论文链接:https://arxiv.org/abs/2105.03889
代码链接:https://github.com/pengzhiliang/Conformer
参考博文:Conformer论文以及代码解析(上)_conformer代码_从现在开始壹并超的博客-CSDN博客
摘要
在卷积神经网络(CNN)中,卷积运算擅长提取局部特征,但难以捕获全局表征。在visual transformer中,级联的自注意模块可以捕获远距离的特征依赖,但不幸的是会破坏局部特征细节。在本文中,我们提出了一种称为Conformer的混合网络结构,以利用卷积运算和自注意机制来增强表征学习。一致性源于特征耦合单元(Feature Coupling Unit, FCU),它以交互的方式融合了不同分辨率下的局部特征和全局表征。Conformer采用并行结构,最大限度地保留局部特征和全局表示。实验表明,在参数复杂度相当的情况下,Conformer在ImageNet上的性能比ViT(DeiT-B)高出2.3%。在MSCOCO上,它在目标检测和实例分割方面的性能分别比ResNet-101高出3.7%和3.6%,显示出作为通用骨干网的巨大潜力。
背景
考虑到CNN与变压器特征之间的特征偏差,设计了特征耦合单元(FCU)作为桥接。一方面,为了融合两种风格的特征,FCU利用11卷积来对齐通道尺寸,向下/向上采样策略来对齐特征分辨率,LayerNorm[2]和BatchNorm[24]来对齐特征值。另一方面,由于CNN和变压器分支倾向于捕获不同级别的特征(例如,局部与全局),因此在每个块中插入FCU,以交互方式连续消除它们之间的语义分歧。这种融合过程可以极大地增强局部特征的全局感知能力和全局表示的局部细节。
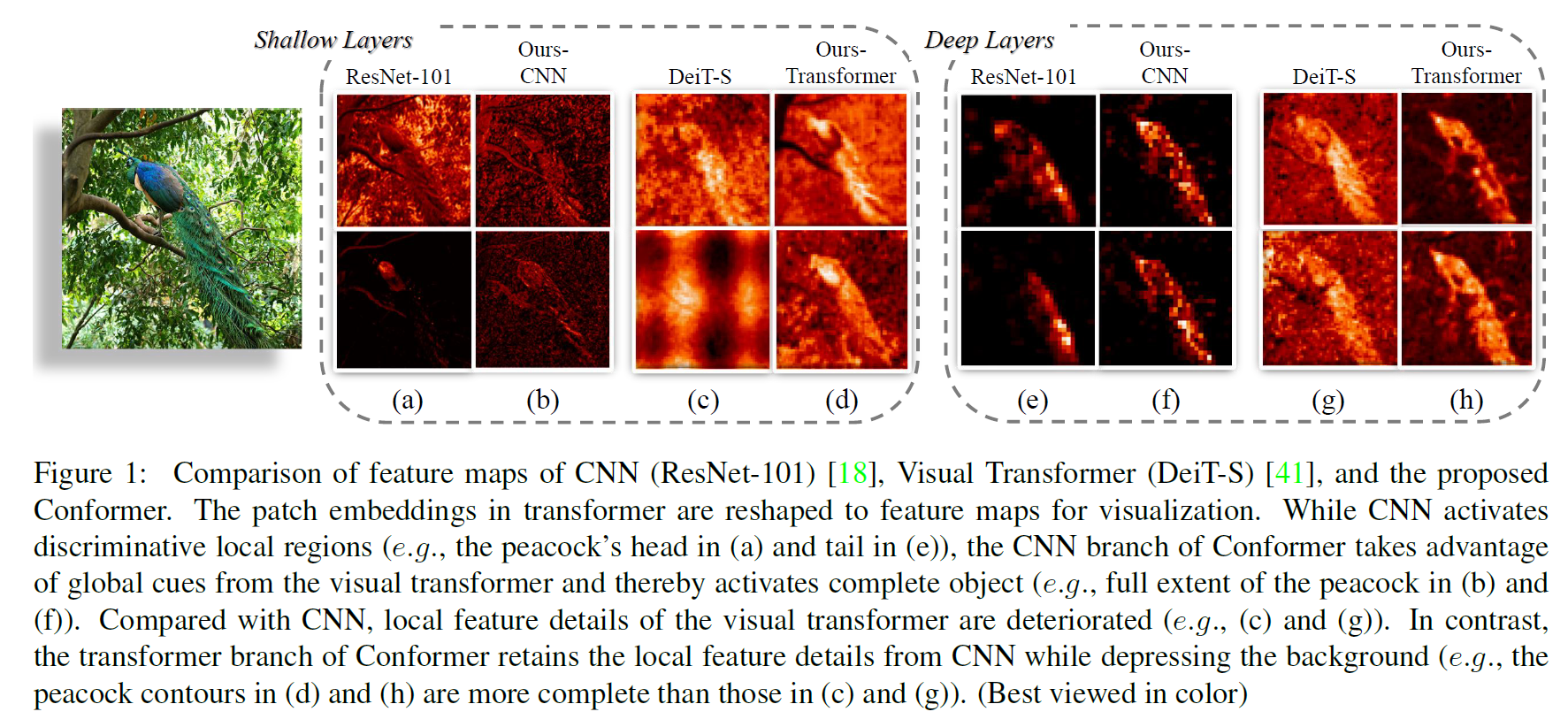
Conformer耦合局部特征和全局表示的能力如图1所示。传统的CNN (e:g:, ResNet-101)倾向于保留判别性的局部区域(如:g:,孔雀的头或尾巴),Conformer的CNN分支可以激活完整的对象范围,如图1(b)和(f)。当单独使用视觉变形器时,对于弱的局部特征(如:g:,模糊的对象边界),很难将对象与背景区分开来。图1(c)和(g).局部特征和全局表征的耦合显著增强了基于变压器的特征的可分辨性,图1(d)和(h)。
贡献
1)我们提出了一种称为Conformer的双重网络结构,它最大程度地保留了局部特征和全局表征。
2)我们提出了特征耦合单元(FCU),以交互方式融合卷积局部特征与基于变压器的全局表示。
3)在参数复杂度相当的情况下,Conformer的性能明显优于cnn和visual transformer。Conformer继承了cnn和visual transformer的结构和泛化优势,具有成为通用骨干网的巨大潜力。
相关工作
1)CNNs with Global Cues
2)Visual Transformers
方法
为了利用局部特征和全局表示,我们设计了一个并发网络结构,如图2(c)所示,称为Conformer
在Conformer中,我们连续地将Transformer分支的全局上下文馈送到特征图中,以增强CNN分支的全局感知能力。同样,CNN支路的局部特征被逐步反馈到patch embedding中,以丰富Transformer支路的局部细节。这样一个过程构成了相互作用。
具体来说,Conformer由主干模块(stem module)、双支路(dual branches)、桥接双支路的fcu、双支路的两个分类器(fc层)组成。
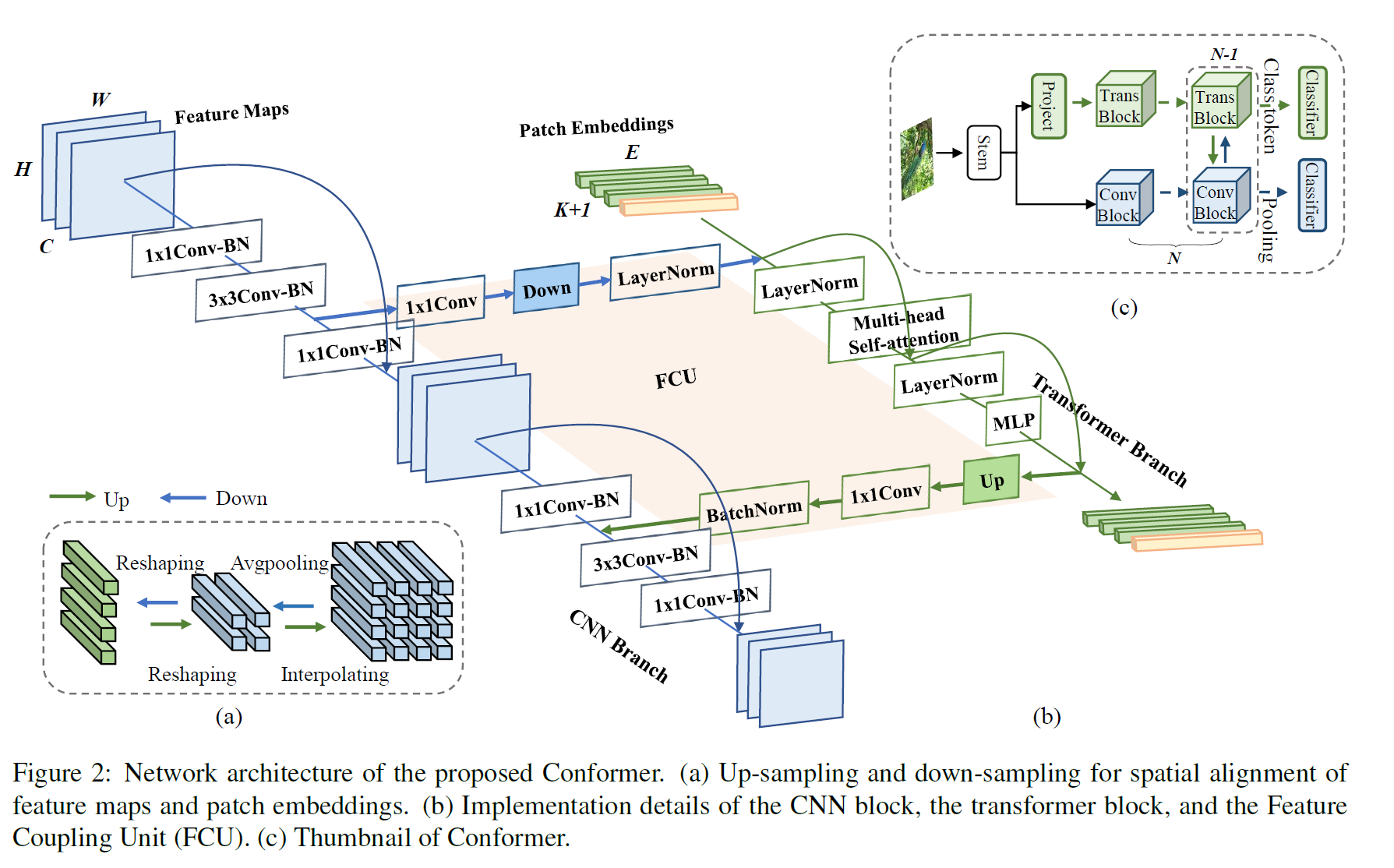
主干模块是一个7X7卷积与步幅2,然后是3X3最大池与步幅2,用于提取初始的局部特征(如:g:,边缘和纹理信息),然后被馈送到双分支。CNN支路和Transformer支路分别由N (eg, 12)个重复卷积和Transformer块组成,如表1所示。这种并行结构意味着CNN和变压器分支可以最大程度地分别保留局部特征和全局表征。FCU被提出作为桥接模块,将CNN支路中的局部特征与变压器支路中的全局表示融合在一起,如图2(b)。FCU从第二个块应用,因为两个分支的初始化特征是相同的。沿着分支,FCU以交互方式逐步融合特征图和patch embedding。
最后,对于CNN分支,所有的特征被汇集并馈送到一个分类器。对于Transformer分支,取出类令牌并馈送到另一个分类器。在训练过程中,我们使用两个交叉熵损失分别监督两个分类器。损失函数的重要性被经验地设定为相同。在推理过程中,两个分类器的输出简单地汇总为预测结果。

网络结构
CNN Branch
如图2(b)所示,CNN分支随着通道数的增加,特征图的分辨率随着网络深度的增加而降低。
我们将整个分支分为4个阶段,如表1(CNN分支)所示。每个阶段由多个卷积块组成,每个卷积块包含nc瓶颈。根据ResNet中的定义[18],瓶颈包含一个1X1向下投影卷积、一个3X3空间卷积、一个1X1向上投影卷积,以及瓶颈输入和输出之间的残差连接。在实验中,nc在第一个卷积块中设为1,在随后的N-1个卷积块中满足≥ 2。
视觉转换器[16,41]通过单步将图像块投影到矢量中,导致局部细节丢失。而在cnn中,卷积核在重叠的特征映射上滑动,这提供了保留精细的局部特征的可能性。因此,CNN分支能够连续地为变压器分支提供本地特征细节。
Transformer Branch
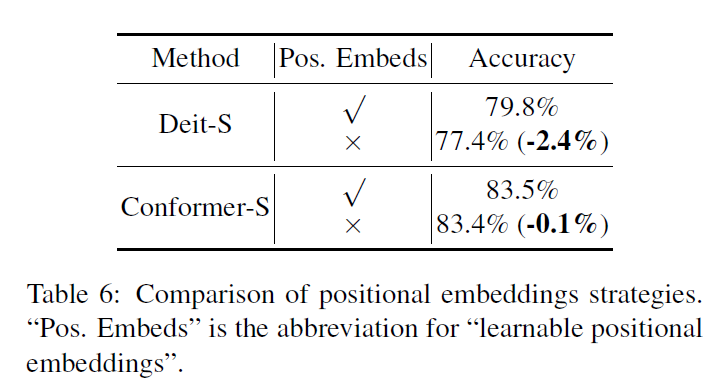
在ViT[16]之后,该支路包含N个重复Transformer块。如图2(b)所示,每个变压器块由一个多头自关注模块和一个MLP块(包含一个向上投影的fc层和一个向下投影的fc层)组成。layernorm[2]在每一层和自关注层和MLP块的剩余连接前应用。对于标记化,我们将词干模块生成的特征映射压缩为14X14个补丁嵌入没有重叠,通过一个线性投影层,这是一个4X4卷积,步幅为4。然后对补丁嵌入伪类标记进行分类。考虑到CNN分支(3X3卷积)既编码局部特征又编码空间位置信息[25],因此不再需要位置嵌入。这有助于提高下游视觉任务的图像分辨率。
Feature Coupling Unit (FCU)
考虑到CNN支路中的特征映射和变压器支路中的patch embedding,如何消除它们之间的不对齐是一个重要的问题。为了解决这个问题,我们提出FCU以交互的方式将局部特征与全局表示连续耦合。
1) 1x1 convolution用来调整channel的维度也就是C;
2) down/up sampling用来调整feature的分辨率也就是H和W;3) Batch Norm和Layer Norm用来调整feature values。
并且,FCU模块被嵌入到网络的每个block中,更好的消除两种机制提取到的feature的语义差异.
一方面,我们必须认识到CNN和变压器的特征维数是不一致的。CNN特征图的维数为C H W (C、H、W分别为通道、高度和宽度),patch embedding的形状为(K + 1) E,其中K、1、E分别表示图像patch的个数、类标记和嵌入维数。当馈送到Transformer支路时,特征映射首先需要经过11次卷积来对齐贴片嵌入的通道号。然后使用下采样模块(图2(A))完成空间维度对齐。最后,对特征映射进行补丁嵌入,如图2(b)所示。当从变压器支路反馈到CNN支路时,需要对贴片嵌入进行上采样(图2(a))以对齐空间尺度。
一方面,我们必须认识到CNN和变压器的特征维数是不一致的。CNN特征图的维数为CX H XW (C、H、W分别为通道、高度和宽度),patch embedding的形状为(K + 1)X E,其中K、1、E分别表示图像patch的个数、class token和嵌入维数。
当馈送到变压器支路时,特征映射首先需要经过1X1卷积来对齐贴片嵌入的通道号。
然后使用下采样模块(图2(A))完成空间维度对齐。

最后,对特征映射进行补丁嵌入,如图2(b)所示。当从变压器支路反馈到CNN支路时,需要对贴片嵌入进行上采样(图2(a))以对齐空间尺度。
然后通过1X1卷积将通道维度与CNN特征图的维度对齐,并添加到特征图中.
同时,使用LayerNorm和BatchNorm模块对特征进行正则化。
另一方面,特征映射和patch embedding之间存在明显的语义差距,即特征映射是从局部卷积算子中收集的,而补丁嵌入是通过全局自关注机制进行聚合的。因此,FCU应用于每个块(除了第一个块),以逐步填补语义空白。
讨论和分析
结构分析
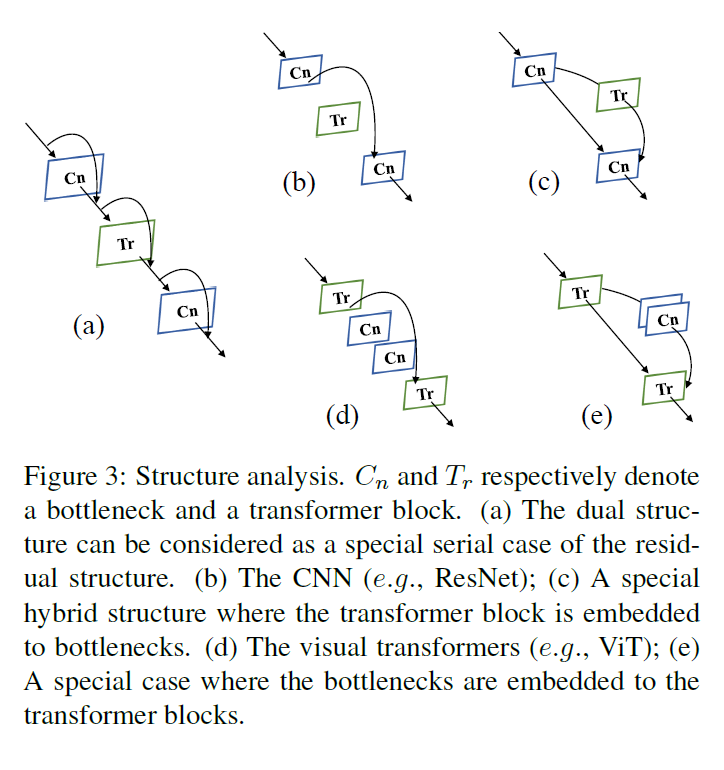
将FCU作为一个短连接,我们可以将所提出的对偶结构抽象为特殊的串行残差结构,如图3(a)所示。在不同的剩余连接单元下,Conformer可以实现不同深度的bottleneck(如ResNet,图3(b))和变压器块(如ViT,图3(d))组合,这意味着Conformer继承了cnn和视觉变压器的结构优势。此外,它还实现了不同深度的bottleneck和变压器块的不同排列,包括但不限于图3(c)和(e),这大大增强了网络的表示能力。
特征分析
我们在图1中可视化特征图,在图4中可视化类激活图和注意图。与ResNet[18]相比,Conformer的CNN分支在耦合全局表示的情况下,更倾向于激活更大的区域,而不是局部区域,这表明长距离特征依赖性增强,这在图1(f)和4(a)中得到了显著的证明。由于CNN支路逐步提供了精细的局部特征,变压器支路在Conformer中的贴片嵌入保留了重要的详细的局部特征(图1(d)和(h)),这些特征被视觉变压器[16,41](图1(c)和(g))破坏了。此外,图4(b)中的注意区域更加完整,背景被明显抑制,这意味着Conformer学习到的特征表征具有更高的判别能力。
实验
模型变量
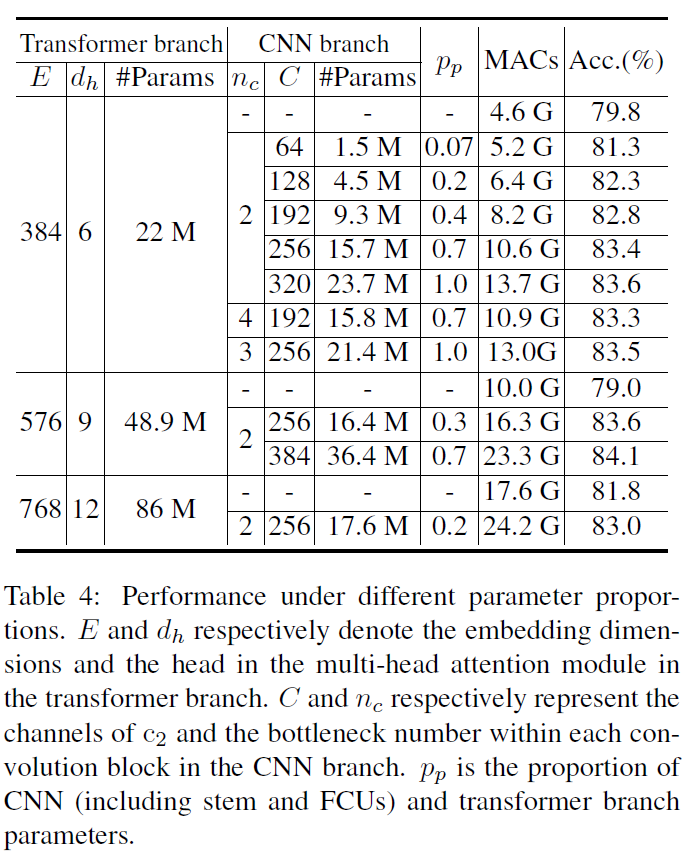
通过调整CNN和变压器支路的参数,我们得到了模型变体,分别称为- Ti, - s和- b。Conformer-S的详细情况见表1,Conformer-Ti/B的详细情况见附录。Conformer-S/32将特征映射分割为7X7个patch, i:e:,在变压器支路中patch的大小为32X32。
图像分类
实验设置
Conformer在具有1.3M张图像的ImageNet-1k[14]训练集上进行训练,并在验证集上进行测试。Top-1的精度如表2所示。为了使变压器收敛到合理的性能,我们采用了DeiT[41]中的数据增强和正则化技术。这些技术包括Mixup[52]、CutMix[51]、erase[54]、Rand- Augment[12]和Stochastic Depth[23])。模型使用AdamW优化器[32]训练300 epoch, batchsize 1024, weight decay 0.05。初始学习率设置为0.001,并在余弦调度中衰减。
表现
在相似的参数和计算预算下,表2中,Conformers的表现优于CNN和visual transformer。例如,Conformer-S(参数为3770万,mac为10.6G)分别比ResNet-152(参数为6020万,mac为11.6G)和DeiT-B(参数为860万,mac为17.6G)分别高出4.1%(83.4%比78.3%)和1.6%(83.4%比81.8%)。参数相似且MAC成本适中的Conformer-B优于DeiT-B 2.3%(84.1%对81.8%)。除了其优越的性能,Conformer收敛速度比视觉变压器快。、
目标检测和实例分割
为了验证Conformer的多功能性,我们在MSCOCO数据上对其在实例级任务(例如:g:,对象检测)和像素级任务(例如:g:,实例分割)上进行了测试[30]。共形器作为主干,无需额外设计进行迁移,相对精度及参数比较见表2。对于CNN分支,我们可以使用[c2;c3;c4;C5]作为侧输出,构建特征金字塔[29]。
实验设置
按照惯例,模型在MSCOCO训练集上进行训练,并在MSCOCO最小集上进行测试。在表3中,我们分别报告了APbbox (APsegm)、APbbox S (APsegm S)、APbbox M (APsegm M)和APbbox L (APsegm L)的平均超过IoU阈值、box (mask)的小、中、大对象。除非明确指定,否则我们使用批大小为32,学习率为0.0002,优化器AdamW[32],权重衰减为0.0001,最大epoch为12。学习率在第8和第11历元时衰减一个数量级。
表现
如表3所示,Conformer显著提高APbbox和APsegm。对于目标检测,Conformer-S/32的mAP (55.4 M & 288.4 GFLOPs)比FPN基线(ResNet-101, 60.5 M & 295.7 GFLOPs)高3.7%。以分割为例,Conformer-S/32的mAP (58.1M & 341.4 GFLOPs)比Mask R-CNN基线(ResNet-101, 63.2 M & 348.8 GFLOPs)高3.6%。这证明了全局表示对于高级任务和建议的重要性
实验结果


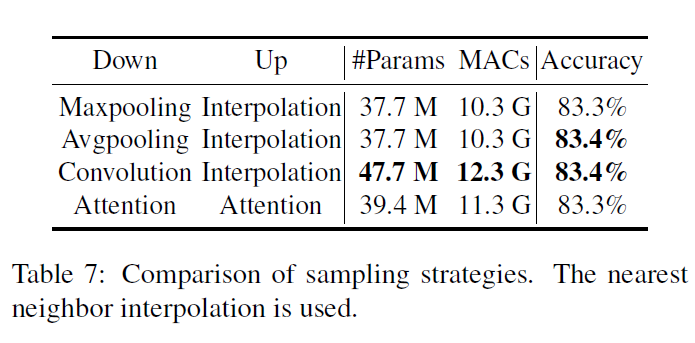
消融实验