如何只使用少量标记示例来训练模型?
到目前为止,人工智能所提供的大部分价值都来自于在日益庞大的数据集上训练的监督模型。其中许多数据集都是由人类标记的,这是一项枯燥、耗时、容易出错,有时还很昂贵的工作。自监督学习(SSL)是一种不同的学习范式,允许机器从未标记的数据中学习。在本文中,我们将讨论SSL的工作原理以及如何将其应用于计算机视觉。我们将比较简单的方法和最先进的方法,并看到SSL在医学诊断中的应用,这个领域可以从中获益很多,但同时也需要深入了解这种方法,以能够正确地实施它。
什么是自监督学习?
根据Meta首席AI科学家Yann LeCun的说法,自监督学习是“构建AI系统的背景知识和近似常识的最有前途的方法之一”。自监督学习的思想是在没有注释的数据上训练模型。
自监督学习是构建AI系统的背景知识和近似常识的最有前途的方法之一。
— Yann LeCun
考虑另外两种学习范式:监督学习和无监督学习。在监督学习中,我们向模型提供一些输入以及相应的标签,它的任务是找到它们之间的映射,以便推广到新数据。
另一方面,在无监督学习中,我们只有输入,没有标签,学习的目标是探索输入数据中的模式,以便对相似的示例进行聚类、减少数据维度或检测异常值,等等。
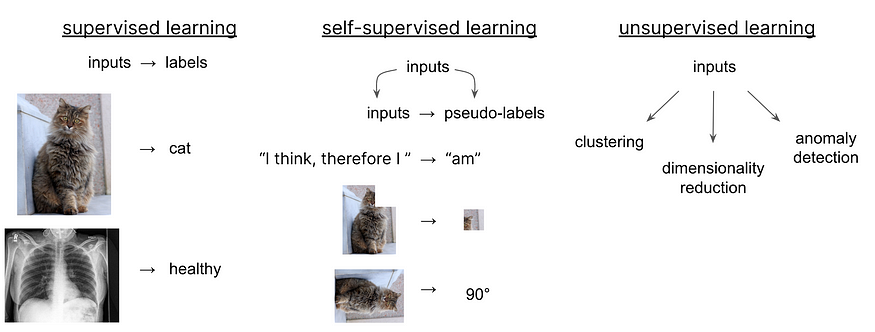
自监督学习在某种程度上位于这两者之间。它与无监督学习类似,因为它从未标记的数据中学习,但与此同时,它也是监督的,因为模型在训练过程中创建自己的伪标签以进行学习。
这个想法并不是全新的。自监督学习在过去已经被广泛使用,尤其是在NLP中,用于训练大型语言模型,如BERT或GPT。在这些模型中,可能会提供原始文本,任务是预测前面标记中的下一个标记。因此,对于每个训练示例,模型会设置它的伪标签为句子中的下一个单词。
然而,过去三年,自监督学习重新被发现,并在计算机视觉领域取得突破性的论文,来自Google、DeepMind和Meta等机构。然而,原理仍然是一样的:模型创建自己的伪标签,例如通过对图像的一部分进行蒙版,然后尝试预测它,或者通过旋转图像并尝试预测旋转角度。我们将在稍后讨论确切的技术。
现在,我们对自监督学习的基本概念有了一定了解,让我们看看它在医学应用中特别有用的原因。
医学数据中的稀缺注释
医疗领域产生了大量的图像。根据IBM的数据,高达90%的医疗数据以图像形式存在。这些数据是通过进行各种检查产生的,例如X光检查,根据世界卫生组织的数据,每年有36亿次。
这么庞大的数据量似乎为应用机器学习算法提供了很好的机会,因为机器学习算法需要数据。但存在一个问题。
传统的监督机器学习模型,为了从数据中学习,不仅需要训练示例,还需要注释或标签:当我们在训练期间向监督模型呈现X光图像时,我们需要告诉它要在其中识别哪些医疗病况。
不幸的是,在医学领域,注释是一种稀缺资源,而且获取它们是一项具有挑战性的任务。通常情况下,它们需要由昂贵的专家医生提供,而这些医生的时间昂贵,可以用来更好地照顾患者。这时自监督学习进场。
自监督学习解决了稀缺注释问题
在稀缺注释的情况下,例如识别X射线图像中的医疗病况,通常会出现如下图所示的情况:我们有大量的数据,但只有一小部分被注释了。
如果我们采用传统的监督方法,只能使用少量带标签的示例来训练模型。然而,通过自监督学习,我们可以从未标记的图像中学习。让我们看看如何做到这一点。
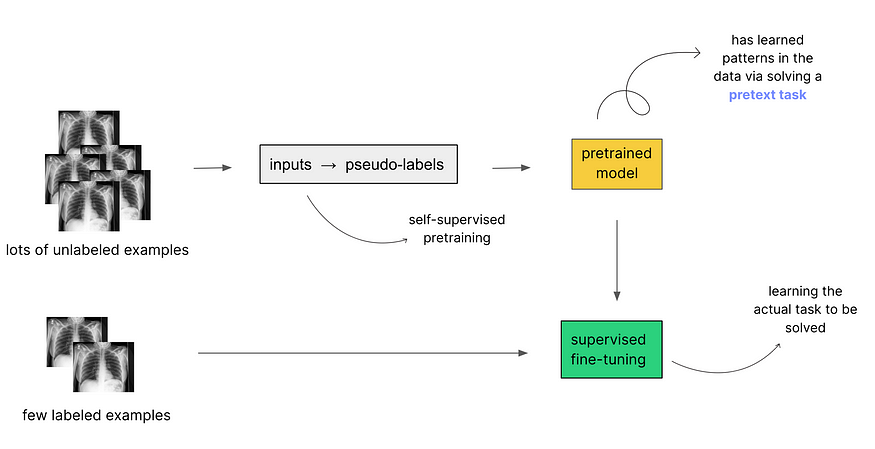
自监督学习工作流程
作为第一步,我们让自监督模型从未标记的数据中生成其伪标签,并在其上进行训练。这被称为自监督预训练,其中模型解决所谓的“前提任务”。这可以是预测蒙版图像片段或旋转角度,正如我们之前所说的那样;我们将在稍后讨论选择前提任务的细节。
上述步骤的结果是一个经过预训练的模型,该模型已经学习了未标记数据中存在的模式。这个模型对特定的医疗病况一无所知(因为这些信息只能在它没有看到的标签中获得),但它可能已经学到了某些X射线图像以一种一致的方式不同于其他图像。这就是LeCun所说的构建背景知识。
自监督学习工作流程包括两个步骤:在未标记数据上进行预训练以构建背景知识,然后在标记数据上进行有监督的微调以学习解决下游任务。
第二步是以常规的有监督方式在标记数据的一部分上对这个经过预训练的模型进行微调。这里的技巧是,现在模型对数据集中的模式有了一些背景知识,所以只需要提供少数带标签的示例给它,它就足够了解如何解决下游任务,我们的情况是在X射线图像中检测医疗病况。
前提任务
现在,让我们讨论模型在预训练阶段解决的前提任务。文献中已经提出了许多前提任务,可能性是无限的。唯一的要求是我们必须能够从输入数据本身创建伪标签。让我们看看一些最受欢迎的传统方法。
蒙版预测
蒙版预测简单地意味着对输入图像的某部分进行蒙版,然后让模型尝试从图像的其余部分来预测它。

变换预测
存在一整套方法可以归为变换预测的广义名称。在这些任务中,我们对图像应用一些变换,比如旋转、颜色移动等。然后,模型的任务是预测变换的参数:角度或比例、颜色移动的量等等。

拼图游戏
另一种方法是让模型解决拼图游戏。我们将输入图像切割成多个片段,然后随机重新排列它们,并要求模型找出正确的原始排列。

实例区分
其他一些方法将前提任务集中在实例区分上。这需要多个相同对象的多个视图,例如,来自不同角度或不同位置的同一只猫的照片。这种方法的变种会自动生成视图,例如来自3D点云或使用生成模型。前提任务是识别两幅图像是否代表完全相同的对象。
我们所讨论的每个前提任务的目标都是迫使模型学习数据中的结构和模式。然而,最近的研究发现,在实现这一目标方面,略有不同的方法效果最好。获胜的方法基于对比学习。
对比学习
对比学习的基础是将样本与样本进行对比,以了解哪些模式在样本之间是共同的,哪些使它们不同。
对比学习通过将样本相互对比来了解哪些模式在它们之间是共同的,哪些使它们不同。
监督对比学习
这种方法不仅限于自监督学习。事实上,它起源于监督的、少样本问题的解决方案。想象一下,你负责办公楼的安全,想要安装一扇只对经过验证的员工开启的自动门。你只有每个员工的几张照片来训练你的模型。
在这里,一个解决方案可以是训练一个模型,以识别两张图像是否描绘出相同的人。然后,系统可以将每个新来的人的脸与员工照片的数据库进行比较,寻找匹配项。这样的模型通常是以对比的方式进行训练的。在训练过程中,它们被呈现给三张图像进行对比:两张相同人的照片和一张不同人的照片。目标是学习第一二张相似,与第三张不同。
自监督对比学习
在这种方法中,我们还是向模型呈现三张图像。
第一张是来自训练数据集的随机图像,被称为锚图像。
第二张图像是相同的锚图像,但以某种方式进行了变换,例如通过旋转或颜色偏移,被称为正例。
第三张图像是来自训练数据的另一张随机图像,与第一张不同,被称为负例。
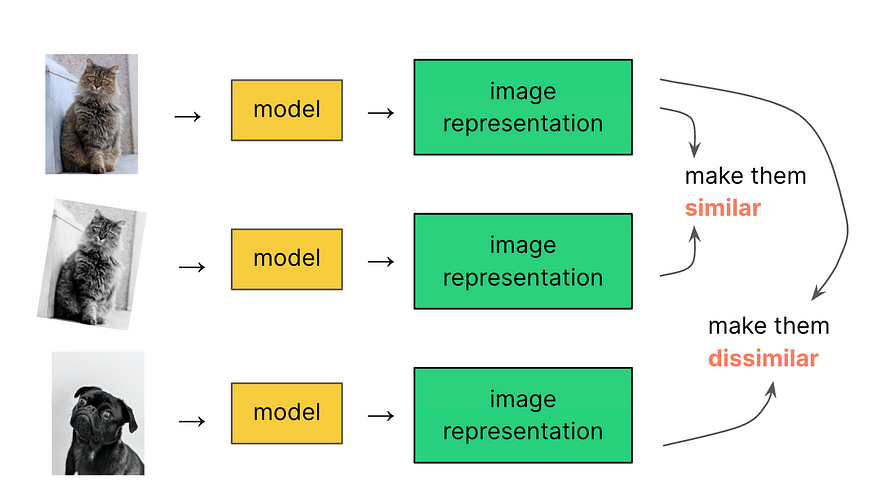
学习的目标是教模型第一二张图像是相似的,我们希望它们的潜在表示接近(毕竟,旋转的黑白猫仍然是一只猫),而最后一张图像与前两张不同,它的潜在表示或嵌入应该远离。现在,让我们更详细地讨论一下一些自监督对比架构。
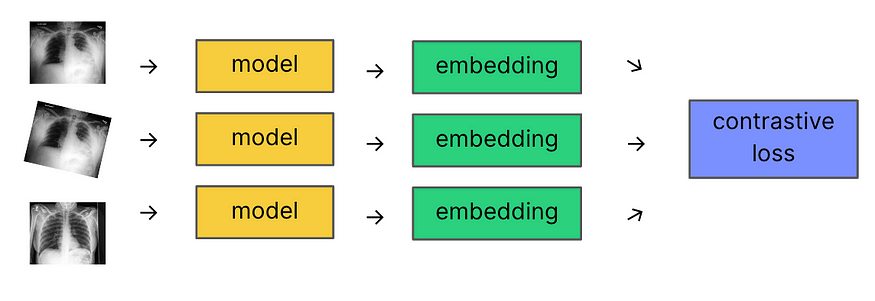
三重损失
可能想象的最简单的方法是基于三重损失的模型。我们通过主干模型(例如ResNet或视觉变换器)传递了锚点、正例和负例图像,以获得它们的嵌入,然后将它们传递给三重损失函数,其目标是教模型将锚点和正例图像放在潜在空间中的接近位置,将锚点和负例图像放在远处。
SimCLR
简单的对比学习框架(Simple Framework for Contrastive Learning),或称为SimCLR,是Google Research于2020年提出的一篇论文。该模型接受两个输入图像:锚图像和它的变换版本,或正例,然后将它们分别通过ResNet编码器、多层感知和可学习的非线性层。噪声对比估计(NCE)损失旨在最大化两个嵌入之间的相似性,同时最小化与同一小批次中其他图像的嵌入的相似性。
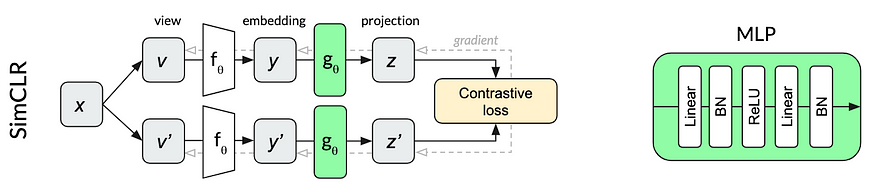
SimCLR在图像识别方面取得了很好的结果。不过,正如作者所展示的,它在批次大小很大(最好为4096)且训练时间很长的情况下表现最佳。这使它对于不愿意在云计算上花费大量美元的个人和公司来说,实际上是不可用的。
MoCo
Facebook AI Research团队的Momentum Contrast,或MoCo,缓解了SimCLR的一些缺点。他们成功地将批次大小减小到了256,这要归功于一个聪明的技巧。
MoCo有两个编码器网络,其参数分别由在线编码器和正例编码器进行优化。在线编码器通过常规梯度下降算法进行优化,而动量编码器则基于在线编码器权重的指数移动平均值进行更新。
最重要的是,MoCo保留了动量编码器嵌入的存储器库,并从中采样负例示例以计算NCE损失。这消除了大批量大小的需求。
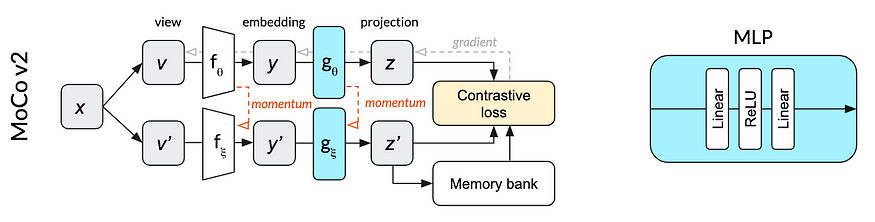
在其发布时,MoCo在许多不同的计算机视觉任务中超越了顶级的监督模型。
BYOL
自助式生成隐变量,或BYOL是DeepMind的一个项目。它构建在MoCo之上,也利用了两个网络,一个是根据另一个的权重进行移动平均值更新的网络。然而,与使用对比损失函数不同,BYOL学会将正例示例和标准化的锚定到嵌入空间中的相同位置。换句话说,在线网络被训练来预测其他网络的表示。这消除了对负例示例和存储库的需求。
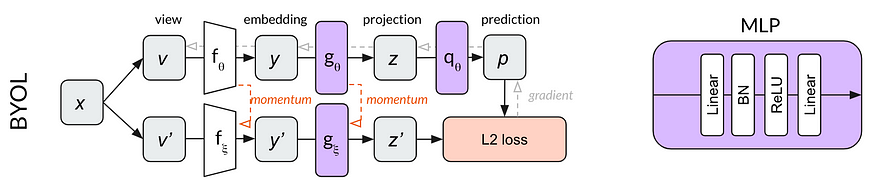
尽管BYOL并没有明确地将不同图像相互对比,但深入的研究发现,它实际上是以一种对比的方式学习的,尽管是间接的。
其他架构
还有许多其他现代的自监督架构,每个月都会有更多的架构出现,超越它们的前辈的结果。目前的研究在很大程度上集中在模型对许多不同的下游任务的可迁移性上。其中大部分来自Meta研究员。一些值得注意的例子包括Barlow Twins、SwAV、SimSiam以及最新的Tico和VICRegL。
选择变换
我们已经讨论了自监督学习的工作原理以及它如何解决医疗数据中稀缺标注的问题。我们还检查了各种前提任务和最先进的对比架构,这些架构将锚定图像与其变换版本进行对比。我们现在缺失的最后一块拼图是如何选择要应用于锚图像的变换,而这个选择事实证明对于成功将自监督学习应用于实际问题非常关键。
最新的文献,包括前面讨论的SimCLR和MoCo论文,声称已经确定了最佳的一组要使用的变换。它们建议使用随机裁剪、颜色抖动和模糊。作者已经证明这些在广泛的下游任务集上效果最好。不幸的是,事情并不那么简单。不同的变换会引入模型不同的不变性,这并不总是可取的。
用于胸部X射线的变换
现在让我们看看选择变换对于X射线图像有多重要。想象一下,我们忽略了将图像分类为不同的医疗状况的下游任务,只是遵循Google和Meta的研究人员的建议,使用随机裁剪作为我们的变换。
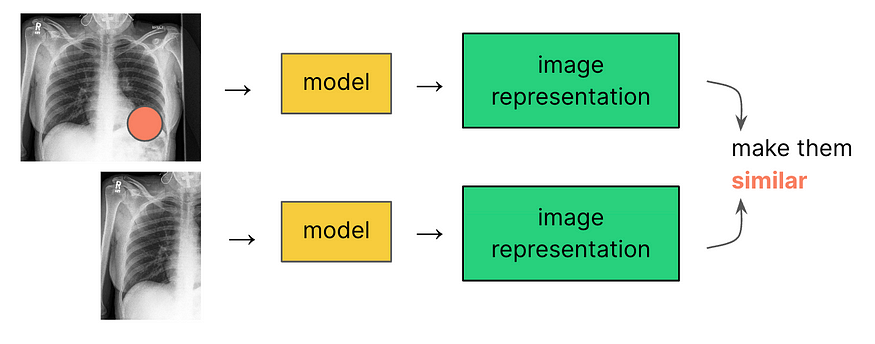
橙色圆圈代表图像中指示特定状况的部分,即肺部的某种损伤。使用随机裁剪,我们可能会得到像上图中的正例一样:损伤区域被裁剪掉了。对比损失将教导模型,有损伤的肺部和没有损伤的肺部是相似的。这样的预训练可能会使模型难以微调以识别这种类型的肺部损伤。
其他两种被认为是最佳的变换也不适用于X射线数据。对于灰度图像,其中灰度值或局部模糊的存在可能指示特定的医疗状况,因此应用颜色抖动或模糊可能会适得其反。再次强调,变换必须始终根据特定数据集和下游任务而选择。
理论考虑到此为止,现在让我们看看在X射线分类中实际应用自监督对比学习。
利用自监督学习进行X射线分类
我们使用了CheXpert数据集,该数据集包含约220,000张胸部X射线图像,标有十个互斥的类别,表示不同的医学状况以及患者体内支持装置的存在。我们只使用了超过200,000张正面图像的子集。我们选择了大约200,000张图像的随机子集进行自监督预训练。经过一系列实验,我们决定将轻微的随机旋转、水平翻转和随机透视作为要应用于锚图像的变换。CheXpert的所有图像都带有标签,但我们在预训练数据中忽略了这些标签。
在预训练之后,我们以监督方式在不同大小的带标签数据集上对模型进行了微调:从250张到10,000张图像。研究的目标是研究性能如何随着带标签集的大小而变化。
最后,我们在一个包含300张手动标记图像的小测试集上测试了模型(精细调校数据的标签是由数据集的作者通过自动解析患者记录获得的,这可能会引入一些噪音到这些标签中;相比之下,测试标签是由医生手动标记的,质量很高)。
性能评估
我们比较了三种模型架构:
传统的迁移学习方法,使用ResNet18。它仅在带标签的微调集上以监督方式进行训练。这反映了我们不使用自监督学习的情况,因此被迫忽略未标记的数据。
使用ResNet18作为骨干结构的简单三元组损失模型,但使用三元组损失以对比的方式进行预训练,并使用我们选择的变换。
Meta的MoCo,同样使用ResNet18骨干结构和我们的变换集。
每个模型都经过十次训练和测试,每次使用不同大小的带标签微调集。我们通过ROC曲线下面积(AUC)来进行比较。
结果
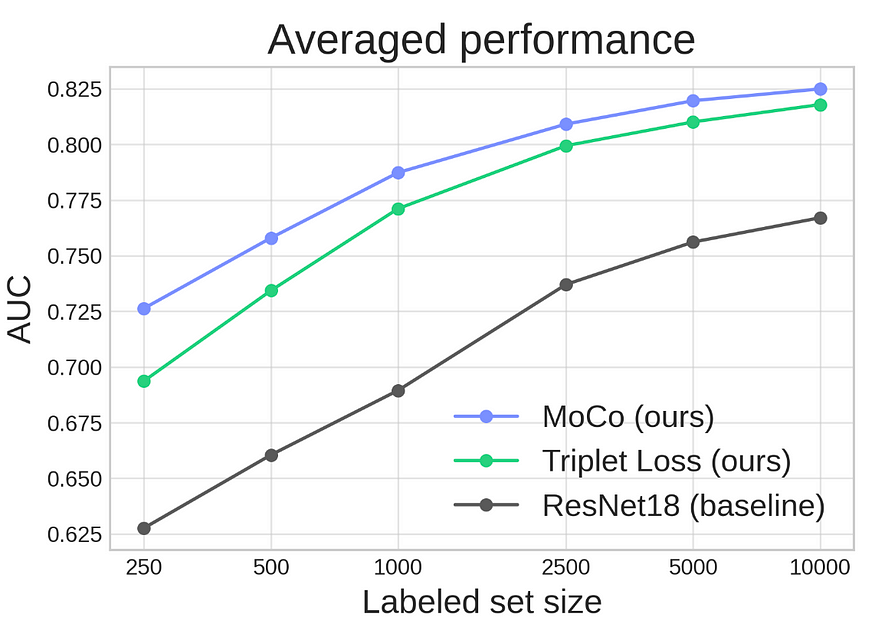
不言而喻,自监督模型明显优于监督基线。然而,从这些结果中还可以得出其他有趣的结论:
在带标签集最小的情况下,自监督预训练提供了最大的增益:仅使用250个带标签的示例,它比监督基线高出10个百分点。
即使标签数据集较大,自监督预训练仍然可以提高性能:对于10,000个标签示例,增益仍然约为6个百分点。
特别是在标签数据集较小时,MoCo相对于基线提供的增益更大。
让我们还要更仔细地看看我们数据中的类别频率。下图的左侧面板显示了MoCo相对于基线的优势(按AUC差异度量)分别对每个类别。右侧面板显示了数据集中的类别频率。
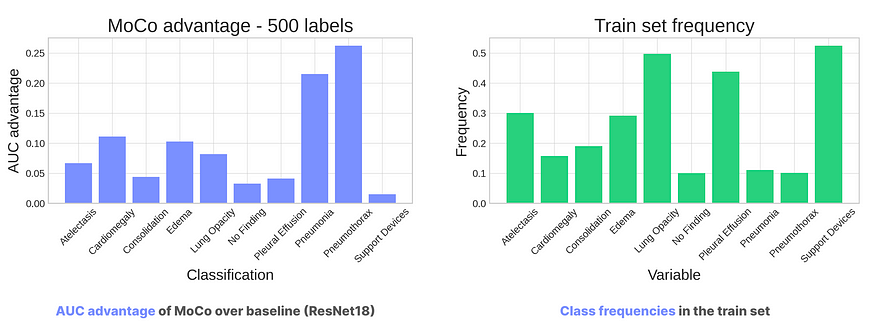
尽管自监督对每个类别都有所帮助,但似乎对相对罕见的类别有最大的帮助。这与前面的情节结果一致,显示了在标签集较小的情况下改进最为显著。
结论
在过去的三年中,计算机视觉的自监督学习取得了巨大的进展。由大型AI研究实验室发布的对比架构,特别是由Meta领导的,不断提高了标准。这有两个重要的后果。
首先,高效利用未标记数据集的能力将成为许多行业的游戏变革者,其中注释数据稀缺。
其次,训练这些所谓的基础模型,它们从未标记数据中学习以获取可以传递到多个不同下游任务的背景知识,这是AI泛化的重要步骤。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除