日益复杂的网络和多样化的工作负载要求网络内置更多的自动化决策能力,通过可编程网络设备在用户面支持机器学习工作负载就是一个可能的选项,本文提出了一种支持用户面推理的架构设计,相对控制面机器学习的性能有数量级的提升。原文: Taurus: A Data Plane Architecture for Per-Packet ML
概要
新兴应用(云计算、物联网、增强/虚拟现实)需要反应迅速、安全、可扩展的数据中心网络,当前这些网络实现了简单的、逐包计算的数据平面(如ECMP和sketches),并在实现了数据驱动的性能、安全策略的慢速、毫秒级延迟控制平面的管理之下。然而,为了满足现代数据中心的应用服务水平目标(SLOs, service-level objectives),网络必须弥合线速(line-rate)、逐包执行(per-packet execution)和复杂决策之间的差距。
因此我们提出并设计和实现了Taurus,这是一个用于线速推理的数据平面。Taurus将灵活的、抽象了并行模式(MapReduce)的定制化硬件添加到可编程网络设备(如交换机和网卡)中,这种新硬件基于流水线SIMD实现并行,完成逐包MapReduce操作(如推理)。我们对Taurus交换机ASIC的评估(基于几个真实世界的模型)表明,Taurus的运行速度比基于服务器的控制平面快几个数量级,同时面积增加了3.8%,线速机器学习模型的延迟增加了221ns。此外,Taurus FPGA原型实现了完整的模型精度,比最先进的控制平面异常检测系统的能力提升了两个数量级。
1. 简介
为现代分布式工作负载(如云计算、物联网、增强/虚拟现实)保证严格的安全和服务水平目标(SLO),需要根据整个数据中心网络的当前状态(如拓扑结构、队列大小以及链路和服务器负载)做出计算密集型管理和控制决策,并按线速应用在每个数据包上[170]。在当今双向Pb级带宽网络[60]中,即使是几微秒的延迟,也可能产生数以百万计的异常数据包[8][17][154],从而使交换机队列饱和并导致拥堵[66][162][169],或者由于丢包而导致过度重传[37],以及造成流量和服务器负载不均衡[4][85]。然而,当前的实现面临两难,必须在每包线速执行或计算复杂性之间做出选择。
数据面ASIC(如交换机和NIC)可以在纳秒级对网络条件做出反应,但其编程模型被限制为以线速度转发数据包(如流量表[15][63]),从而将网络操作限制在简单的启发式方法上[4][85][98],或者需要在固定功能硬件中实现特定任务(如中间件[29][103])。
控制面服务器可以做出复杂的、数据驱动的决策,但频率不高(通常在每条流的第一个数据包上)。即使有快速数据包IO[38][83][132]和专用硬件(如TPU[84]或GPU[119]),控制器和交换机之间的往返时延(10us或更多)也从根本上限制了控制面的反应速度。将计算转移到交换机CPU也没有帮助,因为缺乏全局网络知识,而且交换机ASIC和CPU之间的PCIe接口增加了大约900ns的往返延迟[117],意味着在12.8Tb/s的网络上,ASIC在做出决定之前已经转发了大约12000个128字节的数据包(或22000个64字节数据包)。
因此提出如下问题:"如何能将控制面的复杂决策委托给数据面ASIC?"控制面可以通过对全局网络状态进行采样来学习新的趋势(如攻击[106][153]、流量模式[162][169]和工作负载[169]),并可以训练机器学习(ML)模型来处理此类事件。然后,数据面可以使用封装了全网行为的模型,在不访问控制面的情况下做出转发决策。同时,控制面可以继续捕捉交换机的决策及其对指标的影响(如流量完成时间),训练和优化模型以学习新的事件类型(或签名)以及提高决策质量,并以固定的时间间隔更新交换机模型。这种训练将发生在较粗的时间尺度上(几十毫秒),但不在关键路径上。而且,使用最近训练的机器学习模型,数据面可以从流量的第一个数据包开始做决定,同时对已知(学习)类型的事件做出自主反应,控制面只需要对新(未见)事件类型进行干预[1]。
[1] 另一方面,无论事件类型(或签名)如何[96],流量规则需要控制面对每个事件进行干预。
那么挑战就在于如何在数据面上运行机器学习模型。如果网络行为是稳定的,可以将模型输出映射为交换机的匹配动作表(MAT, match-action table)中的流量规则[15]。然而,现代数据中心网络是动态的,这将导致表项的频繁失效并需要频繁访问控制面,从而增加对网络事件做出反应的时间[170]。直接在现有交换机上实施模型,特别是深度神经网络(DNN, deep neural network)也是不可行的[144][168]。大多数机器学习算法是围绕线性代数建立的,使用了大量的重复性计算,在少量权重上进行定期通信[88][127][150]。匹配动作流水线的VLIW架构[15]缺乏必要的循环和乘法运算,以及不必要的灵活性(如全连通VLIW通信[178]、大型存储器和MAT中的三元CAM[15]),消耗了芯片面积,但对机器学习却没有好处[144]。简而言之,现有数据面缺乏执行现代机器学习算法(如DNN)所需的计算资源,而控制面服务器(和加速器)没有针对超过每秒几十比特的网络速度下的每包低延迟操作进行优化。
我们在本文中提出了Taurus,一个用于数据面逐包运算机器学习的特定领域架构。Taurus扩展了独立于协议的交换架构(PISA, ProtocolIndependent Switch Architecture)[15][63],有一个基于并行模式抽象的新计算模块(即MapReduce)[88],支持现代机器学习应用中常见的数据并行性[28]。MapReduce模块实现了空间SIMD架构,由内存单元(MU, memory unit)和计算单元(CU, compute unit)组成,交错排列在一个网格中,并由一个静态互连(第4节)连接。每个CU有四个流水线计算阶段,每个计算阶段对16个独立的数据元素(通道)各进行一次8位定点操作。当评估一个16位输入感知器时,CU使用第一级来映射16个平行的乘法,然后使用第二级将乘法的值减少到一个单元。第二个CU应用激活函数(例如ReLU[112])。多个CU可以并行用于分层MapReduce计算(宽模型层)或串联用于流水线计算(多层)。
MapReduce模块与解析器、MAT、调度器一起工作转发数据包,MAT将MapReduce与流水线连接起来,预处理MAT负责提取、格式化并记录数据包级、流级[154]、交叉流以及设备特征(基于带内网络遥测即INT[87]),MapReduce模块基于这些特征和机器学习模型生成数学结果,后处理MAT将输出转化为数据包转发决策。不需要机器学习决策的数据包可以绕过MapReduce模块,避免产生额外延迟。
总之,Taurus是一个集成系统,集合了网络和机器学习架构领域的想法(即用MapReduce模块扩展PISA流水线),实现了逐包机器学习(per-packet ML) 这种新的计算范式,以供行业和学界探索、创新[2]。我们做出了如下贡献:
-
用于MapReduce的带有可重配SIMD数据流引擎的Taurus交换机硬件设计(第3节)和实现(第4节)。 -
基于15ns预测PDK[12]对ASIC [3](第5.1.1节)进行分析,并针对真实的机器学习网络应用(第5.1.2节)、微测试(第5.1.3节)和纯MAT实现(第5.1.4节)进行合成,以确定相对于市售交换机的速度和面积开销。Taurus的MapReduce模块为线速(1GPkt/s)机器学习模型平均增加了122ns延迟,而对于最大的模块配置来说,产生的面积和功耗开销分别增加了3.8%和2.8%。 -
基于Taurus测试平台进行端到端系统评估,该测试平台基于连接到FPGA的可编程交换机,可对MapReduce模块进行模拟(第5.2.1节)。结果表明,Taurus完全实现了模型精度,并比控制面事件检测能力提升了两个数量级(第5.2.2节)。此外,数据面模型可以在几毫秒内学会处理来自控制器的新(异常)行为(第5.2.3节)。
[2] Taurus原型源代码可以在https://gitlab.com/dataplane-ai/taurus上公开获取。
[3] 设计评估基于最近的空间SIMD加速器Plasticine[127],并将其修改为针对线速的纯推理应用。代价是需要降低精度,缩短流水线,并且不支持浮点运算,没有DRAM,以及更少的片上存储器。
2. 逐包机器学习需求(THE NEED FOR PER-PACKET ML)
为了满足现代超大规模数据中心严格的SLO,网络界已经基于可编程数据平面(如Barefoot Tofino芯片[114][115])以包为单位运行服务(如负载均衡[4][85]、异常检测[95][102]和拥塞控制[162][169])。然而,数据平面的受限编程模型将服务限制在简单的启发式方法上,无法处理大规模数据中心网络的复杂交互[75]。另一方面,机器学习(ML)可以一定程度上处理这些复杂的交互[43][52],而且,通过自动决策,机器学习算法可以利用大量网络数据,逐步学习适合特定数据中心的更明智的决策[6][17][42][101][110][123][152][153][172-174][99][131][169]。此外,最近关于拥塞控制[162][169]、数据包分类[99][126][131]和异常检测[106][153]的机器学习工作表明,这些算法比手动编写的启发式算法有更平滑、更准确的决策边界。例如,与现有机制(如PCC[37]和QUIC[91])相比,机器学习为拥塞控制提供了更好的针对吞吐量和延迟的平衡。
然而,机器学习通常用于闭环决策系统,因此其反应速度对数据中心的性能和安全性至关重要。例如,如表1所示,主动队列管理(例如RED[45][70]和DCTCP[5])必须针对每个数据包做出标记/删除的决定。入侵/故障检测和缓解方案(例如,针对重击[148]、微爆[139]、DoS[17][36]以及灰色故障[77][170])必须快速行动,因为即使几微秒的延迟也会造成PB级带宽网络中数百万的丢包,从而产生严重的影响。例如,在SYN-flood攻击中,每个丢包会在服务器上打开一个新的连接,造成CPU、内存资源以及网络带宽的不必要的消耗。另一方面,有效的资源分配(例如链接带宽)需要及时对网络流量进行分类[11]。在这些情况下,缓慢的机器学习决策会造成不同后果,但通常会导致次优的行为(例如无法达成安全和服务级别目标),增加的延迟会导致延迟决策,并最终降低机器学习模型的准确性(第5节)。
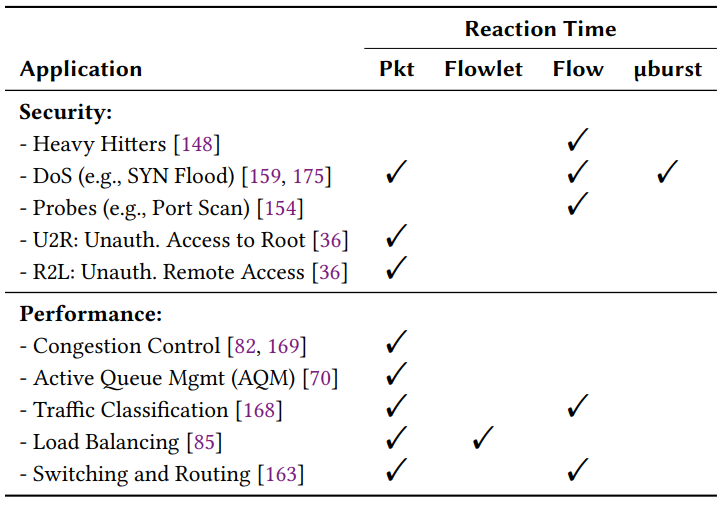
2.1. 数据面机器学习的限制(Limitations of Data-Plane ML)
最近有许多基于当前交换机抽象(例如MAT)[136][144][168]以及专门硬件[53]进行网络内机器学习的尝试,然而,这两种方法都有缺陷,因此无法提供线速的逐包机器学习。
2.1.1. 基于MAT的推理
基于VLIW架构的匹配动作(match-action)抽象,由于缺少指令(尤其是循环和乘法)以及低效的MAT流水线,在现代数据平面设备中不足以实现线速机器学习[15]。已经实现的二进制神经网络(基于几十个MAT)也不够精确[136][144]。同样,用于物联网分类的SVM[168]被证明在NetFPGA参考交换机(一个实验研究平台)上需要消耗额外8个表[104][113]。因此,相对于模型质量而言,其资源使用非常大(第5.1.4节)。
VLIW与SIMD并行模式的比较。 单指令/多数据(SIMD)的每个指令成本比交换机的VLIW模型更便宜。目前在交换机MAT[15]中使用的VLIW模型,每级可以并行执行多个逻辑上独立的指令,可以在包头向量(PHV, packet-header vector)中读写任意位置。这种全对多(all-to-multiple)的输入通信和多对全(multiple-to-all)的输出通信需要大型交换结构,从而限制了每级指令数量。例如,一个16并发VLIW处理器的控制逻辑是同样强大的8个双并发处理器集群的20倍[178]。因此,Barefoot Tofino芯片每级只执行12个操作,8、16、32位操作各4个[65]。一个典型的DNN层可能需要72次乘法和144次加法[153],即使乘法被添加到MAT中,也需要18个阶段(大部分情况下)。
2.1.2. 基于加速器的推理
传统加速器(如TPU[84]、GPU[119]和FPGA[44])可以扩展数据平面,作为通过PCIe或以太网连接的直连推理引擎。在大多数加速器中,输入是批量的,以提高并行性,较大的批量可以通过更有效的矩阵乘法运算来提高吞吐量。然而,非批量(矩阵向量)处理对于确定性延迟是必要的,否则数据平面的数据包需要在等待批量填充时停滞。此外,增加物理上独立的加速器将消耗交换机端口(浪费收发器和带宽)或需要重复实现交换机功能(如数据包解析或者特征提取的匹配行动规则)。因此,独立的加速器会增加冗余面积,降低吞吐量,并增加更多能耗。
2.2. 控制面机器学习的限制(Limitations of Control-Plane ML)
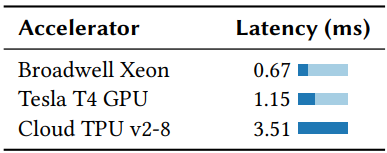
MAT[108]可以缓存在控制面上计算的推理结果,而不是按数据包执行深度模型。在缓存方案中,具有先前未见特征的数据包将被发送到控制面进行推理,而推理结果将作为流量规则存储在数据面中。然而,不同输入的深度模型(如数据包大小),将被频繁触发昂贵的控制面操作。
由于控制面的网络往返时间以及软件本身的开销,很难避免缓存失效的问题,即使有加速器,也会极大损害模型的准确性。表2在矢量CPU[1]、GPU[119]和TPU[84]上对一个用于异常检测的DNN模型[153]进行非批量推理的延迟进行了基准测试。延迟来自加速器的设置开销(例如Tensorflow[1]),CPU延迟最少,但仍需要0.67ms。最后,由于缓存随着流表的增加而增大[47][90],规则配置时间(TCAM[25]为3ms)会限制缓存的大小。
3. Taurus架构
Taurus是用于交换机(和网卡)的新型数据面架构,以线速基于每个数据包运行机器学习模型,并基于模型输出进行转发决策。
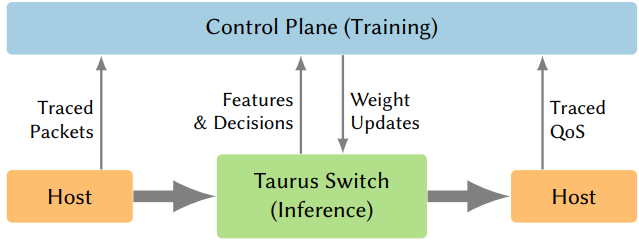
系统概要设计。 在支持Taurus的数据中心中,控制面收集网络全局视图,并训练机器学习模型以优化安全和交换机级指标。同时,数据面基于模型对每个数据包做出数据驱动决策。与传统基于SDN的数据中心不同,控制面在交换机中同时配置了权重和流量规则(图1)。权重比流量规则更节省空间,例如,匹配基准DNN(第5.1.2节)的动作可能需要12MB的流量规则(完整数据集),但权重规则只占5.6KB,内存用量减少了2135倍。使用Deep Insight[78]等监控框架,控制面可以识别机器学习决策的影响并相应优化权重。
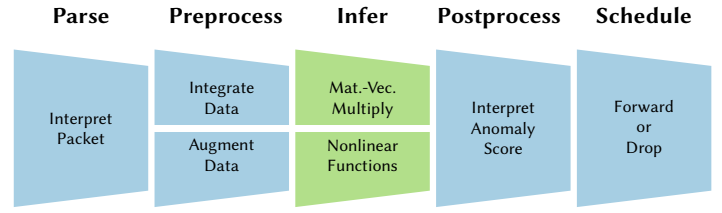
异常检测案例研究。 本节以基于机器学习的异常检测(使用4层DNN[153])作为实际运行的例子引入和介绍Taurus数据面流水线的各种逻辑组件(图2)。当数据包进入交换机时,首先被解析为包头矢量(PHV, 一种固定布局的结构化格式)[15],以提取包头级别的特征(例如,连接时间、传输的字节数以及协议和服务类型)。接下来,交换机通过预处理MAT查找域级特征(例如,匹配IP地址与自治系统子网,以表明所有权或地理位置),这些特征由控制面发现和配置,并使用VLIW动作对头域进行数据整合和增强(第3.1节)。然后,一旦MapReduce模块在提取的特征上执行完模型(第3.3节),Taurus就通过后处理MAT将机器学习模型的输出转化为决策(第3.2节)。然后,这一决策被用来调度、转发或丢弃数据包。我们在基于PISA的交换机中共享MAT,以用于预处理和后处理。
3.1. 解析和预处理(Parsing & Preprocessing)
在推理之前,Taurus通过MAT将原始数据包头处理成规范的形式,根据需要添加或修复包级数据。通过交换机处理流水线的有状态元素(即寄存器)汇聚跨包和跨流特征。然后,MAT将汇聚信息添加到每个数据包元数据中,以增强基于每个数据包的预测。数据预处理也可以使用MAT将头域字段转换为机器学习模型的特征。例如,在异常检测例子中,MAT把特征格式化为定点数,MapReduce模块决定一个数据包是否正常。
Taurus通过查找表将分类关系替换为更简单的数字关系。例如,表格将端口数字转换为线性似然值,这样更容易推理[31]。预处理也可以反转取样值所依据的概率分布。对指数分布的变量取对数会产生均匀分布,机器学习模型可以用更少的层来处理[138]。这样的特征工程将负载从机器学习模型转移到设计者身上,精炼特征可以用恒定大小来提高准确性[16][138]。
最后,带内网络遥测(INT, 将测量嵌入数据包)为交换机提供了全局网络状态视图[87]。因此,Taurus设备不限于利用交换机本地状态进行推理。相反,模型可以通过INT检查数据包的整个历史,并通过有状态寄存器检查流量的整个历史,以提升其预测能力(例如,计算整个流量的紧急标志或监测连接持续时间)。
3.2. 后处理和调度(Postprocessing & Scheduling)
MAT也可以解释机器学习的决策。例如,如果异常检测模型输出0.9(表明可能的异常数据包),MAT需要决定如何处理这个数据包,丢弃、标记还是隔离。在Taurus中,这些后处理MAT将推理与调度联系起来,使用像PIFO[147]这样的抽象来支持各种调度算法。
机器学习模型将提供概率保证,但我们可以用硬约束来约束其行为,以确保网络稳健运行。控制面将高层次的安全(没有不正确行为)和有效性(最终行为正确)属性编译成交换机的约束,作为后处理流程规则。通过约束机器学习模型的决策边界,数据面可以保证正确的网络行为,而无需复杂的模型验证。
3.3. 用于逐包机器学习推理的MapReduce(MapReduce for Per-Packet ML Inference)
对于每个数据包来说,通过推理结合清理过的特征和模型权重来做出决定。机器学习算法,例如支持向量机(SVM, support-vector machine)和神经网络,使用矩阵-向量线性代数运算和元素级非线性运算[59][72]。非线性运算让模型学习非线性语义,否则输出将是输入的线性组合。与头处理不同,机器学习运算是非常有规律的,使用许多乘加运算。在单个DNN神经元的计算量较大的线性部分中,输入特征分别与权重相乘,然后相加,产生标量值。概括来说,向量到向量(map)和向量到标量(reduce)运算足以满足神经元计算密集型的线性部分。这一点,加上目前交换机架构的局限性,促使我们需要新的数据面抽象,即MapReduce,该抽象足够灵活,可以表达各种机器学习模型,但又足够定制化,从而允许有效的硬件实现。
3.3.1. MapReduce抽象
我们的设计利用MapReduce的SIMD并行性,以廉价的方式提供高计算量。Map运算是对元素的向量运算,如加法、乘法或非线性运算。Reduce运算是将元素的向量合并为标量,使用关联运算,如加法或乘法。图3显示了如何使用map和reduce来计算单个神经元(点积),该神经元可以分层组合成大型神经网络。MapReduce是机器学习模型的一种流行形式,既可以在分布式系统中加速机器学习[22][54][55][57][133],也可以在更精细的颗粒度上加速机器学习[20][21][28][150]。

P4中的MapReduce控制块。 为了给Taurus编程,我们在P4[13][122]中引入了新的专用控制块类型,称为MapReduce,此外还有用于入口和出口匹配动作计算的控制块。在这个新的控制块中,MapReduce单元可以用Map和Reduce结构来调用。图4显示了我们提出的MapReduce语法(受到最近提出的Spatial语言[88]的启发),实现了一个用于异常检测的例子。最外层的map对所有层的神经元进行迭代,而内部的MapReduce对每个神经元进行线性运算。最后一个map指令应用激活函数(即ReLU或sigmoids)。除了Map和Reduce之外,唯一需要的额外结构是数组和带外权重更新。
![图4. P4中基于Spatial[88]的MapReduce语法,用于异常检测示例的DNN层。](https://img-blog.csdnimg.cn/img_convert/211ed3f54f68314d6665d3a2910d9682.png)
3.3.2. 更广泛的应用支持
通过提供通用原语,可以支持一系列比机器学习更广泛的应用(图5),包括用于数据分析的流处理[18][89],用于大规模分布式训练的梯度聚合[57][97][111][137],以及交换机和NIC上的应用[125]。例如,Elastic RSS(eRSS)使用MapReduce进行一致性哈希调度数据包和处理器,map评估处理器的适用性,reduce选择最近的处理器[134]。MapReduce还可以支持sketching算法,包括用于流量大小估计的Count-Min-Sketches(CMS)[30]。此外,最近研究表明,布隆过滤器也可以从神经网络中受益,或者被神经网络取代[130]。实质上,Taurus提供了一个可编程的数据面抽象(MapReduce),与现有的数据面抽象(即MAT)相比,可以更有效(在硬件资源使用和性能方面,第5节)的支持大量应用。
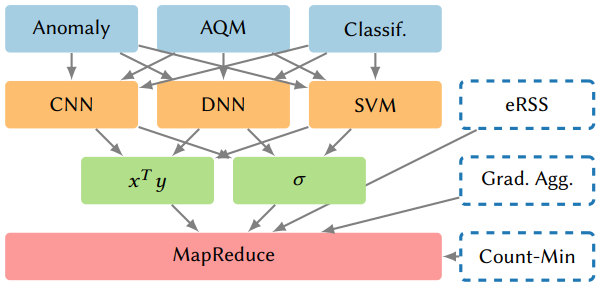
4. Taurus实现
图6显示了Taurus设备的完整物理数据面流水线,包括数据包解析控制块、MapReduce机器学习、基于MAT的数据包转发、调度以及非机器学习数据包的旁路。Taurus数据包解析器、预/后处理MAT和调度器基于现有硬件实现[15][56][147]。我们将Taurus的MapReduce模块建立在Plasticine[127]上,这是一个由计算和存储单元组成的粗粒度可重配阵列(CGRA, coarse-grained reconfigurable array),可重新配置以匹配应用程序数据流图。然而,Plasticine最初是用于设计独立的加速器,而我们需要在网络中运行延迟优化的流媒体结构。
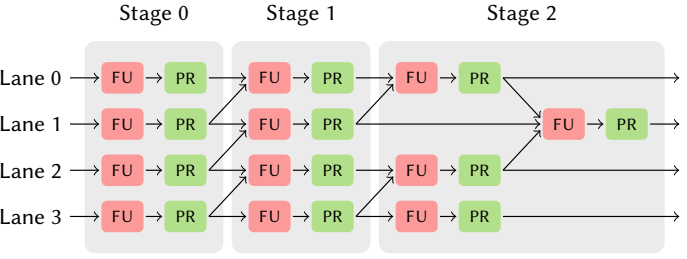
MapReduce: 计算单元(Compute Unit, CU)。 每个计算单元(CU,图8)由功能单元(FU, functional unit)组成,按通道(lane) 和阶段(stage) 组织,分别或者同时执行map和reduce。在一个CU阶段内,所有通道执行相同的指令,并读取相同的相对位置。CU在各阶段之间有流水线寄存器,因此每个FU在每个周期都是活跃的,流水线也在CU之间的较高层次上发生。
由于该结构需要作为全交换ASIC的一部分运行,因此资源效率是关键。我们使用定点低精度硬件来执行机器学习算法中线性代数所需的算术运算。与浮点运算相比,定点硬件速度更快,面积更小,而且功耗更低。此外,我们定制了CU中通道与阶段的比例,以适应应用空间的最低要求。对设计空间探索过程的完整解释见第5节。
MapReduce: 内存单元(Memory Unit, MU)。 接下来,我们重点关注内存访问速度。如果想对每个数据包做决策,就需要快速检索机器学习模型中的权重。基于SRAM操作可以在单周期内完成,所以我们只用片上存储器。由于DRAM访问需要100个周期,因此我们取消了DRAM控制器。虽然这限制了Taurus可以支持的模型大小,但可以在1GHz时钟下确保纳秒级延迟。我们使用堆叠的SRAM作为内存单元(MU),像棋盘一样与CU穿插在一起,用于存储机器学习模型的权重(图7)。该设计也能支持粗粒度流水线,其中CU执行运算,MU充当流水线寄存器。
每个CU内的多级流水线和互连流水线保证了1GHz的时钟频率,这是匹配高端交换机硬件线速的关键因素[15][147][4]。
[4] Taurus中的CU和MU架构目前支持密集机器学习模型,但也可以被扩展以支持稀疏线性代数[135],这是我们未来的工作。
预/后处理MAT。 通过MAT(VLIW)进行数据清理,使用MapReduce(SIMD)进行推理,Taurus结合了不同的并行模式,建立了快速而灵活的数据面流水线。MAT通过相同的PHV接口与MapReduce模块相连,PHV接口用于连接流水线中其他阶段。只有包含特征的PHV的一部分进入MapReduce模块,而其他头域则直接进入后处理MAT,如图7所示。
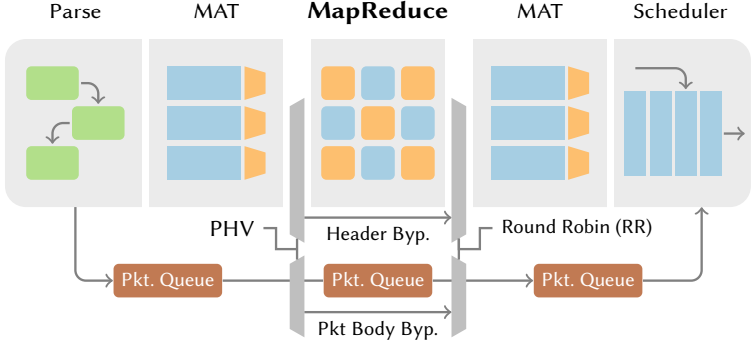
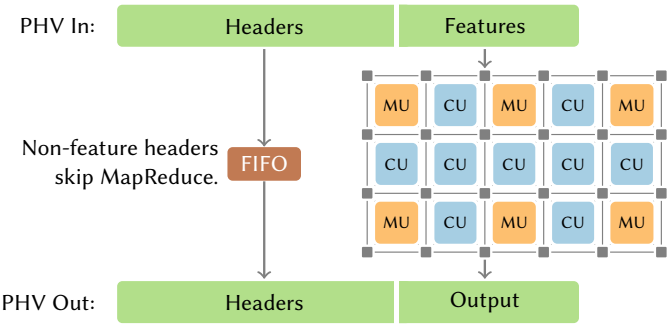
非机器学习流量旁路。 对于不需要机器学习推理的数据包,Taurus直接将其转发到后处理MAT,绕过了MapReduce(图6)。它将传统交换机的单一、大型包队列[15]分成三个子队列: 预处理MAT、MapReduce模块和后处理MAT。根据这些模块的流水线深度,按比例分配流量。预处理MAT将机器学习数据包转发到MapReduce模块(PHV在该模块中处理),包体被排入相应队列,而非机器学习数据包则直接发送到后处理MAT,不会产生任何额外延迟。此外,数据包的非特征头也按照旁路路径进入后处理MAT,只有必要的特征头作为密集PHV才会进入MapReduce模块(以最小化稀疏数据的出现)。
目标无关的优化。 MapReduce的通用性足以支持与目标无关的优化,即考虑可用执行资源(并行化系数、带宽等)的优化,而不考虑特定硬件的设计细节[128][176]。并行化MapReduce程序在空间上展开循环,如果有足够的硬件资源,一个模型可以在每个周期执行一次迭代。由于循环的展开是在编译时进行的,Taurus可以保证确定性的吞吐量: 要么是线速性能,要么遵循已知系数。在交换机中由于回流[15],或者在数据中心网络中由于链路超额订阅[62][118],原有线速都会以某个静态系数下降。
除了面积之外,由于交换机必须在数百纳秒内转发数据包,因此延迟也限制了交换机级的机器学习。延迟随着深度的增加而增加,所以数据中心SLO有效限制了模型的层数。通过用MAT预处理特征,可以用更少的层数和更少的延迟提供足够的准确性: 模型只需要学习特征间的关系,而不用考虑包头与特征的映射。
依赖目标的编译。 各种编程语言都支持MapReduce[71][109][121][155]。为了支持基于SIMD的结构,我们使用Spatial[88]的修改版对Taurus的MapReduce模块进行编程,Spatial是一种基于并行模式的特定领域语言(DSL),将MapReduce程序表示为一连串嵌套循环,支持与目标相关的优化,也支持与目标无关的Taurus优化。程序被编译成流式数据流图,在这一层次结构中,最内部的循环是一个CU内的SIMD操作,外部循环被映射到多个CU。然后,过大的模式(那些需要太多计算阶段、输入或内存的模式)被分割成适合CU和MU的较小模式,这对于映射具有长基本块(即没有分支的长代码序列)的非线性函数很有必要。最后,得到的图通过MapReduce模块的互连结构进行路由。
5. 演进
5.1. Taurus ASIC分析
我们首先通过分析其功率和面积来检查MapReduce模块(第5.1.1节),然后通过编译几个最近提出的网络机器学习应用来评估其性能(第5.1.2节)。接下来,使用常见的机器学习组件来证明其灵活性,这些组件可以被组成表达各种算法(第5.1.3节)。最后,我们将其与现有的纯MAT的机器学习实现进行比较(第5.1.4节)。
5.1.1. 设计空间探索(Design Space Exploration)
Taurus的MapReduce模块是参数化的,包括精度、通道数和阶段数。我们通过ASIC合成和FreePDK15(一个预测性的15ns标准单元库[12])来估算Taurus的面积和功率,还使用CACTI 7.0[9]来估算存储器面积。为了指导评估,我们最大限度的减少面积、功率和延迟,同时以全模型精度(即无量化损失)和每包吞吐量为目标。
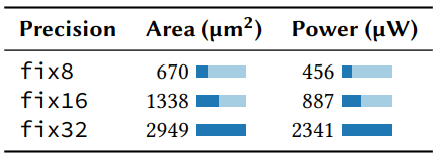
*定点精度。 对于机器学习推理来说,在同等精度下,定点运算比浮点运算要快[67][84]。Taurus使用8位精度,其已经被证明足以用于推理(压缩模型使用的位数更少)[34][100][160]。表3中我们可以看到,对于各种DNN来说,量化误差(使用TensorFlow Lite [61][81])可以忽略不计。最小精度损失和4倍的资源节约(表4)证明我们降低精度的架构是有用的。
![表3. 用于TMC物联网流量分类器的DNN的准确性[145],表明8位量化损失最小。](https://img-blog.csdnimg.cn/img_convert/1cadf6eb330e46fc9ff4f5bbecf4116d.png)
通道数。 理想情况下,一个CU中的通道数与可用的向量(SIMD)并行量相匹配。如果提供的通道太少,一个向量操作将不得不在多个CU之间进行映射,增加所需的控制逻辑,降低了效率。同样,提供超过向量并行量的通道会导致一些通道被闲置,因为CU只能在一个向量上执行操作。图9显示,原始面积效率(每FU的面积)随着通道数量的增加而增加。
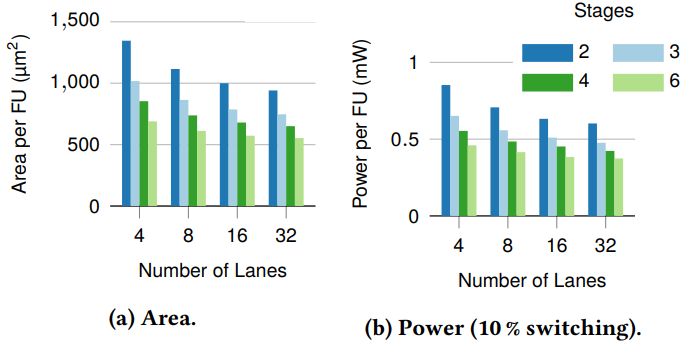
异常检测DNN[153]是需要线速运算的最大模型,所以我们用它来设定理想的通道数。DNN的最大层有12个隐藏单元,因此最大的点积计算涉及12个元素,16通道配置在一个CU内完全展开点积,同时最大限度减少利用率的不足。目前,16通道的配置平衡了面积开销、功率和map效率,但随着数据面机器学习模型的发展,最佳通道数可能会发生变化。由于MapReduce程序与硬件无关,编译器将根据需要处理展开系数的差异(即CU内与跨CU的并行性)。
阶段数。 我们进行了类似研究来量化CU的阶段数对准确性的影响。内积(大多数模型背后的线性运算)使用两个阶段: 一个map(乘法)和一个reduce(加法),而非线性运算使用一连串的map。因此,我们研究阶段数对非线性运算的影响。图10显示了使用不同深度的CU实现各种激活函数所需的总面积(CU数与面积的乘积)。此外,对于浅层激活函数(如ReLU),后面的阶段没有被映射,导致面积随着阶段的增加而增加。理论上,更多的阶段更有效率(图9),并且通过上下文合并可以让编译器映射更复杂的激活函数[177]。然而,内积和ReLU微基准(它们构成了许多普通网络的核心)只受益于两个阶段。因此,我们在最终的ASIC设计中选择了四个计算阶段来支持这两者。
最终ASIC配置。 最终的CU有16个通道、4阶段以及一个8位定点数据路径。包括路由资源[176]在内,需要0.044 (平均每个FU 680 )。每个MU有16组,每组1024个条目,包括路由资源在内消耗0.029 。总的来说,我们提供12×10的网格,CU和MU的比例为3:1,占用4.8 。考虑有4个可重配流水线的交换机,每个流水线有32个MAT,50%的芯片面积被MAT占用[86]。而且,每条流水线增加一个MapReduce模块会使总芯片面积增加3.8%,一个相同面积的设计会使每条流水线减少3个MAT。与我们可以支持的程序类型相比,这是一个可以忽略不计的开销(第5.1.2节)。Taurus的ASIC参数基于目前使用的应用和功能,对于新的模型来说,新的参数可能提供更大的效率。
5.1.2. 应用基准测试(Application Benchmarks)
我们用4个机器学习模型[106][153][168][169]评估Taurus。第一个是物联网流量分类,基于11个特征和5个类别实现了KMeans聚类。第二个是基于SVM[106]的异常检测算法,有8个从KDD数据集[2][36]中选出的输入特征和一个径向基函数来模拟非线性关系。第三个是基于DNN的异常检测算法,需要6个输入特征(也是KDD子集),有12、6和3个隐藏单元的层[153]。最后是基于LSTM的在线拥堵控制算法(Indigo [169]),使用32个LSTM单元和一个softmax层,被设计为在终端主机网卡上运行。虽然Indigo不是按包计算,但其更新间隔明显低于Taurus,从而能够实现更准确的控制决策和更快的反应时间。
面积与功率。 表5显示了相对于现有带有PISA流水线[15]的可编程交换ASIC[5]的面积和功率,只考虑执行有用工作的CU和MU的数量。因此,这些基准测试所用原型的实际面积是最大基准面积,禁用了较小基准的未使用CU。如基于SVM的异常检测这样的简单模型,只有0.2%的面积开销和0.3%的功率开销。因此,我们设定Taurus的MapReduce模块面积为4.8 ,与最近提出的交换结构增加的面积相似(例如,CONGA[4]和Banzai[146]分别消耗2%和12%的额外面积)。如果只支持较小的模型,KMeans、SVM和DNN将只增加约0.8%的面积和0.9%的功率。对于16位和32位的数据路径,面积和功率都将分别增加约2倍和4倍。
[5] 由于台积电的光罩限制为858 [142],64×100 Gb/s交换芯片的尺寸为500-600 。
![表5. 几种应用模型的性能和资源开销。开销是相对于具有4个可重配流水线的500 芯片计算的[65],该系统在以1 GPkt/s线速运行时预计功耗为270W[3][19][114]。](https://img-blog.csdnimg.cn/img_convert/301bf15ee0ff00e404c0810da01d8d13.png)
延迟和吞吐量。 KMeans、SVM和DNN每周期(线速)处理一个数据包头,其延迟保持在纳秒范围内(表5)。假设数据中心交换延迟为1 μs[35],KMeans、SVM和DNN分别增加了6.1%、8.3%和22.1%的延迟。在软件实现中,Indigo LSTM每10毫秒运行一次(可能是受LSTM的计算要求限制),大大改善了应用层的吞吐量和延迟[169]。在Taurus中,Indigo可以每805 ns产生一个决策,从而使得LSTM网络可以对负载的变化做出更快速的反应,并更好的控制尾部延迟,数据旁路也能够避免增加非机器学习数据包的延迟。
5.1.3. 微基准(Microbenchmarks)
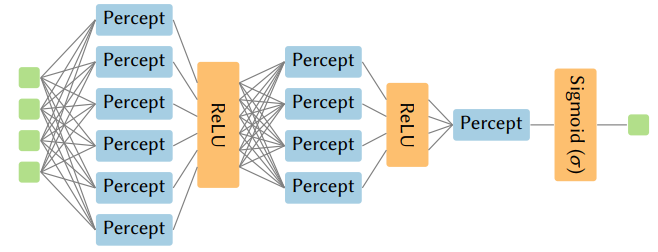
较小的数据流应用可以组成一个大应用,例如,图11显示了由几个(线性)感知器层与非线性激活函数融合而成的DNN。这些微观基准是一般的构建模块,旨在展示可编程的、基于MapReduce的结构的多功能性。线性函数包含reduce网络,能够限制免通信并行的程度。相反,非线性函数由于相邻的数据元素之间没有互动,可以完美实现SIMD并行化。例如,如果16个不同的感知器的输出被输入到ReLU,我们只需将ReLU映射到16个输出上,然后就可以并行计算。表6显示了每个微基准在以线速运行时所需的面积和延迟。
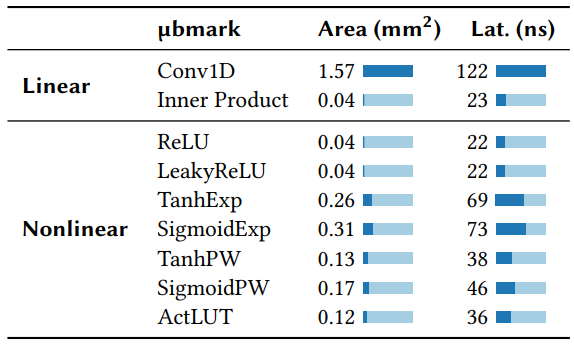
线性运算。 线性微基准是由一个具有8个输出和2个内核维度的一维卷积(经常用于寻找空间或时间上的相关性[94])和一个16元素的内积组成的,构成了感知器神经网络、LSTM和SVM的核心。由于卷积不能很好的映射到向量MapReduce中(有多个小的内积),需要8倍的展开和大量芯片面积。然而,内积只在一个CU中以线速运行,可以被有效组成高性能深度神经网络。一个16通道的CU执行一个MapReduce的最小延迟是5个周期: 1个周期用于map,4个周期用于reduce,每个reduce周期处理不同片段(图8)。其余延迟来自于数据从输入到CU再到输出的移动,Taurus每次移动数据大约需要5个周期,这是空间分布式数据流的结果。
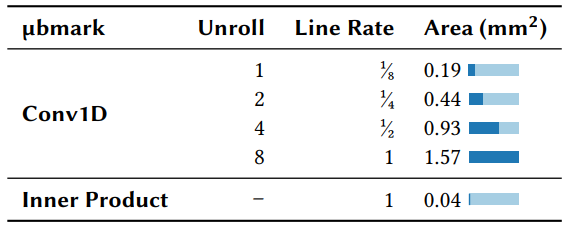
展开(Unrolling)。 基于MapReduce与目标无关的优化,大型机器学习模型可以在多个周期内运行,并相应的降低线速(表7)。展开内循环和外循环将实现更高的吞吐量和更低的延迟,同时消耗更多的面积。然而,并不是所有基准都可以展开其外循环的,例如,内积就没有外循环。迭代(即基于循环的)卷积以1/8的线速运行,展开它以满足线速会导致面积增加8倍。
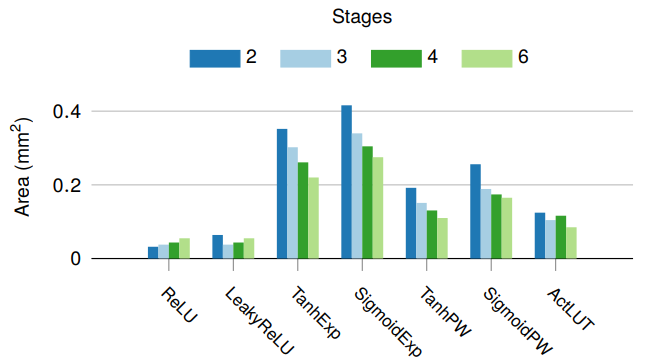
非线性运算。 激活函数对于学习非线性行为是必要的,否则整个神经网络会崩溃成单一线性函数。每个激活函数都有不同的用途: LSTM使用tanh进行门控[73],而DNN使用更简单的ReLU和Leaky ReLU[112]。最有效的函数(ReLU和Leaky ReLU)不需要查找表(LUT, lookup table),只需要CU。更复杂的函数,包括sigmoid和tanh,有几个版本: 泰勒级数(Taylor series)、分片逼近(piecewise approximations)和LUT[67][161],泰勒级数和分片逼近需要2-5倍的面积。基于LUT的函数需要更多内存,每个表通过将预先计算的输出值存储为1024个8位条目来近似模拟激活函数[67][161],即使在复制时,也需要消耗交换内存的一小部分。
5.1.4. 与只有MAT的机器学习设计的比较
正如第5.1.1节所述,最终Taurus ASIC有4条流水线,每条流水线有一个MapReduce模块,消耗了3.8%的额外芯片面积(或者说相当于每个MapReduce模块等价于3个MAT的面积)。相比之下,只有MAT的神经网络(NN)实现[144][168]需要消耗10个MAT。例如,N2Net(一个二进制神经网络实现),每层至少需要12个MAT[144],总共需要48个MAT来支持异常检测DNN[153],而Taurus只需要3个。同样,如果用IIsy框架[168]在MAT上实现非神经网络算法,SVM和KMeans分别消耗8和2个MAT,而相应的Taurus ASIC只需要0.5%的芯片面积(或1个MAT)。N2Net和IIsy都提供了将机器学习算法映射到MAT的独特方法,然而为了使数据面机器学习无处不在,我们需要为网络提供更有效的机器学习硬件。
5.2. 端到端性能
5.2.1. Taurus测试环境
为了评估Taurus的端到端性能,我们使用工业标准的SDN工具、Tofino交换机以及实现了MapReduce模块的FPGA建立了一个测试平台,如图12所示。基于该测试平台,可以看到Taurus以每包为基础进行决策,比传统控制面机器学习解决方案更快,并且具有更大的准确性(第5.2.2节)。
![图12. 用于推理的Taurus测试平台。服务器运行领先的开源软件,即ONOS[46]、XDP[129]、InfluxDB[33],以及使用TensorFlow[1]的控制面推理。Tofino交换机和FPGA分别实现了Taurus的MAT流水线和MapReduce模块。](https://img-blog.csdnimg.cn/img_convert/e3dfbb690bff3ddbedc156e5ed4ac1f7.png)
控制面机器学习: 基线(baseline)。 为了确定比较基线[6],控制面服务器通过10Gbps链接,利用支持XDP的英特尔X710网卡[79] (运行一个84行的自定义XDP/eBPF程序)对遥测数据包进行采样,并将其存储在InfluxDB流数据库中[33]。向量机器学习模型(Keras[64]编写,272行)分批对数据包进行推理,开放网络操作系统(ONOS)[46]将模型结果作为流规则配置在交换机上。
[6] XDP 2.6.32 | Tensorflow/Keras 2.4.0 | InfluxDB 1.7.4 | ONOS 2.2.2 | Stratum/Barefoot SDE 9.2.0 | Xilinx Vivado 2020.2 | Spatial 40d182 | MoonGen 525d991
用户面机器学习: Taurus。 在Taurus中[6],Stratum OS[48]运行在可编程Barefoot Wedge 100BF-32X[116]交换机上,实现Taurus的PISA组件。Tofino交换机的匹配动作流水线实现了Taurus的解析和预处理MAT(172行)。100Gbps以太网链接将交换机连接到Xilinx Alveo U250 FPGA[164],模拟MapReduce硬件。Spatial[88] (105行)和Xilinx OpenNIC Shell[166]将机器学习模型编译到FPGA。为了传输数据包,我们将Xilinx 100G CMAC[167]与AXI流接口[165] (298行)集成到FPGA的MapReduce模块。一旦被FPGA处理,数据包在被转发到网络之前要经过交换机的后处理MAT。最后,用另外两个运行MoonGen[39]的80核英特尔至强服务器来产生和接收流量。
5.2.2. 异常检测案例研究
我们在控制面和数据面实现了机器学习异常检测模型(第3节)。我们从NSL-KDD[36]数据集生成标记的数据包级trace(labeled packet-level trace),方法是将连接级记录扩展为分档的数据包trace(即每个trace元素代表一组数据包),并对其状态进行标记(异常或正常)。从原始trace中取样获取流量大小的分布、混合和数据包头域的变化率,以创造现实的工作负载。我们用这些数据来训练DNN,离线F1得分(典型机器学习指标[157])为71.1。
为了测试数据面机器学习,我们将所有流量发送到交换机和FPGA。交换机使用MAT对特征进行预处理。首先用数据包五元组来索引一组有状态寄存器,这些寄存器积累了整个数据包的特征(例如紧急标志的数量),然后将这些特征格式化为定点数,并将数据包转发到FPGA,由机器学习模型将其标记为异常或正常。然后,数据包返回交换机,后处理MAT基于机器学习决策对包进行处理。
在基线系统中,交换机积累特征并将其作为遥测数据包发送到控制面进行推理。如果该模型确定某个数据包不正常,就会提取相应的IP,并配置一个交换机规则,将其数据包标记为异常。任何在规则安装前通过的数据包都会被(错误的)原样转发。流量以固定的5Gbps发送,而控制面采样从100 kbps ( )到100 Mbps ( )不等。
Taurus对每个包作出响应。 表8显示控制面的毫秒级延迟。即使在低采样率下,基线也有32毫秒的延迟。随着负载增长,批处理的规模也在增长,因为批处理的第一个元素必须等待整个批处理的完成,这又进一步增加了延迟。此外,当实现逐包处理的系统时,机器学习不是瓶颈。相反,表8显示,规则配置和数据包收集使系统不堪重负[7]。

[7] 我们还探索了在交换机CPU而不是在服务器上配置规则,以消除控制器和交换机操作系统之间的RTT。然而,由于交换机CPU性能较差(8个1.6GHz CPU,而服务器有80个2.5GHz CPU),减少的RTT时间被额外的流量规则计算时间所抵消,平均延迟高出112%。
Taurus维持了全部模型的准确性。 大多数异常数据包都没有被基线系统检测到,而Taurus捕获了一半以上(表8)。考虑到被识别的异常情况、遗漏的异常情况和被错误标记为异常的正常数据包的数量[8][153],我们使用F1分数来评估准确性。Taurus实现了与孤立模型相同的F1得分。然而,由于规则配置和其他处理延迟,基线系统错过了很多数据包,因此有效F1得分较低。
5.2.3. 在线训练
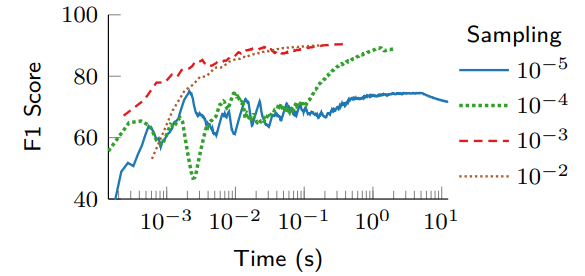
Taurus的机器学习模型也可以被更新以优化全局指标,这对于单个交换机无法观察到的行为(如下游拥堵)很有帮助。我们将遥测数据包送入控制面的训练应用程序,并使用流量规则配置时间作为估计,评估更新数据面模型权重所需的时间。
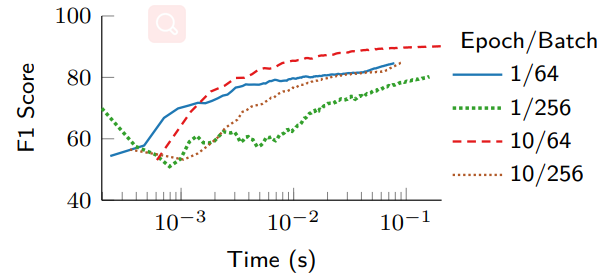
图13显示,更高的采样率(对应更多的批处理数据)收敛速度更快(几十到几百毫秒),表明在线训练是可能的,并切控制面采样数据频率越高越好。此外,图14显示,具有最小批量(64)和最多周期(10)的配置会获得最高的F1分数,并且增加的训练时间被更快的收敛所抵消。因此,较小批量和较大周期会产生较少的但更有意义的更新,从而避免频繁但没有意义的更新。
6. 当前的限制以及未来的工作
虽然Taurus可以比现有平台更有效的支持逐包ML算法,但模型大小仍然受到可用硬件资源的限制。为了适应更大的模型,必须研究模型压缩技术。此外,需要更多研究来提供正确性可证明的模型验证和更快的训练时间。
模型压缩。 Taurus的主要应用是网络控制和协调。神经网络可以解决各种控制问题[10][149][156],而且越来越小。例如,用于非线性控制的结构化控制网[149]的性能几乎与512个神经元的DNN一样好,每层只需要4个神经元。有了这样的小网络,Taurus可以同时运行多个模型(例如,一个模型用于入侵检测,另一个用于流量优化)。此外,像量化(quantization)、修剪(pruning)和蒸馏(distillation)等技术可以进一步减少模型大小[7][69][81][158]。
正确性。 某些应用(如路由)有明确的正确和错误答案,如果没有安全措施,将会很难保证。相反,机器学习最适合于本质上是启发式的应用,如拥塞控制[162][169]、负载均衡[4][85]和异常检测[106][153],其决定只影响网络性能和安全性,而不是其核心的包转发行为。当机器学习决策可能影响网络正确性时,后处理规则可以确保最终决策是有边界的。
训练速度。 最后,对于较大的数据中心网络,训练反应时间可能会更高。这意味着瞬时网络问题(如特定链路上的负载)不能通过训练来处理,因为在训练完成之前,事件可能就已经结束了。相反,训练会逐渐学习是什么导致这些问题以及如何避免这些问题。为了检测和应对具体事件,较低延迟的技术,如INT,反而可以将网络状态作为特征提供给模型。
7. 相关工作
面向机器学习的架构。 现场可编程门阵列(FPGA, Field programmable gate array)是最为广泛使用的可重配架构,既可用作定制加速器[140],也可用作原型(例如NetFPGA[104][113])。然而,FPGA的片上网络消耗了高达70%的芯片总功率[23],而且其可变、缓慢的时钟频率使网络和交换速度(每秒Tb级)操作变得复杂。CGRA为机器学习运算进行了优化,通常有快速、固定的时钟频率,可以和Taurus中的MapReduce模块和MAT进行无缝集成[32][50][58][105][107][143]。其他架构,如Eyeriss[26]、Brainwave[49]和EIE[68],专注于特定算法实现,从而提高效率。这些实现都可用于交换机内机器学习,但过于死板,如果基于特定加速器实现标准化,就有可能由于缺乏灵活的抽象(如MapReduce),使得网络无法从未来的机器学习研究中获益。
面向机器学习的数据面。 在现代数据中心内部,基于MAT的可编程数据面交换机(如Barefoot Tofino[114][115]),允许网络轻松支持、执行不同任务(如重击者检测[148]、负载均衡[85]、安全[93, 175]、快速重路由[74]和调度[147]),而这些任务之前需要通过终端主机服务器、中间件或固定功能交换机实现。最近业界正在努力(N2Net[144]和IIsy[168])研究在交换机上运行更复杂的机器学习算法。然而,仅靠MAT是不适合支持机器学习算法的,为了让数据面机器学习变得无处不在,需要更有效的硬件来减少不必要的资源使用(即面积和功率)。我们相信Taurus是朝着这个方向迈出的第一步。
在数据中心终端主机上,现代智能网卡(和网络加速器)为服务器提供了更高的计算能力,不仅可以卸载数据包处理逻辑,还可以处理特定应用逻辑,以实现更低的延迟和更高的吞吐量。像英特尔的基础设施单元(IPU, Infrastructure Unit)[80]、英伟达的数据处理单元(DPU, Data Processing Unit)[120]和基于FPGA的智能网卡[44, 164]等产品都旨在加速各种终端主机工作负载(例如,管理程序、虚拟交换、基于批处理的机器学习训练和推理、存储)。然而,这些智能网卡并不适合需要在数据中心全网范围内进行的逐包操作。数据包仍然需要从交换机访问服务器(和网卡),从而导致从收到数据包到交换机上的应用做出相应决策之间有一个RTT的延迟。中间件在其固定功能硬件实现上也有类似的问题,从而限制了灵活性并促使其频繁升级[141]。
面向网络的机器学习。 许多网络应用可以从机器学习中受益。例如,拥塞控制学习算法[162][169]已被证明优于人类设计的同类算法[37][66][171]。此外,Boutaba等人[17]确定了网络任务的机器学习用例,如流量分类[40][41]、流量预测[24][27]、主动队列管理[151][179]和安全[124]。所有这些应用都可以立即基于Taurus进行部署。
面向机器学习的网络。 特定的网络也可以加速机器学习算法本身。通过对现代数据面硬件的细微改进,交换机可以在网络中聚合梯度,将训练速度提高300%[51][92][137]。Gaia(一个用于分布式机器学习的系统[76])也考虑了广域网络带宽并在训练过程中调节梯度的移动。虽然Taurus没有明确为分布式训练加速而设计,但MapReduce可以比MAT更有效的聚合包含在数据包中的数字化权重。
8. 结论
目前,数据中心网络被划分为线速网络、逐包数据面和较慢的控制面,其中控制面运行复杂的、数据驱动的管理策略来配置数据面。这种方法太慢了,控制面的传输增加了不可避免的延迟,因此控制面无法对网络事件做出足够快的反应。Taurus把复杂决策放到数据面,降低反应时间,并提高了管理和控制策略的特殊性。我们证明,Taurus可以线速运行,并在可编程交换机流水线(RMT)上增加了很小的开销(3.8%的面积和122 ns的平均延迟),同时可以加速最近提出的几个机器学习网络基准测试。
展望未来,为了实现自动驾驶网络(self-driving network, 又称自智网络),必须在大规模训练开始之前部署硬件。我们相信,Taurus为网内机器学习提供了一个立足点,其硬件可以安装在下一代数据平面上,以提高性能和安全性。
A. 附录
A.1. 概要
该工件包含文中提出的Taurus的MapReduce模块(第3.3节)和端到端性能评估中使用的异常检测(AD)应用程序(第5.2节)的源代码。MapReduce模块与Xilinx OpenNIC Shell[166]集成,并通过称为Spatial[88]的高级DSL进行编程。AD应用程序在端到端测试平台上运行,由各种组件组成: P4程序、Python脚本、ONOS应用和Spatial代码(第5.2.2节)。
A.2. 范围
该工件包含两个新组件: MapReduce模块和异常检测代码,目标是提供实现完整测试平台(第5.2节)所需的两个缺失组件,以运行端到端性能评估。其余组件是现有的专用硬件(Barefoot Tofino Switch [114], Xilinx Alveo Board [164])和软件代码库(P4 [14], ONOS [46], Spatial [88], 等等)的集合,可以随时购买和下载(请见下文的依赖关系)[8]。
[8] 我们希望用户购买所需硬件,并获得必要的工具和许可证的个人访问权,因此在工件中不包含这些组件的设置。
A.3. 内容
-
FPGA中的MapReduce模块。 该资源库包含了构建基于FPGA的MapReduce模块实现的源代码和说明。在FPGA上运行MapReduce模块的详细文档在这里提供: https://gitlab.com/dataplane-ai/taurus/mapreduce。
-
异常检测应用。 该资源库含有异常检测应用(AD)的源代码(P4、Python、ONOS、Spatial)。此外还提供了复制用于评估AD应用的端到端测试平台所需的细节。对AD应用的介绍在这里: https://gitlab.com/dataplane-ai/taurus/applications/anomalydetection-asplos22。
A.4. 托管
源代码托管在GitLab[9]和figshare[10]上。
[9] https://gitlab.com/dataplane-ai/taurus
[10] https://doi.org/10.6084/m9.figshare.17097524
A.5. 依赖
该工件依赖于以下第三方硬件和软件工具:
-
EdgeCore Wedge 100BF-32X Switch [1] -
Xilinx Alveo U250 FPGA board [2] -
Intel P4 Studio [3] -
Xilinx Vivado Design Tool [4] -
Xilinx OpenNIC Shell [5] -
Spatial DSL [6] -
ONF Stratum OS [7] -
ONF Open Network Operating System (ONOS) [8] -
MoonGen Traffic Generator [9]
参考文献
[1] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. 2016. Tensorflow: A System For Large-Scale Machine Learning. In USENIX OSDI ’16.
[2] Preeti Aggarwal and Sudhir Kumar Sharma. 2015. Analysis of KDD Dataset Attributes-Class Wise For Intrusion Detection. Computer Science 57 (2015), 842–851. https://doi.org/10.1016/j.procs.2015.07.490
[3] Anurag Agrawal and Changhoon Kim. 2020. Intel Tofino2 – A 12.9Tbps P4-Programmable Ethernet Switch. In Hot Chips ’20.
[4] Mohammad Alizadeh, Tom Edsall, Sarang Dharmapurikar, Ramanan Vaidyanathan, Kevin Chu, Andy Fingerhut, Vinh The Lam, Francis Matus, Rong Pan, Navindra Yadav, and George Varghese. 2014. CONGA: Distributed Congestion-aware Load Balancing for Datacenters. In ACM SIGCOMM ’14. https://doi.org/10.1145/2619239.2626316
[5] Mohammad Alizadeh, Albert Greenberg, David A Maltz, Jitendra Padhye, Parveen Patel, Balaji Prabhakar, Sudipta Sengupta, and Murari Sridharan. 2010. Data Center TCP (DCTCP). In ACM SIGCOMM ’10. https://doi.org/10.1145/1851182.1851192
[6] Tom Auld, Andrew W Moore, and Stephen F Gull. 2007. Bayesian Neural Networks For Internet Traffic Classification. IEEE Transactions on Neural Networks ’07 18, 1 (2007), 223–239. https://doi.org/10.1109/TNN.2006.883010
[7] Jimmy Ba and Rich Caruana. 2014. Do Deep Nets Really Need to be Deep?. In NeurIPS ’14.
[8] Jarrod Bakker, Bryan Ng, Winston KG Seah, and Adrian Pekar. 2019. Traffic Classification with Machine Learning in a Live Network. In 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM) ’19.
[9] Rajeev Balasubramonian, Andrew B Kahng, Naveen Muralimanohar, Ali Shafiee, and Vaishnav Srinivas. 2017. CACTI 7: New tools for interconnect exploration in innovative off-chip memories. ACM Transactions on Architecture and Code Optimization (TACO ’17) 14, 2 (2017), 1–25. https://doi.org/10.1145/3085572
[10] Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. 2013. The Arcade Learning Environment: An Evaluation Platform for General Agents. Journal of Artificial Intelligence Research (JAIR) 47 (2013), 253–279.
[11] Laurent Bernaille, Renata Teixeira, Ismael Akodkenou, Augustin Soule, and Kave Salamatian. 2006. Traffic Classification on the Fly. ACM SIGCOMM Computer Communication Review (CCR) 36, 2 (2006), 23–26. https://doi.org/10.1145/1129582.1129589
[12] Kirti Bhanushali and W Rhett Davis. 2015. FreePDK15: An open-source predictive process design kit for 15nm FinFET technology. In Proceedings of the 2015 Symposium on International Symposium on Physical Design. 165–170. https://doi.org/10.1145/2717764.2717782
[13] Pat Bosshart, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown, Jennifer Rexford, Cole Schlesinger, Dan Talayco, Amin Vahdat, George Varghese, et al. 2014. P4: Programming protocol-independent packet processors. ACM SIGCOMM Computer Communication Review 44, 3 (2014), 87–95. https://doi.org/10.1145/2656877.2656890
[14] Pat Bosshart, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown, Jennifer Rexford, Cole Schlesinger, Dan Talayco, Amin Vahdat, George Varghese, et al. 2014. P4: Programming Protocol-Independent Packet Processors. ACM SIGCOMM Computer Communication Review (CCR) 44, 3 (2014), 87–95. https://doi.org/10.1145/2656877.2656890
[15] Pat Bosshart, Glen Gibb, Hun-Seok Kim, George Varghese, Nick McKeown, Martin Izzard, Fernando Mujica, and Mark Horowitz. 2013. Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN. In ACM SIGCOMM ’13. https://doi.org/10.1145/2534169.2486011
[16] Leon Bottou. 2010. Feature Engineering. https://www.cs.princeton.edu/ courses/archive/spring10/cos424/slides/18-feat.pdf. Accessed on 08/12/2021.
[17] Raouf Boutaba, Mohammad A Salahuddin, Noura Limam, Sara Ayoubi, Nashid Shahriar, Felipe Estrada-Solano, and Oscar M Caicedo. 2018. A Comprehensive Survey on Machine Learning for Networking: Evolution, Applications and Research Opportunities. Journal of Internet Services and Applications (JISA) 9, 1 (2018), 16. https://doi.org/10.1186/s13174-018-0087-2
[18] Andrey Brito, Andre Martin, Thomas Knauth, Stephan Creutz, Diogo Becker, Stefan Weigert, and Christof Fetzer. 2011. Scalable and Low-Latency Data Processing with Stream MapReduce. In IEEE CLOUDCOM ’11. https://doi.org/10.1109/CloudCom.2011.17
[19] Broadcom. [n.d.]. Tomahawk/BCM56960 Series. https://www.broadcom.com/products/ethernet-connectivity/switching/strataxgs/bcm56960-series. Accessed on 08/12/2021.
[20] Kevin J Brown, HyoukJoong Lee, Tiark Romp, Arvind K Sujeeth, Christopher De Sa, Christopher Aberger, and Kunle Olukotun. 2016. Have Abstraction and Eat Performance, too: Optimized Heterogeneous Computing with Parallel Patterns. In IEEE/ACM CGO ’16. https://doi.org/10.1145/2854038.2854042
[21] Kevin J Brown, Arvind K Sujeeth, Hyouk Joong Lee, Tiark Rompf, Hassan Chafi, Martin Odersky, and Kunle Olukotun. 2011. A Heterogeneous Parallel Framework for Domain-Specific Languages. In IEEE PACT ’11. https://doi.org/10.1109/PACT.2011.15
[22] Douglas Ronald Burdick, Amol Ghoting, Rajasekar Krishnamurthy, Edwin Peter Dawson Pednault, Berthold Reinwald, Vikas Sindhwani, Shirish Tatikonda, Yuanyuan Tian, and Shivakumar Vaithyanathan. 2013. Systems and methods for processing machine learning algorithms in a MapReduce environment. US Patent 8,612,368.
[23] Benton Highsmith Calhoun, Joseph F Ryan, Sudhanshu Khanna, Mateja Putic, and John Lach. 2010. Flexible Circuits and Architectures for Ultralow Power. Proc. IEEE 98, 2 (2010), 267–282.
[24] Samira Chabaa, Abdelouhab Zeroual, and Jilali Antari. 2010. Identification and Prediction of Internet Traffic Using Artificial Neural Networks. Journal of Intelligent Learning Systems and Applications (JILSA) 2, 03 (2010), 147. https://doi.org/10.4236/jilsa.2010.23018
[25] Huan Chen and Theophilus Benson. 2017. The Case for Making Tight Control Plane Latency Guarantees in SDN Switches. In ACM SOSR ’17. https://doi.org/10.1145/3050220.3050237
[26] Yu-Hsin Chen, Tushar Krishna, Joel S Emer, and Vivienne Sze. 2016. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE Journal of Solid-State Circuits 52, 1 (2016), 127–138. https://doi.org/10.1109/JSSC.2016.2616357
[27] Zhitang Chen, Jiayao Wen, and Yanhui Geng. 2016. Predicting Future Traffic Using Hidden Markov Models. In IEEE ICNP ’16.
[28] Cheng-Tao Chu, Sang K Kim, Yi-An Lin, YuanYuan Yu, Gary Bradski, Kunle Olukotun, and Andrew Y Ng. 2007. Map-Reduce for Machine Learning on Multicore. In NeurIPS ’07. 281–288.
[29] Cisco Systems, Inc. [n.d.]. Cisco Meraki (MX450): Powerful Security and SD-WAN for the Branch & Campus. https://meraki.cisco.com/products/appliances/mx450. Accessed on 08/12/2021.
[30] Graham Cormode and Shan Muthukrishnan. 2005. An Improved Data Stream Summary: The Count-Min Sketch and its Applications. Journal of Algorithms 55, 1 (2005), 58–75. https://doi.org/10.1016/j.jalgor.2003.12.001
[31] Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for Youtube Recommendations. In ACM RecSys ’16. https://doi.org/10.1145/2959100.2959190
[32] Darren C Cronquist, Chris Fisher, Miguel Figueroa, Paul Franklin, and Carl Ebeling. 1999. Architecture Design of Reconfigurable Pipelined Datapaths. In IEEE ARVLSI ’99.
[33] Influx Data. [n.d.]. InfluxDB. https://www.influxdata.com/products/influxdboverview/. Accessed on 08/12/2021.
[34] Christopher De Sa, Megan Leszczynski, Jian Zhang, Alana Marzoev, Christopher R Aberger, Kunle Olukotun, and Christopher Ré. 2018. High-Accuracy Low-Precision Training. arXiv preprint arXiv:1803.03383 (2018).
[35] Dell EMC. [n.d.]. Data Center Switching Quick Reference Guide. https://i.dell.com/sites/doccontent/shared-content/datasheets/en/Documents/Dell-Networking-Data-Center-Quick-ReferenceGuide.pdf. Accessed on 08/12/2021.
[36] L Dhanabal and SP Shantharajah. 2015. A Study on NSL-KDD Dataset for Intrusion Detection System Based on Classification Algorithms. International Journal of Advanced Research in Computer and Communication Engineering (IJARCCE) 4, 6 (2015), 446–452. https://doi.org/10.17148/IJARCCE.2015.4696
[37] Mo Dong, Qingxi Li, Doron Zarchy, P Brighten Godfrey, and Michael Schapira. 2015. PCC: Re-architecting Congestion Control for Consistent High Performance. In USENIX NSDI ’15.
[38] DPDK. [n.d.]. DPDK. https://www.dpdk.org/. Accessed on 08/12/2021.
[39] Paul Emmerich, Sebastian Gallenmüller, Daniel Raumer, Florian Wohlfart, and Georg Carle. 2015. Moongen: A Scriptable High-Speed Packet Generator. In ACM IMC ’15.
[40] Jeffrey Erman, Martin Arlitt, and Anirban Mahanti. 2006. Traffic Classification Using Clustering Algorithms. In ACM MineNet ’06. https://doi.org/10.1145/1162678.1162679
[41] Jeffrey Erman, Anirban Mahanti, Martin Arlitt, and Carey Williamson. 2007. Identifying and Discriminating Between Web and Peer-to-Peer Traffic in the Network Core. In WWW ’07. https://doi.org/10.1145/1242572.1242692
[42] Alice Este, Francesco Gringoli, and Luca Salgarelli. 2009. Support Vector Machines For TCP Traffic Classification. Computer Networks 53, 14 (2009), 2476–2490. https://doi.org/10.1016/j.comnet.2009.05.003
[43] Nick Feamster and Jennifer Rexford. 2018. Why (and How) Networks Should Run Themselves. In ACM ANRW ’18.
[44] Daniel Firestone, Andrew Putnam, Sambhrama Mundkur, Derek Chiou, Alireza Dabagh, Mike Andrewartha, Hari Angepat, Vivek Bhanu, Adrian Caulfield, Eric Chung, et al. 2018. Azure Accelerated Networking: SmartNICs in the Public Cloud. In USENIX NSDI ’18.
[45] Sally Floyd and Van Jacobson. 1993. Random early detection gateways for congestion avoidance. IEEE/ACM Transactions on networking 1, 4 (1993), 397–413.
[46] Open Networking Foundation. [n.d.]. ONOS: Open Network Operating System. https://www.opennetworking.org/onos/. Accessed on 08/12/2021.
[47] Open Networking Foundation. [n.d.]. ONOS: Single Bench Flow Latency Test. https://wiki.onosproject.org/display/ONOS/2.2%3A+Experiment+I+-+Single+Bench+Flow+Latency+Test. Accessed on 08/12/2021.
[48] Open Networking Foundation. [n.d.]. Stratum OS. https://www.opennetworking.org/stratum/. Accessed on 08/12/2021.
[49] Jeremy Fowers, Kalin Ovtcharov, Michael Papamichael, Todd Massengill, Ming Liu, Daniel Lo, Shlomi Alkalay, Michael Haselman, Logan Adams, Mahdi Ghandi, et al. 2018. A Configurable Cloud-Scale DNN Processor for Real-Time AI. In IEEE ISCA ’18. https://doi.org/10.1109/ISCA.2018.00012
[50] Mingyu Gao and Christos Kozyrakis. 2016. HRL: Efficient and Flexible Reconfigurable Logic for Near-Data Processing. In IEEE HPCA ’16.
[51] Nadeen Gebara, Manya Ghobadi, and Paolo Costa. 2021. In-network Aggregation for Shared Machine Learning Clusters. In MLSys ’21.
[52] Yilong Geng, Shiyu Liu, Feiran Wang, Zi Yin, Balaji Prabhakar, and Mendel Rosenblum. 2017. Self-Programming Networks: Architecture and Algorithms. In IEEE Allerton ’17.
[53] Yilong Geng, Shiyu Liu, Zi Yin, Ashish Naik, Balaji Prabhakar, Mendel Rosenblum, and Amin Vahdat. 2019. SIMON: A Simple and Scalable Method for Sensing, Inference and Measurement in Data Center Networks. In USENIX NSDI ’19.
[54] Amol Ghoting, Prabhanjan Kambadur, Edwin Pednault, and Ramakrishnan Kannan. 2011. NIMBLE: A Toolkit for the Implementation of Parallel Data Mining and Machine Learning Algorithms on MapReduce. In ACM SIGKDD KDD ’11. https://doi.org/10.1145/2020408.2020464
[55] Amol Ghoting, Rajasekar Krishnamurthy, Edwin Pednault, Berthold Reinwald, Vikas Sindhwani, Shirish Tatikonda, Yuanyuan Tian, and Shivakumar Vaithyanathan. 2011. SystemML: Declarative Machine Learning on MapReduce. In IEEE ICDE ’11.
[56] Glen Gibb, George Varghese, Mark Horowitz, and Nick McKeown. 2013. Design principles for packet parsers. In ACM/IEE ANCS ’13. https://doi.org/10.1109/ANCS.2013.6665172
[57] Dan Gillick, Arlo Faria, and John DeNero. 2006. MapReduce: Distributed Computing for Machine Learning. Berkley, Dec 18 (2006).
[58] Seth Copen Goldstein, Herman Schmit, Mihai Budiu, Srihari Cadambi, Matthew Moe, and R Reed Taylor. 2000. PipeRench: A Reconfigurable Architecture and Compiler. Computer 33, 4 (2000), 70–77.
[59] Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio. 2016. Deep Learning. Vol. 1. MIT Press, Cambridge.
[60] Google. [n.d.]. A look inside Google’s Data Center Networks. https://-cloudplatform.googleblog.com/2015/06/A-Look-Inside-Googles-Data-CenterNetworks.html. Accessed on 08/12/2021.
[61] Google. 2021. Tensorflow Lite. https://www.tensorflow.org/tflite.
[62] Albert Greenberg, James R. Hamilton, Navendu Jain, Srikanth Kandula, Changhoon Kim, Parantap Lahiri, David A. Maltz, Parveen Patel, and Sudipta Sengupta. 2009. VL2: A Scalable and Flexible Data Center Network. In ACM SIGCOMM ’09. https://doi.org/10.1145/1592568.1592576
[63] P4.org Archictecture Working Group. 2018. P4-16 Portable Switch Architecture. https://p4.org/p4-spec/docs/PSA-v1.1.0.pdf.
[64] Antonio Gulli and Sujit Pal. 2017. Deep learning with Keras. Packt Publishing Ltd.
[65] Vladimir Gurevich. 2018. Programmable Data Plane at Terabit Speeds. https://p4.org/assets/p4_d2_2017_programmable_data_plane_at_terabit_-speeds.pdf. Accessed on 08/12/2021.
[66] Sangtae Ha, Injong Rhee, and Lisong Xu. 2008. CUBIC: A New TCP-Friendly High-Speed TCP Variant. ACM SIGOPS Operating Systems Review 42, 5 (2008), 64–74. https://doi.org/10.1145/1400097.1400105
[67] Song Han, Junlong Kang, Huizi Mao, Yiming Hu, Xin Li, Yubin Li, Dongliang Xie, Hong Luo, Song Yao, Yu Wang, et al. 2017. ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA. In ACM/SIGDA FPGA ’17. https://doi.org/10.1145/3020078.3021745
[68] Song Han, Xingyu Liu, Huizi Mao, Jing Pu, Ardavan Pedram, Mark A Horowitz, and William J Dally. 2016. EIE: Efficient Inference Engine on Compressed Deep Neural Network. In ACM/IEEE ISCA ’16. https://doi.org/10.1145/3007787.3001163
[69] Song Han, Jeff Pool, John Tran, and William Dally. 2015. Learning Both Weights and Connections for Efficient Neural Network. In NeurIPS ’15.
[70] B Hariri and N Sadati. 2007. NN-RED: an AQM mechanism based on neural networks. Electronics Letters 43, 19 (2007), 1053–1055. https://doi.org/10.1049/el:20071791
[71] Robert Harper, David MacQueen, and Robin Milner. 1986. Standard ML. Department of Computer Science, University of Edinburgh.
[72] Marti A. Hearst, Susan T Dumais, Edgar Osuna, John Platt, and Bernhard Scholkopf. 1998. Support Vector Machines (SVMs). IEEE Intelligent Systems and their Applications 13, 4 (1998), 18–28.
[73] Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory (LSTM). Neural Computation 9, 8 (1997), 1735–1780.
[74] Thomas Holterbach, Edgar Costa Molero, Maria Apostolaki, Alberto Dainotti, Stefano Vissicchio, and Laurent Vanbever. 2019. Blink: Fast Connectivity Recovery Entirely in the Data Plane. In USENIX NSDI ’19.
[75] Kurt Hornik. 1991. Approximation capabilities of multilayer feedforward networks. Neural networks 4, 2 (1991), 251–257. https://doi.org/10.1016/0893-6080(91)90009-T
[76] Kevin Hsieh, Aaron Harlap, Nandita Vijaykumar, Dimitris Konomis, Gregory R Ganger, Phillip B Gibbons, and Onur Mutlu. 2017. Gaia: Geo-Distributed Machine Learning Approaching LAN Speeds. In USENIX NSDI ’17.
[77] Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R Lorch, Yingnong Dang, Murali Chintalapati, and Randolph Yao. 2017. Gray Failure: The Achilles’ Heel of Cloud-Scale Systems. In ACM HotOS ’17. https://doi.org/10.1145/3102980.3103005
[78] Intel. [n.d.]. Intel Deep Insight Network Analytics Software. https://www.intel.com/content/www/us/en/products/network-io/programmable-ethernetswitch/network-analytics/deep-insight.html. Accessed on 08/12/2021.
[79] Intel. [n.d.]. Intel® Ethernet Network Adapter X710-DA2 for OCP 3.0. https://ark.intel.com/content/www/us/en/ark/products/184822/intelethernet-network-adapter-x710-da4-for-ocp-3-0.html. Accessed on 08/12/2021.
[80] Intel. 2021. Intel Infrastructure Processing Unit (Intel IPU) and SmartNICs. https://www.intel.com/content/www/us/en/products/network-io/smartnic.html.
[81] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In IEEE CVPR ’18.
[82] Nathan Jay, Noga Rotman, Brighten Godfrey, Michael Schapira, and Aviv Tamar. 2019. A deep reinforcement learning perspective on internet congestion control. In ICML ’19.
[83] Eun Young Jeong, Shinae Woo, Muhammad Jamshed, Haewon Jeong, Sunghwan Ihm, Dongsu Han, and KyoungSoo Park. 2014. MTCP: A Highly Scalable UserLevel TCP Stack for Multicore Systems. In USENIX NSDI ’14.
[84] Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. 2017. In-Datacenter Performance Analysis of a Tensor Processing Unit. In IEEE ISCA ’17. https://doi.org/10.1145/3079856.3080246
[85] Naga Katta, Mukesh Hira, Changhoon Kim, Anirudh Sivaraman, and Jennifer Rexford. 2016. HULA: Scalable Load Balancing Using Programmable Data Planes. In ACM SOSR ’16. https://doi.org/10.1145/2890955.2890968
[86] Changhoon Kim. [n.d.]. Programming The Network Data Plane: What, How, and Why? https://conferences.sigcomm.org/ events/apnet2017/slides/chang.pdf. Accessed on 08/12/2021.
[87] Changhoon Kim, Anirudh Sivaraman, Naga Katta, Antonin Bas, Advait Dixit, and Lawrence J Wobker. 2015. In-Band Network Telemetry via Programmable Dataplanes. In ACM SIGCOMM ’15 (Demo).
[88] David Koeplinger, Matthew Feldman, Raghu Prabhakar, Yaqi Zhang, Stefan Hadjis, Ruben Fiszel, Tian Zhao, Luigi Nardi, Ardavan Pedram, Christos Kozyrakis, and Kunle Olukotun. 2018. Spatial: A Language and Compiler for Application Accelerators. In ACM/SIGPLAN PLDI ’18. https://doi.org/10.1145/3192366.3192379
[89] Vibhore Kumar, Henrique Andrade, Buğra Gedik, and Kun-Lung Wu. 2010. DEDUCE: At the Intersection of MapReduce and Stream Processing. In ACM EDBT ’10. https://doi.org/10.1145/1739041.1739120
[90] Maciej Kuźniar, Peter Perešíni, and Dejan Kostić. 2015. What You Need to Know About SDN Flow Tables. In PAM ’15. Springer.
[91] Adam Langley, Alistair Riddoch, Alyssa Wilk, Antonio Vicente, Charles Krasic, Dan Zhang, Fan Yang, Fedor Kouranov, Ian Swett, Janardhan Iyengar, et al. 2017.
The QUIC Transport Protocol: Design and Internet-Scale Deployment. In ACM SIGCOMM ’17. https://doi.org/10.1145/3098822.3098842
[92] ChonLam Lao, Yanfang Le, Kshiteej Mahajan, Yixi Chen, Wenfei Wu, Aditya Akella, and Michael M Swift. 2021. ATP: In-network Aggregation for Multitenant Learning. In NSDI ’21.
[93] Ângelo Cardoso Lapolli, Jonatas Adilson Marques, and Luciano Paschoal Gaspary. 2019. Offloading real-time ddos attack detection to programmable data planes. In 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM) ’19. IEEE, 19–27.
[94] Yann LeCun, LD Jackel, Leon Bottou, A Brunot, Corinna Cortes, JS Denker, Harris Drucker, I Guyon, UA Muller, Eduard Sackinger, P Simard, and V Vapnik. 1995. Comparison of Learning Algorithms for Handwritten Digit Recognition. In ICANN ’95.
[95] Guanyu Li, Menghao Zhang, Shicheng Wang, Chang Liu, Mingwei Xu, Ang Chen, Hongxin Hu, Guofei Gu, Qi Li, and Jianping Wu. 2021. Enabling Performant, Flexible and Cost-Efficient DDoS Defense With Programmable Switches. IEEE/ACM Transactions on Networking ’21 (2021). https://doi.org/10.1109/TNET.2021.3062621
[96] Ruey-Hsia Li and Geneva G. Belford. 2002. Instability of Decision Tree Classification Algorithms. In ACM SIGKDD ’02. https://doi.org/10.1145/775047.775131
[97] Youjie Li, Iou-Jen Liu, Yifan Yuan, Deming Chen, Alexander Schwing, and Jian Huang. 2019. Accelerating Distributed Reinforcement Learning with In-Switch Computing. In ACM/IEEE ISCA ’19. https://doi.org/10.1145/3307650.3322259
[98] Yuliang Li, Rui Miao, Hongqiang Harry Liu, Yan Zhuang, Fei Feng, Lingbo Tang, Zheng Cao, Ming Zhang, Frank Kelly, Mohammad Alizadeh, and Minlan Yu. 2019. HPCC: High Precision Congestion Control. In ACM SIGCOMM ’19. https://doi.org/10.1145/3341302.3342085
[99] Eric Liang, Hang Zhu, Xin Jin, and Ion Stoica. 2019. Neural Packet Classification. In ACM SIGCOMM ’19. https://doi.org/10.1145/3341302.3342221
[100] Darryl Lin, Sachin Talathi, and Sreekanth Annapureddy. 2016. Fixed Point Quantization of Deep Convolutional Networks. In ICML ’16.
[101] Yingqiu Liu, Wei Li, and Yun-Chun Li. 2007. Network Traffic Classification Using K-Means Clustering. In IEEE IMSCCS ’07. https://doi.org/10.1109/IMSCCS.2007.52
[102] Zaoxing Liu, Hun Namkung, Georgios Nikolaidis, Jeongkeun Lee, Changhoon Kim, Xin Jin, Vladimir Braverman, Minlan Yu, and Vyas Sekar. 2021. Jaqen: A High-Performance Switch-Native Approach for Detecting and Mitigating Volumetric DDoS Attacks with Programmable Switches. In USENIX Security ’21.
[103] Loadbalancer.org. [n.d.]. Hardware ADC. https://www.loadbalancer.org/products/hardware/. Accessed on 08/12/2021.
[104] John W Lockwood, Nick McKeown, Greg Watson, Glen Gibb, Paul Hartke, Jad Naous, Ramanan Raghuraman, and Jianying Luo. 2007. NetFPGA: An Open Platform for Gigabit-Rate Network Switching and Routing. In IEEE MSE ’07.
[105] Alan Marshall, Tony Stansfield, Igor Kostarnov, Jean Vuillemin, and Brad Hutchings. 1999. A Reconfigurable Arithmetic Array for Multimedia Applications. In IEEE FPGA ’99. https://doi.org/10.1145/296399.296444
[106] Tahir Mehmood and Helmi B Md Rais. 2015. SVM for Network Anomaly Detection using ACO Feature Subset. In IEEE iSMSC ’15.
[107] Bingfeng Mei, Serge Vernalde, Diederik Verkest, Hugo De Man, and Rudy Lauwereins. 2002. DRESC: A Retargetable Compiler for Coarse-Grained Reconfigurable Architectures. In IEEE FPT ’02.
[108] Albert Mestres, Alberto Rodriguez-Natal, Josep Carner, Pere Barlet-Ros, Eduard Alarcón, Marc Solé, Victor Muntés-Mulero, David Meyer, Sharon Barkai, Mike J Hibbett, et al. 2017. Knowledge-Defined Networking. ACM SIGCOMM Computer Communication Review (CCR) 47, 3 (2017), 2–10. https://doi.org/10.1145/3138808.3138810
[109] Yaron Minsky, Anil Madhavapeddy, and Jason Hickey. 2013. Real World OCaml: Functional Programming for the Masses. O’Reilly Media, Inc.
[110] Andrew W Moore and Denis Zuev. 2005. Internet Traffic Classification using Bayesian Analysis Techniques. In ACM SIGMETRICS ’05. https://doi.org/10.1145/1064212.1064220
[111] Manya Ghobadi Nadeen Gebara, Paolo Costa. 2021. In-Network Aggregation for Shared Machine Learning Clusters. In MlSys.
[112] Vinod Nair and Geoffrey E Hinton. 2010. Rectified Linear Units Improve Restricted Boltzmann Machines. In ICML ’10.
[113] NetFPGA. [n.d.]. NetFPGA: A Line-rate, Flexible, and Open Platform for Research and Classroom Experimentation. https://netfpga.org/. Accessed on 08/12/2021.
[114] Barefoot Networks. [n.d.]. Barefoot Tofino. https://www.intel.com/content/www/us/en/products/network-io/programmable-ethernet-switch/tofinoseries.html. Accessed on 08/12/2021.
[115] Barefoot Networks. [n.d.]. Barefoot Tofino 2. https://www.intel.com/content/www/us/en/products/network-io/programmable-ethernet-switch/tofino2-series.html. Accessed on 08/12/2021.
[116] Edgecore Networks. [n.d.]. WEDGE 100BF-32X: 100GBE Data Center Switch. https://www.edge-core.com/productsInfo.php?cls=1&cls2=5& cls3=181&id=335. Accessed on 08/12/2021.
[117] Rolf Neugebauer, Gianni Antichi, José Fernando Zazo, Yury Audzevich, Sergio López-Buedo, and Andrew W. Moore. 2018. Understanding PCIe Performance for End Host Networking. In ACM SIGCOMM ’18. https://doi.org/10.1145/3230543.3230560
[118] Radhika Niranjan Mysore, Andreas Pamboris, Nathan Farrington, Nelson Huang, Pardis Miri, Sivasankar Radhakrishnan, Vikram Subramanya, and Amin Vahdat. 2009. PortLand: A Scalable Fault-tolerant Layer 2 Data Center Network Fabric. In ACM SIGCOMM ’09. https://doi.org/10.1145/1592568.1592575
[119] NVIDIA. [n.d.]. Tesla T4. https://www.nvidia.com/en-us/data-center/tesla-t4/. Accessed on 08/12/2021.
[120] NVidia. 2021. NVIDIA BLUEFIELD DATA PROCESSING UNITS. https://www.nvidia.com/en-us/networking/products/data-processing-unit/.
[121] Martin Odersky, Lex Spoon, and Bill Venners. 2008. Programming in Scala. Artima Inc.
[122] P4.org. 2020. P4-16 Language Specification. https://p4.org/p4-spec/docs/P4-16-v1.2.1.pdf.
[123] Junghun Park, Hsiao-Rong Tyan, and C-C Jay Kuo. 2006. Internet Traffic Classification for Scalable QoS Provision. In IEEE ICME ’06.
[124] Roberto Perdisci, Davide Ariu, Prahlad Fogla, Giorgio Giacinto, and Wenke Lee. 2009. McPAD: A Multiple Classifier System for Accurate Payload-Based Anomaly Detection. Computer Networks 53, 6 (2009), 864–881. https://doi.org/10.1016/j.comnet.2008.11.011
[125] Dan RK Ports and Jacob Nelson. 2019. When Should The Network Be The Computer?. In ACM HotOS ’19. https://doi.org/10.1145/3317550.3321439
[126] Pascal Poupart, Zhitang Chen, Priyank Jaini, Fred Fung, Hengky Susanto, Yanhui Geng, Li Chen, Kai Chen, and Hao Jin. 2016. Online Flow Size Prediction for Improved Network Routing. In IEEE ICNP ’16.
[127] Raghu Prabhakar, Yaqi Zhang, David Koeplinger, Matt Feldman, Tian Zhao, Stefan Hadjis, Ardavan Pedram, Christos Kozyrakis, and Kunle Olukotun. 2017. Plasticine: A Reconfigurable Architecture for Parallel Patterns. In ACM/IEEE ISCA ’17. https://doi.org/10.1145/3079856.3080256
[128] Raghu Prabhakar, Yaqi Zhang, and Kunle Olukotun. 2020. Coarse-Grained Reconfigurable Architectures. In NANO-CHIPS 2030. Springer, 227–246. https://doi.org/10.1007/978-3-030-18338-7_14
[129] IO Visor Project. [n.d.]. XDP: eXpress Data Path. https://www.iovisor.org/technology/xdp. Accessed on 08/12/2021.
[130] Jack W Rae, Sergey Bartunov, and Timothy P Lillicrap. 2019. Meta-Learning Neural Bloom Filters. arXiv:1906.04304 (2019).
[131] Alon Rashelbach, Ori Rottenstreich, and Mark Silberstein. 2020. A Computational Approach to Packet Classification. In ACM SIGCOMM ’20. https://doi.org/10.1145/3387514.3405886
[132] Luigi Rizzo. 2012. Netmap: A Novel Framework for Fast Packet I/O. In USENIX ATC ’12.
[133] Joshua Rosen, Neoklis Polyzotis, Vinayak Borkar, Yingyi Bu, Michael J Carey, Markus Weimer, Tyson Condie, and Raghu Ramakrishnan. 2013. Iterative mapreduce for large scale machine learning. arXiv preprint arXiv:1303.3517 (2013).
[134] Alexander Rucker, Tushar Swamy, Muhammad Shahbaz, and Kunle Olukotun. 2019. Elastic RSS: Co-Scheduling Packets and Cores Using Programmable NICs. In ACM APNet ’19. https://doi.org/10.1145/3343180.3343184
[135] Alexander Rucker, Matthew Vilim, Tian Zhao, Yaqi Zhang, Raghu Prabhakar, and Kunle Olukotun. 2021. Capstan: A Vector RDA for Sparsity. Association for Computing Machinery, New York, NY, USA, 1022–1035.
[136] Davide Sanvito, Giuseppe Siracusano, and Roberto Bifulco. 2018. Can the Network Be the AI Accelerator?. In NetCompute ’18. https://doi.org/10.1145/3229591.3229594
[137] Amedeo Sapio, Marco Canini, Chen-Yu Ho, Jacob Nelson, Panos Kalnis, Changhoon Kim, Arvind Krishnamurthy, Masoud Moshref, Dan RK Ports, and Peter Richtárik. 2019. Scaling Distributed Machine Learning with In-Network Aggregation. arXiv:1903.06701 (2019).
[138] Dipanjan Sarkar. 2018. Continuous Numeric Data – Strategies for Working with Continuous, Numerical Data. https://towardsdatascience.com/understandingfeature-engineering-part-1-continuous-numeric-data-da4e47099a7b. Accessed on 08/12/2021.
[139] Danfeng Shan, Fengyuan Ren, Peng Cheng, Ran Shu, and Chuanxiong Guo. 2018. Micro-burst in Data Centers: Observations, Analysis, and Mitigations. In IEEE ICNP ’18. https://doi.org/10.1109/ICNP.2018.00019
[140] Ahmad Shawahna, Sadiq M Sait, and Aiman El-Maleh. 2018. Fpga-Based Accelerators of Deep Learning Networks for Learning and Classification: A Review. IEEE Access 7 (2018), 7823–7859.
[141] Justine Sherry, Sylvia Ratnasamy, and Justine Sherry At. 2012. A survey of enterprise middlebox deployments. (2012).
[142] Anton Shilov. [n.d.]. TSMC & Broadcom Develop 1700-mm2 CoWoS Interposer: 2x Larger Than Reticles. https://www.anandtech.com/show/15582/tsmcbroadcom-develop-1700-mm2-cowos-interposer-2x-larger-than-reticles. Accessed on 08/12/2021. [143] Hartej Singh, Ming-Hau Lee, Guangming Lu, Fadi J Kurdahi, Nader Bagherzadeh, and Eliseu M Chaves Filho. 2000. MorphoSys: An Integrated Reconfigurable System for Data-Parallel and Computation-Intensive Applications. IEEE Transactions on Computers ’00 49, 5 (2000), 465–481.
[144] Giuseppe Siracusano and Roberto Bifulco. 2018. In-Network Neural Networks. arXiv:1801.05731 (2018).
[145] Arunan Sivanathan, Hassan Habibi Gharakheili, Franco Loi, Adam Radford, Chamith Wijenayake, Arun Vishwanath, and Vijay Sivaraman. 2018. Classifying IoT devices in Smart Environments Using Network Traffic characteristics. IEEE Transactions on Mobile Computing ’18 18, 8 (2018), 1745–1759. https://doi.org/10.1109/TMC.2018.2866249
[146] Anirudh Sivaraman, Alvin Cheung, Mihai Budiu, Changhoon Kim, Mohammad Alizadeh, Hari Balakrishnan, George Varghese, Nick McKeown, and Steve Licking. 2016. Packet Transactions: High-Level Programming for Line-Rate Switches. In ACM SIGCOMM ’16. https://doi.org/10.1145/2934872.2934900
[147] Anirudh Sivaraman, Suvinay Subramanian, Mohammad Alizadeh, Sharad Chole, Shang-Tse Chuang, Anurag Agrawal, Hari Balakrishnan, Tom Edsall, Sachin Katti, and Nick McKeown. 2016. Programmable Packet Scheduling at Line Rate. In ACM SIGCOMM ’16. https://doi.org/10.1145/2934872.2934899
[148] Vibhaalakshmi Sivaraman, Srinivas Narayana, Ori Rottenstreich, Shan Muthukrishnan, and Jennifer Rexford. 2017. Heavy-Hitter Detection Entirely in the Data Plane. In ACM SOSR ’17. https://doi.org/10.1145/3050220.3063772
[149] Mario Srouji, Jian Zhang, and Ruslan Salakhutdinov. 2018. Structured control nets for deep reinforcement learning. In ICML ’18. PMLR, 4742–4751.
[150] Arvind K Sujeeth, HyoukJoong Lee, Kevin J Brown, Tiark Rompf, Hassan Chafi, Michael Wu, Anand R Atreya, Martin Odersky, and Kunle Olukotun. 2011. OptiML: an implicitly parallel domain-specific language for machine learning. In ICML ’11.
[151] Jinsheng Sun and Moshe Zukerman. 2007. An Adaptive Neuron AQM for a Stable Internet. In International Conference on Research in Networking ’07. Springer.
[152] Runyuan Sun, Bo Yang, Lizhi Peng, Zhenxiang Chen, Lei Zhang, and Shan Jing. 2010. Traffic Classification Using Probabilistic Neural Networks. In IEEE ICNC ’10.
[153] Tuan A Tang, Lotfi Mhamdi, Des McLernon, Syed Ali Raza Zaidi, and Mounir Ghogho. 2016. Deep Learning Approach for Network Intrusion Detection in Software Defined Networking. In IEEE WINCOM ’16.
[154] Mahbod Tavallaee, Ebrahim Bagheri, Wei Lu, and Ali A Ghorbani. 2009. A Detailed Analysis of the KDD CUP 99 Data Set. In IEEE CISDA ’09.
[155] Simon Thompson. 2011. Haskell: The Craft of Functional Programming. Vol. 2. Addison-Wesley.
[156] Emanuel Todorov, Tom Erez, and Yuval Tassa. 2012. Mujoco: A Physics Engine for Model-Based Control. In IEEE IROS ’12.
[157] C Van Rijsbergen. 1979. Information Retrieval: Theory and Practice. In Proceedings of the Joint IBM/University of Newcastle upon Tyne Seminar on Data Base Systems ’79.
[158] Erwei Wang, James J Davis, Ruizhe Zhao, Ho-Cheung Ng, Xinyu Niu, Wayne Luk, Peter YK Cheung, and George A Constantinides. 2019. Deep Neural Network Approximation for Custom Hardware: Where We’ve Been, Where We’re Going. ACM Computing Surveys (CSUR) ’19 52, 2 (2019), 1–39. https://doi.org/10.1145/3309551
[159] Haining Wang, Danlu Zhang, and Kang G Shin. 2002. Detecting SYN Flooding Attacks. In Twenty-First Annual Joint Conference of the IEEE Computer and Communications Societies ’02, Vol. 3. 1530–1539.
[160] Naigang Wang, Jungwook Choi, Daniel Brand, Chia-Yu Chen, and Kailash Gopalakrishnan. 2018. Training Deep Neural Networks with 8-bit Floating Point Numbers. In NeurIPS ’18.
[161] Shuo Wang, Zhe Li, Caiwen Ding, Bo Yuan, Qinru Qiu, Yanzhi Wang, and Yun Liang. 2018. C-LSTM: Enabling Efficient LSTM using Structured Compression Techniques on FPGAs. In ACM/SIGDA FPGA ’18. https://doi.org/10.1145/3174243.3174253
[162] Keith Winstein and Hari Balakrishnan. 2013. TCP Ex Machina: ComputerGenerated Congestion Control. In ACM SIGCOMM ’13. https://doi.org/10.1145/2534169.2486020
[163] Shihan Xiao, Haiyan Mao, Bo Wu, Wenjie Liu, and Fenglin Li. 2020. Neural Packet Routing. In ACM NetAI ’20. https://doi.org/10.1145/3405671.3405813
[164] Xilinx. [n.d.]. Alveo U250 Data Center Accelerator Card. https://www.xilinx.com/products/boards-and-kits/alveo/u250.html. Accessed on 08/12/2021.
[165] Xilinx. [n.d.]. Xilinx: AXI Reference Guide. https://www.xilinx.com/support/-documentation/ip_documentation/ug761_axi_reference_guide.pdf. Accessed on 08/12/2021.
[166] Xilinx. [n.d.]. Xilinx OpenNIC Shell. https://github.com/Xilinx/open-nic-shell. Accessed on 09/30/2021.
[167] Xilinx. [n.d.]. Xilinx: UltraScale+ Integrated 100G Ethernet Subsystem. https://www.xilinx.com/products/intellectual-property/cmac_usplus.html. Accessed on 08/12/2021.
[168] Zhaoqi Xiong and Noa Zilberman. 2019. Do Switches Dream of Machine Learning? Toward In-Network Classification. In ACM HotNets ’19. https://doi.org/10.1145/3365609.3365864
[169] Francis Y Yan, Jestin Ma, Greg D Hill, Deepti Raghavan, Riad S Wahby, Philip Levis, and Keith Winstein. 2018. Pantheon: The Training Ground for Internet Congestion-Control Research. In USENIX ATC ’18.
[170] Liangcheng Yu, John Sonchack, and Vincent Liu. 2020. Mantis: Reactive Programmable Switches. In ACM SIGCOMM ’20. https://doi.org/10.1145/3387514.3405870
[171] Yasir Zaki, Thomas Pötsch, Jay Chen, Lakshminarayanan Subramanian, and Carmelita Görg. 2015. Adaptive Congestion Control for Unpredictable Cellular Networks. In ACM SIGCOMM ’15. https://doi.org/10.1145/2785956.2787498
[172] Sebastian Zander, Thuy Nguyen, and Grenville Armitage. 2005. Automated Traffic Classification and Application Identification Using Machine Learning. In IEEE LCN ’05.
[173] Jun Zhang, Chao Chen, Yang Xiang, Wanlei Zhou, and Yong Xiang. 2012. Internet Traffic Classification by Aggregating Correlated Naïve Bayes Predictions. IEEE Transactions on Information Forensics and Security ’12 8, 1 (2012), 5–15. https://doi.org/10.1109/TIFS.2012.2223675
[174] Jun Zhang, Xiao Chen, Yang Xiang, Wanlei Zhou, and Jie Wu. 2014. Robust Network Traffic Classification. IEEE/ACM Transactions on Networking ’14 23, 4 (2014), 1257–1270. https://doi.org/10.1109/TNET.2014.2320577
[175] Menghao Zhang, Guanyu Li, Shicheng Wang, Chang Liu, Ang Chen, Hongxin Hu, Guofei Gu, Qianqian Li, Mingwei Xu, and Jianping Wu. 2020. Poseidon: Mitigating Volumetric DDoS Attacks with Programmable Switches. In NDSS ’20. https://doi.org/10.14722/ndss.2020.24007
[176] Yaqi Zhang, Alexander Rucker, Matthew Vilim, Raghu Prabhakar, William Hwang, and Kunle Olukotun. 2019. Scalable Interconnects for Reconfigurable Spatial Architectures. In ACM/IEEE ISCA ’19. https://doi.org/10.1145/3307650.3322249
[177] Yaqi Zhang, Nathan Zhang, Tian Zhao, Matt Vilim, Muhammad Shahbaz, and Kunle Olukotun. 2021. SARA: Scaling a Reconfigurable Dataflow Accelerator. In ACM/IEEE ISCA ’21. https://doi.org/10.1109/ISCA52012.2021.00085
[178] Hongtao Zhong, Kevin Fan, Scott Mahlke, and Michael Schlansker. 2005. A Distributed Control Path Architecture for VLIW Processors. In IEEE PACT ’05.
[179] Chuan Zhou, Dongjie Di, Qingwei Chen, and Jian Guo. 2009. An Adaptive AQM Algorithm Based on Neuron Reinforcement Learning. In IEEE ICCA ’09.\
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
EdgeCore Wedge 100BF-32X Switch: https://www.edge-core.com/productsInfo.php?cls=1&cls2=5&cls3=181&id=335
[2]Xilinx Alveo U250 FPGA board: https://www.xilinx.com/products/boards-and-kits/alveo.html
[3]Intel P4 Studio: https://www.intel.com/content/www/us/en/products/network-io/
[4]Xilinx Vivado Design Tool: https://www.xilinx.com/support/university/vivado.html
[5]Xilinx OpenNIC Shell: https://github.com/Xilinx/open-nic-shell
[6]Spatial DSL: https://github.com/stanford-ppl/spatial
[7]ONF Stratum OS: https://opennetworking.org/stratum/
[8]ONF Open Network Operating System (ONOS): https://opennetworking.org/onos/
[9]MoonGen Traffic Generator: https://github.com/emmericp/MoonGen
本文由 mdnice 多平台发布