进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. 连接精度
2. 连接类型
3. 注意事项
Join子句可以对左右两张表的数据进行连接,join语法包含连接精度和连接类型两部分。参照下图帮助大家理解:

上图可知,连接精度分为ALL、ANY、ASOF三种,而连接类型分为外连接、内连接、交叉连接三种。我们对连接类型并不陌生,下面重点介绍连接精度。
为了方便测试,我们创建以下2张表:join_tbl1、join_tbl2,分别创建两张表,并插入数据:
#创建join_tbl1表
node1 :) CREATE TABLE join_tbl1
(
`id` UInt8,
`name` String,
`time` DateTime
)
ENGINE = MergeTree()
ORDER BY id
#向表join_tbl1中插入数据
node1 :) insert into join_tbl1 values (1,'zs','2021-11-01 12:00:00'),(2,'ls','2021-11-01 12:30:00'),(3,'ww','2021-11-01 13:00:00'),(4,'zs','2021-11-01 13:30:00'),(5,'zs','2021-11-01 14:00:00');
#创建join_tbl2表
node1 :) CREATE TABLE join_tbl2
(
`id` UInt8,
`score` UInt8,
`time` DateTime
)
ENGINE = MergeTree()
ORDER BY id;
#向表join_tbl2中插入数据
node1 :) insert into join_tbl2 values (1,100,'2021-11-01 11:55:00'),(1,200,'2021-11-01 12:01:00'),(2,300,'2021-11-01 13:10:00'),(2,400,'2021-11-01 14:30:00'),(6,500,'2021-11-01 15:00:00');
1. 连接精度
连接精度决定了join查询在连接数据时所使用的策略,目前支持ALL、ANY和ASOF三种类型。
- ALL
如果左表内的一行数据在右表中有多行数据与之连接匹配,则返回右表中全部连接的数据,操作如下:
node1 :) SELECT
a.id,
a.name,
a.time,
b.id,
b.score,
b.time
FROM join_tbl1 AS a
ALL INNER JOIN join_tbl2 AS b ON a.id = b.id结果返回了右表中所有与左表id相匹配的数据。

- ANY
如果左表内的一行数据在右表中有多行数据与之连接匹配,则仅返回右表中的第一行连接的数据。操作如下:
node1 :) SELECT
a.id,
a.name,
a.time,
b.id,
b.score,
b.time
FROM join_tbl1 AS a
ANY INNER JOIN join_tbl2 AS b ON a.id = b.id查询结果如下,返回了右表中与左表id相连接的第一行数据

- ASOF
ASOF是一种模糊查询,它允许在连接键之后追加定义一个模糊连接的匹配条件asof_column(此条件要求不等式,大于或者小于)。举例如下:
node1 :) SELECT a.id,a.name,a.time,b.id,b.score,b.time FROM join_tbl1 a ASOF INNER JOIN join_tbl2 b ON a.id = b.id AND a.time>=b.time;2. 连接类型
连接类型与Mysql中的连接类型意思相同,这里就不再详解介绍,直接操作,操作如下:
- INNER
node1 :) SELECT a.id,a.name,a.time,b.id,b.score,b.time FROM join_tbl1 a INNER JOIN join_tbl2 b ON a.id = b.id;
- LEFT OUTER JOIN
node1 :) SELECT a.id,a.name,a.time,b.id,b.score,b.time FROM join_tbl1 a LEFT OUTER JOIN join_tbl2 b ON a.id = b.id;
- RIGHT OUTER JOIN
node1 :) SELECT a.id,a.name,a.time,b.id,b.score,b.time FROM join_tbl1 a RIGHT OUTER JOIN join_tbl2 b ON a.id = b.id;
- FULL JOIN
node1 :) SELECT a.id,a.name,a.time,b.id,b.score,b.time FROM join_tbl1 a FULL OUTER JOIN join_tbl2 b ON a.id = b.id;
- CROSS
CROSS JOIN 表示交叉连接,返回左表与右表两个数据集合的笛卡尔积,不需要指定JOIN key 连接键。
node1 :) SELECT a.id,a.name,a.time,b.id,b.score,b.time FROM join_tbl1 a CROSS JOIN join_tbl2 b;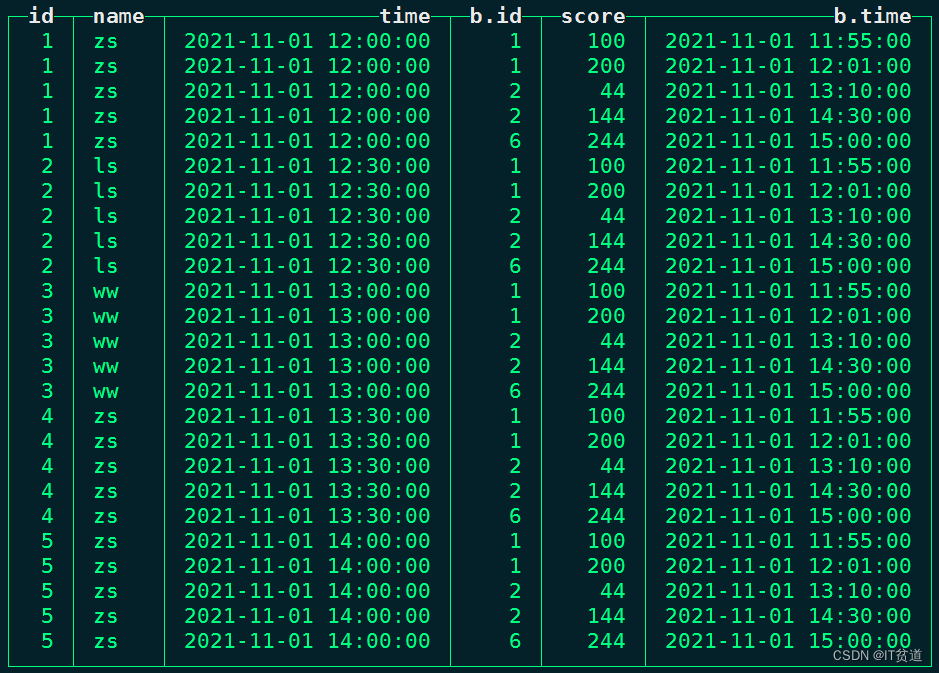
3. 注意事项
在clickhouse使用中,一般作为DWS或者DM层数据使用,很少会有JOIN操作。在使用JOIN查询时,为了优化JOIN查询性能,应该遵循左大右小的原则,即将数据量小的表放在右侧。这是因为在执行JOIN查询时,无论使用哪种JOIN连接方式,右表都会被全部加载到内存中与左表进行比较。
另外,join也没有缓存机制,每一次join查询就算是执行相同的sql查询,也会生成一次全新的查询计划。