目录
一:读取文件
二:查看数据
三:获取数据
四:按标签选择
五:按照位置选择
六:布尔索引
七:缺失值
一:读取文件
read_csv 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
二:查看数据
查看头部数据 head
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.head())
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1
3 39 0 NaN 1
4 5 2 57.0 2查看尾部数据 tail
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.tail())
a b c label
6 6 4 21.0 2
7 7 46 4.0 3
8 9 39 8.0 3
9 9 38 17.0 3
10 2 3 55.0 2查看索引 index
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.index)
RangeIndex(start=0, stop=11, step=1)查看列名 columns
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.columns)
Index(['a', 'b', 'c', 'label'], dtype='object')describe() 可以快速查看数据的统计摘要
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.describe())
a b c label
count 11.000000 11.000000 10.000000 11.000000
mean 18.181818 14.727273 25.200000 1.909091
std 18.845786 17.613012 24.003703 0.831209
min 2.000000 0.000000 4.000000 1.000000
25% 5.500000 2.000000 8.250000 1.000000
50% 9.000000 4.000000 14.000000 2.000000
75% 30.000000 27.500000 46.500000 2.500000
max 54.000000 46.000000 65.000000 3.000000数据转置 .T
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.T)
0 1 2 3 4 5 6 7 8 9 10
a 45.0 21.0 54.0 39.0 5.0 3.0 6.0 7.0 9.0 9.0 2.0
b 2.0 17.0 9.0 0.0 2.0 2.0 4.0 46.0 39.0 38.0 3.0
c 9.0 5.0 11.0 NaN 57.0 65.0 21.0 4.0 8.0 17.0 55.0
label 1.0 1.0 1.0 1.0 2.0 2.0 2.0 3.0 3.0 3.0 2.0三:获取数据
选择单列,产生 Series,与 df.a 等效: 如下 df['a']
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df['a'])
0 45
1 21
2 54
3 39
4 5
5 3
6 6
7 7
8 9
9 9
10 2
Name: a, dtype: int64用[ ]切片行 如下 df[0:3]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df[0:3])
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1四:按标签选择
用标签选择多列数据 如下 df.loc[:,['a','b']]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.loc[:, ['a', 'b']])
a b
0 45 2
1 21 17
2 54 9
3 39 0
4 5 2
5 3 2
6 6 4
7 7 46
8 9 39
9 9 38
10 2 3
用标签切片,包含行与列结束点 如下 df.loc['38':'9', ['a', 'b']]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.loc['38':'9', ['a', 'b']])
a b
4 5 2
5 3 2
6 6 4
7 7 46
8 9 39
9 9 38
10 2 3五:按照位置选择
用整数位置选择 如下 df.iloc[3]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.iloc[3])
a 39.0
b 0.0
c NaN
label 1.0
Name: 3, dtype: float64
类似numpy/python,用整数切片 如下 df.iloc[3:5, 0:2]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.iloc[3:5, 0:2])
a b
3 39 0
4 5 2类似numpy/python,用整数列表按位置切片 如下 df.iloc[[1, 2, 4], [0, 2]]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.iloc[[1, 2, 4], [0, 2]])
a c
1 21 5.0
2 54 11.0
4 5 57.0显式整行切片 如下 df.iloc[1:3, :]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.iloc[1:3, :])
a b c label
1 21 17 5.0 1
2 54 9 11.0 1显示整列切片 如下 df.iloc[:, 1:3]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.iloc[:, 1:3])
b c
0 2 9.0
1 17 5.0
2 9 11.0
3 0 NaN
4 2 57.0
5 2 65.0
6 4 21.0
7 46 4.0
8 39 8.0
9 38 17.0
10 3 55.0显示提取值 如下 df.iloc[1, 1]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.iloc[1, 1])
17快速访问标量,与上述方法等效 如下 df.iat[1, 1]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.iat[1, 1])
17值选择 如下 at
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# 值选择
print(df.at[1, 'b'])
17六:布尔索引
用单列的值选择数据 如下 df[df.a > 0]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df[df.a > 0])
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1
3 39 0 NaN 1
4 5 2 57.0 2
5 3 2 65.0 2
6 6 4 21.0 2
7 7 46 4.0 3
8 9 39 8.0 3
9 9 38 17.0 3
10 2 3 55.0 2选择DataFrame里满足条件的值 如下 df[df > 0]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df[df > 0])
a b c label
0 45 2.0 9.0 1
1 21 17.0 5.0 1
2 54 9.0 11.0 1
3 39 NaN NaN 1
4 5 2.0 57.0 2
5 3 2.0 65.0 2
6 6 4.0 21.0 2
7 7 46.0 4.0 3
8 9 39.0 8.0 3
9 9 38.0 17.0 3
10 2 3.0 55.0 2七:缺失值
Pandas 主要用 np.nan 表示缺失数据。 计算时,默认不包含空值。详见缺失数据。
重建索引(reindex)可以更改、添加、删除指定轴的索引,并返回数据副本,即不更改原数据。
找到缺失值 如下 df.isnull().sum()
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# 找到缺失值
print(df.isnull().sum())
a 0
b 0
c 1
label 0
dtype: int64缺失值,均值填充 如下 df['c'].fillna(df.c.mean())
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# 找到缺失值
# print(df.isnull().sum())
# 均值填充
df['c'].fillna(df.c.mean())
print(df)
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1
3 39 0 NaN 1
4 5 2 57.0 2
5 3 2 65.0 2
6 6 4 21.0 2
7 7 46 4.0 3
8 9 39 8.0 3
9 9 38 17.0 3
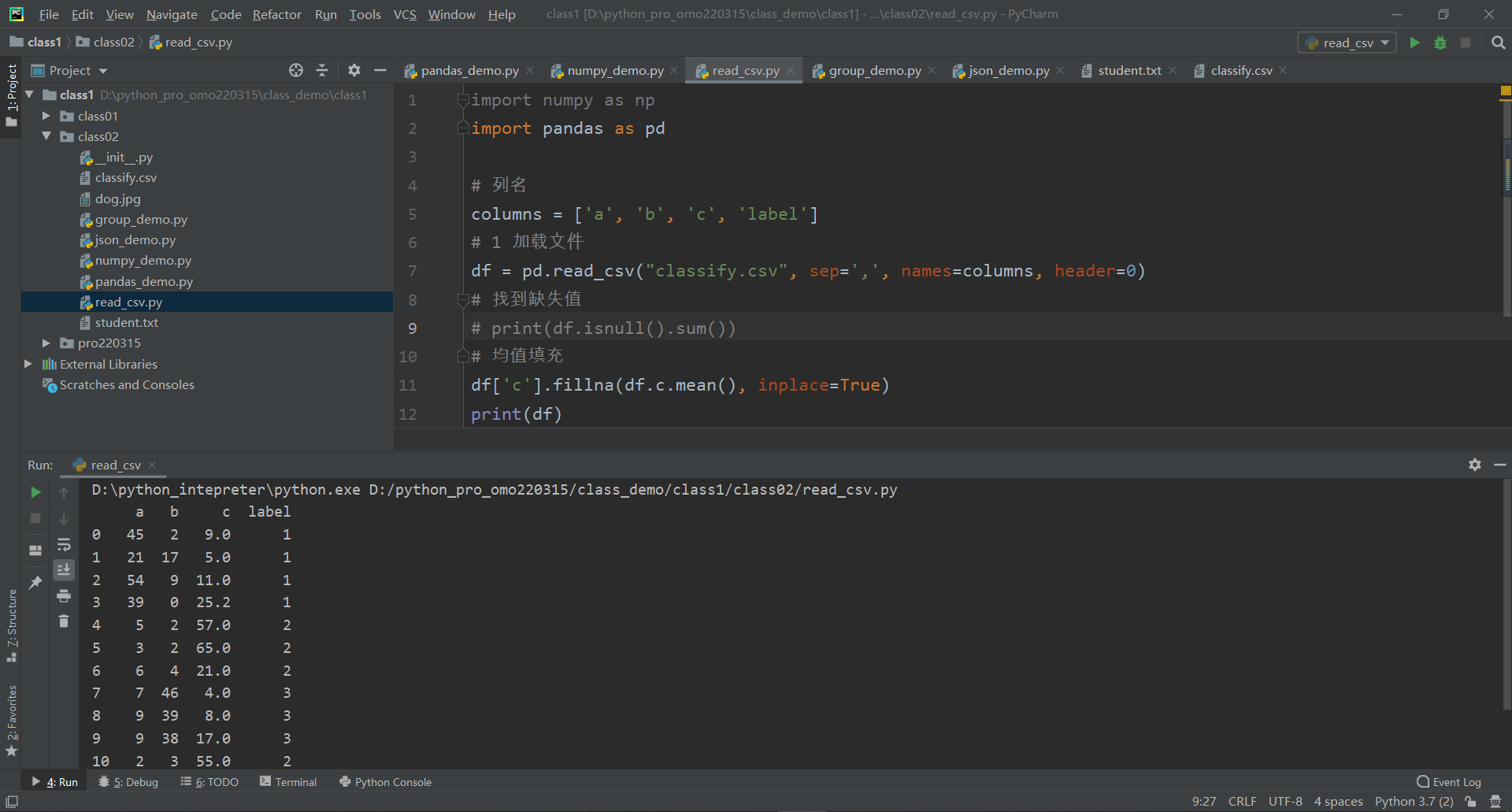
10 2 3 55.0 2需要inplace=True,替换原来的数据 如下 df['c'].fillna(df.c.mean(), inplace=True)
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# 找到缺失值
# print(df.isnull().sum())
# 均值填充
df['c'].fillna(df.c.mean(), inplace=True)
print(df)
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1
3 39 0 25.2 1
4 5 2 57.0 2
5 3 2 65.0 2
6 6 4 21.0 2
7 7 46 4.0 3
8 9 39 8.0 3
9 9 38 17.0 3
10 2 3 55.0 2