两个生成网络,分别对干净融合图像的深度先验𝐼𝑓和源图像对应的焦点图
𝐼
𝑖
𝐼^𝑖
Ii𝑚进行建模𝐼𝑖。虽然估计融合图像或焦点地图会导致最后的结果,和似乎冗余估计焦点地图,同时融合图像。为了满足self-supervised学习,要求我们将Double-DIP的理念,把融合图像和集中映射到变量估计。
MFF using deep image prior
如图1所示,我们的整体框架由深度掩模先验网络MNet组成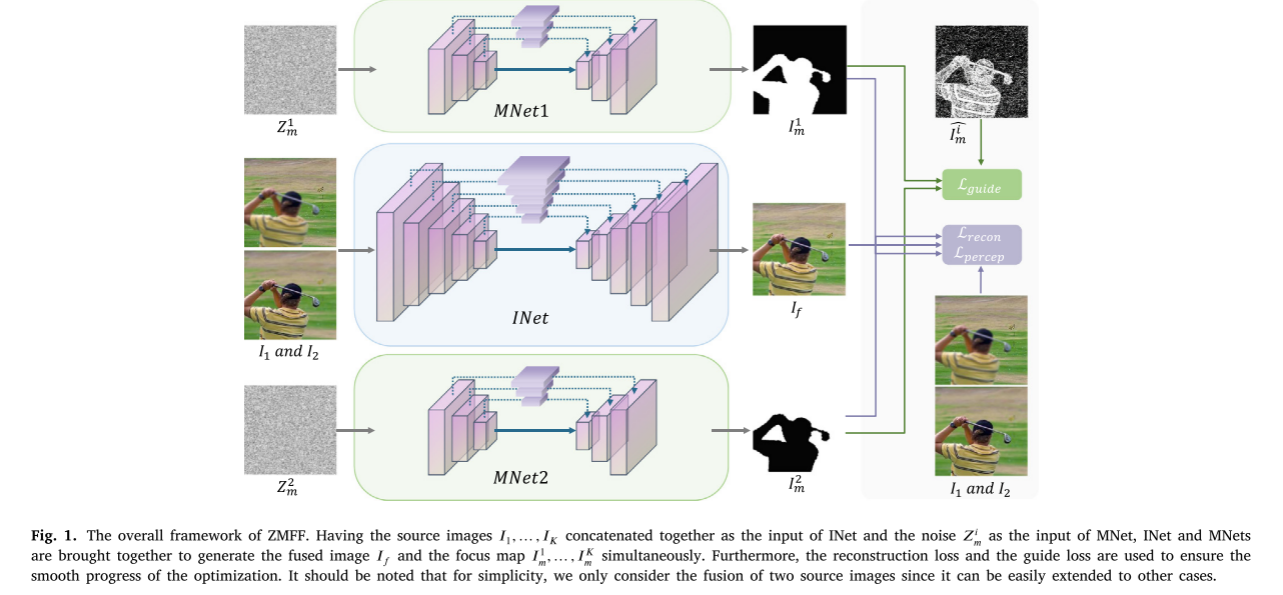 随机采样
𝑍
𝑖
𝑍^𝑖
Zi𝑚噪声均匀分布分别作为输入和输出对应的聚焦图
𝐼
𝑖
𝐼^𝑖
Ii𝑚,深度图像先验网络INet,以源图像的拼接𝐼𝑖作为输入,输出清晰的融合图像𝐼𝑓。我们之所以以源图像而不是噪声作为输入,是因为源图像包含了最重要的信息,可以为融合图像的生成给予最直接的指导𝐼𝑓。图3表明,指导信息从源图像,深度图像之前网络可以更好的融合。
随机采样
𝑍
𝑖
𝑍^𝑖
Zi𝑚噪声均匀分布分别作为输入和输出对应的聚焦图
𝐼
𝑖
𝐼^𝑖
Ii𝑚,深度图像先验网络INet,以源图像的拼接𝐼𝑖作为输入,输出清晰的融合图像𝐼𝑓。我们之所以以源图像而不是噪声作为输入,是因为源图像包含了最重要的信息,可以为融合图像的生成给予最直接的指导𝐼𝑓。图3表明,指导信息从源图像,深度图像之前网络可以更好的融合。
(请注意,虽然我们只使用最常用的两个源图像的设置作为图1中的示例,但我们的框架可以轻松扩展到多个源图像。)
然后生成融合图像和焦点地图对应于每个源图像是由精心设计优化的损失。只因为它是随机初始化深度网络被用来适应单一形象,深模型很容易过度拟合,一个设计良好的hourglass网络可以大大减轻这个问题。U-Net善于提取低级和高标准的信息,因此采用U-Net作为其支柱。下采样模块和上采样模块之间的非对称设计可以有效避免繁琐的解决方案,𝐼𝑓 看起来与源图像之一相同𝐼𝑖,并且
𝐼
𝑖
𝐼^𝑖
Ii𝑚看起来全白色或全黑,这会使算法难以优化。大量的BatchNorm层也可以使网络更好地适应高频组件。共享的网络结构INet和MNet如图2所示,INet的详细参数设置和MNet表1和2所示。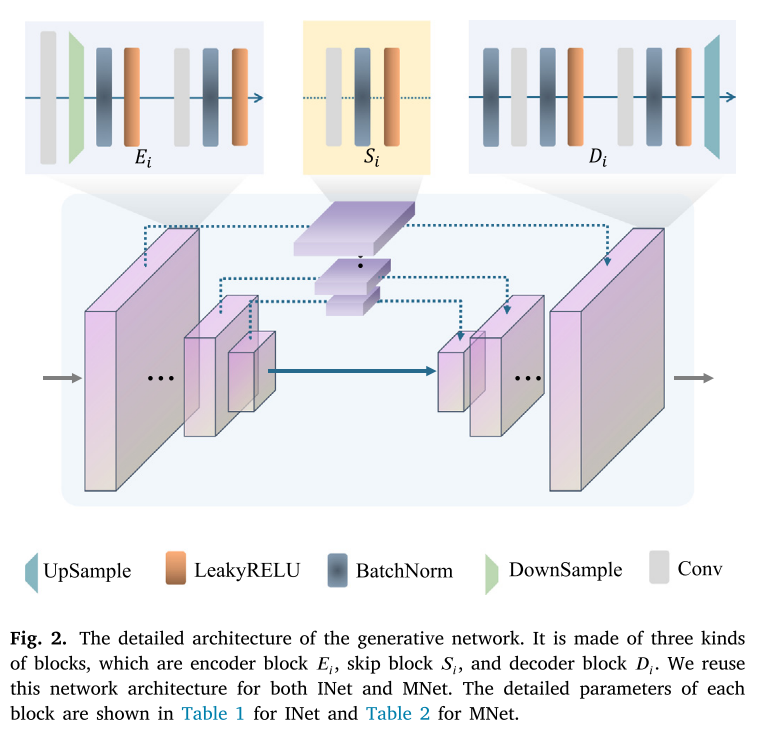


在这项工作中,我们提出了一个重建损失(如Eq.(1)所示) 以获得由神经网络参数化而不是以pixel-to-pixel的方式引导生成的显式正则化捕获的隐式先验: 重建损失提供了一个保证生成的图像的信息来自源图像对,从而避免出现伪影。同时,在高层语义信息的指导下,基于生成的方法能够消除基于选择的融合策略所带来的亮度不一致噪声,特别是在聚焦和散焦区域的边界区域,像素容易被误分类。因此,我们的方法结合了基于聚焦图估计的方法和基于融合图像生成的方法的优点。
重建损失提供了一个保证生成的图像的信息来自源图像对,从而避免出现伪影。同时,在高层语义信息的指导下,基于生成的方法能够消除基于选择的融合策略所带来的亮度不一致噪声,特别是在聚焦和散焦区域的边界区域,像素容易被误分类。因此,我们的方法结合了基于聚焦图估计的方法和基于融合图像生成的方法的优点。
然而,MFF是一个非常不适定的问题,由于缺乏对从INet学习到的信息是清晰还是模糊的约束,使得重构损失很大,并且网络可能会变得混乱而产生令人不快的结果。为此,我们引入一个导失来引导网络学习的明确信息:
对于每个源图像𝐼𝑖,我们有:

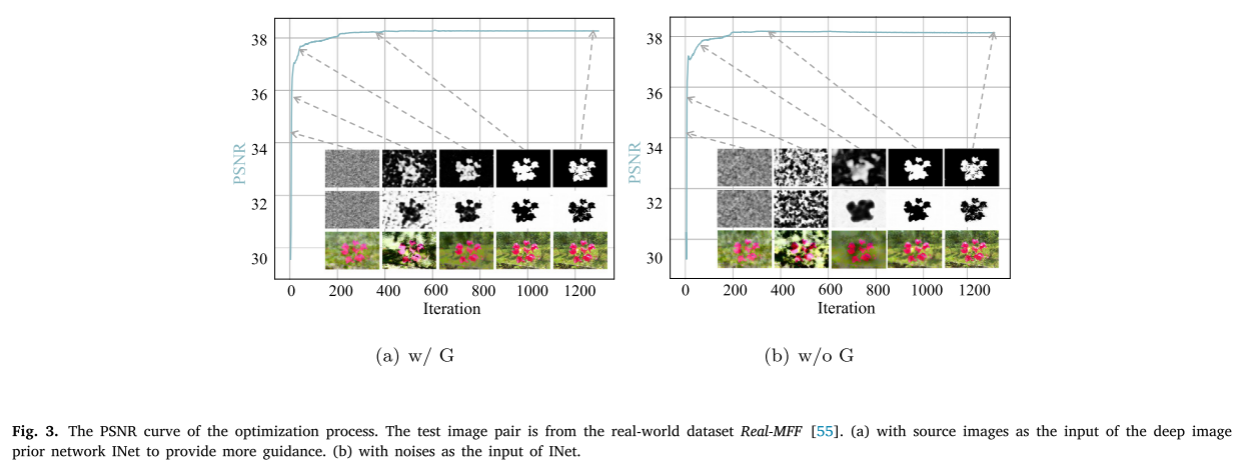
初始聚焦图用于提供高频图像信息,使得网络可以了解图像的清晰度。如图4所示,初始聚焦图噪声很大,我们的方法可以近似看作是初始聚焦图去噪问题。由于深度图像先验结构的抗噪特性,本文提出的框架可以从不准确的分类信息中恢复出更清晰、更精确的聚焦图。
。图3显示了优化过程中一个模拟样本的PSNR曲线和生成的融合图像以及相应的聚焦图,生成的融合图像和聚焦图在Eq.(2)中的重建损失的影响下进行了协同优化。当迭代次数变得太大时,聚焦图可能过拟合有噪声的初始聚焦图。
最后,我们得到我们的目标函数Eq.(5):

其中𝛼是重建损耗和引导损耗之间的权重权衡。
Implementation details
(进行复现时再细看)

![[C语言数据结构]万字长文带你学习八大排序](https://img-blog.csdnimg.cn/0511318ab1e94d548bed34a4335ece19.gif#pic_center)








![[Java] 如何理解和设置ThreadPoolExecutor三大核心属性?什么情况下工作线程数会突破核心线程数?任务拒绝策略都有哪些?](https://img-blog.csdnimg.cn/1eafac10fced4f5b9ed42940c1c63f1f.png)