一、前言
近年来,大语言模型的快速发展为构建更智能和更人性化的AI系统提供了很多可能性。像GPT-3.5、GPT-4、Bard、Claude 2和LLaMa 2等大语言模型 (LLM) 在个人助理或聊天机器人应用领域展示了强大的潜力,可以生成流畅而令人惊叹的响应来回答用户的问题。
然而,随着越来越多的资金涌入生成式人工智能领域,许多初创公司纷纷拥抱这些创新技术。尽管这些模型生成的响应看起来很真实,但它们仍然存在产生幻觉或编造答案的倾向。这可能导致用户获得错误或误导性信息,最终损害用户体验和信任。
为了避免这样的问题,我们需要更好地理解大语言模型的工作原理,并通过数据和算法加强监督来改进它们。我们需要开发更强大的自监督学习技术、更大规模和更高质量的数据集,以及更先进的模型架构,以减少神经网络产生不准确信息的可能性。
尽管LLM技术充满希望,但要在实际应用中发挥其全部潜力,我们必须解决一些基本问题。其中一个最关键的问题是如何避免大型语言模型产生幻觉。
二、什么是LLM幻觉
LLM是一种人工智能 (AI) 模型,通过在大规模文本和代码数据集上进行训练来生成文本、翻译语言、编写创意内容,并以信息丰富的方式回答问题。然而,LLM也容易产生所谓的“幻觉”,即生成实际上不正确或无意义的文本。
幻觉的出现是因为LLM所接受的数据往往不完整或相互矛盾。因此,它们可能会学习将某些单词或短语与某些概念联系起来,即使这些联系不准确或过于准确(即编造真实但不应该分享的信息)。这可能导致LLM生成事实上不正确、过度放纵或无意义的文本。
对于幻觉的基本定义在人工智能研究中心 (CAiRE)发布的一篇研究论文[1]中将LLM的幻觉定义为“当生成的内容无意义或不忠实于所提供的源内容时”。有了这个简单但包容性的定义,下面我们再来看几个例子。
Q1:鲁迅先生在日本留学学医的老师是谁?

显然从GPT-4给出的答案,不清楚这个事实的人可能以为是正确的,实际上它所训练的数据集中没有包含这部分的信息,导致它最终提供了一个不正确的答案,我们再来看另外一个例子。
Q2:鲁迅和周树人之间是什么关系?

这是GPT-3.5给出的答案,从答案可以看出模型基本上是胡乱编造的一段内容来回答的,我们再试着问问GPT-4看看回答是否正确

发现在GPT-4中非常准确的识别到了这个问题的意思且回答完全正确,说明GPT-4在知识内容的摄取范围有所增加、模型的推理理解能力也有增强。
虽然以上这些例子是使用 OpenAI GPT 模型产生幻觉的例子,但值得注意的是,这种现象也适用于许多其他同类型的LLM模型,比如 Claude、Bard 或 LLama 2。
那么为什么会出现幻觉呢?为了解释这一点,让我们先来了解一下大语言模型内部的工作原理,就会LLM明白为什么会出现幻觉了。
三、LLM的基本原理
为了理解产生幻觉的原因,我们首先需要了解LLM是如何运作的,前面有单独介绍过大模型的基本原理,希望深入了解的可以查阅《深度解读 ChatGPT 基本原理》这篇文章,这里我们将重点关注自回归LLM(如 GPT-3 或 GPT-4)。
在基本层面上来看,LLM将任何文本片段都表示为标记序列。这些标记可以是单词、子单词、甚至字符。无论特定 LLM 使用哪种标记化策略,自回归 LLM 都会经过训练以准确预测标记序列中的下一个标记。
用数学术语来说——给定一系列标记 T (1) 、 T (2) 、 …、 T (N) 、 ,LLM 学习下一个标记 T(N+1) 的概率分布以之前的标记为条件:
![]()
例如,考虑以下标记序列(在本例中,我们假设标记是单词):

显然,在token“去”之后,下一个token有很多选项,例如“看电影”或“吃饭”都是有效选项,以及还有许多其他选项。事实上,LLM 学习所有可能的下一个标记集合的概率分布:

该概率分布为每个 token 分配一个概率,LLM 在选择下一个 token 时会从此分布中进行采样。
例如,LLM 最有可能选择“吃饭”这个词(概率为 0.4),其次是“看电影”(概率为 0.3),然后是“睡觉”等等。还有一些不太可能跟随前面标记的词,会被分配一个非常低的概率(0.00001)。
选择下一个标记(假设选择了标记“吃饭”)后,它将附加到现有的单词序列中,并重复该过程,直到创建完整的句子或响应。

所以底线是:大语言模型本质上是大型神经网络,以所有先前的标记为条件,经过训练然后预测下一个标记的可能性。
当语言模型的预测与我们的期望、经验或已知知识相矛盾时,或者当我们找到该回答的反面事实证据(预测标记序列)时,我们就会发现幻觉。
四、为什么LLM会产生幻觉
导致AI模型产生幻觉有若干个因素,其中包括训练数据有偏见或训练数据不足、训练数据过度拟合、上下文理解有限、领域知识缺乏、对抗攻击和模型架构。
-
训练数据有偏见或训练数据不足:AI模型的好坏取决于训练所使用的数据。如果训练数据有偏见、不完整或不足,AI模型可能会基于其对所访问数据的有限理解而产生幻觉。在使用开放的互联网数据训练大型语言模型的情况下,这一点尤其令人担忧,因为互联网中有偏见和错误的信息泛滥。当LLM没有足够的信息时,他们通常不会说“我不知道”。因此,当LLM没有答案时,它会生成最可能的答案。但请注意,“最有可能”并不一定意味着“真实”,当这种错位发生时,最终结果就是幻觉。
-
过度拟合:当AI模型与训练数据过度拟合时,它可能会开始生成对训练数据过于具体的输出,不能很好地推广到新数据。这可能导致模型生成幻觉或不相关的输出。
-
数据噪声:LLM接受大量数据的培训,其中一些数据可能包含不准确之处。这些不准确性可能会在模型的输出中传播。
-
无法验证事实:LLM没有能力交叉核对信息或根据可靠来源验证事实,导致可能生成不正确或捏造的信息。
-
上下文理解缺乏:缺乏上下文理解的AI模型可能会产生脱离上下文或不相关的输出。这可能导致模型生成幻觉或荒谬的输出。
-
领域知识有限:为特定领域或任务设计的AI模型在接受其领域或任务之外的输入时可能会产生幻觉。这是因为它们可能缺乏生成相关输出所需的知识或背景。当模型对不同语言的理解有限时,就会出现这种情况。尽管一个模型可以在多种语言的大量词汇上进行训练,但它可能缺乏文化背景、历史和细微差别,无法正确地将概念串在一起。
-
对抗攻击:不同于组建一支团队“攻破”模型以改进模型的红蓝对抗,AI模型也易受对抗攻击。当恶意攻击者故意操纵模型的输入时,可能会导致它生成不正确或恶意的输出。
-
模型架构:AI模型架构也会影响幻觉产生的容易程度。由于复杂性增加,具有更多分层或更多参数的模型可能更容易产生幻觉。
回到我们上面举的关于鲁迅先生在日本学医的事情,该模型不了解鲁迅先生的历史信息,以其所掌握的有限信息相当自信的做出了不准确的响应。
有时候我们会尝试用Prompt Engineering来影响LLM,让其相信自己正在以某种观点模仿特定的“角色”,这会影响其回答问题的方式。
例如,我们通常在要求 GPT 解释概念的时候,如果要介绍的对象只有4岁,本质上你其实是在让 GPT 作为父母或老师的角色来解释对于幼儿来说这是一个复杂的概念:

五、幻觉对LLM的影响
5.1、有毒或歧视性内容
由于LLM培训数据由于固有的偏见和缺乏多样性,往往充满社会文化刻板印象。因此,LLM可以产生并强化这些针对社会弱势群体的有害思想。他们可以根据种族、性别、宗教、民族等生成这种歧视性和仇恨性的内容。
5.2、隐私问题
LLM接受大量培训语料库的培训,其中通常包含个人的个人信息。此类模型曾经侵犯过人们的隐私。他们可以泄露特定信息,例如社会安全号码、家庭住址、手机号码和医疗详细信息。
5.3、错误信息和虚假信息
语言模型可以生成看似准确但实际上是错误的、没有经验证据支持的类似人类的内容。这可能是偶然的,导致错误信息,也可能背后有恶意故意传播虚假信息。如果不加以控制,可能会造成不利的社会文化经济政治趋势。
六、如何消除LLM的幻觉
所有LLM都会产生幻觉,因为他们接受的训练是基于各种数据集的大语料库,而这些数据集可能存在不完整性、矛盾、不一致和其他偏见。消除LLM的幻觉是一个复杂的问题,但可以采取一些方法来最大限度地减少其产生的影响。以下是一些可能的解决方案:
6.1、人类反馈强化学习(RHLF)
通过将人类反馈纳入训练过程中,可以帮助LLM识别和纠正其潜在的幻觉。这种方法可以通过迭代的方式不断改进模型的性能。OpenAI 使用基于 InstructGPT 方法的人类反馈强化学习 (RHLF),而斯坦福 Alpaca 和 Databricks Dolly 2.0 使用 Self-Instruct 监督微调方法。
6.2、Temperature 参数调整
使用 LLM 构建时(无论是 HuggingFace 模型还是 OpenAI GPT-3 api),有多个可用参数,包括Temperature。模型的Temperature是指用于调整模型预测的概率分布的标量值。就LLM而言,温度参数决定了坚持模型从训练数据中学到的知识与生成更多样化或创造性的响应之间的平衡。一般来说,创造性的反应更有可能包含幻觉。
6.3、使用向量数据库
向量数据库是一种新兴的技术,可以用于存储和检索大规模的语义向量表示。通过将LLM的输出与向量数据库中的已验证数据进行比较,可以减少幻觉的发生,并提供更可靠和准确的回答。
6.4、自我检查(自我批判、自我反思)
一般来说,通过智能提示和思想链(COT)等技术,LLM已经表明他们可以在更复杂的任务上表现更好。
6.4.1、SmartGPT(SmartLLMChain):
SmartLLMChain 是一个自我批评链,旨在帮助解决复杂的问题。它不是使用语言模型 (LLM) 执行单遍,而是遵循三个步骤的过程:
-
创意:用户提示多次(n次)通过LLM以生成n个输出提案,称为“创意”。 n 的值可以作为参数进行调整。
-
批评:LLM产生的所有想法都会经过评估,以找出潜在的缺陷。根据这种批评选择最好的想法。
-
解决:LLM尝试增强上一步中选定的想法,并将其作为最终输出呈现。有关更多详细信息,请参阅 SmartGPT 作者的视频。 LangChain 有一个 SmartGPT 的实现,可以让您在几秒钟内开始使用。
6.4.2、因果程序辅助语言 (CPAL) 链
CPAL 构建在程序辅助语言 (PAL) 语言链之上,将提示的因果结构表示为因果图或 DAG(在 langchain 上查看)。在这种方法中,与代理类似,LLM可以访问代码执行来获取有关需要数学运算的更复杂问题的反馈。

6.5、检索增强生成(RAG)
该技术允许我们从外部知识库检索相关信息并将该信息提供给LLM。通过在预测时提供对知识库中相关数据的访问(添加到提示),我们可以将纯粹的生成问题转换为基于所提供数据的更简单的搜索或总结问题。
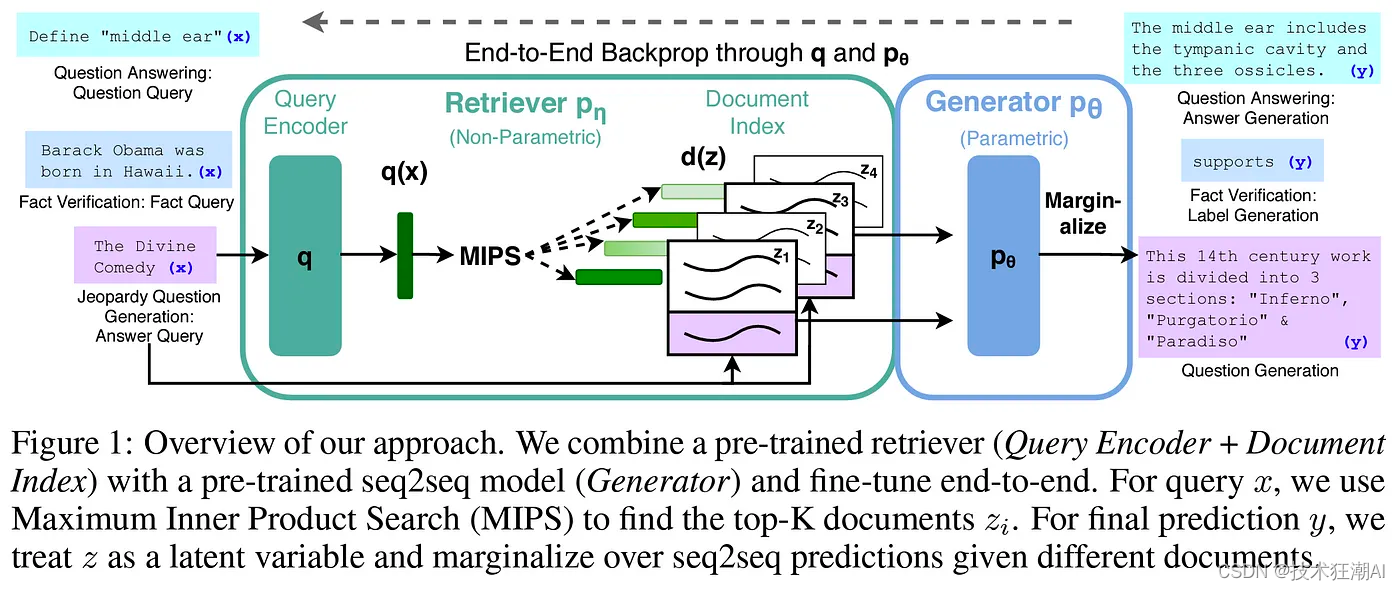
然而,即使拥有 RAG,LLM也容易产生幻觉,如下图所示,来自俄亥俄大学研究人员最近发表的一项研究:
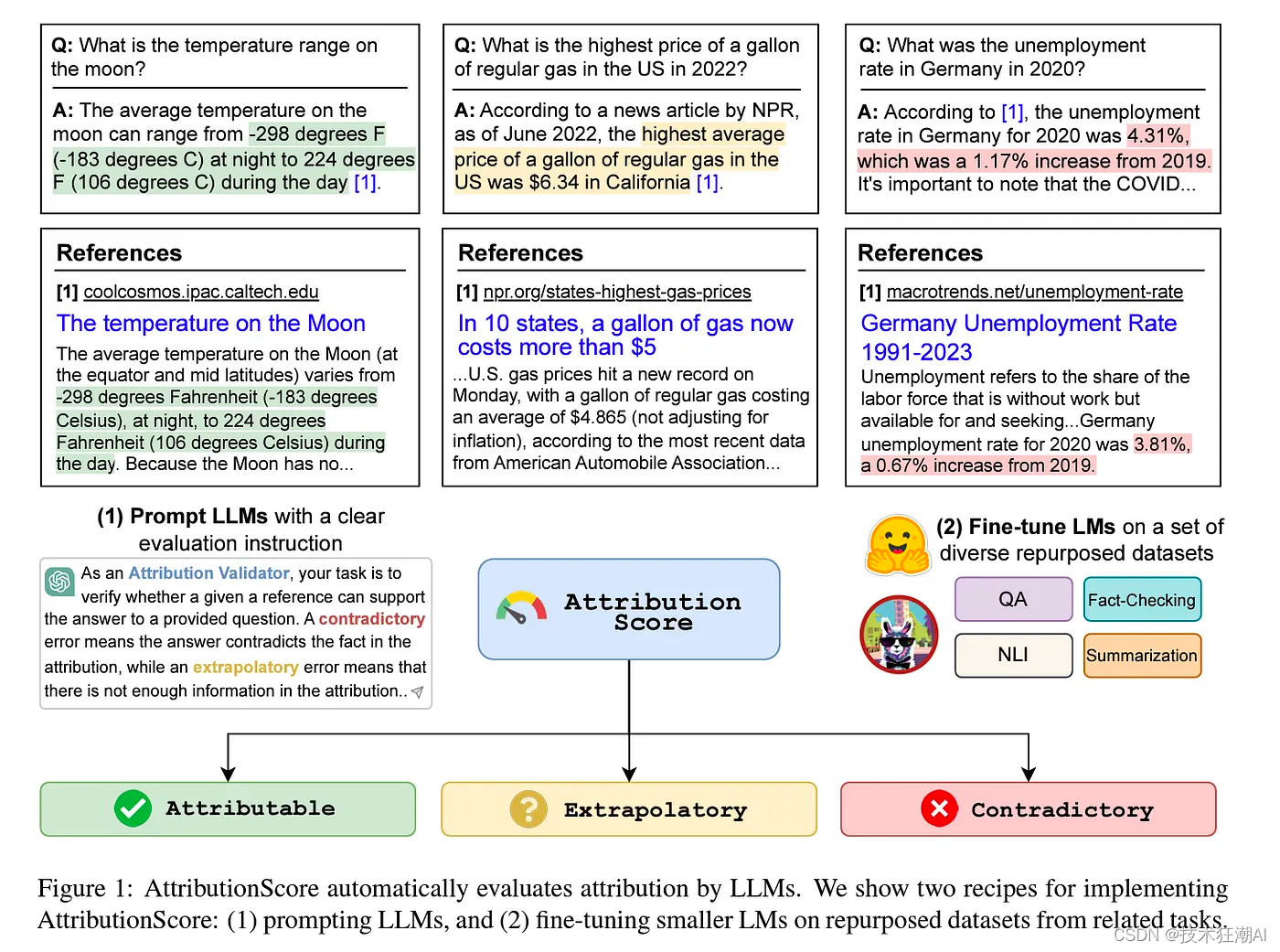
正如您在上面所看到的,当特别涉及到处理符号的更多数学推理时,语言模型仍然可能会产生幻觉。
6.6、Prompt Engineering
Prompt engineering是一种改善LLM响应的常见方法,可以通过提供更明确的背景信息来减少幻觉。以下是一些常见的方法:
6.6.1、更明确的背景
提供清晰具体的提示可以帮助LLM生成最相关、最准确的输出。使用具体的问题或指定特定的领域或主题。例如,不要问“什么是捷豹?”当我们可以指汽车或动物时,我们应该问:“捷豹有哪些不同型号?”
6.6.2、较长的上下文
较长的上下文并不能直接减少幻觉,但可以提供更多的信息和背景,从而增加LLM生成准确回答的可能性。
6.6.3、上下文注入
在与LLM交互时,将先前的对话历史或相关上下文信息提供给模型。这样,LLM可以更好地理解问题的背景,并生成更准确和一致的回答。
6.6.4、使用多次提示
通过给LLM提供多个不同的提示,可以获得更全面和多样化的回答。这有助于减少模型受到单一偏见的影响。
6.5、微调较小的模型来检测幻觉
微调一个较小的LLM模型,可以用于评估LLM响应是否得到了来源的支持。这种方法可以通过语义上的归因评估来检查LLM的回答是否合理。微调LLM可能会更耗时,但似乎效果相当不错(但是并不能完全消除幻觉)。例如,您可以利用 beir_fever 或 AttrScore 来微调一个较小的模型,该模型可以对 LLM 响应的归因进行评分。另请查看此存储库以获取一些实现细节。
需要注意的是,消除LLM的幻觉是一个持续的过程,需要不断地改进和优化。同时,用户也应该保持警惕,对LLM生成的内容进行审查和验证,以确保其准确性和可靠性。
七、总结
总之,在现实应用中使用大型语言模型 (LLM) 时,幻觉仍然是一个重大挑战。LLM生成虚假信息可能会带来灾难性的后果,尤其是在面向客户的系统中。然而,有一些有效的方法可以最大限度地减少幻觉并提高LLM回答的可靠性。
具体来说,调整LLM生成参数、采用不同的解码技术以及实施自检机制可以更好地控制输出并提高响应质量。像 SmartLLMChain 和 CPAL 链这样的技术提供了有前途的方法,通过完善生成的想法并结合因果结构来减少幻觉。此外,检索增强生成(RAG)可以通过检索相关文档来增强LLM的反应,但需要谨慎,因为幻觉仍然可能发生,特别是在数学推理中。
为了进一步提高LLM回复的可靠性,建议及时设计和微调较小的LLM进行归因评估。总的来说,通过实施这些方法并考虑LLM的局限性,开发人员可以减轻幻觉的风险并确保更准确和可靠的信息生成。该领域的持续研究和开发对于提高LLM的表现并最大限度地发挥其在实际应用中的潜力至关重要。
八、References
Karpukhin, Vladimir, et al. "Dense passage retrieval for open-domain question answering." arXiv preprint arXiv:2004.04906 (2020). Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474. Gao, Luyu, et al. HYDE "Precise Zero-Shot Dense Retrieval without Relevance Labels." arXiv preprint arXiv:2212.10496 (2022). Ma, Kaixin, et al. "Open-domain Question Answering via Chain of Reasoning over Heterogeneous Knowledge." arXiv preprint arXiv:2210.12338 (2022).
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
Hu, Ziniu, et al. "REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory." arXiv preprint arXiv:2212.05221 (2022).