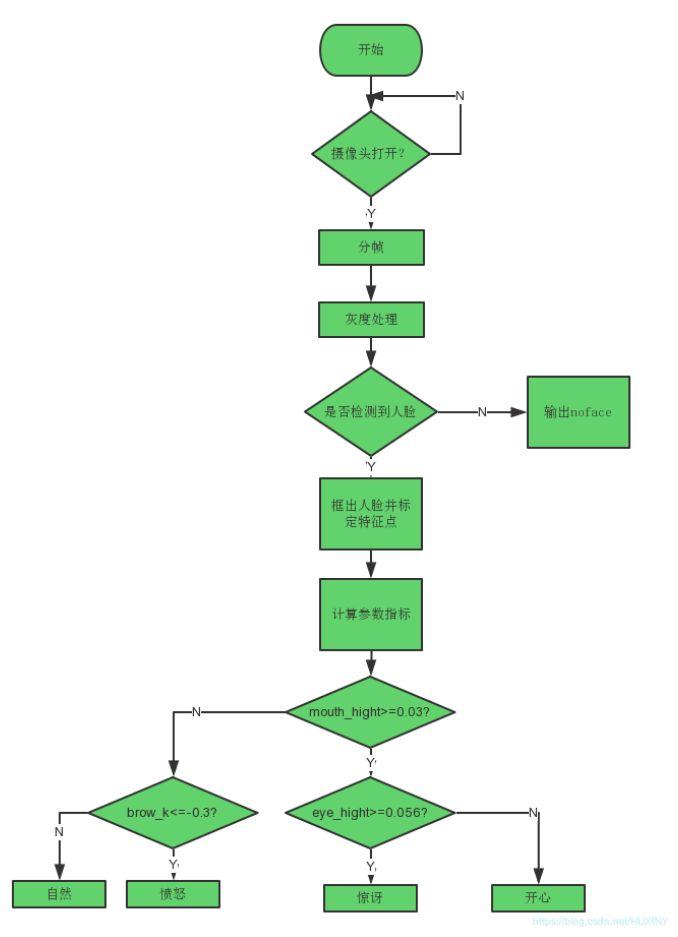
xpath是python做数据解析的库
目录
1 安装
2 解析本地的html文件
2.1 只有一个标签的情况
2.2 有多个标签的情况
3 解析网上的页面
4 xpath表达式
4.1 绝对路径
4.2 两个斜杠表示中间隔了0级或多级
4.3 通过属性查找
4.4 通过索引查找
4.5 获取文本内容
4.6 获取属性
4.7 或运算
5 xpath返回的对象使用xpath
6 常见错误
6.1 存在没闭合的标签
1 安装
pip install lxml

2 解析本地的html文件
2.1 只有一个标签的情况
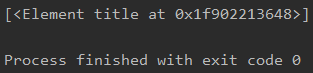
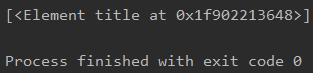
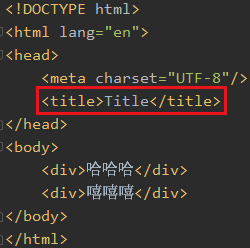
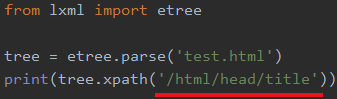
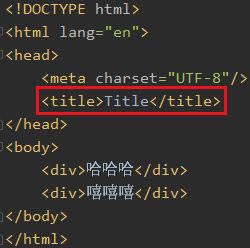
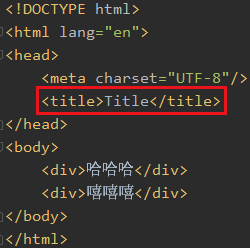
比如我想找到test.html中的title

xpath()中接的是xpath表达式,xpath就和linux中的路径一样,先是html然后是head最后找到title
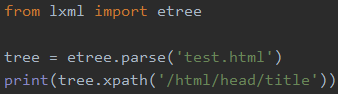
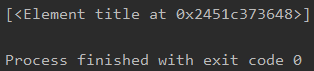
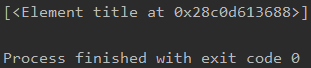
由于title只有一个,所以返回的结果列表中只有一个title对象
2.2 有多个标签的情况
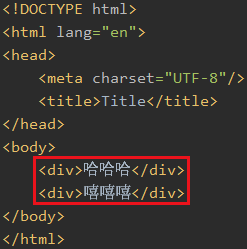
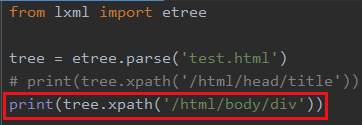
比如我现在想找到这两个div

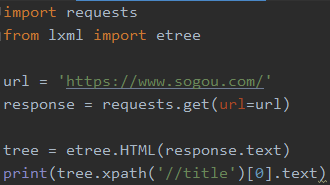
3 解析网上的页面

4 xpath表达式
4.1 绝对路径
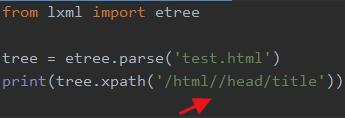
4.2 两个斜杠表示中间隔了0级或多级
可以表示0级

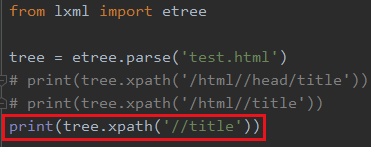
也可以表示多级

由于两个斜杠表示多级,所以一开始的html也没必要写了
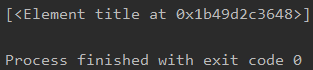
4.3 通过属性查找
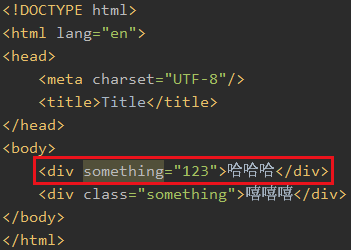
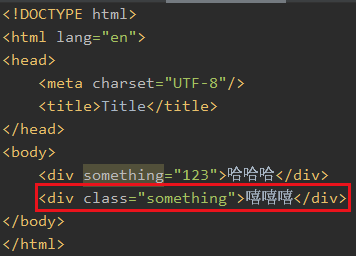
比如我找这个
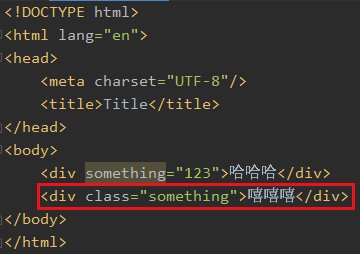
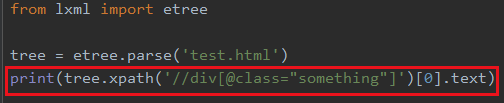
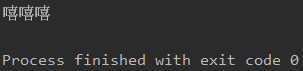
再比如我找这个

4.4 通过索引查找
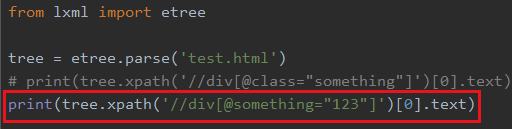
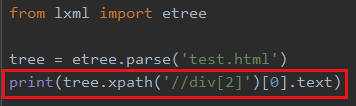
上面我是对tree.xpath()返回的列表进行索引,我们也可以直接写在xpath表达式中,比如我找第二个div
- xpath表达式是从第1个算的,不算从第0个算的
4.5 获取文本内容
上面我是在外部使用的text,你也可以在里面使用text(),比如我想获得所有div的文本内容
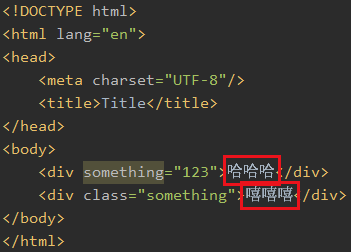

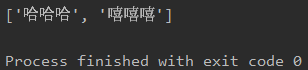
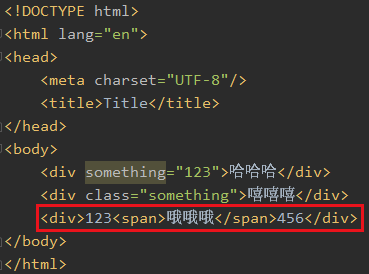
text()只能拿到直系的文本内容,隔一层就拿不到了
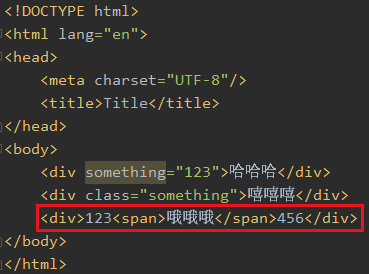
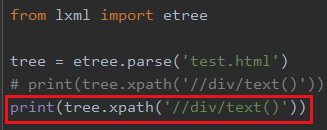

如果你写 //text() 就可以拿到了
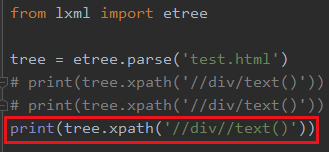

4.6 获取属性
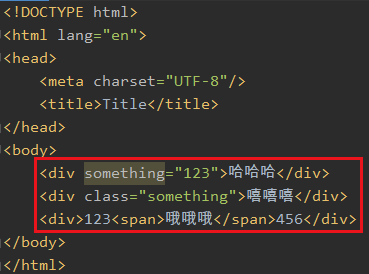
比如我想取所有div的something属性值
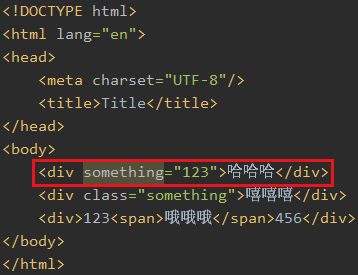
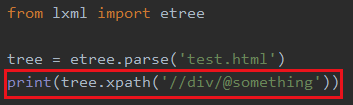
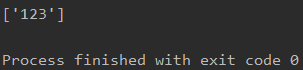
只有一个div有something这个属性,所以只显示一个
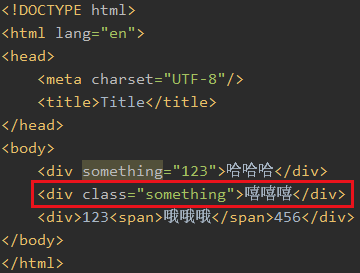
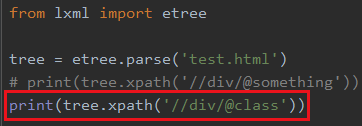
换一个属性也一样,比如class
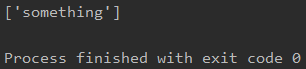
4.7 或运算
比如我现在想那 span或div 的内容


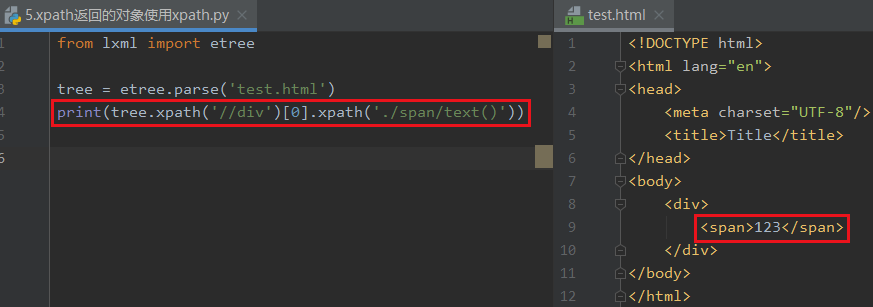
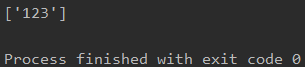
5 xpath返回的对象使用xpath
6 常见错误
6.1 存在没闭合的标签
我现在想找这个title
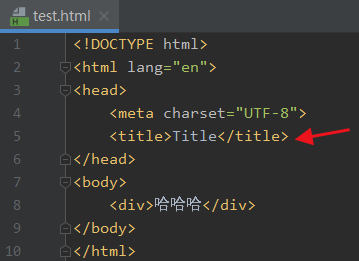
那我可以这样写
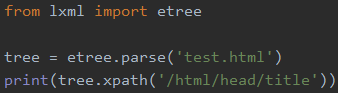
运行后会报错
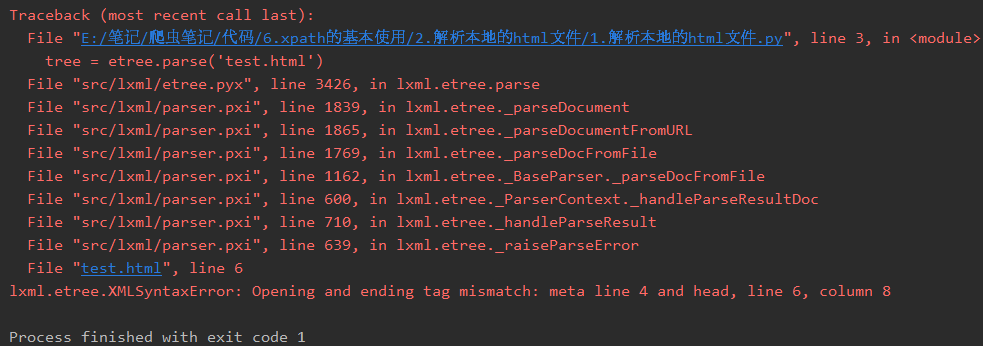
这个错误的原因就是有没闭合的标签,比如这里的meta
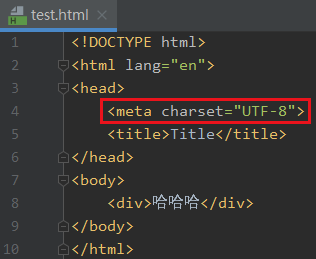
我们需要闭合这里的标签
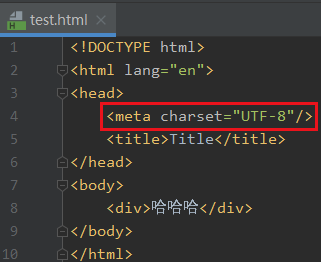
|然后再运行就可以了