hadoop的三种运行模式
- 本地模式:测试本地的hadoop是否能够运行,用来运行官方的代码。
- 伪分布模式:原先有人拿来测试,目前测试都不用这个模式了。
- 完全分布模式:多台服务器组成分布式环境,生产环境使用
分布式主机文件同步命令
scp -r 需要分发的本机文件路径 外部主机的路径xsync -av 需要分发的本机文件路径 外部主机的路径
编写集群分发脚本
编写一个脚本,实现调用xsync 文件名,可以快速将本地文件同步给所有外部主机,并且可以在所有主机的任意路径使用。
- $PATH,查看里面的环境变量
/home/atguigu/bin - 这个路径天然在环境变量中,可以在该路径中编写自己的脚本代码
- 脚本名称为xsync, 文件名参数可以有多个
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
免密登录
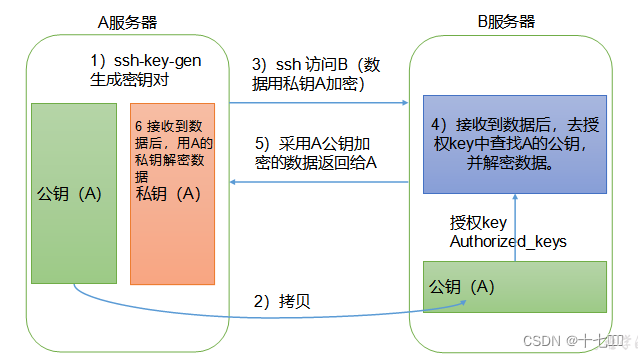
- 每个用户的家目录下都有一个.ssh文件,用来保存公钥私钥
- 公钥私钥生成命令 ssh-keygen -t rsa, 三次回车即可
- 将公钥发送给其他主机
- 其他主机会将其他主机发送过来的公钥保存到authorized_keys文件中
- 其他主机登录时,查验该主机是否在目前的公钥文件中,是的话即可免密登录。
集群规划
原则:老大尽可能分开,小弟尽可能多
hdfs: 老大nn,老大2nn, 小弟dn
yarn: 老大rm , 小弟nm
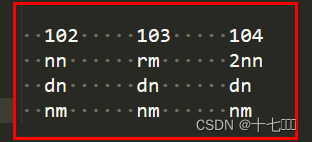
每台主机最多一个datanode节点和nodemanager节点,namenode、resourcemanager、secondnamenode这三个节点为了负载均衡,分别分布在不同主机。
五个重要文件
在/etc路径下,在jar包中有与之对应的默认配置文件default.xml
- core-default.xml ->core-site.xml
- hdfs-default.xml -> hdfs-site.xml
- yarn-default.xml -> yarn-site.xml
- mapred-default.xml -> mapred-site.xml
- workers:配置datanode节点的主机
- core-site文件
- fs.defaultFs:文件系统参数
- 协议更改为hdfs
- NameNode节点的位置hadoop102
- 端口号为8020
- hadoop.tem.dir:指定数据的存储目录
- hadoop.http.staticuser.user: 配置网页登录使用的静态用户
- fs.defaultFs:文件系统参数
- hdfs-site文件
- dfs.namenode.http-address:nn web端访问地址
- dfs.namenode.secondary.http-address: 2nn web端访问地址
- yarn-site文件
- yarn.nodemanager.aux-service: 指定MR走shuffle
- yarn.resourcemanager.hostname: 指定RM节点的位置
- MapReduce-site文件
- mapreduce.framework.name:指定MapReduce跑在yarn上
- workers DataNode节点配置:配置数据库节点在哪些主机。
启动集群
- 格式化
- start-dfs.sh: 启动hdfs
- 单点启动 hdfs --daemon start datanode
- hadoop103:8088/cluster:查看hadoop集群任务运行情况
- 配置历史服务器在102上,内部端口号为10020,外部端口号为19888
- 访问历史服务器方式hadoop102:19888/jobhistory
- 开启日志聚集功能,方便查看日志
集群的启动方式
- 群启:按模块启动
- start/stop-dfs.sh 102
- start/stop-yarn.sh 103
- 单启:按组件启动
- hdfs --daemon start/stop namenode/datanode/secondarynamenode
- yarn --daemon start/stop resourcemanager/ nodemanager
- mapred --daemon start/stop
- 编写脚本实现一次性启动/关闭
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " ============= 启动 hadoop集群 ================"
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.3.4/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.3.4/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.3.4/bin/mapred --daemon start historyserver"
;;
"stop")
echo " ============== 关闭 hadoop集群 ================"
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.3.4/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.3.4/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.3.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac